自注意力机制的属性异构信息网络嵌入的商品推荐
2022-07-12王宏琳聂铁铮
王宏琳 杨 丹 聂铁铮 寇 月
1(辽宁科技大学计算机与软件工程学院 辽宁鞍山 114051) 2(东北大学计算机科学与工程学院 沈阳 110169)
网络嵌入由于其自身良好的有效性和灵活性,不仅可以解决数据稀疏[1]等网络数据存在的问题,在各种下游任务中也已经取得显著的成果,如节点分类[2]、链路预测[3]、节点聚类[4]、网络可视化[5]以及推荐[6].
基于网络嵌入的推荐算法根据网络中存在节点类型的数量与边类型的数量分为基于同构信息网络嵌入的推荐算法与基于异构信息网络嵌入的推荐算法2种.针对同构信息网络的网络嵌入已经有许多经典的算法,如文献[7-8];针对异构信息网络的网络嵌入也有许多经典的算法,如文献[9-10]等.

Fig. 1 An example of attributed heterogeneous information network composed of users and products图1 用户与商品组成的属性异构信息网络示例图
然而现实存在的网络节点与边不但分为多种类型,每个节点还拥有自己的属性信息.比如在一个商品推荐网络中,节点类型分为用户和商品2种,用户有年龄、性别等属性信息,商品有种类、价格等属性信息,用户与商品之间的关系分为浏览、加入购物车和购买3种.用户在选择商品时考虑商品不同的属性信息,这也意味着不同的属性信息对推荐结果有不同程度的影响,用户和商品之间不同类型的边关系也意味着用户对商品不同程度的偏好.但是现有的网络嵌入方法更关注单一边类型的网络结构,不但忽略了网络中的边分为多种类型,还忽略了节点的属性信息与节点的属性信息对推荐结果的影响.
将拥有多种类型的节点与边且节点拥有属性信息的网络称为属性异构信息网络,如图1所示的是一个由用户与商品组成的属性异构信息网络.处理属性异构信息网络的嵌入方法为属性异构信息网络嵌入.在处理属性异构信息网络时会面临一些特别的挑战:
1) 丰富的属性信息.属性异构信息网络中的每个节点都拥有自己丰富的属性信息,而且用户在选择项目时会考虑项目不同的属性信息,如何在考虑不同属性信息对推荐结果影响的同时,学习属性嵌入表示是属性异构信息网络嵌入面临的一大挑战.
2) 网络异构性.现实网络中的节点与节点之间的边分为多种类型,不同类型的边意味着用户对商品不同程度的偏好,如何在学习每种边类型对推荐结果影响的同时,为在每种边关系情况下的节点学习统一的嵌入表示是一大挑战.
3) 融合节点属性嵌入与节点结构嵌入.在网络嵌入中引入属性信息解决推荐问题时,如何融合学习到的节点属性嵌入与节点结构嵌入,学习节点统一低维的嵌入表示是一大挑战.
除这3种属性异构信息网络嵌入所要面临的挑战外,在使用网络嵌入解决推荐问题时,现有的网络嵌入方法大多采用点积方法作为匹配函数计算匹配分数,然后根据匹配分数进行商品排序从而得到商品推荐列表.但是点积方法在解决推荐问题时表现力和求取低秩关系的能力较弱,降低了推荐性能.而基于匹配函数学习的推荐方法相比于学习节点表示更注重如何有效学习匹配函数,这就导致了学习节点表示能力的不足.
为了解决上述问题,本文提出一个自注意力机制的属性异构信息网络嵌入的商品推荐(attributed heterogeneous information network embedding with self-attention mechanism for product recommendation, AHNER)框架.该框架基于自注意力机制利用属性异构信息网络嵌入学习用户嵌入表示与商品嵌入表示,并结合深度神经网络(deep neural network, DNN)学习高效的匹配函数用于解决商品推荐问题.
AHNER在获取节点丰富的属性信息的同时,考虑到不同的属性信息对推荐结果有不同程度的影响,AHNER引入自注意力机制学习每个属性信息的权重,并为每个属性信息学习统一低维的属性嵌入表示.由于属性异构信息网络拥有多种类型的边关系,所以在学习节点的结构嵌入时,AHNER在每种边类型情况下为每个节点学习嵌入表示,然后引入自注意力机制学习每种边类型之间的相互影响,并融合每种边类型情况下的节点嵌入学习最后的节点结构嵌入.最后通过融合机制将学习到的属性嵌入与结构嵌入融合成统一低维的嵌入表示,并将学习到的节点嵌入应用在基于DNN的匹配函数学习模型中,学习匹配分数解决推荐问题.
本文的主要工作概括为4个方面:
1) 强调属性信息在学习节点嵌入时的重要性,引入属性信息学习节点更有效的嵌入表示,并在学习节点属性信息时,引入自注意力机制学习节点属性的权重系数.
2) 详细阐述属性异构信息网络嵌入的学习过程,考虑到不同类型的边关系反映用户对商品不同程度的偏好,引入自注意力机制学习每种边关系的权重,并融合网络结构信息与节点属性信息学习更有效的、统一的、低维的用户嵌入表示与商品嵌入表示.
3) 提出一个推荐框架AHNER用于解决商品推荐问题,并克服传统点积方法在属性异构信息网络嵌入解决推荐问题时的局限性,提高推荐算法的性能.
4) 在3个公共数据集上进行大量的实验,并完成Top-K推荐任务与链路预测任务.实验结果表明,所提出的框架AHNER的性能优于其他方法的性能.
1 相关工作
本文的相关工作主要包括基于网络嵌入的推荐技术、基于属性网络嵌入的推荐技术、基于异构信息网络嵌入的推荐技术与基于匹配函数学习的推荐技术这4方面.
1.1 基于网络嵌入的推荐技术
现有的基于网络嵌入的推荐技术大致分为基于矩阵分解的网络嵌入推荐技术[11]、基于深度学习的网络嵌入推荐技术、基于随机游走的网络嵌入推荐技术3种.早期针对基于矩阵分解的网络嵌入推荐技术研究较多,但是由于对深度神经网络持续的研究发现,深度神经网络可以为网络嵌入寻求一个有效的非线性函数学习模型,如文献[12-14].与此同时,还发现深度神经网络非常适合学习推荐问题中复杂的匹配函数,因为它们能够逼近任何连续函数[15].例如,文献[16]使用神经网络学习匹配函数;文献[17]采用表示学习和多层感知机(multilayer perceptron, MLP),从用户和项目的输入特征和分类特征中学习匹配函数.基于随机游走的网络嵌入推荐技术的思想是通过邻域的嵌入表示学习推荐网络中节点的嵌入表示,并利用节点的嵌入表示解决推荐问题.例如,word2vec[18]是一种通过邻域词的向量构建出中心词的向量的网络嵌入方法.专家发现可以利用word2vec根据用户前后交互的内容推测用户的兴趣,并学习推荐系统中用户、项目的嵌入表示,如文献[19-20]就是使用word2vec的方法解决推荐问题.Deepwalk[7]通过游走策略随机选择游走路径,并将随机路径看作一个句子,将节点看作一个词学习节点的嵌入表示.node2vec[8]通过使用广度优先(breadth-first search, BFS)和深度优先(depth-first search, DFS)遍历探索不同的邻居节点,从而进一步扩充了Deepwalk.LINE[21]是一种能够处理大规模网络的利用邻域相似假设的嵌入方法.基于随机游走的网络嵌入推荐技术通过利用word2vec,Deepwalk等基于随机游走的网络嵌入方法解决推荐问题.
1.2 基于属性网络嵌入的推荐技术
属性网络[22]除了网络的结构信息外,还包括节点的属性信息.属性网络嵌入会将节点的属性信息作为另一种信息源将其映射到一个联合的低维向量空间中学习节点的嵌入表示.MMDW[23]是一种利用节点标记信息的半监督网络嵌入方法,它基于深度游走矩阵分解与支持向量机[24]结合节点的标签信息学习节点表示.TADW[25]是一种基于深度游走矩阵分解结合网络结构与文本信息学习节点嵌入表示的方法,但是它的计算成本高,节点属性也只是简单地合并为无序特征,失去了大量的语义信息.文献[26]将文本内容视为一种特殊的节点,并构建一个增强网络使用逻辑回归(logistic)函数学习节点表示.文献[27]基于光谱技术将标签信息引入到属性网络嵌入中学习节点嵌入表示.文献[28]提出一个可以融合结构信息与属性信息的社交网络通用框架.文献[29]在使用邻居增强自动编码器建模节点属性信息的同时使用跳字模型(skip-gram)汇集邻居节点的特征来学习节点表示.文献[30]利用文本信息学习网络节点表示.
1.3 基于异构信息网络嵌入的推荐技术
基于异构信息网络嵌入的推荐技术将用户不同类型的偏好集成到同一公共空间中学习节点统一低维的嵌入表示.例如,metapath2vec[9]通过图上的采样路径自动利用邻居结构.文献[31]提出一个推荐系统,它通过获取异构信息网络中的用户隐式偏好进行推荐.文献[32]利用user,meta_path,item三元组将基于上下文的元路径合并到交互模型中,并通过MLP对项目进行打分完成Top-K推荐任务.文献[33]通过基于元路径的交互矩阵和注意力机制来识别不同的语义信息并推荐.基于异构信息网络嵌入的推荐技术在推荐效果、多样性等性能都有优秀的表现,但是基于异构信息网络嵌入的推荐技术也存在2点不足:1)忽略属性信息与不同属性信息对推荐结果的影响;2)较少考虑用户与项目之间不同的交互行为对推荐结果的影响.
1.4 基于匹配函数学习的推荐技术
基于匹配函数学习的推荐技术更注重学习有效、准确的匹配函数来解决推荐问题.例如,NeuMF[16]利用神经网络代替香草矩阵分解中使用的点积来学习匹配函数,还将矩阵分解与多层感知机结合在一个模型中解决推荐问题.文献[34]是NeuMF的一个变体,它以用户邻居和项目邻居作为输入解决推荐问题.文献[35]使用外部产品操作,以便能够更好地学习推荐系统中用户与项之间的相关性.文献[36]使用基于神经网络的分解机(factorization machines, FM)来避免人工特征工程,解决推荐问题.
基于属性网络嵌入的推荐技术大多局限在同构信息网络中学习节点嵌入表示;基于异构信息网络嵌入的推荐技术不仅忽略了节点丰富的属性信息与不同属性信息对推荐结果的不同影响,还忽略了节点之间不同类型的边对推荐结果的影响.为了解决上述问题,本文使用基于自注意力机制的属性异构信息网络嵌入学习节点的嵌入表示,并为了克服点积方法在推荐问题中存在的局限性,将属性异构信息网络嵌入与DNN结合起来,提出一个通用的推荐框架,在引入节点属性信息的同时学习异构信息网络中节点的嵌入表示,并通过DNN学习高效的匹配函数解决推荐问题.
2 预备知识与问题定义
一个网络通常定义为G=(V,E).其中,V表示节点的集合,且V={v1,v2,…,vn},n表示节点总数;E表示边的集合.本文符号具体如表1所示:

Table 1 Symbols and Their Definitions表1 符号及其含义
定义1.异构信息网络.一个异构信息网络定义为G=(V,E,O,R).节点与边分别关联一个类型映射函数Φ:V→O与Ψ:E→R,其中O表示节点类型的集合,R表示边类型的集合.如果一个网络中的|O|+|R|>2,则此网络为异构信息网络,否则为同构信息网络.

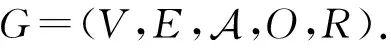
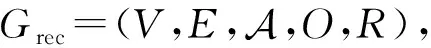
3 推荐框架
本节将详细描述提出的推荐框架AHNER,框架结构如图2所示.该框架主要包含2部分:1)基于商品推荐的属性异构信息网络嵌入;2)基于DNN的匹配函数学习模型.
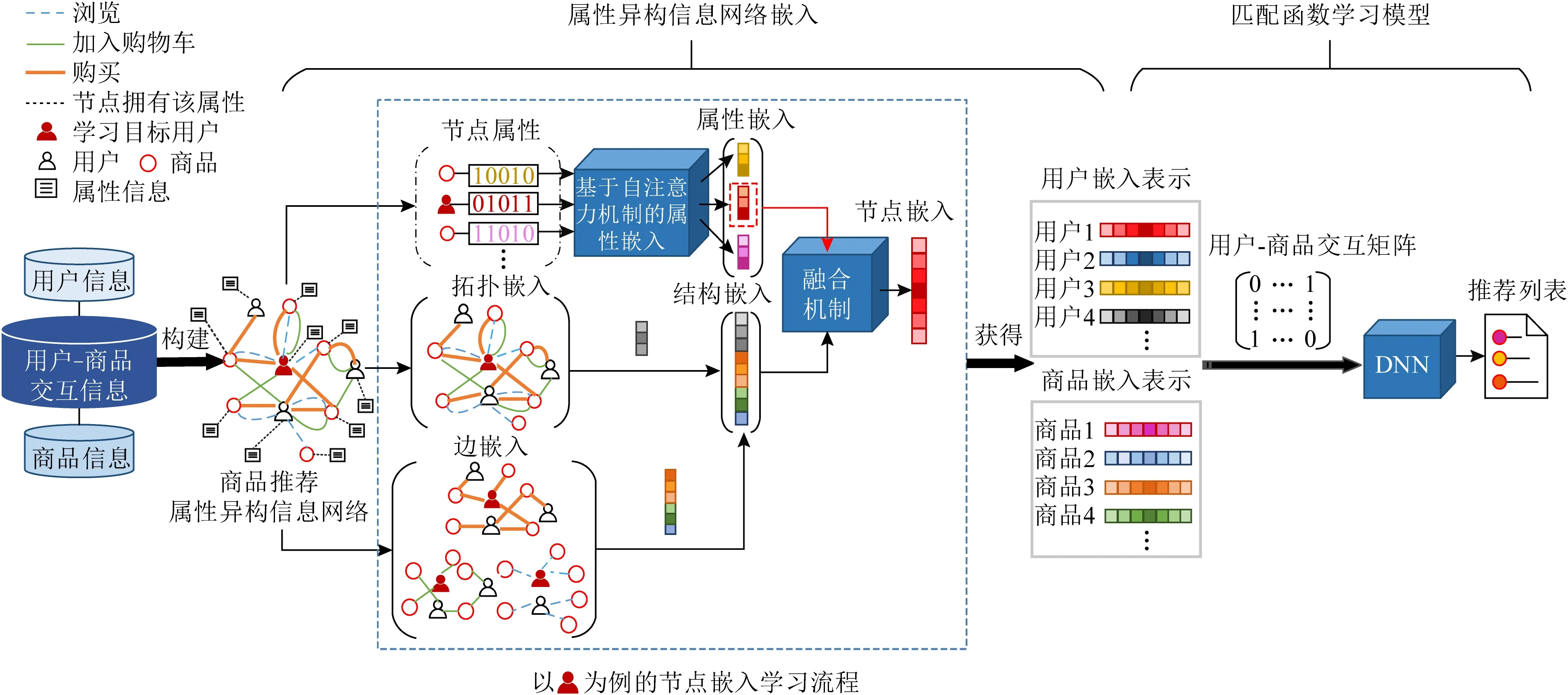
Fig. 2 Overview of AHNER图2 AHNER总体框架图
3.1 基于商品推荐的属性异构信息网络嵌入
3.1.1 商品推荐属性异构信息网络的构建
构建基于商品推荐的属性异构信息网络时,节点类型分为用户与商品2种.AHNER使用用户信息作为网络中用户节点的属性信息,如性别、年龄等,使用商品信息作为网络中商品节点的属性信息,如种类、价格等;又从用户的交互信息中得到节点间的边关系,其中用户与商品之间的边关系分为3种,分别是浏览、加入购物车与购买.通过使用2组节点集合(即用户和商品)和节点间不同的边关系来连接节点,从而得到属性异构信息网络.
3.1.2 基于自注意力机制的属性嵌入表示学习
在实际推荐问题中,网络中的节点属性信息是多种多样的,不同的属性信息对推荐结果产生不同程度的影响.比如,在用户选择商品时,除考虑商品本身的特征外,还要考虑商品的价格.在2个商品本身特征相似的情况下,大部分用户会选择优惠力度比较大或价格更便宜的那一个商品.为了建模不同属性信息对推荐结果不同程度的影响,AHNER引入自注意力机制来学习每个属性的权重系数,并学习统一的节点属性嵌入.具体的基于自注意力机制的属性嵌入结构如图3所示:
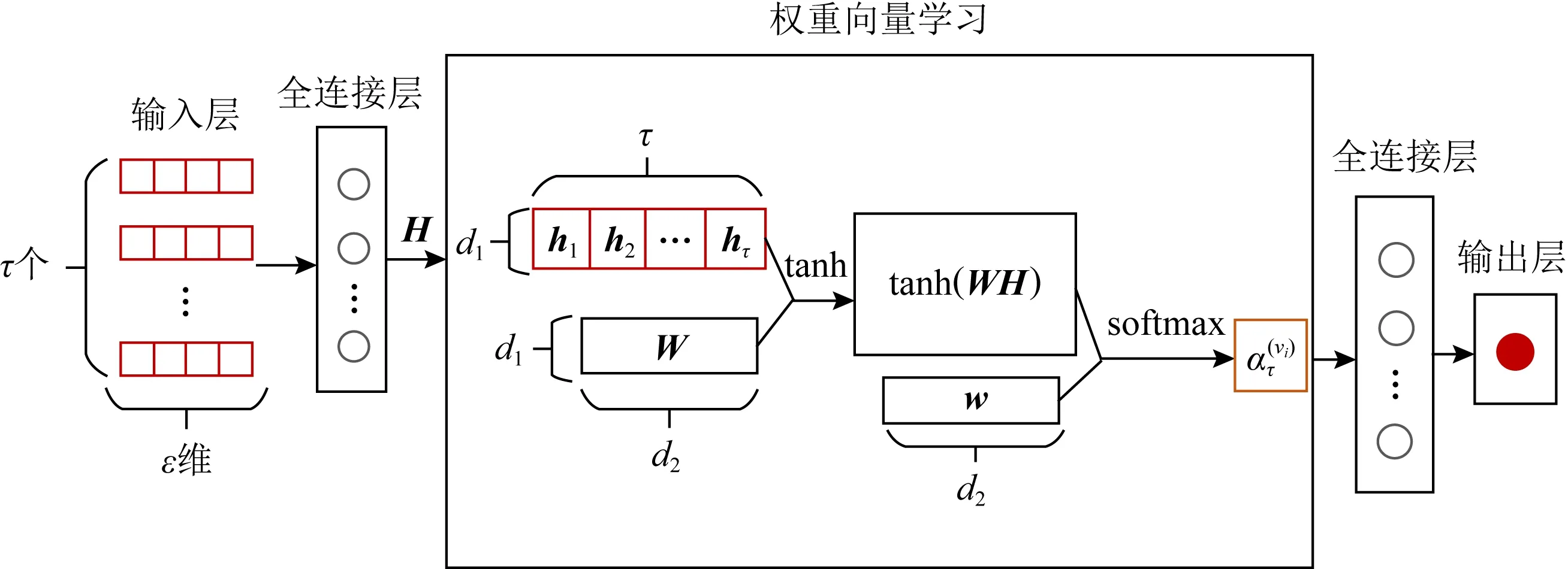
Fig. 3 The architecture of attributed embedding based on self-attention mechanism图3 基于自注意力机制的属性嵌入结构图
假设一个节点vi共有τ个属性信息,使用word2vec方法将节点vi的每个属性信息表示成初始的属性向量,作为基于自注意力机制的属性嵌入的输入数据,具体表示为
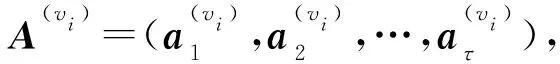
(1)
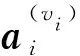
1) 通过一层全连接层学习输入数据的隐藏状态H=(h1,h2,…,hτ),其中ht表示第t层隐藏层学习到的隐藏状态.H的具体表示为
H=σ(WA(vi)+b),
(2)
其中,H是维度为d1×τ的矩阵,W与b是模型的参数,σ是激活函数.
2) 通过注意力打分函数和softmax函数为节点vi的每个属性信息计算权重系数.在AHNER中采用加性注意力作为注意力打分函数[37].节点vi的每个属性信息的权重系数表示为
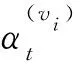
(3)

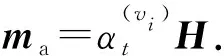
(4)
3) 通过全连接层将节点vi的每个属性信息的属性嵌入连接到一起,并输出到输出层得到节点vi的所有属性信息的属性嵌入表示.
3.1.3 节点结构嵌入表示学习
ρ:V1→V2→…→Vt→…→Vl.
基于元路径的随机游走方法产生的游走流取决于预定义的元路径,预定义的长度决定游走流的长度.在游走后,会得到每一种边类型情况下的基于不同元路径的节点序列.随机游走的转移概率表示为
(5)
其中,vi∈Vt,Ni,r表示节点vi在边的类型为r的情况下的邻居节点集合,Er表示边类型为r的边集合.
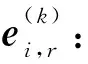
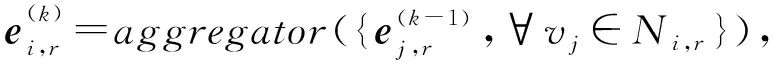
(6)
其中,aggregator表示聚合函数.
聚合函数有2种计算方法[38],分别是平均池化和最大池化,AHENR采用平均池化的方法进行计算,变换后的节点嵌入表示为
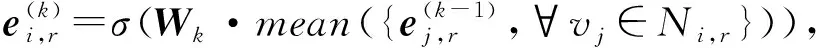
(7)
其中,σ表示激活函数,Wk表示权重矩阵.
每个边嵌入的维度为z,边类型的总数为m.连接不同边类型下的节点vi的嵌入表示得到维度z×m的矩阵Mi:
Mi=(ei,1,ei,2,…,ei,m).
(8)
由于不同类型的边反映用户不同的偏好程度,所以引入自注意力机制捕捉不同边类型之间的影响因素,学习每种边类型下各个边嵌入的权重系数αi,r:
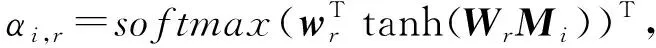
(9)
其中,wr和Wr是模型训练得到的参数.
最后节点vi的结构嵌入表示为
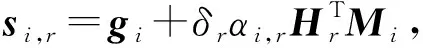
(10)
其中,δr是边嵌入在整个节点嵌入中重要性的超参数,Hr是维度为z×d的可训练的转换矩阵,gi是节点vi的拓扑嵌入,拓扑嵌入是提取网络中的基础结构形成的嵌入表示,它会在每个边嵌入中共享.
3.1.4 节点嵌入表示学习
AHNER采用融合节点结构嵌入与属性嵌入的融合机制学习节点统一的低维嵌入表示,具体结构如图4所示:
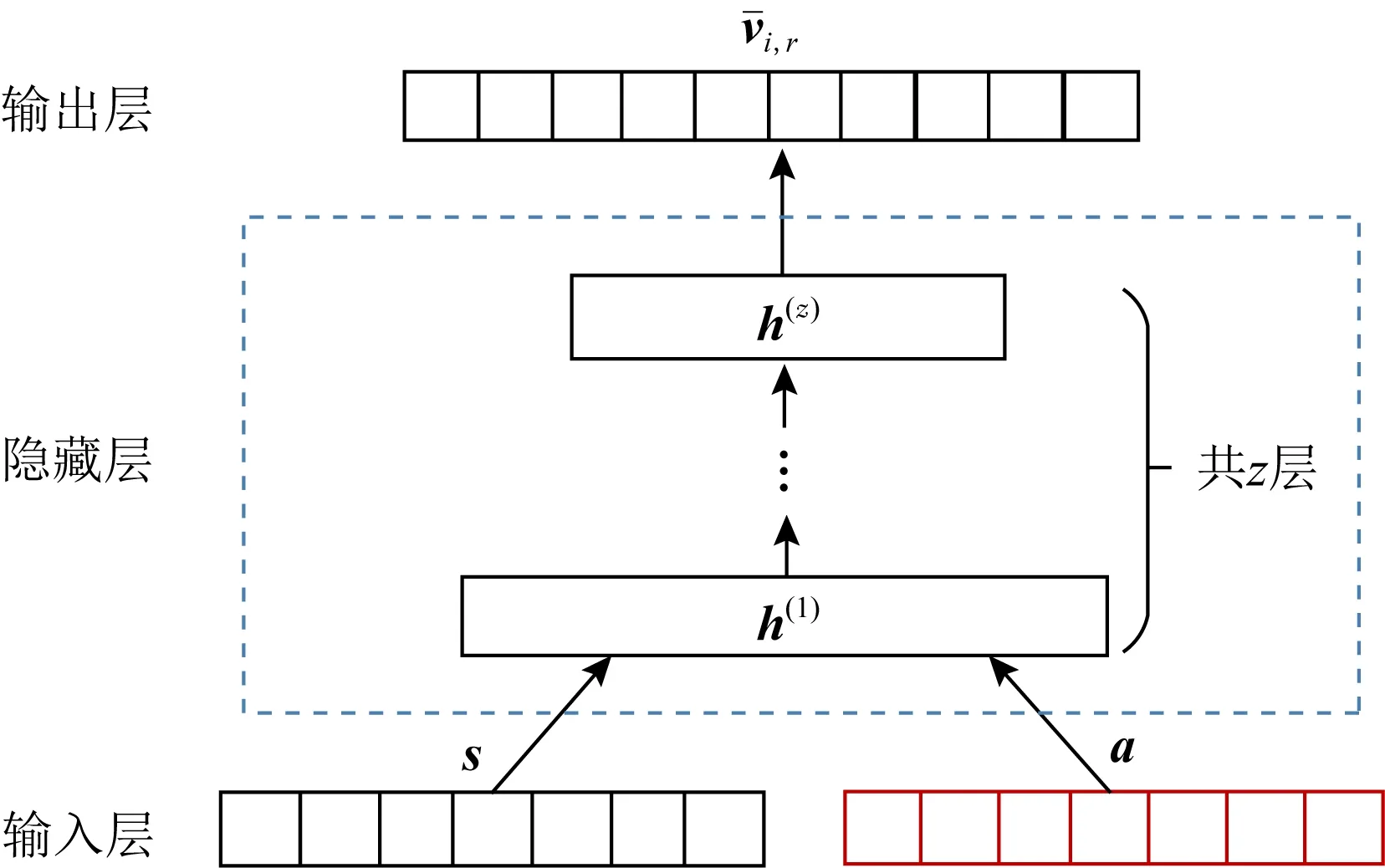
Fig. 4 The architecture of fusion mechanism图4 融合机制结构图
输入层的输入数据是节点的属性嵌入表示a与节点的结构嵌入表示s,具体表示为
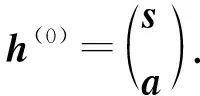
(11)
通过输入层将数据送入隐藏层中,每个隐藏层表示为h(1),h(2),…,h(z),具体定义为
h(t)=θt(Wtht-1+bt),t=1,2,…,z,
(12)
其中,t代表隐藏层的层数,Wt与bt分别表示第t层的权重矩阵与偏置向量,θt表示第t层的激活函数.
经过z个隐藏层,输出层得到最后的节点表示为
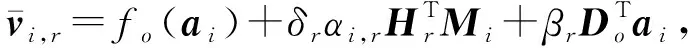
(13)
其中,Do是节点vi的特征转换矩阵,o是节点的类型,βr是系数.节点vi的拓扑嵌入gi由节点的属性嵌入通过融合机制学到的转化函数fo进行计算.
3.1.5 属性异构信息网络嵌入优化
假设P=(v1,v2,…,vl)是在边类型为r的情况下得到的长度为l的游走序列,其中(vt-1,vt)∈Er,t=2,3,…,l.
通过基于元路径的随机游走得到的节点vt的上下文节点集合定义为
C={vk|vk∈P,|k-1|≤c,t≠k},
(14)
其中,vk是游走序列P中的节点,c是上下文窗口的范围.
给定一个节点和元路径,可以得到在固定大小窗口中的基于共现概率的邻居节点,则优化目标是最小化式(15):

(15)
其中,η表示所有可优化的参数,C表示上下文节点集合.
遵循metapath2vec采用异构softmax函数计算Pη(vj|vi),具体表示为
(16)
其中,xk表示节点vk的上下文嵌入表示.
为了高效优化,引入负采样方法近似-logPη(vj|vi)并得到最终的目标函数表示为
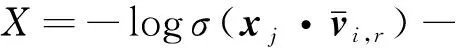
(17)
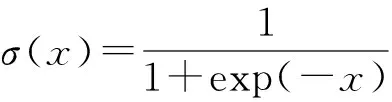
3.2 基于DNN的匹配函数学习模型
为了克服传统点积方法在网络嵌入中求取低秩关系的局限性,AHNER提出基于DNN的匹配函数学习模型,用于学习高效的匹配函数,从而提升推荐性能,具体结构如图5所示.

Fig. 5 The architecture of matching function learning model based on DNN图5 基于DNN的匹配函数学习模型结构图
输入层的输入数据是用户与商品形成的交互矩阵和通过属性异构信息网络嵌入学习到的用户嵌入表示与商品嵌入表示.基于DNN的匹配函数学习模型的输入层定义为

(18)
其中,pu表示用户u的嵌入表示,qp表示商品p的嵌入表示.
通过输入层将数据送入隐藏层中,经过多个隐藏层学习匹配函数,每个隐藏层表示为h(1),h(2),…,h(z),具体定义为
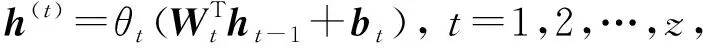
(19)
其中,Wt和bt分别表示第t层感知器的权重矩阵与偏置向量,θt表示第t层的激活函数,隐藏层的激活函数采用ReLU函数.
最后学习到的匹配函数公式为

(20)
其中,σ是激活函数sigmoid,W表示权重矩阵.
4 实验评价与分析
本节首先介绍实验数据集、对比方法和评价指标,然后根据实验数据说明AHNER的性能.本节实验是在Intel®Xeon®E5-2620 v4@2.10 GHz的硬件环境下,基于python3.6的Keras与TensorFlow实现.
4.1 实验数据集
AHNER在3个公开数据集Retailrocket,Amazon Product,YouTube上完成Top-K推荐任务与链路预测任务的性能评价.表2是3个实验数据集的统计数据:
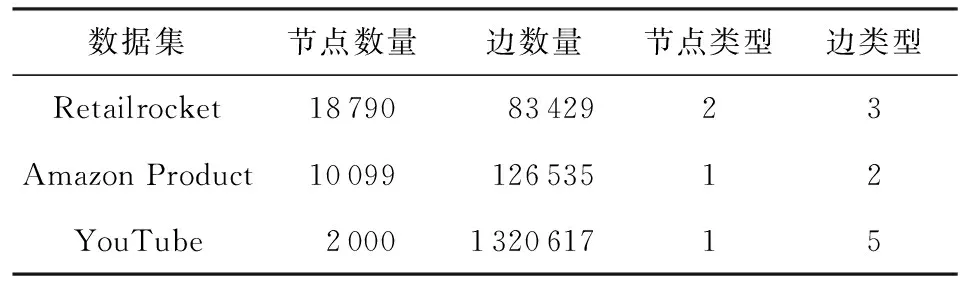
Table 2 Statistics of Datasets表2 数据集的统计信息
Retailrocket数据集是从一个真实的电子商务网站中收集的数据.其中:包含“用户”“商品”2种节点类型;节点之间的边类型分为“购买”“加入购物车”“浏览”3种;商品节点包括“种类”“价格”等属性信息.
Amazon Product数据集提供Amazon的产品评论和元数据.由于Amazon的产品分为多种类别,每种类别的产品数量都很大,所以在实验中只使用电子类产品的元数据.其中:节点类型只有“产品”1种;节点间的边关系分为“共同浏览”“共同购买”2种;产品节点包括“价格”“销售排行”“品牌”“种类”等属性信息.
YouTube数据集的节点类型只有“用户”1种;边的类型分为“联系人”“共享好友”“共享订阅”“共享订阅者”“用户之间共享最喜欢的视频”5种.
4.2 对比方法
实验针对AHNER中的属性异构信息网络嵌入和匹配函数学习模型选择不同的对比方法.针对属性异构信息网络嵌入,本节选择网络嵌入的方法进行对比实验.针对匹配函数学习模型,采用点积方法作为匹配函数进行对比实验.
4.2.1 属性异构信息网络嵌入的对比实验
选择网络嵌入对比方法时,考虑到网络结构的不同,分别选择基于同构信息网络的嵌入方法与基于异构信息网络的嵌入方法.针对同构信息网络,选择Deepwalk,node2vec,LINE作为对比方法.针对异构信息网络,选用metapath2vec作为对比方法.除此之外,选择AHNER方法的变形——AHNER-NS验证AHNER基于自注意力机制学习属性嵌入的必要性.下面逐一介绍各方法.
1) Deepwalk.在网络图上分离出不同边种类的子图,为每个子图使用随机游走和skip-gram分析节点结构关系并学习节点的向量表示.
2) node2vec.设计了一种二阶随机游走策略对邻域节点进行采样,在BFS和DFS之间平滑插入.在本节实验中,参数p=2,参数q=0.5.
3) LINE.该方法是一种运用一阶相似度与二阶相似度学习节点嵌入表示的同构网络嵌入方法.在本节实验中,节点嵌入表示的维度设置为100.
4) metapath2vec.该方法能够处理网络中节点的异构性.但是当网络节点只有一种时,方法会退化为Deepwalk.由于Amazon Product,YouTube数据集的节点类型都为1种,所以metapath2vec在这2个数据集中退化为Deepwalk.在Retailrocket数据集上,节点类型包括用户U和项目I,元路径在实验中设置为U—I—U和I—U—I.
5) AHNER-NS.该方法是AHNER的一种变形.在对比实验中使用该方法时,处理离散类型的属性信息使用one-hot方法,处理连续型属性信息使用word2vec方法.AHNER-NS与AHNER的主要区别是当AHNER-NS学习属性嵌入时,不使用自注意力机制.
4.2.2 匹配函数学习的对比实验
针对匹配函数学习的对比,使用AHNER-ND作为对比方法.
1) AHNER-ND.该方法是AHNER方法的一种变形,在实验中使用传统的点积作为匹配函数代替提出的基于DNN的匹配函数学习模型.通过该方法作为对比方法,可以根据实验结果观察到AHNER在为匹配函数学习做出改进的重要性.
2) AHNER.该方法是本文提出的商品推荐的方法.在实验中为了公平性,使用与metapath2vec相同的元路径方案U—I—U和I—U—I.节点嵌入维度d设置为200,边嵌入维度z设置为10.每个节点的随机游走次数设置为20,随机游走的长度设置为10,窗口大小设置为5,用于生成节点上下文.每个训练对的负样本数设置为5,训练skip-gram模型的迭代次数设置为100,epoch设置为50,每个边类型下的系数δr和βr都设置为1.AHNER在TensorFlow中使用Adam优化器的默认设置,学习速率设置为0.001.
在实现对比方法时,对比方法中的参数设置与AHNER中的参数设置相同.
4.3 任务与评价指标
实验通过完成Top-K推荐任务与链路预测任务来测试AHNER的性能.在完成Top-K推荐任务时,根据当前和以前会话中用户已购买、加入购物车和浏览的商品来预测用户在当前会话中下一个浏览的商品,并选取2个广泛使用的命中率(hit ratio,HR)和归一化折损累计增益(normalized discounted cumulative gain,NDCG)作为Top-K推荐任务的评价指标,并以10作为推荐列表的截至数量来评估提出推荐框架的推荐性能.HR评估测试集中的商品是否在所得推荐列表的前10个商品中,HR的值越高说明推荐性能越好;NDCG评估的是排名质量,NDCG的值越高说明推荐性能越好.在链路预测任务中,评价指标为常用的受试者工作特征曲线下的面积(area under curve,AUC),AUC的值越大说明预测效果越好.在本节中,随机选取3次实验的实验数据,计算它们的平均数作为本节统计的实验数据.
4.4 实验结果分析
在实验中,按照90%,7%,3%的比例随机选择训练集、测试集与验证集.在完成Top-K推荐任务时,为了更方便地观察AHNER的性能,在实现Deepwalk,node2vec,LINE,metapath2vec,AHNER-NS时,将这5种方法学习到的嵌入表示输入基于DNN的匹配函数学习模型中求出相应评价指标的值,在实现AHNER-ND时采用传统的点积方法作为匹配函数得到推荐结果并计算相应的评价指标的值,具体实验结果如表3所示:
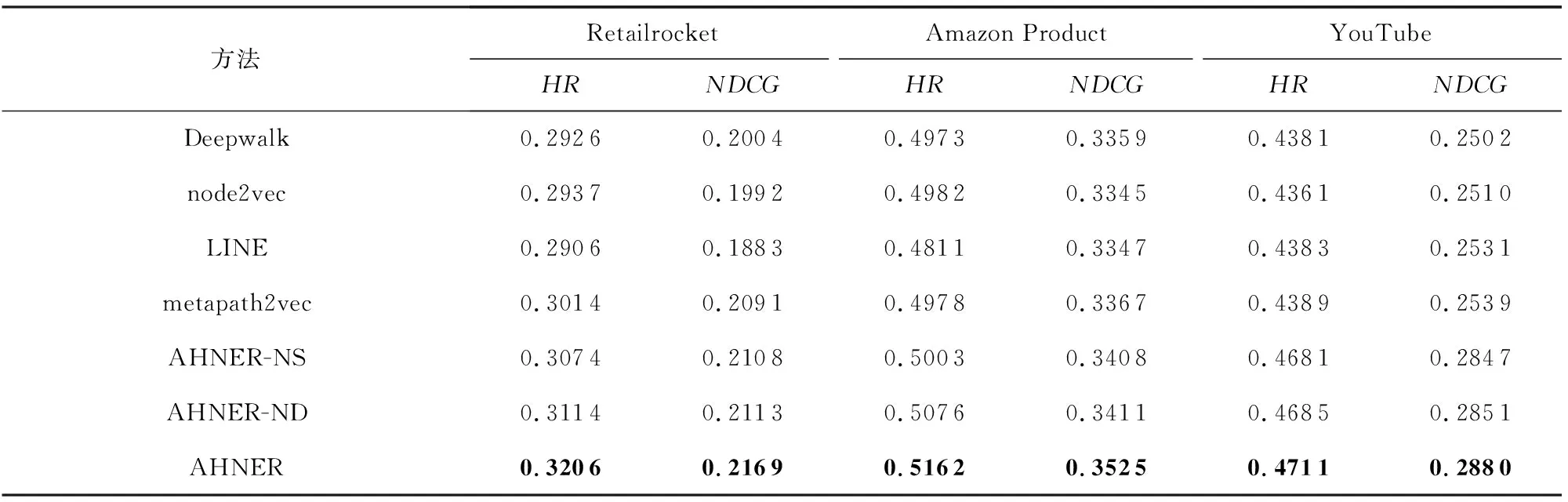
Table 3 Results of Top-K Recommendation Experiments with Different Methods on Three Datasets表 3 3个数据集上不同方法的Top-K推荐任务实验结果
实验结果表明AHNER在很大程度上明显优于其他方法.在完成链路预测任务时,各个对比方法采用点积作为匹配函数,具体实验结果如表4所示.
从表4发现:
1) 异构信息网络嵌入引入属性信息会显著提高推荐性能.通过表3与表4中的实验结果可以发现,引入属性信息会显著提高网络嵌入方法的性能,将更多的属性信息纳入推荐系统将提高总体的推荐性能;与其他只关注用户与项目的方法相比,AHNER通过结合属性信息更能捕获节点间的相互关系,从而提升推荐性能.从表4中可以观察到在链路预测问题上AHNER的性能也是优于其他对比方法的,这也体现出AHNER的适用性与普遍性.
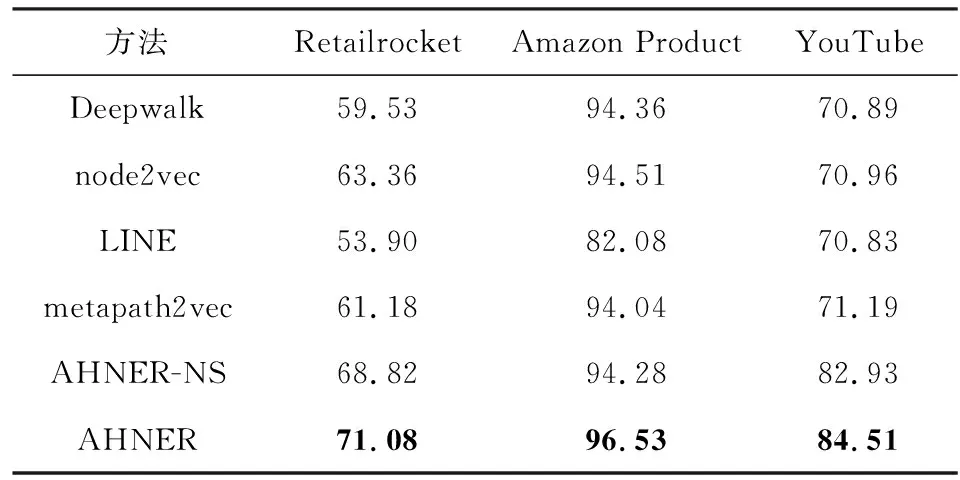
Table 4 AUC of Link Prediction Experiments withDifferent Methods on Three Datasets
2) 使用基于自注意力机制的属性嵌入表示学习能够提高推荐性能.通过对比AHNER-NS与AHNER的实验结果可以发现,AHNER通过自注意力机制学习带有权重的属性嵌入后,能捕获更多属性信息和节点之间的相互作用关系,提升了推荐系统的性能.数据集提供的属性信息越多,提升性能的幅度越大,Retailrocket在这3个数据集中提供的属性信息最多,所以提升的性能幅度更大,在HR@10上提升4.3%,在NDCG@10上提升2.9%.
3) 基于DNN的匹配函数学习模型比基于点积的方法更有优势.通过对比AHNER-ND与AHNER的实验结果可以发现,使用深度神经网络作为匹配函数的方法比使用点积作为匹配函数的方法取得了更好的结果.这种性能增益是合理的,因为神经单元增加了模型的容量.结果表明,通过使用参数神经网络替换传统的点积方法作为匹配函数来解决推荐问题,能够更好地在推荐系统中进行学习和交互建模,提升推荐性能.
4.4.1 冷启动场景的实验结果
为了研究AHNER在冷启动场景中的性能,本节改变Retailrocket数据集中训练集的比例,将用于实验的训练集比例从90%逐渐降低至20%,然后利用AHNER解决链路预测问题,具体实验结果如表5所示:
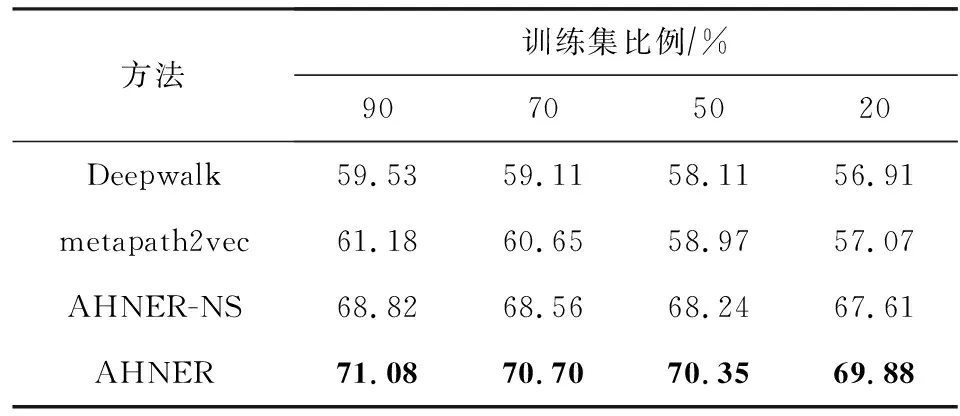
Table 5 AUC of Cold Start on Retailrocket Dataset表5 Retailrocket数据集上冷启动场景的AUC
通过分析实验结果,在训练集比例从90%逐渐降低至20%时,2个对比方法的AUC值分别下降4.6%与7.2%,但AHNER的性能仅下降1.7%~1.8%.这表明AHNER即使用户与商品之间的交互稀疏,也能保持预测性能.
4.4.2 属性权重可视化
本节在Amazon数据集中随机选择5个商品进行属性权重系数可视化,结果如图6所示:
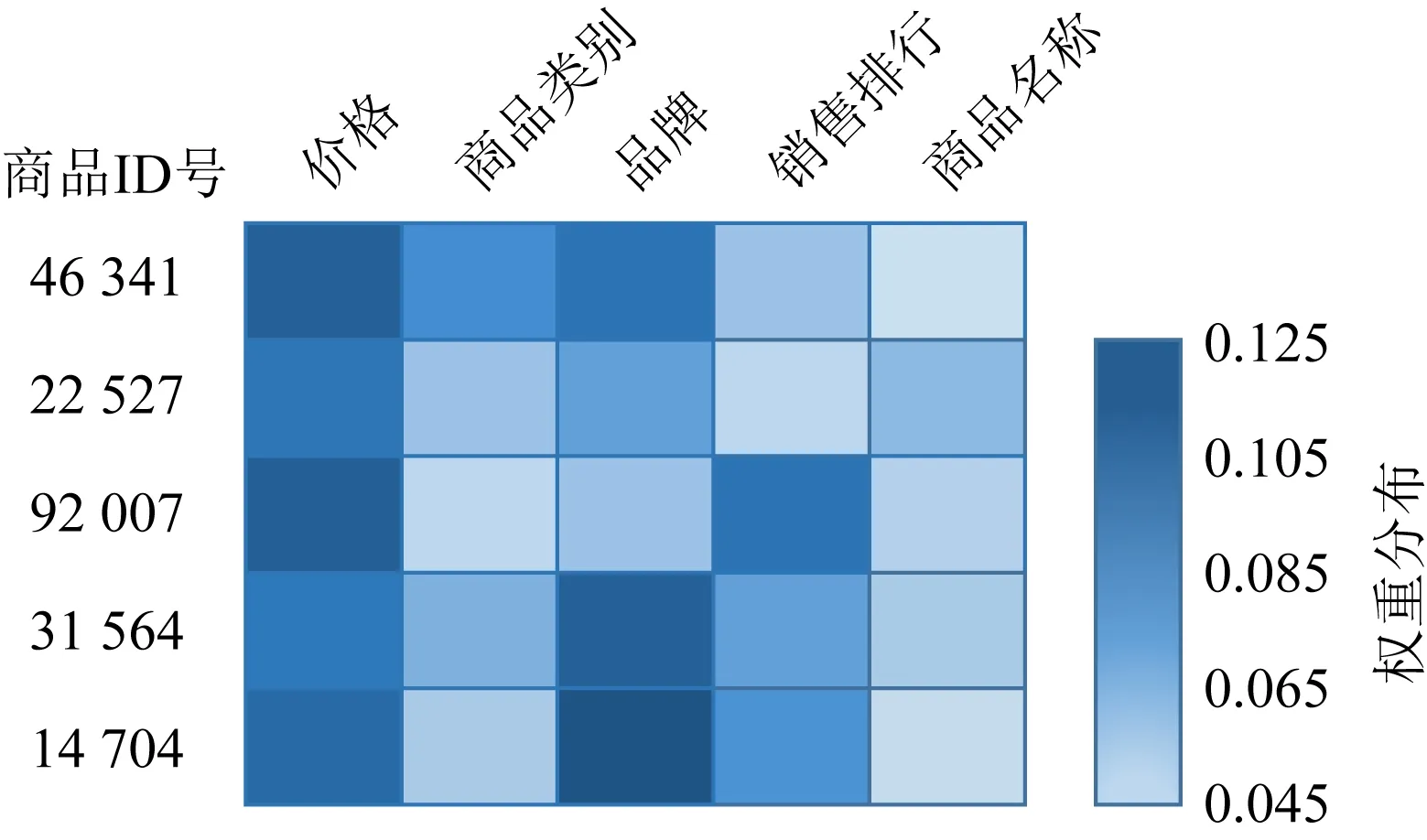
Fig. 6The attribute weight coefficient of different products图6 不同商品的属性权重系数图
图6中所示的权重系数都是由基于自注意力机制的属性嵌入表示学习出的商品属性的权重系数,其中每一行记录一个商品(由商品ID号表示)的权重系数.从实验结果中可以观察出:
1) 商品不同的属性信息,权重系数也是不同的.这一现象与本文的猜想是一致的,即不同的属性信息对最终嵌入表示的贡献是不同的.
2) “价格”属性的权重系数在每个商品的属性信息中占比较大.这一发现与用户在实际推荐系统中的消费行为相一致.除此之外,“品牌”属性的权重系数也比较大,这种现象也反映出用户的消费行为规律,即用户倾向于购买同一品牌的商品,以方便降低价格或领取优惠.
3) 对于不同的商品,用户倾向考虑的属性信息也会不同.比如商品ID为14 704的商品,用户除考虑商品本身的特征外,相比于“销售排行”会更加考虑商品的品牌,所以“品牌”的权重占比会比较大.而在商品ID为92 007的商品中,用户会相比于“品牌”属性更多地考虑商品的“销售排行”属性.
4.4.3 参数分析
本节将讨论AHNER的参数问题,主要涉及在进行属性异构信息网络嵌入学习时所采用的边嵌入维度z.通过保持其他设置不变,改变边嵌入维度z的值,观察AHNER的性能变化,图7给出了调整边嵌入维度z时,AHNER在Retailrocket数据集上性能的表现.
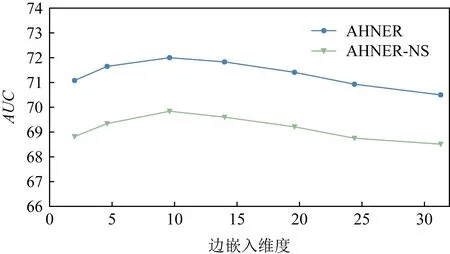
Fig. 7 Parameter performance changes of AHNER on Retailrocket dataset图7 Retailrocket数据集上AHNER参数性能变化图
从图7中可以观察到,边嵌入维度对AHNER的推荐性能影响较弱,当维度取值在10左右时AHNER的性能最好,当维度取值大于10时性能平缓下降,当维度取值小于10时性能平稳上升.
5 总 结
本文提出一个通用的基于自注意力机制的属性异构信息网络嵌入的商品推荐框架——AHNER,该框架通过基于自注意力机制的属性异构信息网络嵌入学习用户与商品的嵌入表示并解决推荐问题.AHNER在学习嵌入表示时充分利用节点的属性信息,学习不同属性信息的权重系数,并学习节点的属性嵌入表示.在学习节点的结构嵌入时,使用自注意力机制解决属性异构信息网络中多种边类型的问题,并为其学习统一的节点嵌入表示.然后融合节点的属性嵌入与节点的结构嵌入为节点学习整体统一的、低维的节点嵌入表示,并在推荐过程中克服点积作为匹配函数的局限性,利用DNN学习高效的匹配函数并解决推荐问题.AHNER在3个公开数据集上进行实验,实验结果证明AHNER比以前的方法取得了更好的性能.在未来的工作中:1)研究如何引入多模态的商品描述信息,如用户对商品的评论、商品图片、视频等来丰富网络中的节点属性信息,从而提高推荐性能;2)研究如何引入知识图谱来增强推荐系统的可解释性.
作者贡献声明:王宏琳负责方法的设计与实现,以及论文的撰写;杨丹负责确定研究思路和全文结构设计,并指导论文撰写;聂铁铮指导实验方案的实现;寇月负责审阅和完善论文内容.
