磨削功率信号采集与动态功率监测数据库建立方法*
2022-07-14王进玲李建伟田业冰刘俨后
王进玲,李建伟,田业冰,刘俨后,张 昆
(山东理工大学 机械工程学院,山东 淄博 255000)
磨削功率信号在线监测便捷,被广泛用于磨削砂轮状态比较、磨削工艺优化和效能提高等中[1]。TIAN 等[1]通过监测镍合金平面磨削过程中的功率信号,智能判别了砂轮的磨损状态;易军等[2]建立了磨削功率、齿面硬度、巴克豪森信号值之间的相互关系,用信号监测方式可无损判定齿轮成形磨削时的烧伤;CHI 等[3]针对轴承外滚道内切入磨削,提出了功率信号和材料去除率的通用模型,以此评估砂轮的性能和工件磨削质量;DAI 等[4]提出了磨削效能最优的高速磨削加工工艺方案。由此可见,磨削功率监测对于推动磨削加工过程改进乃至磨具磨料生产中数据驱动的高效绿色生产具有显著意义[5]。但磨削加工中在线采集的功率信号为动态流数据,数据量庞大且不可避免地混入机床噪声等,对其动态数据直接进行存储,不仅提高磨削数据库的存储成本,而且增加了通信响应时间,降低了生产效率[6]。因此,有必要对磨削功率监测信号数据的提取和快速存储技术进行研究。
尹晖[7]基于磨削功率监测信号建立比磨削能模型,直接存储了比磨削能静态数据,但后续无法调用,用来对磨削砂轮进行比较及能耗分析。时间序列数据库是针对动态流数据开发的快速存储工具,能够较好地适应动态数据响应需求,但其价格昂贵、用途单一,不适合磨削功率数据库的工业化存储和实时分析要求[8]。关系型数据库以行和列索引进行序列数据的快速存储,读取方便,响应较快,但需要建立复杂的检索和读取关系[9]。王玙等[10]根据不确定时间序列和关系型数据库特点,提出了一系列数据存储规则并统一系统存储算法,能够在数据采集时自动进行关系型数据库存储。RHEA 等[11]提出基于Little Table 工具的关系型数据库存储模型,通过在2 个维度上的聚类表优化时间序列数据,以时间戳对行进行分区,以提高其检索效率。
以上研究主要针对的是一般时间序列的数据优化与关系型数据库读写,以时间戳对关系型数据库进行分区,可提高数据读取速度。针对磨削过程中的监测功率动态数据而言,因其存在着典型的锯齿波和二值化特征,存储数据的波峰和波谷点在一定程度上能够较好地还原原始动态数据,且以磨削状态和存储数据的波峰、波谷时域标记点(时间戳)来对关系型数据库进行行分区,更有数据针对性。因此,基于工业化磨削过程中的功率监测动态数据库的高效存储和快速响应需求,设计一种适用于磨削功率数据的关系型数据库建立方法。利用II 型切比雪夫低通滤波器滤除噪声,提高功率数据信噪比;基于寻峰寻谷法提取功率信号波峰和波谷点并进行时域标记;且为保证数据的完整性及精度进行首尾及插值修正,显著降低数据规模。同时,基于二值化对磨削加工过程进行工作状态标记,并将数据转换为字符串存储在关系型数据库单元格中,以波峰、波谷点的时域标记和回程、磨削二值化的时间标记,对关系型数据库进行行分区,提高磨削数据库响应速度。
1 磨削功率信号采集实验系统
1.1 磨削功率采集实验平台
采集实验平台如图1所示,由RIFA 全自动智能磨床(工作电压为380 V,频率为50 Hz)、主轴功率计PPC−3、数据采集卡NI 9203、便携信号采集机箱NI cDAQ 9174和计算机等组成。磨削实验材料为GCr15 轴承钢;磨削用砂轮为陶瓷结合剂棕刚玉平型砂轮,尺寸为600 mm(外径)× 25 mm(宽度),棕刚玉磨粒基本尺寸为100 μm。砂轮速度为50 m/s,工件转速为 158 r/min,加工余量为10 mm。

图1 磨削功率采集实验平台Fig.1 Grinding power acquisition experimental platform
图1 中,主轴功率计PPC−3 通过3 个电压钳和3个电流钳连接在磨床主轴电机交流变频器输出线上,采集磨床主轴的电压和电流值并计算磨削过程中的功率值,将磨削功率转换成4~20 mA 的电流。同时,通过接入NI cDAQ 9174 机箱中的NI 9203 数据采集卡进行实时信号采集,并用USB 数据线连接至计算机,使得基于LabVIEW 软件开发的功率采集模块能够获取磨削功率数据。
1.2 磨削功率信号采集与数据库存储系统
利用LabVIEW 和SQL Server 软件开发的磨削功率信号采集与数据库存储系统界面如图2所示。将图2中采集的磨削功率动态流数据标记为y(n)(n为采样点总个数)。采样频率fs设置为1 000 Hz,磨削加工工件8个循环,在实验时间为2 090 s 时采样点个数n=2 090 000,则得到2 090 000 个磨削功率数据点yi(i=0,1,···,2 089 999),其集合y(2 090 000)可标记为:
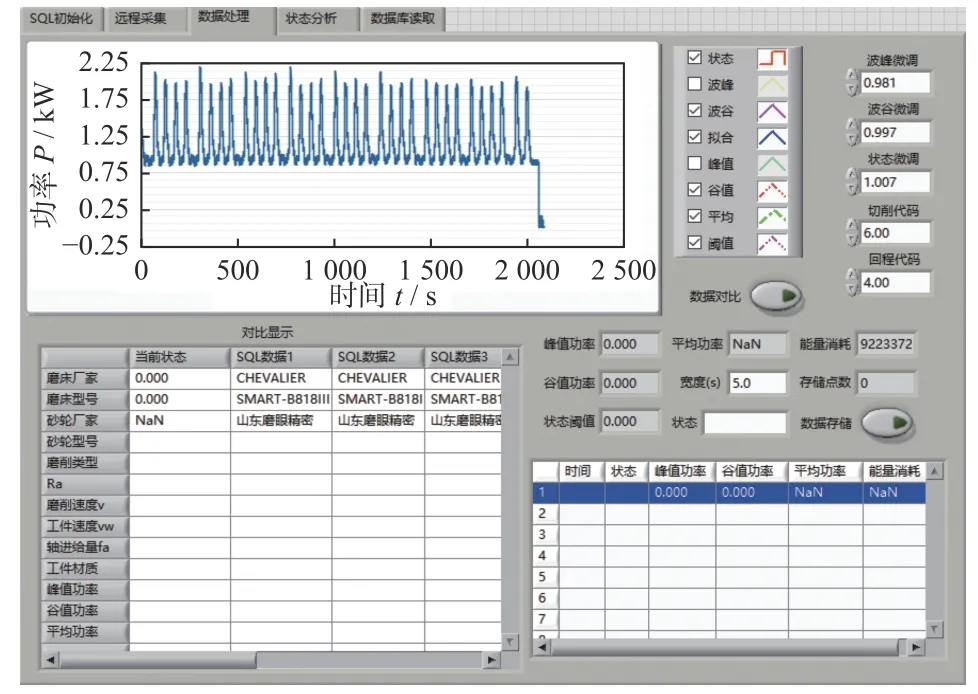
图2 磨削功率信号采集与数据库存储系统界面Fig.2 Interface of grinding power signal acquisition and database storage system
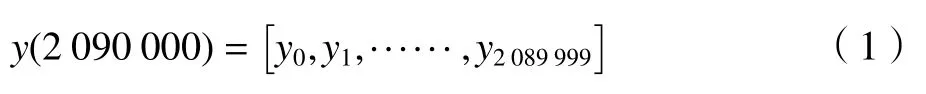
设磨削功率y0数据点对应的采样时间为t0,则yi数据点对应的采样时间ti为:
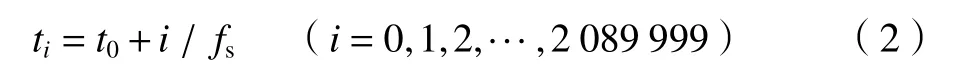
由此说明,功率动态流数据样本量巨大。若工业生产线上连续采集则数据量成倍增加,会严重降低磨削功率数据库响应速度。
2 磨削功率信号特征提取、压缩及关系型数据库存储方法
磨削功率信号的特征提取、压缩和关系型数据库存储流程如图3所示。磨削功率采集实验平台采集的功率信号频率为工频50 Hz,针对磨削功率信号含高频电气和机械噪声等的特性,选用低通滤波器,消除功率信号中的高频尖峰和毛刺噪声,进行数据清洗;后利用信号的波峰波谷特性进行趋势拐点提取,并进行首尾处理及插值修正,以保证数据的拟合精度和完整性;再基于二值化状态标记对回程和磨削2 种状态进行特征标记;最后用LabVIEW 对功率信号特征数组和字符串进行相互转换,并以开始、波峰、波谷、插值和结束状态的时间域对字符串行进行分区,顶层则通过Lab-SQL 对磨削数据库进行互访和管理。

图3 磨削功率信号特征提取、压缩和存储流程Fig.3 Extraction,compression and storage flow of grinding power signal
2.1 Ⅱ型切比雪夫低通滤波器
受磨床、环境干扰及采集系统、人为因素等的综合影响,采集的磨削功率信号不可避免地混入大量噪声和异常值,需对其波形进行滤波处理,以去除测量信号中多余的信号突变及毛刺,并减少波峰波谷特征提取时出现的过多虚峰和虚谷。相比于I 型切比雪夫滤波器的通带波动,Ⅱ型切比雪夫滤波器的通带更为平坦[12],如图4所示。因此,采用Ⅱ型切比雪夫滤波器进行低通滤波,其幅度H(ω)的特性函数为[13]:
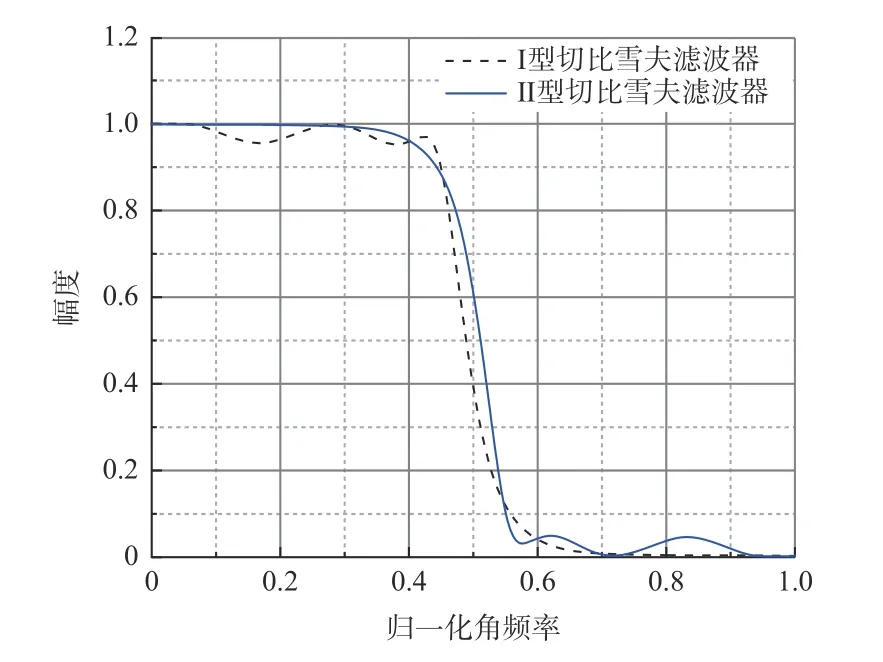
图4 Ⅰ型和Ⅱ型切比雪夫滤波器的频率响应Fig.4 Frequency response of type Ⅰ and type Ⅱ Chebyshev filters
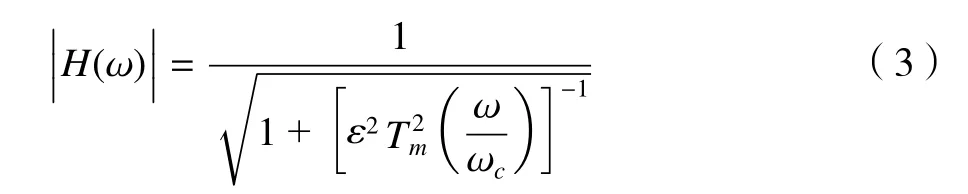
式中:ω为数字域频率,单位是rad/s,表示序列变化的速率;ωc为通带截止频率;m为滤波器的阶数;ε为小于1 的正常数,表示通带内幅度波动的程度,ε愈大,波动幅度也愈大;Tm为m阶切比雪夫多项式,其定义为:

Ⅱ型切比雪夫滤波器的低通滤波频率设置为10 Hz[14],阶数设置为2,滤波后的磨削功率数据如图5所示,其中图5b 是图5a 中红框内数据放大后的图,图5c是图5b 中红框内数据放大后的图。
对比图2 中采集的原始功率数据波形,图5 滤波后的波形更平滑,高频尖峰和毛刺显著减少。滤波后的功率数据为Fi(i=0,1,···,2 089 999),其集合F(2 090 000)可标记为:

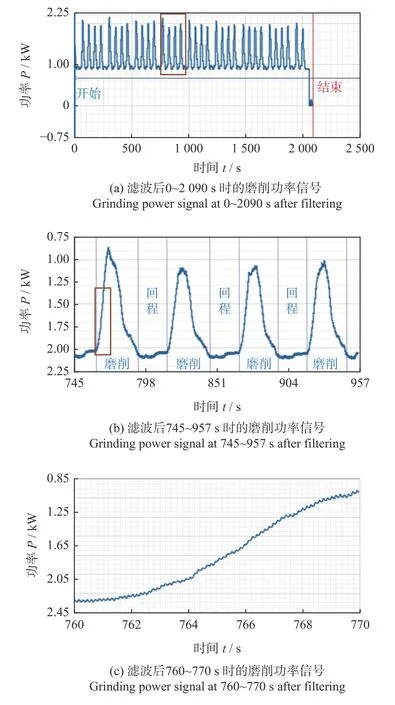
图5 滤波后的功率数据Fig.5 Filtered power data
2.2 寻峰寻谷
从图5b、图5c 的局部放大图可进一步看出:磨削功率信号由锯齿状波形组成,其记录的波峰和波谷值可准确描述磨削功率变化规律,同时大大减少数据存储量。峰值检测是在满足一定性质的信号中寻找局部极大值或极小值的位置和振幅的过程。在功率信号峰谷值提取中,使用LabVIEW 中的波形波峰检测功能,获取局部极大值和极小值的数量和位置。2 次搜索后得到的波峰幅值和时间位置序列为:
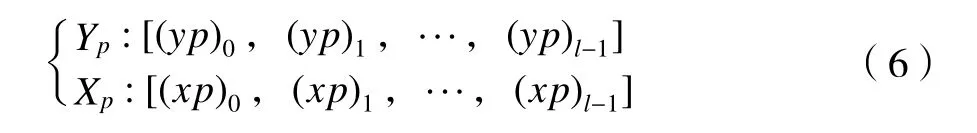
以及波谷的幅值和位置序列为:
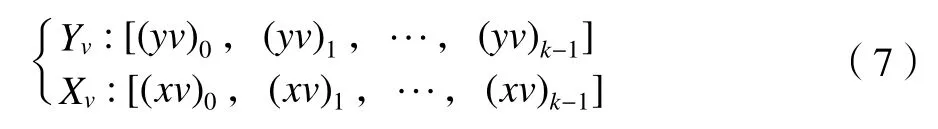
式中:Yp表示波峰幅值数组;(yp)0,(yp)1,…,(yp)l-1表示l个波峰幅值分量;Xp为其对应的时间数组;(xp)0,(xp)1,…,(xp)l-1表示l个波峰幅值分量对应的时间;l为寻峰得到的波峰个数,提取的波峰数l为16 807。相应的,Yv表示波谷幅值数组;(yv)0,(yv)1,…,(yv)k-1表示k个波谷幅值分量;Xv为波谷幅值对应的时间数组;(xv)0,(xv)1,…,(xv)k-1表示k个波谷幅值分量对应的时间;k为寻谷得到的波谷个数,波谷数k为16 808。
2.3 数据首尾点处理
图6 为数据首尾点丢失示意图。如图6所示:峰谷点正好不在功率信号的首尾端,在此情况下,峰谷提取过程中可能会造成数据的首尾点丢失。提取滤波后数据的首尾点值(0,F0),(n−1,Fn−1)(n=2 090 000),将其与波峰波谷幅值和位置数组(Xp,Yp),(Xv,Yv)合并得到峰谷拟合数组(XY)pv,并对其进一步进行插值修正处理。

图6 数据首尾点丢失示意图Fig.6 Schematic diagram of data head and tail point loss
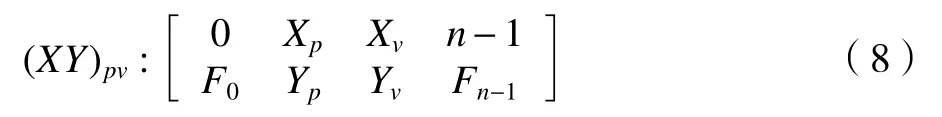
2.4 插值修正
当采样波形的直线拟合度较差时,需对拟合数据进行插值修正。幅值坐标插值修正方法需求出插值点幅值并检索对比,但计算机无法对浮点型数据直接对比。因此,采用时间坐标插值修正方法。图7所示为插值点数分别为0,1,2,3,5 和8 时的拟合示意图。如图7 显示:随插值点数增加,插值拟合精度提高,同时磨削数据库需记录的数据量增大。当图7e 中所示插值点数为5 时,拟合波形基本接近滤波后的原始数据波形。因此,选择5 点插值方法进行波形插值修正。
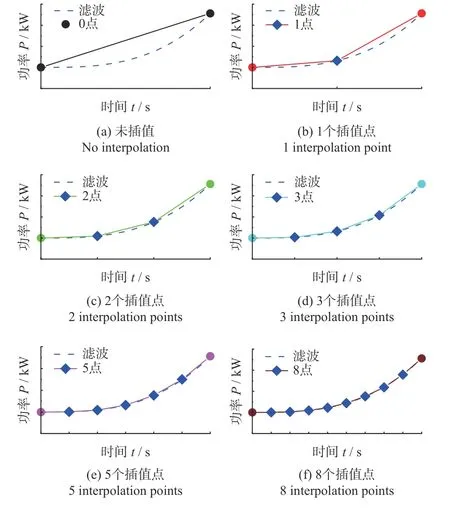
图7 不同插值点数时的拟合示意图Fig.7 Fitting diagram of different interpolation points
5 点插值法将功率相邻峰谷幅值等分得到插值点幅值yavi,时间位置等分后取整得插值点位置xavi。按插值点位置坐标xavi检索滤波后数据F(2 090 000),从中得到检索后的对应数据Fxavi。设定插值拟合点的辨识偏差为 δM,将Fxavi与yavi比较,满足

对插值点进行标记提取,得到插值数组(Xav,Yav):
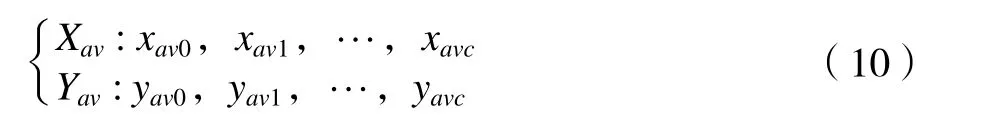
式中:c为插值点个数;Yav是插值点功率值;yav0,yav1,…,yavc是插值点功率分量值;Xav为插值点功率对应的时间;xav0,xav1,…,xavc表示插值点功率分量对应的时间。
将峰谷拟合数组(XY)pv与插值数组(Xav,Yav)合并,得二维数组XY1(2,M):
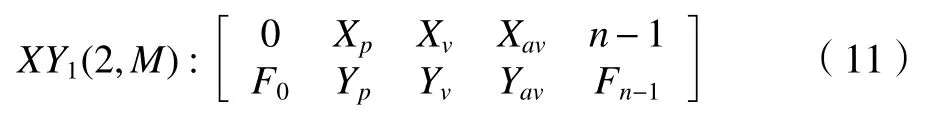
式中:M为经过数据提取和插值后的数据个数。
2.5 状态标记和去重
在磨削加工中,一个完整的磨削加工过程是磨床往复运动的过程,包含磨削加工模式和回程模式2 种工作状态,表现出的磨削功率信号是周期变化的稳定信号。因此,提出基于二值化的磨削功率信号状态标记方法,状态标记流程如图8所示。
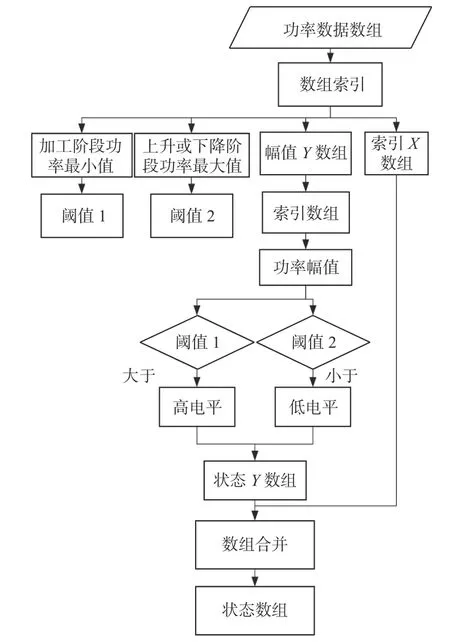
图8 状态标记流程图Fig.8 Flow chart of status marking
首先,将磨削加工阶段功率信号的最小值设定为阈值1,将磨削功率信号上升或下降阶段的最大值设置为阈值2;然后,搜索功率数据中所有大于阈值1 的点用高电平表示,标记为磨削加工模式,所有小于阈值2的点用低电平表示,标记为回程模式;最后,将索引得到的低电平和高电平标记点合并为状态数组。
图9 为0~180 s 时状态标记后的磨削功率信号。图9 中数据分为2 部分:一部分为搜索得到的低电平和高电平数据,为方波状波形;另一部分为搜索得到的状态数据拟合得到的磨削功率信号。因此,可将磨削回程和加工模式的数据分别标识和提取。
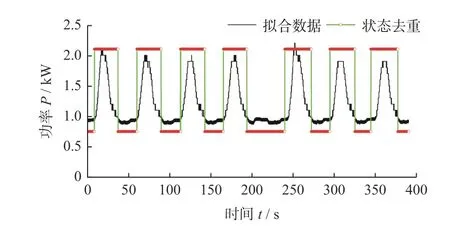
图9 状态标记后的磨削功率信号Fig.9 Grinding power signal after status marking
状态标记后的状态数组是逐点显示的,为了进一步减少数据量,需要对状态数组进行去重。状态去重流程如图10所示。图10 中:通过遍历所有状态标记点,比较前后2 个标记点的状态标记值是否相等,若相等则认为其属于同一重复标记点,删除后状态点。以此类推,最终得到磨削回程/加工模式状态开始和结束时的坐标,保留每个回程/加工状态的磨削功率数据序列的第一个和最后一个元素。
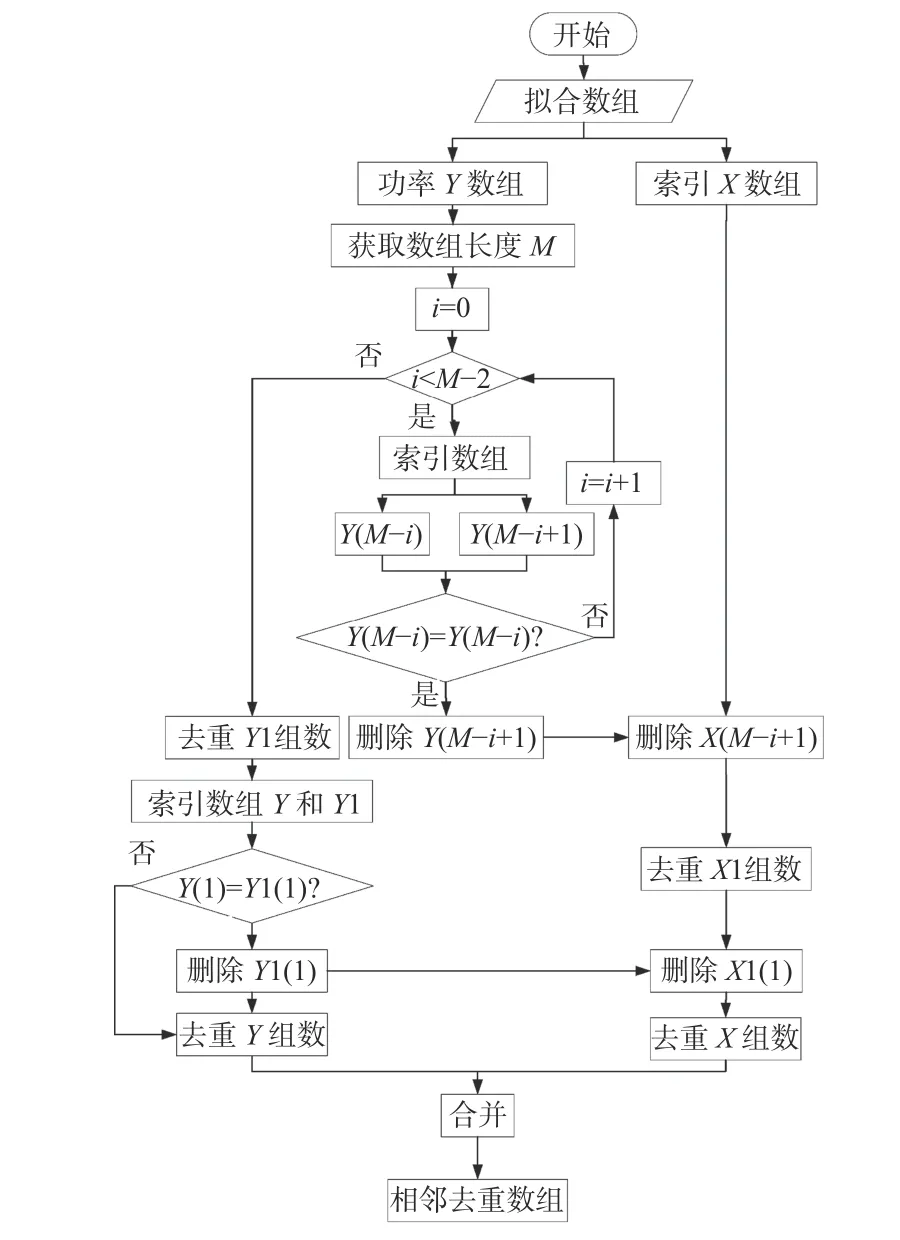
图10 状态去重流程图Fig.10 Flow chart of removing duplicate states
去重后的结果示意图如图11所示。对比图9、图11中只有磨削状态改变的起始状态标记点被保留,用以保证磨削过程中回程和加工状态改变的数据点能够储存在磨削数据库中。状态去重后得到的二维数据表示为XYs(2,N):
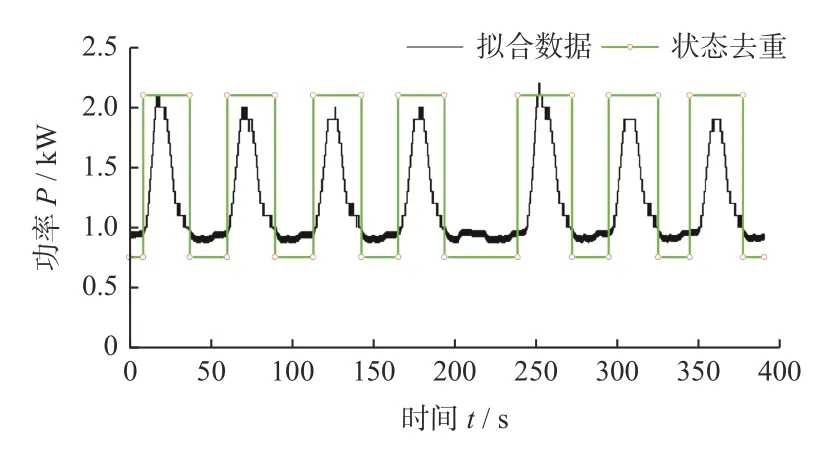
图11 状态去重结果示意图Fig.11 Schematic diagram of state deduplication results
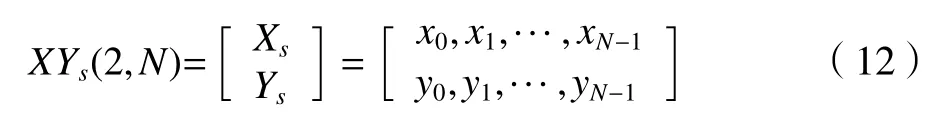
其中:N表示经过状态去重后的插值点个数,N为19 379;Ys,Xs分别表示状态去重后的磨削功率数组和时间索引数组;y0,y1,…,yN−1和x0,x1,…,xN−1分别表示状态去重后的磨削功率数组分量和对应的时间索引分量。
2.6 关系型数据库存储
针对磨削功率动态数据的典型特征,以开始状态时域标记、波峰时域标记、波谷时域标记、插值点时域标记和结束状态时域标记[0,Xp,Xv,Xs,n−1]为时间戳对磨削功率特征数据进行行分区,行分区区间以空格标识。
在LabVIEW 中使用数组至电子表格字符串转换功能,将拟合去重和状态标记后得到的时间序列数组转换为电子表格字符串。分隔符“,”用于对电子表格文件中的栏进行分隔,即分隔各个元素;空格符“ ”用于对磨削功率特征数据进行时间区划分;TAB 符为行结束符,进行行间分隔。因此,得到时间序列数组的字符串(关系型数据库的表示方式)为:
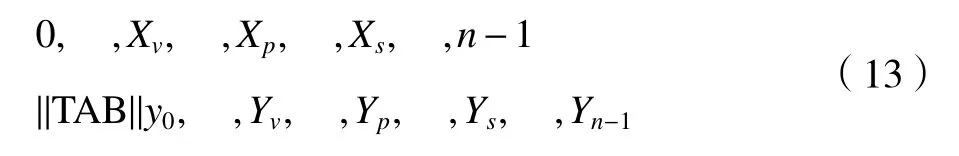
在LabVIEW 中,可调用免费工具包Lab SQL,对关系型数据库进行互访和管理。将式(13)的字符串储存在SQL Server 数据表的单元格中,建立磨削功率动态数据的关系型数据库;同样,使用相同方法可将拟合的字符串还原为二维数组。
2.7 验证实验及结果
按照上述方案对磨削实验平台采集的如图2所示的磨削功率信号进行数据提取、拟合和存储验证等。提取、拟合信号界面和拟合后的功率信号波形数据如图12所示,其中图12c 是图12b 中红边方框内数据放大,图12d 是图12c 中红边方框内数据放大。

图12 功率信号y(2 090 000)的拟合波形数据Fig.12 Fitting waveform data of y(2 090 000)power signal
对比图12b、图12c 和图12d 中的原始波形,提取和拟合后的波形与原始波形基本一致,表明本文所提方法能够保证数据的提取和拟合精度。进一步从图12b~图12d 中可看出:相比于原始功率波形5 s 需存储5 000 个数据点,功率波形经提取、插值拟合和去重后,只需存储23 个数据点,数据存储量大大降低。
总之,对磨削过程2 090 s 的所有功率数据进行统计,共提取功率信号波峰点数16 809 个、波谷点数16 808 个、首尾点2 个、去重后插值点数19 379 个,数据由y(2 090 000)变换为XY(2,52 998),将2 090 000个动态数据点转变为2 × 52 998 个单元格数据,建立的磨削数据库存储成本仅为原数据的5.07%。数据规模大幅度缩小,访问速度显著提升。与此同时,经过数组至电子表格字符串转换功能,将拟合数组XY(2,52 998)转换为电子表格字符串,储存在SQL Server 数据表的单元格中,建立功率动态数据的关系型数据库。所以,本文方法建立的监测动态功率数据库能显著提高智能磨削系统的通信效率。
3 结论
基于LabVIEW 软件开发动态磨削功率信号在线监测与数据库存储系统,针对磨削过程监测的功率信号数据量大且混含噪声的问题,提出一种磨削功率动态数据典型特征提取和关系型磨削数据库建立方法。在砂轮速度为50 m/s,工件转速为158 r/min,加工余量为10 mm 的磨削条件下进行轴承钢磨削实验,采集到的磨削功率信号动态数据集合为y(2 090 000),将其变换为XY(2,52 998)电子表格字符串,建立了磨削过程监测动态功率数据库。
在保证数据精度的前提下,将2 090 000 个动态数据点转变为2×52 998 个单元格数据,其数据量降至原数据的5.07%,大大减小了数据存储量,可在工业化智能磨削或磨削数据库技术上应用。此外,功率数据库研究方法具有通用性,可推广应用到其他信号数据(如力、振动等)和磨料磨具生产行业时间序列数据的存储和管理上。
