集成空间注意力和姿态估计的遮挡行人再辨识
2022-07-12张灿龙李志欣唐艳平
杨 静 张灿龙 李志欣 唐艳平
1(广西多源信息挖掘与安全重点实验室(广西师范大学) 广西桂林 541004) 2(桂林电子科技大学计算机与信息安全学院 广西桂林 541004)
行人再辨识[1-4]可以理解为在关联时间和空间的情况下,从不同区域的非重叠的摄像头下检索并辨识出同一个行人.由于安全需求的增长,以及监控设备所采集的数据量剧增,行人再辨识已成为计算机视觉领域重要的研究课题.在实际的应用场景中,行人再辨识可以结合步态、人脸、属性等其他领域的相关技术开展警务系统的嫌犯追踪、智能寻人等任务.
现存的大部分研究方法[5-8]主要是提取2张行人图像的整体特征进行特征匹配.行人所处环境复杂多样,匹配过程存在大量干扰信息,比如光线、视角不同会引起行人图像发生不同程度的形变,行人常常会面临被树木、车辆、建筑物及周围其他行人遮挡的情况,因此研究遮挡的行人再辨识这个课题是十分有意义的.
由于遮挡的行人图像包含了比较复杂的干扰性遮挡信息,直观的解决方案是去除遮挡部分再进行特征匹配.现有针对遮挡的行人再辨识的工作采用直接裁剪的方式,将存在遮挡的区域手工裁剪掉,再将未遮挡部分的图像与图像库进行匹配.面临大量需要匹配的图像时十分低效耗时,这个过程可能会引入噪声干扰.现有的一些工作[9-11]将注意力机制用于行人再辨识的研究中.注意力机制通过关注局部区域从而达到增强特征的目的,在识别精度上有了一定的提升.
受此启发,本文提出了一种集成空间注意力和姿态估计(spatial attention and pose estimation, SAPE)的遮挡行人再辨识模型.具体来说,SAPE模型利用空间注意力机制将模型注意力锚定在未遮挡的丰富视觉语义区域;结合分块匹配的思想,将注意力引导的特征图水平均匀分割成若干块,通过局部特征的匹配增加辨识的细粒度.而改进的姿态估计分支提取行人的关键点区域并得到标记遮挡的姿态引导特征图与注意力引导特征图深度融合,以获得更强的语义特征,消除遮挡区域对再辨识模型结果的影响.在构建再辨识特征阶段,本文所提出的SAPE模型充分关注行人的无遮挡区域,忽略行人在不同场景下的遮挡区域信息,有效缓解数据偏差对辨识精度的影响.
本文的主要贡献有3个方面:
1) 将空间注意力机制引入遮挡的行人再辨识任务中,它能够提取行人图像中辨识性强的关键语义信息,引导模型关注到未被遮挡的行人图像区域,以此来优化行人再辨识的分类效果.
2) 改进了姿态估计模型,通过姿态估计得到的关键点区域与特征图进行融合后得到辨识性强的特征,有效地消除遮挡区域对辨识的影响.
3) 实验结果表明,本文提出的SAPE模型比现存模型的mAP评价指标显著提高,在遮挡数据集Occluded-DukeMTMC,Occluded-REID和半身数据集Partial-REID上达到了优良的效果.此外SAPE是一个端到端的结构,支持潜在改进.
1 相关工作
1.1 遮挡行人再辨识
现有的行人再辨识的研究[12-17]已经取得一些进步,但是遮挡对于行人再辨识的研究是一个不可忽略的因素.现有一些基于遮挡面部识别的工作[18-19]已经取得了一些研究成果,这些工作[18-19]主要考虑利用生成对抗网络去除遮挡区域,均在遮挡的面部识别任务上取得了显著的效果,为遮挡的行人再辨识提供了很好的思路.还有一些工作开始尝试解决遮挡的行人再辨识问题.Zhuo等人[20]提出了行人身体注意力框架(attention framework of person body, AFPB),试图从随机增加遮挡的角度解决这个问题.该模型利用遮挡模拟器在人体图像中随机添加背景块,自动生成大量的人工遮挡行人图像,迫使网络区分模拟遮挡样本和非遮挡样本,从而学习一种抗遮挡的更加鲁棒的特征表示.He等人[21]针对遮挡问题提出了一种无对齐的模型,通过金字塔池对全卷积网络采集到的空间特征进行不同池化后得到金字塔特征,该模型提出的基于前景感知的金字塔重建(foreground-aware pyramid reconstruction, FPR)的相似性度量函数能够在遮挡严重的情况下提高精度.Wang等人[22]采用了图神经网络去建模,自适应图卷积网络(adaptive direction graph convolutional, ADGC)可以动态地学习高阶关系特征,以达到抑制无关信息、消除遮挡噪声的目的.上述3种方法[20-22]都是直接从被遮挡的整张图像中提取特征,避免了对图像进行裁剪,但是行人图像并没有区域遮挡的标签,这限制了在实际监控场景中的适用性.
1.2 注意力机制行人再辨识
近些年,注意力机制大大提升了许多计算机视觉任务的性能[9-10,17,23].注意力可以使资源的分配偏向投入到包含更加丰富信息的区域中.对于行人再辨识,注意力机制主要用于增强模型对辨识度高的区域关注度.Fu等人[9]设计了残差双注意模块聚合特征,该模块嵌入级联抑制网络(salience-guided cascaded suppression network, SCSN)后能够挖掘多样化的显著特征,增加网络对显著性特征的容量.Chen等人[17]提出了多样专注网络(attentive but diverse network, ABD-Net),该网络将注意力模块和多样性正则化作为相互补充,可以直接从数据和上下文中学习注意力掩码,并且避免过度关联和冗余的注意力特征.Tay等人[23]将注意力机制与属性信息结合,提出了属性注意网络框架(attribute attention network, AANet),将图像的局部特征以及行人的服装颜色、头发、背包等外观属性统一到一个框架中,来共同学习一个具有高判别度的属性注意特征.上述3种不同的注意力模型提升了模型对人体区域的关注,但是易出现过度关注与人体不相关细节的问题,对于遮挡行人再辨识这类特殊问题,并不具有良好的普适性.
1.3 姿态估计行人再辨识
基于姿态估计的行人再辨识可以有效解决行人姿态变化过大导致的辨识不准确[14,24-27].但是姿态估计也存在着姿态样本小、严重扭曲的行人样本姿态转化困难的问题.因此,Liu等人[24]提出了一种姿态转换框架(pose transfer),利用生成对抗网络和姿态骨架进行联合学习,以生成新姿势的变体增强数据样本,该姿态转移模型能提供足够的判别力特征.Artacho等人[25]提出了一个基于瀑布式的统一行人姿态估计框架UniPose,单姿态估计联合上下文分割有效地定位一个阶段的行人姿态.瀑布式的行人姿态估计结构具有精度高、不依赖统计后处理的方法等特点.但是,本节提出的模型运用在遮挡的行人场景时,行人姿态的关键点未能完全提取,姿态估计的效果不佳.本文提出将姿态估计关键点信息特征和空间注意力特征图相融合,用姿态估计引导特征匹配,特征更具鲁棒性,具有很好的辨识效果.
2 本文模型
为了更好地解决遮挡对行人再辨识的影响,对遮挡的行人图像提取更具辨识性的特征,本文提出了一个集成空间注意力和姿态估计(SAPE)的端到端的遮挡的行人再辨识模型.如图1所示,SAPE模型由空间注意力引导的全局特征子网络(SA-GFN)、水平分块的部分特征子网络(HP-PFN)以及姿态引导的全局特征子网络(PE-GFN)这3个子网络构成.本节对SAPE的各模块进行详细阐述,最后介绍本文使用的损失.

Fig. 1 Schematic overview of SAPE图1 SAPE结构图

Fig. 2 Schematic of spatial attention图2 空间注意力结构图
2.1 空间注意力引导的全局特征子网络(SA-GFN)
空间注意力的目的是建立空间域中像素间成对关系,从而捕获并聚合空间域中语义相关度较高的像素,使模型更加集中关注于图像中未被遮挡的区域.本文设计的SA-GFN的结构如图2所示.由骨干网提取的卷积特征图A∈C×H×W可作为空间注意力的输入,这里的C是总的通道数,H×W是特征图的尺寸.卷积特征图A∈C×H×W经过形变可以表示为一个N×C的2维矩阵M,这里N=H×W表示卷积特征图中像素点的个数,2维矩阵M可以视为包含N个C维的特征向量.本文将这些特征向量(即像素点)表示为Ai,其中i=1,2,…,N.空间注意力模块生成的注意力图Fsa可计算为:
Fsa=[g(δ(τ(W1Ai)))]©[δ(τ(W2si))],
(1)
其中,W1和W2均为1×1空间卷积层的参数,卷积核尺寸分别为C×(C/r)×1×1,2N×(2N/r)×1×1,r是一个预定义的控制降维比的正整数,τ表示BN层,δ表示ReLU激活函数,g(·)表示沿着通道维度方向的全局平均池化操作,池化后将通道维度降为1,©表示拼接操作,将降维后的原始特征Ai与包含全局关系的特征si嵌入后联结为注意图Fsa,这里的注意力图Fsa不仅包含了原始的特征,而且包含了全局关系的特征,具有更好的辨识性.而全局关系特征si∈2N可以表示为
si=S(i,:)©S(:,i),
(2)
这里S(i,:)表示像素点间的关联矩阵S∈N×N的第i行,S(:,i)表示像素点间的关联矩阵S∈N×N的第i列,因此全局关系特征si的计算可理解为联结了像素点间的关联矩阵S经过形变得到的行关系特征和列关系特征.像素点间的关联矩阵S计算为
Sij=[δ(τ(W3Ai))]T[δ(τ(W4Aj))],
(3)
这里Sij是关联矩阵S的第i行、第j列元素,表示第i个像素点对第j个像素点的作用,其中,i,j∈[1,N],W3和W4均为1×1空间卷积层的参数,卷积核的尺寸均为C×(C/r)×1×1.
注意力图Fsa作为全局平均池化的输入,使用一个3层的微网络结构,分别包含了1×1卷积层(V)、BN层(R)、ReLU层(L)这3层,之后将通道维度降为C,进一步增加网络深度,学习到更具深层的语义特征.最后使用Softmax来预测每个输入图像的身份分类概率fu,该网络的训练用到了交叉熵损失,损失Lsa的计算公式为
(4)
其中,mu通过第u个训练样本的标签得到,当子网络输出的分类结果与该样本对应的真实标签一致时mu=1,否则mu=0.
2.2 水平分块的部分特征子网络(HP-PFN)
受到Sun等人[28]提出的PCB(part-based con-volutional baseline)网络的启发,若只是单一地将主干网络提取的全局特征进行池化并分类,极易造成大量的细节特征丢失.为细化网络结构,进一步提升特征的表征能力,本文增加了一个水平分块的部分特征子网络,其结构如图1的HP-PFN虚框所示.
在水平分块部分特征子网络中,本文通过将骨干网络输出的全局特征图A∈C×H×W与行人图像注意力图Fsa做外积来提取注意感知特征图,该特征图能够更加有效地关注未遮挡区域.接下来将该特征图水平分成p个部分,分别表示为xp,p=1,2,…,P,再分别对每个部分做全局均值池化,此时每个分块的维度为2 048维,再经过一个1×1的卷积降维得到的分块维度为256维.训练时将p个特征向量分别送入全连接层用于分类,得到每一个分块的分类结果后与行人整体特征分类相同的标签计算交叉熵损失.多分类交叉熵损失函数为
(5)
其中,yp表示该图像的行人身份,K表示训练集中的行人身份总数量,W,b分别表示分类层的权重和偏置.水平分块的部分特征子网络的总损失用Lhp表示.
2.3 姿态引导的全局特征子网络(PE-GFN)
由于姿态估计可以定位到行人的骨骼关键点,在行人再辨识方向的应用已经表现出很好的性能,对于遮挡这类特定问题而言,有效地消除遮挡能够抑制噪声干扰.受此启发,本文提出了姿态引导的全局特征子网络(PE-GFN).输入一张行人图像后,姿态估计模型可以提取出Q个关键点,并得到关键点区域的置信图,对应可见区域的每个关键点处都有一个高斯峰值,而存在遮挡的关键点置信度较低,因此设置一个阈值λ过滤掉置信度比较低的关键点以消除遮挡区域.
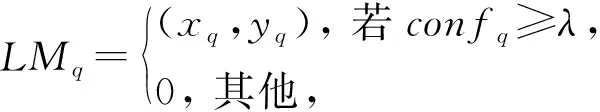
(6)
其中,LMq表示第q个关键点标志,q=1,2,…,Q,(xq,yq)表示相应的坐标,confq表示该关键点的置信度.由关键点标志可以生成热图,然后将热图与空间注意力图进行特征融合,在融合特征时若使用简单的求和或池化操作,容易引入特征噪声干扰.本文将子网络的特征拼接起来,通过融合模块进行卷积运算.首先将热图与空间注意力图Fsa相乘得到包含姿态信息的特征图Fpose,由于每个热图都明确地标示了图像的遮挡区域,因此包含姿态信息的特征图Fpose能够使模型更加关注非遮挡区域,有效地抑制遮挡噪声.然后将包含姿态信息的特征图Fpose与空间注意力图Fsa拼接,这里的卷积神经网络使用了深度卷积和点卷积,能够得到更具细粒度的融合特征,并且能够有效地减少神经网络的参数.得到融合后的特征图,经过全连接后进行分类,整个融合过程可以表示为
Ffuse=W6[W5((Fpose⊗Fsa)©Fsa)],
(7)
这里W5和W6分别表示深度卷积和点卷积的参数,⊗表示外积操作.与SA-GFN相同,这里使用Softmax函数来预测每个输入的图像身份,并与真实的身份标签一起使用交叉熵作为损失函数,该网络损失Lpe计算过程与式(4)相同.
2.4 损失函数
本文提出的SAPE框架共包含了3个子任务网络,可将此网络结构视为多任务网络,由于每个子任务对于整个模型存在不同的贡献,若将每个子任务损失的权重设为相同,则会影响最后的辨识精度.而由于每个子任务的最优权重不仅依赖于衡量尺度,而且依赖于每个任务噪声的大小.故在本文的工作中使用同方差不确定性学习[29-30],结合多个子任务的损失,同时去学习多目标,以获得子任务损失的权重因子.
同方差不确定可以利用贝叶斯建模去优化多任务的不同权重.当其中的一个子任务的损失增大时,其权重参数缩小,反之亦然.本文假设预测误差满足高斯分布,因此该网络结构的最小化总任务损失为
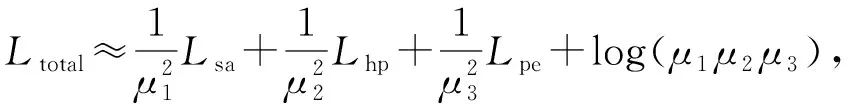
(8)
其中,μ1,μ2,μ3分别为它们的噪声因子,将这3个参数作为训练参数代到多任务学习中进行训练.
3 实 验
3.1 数据集和评价指标
为了验证本文模型能够有效地解决行人再辨识中的遮挡问题,分别在Occluded-DukeMTMC[31]和Occluded-REID[20]这2个遮挡数据集以及半身数据集Partial-REID[32]上进行了实验.此外,本文在2个常规全身图像行人再辨识数据集Market-1501[33]和DukeMTMC-reID[34]上评估所提出模型的鲁棒性.
Occluded-DukeMTMC是在DukeMTMC-reID数据集中提取的一个遮挡数据集.其中,训练集共包含702个行人的15 618张图像,测试集包含1 110个行人身份,其中图库和查询集中分别有17 661张图像和2 210张图像.
Occluded-REID是由校园内的移动摄像设备捕获的行人图像,包含200个被遮挡行人的2 000张注释过的图像.其中每个行人身份分别包含5张全身的和5张被不同程度遮挡的图像.
Partial-REID包括60个行人的900张图像,每个行人包含5张全身图像、5张遮挡图像和5张手工裁剪的半身图像.本文只使用全身图像和半身图像做性能评估.
Market-1501包含从6个摄像机所拍摄到的1 501个不同身份的行人图像,所有的图像都是固定尺寸的.其中包含19 732张图库图像和12 936张训练图像,数据集包含较少的遮挡或部分行人图像.
DukeMTMC-reID是由不同位置的8个摄像头采集到的36 411张不同尺寸的图像,共有1 404个行人身份、16 522张训练图像、2 228张待查询图像,共17 661个图库图像.
本文的实验使用累积匹配特征曲线(cumulative match characteristic, CMC)和平均精度均值(mean average precision, mAP)来衡量模型辨识性能.CMC曲线主要反映整个模型的分类准确率,常以Rank-n的形式表示前n个匹配结果;mAP是某一个分类的所有返回结果的平均准确率.
3.2 参数设置
实验所使用的硬件平台中GPU为32 GB的Tesla V100,操作系统为Ubuntu 18.04.实验使用的深度学习框架为PyTorch1.0,Python的版本为3.7,CUDA的版本为10.1.
本文使用在ImageNet[35]数据集上预训练过的ResNet50[36]作为采集特征的骨干网络,并对该网络做了进一步的微调:移除了网络最后一层的池化层和全连接层,并且为了获得更加丰富的特征信息,将conv4_1的步长设置为1.在训练过程中,所有输入图像的大小调整为384×128,并通过随机水平翻转和随机删除去增强数据.设置批次大小为32,网络模型的训练迭代次数为120,训练过程中采用Adam优化.在水平分块的部分特征子网络中,特征图被水平分成p个部分,这里p=3.在空间注意力引导的全局特征子网络中,预定义的控制降维比的正整数r=8.在姿态引导的全局特征子网络中,本文采用了在COCO[37]数据集上预训练过的AlphaPose[38]模型作为姿态估计器,用来生成人体的关键点.该模型共预测18个关键点,本文对头部区域的关键点进行了融合,最终获得Q=14个关键点,包括头、颈、肩膀、手肘、手腕、腰部、膝盖、脚踝.置信度阈值λ=0.2.对于Occluded-DukeMTMC和Occluded-REID数据集,初始学习率设定为0.1,并且40轮以后降为0.01.对于Partial-REID数据集,初始学习率设定为0.02.
3.3 实验结果定量评估分析
本节分3组实验,与注意力方法、分块方法以及姿态估计方法分别在Occluded-DukeMTMC,Occluded-REID,Partial-REID三个数据集上进行性能比较,结果如表1所示:

Table 1 Performance Comparison with Attention Methods, Part Methods and Pose Estimation Methods on Three Datasets表1 与注意力方法、分块方法和姿态估计方法在3个数据集上的性能比较 %
1) 与注意力方法的对比
与注意力方法的比较在表1的第1组中说明.在这些方法中,SCSN[9]设计了残差双注意模块聚合特征,ABD-Net[17]引入了双注意力机制和正则化作为相互补充,AANet[23]提出了属性和注意力结合的属性注意力机制.从表1中可以观察到,与SCSN,ABD-Net,AANet这3种注意力方法比较,本文提出的SAPE模型在3个数据集上性能均有很好的表现.在Occluded-DukeMTMC数据集上,SAPE的Rank-1精度比排名第2的注意力方法ABD-Net高出约10%.这一对比实验表明,缺少遮挡处理的注意力机制在辨识被遮挡的行人时性能欠佳,同时也说明设计专门的遮挡处理机制十分必要.
2) 与分块方法的对比
分块后的图像的局部匹配可能会导致图像的不对齐,并且不能去除遮挡进行分块匹配时每个分块均有可能存在严重的噪声干扰,可能会增加局部匹配的难度.比较表1的第2组中的数据可以看出,相较于现存的基于分块的行人再辨识的方法,本文提出的SAPE对于遮挡问题表现出更好的适用性.这是由于本文的分块是针对注意力感知特征图,融入注意力机制后的特征图增强了对于未遮挡区域的关注,分块后能够更加精确地匹配未遮挡区域.
3) 与姿态估计方法的对比
表1中的第3组数据展示了姿态估计方法的性能.与表1中展示的3种方法比较,本文提出的SAPE模型在Occluded-DukeMTMC,Occluded-REID,Partial-REID这3个数据集上分别达到了55.1%,76.4%,82.5%的Rank-1精度,超过了现有模型的精度.总的来说,本文所达到的性能提升主要得益于2个方面:①部分匹配比全局特征学习更适合于被遮挡的行人再辨识任务;②与简单地将特征与姿态关键点热图融合相比,姿态融合特征对于辨识精度更加有效.
4) 在整体数据集上的性能
尽管,现有的一些针对遮挡的模型在遮挡和半身数据集上取得了不错的匹配结果,但是由于特征学习和对准过程中的噪声影响,在整体数据集上也可能面临模型出现过拟合的问题,往往不能取得令人满意的性能.表2展示了在Market-1501和DukeMTMC-reID数据集上不同模型的性能比较.“+Aug”的对应结果是当训练本文的模型时,添加了随机遮挡图像以解决训练集的数据不平衡问题.这种随机增加遮挡是在训练集中选取的图像送入网络之前随机选取一个背景块,随机替换该图像的一个区域,以增加遮挡训练样本.从表2中可以观察到,SAPE+Aug模型取得了最优的性能,表明本文的模型针对整体数据集也是有效的,本文的方法并不囿于遮挡行人,具有更好的普适性.
3.4 消融实验
首先,本文在Occluded-DukeMTMC数据集上验证了3个子网络对SAPE辨识性能的影响,实验结果如表3所示.表3中第1行仅使用单个损失Lsa,第2行使用了Lsa和Lhp两个损失的组合,第3行使用3个损失的组合,第2组和第3组中每个损失权重均相同.当向网络中添加这些相关的子任务时,网络的整体辨识准确率会提高,这验证了每个子任务对模型的整体性能均有一定的贡献.另外,表3最后一行采用同方差不确定性学习的方法获得任务损失权值,可以看出,与前面3组损失组合方式相比,辨识准确率有了很大的提升,mAP和Rank-1准确率分别提高到42.3%和55.1%.
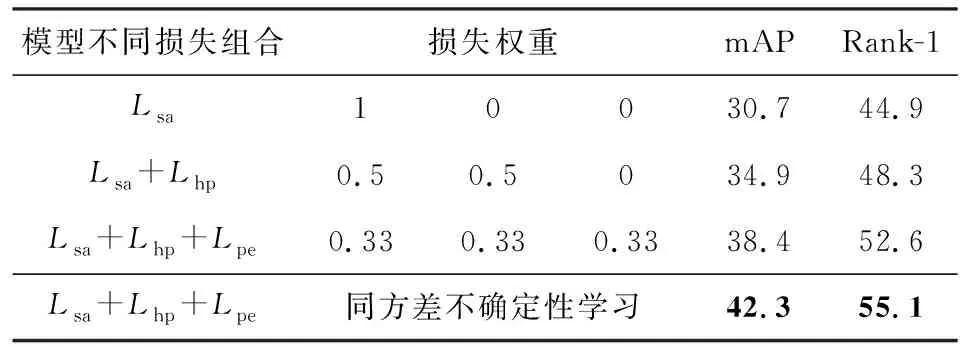
Table 3 Performance Comparison of Different Task Loss onOccluded-DukeMTMC Dataset表3 在Occluded-DukeMTMC数据集上不同任务损失的性能比较 %
然后,本文分析了空间注意力(SA)模块在骨干网络ResNet-50的不同层对SAPE准确性性能的影响.由于SA模块是可以即插即用的,因此本文在所有的残差块(包括conv2_x,conv3_x,conv4_x和conv5_x)之后添加了所提出的SA模块.表4展示了分别在Occluded-DukeMTMC和Partial-REID数据集上的实验结果.由表4可以看出,在不同的残差块加入SA模块后mAP和Rank-1均有提升,在conv5_x后加入SA模块性能可以达到最优.
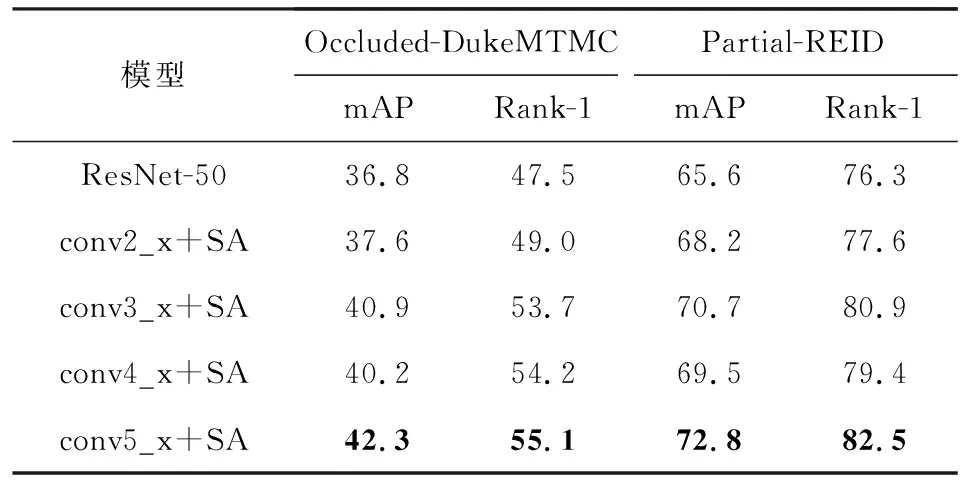
Table 4 Experimental Results after Adding Spatial Attention(SA) Module to Different Layers of the ResNet-50表4 将空间注意力(SA)模块加入ResNet-50网络的不同层后的实验结果 %
接下来,本文尝试在模型中使用3种不同的姿态估计算法,分别是OpenPose[41],HR-Net[42],AlphaPose[38].对模型分别在2个不同的数据集Occluded-DukeMTMC和Partial-REID上进行测试,实验结果如表5所示.由表5可以看出,3种算法精度相近,最终本文采用了表现更好的AlphaPose.
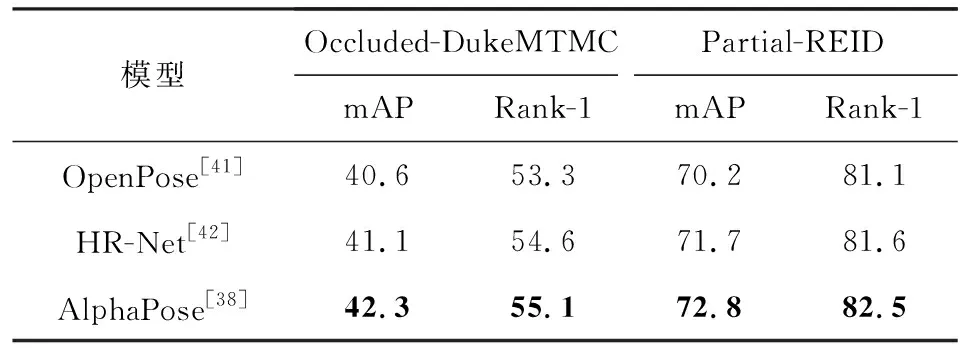
Table 5 Performance Comparison of Pose Estimation Algorithms表5 姿态估计算法的性能比较 %
如式(5)所示,本文设置了一个阈值λ过滤掉置信度比较低的关键点以消除遮挡区域.图3中展示了不同阈值的设置在不同的数据集上对于辨识精度的影响.由图3可知,当阈值太小或太大时,性能较差.这是因为当阈值太小(例如λ=0)时,模型将选择所有检测到的标志,这样就达不到利用关键点消除遮挡的目的,当利用存在遮挡区域的信息进行匹配时,将不可避免地带来噪声信息;当阈值太大(例如λ=0.7)时,许多标志就会被丢弃,这些被丢弃的标志的对应区域,尽管它们可能没有任何遮挡,却被不必要地丢弃了.由实验结果可以看出,当阈值λ=0.2时,在3个数据集上的精度达到最优.
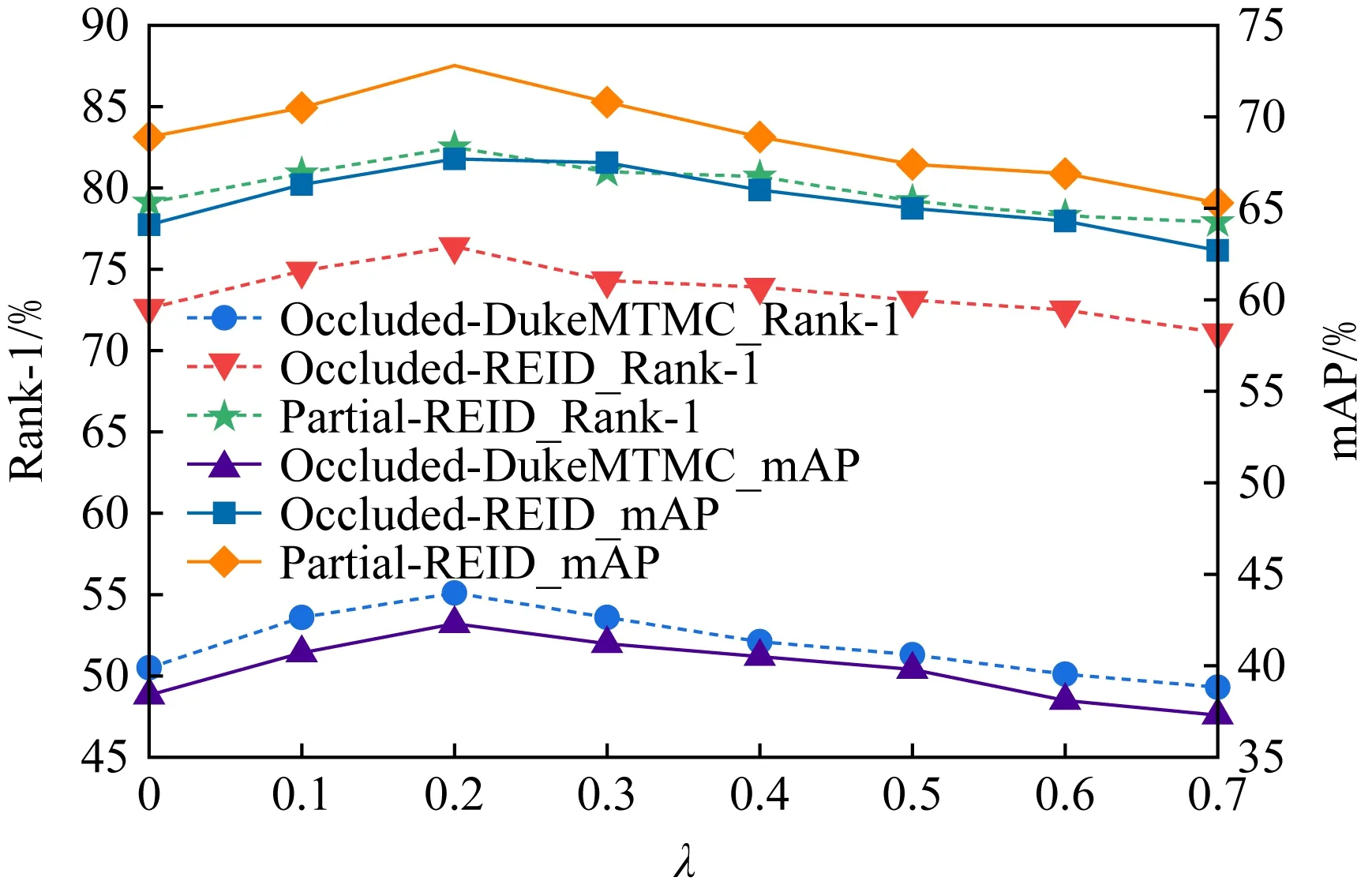
Fig. 3 Influence of confidence threshold λ on accuracy图3 置信度阈值λ对精度的影响
图4展示了水平分块p的不同设置在不同数据集上对辨识性能的影响.水平分块p的大小对于分块特征的粒度有很大的影响.当p=1时,学习到的特征是一个全局特征,此时性能总是比p>1时的精度差,这恰好也证明了对于卷积神经网络提取到的特征进行分块的必要性;当p增加到3时,SAPE模型性能达到最优;当p>3时,性能开始缓慢下降.这是因为当分块数目过多时,一些未遮挡的部分可能不包含任何关键点,由于在式(5)中对应的置信度为0,在匹配时该区域将被过滤掉.
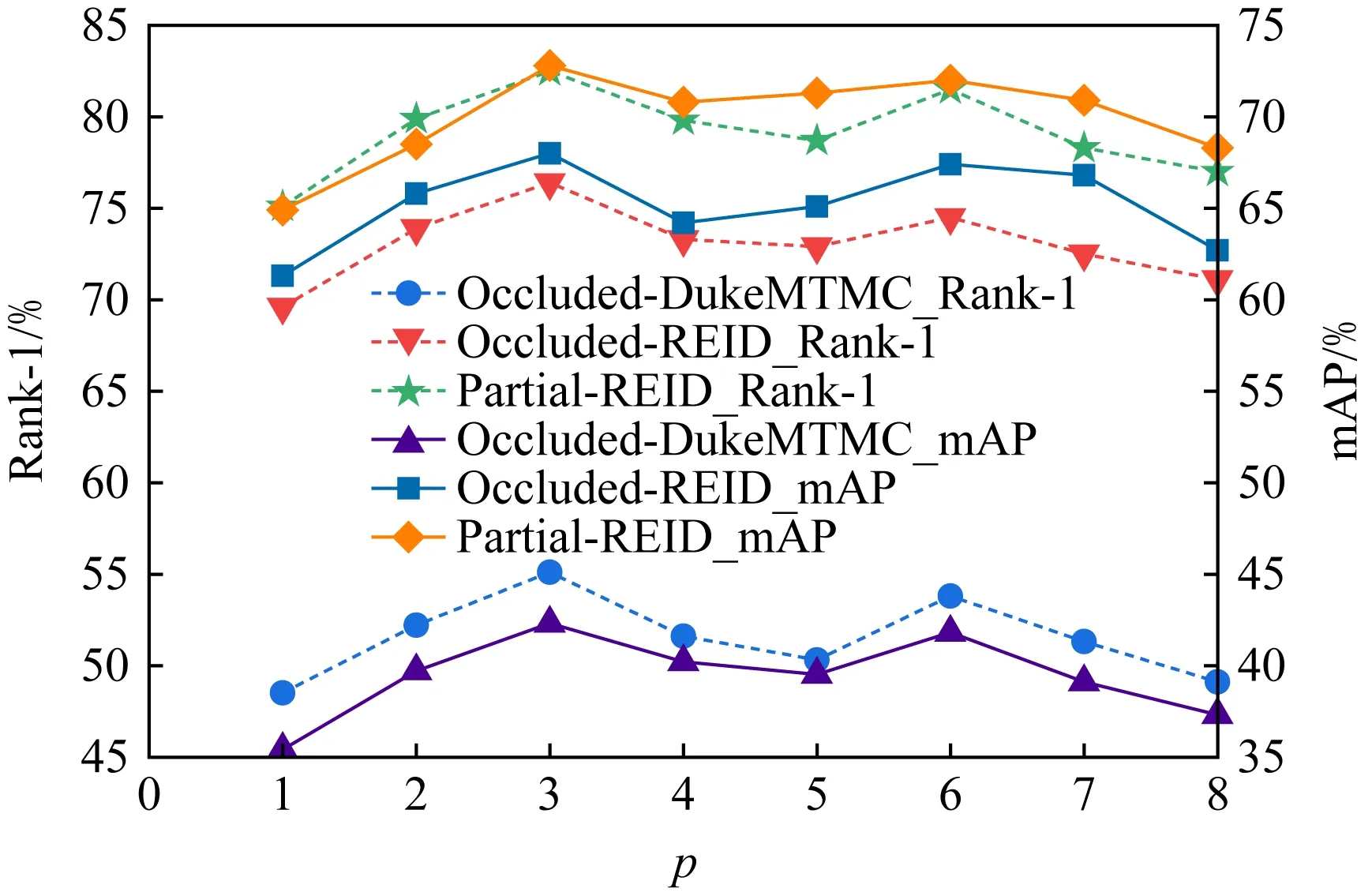
Fig. 4 Influence of horizontal partitioning p on accuracy 图4 水平分块p对精度的影响
3.5 训练细节

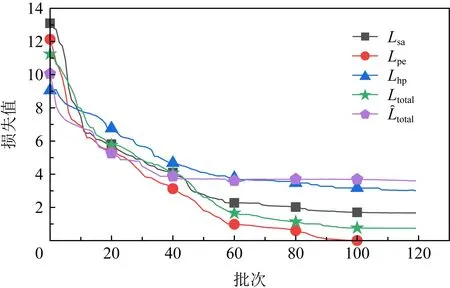
Fig. 5 Loss function declines on Occluded-DukeMTMC dataset图5 在Occluded-DukeMTMC数据集上损失函数 下降曲线图
图6展示了在这3个数据集上测试时Rank-1精度的上升曲线.由图6中可以看出,模型精度在100个批次以后变化比较缓慢,在120个批次左右时基本上趋于稳定状态,因此在网络训练时我们的模型总的训练批次设置为120个批次.而在不同的数据上测试时,在60个批次左右均已经达到了比较高的分类精度,并且在前60个批次训练过程中损失下降速度较快,60个批次以后缓慢上升并逐渐趋于稳定状态,说明整个模型的收敛性能比较理想.
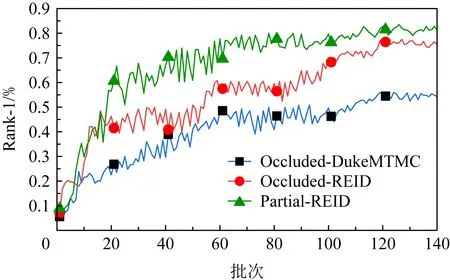
Fig. 6 Increasing curve of test accuracy on different datasets图6 不同数据集上测试精度的上升曲线图
3.6 可视化
为了更加直观地感受本文的注意力机制,图7展示了本文利用梯度响应对PCB基线模型和我们的SAPE模型进行定性分析的可视化结果.梯度响应可以识别出网络模型认为相对重要的区域.图7中可以清楚地看到本文提出的SAPE模型能够更加精确地关注到未被遮挡的区域,对比PCB基线模型展现了更好的效果.
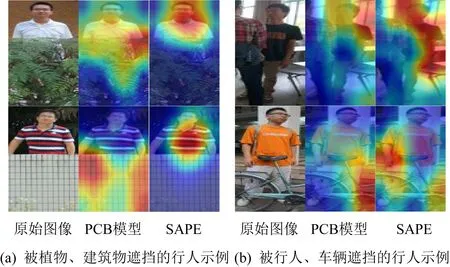
Fig. 7 Visualization results of PCB and SAPE according to gradient response图7 PCB和SAPE根据梯度响应的可视化结果
4 总 结
本文提出了一种集成空间注意力和姿态估计的遮挡行人再辨识模型SAPE,解决了行人再辨识中的遮挡问题.利用空间注意力机制从全局特征中挖掘更具辨识度的细粒度特征,并运用姿态估计提取图像中行人的关键点信息后与细粒度的注意力特征图相融合,从而消除遮挡对再辨识结果的影响,并且增加了一个局部特征匹配的子网络,实现了特征的多细粒度表示.通过多个实验分析验证,本文的模型针对遮挡的行人再辨识具有不错的辨识精度.接下来的工作将对结合姿态估计的遮挡行人再辨识模型进行进一步研究,通过抑制背景干扰、利用图卷积挖掘深层次语义信息等提高遮挡行人再辨识的准确率.
作者贡献声明:杨静提出选题,设计研究方案,实施研究过程,采集整理数据,撰写和修订论文;张灿龙设计研究方案和论文框架,修订论文;李志欣设计研究方案,提出指导性建议;唐艳平指导论文写作.
