基于音节时间长度高斯拟合的汉语音节切分方法
2016-05-14张扬赵晓群王缔罡
张扬 赵晓群 王缔罡


摘要:研究汉语自然语音音节切分方法具有明显现实意义,比较准确的自然语音切分方法可以代替人工对一些拥有参照文本的语音进行标注。然而至今为止并没有完全准确的汉语语音音节切分方法。依据相同发音环境下汉语语音音节时间长度服从某种高斯分布和相邻语音音节之间存在短时能量波谷两个假设,提出了基于音节时间长度高斯拟合的汉语音节切分方法。对算法进行分析,根据初步切分短时能量波谷分散到各分语音段的特性,提出了简化算法,有效降低了该音节切分方法的时间复杂度。实验结果表明,音节切分准确度(与人工标注切分时间距离平方的均值)达到小数点后3位,在台式机Matlab环境下运算时间均不超过1s,可以达到应用要求。
关键词:汉语;自然语音;音节切分;时间长度;波谷;高斯分布
中图分类号:TP391.4 文献标志码:A
Abstract:So far away, there is no accurate method for Chinese natural speech segmentation of syllables,which is meaningful in labeling speech with reference text instead of people. According to two hypotheses that time spans of Chinese syllables under the same pronunciation obey Gauss distribution and shorttime energy valley exists between two adjacent syllables, Chinese speech segmentation method based on Gauss distribution of time spans of syllables was proposed. A simplified method based on distribution of energy valleys was given, which effectively reduced the time complexity of this speech segmentation method. The experimental results show that segmentation accuracy (mean square value of time spans between artificial labels and labels created by this method) achieve 10-3 and computing times are less than 1s in Matlab of PC.
Key words:Chinese; natural speech; speech segmentation; time span; valley; Gauss distribution
0 引言
在信息科学领域,语音切分指辨识出语音段中所需单位语音(如音素、音节)的时间位置。目前为止,语音切分用到的方法基本分为基于隐马尔可夫模型(Hidden Markov Model,HMM)的方法[1-2]、基于边界模型的方法[3]以及HMM与边界模型混合的方法[4]。在国内,从事相关研究的主要有中国科学院研究生院、北京邮电大学及哈尔滨工业大学等,研究方向有语音音素切分[5]、音节切分[6]及语句切分[7]等。其中音节切分研究结果并不理想,表现在对音节开始、音节结束和音节交界处的分类很差[6]。在国外,从事相关研究的有韩国建国大学、剑桥大学及哥伦比亚大学等。由于英语等印欧语系语言的特点,对音节切分的研究较少,主要研究集中在音素切分[8-9]。
研究自然语音切分技术具有明显现实意义,较准确的自然语音切分方法可以代替人工对一些拥有参照文本的语音进行标注,大大减少类似语料库建设或广播语料后期处理中的标注时间,同时降低人工标注成本。本文将语音音节时间长度的分布规律应用到拥有参考文本的自然语音切分当中,提出了相同发音环境下汉语语音音节时间长度符合高斯分布及相邻语音音节之间存在短时能量波谷的假设并予以验证。以改进的双门限法对语音进行第一次切分,在此基础上计算各种波谷组合情况下语音切分构成可能音节的存在概率的和(可能音节存在概率来源于相同环境下少量已切分语段拟合的分布),得到存在概率和最大的切分。同时提出了简化算法,大大缩减了语音切分花费的时间。实验结果表明,本文方法切分音节准确度(与人工标注切分时间距离平方的均值)达到小数点后3位,同时在台式机Maltab环境下运算时间均不超过1s,可以达到应用要求。
1 基于高斯拟合的语音切分方法
在相同的发音环境下,又已知汉语语音段中包含的音节数(以字为单位)时,可以抽取小部分语音统计发音音节时间长度,拟合音节时间长度的分布,利用传统方法对其进行初步切分,再利用波谷及拟合的音节时间长度分布,对语音段进行再切分,最终达到切分出语音段各音节时间位置的目的,流程如图1。
基于高斯拟合的语音切分方法,可以用来对拥有对应文本的汉语语音段进行切分并标注。其在传统双门限方法的基础上,引入音节时间长度分布,以波谷为依据,实现了以音节(以字为单位)为切分目的的语音切分。
1.1 两个合理假设的提出
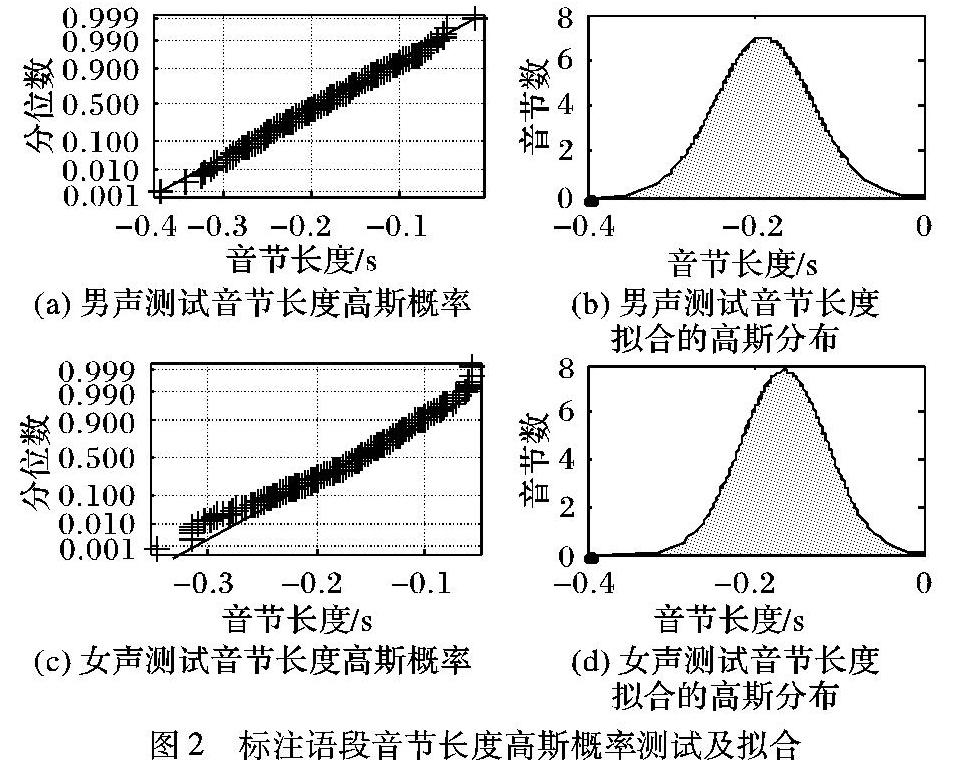
本文算法依托于两个假设:1)在相同发音环境下,汉语语音音节(以字为单位)时间长度(后面简称长度)服从某种高斯(正态)分布;2)汉语语音相邻音节(以字为单位)之间一定存在短时能量的波谷。对两个假设进行验证:选取2段语音(一段为男声朗读语音,共451个字节,一段为女声新闻语音,共581个字节)并进行人工标注,根据人工检验,标注点均落在短时能量波谷附近,假设2得以验证;根据标注分别计算两端语音的音节长度,进行正态化检验测试,测试结果理想,假设1得以验证。正态化检验方法参照文献[10]。图2为根据正态化检验测试结果绘制的图形。
测试音节长度由其标注的起始时间减去终止时间所得,所以图中音节长度均为负值。测试语音长度及所属分位数所对应坐标以“+”标出。若测试音节长度符合高斯(正态)分布,则其对应坐标应该接近图中实线。根据图2(a)、(c)中标出的数据坐标可以看出,两段测试语音音节长度均符合高斯(正态)分布。根据数据计算拟合得到男声语音段音节长度均值为-0.1899s,方差为0.0571s,正态分布图如图2(b)所示,女生语音段音节长度均值为-0.1654s,方差为0.0516s,正态分布图如图2(d)所示。
1.2 改进双门限端点检测算法
原双门限端点检测算法(本文讨论的双门限算法是以短时能量和短时过零率为检测门限的端点检测算法)在没有背景噪声的情况下,已经可以较准确地将语音段及静音段区分。具体算法实现见文献[11]。本文算法首先利用双门限法对语音段及静音段作初步分割,因为整体算法需要,对原双门限法作以下改进:
1)对初始无话帧判断的改进。在对语音数据进行分帧,求取平均能量及平均过零率以后,需要通过语音起始静音段的短时能量及短时过零率来设定两个门限。原方法起始静音段由人工给出,对其进行相应改进,使其尽量能够自动给出。自动给出要求背景噪声不明显。自动给出的方法会有少数情况不准确,并影响后续判断,但由于这种不准确十分突出,可以被判断出,在改变能量判别门限时区分对待即可。假设输入语音段分帧后第i帧短时过零率为zcr(i),则寻找帧数j,使得:
则判断从第0帧到第j帧为静音段,其中Z为过零率突变门限。本文不考虑含背景噪声情况,如果语音段含较强背景噪声,则上述改进失效。
2)动态改变能量判别门限,使语音段初步切分数目达到音节数目的一半及以上。依据自动划分的初始静音段的短时能量大小,可以分为两种情况: 一种是划分初始静音段短时能量远小于语音段平均能量(文中方法以语音段平均能量的0.125倍为判别是否远小于的门限),即准确划分静音段情况;另一种是划分初始静音段短时能量接近甚至远大于语音段平均能量,即没能准确划分静音段情况。能量判别门限ampth变化规则如下:
其中: ampth1表示初始静音段短时能量最大值,avamp表示语音段平均能量。
随着能量判别门限的增加,被判断为静音的帧数增加,从而增加了切分出的语音段数目。这样做的原因是,如果初始语音段切分数目太少,将完全依靠波谷及存在概率对语音段切分,准确性将大大降低,同时计算时间将大大增加(时间增加原因详见2.1节)。
3)将最小静音长度改为帧数平均值的0.3倍。最小静音长度主要作用是,在静音长度不满足最小静音长度时,将这部分静音长度判断为有话帧,以防止偶尔的低能量帧影响判断准确性。帧数平均值指根据假设1拟合出相同发音人及相似发音环境下单音节包含帧数的平均值。
4)初步切分出的分语音段的起始帧向前移动两帧。动态改变能量判别门限使语音段切分数目达到音节数目的一半及以上后,由于声母能量少,有可能出现丢掉部分声母帧的情况,起始帧向前移动两帧可以将丢掉的声母帧包含一部分。
1.3 动态调整参与竞选波谷数量
短时能量波谷是对已经初步切分的分语音段进行精确切分的参照标准。将其作为主要参照标准的依据是假设2,即汉语语音相邻音节之间一定存在短时能量的波谷。首先,需要对语音短时能量进行中值滤波,消除跳跃点,即消除突发性噪声的影响。然后,进行j阶的波形平滑,设第i帧的短时能量为amp(i),平滑后的短时能量为A(i),则j阶波形平滑表示为:
2 时间复杂度分析及简化算法
2.1 时间复杂度分析
上述方法中,影响时间复杂度的主要是1.4节中计算不同语音切分存在概率和的部分。在对一段含有12个音节的语音(3.1节中出现的“test_11.wav”)进行切分过程中,运行1.4节(波谷组合及语音段再切分)之前的程序在普通台式机Matlab环境下耗费时间为0.399s,将语音段初步切分为8段;计算一次概率和花费的时间为0.0554s左右(对不同切分判决花费时间差距很小,此处做大概计算),但计算次数为8568次,即总体时间471.240s。而在一些初始切分段落数量相对音节数较少的语音段,后续判决将花费更多时间。如3.1节中出现的“test_6.wav”,包含音节数为16,运行1.4节(波谷组合及语段再切分)之前的程序在相同环境下耗费时间为0.257s,将语音段初步切分为8段;计算一次概率和花费的时间为0.047s,但计算次数为203490,即总体时间9564s。这样的计算时间难以满足实际应用需求。
设需要切分的语音段采样点储存在数组x中,语音段初步切分(即1.4节之前)程序耗费时间为f(x),对第i次波谷组合再切分进行可能音节存在概率和计算耗费的时间为gi(x),初始切分后剩余波谷数目为n,需要挑选参与再切分的波谷数目为m,则耗费总时间t(x)为:
2.2 简化算法
虽然减少初步切分后语音段内波谷数目n及减少需要得到的波谷数目m都是不可行的,对语音段进行初步切分后,语音段被切分为许多分语音段,与此同时,波谷n也被分别切分到不同的分语音段中。利用这个规律,可以得到如下简化算法。为了配合简化算法的说明,选取以原方法计算花费时间最长的“test_6.wav”语音跟随简化算法步骤。在此给出以第1章中描述的方法对语音段“test_6.wav”进行切分的最终结果(单位为帧):3469;7196;96121;121145;145163;169197;197232;232258;265287;293324;324345;345366;366390;390411;420430;439461。符号“”之前数字表示起始帧,之后数字表示结束帧。
简化算法步骤如下:
1)对语音段进行初步切分、确定参与竞选波谷(即1.1节~1.3节涉及算法)。对语音段“test_6.wav”进行初步切分,其中参数取值:采样率为16kHz,帧长为200个采样点,帧移为100个采样点,拟合均值为-25.8623帧,拟合方差为11.0625。其初步切分结果为(单位为帧):3469;71163;169197;197258;265287;293411;420430;439461,共计8个分段。确定参与竞选的波谷帧数值为:55;82;86;96;110;121;126;145;202;207;214;232;311;324;345;355;366;376;390;393;405共计21个波谷。
2)将参与竞争的波谷,按照所属关系分配给初步切分的分语音段。语音段“test_6.wav”的波谷分配给初步切分的分语音段:345569;71828696160121126145163;169197;197202207214232258;265287;293311324345355366376390393405411;420430;439461。其中每一行第一个数字和最后一个数字是初步切分语音段的起始帧数值和结束帧数值,中间数字为按照要求分配的波谷帧数值。
3)引入最大平均概率值概念,即概率和最大值与切分后分段数目的商。分别计算每一个分段选取i(i取值从0开始,到本分段波谷值)个波谷组合作为切分点的最大平均概率,并记录最大平均概率对应的波谷组合,以分段数及选取波谷数为表头对最大平均概率值列表。如语音段“test_6.wav”第二个分段选取2个波谷进行组合作为切分点,计算得到最大平均概率为0.0180,对应的波谷组合为96帧、126帧。语音段“test_6.wav” 以分段数及选取波谷数为表头对最大概率值列表结果如表1。
3 仿真结果与分析
实验在Matlab环境下进行,语音选取新闻联播某分段,共计21段语音(命名为“test_1~21.wav”),每段语音包含4到16个音节不等。不在实验中采用标准语音语料库,因为汉语标准语音语料库中,除了讯飞公司发布的语料库外,其他语料库如863语音语料库、CASS汉语口语语料库等,存在标注不准确问题,而讯飞公司发布的语料库为非共享资源[12]。另外,上述语料库多为语音识别服务,语音采集重视多人数、短语句,而本文方法适用于同环境下的语音切分,同一发音人长时间发音可以看作一种苛刻的同环境,故选取新闻联播某分段进行实验。语音采样率fs为16kHz,帧长wlen为200个采样点,帧移inc为100个采样点。对21段语音进行人工标注,选取前四段拟合其音节长度的高斯分布,得到高斯分布均值mu为-0.1554s,方差sigma为0.0629s。对语音段音节切分,切分音节位置包含音节起点及音节终点,因为对起点及终点的分析方法相同,相邻音节常常出现前音节终点为后音节起点的情况,在以下实验中,选择音节起点进行分析。
传统端点检测方法可以较准确检出静音段,但在切分音节方面效果不好。以基于能量和过零率的双门限法为例,以不同门限对语音段“test_6.wav”进行切分。设静音段短时能量均值为ampth,短时过零率均值为zcrth,则设置高阈值能量门限amp1、低阈值能量门限amp2及过零率门限zcr如下:
从图3中可以看出,利用双门限法,最优的切分情况同人工标注差距仍旧比较大。其最好切分情况下,帧距离平方和大于2×104,即起始帧平均相差35.3553帧,换算成时间则相差0.2147s。造成这种差距的原因是语音“test_6.wav”中有许多连续发音的音节。
文献[7]提出了基于归并的语音音节切分方法。其原理为:把语音特征参数相似的相邻帧进行归并,形成类似段;将特征发生突然变化的位置记作1类转折,将特征发生缓慢变化的位置记作2类转折;将不同声韵母及静音按照其特性划分到1或2类转折中;利用文本信息及转折位置进行划分。
利用本文方法对语音段“test_6.wav”进行切分,并与文献[7]提出的归并切分方法、双门限切分的最优情况中的一种(p1=1、p2=3、p3=20、maxsilence=8)及人工切分进行比较,切分结果如图4所示。
利用本文方法对实验语音进行自动行切,其切分准确度S达到小数点后3位。其中S最大值(S大表示切分不准确)为0.0031,即与人工标注起始点相差0.0557s,差距在可接受范围内。利用简化算法后,本文方法计算效率明显提升,在对实验语音进行自动切分过程中,在台式机Matlab环境下,平均运算时间为0.3035s,最长运算时间为0.81s,达到应用水平。
4 结语
准确自动切分语音段中的音节,为语料库及广播语音的标注等工作提供许多便利。本文在传统双门限法的基础上,对其进行4方面改进;进而利用相同发音环境下音节发音时间长度的分布规律,以波谷为依据,计算波谷组合下可能音节存在概率的和,进而得到最有可能的语音音节位置。利用本文算法两次切分的特点,对其进行简化。实验仿真结果表明,本文方法切分音节准确度(与标注切分时间距离平方的均值)达到小数点后3位,同时在台式机Maltab环境下运算时间均不超过1s,可以达到应用要求。然而本文方法主要针对较短语音段,适用于更长语音段的音节切分方法还有待进一步深入研究。
参考文献:
[1]TOLEDANO D T, GOMEZ L A H, GRANDE L V . Automatic phonetic segmentation[J]. IEEE Transactions on Speech and Audio Processing, 2003,11(6):617-625.
[2]WU Y J, KAWAI H, NI J, et al. Discriminative training and explicit duration modeling for HMMbased automatic segmentation[J]. Speech Communication, 2005,47(3): 397-410.
[3]van HEMERT J P. Automatic segmentation of speech[J]. IEEE Transactions on Signal Processing,1991,39(4):1008-1012.
[4]CHOU F C, TSENG C Y, LEE L S. A set of corpusbased texttospeech synthesis technologies for Mandarin Chinese[J]. IEEE Transactions on Speech and Audio Processing,2002,10(7):481-494.
[5]杜守栓. 方言口音普通话语音自动切分算法研究[D].北京: 中国科学院,2006:15-26.(DU S S. Research on robust automatic segmentation of dialectal speech[D]. Beijing: University of Chinese Academy of Sciences, 2006:15-26.)
[6]何可嘉. 广播语言的自动标注系统[D].北京: 北京邮电大学,2010:22-47.(HE K J. An automatic labeling system for broadcast news[D]. Beijing: Beijing University of Posts and Telecommunications, 2010:22-47.)
[7]韩虎. 汉语连续语音的音节自动标注算法研究及实现[D].哈尔滨: 哈尔滨工业大学,2008:21-44.(HAN H. Research and realization of the automatic syllable marking algorithm for Chinese continuous speech[D]. Harbin: Harbin Institute of Technology, 2008: 21-44.)
[8]LEE K S. MLPbased phone boundary refining for a TTS database[J]. IEEE Transactions on Audio, Speech and Language Processing, 2006,14(3):981-989.
[9]BROGNAUX S, DRUGMAN T. HMMbased speech segmentation: improvements of fully automatic approaches[J]. IEEE Transactions on Audio, Speech and Language Processing,2016,24(1):5-15
[10]廖文辉,刘炎.数据分析与SAS实验[M].北京:经济科学出版社,2010:13-32.(LIAO W H,LIU Y. Data Analysis and SAS Experiment[M]. Beijing: Economic Science Press,2010:13-32.)
[11]宋知用.Matlab在语音信号分析与合成中的应用[M].北京:北京航空航天大学出版社,2013:117-129.(SONG Z Y. Application of Matlab in Speech Signal Analysis and Synthesis[M].Beijing: Beihang University Press, 2013:117-129.)
[12]章森,刘磊,刁麓弘.大规模语音语料库及其在TTS中应用的几个问题[J].计算机学报,2010,33(4):667-696.(ZHANG S,LIU L,DIAO L H. Problems on largescale speech corpus and the applications in TTS[J]. Chinese Journal of Computers, 2010,33(4):667-696.)
