移动边缘网络中联邦学习效率优化综述
2022-07-12彭绍亮王国军贾维嘉
孙 兵 刘 艳 王 田 彭绍亮 王国军 贾维嘉
1(华侨大学计算机科学与技术学院 福建厦门 361021) 2(北京师范大学人工智能与未来网络研究院 广东珠海 519087) 3(北京师范大学-香港浸会大学联合国际学院人工智能与多模态数据处理重点实验室 广东珠海 519087) 4(湖南大学信息科学与工程学院 长沙 410082) 5(广州大学计算机科学与网络工程学院 广州510006)
近年来,深度学习(deep learning, DL)[1]的发展为人工智能技术的进步创造了动力.随着物联网技术的发展,移动设备都具备强大的芯片、传感器以及计算能力,能够在处理高级任务的同时,收集和产生更丰富的数据[2].这些数据为深度学习的研究提供了有利的基础条件,是深度学习不可或缺的部分.
传统以云为中心的深度学习,需要先收集移动设备的数据,包括物联网设备和智能手机收集的数据,例如照片、视频和位置等信息[3-5],并全部发送到基于云的服务器或数据中心进行处理与训练.然而,这种方法存在2个问题:
1) 网络负担.在万物互联的时代,移动设备每分每秒都产生数以亿计的数据[6],这些数据全部上传到云服务器会占用大量的网络带宽.同时,以云为中心的学习方式传输延迟高,不能及时进行数据交互,给网络带来不必要的负担.
2) 数据隐私[7].数据所有者对隐私越来越注重,用户往往不愿共享自己的个人数据.许多国家和组织也制定了相关隐私政策,例如欧盟委员会制定的“General Data Protection Regulation”(《通用数据保护条例》)[8].因此,利用一些边缘设备的计算和存储能力,把计算推向边缘[9]被提出作为一种解决方案.
因此,联邦学习(federated learning, FL)[10]应运而生,目的在于保护大数据环境下模型学习中涉及的用户数据隐私.在联邦学习训练过程中,只需要将所有移动设备在其私有数据上训练的本地模型上传到云服务器中进行聚合,不涉及数据本身,很大程度上提高了用户数据的隐私性.同时,边缘计算的提出是为了缓解云中心的计算压力,目的是把云服务中心的计算任务卸载到边缘[11],这恰好与联邦学习的计算模式相适应,为联邦学习创造了有利条件.在移动设备上训练模型,除了保证数据不离开本地,还能让计算更加靠近数据源以节省通信成本.
然而,无线传感网络[12-13]等边缘环境复杂、设备能力的差异性、数据质量等因素,使得如何在边缘网络高效率地执行联邦学习是当前面临的关键问题.一方面,一些实时性强的应用需要及时得到反馈,例如车联网服务[14]等;另一方面,在物联网快速发展的时代,爆发式增长的数据需要高效的处理机制才能发挥其作用.因此,对联邦学习效率的研究是非常必要的.
目前,联邦学习的热度呈持续增长的趋势.图1为谷歌搜索随时间变化的热度值,图2为国内外文献网站检索到的近几年关于联邦学习的文献数量.可以看出,联邦学习正处于迅速发展的阶段.
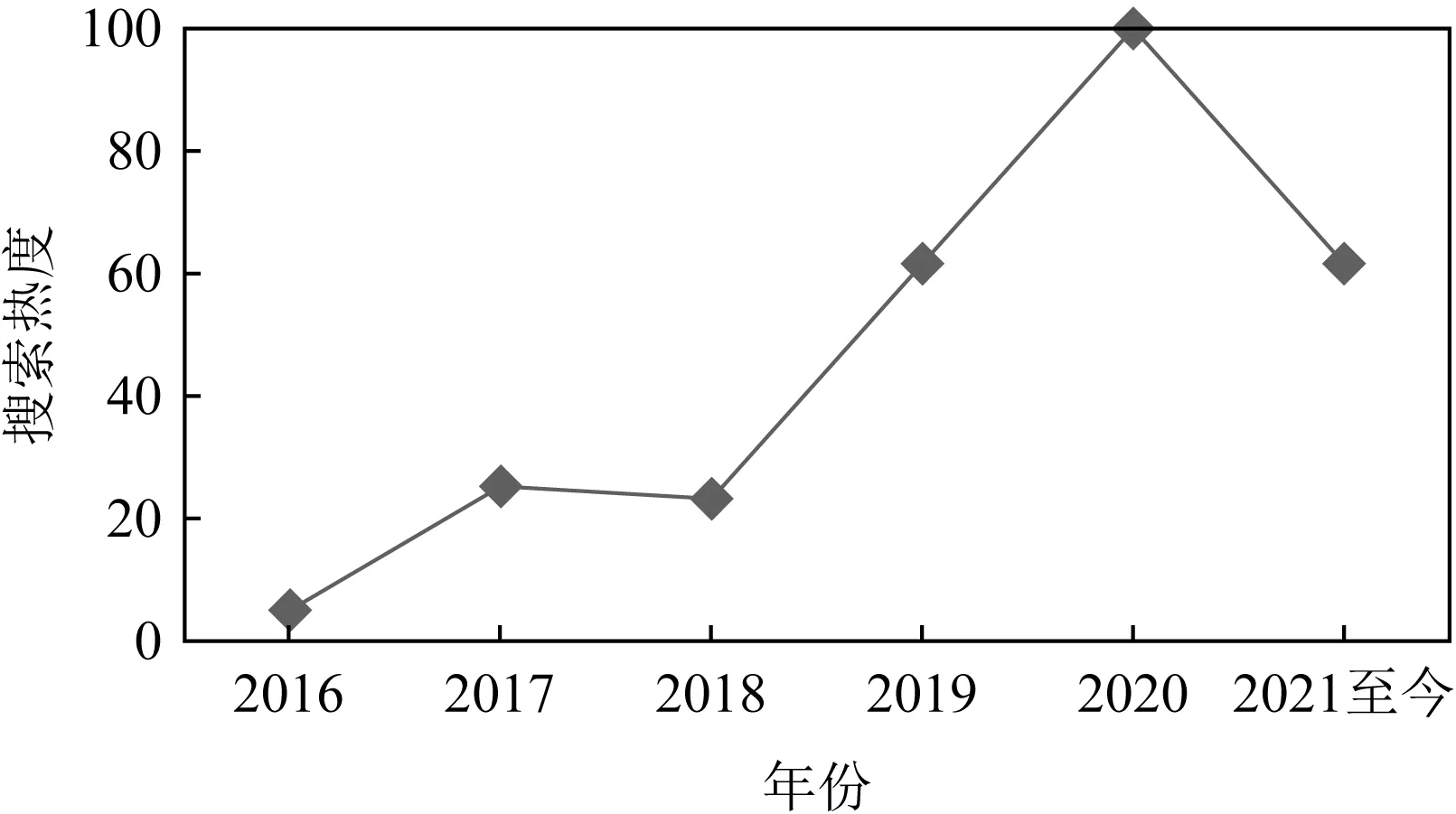
Fig. 1 Google trends图1 谷歌搜索热度
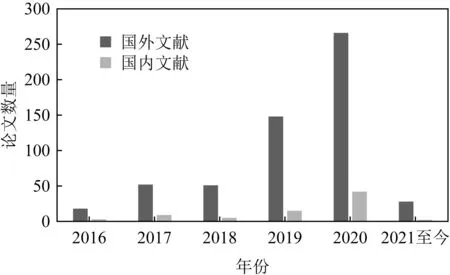
Fig. 2 Number of papers at home and abroad图2 国内外文献数量
本文首先对联邦学习效率优化方案进行了广泛调研,阐述了联邦学习的技术背景以及深度学习等基础知识,并说明了边缘计算与联邦学习的基本原理以及二者之间的相互作用与影响.其次,分析了联邦学习中存在的效率优化问题,根据影响效率的不同因素,将联邦学习效率优化归纳为通信优化、训练优化以及从安全与隐私角度考虑的效率优化.再次,列举并对比分析了目前的研究方案,揭示了现有方案存在的不足.联邦学习的研究还处于正在发展的阶段,现有技术还不够完善.最后,探讨了联邦学习面临的新挑战,本文以边缘计算作为扩展,提出了基于边缘学习的联邦学习方案,并在数据优化、自适应学习、激励机制和前沿技术等方面提出了创新性的理念与思想,为联邦学习未来的研究提供了新的解决思路.
1 联邦学习背景概述
通过联邦学习在国内外的研究现状,可以看出其重要性与研究价值.联邦学习的提出和实现与边缘计算和深度学习息息相关.边缘计算为联邦学习的本地训练创造了条件,深度学习为联邦学习提供了理论依据和核心技术.本节首先介绍深度学习和边缘计算等背景知识,然后阐述传统数据隐私保护技术及其不足,从而引出联邦学习的概念、架构与分类,突出联邦学习的特点与优势,对比了联邦学习与传统分布式学习的区别,并总结了现有的联邦学习平台的特点.
1.1 深度学习
现有的人工智能应用大多是通过机器学习(machine learning, ML)来实现的,从各类设备上获取数据来训练机器,实现分类和预测等任务.深度学习则是利用人工神经网络[15]来学习数据,结构如图3所示.深度学习模型的每一层都由神经元组成,神经元根据输入的数据产生非线性输出.输入层的神经元接收数据并将其传播到隐含层,隐含层的神经元生成数据的加权和,然后用特定的激活函数[16]输出加权和,最后的结果发送到输出层.一个训练好的深度学习模型可以应用于实际场景以代替人类部分的智能行为.
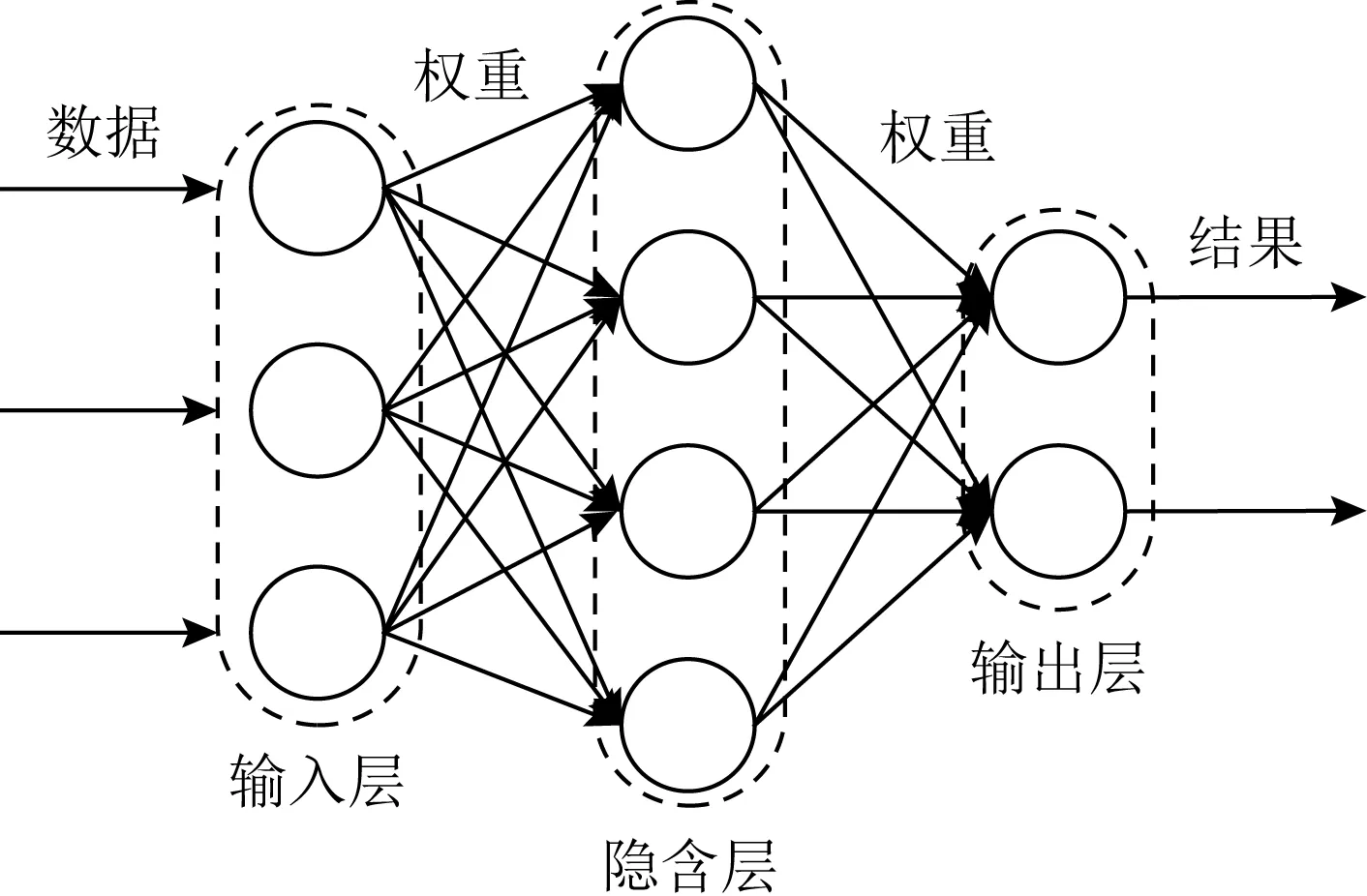
Fig. 3 Deep learning model图3 深度学习模型
常见的模型有3种:
1) 卷积神经网络(convolution neural network, CNN)[17].CNN是一种前馈式的深层神经网络,包含卷积层、池化层和全连接层.在图像识别上应用的过程首先将数据输入CNN模型,经过多次卷积和池化操作,再将提取到的图像特征输入全连接层进行识别与分类.
2) 循环神经网络(recurrent neural network, RNN)[18].RNN是用来解决顺序输入数据等时序问题的模型.RNN的输入包括当前和先前输入的样本,每个神经元都拥有一个内部存储器,用来存储先前样本的信息.例如长短期记忆网络就是RNN的扩展,并且广泛应用于自然语言处理等领域.
3) 生成式对抗网络(generative adversarial net-work, GAN)[19].GAN由2个主要组件组成,即生成器和鉴别器.生成器负责从真实数据的训练数据集中学习数据特征之后生成新的伪数据;鉴别器负责根据生成器生成的伪数据对真实数据进行区分.GAN通常应用在图像生成、图像转换、图像合成等领域.
1.2 边缘计算
边缘计算顾名思义就是在边缘进行计算.随着物联网设备和数据的增长,云计算中心的负载越来越大,通信成本和传输延迟也在不断增加.为此,边缘计算将计算从网络中心推向更接近用户和数据源的网络边缘,把计算任务卸载到边缘或者移动设备上,从而降低延迟与带宽消耗[20]、提高效率和数据隐私性.
“边缘”是一个相对的概念,指云服务器之外包含具有计算和存储能力的设备节点的边缘网络层,例如由云计算与传感器网络层构成的传感云系统[12].随着技术的深入研究与发展,相继提出雾计算[21]、移动边缘计算(mobile edge computing, MEC)[22]等边缘化模型.如图4所示,网络环境中的基站、微型服务器和智能设备等都可以作为边缘计算节点.

Fig. 4 Edge computing model图4 边缘计算模型
从联邦学习的设置来看,在移动设备上进行本地模型训练,服务器进行模型聚合,将主要的学习任务卸载到移动设备,这种基于边缘端以保护用户隐私的深度学习方式也顺应了边缘计算的模式.联邦学习与边缘计算的结合与互补是一种必然的趋势.边缘计算旨在协调大量的移动设备和边缘服务器以处理在其附近生成的数据[23],在边缘处理数据还能大大提高数据的隐私性.而联邦学习的目的也是在保护用户数据隐私的前提下,通过从移动边缘设备的数据中学习特征信息来实现智能决策和行为.此外,联邦学习与边缘计算之间还存在3方面的联系与相互作用:
1) 移动边缘网络中产生的数据需要联邦学习充分发挥其价值.联邦学习可以自动识别并获取边缘设备上产生的有用数据,例如文本信息、图像视频信息、车辆信息等.然后,根据快速变化的边缘环境,从数据中提取特征信息并反馈到实时预测决策应用(例如智能交通[24]、智能驾驶[25]等)中,从而在提高数据处理效率的同时保护用户数据隐私[26].
2) 边缘计算可以利用大量的资源丰富联邦学习的应用场景.深度学习的发展离不开算法优化、硬件优化、数据和应用场景等重要推动力.边缘计算可以为联邦学习提供丰富的数据与资源.为了提高模型的性能,最常用的方法是使用更多层神经元来细化模型,需要在模型中学习更多参数,训练所需的数据也随之增加.移动边缘网络中大量的物联网设备恰好为联邦学习提供了丰富的数据.此外,如果这些数据集上传到云数据中心进行处理,会消耗大量的带宽资源,并给云服务器带来巨大压力.边缘计算为联邦学习提供了大量的计算资源,移动设备的计算资源也是联邦学习的应用基础.
3) 人工智能面向用户需要结合边缘计算和联邦学习作为基本架构.人工智能已经在日常生活中的许多领域取得了巨大的成功,例如智能推荐系统、模式识别和智慧城市等.为了支持更多的应用程序,人工智能需要更接近用户.边缘设备更接近用户和移动设备,并且边缘计算相比云计算更加灵活、成本更低廉.而联邦学习在边缘计算的基础上,承载了人工智能应用的部署任务.随着用户对隐私的关注,通过联邦学习的调控能实现保护隐私的人工智能.因此,联邦学习与边缘计算除了具有互补性,同时也是普及人工智能的基础架构.
1.3 深度学习中的隐私保护
传统的深度学习训练中,各方数据首先被数据收集者集中收集,然后由数据分析者进行模型训练.其中,数据收集者与数据分析者可以是同一方,如移动应用开发者(云服务器);也可以是多方,如开发者将数据共享给其他数据分析机构.由此可见集中学习模式下,用户数据一旦被收集,便很难再拥有对数据的控制权,其数据将被用于何处、如何使用也不得而知[27].针对深度学习面临的数据隐私问题,目前的研究主要从差分隐私、同态加密以及多方安全计算等不同角度对深度学习中的隐私保护方法进行了探讨.
1.3.1 差分隐私技术
差分隐私是一种扰动技术,指在模型训练过程中引入随机性,即添加一定的随机噪声,使输出结果与真实结果具有一定程度的偏差,防止攻击者恶意推理.具体来说,差分隐私在服务器进行计算的过程中利用扰动方法来保护敏感数据,如图5所示.文献[28]基于差分隐私保护机制提出了一种对本地数据进行扰动变换的机制,使用噪声训练从而增加云端深度神经网络对移动设备提交的扰动数据的鲁棒性.差分隐私技术大多是在原始数据或模型参数上进行加噪,保护数据隐私的同时模型精度会有所影响.
1.3.2 同态加密技术
如图6所示,同态加密的核心思想是直接在密文上做运算,运算结果解密后与明文运算的结果相同.目前,同态加密已被广泛应用于基于云计算场景的隐私保护研究中.在以云为中心的深度学习过程中使用同态加密对数据加密然后分析计算,能够很好地解决数据保密与安全等问题.然而,同态加密十分依赖于函数的复杂度,对于存在大量的非线性计算的深度学习模型,算法的计算开销十分高昂.此外,同态加密只支持整数数据,且需要固定的乘法深度[29]等.
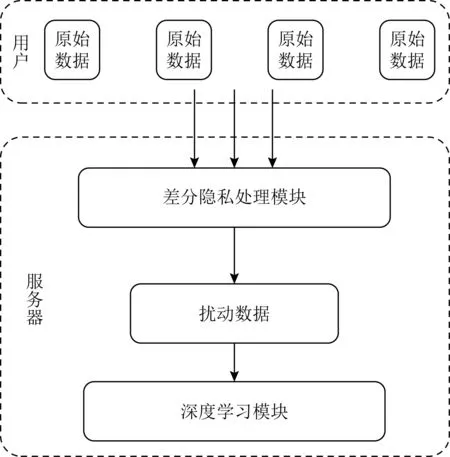
Fig. 5 Differential privacy technology图5 差分隐私技术
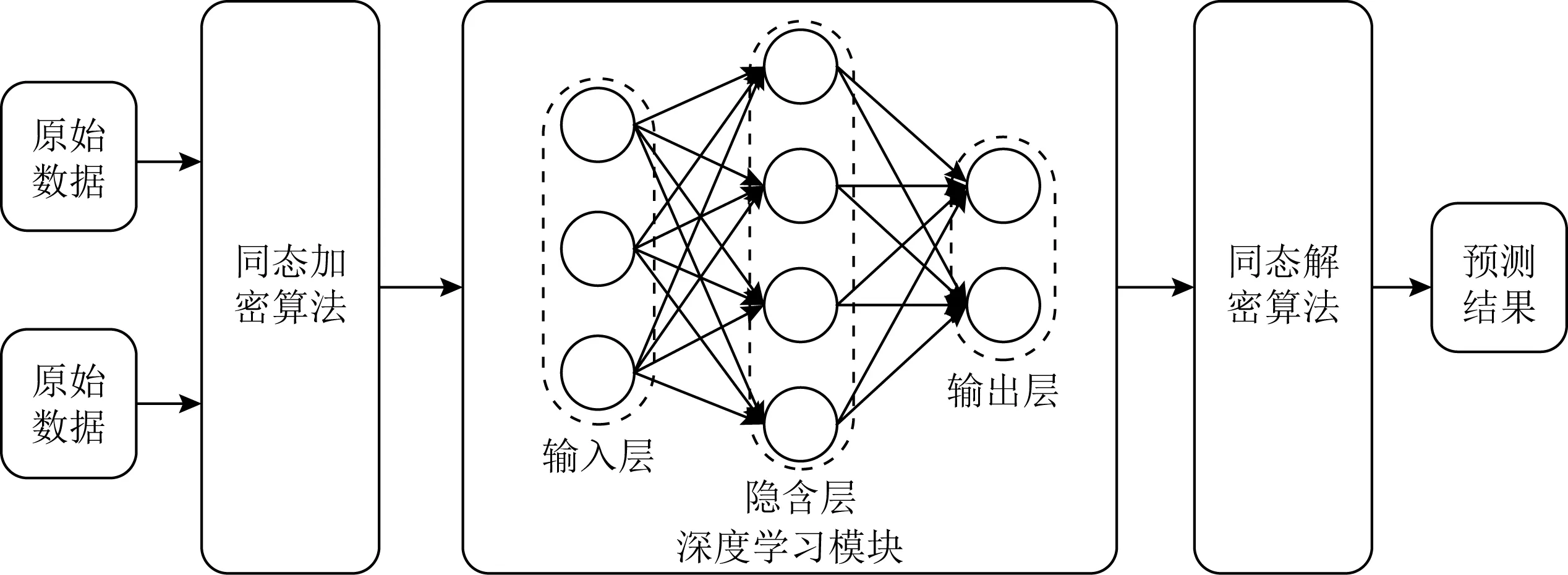
Fig. 6 Homomorphic encryption technology图6 同态加密技术
1.3.3 多方安全计算
多方安全计算是通过特殊的算法在无可信第三方的情况下,确保输入的隐私性与输出的正确性[30].具体来说,假设有多个参与方,它们拥有各自的数据集,在无可信第三方的情况下,通过计算一个约定函数,要求每个参与方除了计算结果外不能得到其他参与方的任何输入信息.多方安全计算可以实现无可信方场景下的安全计算,但是为了实现隐私保护,需要进行多次传输,通信开销较大.该方法比较适用于小规模实体间的安全计算,对于具有大量用户的深度学习场景的适应性较差.
目前,主流的深度学习隐私保护技术在一定程度上保护了用户的数据隐私,但从本质上来说,数据同样需要离开设备本地,用户失去了对数据的控制权,就会存在隐私风险.且差分隐私技术、同态加密技术和多方安全计算这3种隐私保护技术存在各自的不足,因此研究者开始探索如何实现无需数据收集的学习方案.
1.4 联邦学习
1.4.1 概念与架构
基于数据拥有者对于隐私的高需求,在联邦学习中,服务器不需要用户共享个人的隐私数据,在本地设备上用个人数据训练共享模型即可.联邦学习的体系结构以及训练过程如图7所示.其中参与联邦学习的设备为数据拥有者,每个设备都持有私有数据集,每个设备利用这些数据训练本地模型.所有训练好的本地模型参数发送到服务器中聚合,并更新全局模型.然后服务器再把更新后的全局模型作为新一轮的共享模型发送到参与设备迭代训练,直到训练后的全局模型达到要求.
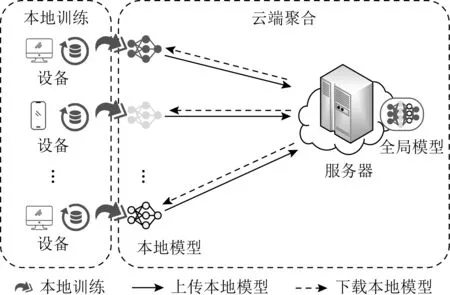
Fig. 7 Classical federated learning structure图7 经典的联邦学习结构
通常来说,联邦学习由多个参与者和一个服务器组成,参与者用来分布式地训练共享模型,服务器用来聚合这些本地模型并给参与者分发任务.联邦学习的训练过程分为3步:
1) 任务初始化.在训练开始之前,服务器首先要确定训练的任务和目标,并选择参与联邦学习的设备,然后把共享模型发送给已选择的设备.
2) 本地训练与共享.每个设备利用私有数据训练本地模型.训练的目标就是找到最佳的本地模型.设备训练完之后把模型参数上传到服务器,进行下一步操作.
3) 全局聚合与更新.服务器收集到来自所有参与设备的本地模型后,进行模型参数聚合.典型的聚合操作是平均算法FedAvg[31],联邦学习服务器通过平均本地模型参数得到下一轮的共享全局模型,目标是找到最佳的全局模型.
这3个步骤将会依次迭代进行,当全局模型收敛或者达到一定的准确率时结束训练.
1.4.2 联邦学习分类
如果要对用户的数据建立学习模型,需要其数据的特征,也必须有标签数据,即期望得到的答案.比如,在图像识别领域,标签是被识别的用户的身份(或实体的类别);在车联网领域,标签是与车辆用户相关的信息等.用户特征加标签构成了完整的训练数据.在联邦学习的应用场景中,各个数据集的用户不完全相同,或用户特征不完全相同.因此,根据数据的不同特点,将联邦学习分为3类:横向联邦学习、纵向联邦学习和联邦迁移学习[32].我们以2个数据集为例,分别介绍3类联邦学习的区别.
1) 横向联邦学习.如图8(a)所示,当2个数据集的用户重叠部分很少,但是用户特征重叠部分比较大时,把数据集横向切分,取出2个数据集中特征相同但来自不同用户的数据进行训练,这种场景下的联邦学习属于横向联邦学习.
2) 纵向联邦学习.如图8(b)所示,当2个数据集的用户重叠部分很多,但用户特征重叠部分比较少时,通过用户的不同数据特征联合训练一个更综合的模型,这种场景下的联邦学习属于纵向联邦学习.
3) 联邦迁移学习.如图8(c)所示,联邦迁移学习是纵向联邦学习的一种特例.当2个数据集的用户重叠部分少,用户特征重叠部分也较少,且有的数据还存在标签缺失时,此时利用迁移学习来解决数据规模小的问题,这种场景下的联邦学习就是联邦迁移学习.

Fig. 8 Three types of federated learning图8 3类联邦学习
这3种类型的联邦学习的共同点都在于保护用户数据的隐私性,区别主要在于用户和数据的重叠性.联邦学习的提出是基于不同用户、数据特征重叠性高的情况,并且目前大部分的研究都是基于横向联邦学习,纵向联邦学习和联邦迁移学习的研究工作暂时比较少.由于不同类型的联邦学习训练与优化机理都相互独立,而在移动边缘网络中部署实现联邦学习旨在利用更多不同的用户和设备来训练模型.因此,本文主要关注的是横向联邦学习的效率优化,本文所提及的联邦学习均为横向联邦学习.
1.4.3 特点与优势
随着数据的急剧增长,集中式的数据中心无法完成巨大的任务量.当单个节点的处理能力无法满足日益增长的计算、存储任务,硬件的提升成本高昂到得不偿失,且应用程序也不能进一步优化的时候,就需要考虑分布式的学习模式.分布式学习是早于联邦学习的用来解决大数据处理的方案,分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统.它的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务,简单来说就是利用更多的机器处理更多的数据.云服务器之外的大量子设备为分布式学习提供了基础,利用分片或者复制集的思想,把任务和数据分配给每一个服务器.虽然分布式学习减轻了云服务器的计算压力,但同时也存在问题.分布式系统中有大量的服务器节点,若其中一个节点出现故障,则整个系统出现故障的可能性就会变大.此外,分片或者复制集都或多或少共享了数据,数据泄露等安全问题无法解决.
与此类似的,在移动设备上基于点对点通信的学习方式[33]相比分布式学习更灵活,但是非主从式的结构使得学习效率低下,设备之间的交互也让用户的隐私面临威胁.联邦学习不同于传统的分布式学习以及点对点通信方式的学习,用户的数据始终保存在本地,在移动设备进行训练,并由服务器统一调控.联邦学习属于主从式的学习方式,服务器与移动设备共同协调,在保护用户数据隐私的前提下,提高了学习的可靠性.联邦学习与传统分布式学习的相关对比见表1.在移动边缘网络中进行多次训练与通信,意味着联邦学习拥有3种特性:
1) 通信环境不稳定.在基于数据中心的分布式训练中,通信环境是较封闭的,数据传输速率非常高且没有数据包丢失.但是,这些假设不适用于在训练中涉及异构设备的联邦学习环境.在通信通道不稳定的情况下,移动设备可能会由于断网而退出.
2) 资源约束.除了带宽限制之外,联邦学习还受到参与设备本身的约束.例如设备可以具有不同的计算能力、CPU性能等.移动设备没有分布式服务器的强大性能,本地训练的效率无法保障,且无法直接进行管理和维护.
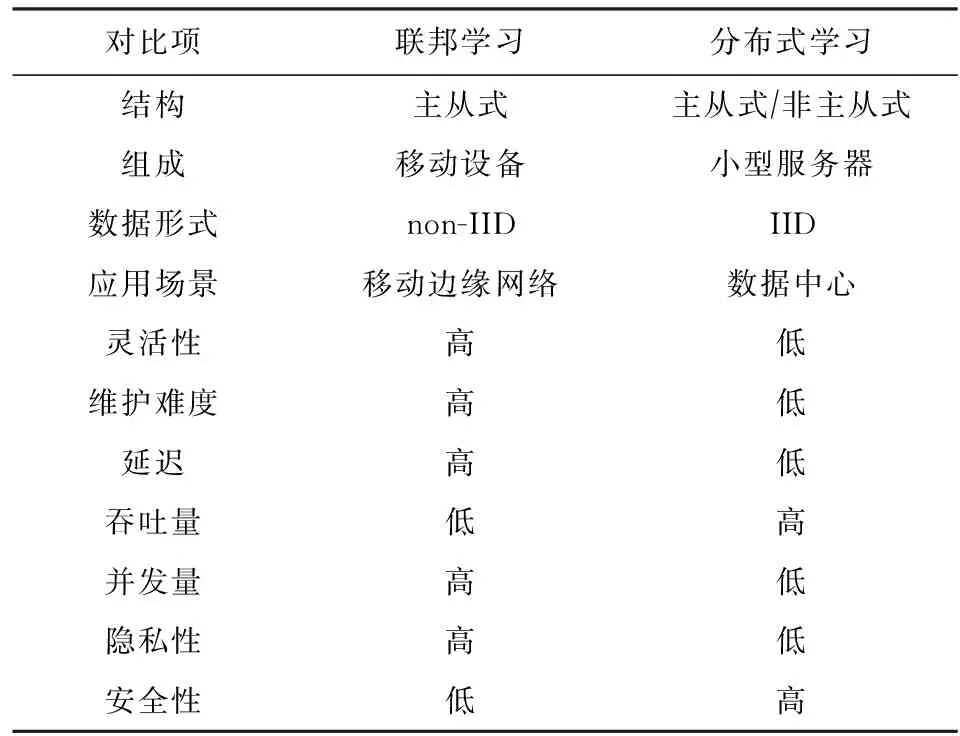
Table 1 Federated Learning Versus TraditionalDistributed Learning表1 联邦学习与传统分布式学习对比
3) 安全与隐私问题.虽然联邦学习不用收集用户的数据,但仍然存在恶意参与者针对模型或系统的隐私侵犯威胁,这很可能泄露用户的隐私.此外,移动设备自身的抗干扰和抵抗第三方攻击的能力较弱,联邦学习系统的安全性容易被破坏.
1.5 联邦学习平台
随着国内外学者的研究,许多适用于联邦学习的开源平台或项目已经研发出来,表2总结了9种目前主流的平台.
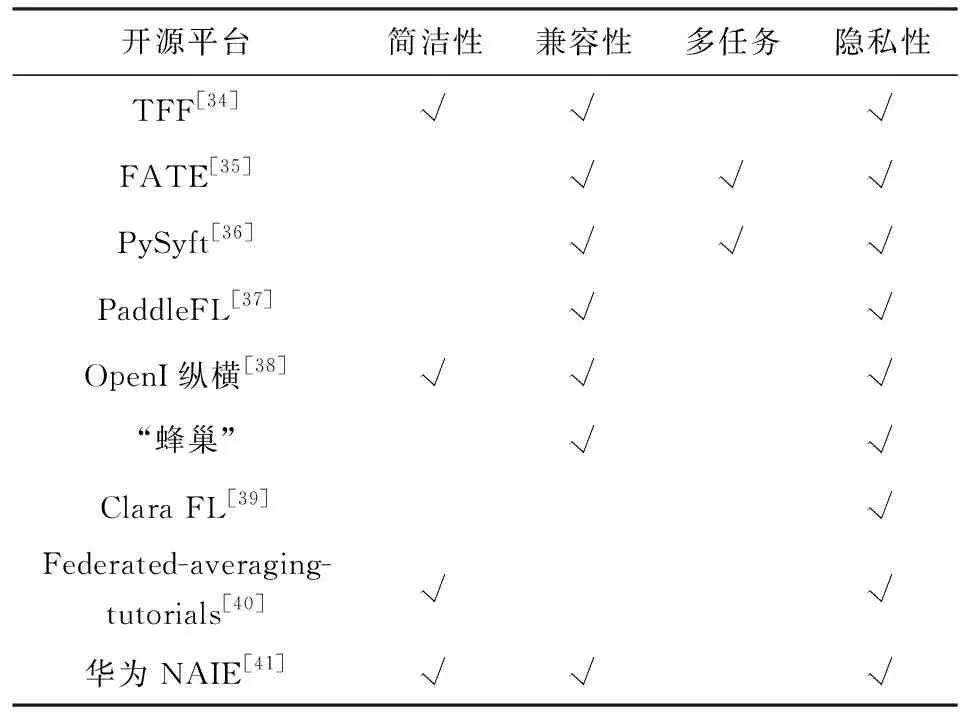
Table 2 Federated Learning Platforms and Their Features表2 联邦学习平台及其特点
1) TFF(TensorFlow federated). TFF[34]是由谷歌开发的一个基于TensorFlow的框架,用于分布式机器学习和其他分布式计算.TFF为2层结构,其中联邦学习层是一个高级接口,允许现有的TensorFlow模型支持并实现联邦学习,用户不必亲自设计联邦学习算法.另一层为联邦核心层,结合了TensorFlow和通信运营商,允许用户自己设计联邦学习算法.
2) 工业级开源框架FATE(federated AI tech-nology enabler).FATE[35]是微众银行AI团队推出的工业级别联邦学习框架,可以在保护数据安全和数据隐私的前提下进行人工智能协作.作为一个工业级的联邦学习框架,FATE项目提供了许多现成的联邦学习算法以及多种加密机制,可以支持不同种类的安全计算.
3) PySyft. PySyft[36]是一个基于PyTorch的框架,可以在不可信的环境中执行加密、保护隐私的深度学习.为了模拟联邦学习,参与者被创建为虚拟工作者,将数据分割并分配给虚拟工作者,并指定数据所有者和存储位置,然后从虚拟工作者中获取模型后以进行全局聚合.
4) PaddleFL.PaddleFL[37]主要是面向深度学习进行设计的,提供了众多在计算机视觉、自然语言处理、推荐算法等领域的联邦学习策略及应用.同时PaddleFL还将提供横向与纵向传统机器学习方法的应用策略,利用开源的FedAvg算法和基于差分隐私的随机梯度下降(stochastic gradient descent, SGD)算法来实现保护隐私的分布式学习,以对分散式的数据集进行模型训练.结合本身在大规模分布式训练的弹性调度能力,PaddleFL在联邦学习领域有非常多的应用场景.
5) OpenI纵横.OpenI纵横[38]是由微众银行、鹏城实验室、香港人工智能与机器人协会以及星云Clustar等共同开发并应用到OpenI启智平台的孤岛数据联邦解决方案.该方案主要关注在满足用户数据安全、法律合规条件下的多方数据使用和联邦建模的问题.OpenI纵横提供了丰富的一站式联邦建模算法组件,可以执行大多数联邦建模任务.
6) “蜂巢”联邦学习平台.该平台由平安科技自主研发,是一个完整的联邦学习智能系统,包括4个功能层级:“蜂巢”数据层、“蜂巢”联邦层、“蜂巢”算法层以及“蜂巢”优化层.依托平安集团在金融科技业务经验的优势,在金融领域做了大量的定向优化工作,例如风险控制和金融安全测试等.
7) Clara FL. Clara FL[39]是一款由英伟达公司开发的用于分布式协作联邦学习训练的应用程序,主要应用于医疗领域,目的在于保护患者的隐私且实现联邦训练.该应用程序面向边缘服务器并部署这些分布式客户端系统,可以实现本地深度学习训练,并协同训练出更为实用的全局模型.
8) Federated-averaging-tutorials[40].该项目是在TensorFlow框架上实现联邦平均算法的一组开源教程,主要的目标是把隐私保护相关技术应用在分布式机器学习算法上.Federated-averaging-tutorials使用Keras深度学习框架作为基础,并提供本地、分布式、联邦平均3种方法来训练TensorFlow模型.
9) 华为联邦学习平台NAIE(network AI engine). NAIE[41]提供了一套自动化的联邦学习服务,实现了一键式从创建联邦实例到管理边缘节点的平台服务.用户只要下载一个客户端就可以轻松加入或退出联邦学习,且平台对联邦学习的整个过程实现了可视化的管理.华为NAIE以横向联邦为基础,内置了众多联邦学习能力,包括联邦汇聚、梯度分叉、多方计算和压缩算法等能力.用户可以通过创建联邦实例来发起众筹式训练,并能够查看训练状态,享受共同训练的成果.华为NAIE联邦学习平台具有联邦实例管理能力、边缘节点管理能力和运行联邦实例能力,后续还将对纵向联邦学习提供支持.
2 联邦学习优化问题
我们在调研中发现设备与服务器之间的通信问题是影响联邦学习效率的主要因素.移动边缘网络层与云服务器之间的距离较远,而联邦学习需要进行多轮训练,这带来了较多的通信时间与成本.此外,在联邦学习过程的3个步骤中,每个步骤都影响联邦学习的训练效率.例如在初始化中,服务器需要选择性能强大的移动设备参加训练,从而加快本地训练与上传的速度;在聚合步骤中,需要控制聚合的频率或内容来提高模型聚合的收敛效果.因此,本节将从通信、训练以及由安全与隐私引起的效率优化问题等方面展开描述联邦学习目前存在的优化问题.
2.1 通 信
传统联邦学习为2层结构,移动设备利用本地数据训练得到本地模型,通过广域网将模型传送到云端服务器.然而参与联邦学习的设备数量成千上万,甚至更多,设备与服务器之间的大量通信必然会占用过多的带宽.同时,设备的信号与能量状态也会影响与服务器的通信,导致网络延迟,消耗更高的通信成本.因此为了提高训练的实时性,联邦学习需要解决通信问题.
2.1.1 边缘计算协调
参与联邦学习的移动设备一般都具有高计算能力的处理芯片,能够在短时间内满足本地训练的要求,所以模型的计算时间往往可忽略不计.然而,每个设备拥有的数据集大小以及分布情况不一致,需要通过多次联邦训练才可能使模型收敛,这就导致联邦学习的通信消耗远大于计算消耗[31].传统联邦学习在高通信效率和高模型性能之间难以平衡,而边缘计算提供了合适的解决方案.利用边缘计算的优势,可以把更多的计算任务卸载到边缘设备.在服务器全局聚合之前,在边缘节点或者移动设备上增加本地训练迭代次数或更多的计算,使本地模型的精度更高,以减少联邦学习的训练轮数.此外,在训练优化中使用更合理的模型聚合方式或更快速的模型收敛方法,也可以减少通信次数.
2.1.2 模型传输消耗
联邦学习大多是通过训练复杂的模型来实现最终的目的,一个复杂的模型可能包含上百万个参数[42],在网络中传输高维度的模型参数也会消耗更多的通信资源.为了减少分布式训练带来的通信开销,模型压缩是一种解决方法[43].利用梯度量化和梯度稀疏化技术,将带有数百万参数的模型转化为一个简单的、能保证训练质量的模型.梯度量化通过将梯度向量的每个元素量化为有限位的低精度值来对梯度向量进行有损压缩,而梯度稀疏化是通过选择性地传输部分梯度向量来减少通信消耗[44].文献[45]观察到分布式梯度下降方法的参数优化过程中存在99.9%的梯度交换是冗余的.基于这一观察结果,文献[45]的作者提出了深度梯度压缩(deep gradient com-pression, DGC),并且在对CNN和RNN进行了大量实验后,证明了模型梯度压缩在效果上是可行的.
2.2 训 练
联邦学习的本地训练与常规深度学习训练过程类似,而联邦学习中存在的异构计算资源、模型聚合以及数据质量是影响其训练效率的关键.
2.2.1 移动设备异构
联邦学习协议[46]如图9所示.在每一轮训练开始之前,都要选择设备来加入联邦训练.传统方案中,服务器会随机选择一组设备作为参与者,把共享模型发送到这些设备进行训练,然后服务器需要收集这一轮所有设备的本地模型来更新全局模型[31].这意味着,联邦学习整体的训练过程受到训练时间最长的设备的影响.
在包含无数设备的网络中,每个设备的性能、网络状态和能量都不一样,导致每个设备训练模型的时间也不一样.同时,除了设备在硬件上的差异之外,每个用户的使用情况也不一样.例如有的用户只有在连入了无线网络的情况下才愿意接受联邦训练[47].因此,为了解决这一问题,相关研究者已经研究出新的联邦学习参与者选择协议,在联邦学习初始化时,评估每个设备的资源状态,通过解决参与设备的资源约束问题来减少本地训练的时间,从而提高联邦学习训练的效率.

Fig. 9 Communication protocol of federated learning[46]图9 联邦学习通信协议[46]
2.2.2 服务器聚合频率
在边缘计算环境下实现分布式地训练深度学习模型,通常都是采用先局部后集中的方法.联邦学习训练过程中本地模型训练完成后,这些模型参数就被传递到联邦学习服务器进行聚合.在这种情况下,服务器如何控制模型的聚合更新,显然会影响联邦学习的训练效率.聚合控制的过程包括聚合的内容(即本地模型参数)和聚合的频率.图9中处理全局聚合的传统方法是同步方法,即聚合操作在固定的时间间隔进行,模型的训练受到最坏设备的约束.
另一种选择性聚合可以控制联邦学习服务器聚合的内容.大量的设备在不安全的边缘网络中训练模型,模型参数冗余或遭到恶意篡改的可能性很大[48],这些不可用的模型参数会大大降低全局模型的准确率.因此,尽可能聚合正确的本地模型可以大大提高联邦学习的训练效率.
2.2.3 数据质量
在联邦学习过程中,移动设备上数据集的非独立同分布(non-independent and identically distributed, non-IID)问题是影响联邦学习训练效果的重要因素.同分布性意味着数据没有总体趋势,分布不会波动,样本中的所有数据都取自同一概率分布.独立性意味着样本都是独立的事件,没有任何关联.传统的分布式深度学习,云服务器将收集到的数据集划分为若干个子数据集,这些子数据集被发送到各个分布式节点进行训练.这样,即使是较小的数据集,同样能代表总体分布,训练出的模型在准确率上没有差别.然而,这种方式不符合联邦学习,并且假设每个移动设备上的本地数据符合独立同分布(independent and identically distributed, IID)原则也是不现实的.具体来说,有2个原因:
1) 违背独立性原则.如果设备上的数据生成或收集不够随机.例如,数据是按时间排序的,则违背了独立性原则.此外,同一地理位置内设备的数据可能具有一定程度的关联,同样违背了独立性原则.
2) 违背同分布性原则.由于移动设备与特定地理区域相关联,标签的分布因分区而异.此外,由于设备存储能力的不同,本地数据量也不同,所以违背了同分布性原则.因此,联邦学习中的数据集属于non-IID.
文献[31]提出FedAvg算法以缓解non-IID数据带来的影响.但随着技术研究的深入,该算法并不完全适用.因此,为了提高联邦学习的学习效率以及收敛速度,解决移动设备上数据的non-IID问题是非常关键的.
2.2.4 模型收敛
通常来说,如果模型具有较快的收敛速率,则在联邦学习过程中可以节省参与设备训练所需的时间和资源消耗,能够极大地提高联邦学习的效率.以一个简单的神经网络模型fθ(x)的优化为例,训练的过程就是找到一个最优的模型参数使得模型预测值与样本标签真实值之间的损失最小,此时模型达到收敛.用数学表达式表示为:
(1)
其中,θ为神经网络模型的权重参数,为损失函数,(xi,yi)为n个样本中的第i个样本.

(2)
由于GD每次都要对所有样本计算梯度,造成了冗余计算.因此,随机梯度下降(stochastic gradient descent, SGD)通过随机选择样本进行梯度计算从而提高计算效率.SGD的优化目标通过式(1)可得到式(3):
(3)
其中,B为样本批量的数量.同样地,在第t次的训练中随机选择第i个样本批量来计算梯度,而无须计算所有的样本,SGD的数学表达式为
(4)
然而,SGD方法可能在优化过程中产生左右振荡的情况.为了加快模型的收敛速率,文献[49]提出通过考虑更多先前的迭代来提高GD的收敛速度.因此,考虑了动量梯度下降法(momentum gradient descent, MGD)以加速模型收敛[50].具体来说,MGD像传统GD一样计算梯度,但是不直接用计算出的梯度进行参数更新,而是赋予当前梯度一个权值,并综合考虑之前的梯度得到一个加权的平均值,再进行参数更新.MGD在第t+1次的参数更新为:
(5)
θt+1=θt-ηtd(t+1),
(6)
其中,d(t)是动量项,γ是衰减因子.由于基于动量的梯度方法能改进模型的收敛速率,在分布式机器学习领域中有一些将动量项应用于SGD优化的工作.例如在文献[51]中,动量应用于每个聚合回合的更新,以改善优化和泛化.在文献[52]中,证明了带有动量的分布式SGD的线性收敛性.
文献[53]提出了一种新的动量联邦学习(mom-entum federated learning, MFL).该文作者在联邦学习的本地更新中引入动量项,并利用MGD执行本地迭代.理论证明了所提出的MFL的全局收敛性,并推导了MFL的收敛边界.与传统联邦学习相比,提出的MFL具有更快的模型收敛速度.
联邦学习不同于传统深度学习,由于设备上的数据属于non-IID,导致本地模型训练的质量不一致,在验证集上的损失可能超出估计值,这也是影响联邦学习模型收敛的主要因素.文献[54]提出了可以自适应调整的FedProx算法,它对损失函数进行了修改,包括一个可调节的参数,该参数限制了本地更新对初始模型参数的影响程度.当训练损失增加时,可以调整模型更新以减小对当前参数的影响.
同样地,文献[55]提出的LoAdaBoost FedAvg算法,在参与设备训练完本地模型后,将交叉损耗与前一轮训练的中值损耗进行比较.如果损失较大,则在聚合之前对本地模型再次进行训练,以提高学习效率.实验证明该算法具有较快的收敛速度.更多优化联邦学习non-IID问题的解决方案在3.2节中进行详细的讨论.
2.3 安全与隐私
与集中式学习相比,联邦学习的环境不可控,来自恶意设备的攻击成为主要的隐患.研究表明,恶意的攻击者仍可以根据其他参与者的共享模型来推断用户相关的隐私信息(例如生成式对抗网络攻击、模型反演攻击等),并且精度高达90%[56-57].这种攻击也可以成功地从各种训练模型中提取模型信息[58].此外,联邦学习中也存在许多安全威胁,例如中毒攻击,这也会导致联邦学习的训练效率瓶颈.联邦学习中的中毒攻击可分为2类:
1) 数据中毒.在联邦学习中,设备使用本地数据进行模型训练,并将训练后的模型发送到服务器以进行进一步处理.在这种情况下,服务器难以确定每个设备的本地数据是否真实.因此,恶意参与者可以通过创建脏标签数据来训练模型,以产生错误的参数,降低全局模型的准确性.文献[59]研究了联邦学习中的基于标签反转的数据中毒攻击,攻击者使用与其他参与者相同的损失函数和超参数训练的本地模型,利用标签反转污染数据集.实验表明攻击成功率、效率随中毒样本和攻击者数量呈线性增加.
2) 模型参数中毒.另一种比数据中毒更为有效的攻击是模型中毒攻击[60].对于模型中毒攻击,攻击者可以直接修改模型的参数,该模型直接发送到服务器以进行聚合.相比数据中毒,即使只有一个模型中毒攻击者,也能迅速降低全局模型的精度.
安全与隐私问题除了破坏模型的训练精度,更严重的是导致用户不再信任联邦学习服务器,用户将不愿意参与共同训练,而过低的设备参与率导致全局模型的性能低下,甚至造成模型收敛的瓶颈.为了提高模型训练的效率与精度,需要结合相关隐私与安全机制,解决针对联邦学习环境的安全与隐私问题,提高模型的稳定性与用户的参与度,为高效的联邦学习提供可靠环境.
3 现有优化研究方案
第2节讨论了当前联邦学习存在的优化问题,本节将详细介绍与分析目前针对联邦学习效率优化的相关研究与技术方案.通信效率的研究主要为解决在基于云或基于边缘的环境中实现联邦学习带来的通信时间与负载的问题.而训练优化是对联邦学习训练的每个步骤进行优化,包括参与设备选择与协调、模型聚合控制.此外,还针对数据质量问题,总结了联邦学习收敛优化等相关的研究方案.最后列举了通过保护联邦学习安全与隐私从而提高模型性能的方案.
3.1 通信优化
3.1.1 增加边缘端的计算
为了减少由多轮通信带来的通信消耗,文献[31]提出2种方法来增加设备上的计算量:1)增加任务的并行性,通过在每一轮选择更多的设备参与联邦训练来减少训练的轮数;2)增加设备的计算,即在全局聚合更新之前,在每个设备上执行更多的训练任务.因此,文献[31]的作者提出了一种基于平均迭代模型的深度神经网络联邦学习的FedAvg算法,考虑了不同的模型体系结构和数据集,进行了广泛的实验评估.根据联邦学习的规则,每轮随机选择的设备训练出来的本地模型精度都不相同,FedAvg算法对这些模型参数进行平均操作.具体来说,文献[31]的作者定义了联邦学习的优化问题,将式(1)的深度学习优化问题改写为
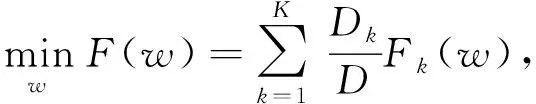
(7)
(8)
其中,f(w)为损失函数,w为模型参数,K代表参加训练的设备数量,数据样本总量为D,pk代表设备k拥有的数据集,其大小为Dk=|pk|.该文作者首先分析了目前主流的SGD优化方法,并将其直接应用于联邦学习,即每一轮训练在设备上进行一次梯度计算,对于每个设备k有
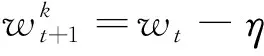
(9)
(10)
其中,t表示当前联邦学习的训练轮数.传统SGD的计算效率虽然很高,但是需要进行大量的训练轮数才能得到好的模型.为了让每个设备执行更多的计算以减少通信,FedAvg算法将本地的一次梯度计算改进为多次,即设备进行多次本地训练:
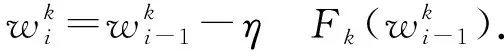
(11)
此外,算法还设置了超参数C,E,B.其中C表示每一轮选择设备的比例;E表示设备上本地迭代的次数;B表示设备训练的本地数据批量大小.通过调整这些超参数的值来增加设备端的计算量,从而使本地模型的精度更高.本地训练之后,对所有的本地模型进行平均得到更新后的全局模型,并将其作为新的初始模型发送给下一轮训练的设备,算法1完整地表示了FedAvg的细节.根据仿真实验结果,FedAvg算法的通信轮数减少到SGD算法的1/30,也证明了当模型精度达到一定的阈值时,增加计算量并不会带来额外的通信消耗.
算法1.FedAvg.
输入:设备数量K和选择比例C、本地数据批量大小B、本地迭代次数E、学习率η;
输出:模型参数w.
服务器端:
① 初始化全局模型w0;
② 确定需要选择设备的数量m←max(C×K,1);
③ 服务器随机选择m个设备并下发全局模型;
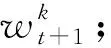
⑤ 利用式(10)全局聚合;
⑥ 重复②~⑤直到模型w收敛,其中t为轮数.
设备端(k,w):
① 将本地数据集pk划分为大小为B的样本批量;
② 对于B中的样本用式(11)进行权值更新;
③ 重复E次步骤②;
④ 将训练好的本地模型w发送到服务器端.

Fig. 10 AlexNet model based on two-stream federated learning[61]图10 基于双流联邦学习的AlexNet模型[61]
虽然FedAvg算法已经广泛用于联邦学习的研究,但是在non-IID数据集上的效果不明显,会带来更多的训练轮数与通信消耗.文献[61]基于文献[31]的思想,为了增加每个参与设备的计算量,提出了带有最大平均偏差(maximum mean discrepancy, MMD)的双流联邦学习模型.MMD用来测量数据分布均值之间的距离.例如,给定数据分布ρ1和ρ2,则MMD可用数学表达式表示为
ZMMD(ρ1,ρ2)(E[φ(ρ1)]-E[φ(ρ2)])2,
(12)
其中,φ(·)表示映射到再生核希尔伯特空间.
文献[61]的作者认为全局模型包含来自多个设备的信息,有利于本地模型的训练.如图10所示,双流联邦学习算法与传统FedAvg对比,可以使参与设备在每一轮的本地训练中保留全局模型作为参考,除了训练本地数据之外,还参考全局模型从其他设备中学习.具体来说,双流模型在本地训练中,通过最小化全局模型与本地模型之间的损失来保证设备学习到其他设备数据之外的特征,从而加快模型收敛的进程,减少通信的轮数,计算公式为:
(wk|w,Xk,Yk)=cls+MMD,
(13)
(14)
MMD=λZMMD(w(Xk),wk(Xk)),
(15)
其中,X,Y分别表示样本(xi,yi)的数据与标签,表示全局模型与本地模型之间的损失,J为模型分类损失,λ为系数.在实验中,文献[61]的作者使用CNN模型在CIFAR-10和MNIST数据集上进行了评估.结果表明,即使参与设备上的数据是non-IID形式的,提出的双流模型算法也可以在少于20%的通信轮数的情况下,使联邦学习的全局模型达到理想的精度,优于传统的方案.
目前,联邦学习的方案大多数是基于服务器与设备之间的2层结构.长距离的通信与交流显然会带来更多的通信成本,将服务部署在边缘服务器成为一种解决方案.例如,文献[62]将深度强化学习技术和联邦学习框架与移动边缘系统相结合,以对MEC、缓存和通信进行优化.为了更好地利用设备和边缘节点之间的协作交流,加快模型训练和模型推理,文献[62]的作者设计了一个“In-Edge-AI”框架,从而实现动态的优化和增强效果,同时减少不必要的系统通信负载.此框架通过深度强化学习来共同管理与优化边缘通信和计算资源,并通过联邦学习来分布式地训练深度强化学习代理.
文献[63]的作者认为,联邦学习反复地训练会带来巨大的通信延迟,同样基于边缘智能的理念,引入了MEC平台作为联邦学习的中间层.该文作者提出了一种分层的联邦学习架构用来减少用户和云之间的通信轮数.此外,还提出了HierFAVG分层联邦学习平均算法.该算法与FedAvg相比,利用边缘层节点的计算能力,在联邦学习服务器全局聚合前,使边缘服务器聚合多个设备的本地模型,以减少设备的通信连接次数.文献[63]的作者对比了基于云和基于边缘的联邦学习框架,如图11所示.基于云的联邦学习服务器需要与每个设备进行远程通信连接,并且频繁的通信连接会消耗大量的网络带宽资源.而完全基于边缘服务器的联邦学习虽然通信距离缩短了,但边缘服务器的计算性能不如强大的云服务器,在计算时延上有所妥协.可以看出基于边缘的分层联邦学习与云服务器的通信连接次数更少,并且保留云服务器的计算资源,在减少与云通信的同时,系统的计算性能也得到了保障.仿真结果表明,HierFAVG算法利用更多边缘服务器进行边缘聚合,比传统FedAvg算法在云中统一聚合方案的通信开销更少,但是应用在non-IID数据上,模型还达不到期望的效果.
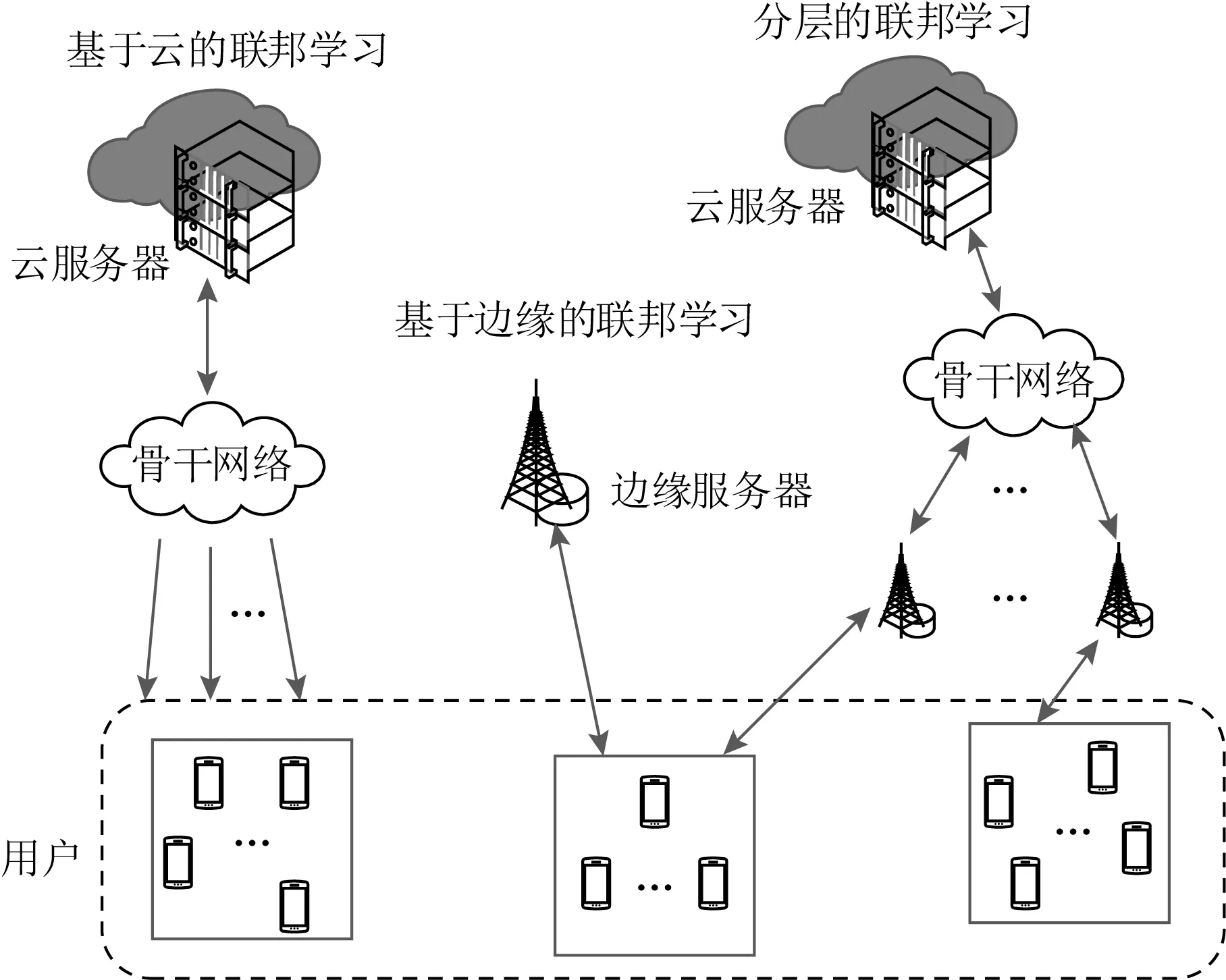
Fig. 11 Cloud-based versus edge-based federated learning[63]图11 基于云与基于边缘的联邦学习框架对比[63]
3.1.2 模型压缩
为了解决传输复杂模型带来的过多通信消耗,文献[64]在FedAvg算法的基础上进行了调整,结合分布式的Adam优化形式和新型压缩技术,提出了基于通信效率的CE-FedAvg算法.该文作者通过结合均匀量化和指数量化2种方法来减少每轮训练上传的总数据量与通信的次数,并且对不同数量的设备设置IID数据与non-IID数据,通过大量实验测试了设备的参与率和压缩率.结果表明,当模型收敛时,CE-FedAvg的通信轮数仅为FedAvg的通信轮数的1/6.CE-FedAvg的优势在于能够以更少的通信轮次来使模型达到收敛,同时压缩了上传的数据,大大减少了通信损耗.此优化方案在FedAvg算法的基础上加入了压缩与量化的思想,从而减少联邦学习传输过程中的通信消耗.
文献[65]提出了一种将模型剪枝与联邦学习相结合的方法,目的就是压缩模型的大小来降低传输时的通信成本.剪枝包括在服务器上对初始模型剪枝和在设备上对本地模型的剪枝,其他部分与传统的联邦学习过程保持一致.模型剪枝[66]就是删除一定剪枝率的最小绝对值权值,当模型训练和剪枝同时反复进行后,最终会得到一个小尺寸的模型.
如图12所示,在服务器上对初始模型剪枝后,根据联邦剪枝需要,进一步再对聚合后的全局模型进行剪枝以删除小幅度的权重值,直到模型的大小达到所需的修剪水平.文献[65]的作者通过复杂性分析和大量的模拟与真实实验,证明了该方法可以大大降低通信和计算的负载.该文作者还讨论了在各种条件下模型剪枝的效果,例如在不同类型的优化方法上对联邦学习模型剪枝的影响.

Fig. 12 Model pruning图12 剪枝模型
文献[47]为了降低联邦学习上行链路的通信消耗,基于模型压缩的思想提出了结构化更新和概略化更新2种方法.结构化更新的目的是使本地模型在具有较少变量的有限空间结构(例如低秩或随机掩码)上进行更新与训练;概略化更新指的是在与服务器通信之前,结合量化、随机旋转与子采样等压缩形式对模型进行编码,然后在服务器聚合之前对模型解码的方法.实验结果表明,结构化与概略化更新可以将通信成本降低2个数量级.同时,在损失一定精度的条件下,可以实现更高的压缩率和更快的收敛速度.
文献[67]认为设备和云服务器之间的梯度和参数同步是影响通信成本的重要因素.因此,该文作者提出了一种基于边缘随机梯度下降(edge stochastic gradient descent, eSGD)的方法,以扩大CNN的边缘训练.eSGD是一组具有收敛性和实际性能保证的稀疏方案.首先,eSGD确定哪些梯度坐标是重要的,并且只将重要的梯度坐标传输给云进行同步.这个重要的更新可以大大降低通信成本.其次,使用动量残差累积来跟踪过期的残差梯度坐标,以避免稀疏更新导致的低收敛速度.实验表明,在梯度下降比分别为50%,75%,87.5%的时候,该算法在MNIST数据集上训练的准确率分别为91.2%,86.7%,81.5%.该方案利用了梯度稀疏化等技术,减少了边缘到云传输的数据量,从而减小通信消耗.
文献[68]提出了2种技术来减少联邦学习中的通信开销.一种是在服务器到设备之间的通信中使用有损压缩技术;另一种是使用联邦Dropout技术,即向每个设备传递全局模型的子模型.在有损压缩过程中,首先将模型中每个要压缩的权值矩阵重构成向量形式,然后进行基础变换、子采样和量化操作.此时的模型大小已经比原始模型小,为进一步减少通信消耗,该文作者通过联邦Dropout在模型的全连接层将固定数量的激活向量丢弃,从而得到一个简化的子模型.如图13所示,具体过程为:①通过联邦Dropout构造子模型;②有损压缩结果对象,压缩了要进行通信的模型大小;③将这个压缩模型发送给设备,设备使用本地数据对其进行解压和训练;④压缩最后的更新;⑤这个更新被发送回服务器进行解压;⑥聚合到全局模型中.文献[68]的作者在常用的数据集上进行了大量的对比实验,结果表明在不影响模型质量的情况下,该通信策略大大减少了服务器到设备的通信,节约了本地计算资源以及模型上传时产生的通信延迟.

Fig. 13 A compression process that combines two technologies[68]图13 结合2种技术的压缩过程[68]
现有的压缩技术多数只有在理想条件下表现良好,例如设备上数据的分布是均衡的,对于non-IID数据的模型收敛性不能保证.为了解决基于模型压缩的通信友好但收敛效果差的问题,文献[69]的作者通过对比实验,发现在现有的压缩算法中,top-k稀疏化算法对于联邦学习模型的收敛影响最小,因此提出了一种新的压缩框架——稀疏三元压缩(sparse ternary compression, STC).STC扩展了现有的top-k梯度稀疏化压缩技术,并提供了一种新的机制,实现对权值更新的分层与最优格伦布编码[70].实验表明,STC的性能明显优于FedAvg算法,STC方案下的联邦学习在训练迭代次数和通信比特数方面的收敛速度都快于FedAvg.因此,该方案适用于设备与服务器之间低延迟和低带宽的联邦学习环境.
3.1.3 归纳总结
本节主要从增加端设备的计算量、模型压缩2种策略来讨论降低联邦学习的通信消耗的方案,在表3中总结了这些方法.
联邦学习把训练任务分散到每个移动设备上,服务器与设备之间的通信消耗是影响训练的首要因素.研究者通过云端协作与云边端协作的方式,结合MEC等边缘计算平台,将更多的计算卸载到边缘或设备端,以减少训练轮数.从表3中可以看出,目前通信优化的方案大部分是基于云端2层结构的协作,然而,云服务器与移动设备的距离较远,当参加训练的设备数量很大时,带宽的限制与通信延迟仍是一大挑战.
此外,丢弃部分冗余的梯度或压缩模型也是降低通信时延和负载的方法.然而,许多通过压缩技术来降低通信消耗的方案会带来其他方面的不利影响,例如模型剪枝可以丢弃不必要的数据以达到减少传输量的目的,但是,这些数据或多或少都与模型的收敛相关,模型的精度在一定程度上会受到影响.表3的方案还存在一些不足,大部分支持通信效率的研究方案在面对分布式机器学习带来的数据质量问题时并不能很好地适用,只是在数据分布理想的状态下保证了通信的效率和模型的收敛.因此,设计权衡通信消耗与模型收敛的算法来提高联邦学习整体的效率仍然是重要的研究点.

Table 3 Summary and Comparison of Researches on Federated Learning Communication Optimization表3 联邦学习通信优化研究方案的总结与对比
3.2 训练优化
3.2.1 设备选择
在文献[31]中,为了使联邦学习训练效果达到最佳,该文作者提出最大化选择参与设备的方法.但是,文献[71]的作者认为在某些设备计算资源有限或无线信道条件差的情况下,会导致联邦学习需要更长的训练时间和上传时间.因此,为了解决这个问题,文献[71]的作者提出一种新的联邦学习协议,称之为FedCS.该协议基于MEC框架,根据设备的资源状况动态地选择设备参与并有效地执行联邦学习.FedCS协议解决了带有资源约束的设备选择的问题,允许服务器尽可能多地聚合来自设备的模型更新.

Fig. 14 Protocol of FedCS[71]图14 FedCS协议[71]

ϑi
(16)
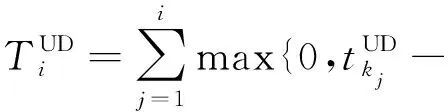
(17)
(18)
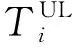

(19)
则认为该设备集S中存在资源受约束的设备,需要重新通过计算来选择一组更好的设备.
文献[71]的作者在MEC环境中使用ClFAR-10图像数据集进行了实验评估,实验结果表明,与传统的联邦学习协议相比,FedCS协议通过对具有不同约束的设备进行选择,使联邦学习能够在预期的时间内完成训练过程.然而,FedCS仅在简单的模型上进行了测试.当扩展到更复杂的模型上或者面对数量庞大的设备集时,不断计算设备的时间会带来额外的负载与计算时延,并且FedCS协议不关注模型聚合的精度,对于数据non-IID问题不能完全适用.
在此基础上,文献[72]提出一种基于多标准的联邦学习设备选择方法,并预测设备是否能够执行联邦学习任务.特别是在每一轮中,该选择算法中的设备数量都最大化,同时考虑到每个设备的资源及其完成训练和发送所需更新的能力.
文献[73]假设一些设备是可用的,而另一些设备为脱机或超出通信范围.基于这个假设提出一个启发式算法,在保证模型的测试精度的前提下选择最佳的设备参加训练,从而解决了当设备达到预算的目标数量时优化模型准确性的问题.文献[74]为长期处在能量约束下的联邦学习设备选择和带宽分配制定了一个随机优化问题,并设计了一种仅利用当前可用无线信道信息但可以实现长期性能保证的算法.文献[75]从最小模型交换时间的角度研究联邦学习中的设备选择方案,并使用动态队列量化设备的参与率.
3.2.2 资源协调
一般情况下,移动边缘网络环境是动态的、不确定的,设备所拥有的资源时刻都在变化,例如无线网络和能量等条件都会影响联邦学习的训练.为此,文献[76]考虑了基于移动群体机器学习(mobile crowd-machine learning, MCML)的联邦学习模型.同样地,MCML使边缘网络中的移动设备能够协同训练服务器所需的DNN模型,同时将数据保存在移动设备上,解决了传统机器学习的数据隐私问题.为了解决动态网络环境中资源的限制,同时将能耗、时间和通信的成本最小化,服务器需要确定设备用于训练的适当数据量和能量.为此,文献[76]的作者采用基于双深度Q-Network[77]的算法,允许服务器在不具备任何网络动态先验知识的情况下学习并找到最优决策.具体来说,为了使联邦学习长期累积的回报最大化,服务器在给定状态s的情况下确定最优的决策a.基于Q-learning构造了一个最优策略的状态-动作查询表Q(s,a),并通过以下方式进行更新:
Qnew(s,a)=(1-η)Q(s,a)+η(r(s,a)+γmaxQ(s′,a′)),
(20)
(21)
其中,γ是衰减因子,r(s,a)是回报函数,G,H,I分别代表累积的数据、训练延迟与能量消耗,α是比例因子.根据查询表,服务器可以从任何状态找到对应的最佳决策,使整个系统的能耗与成本最低.然而,Q-learning受到服务器的大规模状态和动作空间的困扰,为此采用深度Q-learning为服务器找到最优策略.实验结果表明,该算法在能量消耗和训练延迟方面均优于静态算法;与贪婪算法相比,该方案能减少31%左右的能量消耗;与随机方案相比,训练延迟减少55%左右,大大提高了联邦学习的效率.
文献[78]的作者认为,现有的联邦训练和推理结果可能会偏向个别设备,即本地训练中模型损失最高的设备将会主导整个全局模型的损失,意味着在进行模型推理时不利于其他设备.因此,提出了一个不可知的联邦学习框架.该文作者证明该框架会使联邦学习产生公平的训练效果.此外,该文作者还提出了公平联邦学习(q-fair federated learning,q-FFL)资源分配的优化目标,通过这个目标可以动态地为每个本地模型分配不同的权重,即
(22)
其中,q为公平性参数.当q=0时,该优化目标相当于传统联邦学习的目标,如式(23)所示;当q的值较大时,说明此本地模型的损失较大,需要优化此本地模型以减小训练精度分布的方差.
(23)
为了解决q-FFL问题,文献[78]的作者相应地设计了一种适合于联邦学习的高效率方案q-FedAvg,对传统FedAvg算法中的目标函数进行重新加权,将较高的权重分配给损失较大的设备,整体的优化目标就偏向本地经验风险较大的设备.实验证明了该方案在公平性、灵活性和效率方面均优于现有方案.
考虑到无线信道的资源分配问题,文献[79]提出了一种基于空中计算的带宽模拟聚合技术(broad-band analog aggregation, BAA)的联邦学习框架.图15(a)表示传统的多址通信系统,其中不同线型表示相互正交的通信信道.为了避免传输节点间的相互干扰,每个节点都需要通过某种多址方式来实现在不同信道同时传输,在接入点再恢复每个节点的数据进行计算.当节点数目增多且无线资源有限时,计算等待时延将会大大增加.相反,图15(b)所示的空中计算将所有发送节点并发传输,接入点直接计算数据,只需一次信道使用,大大节省了带宽资源.

Fig. 15 Air computing versus traditional multiple access communication图15 空中计算与传统多址通信对比
文献[79]的作者利用了多址信道的波形叠加特性,实现了设备同时占用全部带宽的传输.与此同时,BAA考虑了衰落信道模型,通过信道翻转对移动设备发射功率进行控制,同时限制了信道质量差的设备的传输,以减少通信延迟,同时在一定程度上减少了传输的数据量.作为延伸,在文献[80]中还引入了除空中计算外的误差累积和梯度稀疏化.为了提高模型精度,未经扫描的梯度向量可以首先存储在误差累积向量中,在下一轮中使用误差向量校正局部梯度估计.另外,当存在带宽限制时,参与设备可以应用梯度稀疏,以确保更新幅度大的参数进行传输.
文献[81]还提出了一种高效节能的带宽分配和调度策略,用来降低设备的能耗.该方案一方面适应设备的信道状态和计算能力,从而在保证学习性能的同时降低总能耗.与传统联邦学习的时间优化设计相比,该策略将更多的带宽资源分配给那些信道较弱或计算能力较差的调度设备.另一方面,封闭式的调度优先级函数对具有更好的信道状态和计算能力的设备具有优先偏向.实验证明了所提出的策略能够降低大量的能耗,同时保证了模型训练的速率.文献[82]针对边缘计算环境中的联邦学习,引入了带宽切片来支持联邦学习,以保证训练带宽的低通信延迟.带宽切片可以保留专门用于学习任务的网络资源,打破了在训练过程中落后设备带来的瓶颈.
3.2.3 聚合控制
传统的FedAvg算法,模型的全局聚合是在收集到所有设备上的本地更新后再进行的,虽然可以通过对参与设备的选择与协调来加快联邦学习的进程,但是同步聚合总是会受到最后一个上传模型的设备的影响.对此,为了加快全局模型聚合和收敛,文献[83]提出一种新的异步联邦学习算法,只要设备的本地训练完成,即可上传本地模型.
图16对同步联邦学习与异步联邦学习进行了对比.该异步模型允许参与设备在联邦学习训练过程中,只要训练完本地模型就可以立即上传到服务器进行聚合,而无须等待所有设备都上传完毕后再聚合.文献[83]的作者还发现,异步联邦学习模型对于在训练时中途加入的设备具有鲁棒性,不会影响训练效果.通过对联邦同步学习和异步学习的对比实验,证明了异步学习模型的训练效果更好.然而,在non-IID数据集上模型的准确性依然存在不足.
为了更好地管理动态资源约束,实现全局最佳聚合,文献[84]的作者基于梯度下降的训练方法,提出了一种自适应的全局聚合方案.该方案改变了全局模型的聚合频率,从而在保证联邦学习训练过程中有效利用可用资源的同时,保证了模型的性能.该文作者还认为当服务器聚合模型总数和聚合间隔之间的本地模型的总数不同时,训练损失是随之受到影响的.为此,提出了一种基于最新系统状态自适应选择最优全局聚合频率的控制算法,该算法能够确定本地更新和全局参数聚合之间的最佳折中,以在给定资源预算下将损失函数最小化.例如,如果全局聚合耗费大量时间,那么在与联邦学习服务器的通信之前,会进行更多的边缘聚合.仿真结果表明,在相同的时间预算下,自适应聚合方案在损失函数最小化和精度方面都优于固定聚合方案.
文献[85]提出了一种提高联邦学习通信与训练效率的模型选择性聚合算法CMFL(communication-mitigated federated learning).关键思想是识别和排除有偏差的、与全局收敛不相关的本地更新.首先用式(24)证明了连续的全局模型wt和wt+1之间的归一化差值很小,即
(24)
基于这一结果,提出CMFL方案根据参与设备的本地更新与所有参与的设备协作生成的全局更新的一致性来度量设备上的本地模型参数的相关性,即比较本地更新与全局更新中模型参数的符号.具体来说,CMFL设置了一个可调的阈值来识别和排除不相关的更新.假设本地模型w具有N个模型参数u1,u2,…,uN,全局模型w*具有N个模型参数g1,g2,…,gN.若本地模型与全局模型参数符号相同的比例大于这个阈值,则认为本地模型是相关的,反之则不相关,即:
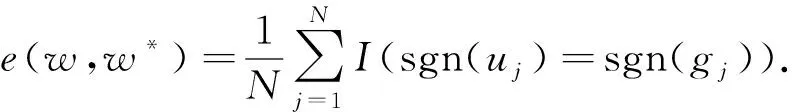
(25)
当模型的参数符号相等时,设置I(·)=1;否则I(·)=0.若e大于阈值,则保留该本地模型并上传到服务器中聚合,反之丢弃.从理论上证明了CMFL是收敛的,并通过与现有解决方案相比,证明了CMFL可以显著地减少网络通信带宽的占用,排除不相关的本地模型后全局模型聚合的收敛程度也得到提高.在联邦多任务学习场景下,CMFL方案提高了5.7倍的通信效率和4%的模型预测精度.
通过对联邦学习通信优化的讨论,可知有限的通信带宽是聚合本地模型更新的主要瓶颈.为了加快联邦学习全局聚合的速度,文献[86]提出了基于空中计算的快速全局模型聚合方法.该方法通过设备选择和波束成形设计来实现,能够在满足模型聚合的均方误差要求下最大化所选参与联邦学习的设备数量.该文作者利用稀疏和低秩优化来提升该方法的性能.考虑到现有算法在稀疏和低秩优化中的局限性,该文作者使用凸差函数(difference-of-convex-functions, DC)表示稀疏低秩函数,并在设备选择过程中准确地检测出固定秩约束.为了进一步改进DC算法,将DC函数重写为强凸差函数,更优化了DC算法的全局收敛速度.实验结果证明了所提出的DC方法的可行性,在CIFAR-10数据集上训练的支持向量机分类器可以实现更高的预测精度和更快的收敛速度.
3.2.4 数据优化
数据的non-IID是影响联邦学习模型训练效果主要的因素.文献[87]指出如果使用non-IID数据训练CNN模型,则FedAvg的准确性将大大下降.对于MNIST数据集,模型下降的准确率可达11%;对于CIFAR-10数据集,模型下降的准确率可达51%.联邦学习模型在IID数据集与non-IID数据集下的训练效果如图17所示,可以看出由于数据的non-IID,随着时间的推移,导致本地训练后的本地模型之间的差距较大,意味着全局模型将缓慢收敛,甚至无法收敛.
为了缓解此问题,文献[87]基于在设备上的本地训练中引入其他机制的思想来提出2个潜在的解决方案.首先采用基于最大平均差异算法的联邦双流模型FedMMD(federated maximum mean discrepancy),以解决在传统联邦学习设置下,设备上训练单一本地模型的不足.最大平均差异算法被引入设备上的训练迭代中,使本地模型集成来自全局模型的更多知识.实验表明,所提出的FedMMD模型在不影响最终测试性能的情况下减少了所需的通信次数.文献[87]的作者进一步提出了具有特征融合机制的联邦学习算法(federated learning feature fusion, FedFusion),以降低通信成本.通过引入特征融合模块,可以在特征提取阶段之后从本地模型和全局模型中聚合特征,而无须耗费额外的计算成本.这些模块使每个移动设备上的训练过程更加高效,并且可以更恰当地处理non-IID的数据,因为每个设备将为其自身学习最合适的功能融合模块.图18展示了特征融合的过程,在第t轮开始时,保留了全局模型的特征提取器,通过聚合本地和全局模型的特征,以更低的通信成本获得了更高的精度.此外,特征融合模块为新加入训练的参与设备提供了更好的初始化,从而加快了收敛速度.实验表明,FedFusion在准确性和泛化能力方面都优于标准的联邦学习算法,同时将所需的通信轮数减少了60%以上.

Fig. 17 The difference between the models in IID and non-IID datasets图17 在IID与non-IID数据集下模型的差别
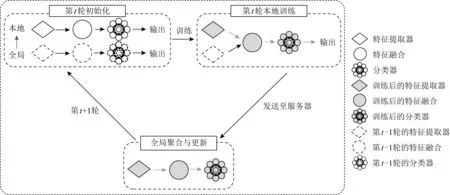
Fig. 18 Training iteration of FedFusion[87]图18 FedFusion的训练迭代[87]
文献[88]提出了联邦扩展(federated augmenta-tion, FAug)方案,其中每个设备共同训练一个生成模型,每个设备可以使用生成模型生成缺失的数据样本,从而将其本地数据扩展为一个IID数据集.具体来说,FAug中的每个设备都能识别出自己的数据样本中缺少的标签,即所谓的目标标签,并通过无线链路将这些目标标签的少数种子数据样本上传到服务器.服务器对上传的种子数据样本进行过采样,从而训练出一个GAN模型.最后,每个设备可以下载经过训练的GAN生成器使每个设备能够补充目标标签,直到得到一个平衡的IID数据集.这大大减少了与直接数据样本交换相比的通信开销.实验表明,FAug相比传统联邦学习仅需要1/26的通信轮数就能实现95%以上的测试准确性.通过数据扩充,每个设备可以根据生成的数据集训练出一个更加个性化和精确的用于分类或推理任务的模型.值得注意的是,FAug方法中的服务器需要是可信的,这样用户才愿意上传数据.
文献[89]的作者认为对于高度倾斜的non-IID数据集训练的神经网络,最高会使联邦学习的精度降低55%左右.该文作者进一步证明了这种精度下降可以用权值散度来解释,权值散度可以用每个设备上的类分布与总体分布之间的陆地移动距离(earth’s mover’s distance, EMD)来量化.因此,提出了一种策略,通过创建一个在所有边缘设备之间全局共享的数据子集来缩小每个模型之间的距离,从而改进对non-IID数据的训练效果.实验表明,仅使用5%的全局共享数据,CIFAR-10数据集的准确性可提高约30%.
文献[90]在文献[71]的基础上,假设有限数量(例如低于1%)的设备让它们的数据上传到服务器,提出一个新颖的学习机制Hybrid-FL.服务器使用从隐私敏感度低的设备收集的数据来构造部分IID数据,服务器利用构造的数据训练模型并聚合到全局模型中来更新模型,如图19所示.在Hybrid-FL算法中,文献[90]的作者设计了一种启发式算法,从而在带宽和时间的约束下在服务器上构建分布良好的数据集.具体来说,假设Dr={d1,d2,…,dcate}为第r轮训练中参与设备上存储的每个类的总数据量,则设备上数据之间的偏差为
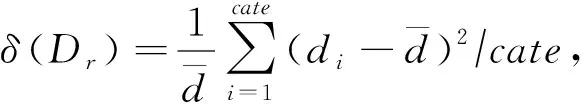
(26)

(27)

Fig. 19 Framework of Hybrid-FL[90]图19 Hybrid-FL框架[90]
通过分类数据中固有的异构属性内和属性间耦合以及属性到对象的耦合来学习相似性,可以计算数据之间的相关性,从而提高移动设备模型训练所需数据的质量以及提高模型训练的收敛性[91].通过该算法可以使训练数据集的每个类别更加均匀.此外,该算法增加了从设备收集的数据量,使数据近似IID,以提高模型性能.实验结果表明,在non-IID情况下,该方法的分类精度明显高于已有方法.但是考虑到用户对隐私的注重,可能不愿意共享数据,因此,该方法存在一定的局限性.
作为异步联邦学习的改进,考虑到落后的本地模型对全局收敛的贡献大小,文献[92]提出了基于non-IID数据集的异步联邦优化FedAsync算法.因为服务器和参与设备并不是同步工作,所以服务器不会一直等待.由于设备上传时受通信的延迟或训练的先后顺序影响,当服务器接收到该模型参数时,可能此时已经进行过几轮全局聚合,导致服务器接收模型与聚合之间存在延迟.该延迟越大对模型收敛结果的影响也就越大.因此,提出了一个混合超参数来控制由延迟影响的模型权重.每个新接收的本地更新根据时效性自适应加权,时效性定义为当前训练迭代与所接收更新所属迭代的差值.例如,来自落后设备的过时更新是没有价值的,因为它应该在前几轮训练中收到.因此,它的权重相对更小.此外,为了解决由于数据non-IID所导致的模型收敛缓慢问题,文献[93]还在损失函数中加入一个惩罚项,迫使所有本地模型收敛到一个共享最优值.该文作者证明,在保证隐私的前提下可以有效地实现通信,并且这个惩罚项可以随着分布式设置中节点的数量变化而进行缩放.实验结果表明,该方法在MNIST数据集上的图像识别的效果优于其他方法.
3.2.5 归纳总结
由于在联邦学习中会涉及到不同计算能力的设备和不同质量与数量的数据集,这些异构因素在很大程度上会影响训练的效率.针对这些因素,本文从联邦学习训练优化的3个方面来介绍相关解决方案,如表4所示.
从表4中可以看出,目前联邦学习在训练上的优化主要是在设备选择、资源协调、聚合控制和数据优化这4个方面.设备的选择打破了训练的瓶颈,使训练不受最慢设备的影响.为了使训练结果不偏向某个设备,许多文献提出资源协调的方案,让联邦学习变得更加公平与准确.除此之外,现有技术对模型的全局聚合进行了优化,通过调整聚合的频率或聚合的内容,让聚合的速率与模型效果更加优于传统的联邦学习.

Table 4 Summary and Comparison of Researches on Federated Learning Training Optimization表4 联邦学习训练优化研究方案的总结与对比
然而,non-IID数据仍是影响模型收敛最重要的因素,要想保证模型训练的准确度,就必须优化数据的non-IID问题.为此,本文专门讨论了基于该问题的优化技术.我们发现提出的解决方案之一是人为地共享或构造一个IID数据集,而这些数据是来自用户的,这可能在实际应用中并不适用,也不符合联邦学习的初始设置.因此,对于联邦学习收敛效率的研究还有很大的空间.
从结果上来看,目前训练优化方面的技术方案在训练能耗、时间与收敛效果上与传统的联邦学习相比,得到了有效的提升.
3.3 安全与隐私保护
3.3.1 安 全
1) 数据安全.联邦学习能够为分布式训练和模型推理提供可扩展的共享环境.然而,联邦学习架构潜在的安全漏洞,特别是对于从用户传入联邦的数据中毒攻击,造成全局模型收敛的阻碍.在这种情况下,恶意参与者可能会伪造错误数据以破坏训练结果,此类攻击可能会降低学习模型的总体性能.文献[94]研究了针对联邦学习系统的数据中毒攻击,其中参与者的恶意子集旨在通过发送源自错误标记数据的模型更新来毒害全局模型.该文作者证明,即使有一小部分恶意参与者,此类数据中毒攻击也会导致分类准确度和召回率的大幅下降.
文献[95]评估了基于女巫攻击的数据中毒对联邦学习系统的影响.恶意攻击者通过创建大量的假数据标签或脏标签来破坏训练全局模型时的有效性.为了减轻女巫攻击,该文作者提出了一种称为FoolsGold的防御策略.该方案的关键思想是可以根据更新的梯度将诚实的参与者与女巫攻击者区分.具体来说,每个参与者的训练数据都有其自身的特殊性,根据学习过程中参与者本地更新的多样性来识别数据中毒攻击.借助FoolsGold,系统可以在传统联邦学习过程进行最小更改的情况下防御数据中毒攻击,并且不需要学习过程之外的任何辅助信息.实验结果表明,FoolsGold超过了现有最先进方法的能力,可以应对基于女巫攻击的数据标签翻转,并且可以适用于不同分布的用户数据、不同的中毒目标和各种女巫策略.文献[96]提出了一个检测恶意用户并生成准确模型的系统,用户不再向服务器传送模型梯度而是上传伪装特征,并设计了一种基于这些伪装特征的自动统计机制来抵御数据中毒攻击.在这种解决方案中,使用均值聚类算法对每轮通信过程中的本地模型更新(伪装特征)进行聚类,并识别出异常分布的孤立点,即数据中毒后的本地模型.
2) 模型参数安全.对于模型中毒攻击,恶意参与者可以直接修改更新后的模型,然后将其发送到服务器进行聚合.即使只有一个攻击者,整个全局模型也可能中毒.文献[97]提出了一些防止全局模型受到恶意本地模型影响的解决方案.第1种解决方案,根据移动设备共享的更新模型,服务器可以检查共享模型是否有助于提高全局模型的性能;否则,该设备将被标记为潜在的攻击者,并且在经过几轮该设备的更新模型观察之后,服务器可以确定这是否是恶意用户.第2种解决方案是移动设备上的互相比较.如果某个移动设备的更新模型与其他设备上的模型有很大差别,则该设备可能是恶意模型;然后,服务器将继续观察该设备的更新,才能确定这是否是恶意用户.
为防止由于移动设备上传不可靠的模型从而导致联邦学习被破坏,或由于能量限制以及高速移动而导致劣质数据对模型训练的影响,文献[98]引入了信誉的概念作为度量指标,以防止设备发送不可靠或恶意的模型更新等危险行为.此外,文献[99]提出了一种方法,利用预先训练好的异常检测模型来检测移动边缘网络中存在异常行为的设备,及时消除恶意用户对全局模型以及联邦学习系统产生的不利影响.
3.3.2 隐私保护
文献[100]的作者将服务器设置成恶意的,当进行全局模型聚合时,通过利用设备发送到服务器的本地模型,结合GAN网络模型共同推断并精准地伪造出受害者设备上的一些隐私数据.如图20所示,恶意服务器获取到来自设备的本地模型后,将某个设备的本地模型复制到GAN模型的鉴别器中进行训练,并通过数据分布计算与附加数据集的训练,使鉴别器与生成器能够得到更准确的训练.最后,生成器能够生成该设备的隐私数据.这种攻击方式对特定的设备进行攻击,生成该设备上的具体数据信息,是联邦学习中一种较严重的隐私威胁.
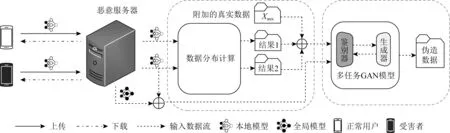
Fig. 20 Federated learning GAN attack model based on malicious server图20 基于恶意服务器的联邦学习GAN攻击模型
为了保护用户模型参数的私密性,文献[101]介绍了一种称为差分隐私的随机梯度下降技术,该技术可以在传统深度学习算法上有效地实现.在此基础上,文献[102]将差分隐私技术应用到联邦学习环境,关键思想是在模型参数发送到服务器之前,在移动设备上部署差分隐私技术,在训练后的本地参数上添加一些噪声.该文作者还分析了该方案下联邦平均聚合的收敛效果,结果表明可以达到效率和所需隐私保护级别之间的平衡.通过这种方式,参与设备可以降低从其共享参数中泄露隐私的风险.
文献[103]中的作者提出了一种更全面的隐私保护方案.对于每个训练轮次,服务器首先选择随机数量的参与者以训练全局模型,然后进一步在模型参数上添加噪声.因为无法得知哪些设备参与了训练,所以能够有效防止恶意设备通过共享模型来推断其他设备的隐私.
3.3.3 归纳总结
本节讨论了在联邦学习训练模型的过程中存在的恶意攻击行为,从安全性和隐私性2个方面分析了当前的安全与隐私保护机制.联邦学习的目的是供移动设备执行有效的且保护隐私的协作模型训练方案.但是,针对联邦学习的隐私攻击过程,攻击恶意设备可以获得其他参与者敏感信息的访问权限.此外,在传输共享模型的阶段,攻击者也可以执行模型中毒攻击,这些攻击将会破坏整个学习系统.本文对比分析了目前联邦学习的隐私与安全的策略,在表5中进行了总结.
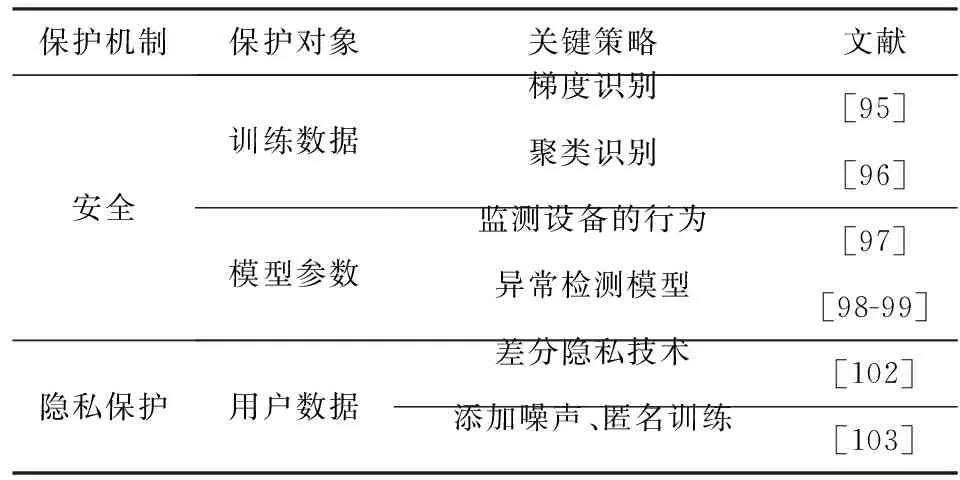
Table 5 Federated Learning Security and Privacy Strategies表5 联邦学习安全与隐私策略
4 挑战及未来研究方向
联邦学习由于其分布式的特性,以及移动边缘网络环境的复杂性,使联邦学习系统的稳定性不如传统分布式学习.用户的不可控性造成许多未知因素,这给联邦学习的效率优化带来了极大的挑战.目前,联邦学习的研究仍处于初期,没有一套完善的方案解决稳定性、效率优化问题,训练过程容易受到影响.通过对移动边缘网络中联邦学习效率优化研究现状的深入分析,我们认为未来联邦学习的优化研究可以重点从7个方面展开:
4.1 基于更多边缘计算的联邦学习
联邦学习的研究还处于初级阶段,大多数是基于云和端的2层学习架构.大量的移动设备与云服务器直接通信会带来更多的能耗和通信成本.同时,随着模型的日渐复杂化,服务器也会承受越来越大的负载.为了高效利用移动边缘网络中设备的计算资源并进一步释放人工智能的潜力,将传统基于集中式(例如数据中心)的人工智能下沉到靠近用户的网络边缘已成为一种技术趋势,例如目前新兴的边缘智能[104].在联邦学习领域中利用云—边—端协作方式的技术还比较少,或只是简单地用边缘层来存放数据,没有真正发挥边缘的价值.相比基于云的云—端协作,边缘化学习的优势有4方面:
1) 低时延与低能耗.在实时性较高的场景,例如智能交通系统、智能医疗系统等,这些场景对时延非常敏感,如果数据没有及时传送,可能会造成模型决策错误.云和端之间的传输需要更长的时间,边缘化学习可以降低通信的响应时间以及成本.
2) 高安全性与高隐私性.在通信过程中,联邦学习以及设备本身容易受到恶意攻击,但移动设备的能力有限,不能保证模型以及自身的安全性.利用边缘设备,例如小型基站和服务器,结合同态加密和多方安全计算等安全机制可以降低设备被攻击的风险[105].
3) 易管理.在实际应用中,由于网络连接不稳定等因素,设备可能在训练中途退出,导致模型性能下降.边缘服务器靠近用户,通信连接相对稳定,可以更方便地监控设备状态并进行管理.
4) 易扩展.云服务器的建立和维护的成本很高,而人工智技术更新换代迅速,使云数据中心需要不断地升级与扩展.相反,边缘设备成本更低、灵活易扩展.可以将更多的任务部署到边缘设备中,而不需要更多的服务成本.
结合更多的边缘计算可以为联邦学习带来更多的学习场景.例如,传统的Gossip算法[33]作为移动边缘网络中一种点对点的通信方式,也可以看作去中心化的边缘计算模式.具体来说,在一个有界网络中,每个节点都随机地与其他节点通信,经过几轮随机的通信,最终所有节点的状态都会达成一致.考虑到联邦学习设备的异构性,在本地训练阶段可以基于Gossip使设备之间进行互相学习,提高本地模型的质量,从而加速全局模型的收敛.
4.2 针对联邦学习的数据清洗
联邦学习应用在移动边缘网络,用户的数据无法进行统一的预处理,除了来自第三方的恶意攻击,设备自身存在的错误数据、数据冗余等问题无法避免.数据质量是模型快速收敛的关键,因此,针对联邦学习的数据清洗是一个很大的挑战.
文献[106]提出一种基于移动边缘节点的数据清洗模型,在边缘节点上建立分类模型以辨别异常数据.同样地,在参与联邦学习的移动设备上建立数据清洗模型也是一个解决方案.因此,在保证设备计算资源足够的前提下,本文提出一种联邦学习数据清洗方案.服务器在联邦学习任务初始化过程中同时准备一个先验的数据清洗模型,并将该模型一同发送给设备.设备在进行本地训练之前,先经过数据清洗模型以筛选并剔除部分错误或无用的数据.这样能减小本地模型训练的误差,大大提高联邦学习模型的学习效果.
考虑到无法直接对用户数据进行处理或清洗,可以利用边缘的计算和通信资源来获得最佳的联邦学习性能.例如,在不同的网络位置部署移动边缘节点,使其成为远程云和移动设备通信的枢纽.在本地更新阶段,每个移动设备计算本地模型和全局模型参数之间的相似度,如果二者之间的相似性较低,则推测该本地模型所使用的数据集质量低,存在错误数据或脏标签的可能性高,选择丢弃而不上传到边缘服务器;本地训练结束后,部署在不同网络位置的移动边缘节点聚合簇内的必要本地更新,然后将边缘聚合后的模型发送到云服务器进行全局聚合,从而减少由错误数据训练的本地模型,达到模型清洗的目的.
4.3 自适应联邦学习
联邦学习作为分布式学习的一种延伸,通信消耗与收敛性能是系统的主要评价指标.在本文的联邦学习通信与训练优化方案中,很难将二者同时满足.例如模型压缩技术压缩了模型大小,虽然能够降低传输过程中的消耗,但是在模型精度上有一定的妥协.因此,文献[76]综合考虑了将能耗、训练时间和通信成本最小化,提出设备资源最优决策方案.然而,随着模型的复杂化和训练任务的增加,综合各方面提升联邦学习的效率是非常困难的,考虑自适应的训练算法变得尤为重要,我们给出2个自适应方向:
1) 自适应通信与训练时间的折中.根据联邦学习系统的通信与能量消耗的侧重点,对移动边缘网络的环境进行建模并设计动态的决策算法,以保持训练过程动态平衡地进行.例如,当训练时通信所消耗的资源过多或时延过高时,则可通过算法调整本地训练与更新的时间,或通过压缩减少模型的数据量;反之,可以增加本地更新的次数,或传输完整的模型参数,以学习更多的知识来提高模型的收敛速率.
2) 自适应本地训练.在本地模型迭代优化时,学习率是一个非常重要的超参数.学习率是梯度下降优化方法中的步长,若步长过大则可能导致模型的振荡,若步长过小又会使模型收敛的速率很慢.由于联邦学习使用的数据集的分布因用户而异,依赖于历史经验的步长不能准确地适应模型的训练状况,步长的设置变得非常困难.因此,采用设备的自适应训练以优化模型收敛也是提高联邦学习效率的重要方法.
4.4 激励机制与服务定价
大多数联邦学习的框架仅由一个服务器与多个参与设备组成,即单一服务器的联邦学习.在实际情况下,可能会存在2种情况:1)参与设备可能是不愿共享其模型参数的竞争者,并且还受益于训练好的全局模型,但没有对全局模型做出贡献;2)联邦学习服务器可能正在与其他服务器竞争,在极端情况下,服务器可能接收不到设备的本地模型.此外,由于参与设备对它们的可用计算资源和数据质量有更多的了解,在联邦学习服务器与参与设备之间存在信息不对称.因此,设计更合理的激励机制[107],以激励移动设备用户参与联邦学习并减小由于信息不对称带来的潜在不利影响,以及解决服务器之间的竞争问题.此外,对于联邦学习,用户可以是服务使用者,同时也可以是数据生成器.在这种情况下,需要一种新颖的服务定价机制[108]来考虑用户的服务消耗及其数据贡献的价值.
例如,移动设备和服务器之间的通信可以利用Stackelberg博弈论[109-110]进行建模,其中服务器是买方,移动设备是卖方,每个设备都可以非合作地决定自己的利润最大化价格.首先,服务器考虑模型的学习准确性与训练数据大小之间不断增加的凹关系,确定训练数据的大小以使模型学习的利润最大化;然后,移动设备决定每单位数据的价格以最大化个人利润.
文献[111]的作者提出了一种利用合同理论[112]的激励设计,以吸引具有高质量数据的移动设备.该合同可以通过自我披露机制来减少信息不对称,在这种激励机制下,每个合同必须确保每个设备参加联邦学习时都具有积极作用,并且每个最大化效用的设备都只会选择为其类型设计的合同.服务器的目标则是在该合同的约束情况下最大化自己的利润,通过这种方式来达到联邦学习参与设备与服务器的效率平衡.随着联邦学习参与用户对利益的要求发生变化,设计合理的服务定价也是未来重要的研究方向.
4.5 资源友好的安全与隐私保护
由于移动边缘网络的复杂性与不确定因素较多,且移动设备的计算资源不足,在联邦学习过程中发生故障或被攻击的可能性大,用户的隐私仍然受到来自第三方的威胁.目前的联邦学习隐私保护方案依赖于传统的加密与数据扰动的方式,例如同态加密和差分隐私.然而,由于现有技术的局限性,权衡模型的可用性与隐私性成为联邦学习的挑战.
例如,差分隐私的优点在于添加随机噪声不会造成过高的性能代价,而缺点在于扰动机制将可能使模型精度变差.同样地,同态加密虽然能够保证数据在存储、传输与计算过程中的隐私与安全,但加密过程涉及大量的复杂计算和密钥传输,对于复杂模型来说,计算和通信的开销都非常大.为了保证联邦学习的效率,对隐私的保护虽然重要,而对于隐私保护的可行性更为重要.在未来的工作中,需要考虑权衡算法的可行性与隐私性,研究轻量级的安全与隐私保护策略,从整体上提高联邦学习的性能.
4.6 联邦学习与前沿技术结合
联邦学习中由于用户与用户之间的差异,本地non-IID数据随着用户地域分布以及偏好而变动,导致每个用户自身的模型参数仅适合本身的数据,全局模型很难满足所有参与者的需求.因此,需要考虑一种新颖的方法使全局模型针对每个用户进行优化,提高全局模型在统计学异构性方面的泛化能力.
4.6.1 个性化
基于模型初始化的元学习(例如模型无关元学习)对任务的快速收敛拥有良好的适应性和泛化性.例如,文献[113]将元学习方法与联邦学习方法相结合.具体来说,每个设备被看成一个任务,设备的本地数据被分为support set与query set.参与训练的设备接收元学习器参数meta-learner进行模型训练,利用support set更新本地任务的参数learner,然后基于更新后的learner在query set上更新meta-learner.经过几轮训练后,元学习器参数meta-learner不会偏袒任何设备,提升了在所有设备上的泛化能力.相比传统的联邦学习,联邦元学习共享的不再是整个模型,而是元模型参数,使联邦元学习可以应用得更加灵活.与传统的联邦平均算法相比,联邦元学习在模型精度和通信成本上都有所改善.文献[114]通过联邦元学习方法,使模型仅用少量的样本就能迅速适应学习新的学习任务,减少了大量计算成本.文献[115]在联邦学习环境中构建了一种个性化的模型,并提出基于多任务学习的MOCHA算法以解决移动边缘网络中通信、设备断线和容错性等问题,从而增加模型的泛化能力.
4.6.2 去中心化
目前主流的方法都是基于中心化联邦学习,而中心化联邦学习方法的缺点是依赖一个中央服务器,这需要所有设备同意一个可信的中央服务器.目前,从系统架构上通过去中心化等方式优化通信效率也正在深入研究.文献[116]提出了一个去中心化的联邦学习框架BrainTorrent,所有的参与者相互作用,而不依赖于一个中央服务器.在参与者之间进行点对点学习,模型随时根据不同的参与者动态调整,从而提升模型的性能.而文献[117]考虑了去中心化联邦学习下的单向信任问题(即用户A信任用户B,用户B不信任用户A).该文作者提出了无中央服务器的联邦学习算法,每个节点只需要知道它的外部邻居节点,而不需要知道全局拓扑,因此在训练过程中更加灵活,并且被证明具有最佳的收敛速度.除此之外,基于区块链的联邦学习除了可以实现去中心化,还能避免数据或模型受到攻击,提高效率的同时还能增强系统的稳定性[118].联邦学习与前沿技术结合的研究还处于起步阶段,正逐步成为研究热点,技术的融合能促进共同发展,因此值得不断探索.
4.7 联邦学习与智能场景结合
随着对个人隐私的关注,联邦学习在许多应用中扮演着越来越重要的角色.将现有的智能场景与联邦学习结合,可以实现保护用户隐私的智能服务,同时,通过实践中的反馈能够为联邦学习的改进与发展奠定良好的基础.目前,主要有3种结合的智能场景:
1) 计算卸载与缓存.计算卸载是给定边缘设备的计算和存储容量约束,将移动设备上一些计算量大的任务卸载到云服务器上进行计算[119-120].然而,来自用户的计算涉及用户的隐私信息,服务器提供商并不是完全可信的,用户的隐私因此受到威胁.此外,可以将常用的请求文件或服务缓存在边缘服务器以加快检索速度,不必与远距离的云进行通信[121].同样出于对用户隐私的考虑,可以利用联邦学习的优势,设计保护隐私的智能计算卸载与缓存方案.文献[122]介绍了一种隐私感知边缘缓存方案,提出了一种基于联邦学习的方法来训练偏好模型,同时将用户的数据保留在其个人设备上.目标在不受资源约束的情况下,最大限度地增加了边缘需求的服务数量,既保证了用户数据的隐私,又实现了最优边缘缓存.
2) 车联网.车联网是智慧城市服务的一方面,智能车辆具有数据收集、计算和通信等功能,例如导航和交通管理.由于这些信息可以包含驾驶员的位置和个人信息,若共享这些数据,会导致用户隐私得不到保障[123].利用联邦学习,可以实现在车联网环境中高效地学习与交互,有效保护用户的隐私.
3) 智能医疗.目前,全世界的数据库都包含海量的数字医疗图像[124].结合数据科学的发展,医疗数据提供了认识与治疗疾病的基础.然而,由于隐私和法律方面的考虑,存储在不同医院与机构中的异构数据集无法直接共享.因此,医疗图像数据的价值无法利用,这限制了医疗学者对疾病的研究.结合联邦学习框架,可以安全地进行生物医学数据的识别与分析,而无需共享患者的个人隐私信息.
5 结束语
随着大数据时代的来临,用户对数据隐私的要求越来越高,深度学习需要从集中的方式转变为面向用户的分布式方式.联邦学习的效率决定着人工智能技术面向用户的普及与应用程度.在异构的移动边缘网络中,由于带宽与通信距离的限制,联邦学习的通信效率是主要的问题.因而,许多学者基于模型压缩技术提出了解决方案.此外,移动设备的选择、模型聚合与数据分布等资源分配问题同样影响着联邦学习的训练,本文将这些归纳为训练优化,并系统性地对比分析了相关的方案.针对联邦学习中可能发生的安全与隐私问题,本文总结了现有的联邦学习安全与隐私保护机制.
同时,我们在文献调研过程中发现目前的大多数解决方案都属于基本的设备层与服务器层的联邦学习框架,在训练任务比较复杂的情况下,移动设备可能无法承受巨大的计算压力.而边缘计算模式能为联邦学习提供适应的场景,可以利用边缘技术将更多的计算卸载到边缘(例如边缘服务器)以充分释放边缘的价值,为联邦学习的优化提供更多的可能性.本文从通信、模型训练和安全与隐私3个方面分析与对比了联邦学习效率优化的研究方案.根据现有方案的不足,本文总结了联邦学习面临的一些新挑战,从边缘计算、数据优化、自适应学习、激励机制以及可行性隐私保护等方面给出了联邦学习未来的研究方向,并提出了针对联邦学习效率优化的前沿技术与解决方案,为联邦学习进一步发展提供参考.联邦学习的研究目前虽然还处于发展阶段,但我们认为结合更多边缘计算的联邦学习是未来的重要课题,也将成为实现联邦学习落地的最后一公里.
作者贡献声明:孙兵负责相关文献资料的收集、分析和论文初稿的撰写;刘艳负责文献补充和相关图表的修正;王田提出写作思路并指导论文撰写与修改;彭绍亮针对文献调研提出意见并指导修改;王国军和贾维嘉提出论文格式排版建议并校对全文.
