FAQ-CNN:面向量化卷积神经网络的嵌入式FPGA可扩展加速框架
2022-07-12谢坤鹏靳宗明刘义情陈新伟
谢坤鹏 卢 冶,3 靳宗明 刘义情 龚 成 陈新伟 李 涛,3
1(南开大学计算机学院 天津 300350) 2(天津市网络与数据安全技术重点实验室(南开大学) 天津 300350) 3(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) 4(福建省信息处理与智能控制重点实验室(闽江学院) 福州 350108)
由于卷积神经网络(convolutional neural network, CNN)往往规模庞大、参数量众多,难以直接部署于边缘计算平台,因此为迁移CNN到资源受限的嵌入式现场可编程门阵列(field programable gate array, FPGA)平台来加速边缘应用计算,研究人员提出了多种CNN量化方法,在符合应用要求的基础上降低CNN的计算规模和存储需求[1-2].CNN的权值和激活值经过量化操作后,只需低位宽的算术运算单元和少量的存储资源就可以部署CNN模型.FPGA凭借其独特的灵活性、可编程性、高层次综合设计和出色的能效比[3],成为设计CNN加速器的首选平台[4-6].因此,利用嵌入式FPGA来实现量化模型的低位宽加速器已成为当前的研究热点[7-10].然而,以往的CNN加速器设计通常存在3个问题:
1) CNN模型量化算法与相应硬件加速器的设计紧耦合,导致模型重构需要相应的硬件修改量大且复杂,无法高效适配不同量化方法,代码复用效率极低.传统量化CNN加速器的设计是根据量化方法的数据格式定义和数据位宽声明来设定计算规则,然后将计算规则映射成为相应的硬件配置[4-5].研究人员往往期望以类似“即插即用”的方式将各种量化CNN快速地部署于FPGA来验证其硬件效率[11-12].然而,不同的量化方案在实现过程中,通常具有自身特殊的数据格式和运算规则,这些差异导致重构时无法高效复用.具体来说,数据格式会直接影响数据传输模式和读写方式,重构时需要针对特定数据格式重新设定编码规则和数据重组织方案;而特定的运算规则又需要重新定制算子才能支持高效计算,另外计算的高度并行需求也会增加硬件重构时的难度.
2) 已有的工作多是利用切片处理方式从不同的角度将大块计算分解为可部署到FPGA上的多个小块计算,并优化数据交换机制来减少片上存储和片外存储之间的通信代价[10,13].但是,低位宽数据在片上片外数据交换过程中,由于缺少对数据的有效组织,导致带宽资源利用不充分、并行读写效率低,从而成为制约高效计算的瓶颈.尽管可将多个数据项打包为单个宽字[14-15],然后在每个周期并行地传输这些数据项,但是未进行编码设计和数据重组织则会降低并行解码的执行效率.此外,并行解码操作需要存储数据的硬件资源独立分布,才能避免片上数据并行访问冲突.在计算方面,并行计算同样也需要合理的数据存储资源分布,才能保证数据的无冲突并行访问.因此,以往的设计方案需要大量的片上存储资源才能同时满足并行解码和并行计算的需要.
3) 实际部署CNN时需要调整计算并行规模、存储资源类型、通信缓冲大小等一系列参数配置以符合FPGA片上资源的约束并进行性能优化,但片上资源配置与优化严重依赖人工经验,缺乏建模分析和明确的理论依据来支持决策,导致资源未有效利用、FPGA性能发挥不充分.具体来讲,仅凭人工经验难以精准决策要分配哪种资源、分配多少资源来用于计算操作、数据存储和数据通信.尽管有一些相关研究尝试对CNN加速器的性能和资源进行分析来解决FPGA片上资源如何配置的问题,但未能构建全面地覆盖所有资源的分析模型,造成资源配置方法具有局限性.例如,利用Roofline搜索最优的DSP资源配置[16],但LUT等其他片上资源并未涉及和充分利用.因此,对于CNN加速器来说,缺乏FPGA片上资源(如LUT,DSP,BRAM)利用率与CNN推理延迟的联合分析,会使加速器的设计和优化缺乏理论依据,进而难以进行资源合理配置,无法充分发挥硬件性能.
目前,学术界和工业界缺乏针对量化CNN模型提供框架级支撑的灵活通用FPGA加速器设计研究工作,现有框架级工作主要集中于适配专用、特定量化方法的FPGA加速器设计研究.这是由于FPGA设计流程相对复杂且灵活度较高,需要研究人员具备软硬件协同设计能力,既要熟悉硬件研发方法又要对算法执行流程[17]一清二楚,无形中提高了FPGA加速框架的设计门槛,也造成了当前面向CNN的FPGA加速框架相关研究的匮乏.相比而言,GPU平台上的算法加速研究和应用却很充分,先后出现了多种加速库和框架工具来加速深度神经网络并简化其部署过程,如cuDNN[18],cuBlas[19],TensorFlow等功能强大又丰富的类库和框架工具,而FPGA平台上的量化CNN加速器框架相关内容还未被深入探索.尽管Xilinx推出的VITIS AI工具可支持Caffe和TensorFlow的模型直接进行量化并部署到目标平台[20],但是该工具所采用的量化方法固定,难以更改或拓展,而量化CNN加速器的研究人员亟需快速集成各种类型量化方法来验证硬件效率[12].
因此,为解决上述问题,本文提出一种面向量化CNN模型的嵌入式FPGA加速框架FAQ-CNN,从计算并行、数据通信与数据存储3方面来进行相关设计、方案实现和联合优化.FAQ-CNN把量化方法相关操作抽象成模板化的量化组件,以此支持各种量化算法的灵活接入和量化模型快速部署.CNN模型量化和方案部署研究人员可利用FAQ-CNN框架中的缺省量化组件或自定义新量化组件,以类似“即插即用”的方式来快速定制量化CNN加速器,从而减少设计重构带来的代价.为提升定制量化CNN加速器的性能,FAQ-CNN利用搜索工具实现硬件参数快速自动配置,从而发挥各种量化方法的优势并避免框架通用性带来的性能损失.在加速器设计方面,FAQ-CNN分别实现卷积、池化、ReLU激活和全连接4种不同的CNN算子,以此作为建立通用CNN结构的基础,并运用算子融合、双缓冲和流水线等优化技术,提升CNN推理任务内部并行的执行效率.在数据传输方面,FAQ-CNN采用高位宽的数据传输模式实现单周期交付多数据,并结合数据预处理、数据并行解码和并行计算等机制进行协同优化.此外,FAQ-CNN综合分析片上资源利用情况并构建资源配置模型,以CNN推理最小延迟为性能目标,以片上资源为约束,来支持搜索工具寻求最佳的片上资源配置方案.本文相关实验验证了FAQ-CNN能够高效地实现如BNN[1],TNN[2],μL2Q[12],DoReFa-Net[21],VecQ[11],PoT[22]等量化CNN加速器.以8 b位宽的DoReFa量化算法加速器为例,其在Xilinx ZCU102平台上FAQ-CNN可获得高达1.23TOPS的计算性能.
本文的主要贡献包括3个方面:
1) 提出面向量化CNN的FPGA加速框架FAQ-CNN.软件工具FAQ-CNN可提供快速部署量化CNN模型的解决方案,将量化方法的相关操作模板化为FAQ-CNN框架的量化组件,并提供2种不同粒度的CNN硬件加速器实现方式;通过算子融合将卷积层的输出结果作为激活层和池化层的输入数据,并采用双缓冲存储张量数据,从而实现4段流水线来提升FAQ-CNN迭代时的并行执行效率.
2) 提出针对数据特征的分级编码和位宽无关编码的方案,设计低位宽与高位宽数据的编解码规则,高效利用带宽传输数据.在数据传输前,将片外数据重组织为按固定维度展开的连续分布数据;在数据解码时,通过存储资源复用机制来满足并行解码和并行计算的资源需求,降低总体资源消耗.
3) 建立资源配置优化模型并转为整数非线性规划问题,将输入通道与输出通道的切片因子与权值存储方式设定为超参数来探索设计空间.在求解时采用启发式剪枝策略缩小设计空间规模,借助CPU-GPU异构平台来加速参数搜索过程,快速完成相应的FPGA片上资源的最佳配置.
1 相关工作
关于FPGA平台的CNN加速器研究集中于上层CNN量化方法和底层硬件设计2个方面[23-24].上层CNN量化方法侧重降低数据位宽来契合FPGA硬件计算要求[1];底层硬件设计侧重从CNN计算、数据通信、存储等方面来优化加速器性能[13].
在CNN模型量化方法方面,量化可分为超低位宽[1]、线性[21]和非线性[22]这3类方法.对于超低位宽,Courbariaux等人[1]提出了二值化网络BNN,将模型权值量化为1或-1这2个值,仅用1 b即可表示模型的参数.Zhao等人[25]基于FPGA平台实现了BNN,将其模型权值数据全部置于片上存储器,避免片外数据加载高延迟.Xilinx研究实验室提出了基于FPGA的BNN加速框架FINN[26],所实现的加速器能够在CIFAR-10数据集上获得283 μs的推理延迟.Li等人[2]提出了三值化网络TNN,将模型权值量化为1,-1或0,相比于BNN,TNN能够有效提升模型分类精度.Prost-Boucle等人[5]部署TNN量化算法到FPGA平台并获得了16.7TOPS的计算性能.Wang等人[27]提出基于BNN和TNN的混合精度神经网络,并采用多种组合方案来权衡模型的准确性和计算复杂度.对于线性量化,Gong等人[11]提出VecQ量化方法,利用范数形式化表示量化值和全精度值之间的偏差,能够在给定位宽下最小化量化误差.Zhou等人[21]提出了DoReFa-Net,量化反向传播过程中的梯度值为低位宽定点数,从而能够利用FPGA平台加速CNN模型的训练和推理过程.Wang等人[28]提出HAQ量化框架,利用增强学习机制优化量化策略,对模型的各层采取不同的量化策略,能够有效降低推理延迟并减少量化造成的精度损失.对于非线性量化,Miyashita等人[22]提出了PoT量化算法,将模型权值量化为0或2的幂.Jing等人[29]部署PoT量化算法到FPGA平台,利用幂计算的性质将乘法和累加运算转换为利用LUT实现的移位运算.Li等人[30]提出APoT算法,将浮点数量化为多个PoT值(2的幂)的和,从而更好地拟合权值分布.Tambe等人[24]提出AdaptiveFloat量化算法,利用指数和底数来表示量化后的数值,不仅扩大了数值表示范围,而且支持硬件的高效实现.Jain等人[31]提出BiScaled-Fxp定点数表示方式,采用2个不同的缩放因子来拟合长尾分布,按比例分别缩放模型权值中较大数值和较小数值,并成功部署于FPGA平台.
在CNN模型计算方面,主要的计算量集中于卷积层,Cong等人[32]证明了卷积层的计算量占据整个模型计算量的90%.针对卷积层中大量的循环操作,Zhang等人[16]采用多种嵌套循环优化技术来提升卷积层的计算效率,如循环流水线、循环展开和循环平铺.卢冶等人[33]从数据访问独立性的角度提出通道并行计算的方案,引入循环切割因子并在通道维度展开循环,利用数据流优化和缓存优化技术加速CNN的卷积计算.Liang等人[34]利用Winograd算法降低卷积层的计算复杂度,提高卷积层的处理速度.然而,Winograd算法效率依赖卷积步长的选取,当步长为1时计算效率较高,而其他情况下算法效率不够理想.为了部署CNN到配备大规模硬件资源的FPGA平台上,有研究人员从处理器结构方面来加速卷积计算.例如,Wei等人[10]提出利用脉动阵列来进行卷积层计算的方案,能够以280 MHz的工作频率处理CNN推理任务,大幅度降低推理延迟.Cong等人[35]利用多面体模型自动化设计CNN的脉动阵列结构,探索了从计算需求到硬件结构的最佳映射方案.然而,这些基于脉动阵列的计算方案会消耗大量局部存储资源.此外陈桂林等人[36]将卷积计算映射为2维阵列的计算和相应的数据流调度,并通过加速器实例进行了相应验证.
在数据交换效率方面,CNN加速器片上与片外的数据存储和访问方式对加速器的处理速度提升至关重要.Du等人[37]提出ShiDianNao,将所有的模型参数置于片上SRAM,消除对DRAM的访问,避免因片外数据访问引起的高功耗和高延迟.Zhang等人[13]提出将全连接层的计算任务映射到卷积的计算引擎中,通过探究输入特征图和权重数据的映射方式并利用共享机制,来减少对片外存储器的访问时间.Li等人[38]提出矩阵分解的方案,将全连接层的矩阵乘法分解为多个小规模矩阵乘法,并采用批处理的模式来缓解外存访问压力.除了访存优化,数据读取方式优化也能够提高数据传输效率.对片外存储器非连续存放的权值数据进行重新排列,可增大数据读取的猝发长度,进而提高实时带宽[13,39].此外,Cong等人[14]提出了利用高位宽模式传输数据的方案,将多个32 b的字合并为1个512 b的宽字来实现单周期传输多数据,以充分利用带宽资源.

Fig. 1 FAQ-CNN framework components and implementation mechanism图1 FAQ-CNN框架组成和实现机制
在片上资源配置优化和设计空间探索方面,Zhang等人[16]提出roofline模型,利用带宽需求和实时处理性能2个指标建模,最小化卷积层处理时间.Motamedi等人[40]联合各类CNN设计方案与硬件平台参数提出基于FPGA的CNN加速器性能评估模型,并利用设计空间自动化搜索工具获取给定平台的最佳实现方案.Mu等人[41]提出LoopTrees数据结构,对CNN加速器进行资源建模,通过2阶段先后的粗粒度和细粒度分析来获取精准的资源模型.这些工作在搜索最优的CNN硬件实现结构时,主要针对部分片上资源进行建模,如DSP和BRAM.然而,作为片上资源重要组成部分的LUT未被充分探索,导致片上资源利用不充分.LUT的使用会增大建立资源模型的复杂度,而现有的工作缺乏关于LUT资源利用方面的探索.
2 FAQ-CNN框架设计
本节首先介绍FAQ-CNN加速框架的总体架构,然后分别从数据并行计算、数据通信和数据存储3个方面具体论述FAQ-CNN的设计思路和优化方法,并详细阐述FAQ-CNN的优势.
2.1 FAQ-CNN架构
FAQ-CNN加速框架的FPGA设计架构如图1所示,分别由量化组件、数据引擎、片上缓存单元、指令单元及计算引擎5个部分组成.
1) 量化组件.量化方法往往具有自身独特的数据格式和运算规则.FAQ-CNN通过量化组件来形式化地描述量化方法的硬件代码实现规则,将量化方法的硬件实现过程分解为运算规则和量化数值映射,以灵活支持各类量化方法的快速集成.具体来讲,量化组件中的模块op负责量化算法所涉及的乘加(multiply accumulate, MAC)操作;模块quanti-zation负责量化算法的数值映射.这2个模块的具体实现可根据量化方法的特点来定制,3.1节中将详细介绍这2个模块的模板化实现方法.
2) 数据引擎.低位宽数据不经重组而直接传输,往往对带宽利用不够充分且效率低下,甚至会导致通信瓶颈,而将低位宽数据组织成高位宽的数据来提升带宽利用率又会增加设计复杂性.FAQ-CNN设计了支持并行读写的数据引擎,包含编码器和解码器2个模块,用来实现单时钟周期内多个数据的并行读写,缓解数据传输与数据计算间速率不匹配的矛盾.
3) 片上缓存.FAQ-CNN中的片上缓存资源用于存储输入特征图、输出特征图及模型权重.如图1所示,数据引擎中的Load操作将输入特征图与模型权重加载到片上缓存,并通过Store操作将输出特征图写入片外存储器.
4) 指令单元.负责按照预先定义的指令规则解析模型配置参数,这些配置参数规定了数据引擎与计算单元的工作方式.在FAQ-CNN中,指令由8个元素构成:输入通道、输出通道、输入特征图高度、输入特征图宽度、卷积核大小、卷积步长、卷积填充和计算类型.其中,计算类型用来明确是卷积层的计算还是全连接层的计算以及是否还包含激活层和池化层计算.如图2所示,以AlexNet[42]模型的第4个卷积层为例,按照FAQ-CNN所定义的指令格式,则其相应的指令配置参数实例为(384,384,13,13,3,1,1,1).
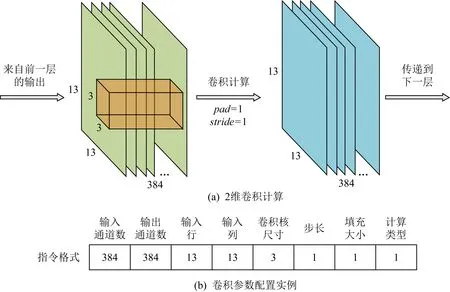
Fig. 2 Definition of instruction format图2 指令格式定义
5) 计算引擎.当加载满足计算条件的输入数据之后,FAQ-CNN的计算引擎按指令配置参数来对这些数据进行计算并输出相应的结果数据.由于CNN模型各层的计算任务类型不同,比如卷积层是计算密集型的,而全连接层却是通信密集型的,因此FAQ-CNN在计算引擎中采用2个计算内核来分别处理这2类计算.
此外,由于FPGA片上资源受限,所以在CNN模型部署时无法将其某一层的全部张量数据都直接加载进来,只能利用数据切片来迭代地完成整个层的计算.对于每次的迭代处理,其过程可分为4个阶段,即加载、计算、后处理、存储.其中,后处理主要包括非线性激活操作和池化2类操作.此外,FAQ-CNN为片上缓存相应地设计了双缓冲区.双缓冲区的设计能够有效支持FAQ-CNN利用流水线技术对该4个阶段数据流进行并行处理.
2.2 数据并行计算
当张量数据加载到片上存储器后,FAQ-CNN中的卷积层和全连接层进行相应计算,其流程代码如图3所示.结合硬件设计特性,FAQ-CNN采用多种机制加速计算.

Fig. 3 Computing engine of convolutional layer and full connected layer图3 卷积层和全连接层的计算引擎
1) 循环展开.FAQ-CNN卷积层的嵌套循环结构如图3(a)的代码所示.由于张量数据在不同通道上的计算操作是彼此独立的,因此可将与输入和输出数据通道相关的2个循环放置到嵌套循环的最内层并进行循环展开.pragma指令规定了编译器以复制硬件资源的方式来展开这2个内部循环并进行流水线处理.
2) 数据切片.在图3(a)中,代码的4个外层循环用来对单个通道的卷积核和特征图进行处理,tm和tn参数分别代表输出特征图和输入特征图在通道维度上的切片因子.因此,卷积计算的并行度可由tm与tn的乘积获得.此外,为符合并行计算的要求,权重数据需沿着输入通道和输出通道进行数组分割,输入特征图和输出特征图同样需要在通道维度上进行数组分割.全连接层的循环结构代码如图3(b)所示.与卷积层类似,全连接层的输入和输出均是1维张量,图3(b)中的tm和tn分别表示输出和输入张量模长的切片因子.
3) 运算规则.图3中op模块定义运算规则,可以代替MAC操作并依据特定量化方法的数据格式进行定制.FAQ-CNN中提供了2种不同粒度的op运算,有关op运算操作更多的实现细节将在3.1节进行详细讨论.
4) 算子融合.FAQ-CNN将激活与池化操作直接融合到卷积层或全连接层的后处理阶段.该方式能够充分利用FPGA片上资源,减少片上存储器和片外存储器的数据传输次数,从而快速处理此类计算任务.此外,在FAQ-CNN流水线处理流程中,计算阶段和数据加载阶段是主要的耗时阶段,而后处理阶段并不耗时,因此将激活层和池化层的计算任务融合到卷积层或者全连接层的后处理阶段,不会影响FAQ-CNN流水线处理性能.
2.3 通信带宽优化
CNN参数量庞大,但FPGA片上存储资源有限,难以容纳如此众多的参数,因此张量数据须放置于片外存储器以备访问.FAQ-CNN为了充分利用数据传输带宽资源,采用将多个数据项打包合并成1个宽字(例如512 b的字)的方式,在1个时钟周期内批量地传输数据,以此来提高数据传输效率.FAQ-CNN依据CNN模型数据特征设计了2种便于高效读写的数据编码规则和相应的并行解码方法,并充分利用猝发传输的优势来进一步提高宽字传输效率.
1) 编码规则.FAQ-CNN采用2种编码规则来处理不同场景的张量数据,分别是分级编码和位宽无关编码.考虑到实际应用场景的位宽限制,分级编码采用3种不同的位宽来编码数据,如图4所示,分别是低位宽lbit,次高位宽qbit和高位宽hbit.低位宽的lbit数据是真正需要访问的数据,高位宽的hbit数据是所要传输的对象数据.多个lbit的数据首先被编码为1个qbit的数据,然后多个qbit的数据再被编码为hbit的数据.在解码时,可根据分级规则来读取实际数据,即按qbit直接读取(一般为32 b),然后再逐个读取lbit的数据.位宽无关编码则是将多个lbit的数据直接编码为1个hbit的数据,在解码时可直接读取每一个lbit的数据.2种编码规则在遇到多个数据项的比特位之和不足以填充目标位宽时,将采用无效值0作为填充项.
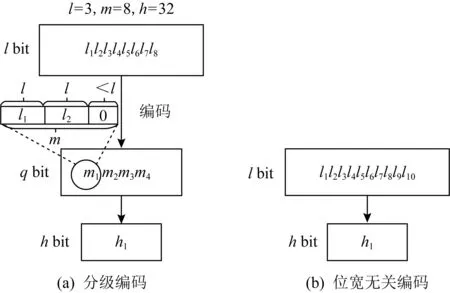
Fig. 4 Encoding scheme图4 编码规则示意
FAQ-CNN采用位宽无关编码方式处理权重数据,而对输入特征图和输出特征图数据则采用分级编码方式.这是因为,对于权值数据来讲,在模型推理过程中只需加载一次并保持不变,采用位宽无关编码方式可以最大限度地利用带宽资源,避免填充大量无效值0.对于输入特征图和输出特征图数据来讲,相比于权重数据,特征图数据的数据项较少且维度不同,数据在线重组织会引入较高的时间消耗,而分级编码方式适用于来自不同维度的少量数据项,且能有效减少无效数据,支持特征图数据的实时处理.以输出特征图为例,图5展示了具体的分级编码流程,输入特征图亦可按类似方式进行处理.
2) 并行解码.片上与片外的数据交换性能除受带宽利用率的影响外,还取决于数据的解码速率.FAQ-CNN中的编码数据对象是多维张量,对这些多维张量数据在同周期内并行解码将极大提升数据交换性能.为避免并行解码引起片上存储资源访问冲突,FAQ-CNN将宽字数据的各个数据项存放在FPGA上的不同存储区域(bank)来解决此问题.FAQ-CNN解码时利用资源复用机制同时支持解码和计算引擎对存储资源的访问,从而降低总体资源消耗量.
具体来说,对于模型权重数据,FAQ-CNN解码时沿着数据的输入通道和输出通道的维度进行访问,并采用与计算引擎相同的数组分割规则以便并行执行,具体过程如图6所示.尽管对输入特征图和输出特征图亦可沿着通道维度并行解码,但是,考虑到输入特征图和输出特征图的数据拷贝方式是每次只传输通道维度的部分数据,如果沿着通道维度进行编解码,在传输过程中将会出现大量的碎片化数据,导致传输性能大幅降低.虽然数据重组织能够缓解数据碎片化的问题,但会引起额外的时间消耗.因此,对于输入特征图和输出特征图数据,FAQ-CNN解码时沿着特征图数据的列维度处理,既能连续读取数据,又能有效支撑并行执行.在实际应用中,为减少列维度数组分割因子的大小,采用适当的编码位宽来满足数据高效传输的需求又不消耗过多的片上存储资源.
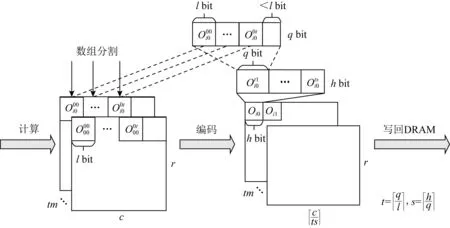
Fig. 5 Encoding detail of output feature map图5 输出特征图编码细节

Fig. 6 Decoding detail of model weights图6 模型权值解码细节
3) 猝发式传输.利用猝发式传输的方式可提高数据传输性能,尤其对于宽字传输更为有效.猝发式传输高效与否取决于猝发传输长度的具体设置,而猝发传输长度的取值受片外存储和访问方式的制约,2.4节中将讨论提升猝发传输长度的存储策略.本文前期初步探究了不同传输位宽和猝发传输长度在200 MHz频率下的实时带宽情况,如图7所示.可以看到,带宽峰值会随着位宽的增加和猝发传输长度的增加而提升.当位宽增加时猝发传输长度对实时带宽的影响更加明显.因此,FAQ-CNN通过提升猝发传输长度来利用猝发传输的优势进一步提高宽字传输效率.
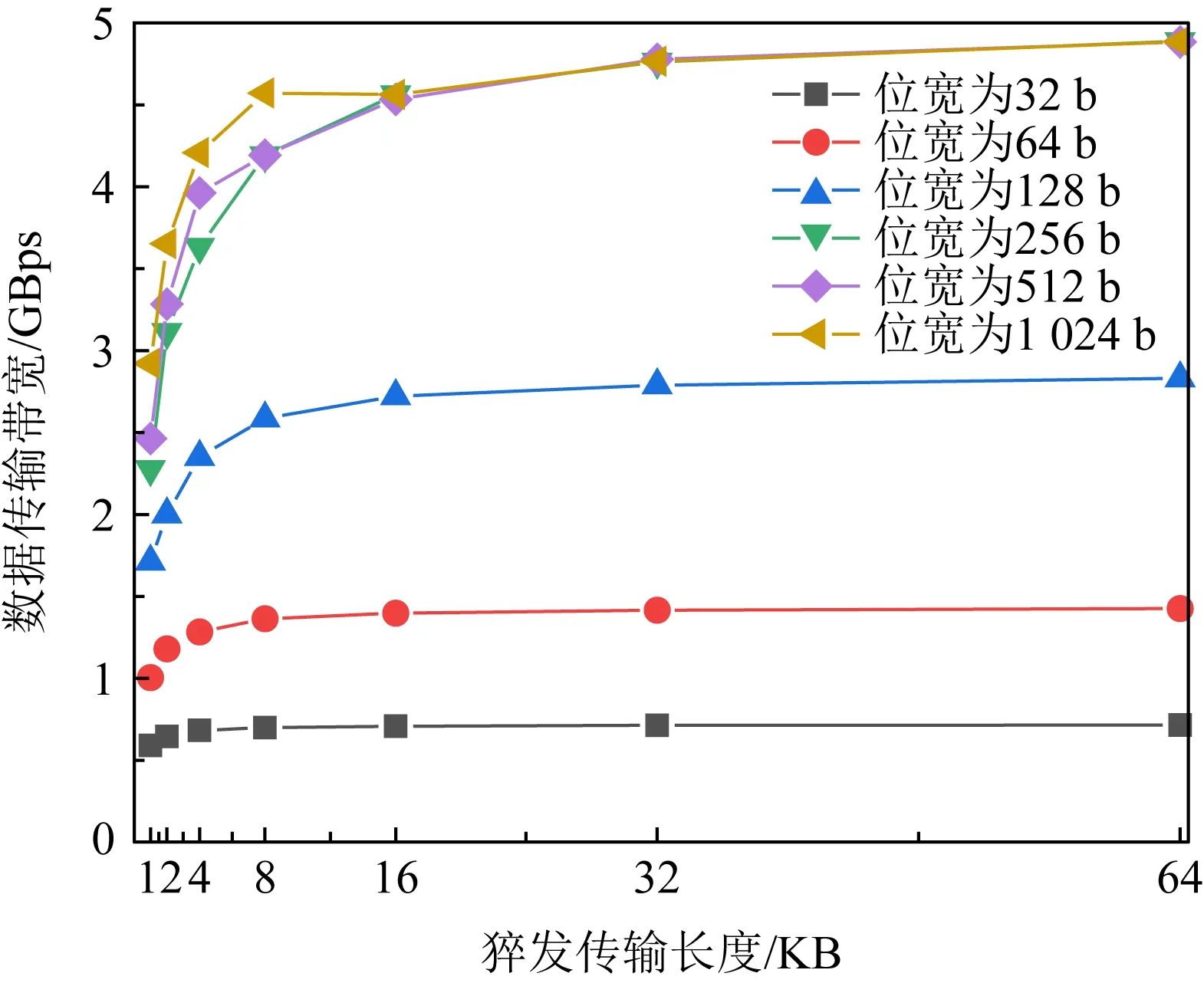
Fig. 7 Bandwidth of different bit width and burst lengths图7 不同位宽和猝发传输长度下的带宽
4) 传输频率.数据中心的FPGA平台能够支持最大512 b的数据传输位宽,Zynq系列嵌入式FPGA的数据传输接口支持位宽有限,通常不超过256 b或128 b[43].因此,为提高数据接口读写效率,FAQ-CNN利用异步时钟传输方式,并在AXI传输总线的路径上添加时钟转换器和位宽转换器来弥合通信接口速率差异,从而提高FPGA片外存储器的数据读写速率.例如,片外存储器的工作频率设定为FPGA片上存储器I/O端口频率的2倍甚至更高,以支持快速读写.
2.4 数据存储优化
数据存储方式是影响加速器性能的另一重要因素.针对片上存储,FAQ-CNN避免硬件资源访问端口数目限制导致的数据访问冲突,设计满足单周期多数据访问需求的存储方案.对于片外存储,数据重组织机制用于保证数据分布连续性,提升数据通信效率.FAQ-CNN针对片上存储和片外存储2个方面进行联合优化.
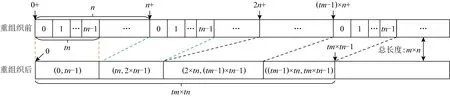
Fig. 8 Weight reorganization of fully connected layer图8 全连接层权值重组织过程
1) 片上存储.在2.2节中,计算引擎沿数据的通道维度并行访问张量数据.因此,为避免访问冲突,不同通道的数据必须位于不同的存储资源块中.具体优化时则利用pragma指令将张量数据沿通道维度进行数组分割.需要注意的是,对卷积层的权重、输入通道和输出通道同时进行数组分割将造成片上存储压力.为减少存储资源消耗,FAQ-CNN设计了2级缓存机制,将从片外存储器拷贝的大块数据用高位宽模式缓冲于片上存储中.2级存储主要面向计算引擎,依靠LUT资源实现.1级存储既可以利用LUT资源也可以利用BRAM,实际使用时需要根据片上资源消耗的情况来进行配置,同时还需决策是否对权重进行双缓冲.在3.3节中,本文将通过设计空间探索来具体阐述资源配置优化的实现细节.
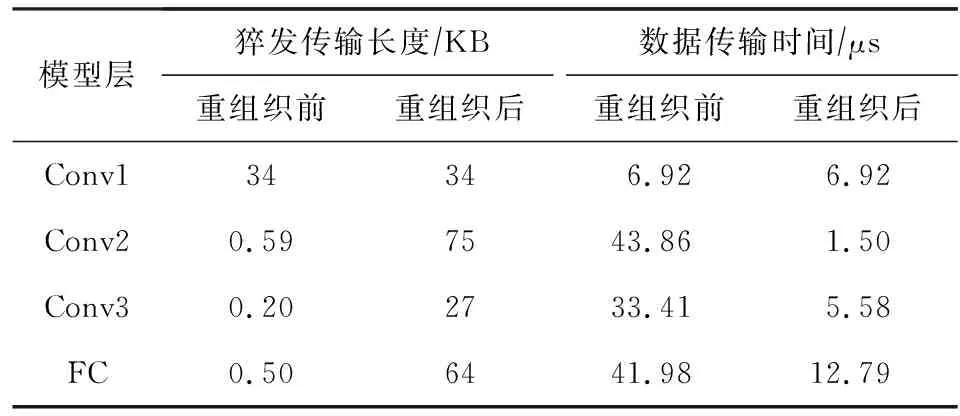
2) 片外存储.由于切片方式的设计,FAQ-CNN对多维张量的数据访问具有局部性.如图8所示,FAQ-CNN每次所访问的原始数据在片外存储器中是非连续存放的.图8中使用地址偏移量表示的数据是全连接层流水线处理过程中的一次迭代中需要传输的数据,可以明显地看到数据是碎片形式分布的.和图8全连接层的权值相比,卷积层的权值仅多了卷积核行和列2个维度,权值访问同样存在数据碎片化的问题.在2.3节中提到,猝发传输长度直接影响实时的数据传输带宽,而猝发传输长度取值受片外数据存储方式和访问方式的制约,碎片化数据访问模式将严重降低数据传输性能.为了最大化数据传输硬件资源的性能,FAQ-CNN利用重组织操作将片外存储碎片化的数据进行整理,形成连续的数据分布.图8显示了全连接层权值数据的重组织过程,FAQ-CNN根据数据访问方式,将每次需要传输的数据按照地址连续的方式存放于片外存储器中.片外数据经过重新组织后,可有效利用猝发传输长度机制来提高实时带宽.由于CNN模型在处理图像分类任务时,其权重数据的访问保持恒定顺序,因此数据重组织的处理只需要离线执行1次.一旦经过重组织,权值数据加载到片外存储器后每次需要访问的数据是地址连续的.模型中卷积层权重数据的具体处理过程如算法1所示:
算法1.卷积层权重数据重组织算法(CWRA).
输入:原始权重张量W、权值位宽bwl、编码后的位宽bwh、输出通道数m、输入通道n、输出通道切片因子tm、输入通道切片因子tn;
输出:重组织后的权重张量W′.
①weight_num←bwh/bwl;
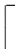
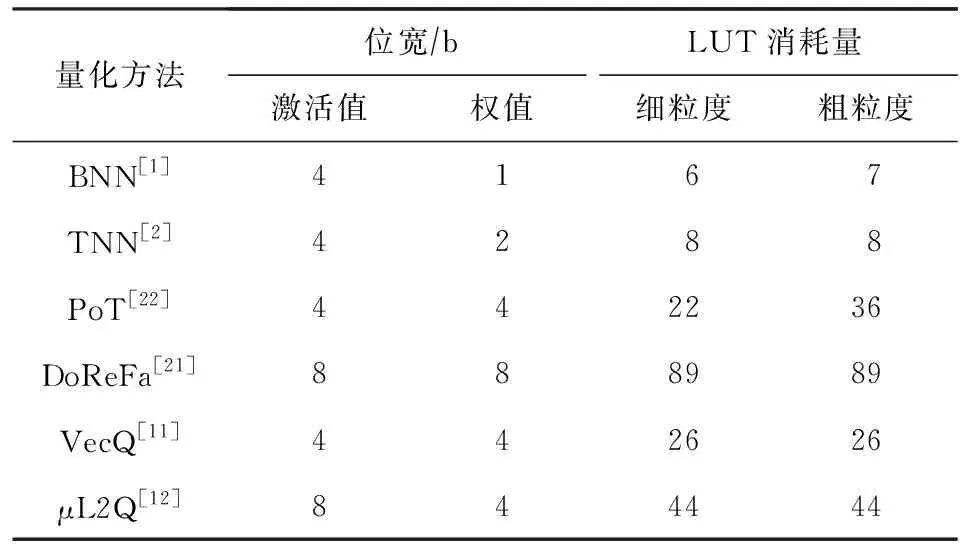
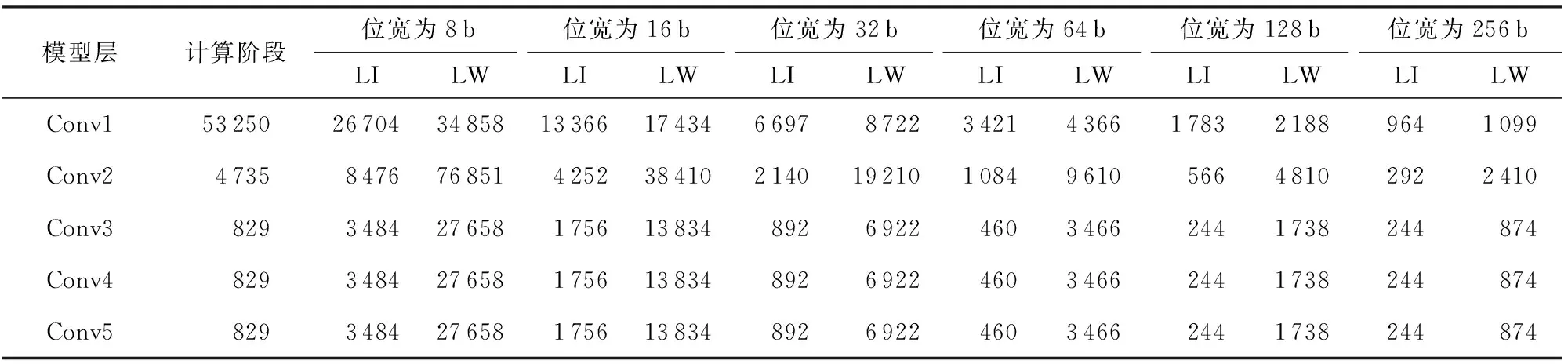
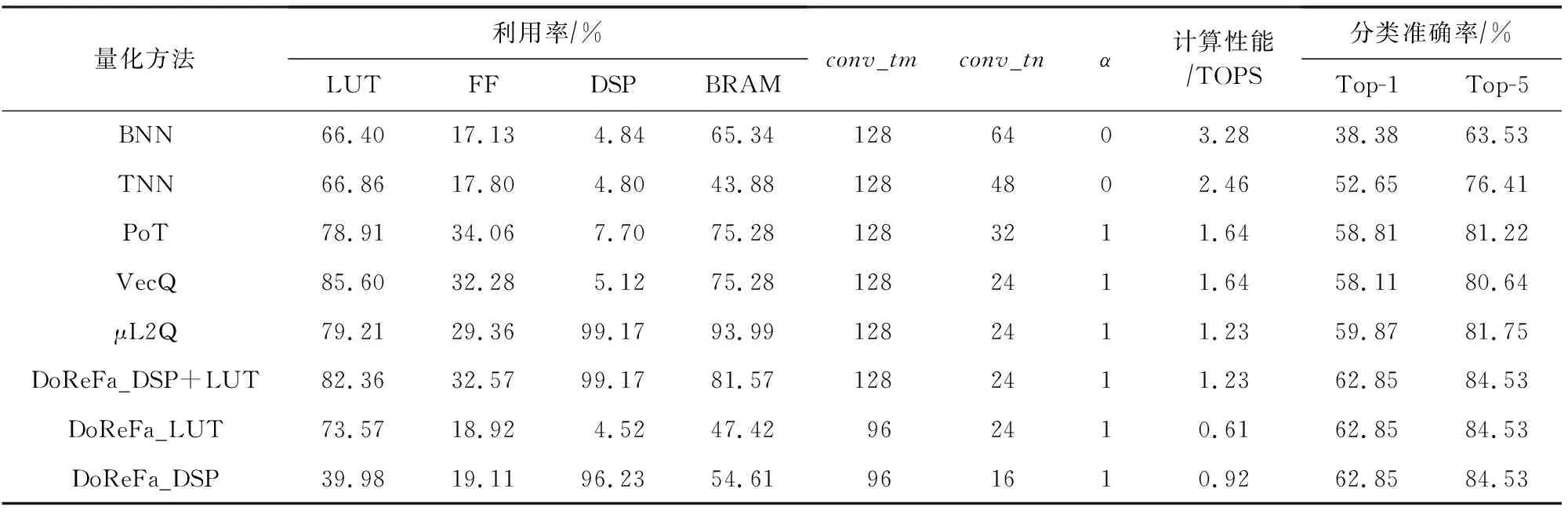
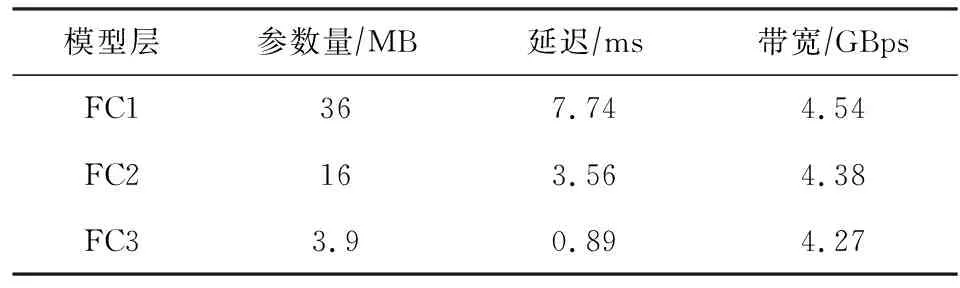
⑤ for alli ⑥ for allti ⑦ for allto ⑧temp←0; ⑨ for alls ⑩ 使用bo,bi,i,ti,s计算源index; 本节分别从加速器的量化方法适配、片上资源建模和设计空间探索3个方面来阐明FAQ-CNN框架实现过程.为了适配多种量化方法,FAQ-CNN框架通过模板将量化方法自身的具体操作抽象成量化组件.为优化FPGA片上资源的配置,FAQ-CNN对资源消耗情况进行建模,采用启发式规则来降低搜索规模,并利用CPU-GPU异构平台快速寻找最佳配置. 为了适配各种量化方法,FAQ-CNN中的量化组件需要与计算引擎、数据引擎等模块解耦.FAQ-CNN通过模板化的方式将量化组件分解为数值映射与运算规则,量化算法能够灵活地适配到FAQ-CNN框架中,并定制CNN加速器. FAQ-CNN主要考虑量化后数值的数据位宽和数据格式,因为数据位宽会影响数据拷贝的方式进而影响传输效率,尤其处理宽字数据时更为敏感,借助2.3节中的编解码方案可以屏蔽底层数据传输时的位宽差异.每种量化方法都有其独特的数据格式,而数据格式会影响到数值映射方式和相应的运算规则.例如,BNN中的1 b用于表示数值1和-1而不是0和1,所以运算时需要用-1来替代0[1].与之不同的是,PoT量化方法的数值位表示2的幂,且最高位用作符号位,所以运算时需要进行移位等操作[22].为应对数据位宽和数据格式的变化,FAQ-CNN分别实现了粗粒度和细粒度的量化方法适配方案. FAQ-CNN中的粗粒度适配方案能够快速且简便地定义数值映射和运算规则,即将量化后的目标数值转化为可直接参与MAC操作的补码数值,然后在运算时对补码数值直接进行MAC操作.对于数值映射,线性量化过程通常包含缩放(scale)、截断(clip)和取整(round)三个步骤.通过这3个步骤,FAQ-CNN可得到补码数值,然后利用逆变换规则,将补码数值转换为目标数值则可得到最终结果. 然而,粗粒度的解决方案无法应对复杂的量化方法,例如基于K-means的量化[44].这类量化方法通常需要提供完整的量化规则才能完成相应的数值映射.因此,为支持细粒度量化方法适配方案,FAQ-CNN将数值映射和运算规则封装成抽象接口函数来支持具体的量化方法实现.对于数值映射,FAQ-CNN提供全精度输入和量化后的低精度输出,接口函数负责完成全精度数值向低精度输出的投影(project);对于运算规则,FAQ-CNN提供2个低精度的量化数值和1个全精度的输出数值,该接口函数负责完成低精度数值的乘法操作并把乘法结果累加到单精度32 b浮点数表示的输出数值上. 嵌入式FPGA上的片上资源有限,因此实现方案要充分利用这些资源才能达到最佳性能.在具体方案实现过程中,为了提高资源利用率和模型推理性能,FAQ-CNN通过对资源消耗分析并构建资源模型来寻求最优的资源配置.FPGA片上的主要资源为DSP,BRAM和LUT,因此FAQ-CNN将它们作为资源模型的主要分析对象.此外,还需要结合FAQ-CNN中卷积层与全连接层的未确定的切片因子,才能构建FAQ-CNN的资源消耗模型.为方便理解,定义切片因子四元组 tFAQ-CNN=conv_tm,conv_tn,fc_tm,fc_tn, (1) conv_tm,conv_tn,fc_tm,fc_tn分别代表卷积层的输出通道和输入通道的切片因子以及全连接层输出向量和输入向量的切片因子.实际上,全连接层的操作可以复用卷积层的计算引擎来实现,即可将全连接层的操作转换为卷积操作,以减少FAQ-CNN中的资源占用.因此,全连接层的切片因子fc_tm和fc_tn可配置为0.对于以卷积层为主的CNN模型,这种复用机制非常有效.下面着重分析DSP,BRAM,LUT的资源使用场景并构建资源消耗模型.对应FPGA模块调用的设计模式,FAQ-CNN采用树状自顶向下的方式分析总资源消耗. 1) DSP模型.DSP资源的使用分为2部分:①与卷积层和全连接层的乘法有关,该部分DSP消耗量可由切片因子四元组tFAQ-CNN直接表示;②用于数组索引等计算,与切片因子四元组无关.因此,DSP的资源模型可表示为 (2) 2) BRAM模型.在FAQ-CNN实现时,BRAM用于存储大块数组数据.BRAM有3种不同的配置模式,分别是:①单端口(SP);②真双端口(TDP);③简单双端口(SDP)[45].3种模式所支持的读写方式和存储形式不同,因此BRAM的使用量与配置模式密切相关.此外,数组分割因子也会影响所需的bank数量,而bank数量可直接反映消耗多少BRAM.BRAM的总消耗量可定义为 (3) (4) (5) 其中,data_bits是张量元素的位宽,buff_size表示输入张量、输出张量或者权重张量的大小,而width和depth取决于BRAM各种配置模式中块BRAM的宽度和深度,pf表示数组分割因子.由于输入特征图数据和模型权重只进行读操作,所以使用单端口的存储模式即可.输出特征图的数据包含累加操作,所以需要真双端口的模式支持单周期的读写.以此类推,也可为全连接层构造BRAM资源消耗模型.全连接层是通信密集的,FAQ-CNN需要传输大量的权值数据,因此权值使用BRAM资源存储并进行双缓存,输入向量和输出向量在寄存器资源中缓存确保并行访问. 3) LUT模型.FAQ-CNN在循环控制、循环内部模块设计、BRAM、寄存器和独立的表达式逻辑中都使用到LUT资源.事实上,几乎所有的模块设计都会用到FPGA中的LUT资源.因此,准确构建LUT资源模型十分重要.FAQ-CNN通过理论分析和Vivado[43]综合工具来联合构建LUT资源模型.首先,借助文献[14,17]的分析模式给出LUT资源消耗的参数化表示方式;然后,利用Vivado工具获得表示方式中的未知参数,并将这些参数作为常数来形成最终的资源模型.LUT资源的总消耗量可被定义为 (6) (7) (8) (9) (10) 在构建资源模型后,FAQ-CNN通过探索设计空间确定卷积层等资源最佳配置方式,实现CNN推理延迟最小.根据2.1节中的数据流调度规则,FAQ-CNN利用流水线模型来表示总延迟.CNN模型中某i层计算延迟和CNN模型中所有层的处理延迟总和被定义为 (11) 其中,β是流水线的迭代次数.流水线迭代计算2批不同输出数据的间隔时间,取决于流水线4个阶段中时间消耗最多的环节.依据3.2节中已构建的资源模型,FAQ-CNN将资源配置设计空间搜索问题转换为整数非线性规划(integer nonlinear programming, INLP)问题,即: 目标函数 min:latencytotal, 约束条件 (12) pf_min (13) 对于全连接层,可在每次迭代期间计算出fc_tm个元素.为了计算输出向量的所有元素,需要将迭代次数向上取整.如果元素总个数不能被fc_tm整除,则向上取整操作必然会引入无效计算.因此,限制fc_tm来减少无效操作: (14) 其中,fc_m表示全连接层输出向量的最大长度.fc_tn可以使用相同的方式约束.通过式(14)的约束条件,AlexNet的搜索空间规模可由1013降低到109.此外,本文在FAQ-CNN实现时利用CPU-GPU异构平台来加快参数搜索过程.在CPU端计算可行解并借助约束条件完成设计空间剪枝,然后在GPU端来验证可行解并寻找最优解.借此,AlexNet[42],VGG16[46]等典型模型只需花费数秒即可完成配置参数搜索. 本节通过实验验证FAQ-CNN性能收益,并通过设计空间探索实验来论证FAQ-CNN的资源配置方法.首先,介绍实验所需软硬件配置,并选取典型量化方法作为FAQ-CNN加速器设计的实现对象.其次,通过7组不同传输位宽配置的实验来观测FAQ-CNN编解码方案对硬件加速器的数据传输效率的性能增益.再次,呈现各种量化方法在不同位宽下完成单个MAC操作所需的资源情况,并依据资源模型探究资源的整体消耗情况.最后,通过寻找片上资源最佳配置,并与其他最新方法进行性能对比,明确FAQ-CNN的性能优势. 1) 软件环境.实验采用集成开发环境Vitis 2020.1[47]进行FPGA加速器设计.通过编程语言C++设计各模块,并利用Vitis HLS工具来进行高层次综合. 2) 硬件环境.实验采用Xilinx ZCU102 SoC FPGA开发板作为硬件加速器验证平台,FPGA的运行频率设定为200 MHz.此外,配备工作站运行Vitis软件,搭载Intel Xeon Silver 4210 CPU@2.20 GHz和64 GB DDR4内存.配备1块GeForce RTX2080Ti GPU显卡,用于搜索参数配置. 3) CNN模型与量化方法.选取AlexNet模型和当前业界经典的CNN量化方法,这些量化方法的激活值和权值的位宽配置如表1所示: Table 1 Bit Width and LUT Consumption of DifferentQuantization Methods’ MAC Operation表1 不同量化方法乘累加操作的位宽配置和LUT消耗 4) 评估指标.FAQ-CNN的实验评估选取3个定量指标来观测和分析FAQ-CNN的性能收益. ① 数据传输效率.为了验证FAQ-CNN的编解码方案能够有效提升数据传输效率,实验以量化方法DoReFa的加速器为例,来探究各种编解码位宽对加速器的数据传输速度的影响. ② 片上资源利用率.该指标能够反映FAQ-CNN所实现的低位宽加速器在完成单个MAC操作后的资源消耗情况及该加速器的整体资源消耗情况,资源利用率数据可由Vivado综合工具得到,能够准确反映FAQ-CNN是否高效利用FPGA片上资源. ③ 每秒运算次数.该指标能够反映FAQ-CNN所实现的低位宽加速器的峰值计算性能和CNN模型中各卷积层的实时计算性能. 依据2.3节给出的编解码规则,高位宽字的位个数会直接影响数据传输的效率.本节实验通过评测数据传输的执行时间,来探究编解码位宽对数据传输效率的影响.在CNN卷积层流水执行过程中,主要包含3个阶段,分别是computing,loading input,loading weight,其中loading input和loading weight阶段负责加载输入特征图和权值数据到片上存储,占据数据传输的主要部分.首先,根据搜索工具获得的最佳配置来设定卷积层的输入通道和输出通道的切片因子,分别设置为24和128.在此基础上,computing阶段的时间会确定下来.然后,对不同位宽下的loading input和loading weight的时间进行评测. 以DoReFa量化算法为例,实验结果如表2所示,可以看到施加编解码之前,即数据的实际传输位宽和数据的位宽相同时,数据传输的时间远远高于计算所需时间,成为CNN计算耗时的主要原因.随着位宽的提升,数据传输耗时不断降低.从表2可知,当权重使用256 b的传输模式时,对于AlexNet的5层卷积层,数据传输的能力都可满足计算引擎的需求,此时编解码技术理论上带来的增益是未使用编解码时的32(32=256/8)倍.对于输入特征图,当数据编码位宽设置为32 b即可满足数据传输需求,此时编解码技术提升4倍的传输速度. Table 2 Clock Cycle of Computing, LI(loading input) and LW(loading weight) Phases表2 计算、LI(loading input)和LW(loading weight)三个阶段的时钟周期数 2.3节中明确指出权重数据的编解码是沿着通道维度进行的.当编码位宽采用256 b时,FAQ-CNN要求片上权值的存储资源在输入或者输出通道上的数组分割因子是32.因为计算引擎的并行能力是24×128,即要求权重数组在输入通道的数组分割因子是24,在输出通道维度的数组分割因子是128,所以通过复用的机制对权重数据编解码时沿着输出通道进行对数组的分割程度最小,即会使用最少的存储资源.对于输入特征图,数据张量的存储方式在列维度数组分割因子是4,尽管无法满足计算引擎所要求的数组分割规则,即无法在通道维度上进行资源复用.但是,仍可通过使用较低的输入切片因子降低对输入特征图的数组分割因子,从而降低存储资源的需求.在输入切片因子较低时,使用较高的输出切片因子保证较强的并行能力. 本节实验测量多种经典量化方法中单个MAC操作的LUT资源消耗量,用来指导LUT资源配置方式和构建资源模型.给定的操作数位宽下,分别使用细粒度和粗粒度2种方式完成各种量化方法的MAC操作.实验采用Vivado来获取准确的资源消耗量. 实验结果如表1所示,对于BNN和PoT算法,粗粒度方式比细粒度方式完成MAC操作需要更多的LUT资源,这是因为它们的数值不能直接参与MAC操作.粗粒度计算模式中需要中间转换步骤,例如BNN算法需要将1 b的0转化为2 b的-1,而细粒度计算模式中通过定制的计算方式完成MAC操作.BNN只需要判断1 b的操作数为0或者1,然后选通另一操作数原值或者取反后的值. 此外,可看出操作数位宽最低的BNN量化算法需要最少的LUT数量,在细粒度模式下只需要6个LUTs就可以完成MAC操作.操作数位宽相同的PoT量化算法和VecQ相比,PoT算法的MAC操作需要更少的LUT资源.PoT的数值表示的是2的幂次方,乘法操作可通过高效的移位操作来代替.对于激活值和权重配置为8 b的DoReFa量化方法,MAC操作需要89个LUTs来完成.由于LUT资源总量有限,优先选择使用DSP资源来实现8 b的MAC操作. 本节实验部署多种量化算法到FAQ-CNN框架中,得到不同量化算法的加速器并统计相应的资源消耗量和计算性能.片上资源面向AlexNet模型进行配置且该模型用于评估各种量化算法的分类准确率.为了探究同时使用DSP和LUT这2种资源完成计算带来的收益,利用3组实验对比8 b的DoReFa量化方法加速器的资源消耗和性能,分别是只使用DSP、只使用LUT、联合使用DSP和LUT完成MAC操作.对于其他低位宽的量化算法,仅使用LUT资源完成MAC操作.最后,选择FAQ-CNN框架实现的3种加速器与Caffeine等量化加速器的性能进行对比. 表3中显示了各种量化算法加速器的资源利用率、峰值计算性能以及分类准确率.位宽配置最低的BNN加速器可以实现3.28 TOPS的峰值计算性能,其中LUT资源使用率最高达到了66.40%,仅使用少量的DSP资源.但是,BNN量化方法会严重降低分类精度导致无法保证应用需求.当部署8 b的DoReFa量化算法时,可获得1.23 TOPS的峰值计算性能,且CNN推理精度损失极小.此外,从DoReFa量化算法的3组实验可以看到,当只使用DSP或者LUT的时候都不能完全发挥片上资源的计算能力.当所有MAC操作使用DSP资源执行时,加速器设计仅使用了39.98%的LUT资源.同样,当所有MAC操作使用LUT资源执行时,加速器设计仅使用了4.52%的DSP资源.由此可见,这2种设计方式对片上逻辑资源使用都极不充分.在联合使用DSP和LUT完成MAC操作时,LUT资源和DSP资源的使用率分别达到82.36%和99.17%,该设计能够显著提升计算引擎的计算能力. Table 3 Resource Consumption Utilization, Hardware Configuration and Computing Performance ofDifferent Quantization Methods Accelerator表3 不同量化方法加速器的资源消耗率、硬件配置和计算性能 卷积层输入通道并行因子;α表示权值存储模式(0表示LUT单缓冲,1表示LUT双缓冲). 表4展示了采用DoReFa量化算法的FAQ-CNN与相关量化加速器的性能对比,Caffeine[13]和AccELB[27]加速器的时钟频率同样为200 MHz.Caffeine[13]采用高位宽16 b的数据配置,AccELB[27]采用低位宽8 b和2 b的数据配置.在2 b数据配置下,FAQ-CNN和AccELB[27]相比,计算引擎完全采用LUT资源完成计算,其他模块仅使用少量的DSP资源.在16 b数据配置下,FAQ-CNN受限于存储资源限制实现和Caffeine接近的性能.在低位宽8 b数据配置下,FAQ-CNN充分利用DSP资源和LUT逻辑资源实现1 229 GOPS的计算性能,和采用16 b的Caffeine相比,峰值性能提升至3.6倍. Table 4 Computing Performance of FAQ-CNN andOther Quantization Accelerators表4 FAQ-CNN与相关量化加速器计算性能对比 由于参数的设置面向特定的CNN模型,虽然增大并行参数能够增强峰值计算性能,但是并不能增强实时处理性能.这是因为采用切片的方法,当通道切片因子无法整除总体通道数目时,必须向上取整计算完所有通道数据,不可避免地引发大量的无效计算.本节的实验是根据具体的CNN模型选取通道切片因子,在保证最佳的实时处理性能时选取最小化资源消耗量,所以片上的资源仍有余量. 本节对低位宽加速器的设计资源消耗量进行建模,并利用自动化搜索工具搜索片上资源最佳配置.采用的量化算法是在AlexNet模型上分类准确率最高的INT8数据类型的DoReFa量化算法.根据搜索到的参数对FPGA进行资源配置,实验结果与采用相同计算引擎的相关研究工作Caffeine进行对比.值得注意的是,Caffeine仅实现了16 b的AlexNet网络模型.本节利用FAQ-CNN分别实现16 b和8 b的AlexNet模型与Caffeine进行细粒度性能对比.此外,将搜索算法得到的配置代入硬件设计中,分析AlexNet所有层的实时计算性能. Fig. 9 Resource configuration of convolutional layer and full connected layer图9 卷积层和全连接层的资源配置 FAQ-CNN依据搜索工具得到的参数值对FPGA片上资源进行配置,图9显示了卷积层和全连接层的资源配置.值得注意的是,卷积核较大的第1层卷积层单独实现.可以看到计算并行度较高的卷积层使用60%左右的LUT资源和95%的DSP资源,通信密集的全连接层仅使用了10%左右的片上资源.其中,卷积层输出通道切片因子和输入通道切片因子分别是128和24,模型权值使用LUT资源进行存储同时采用双缓冲机制.图10反映了AlexNet模型5层卷积层单层的实时处理性能,表5显示了卷积层的理论峰值性能和5层卷积层的平均计算性能.其中,FAQ-CNN和Caffeine加速器设计的资源使用量显示在表4中.在16 b数据下,FAQ-CNN受限于存储资源限制,实现和Caffeine加速器相近的处理性能.在8 b数据配置下,FAQ-CNN得到卷积层1.23 TOPS的峰值计算性能和490GOPS的平均处理性能.与Caffeine相比,FAQ-CNN使用了2.3倍的DSP计算资源和1.67倍的LUT资源.值得注意的是,8 b数据的乘法和16 b数据的乘法都仅利用1个DSP完成计算.FAQ-CNN的峰值处理性能是采用16 b数据配置Caffeine加速器的3.6倍,其中DSP资源提供了2倍左右的性能增益,LUT资源提供额外的性能增益.因为第1层的输入通道较少,并不适合这种通道并行的设计,得到的实时处理性能只有96 GOPS.除此之外,其他层的实际计算性能和峰值性能差距较小.对于卷积层,由于设计方案中采用流水线的机制,除了指令参数外,其他所有的数据都进行双缓存.通过这种缓存机制,在整个流水线计算过程中,计算引擎在70%的时间内处于活跃状态.在计算方面,FAQ-CNN联合使用LUT资源和DSP资源完成MAC操作的方式可以最大化片上资源带来的计算性能,从而能够实现24×128的计算阵列.在DSP和LUT联合使用时,有多种配置方式,即按照输入通道进行配置和按照输出通道进行配置.由于DSP能够同时完成乘法操作和累加操作,所以在设计中采用输出通道配置的方式会更加有效. Fig. 10 Computing performance of AlexNet convolutional layers of FAQ-CNN and Caffeine图10 FAQ-CNN和Caffeine处理AlexNet卷积层的 计算性能 Table 5 Hardware Platform and Computing Performance of FAQ-CNN and Caffeine 在数据通信方面,对于权重数据来说,通过重组织操作进行预处理,可确保每次所需传输的数据在外部存储器中是连续分布的.表6显示了数据重组织策略对卷积层和全连接层权值通信性能的影响.由于AlexNet第3,4,5层的权值数据传输方式相同,仅以第3层为例进行说明. 从表6中可以看到,重组织后的权值数据在进行数据传输时,猝发传输长度能够有效地提升到27 KB甚至更高,从而能够得到数据位宽为256 b模式下的最高传输带宽4.77 GBps.对于输入特征图,尽管未进行重组织,但是采用的是32 b的数据位宽,依然能够得到该传输模式下的最高带宽715 MBps.表6的数据传输速度足够保证计算引擎对数据的需求.此外,表7显示了AlexNet中的3个全连接层的参数配置和相应的处理时间.可以看到,全连接层的实时平均带宽速度最高达到了4.54 GBps,接近硬件资源能够提供的最大带宽速度4.77 GBps.FAQ-CNN充分利用带宽资源,能够实现全连接层的最低处理延迟. Table 6 Impact of Data Reorganization onCommunication Performance表6 数据重组织对通信性能的影响 Table 7 Realtime Performance of Fully Connected Layers表7 全连接层的实时处理性能 本文提出一种灵活的嵌入式FPGA加速器设计框架FAQ-CNN,从量化方法到硬件加速器设计进行联合优化,支持嵌入式FPGA平台上快速且高效地部署量化CNN模型.FAQ-CNN将量化方法分解为量化数值映射和数值运算规则,并通过模板来统一描述量化方法的实现过程;通过分级和位宽无关2种编码方案与并行解码机制,来提升片上与片外存储之间的数据交换效率;建立FPGA资源和性能的联合优化模型,针对带约束条件的设计空间,采用启发式策略进行裁剪,并利用异构平台搜索最优参数,实现FPGA片上资源的快速配置.实验结果表明,FAQ-CNN能够高效适配多种量化方法,并能实现8 b下高达1.23TOPS的优越性能.FAQ-CNN能够支持相关研究人员快速构建量化CNN加速器,对深度学习及异构计算等领域具有很好的指导意义和研究价值. 作者贡献声明:谢坤鹏提出算法思路,负责完成实验并撰写论文;卢冶提出系统思路、实验方案和指导意见,并修改与审核论文;靳宗明协助完成部分实验;刘义情参与论文校对和图表修正;龚成负责调研和数据分析;陈新伟参与论文校对和实验数据审查;李涛提出方法的指导意见.3 FAQ-CNN框架实现
3.1 量化方法适配
3.2 片上资源模型构建
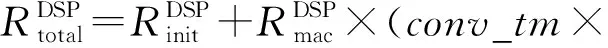
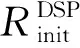
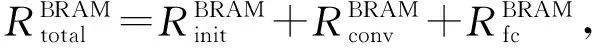
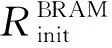
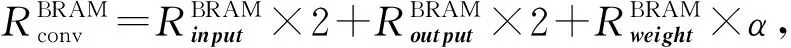
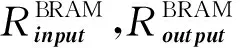
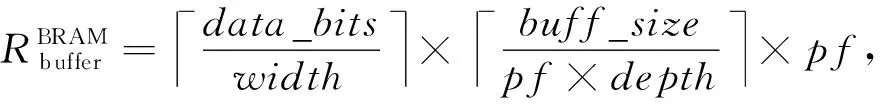
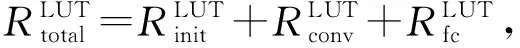
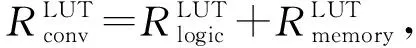
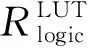
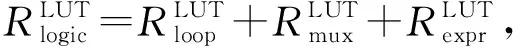
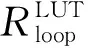
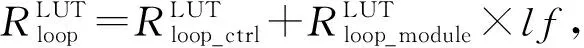
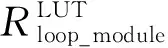

3.3 设计空间探索
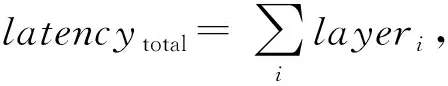
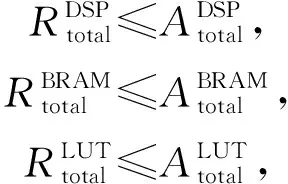
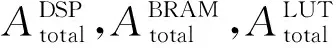
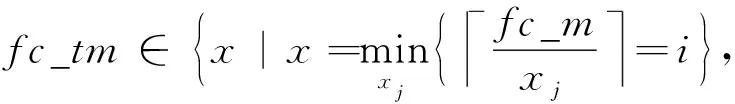
4 实验评估
4.1 实验设置
4.2 编解码效率增益
4.3 MAC操作资源消耗
4.4 卷积层整体开销与性能对比分析
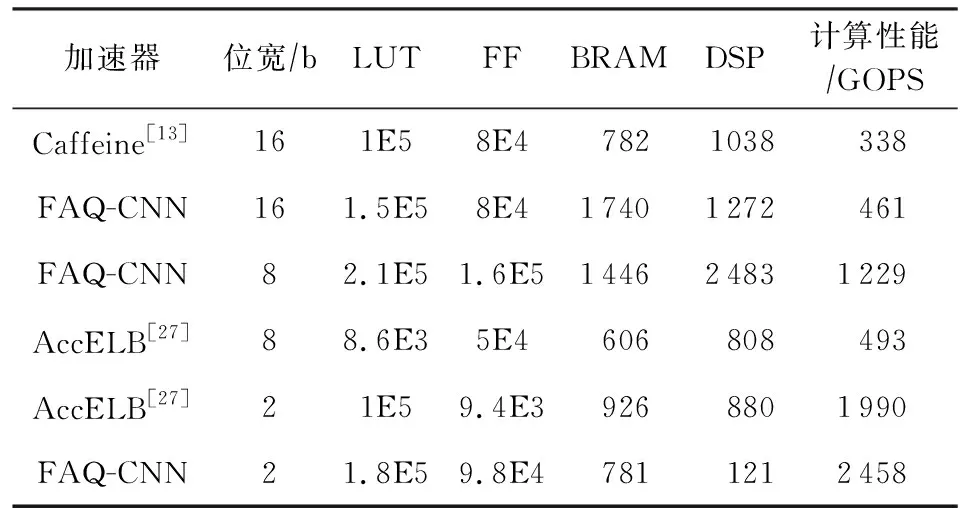
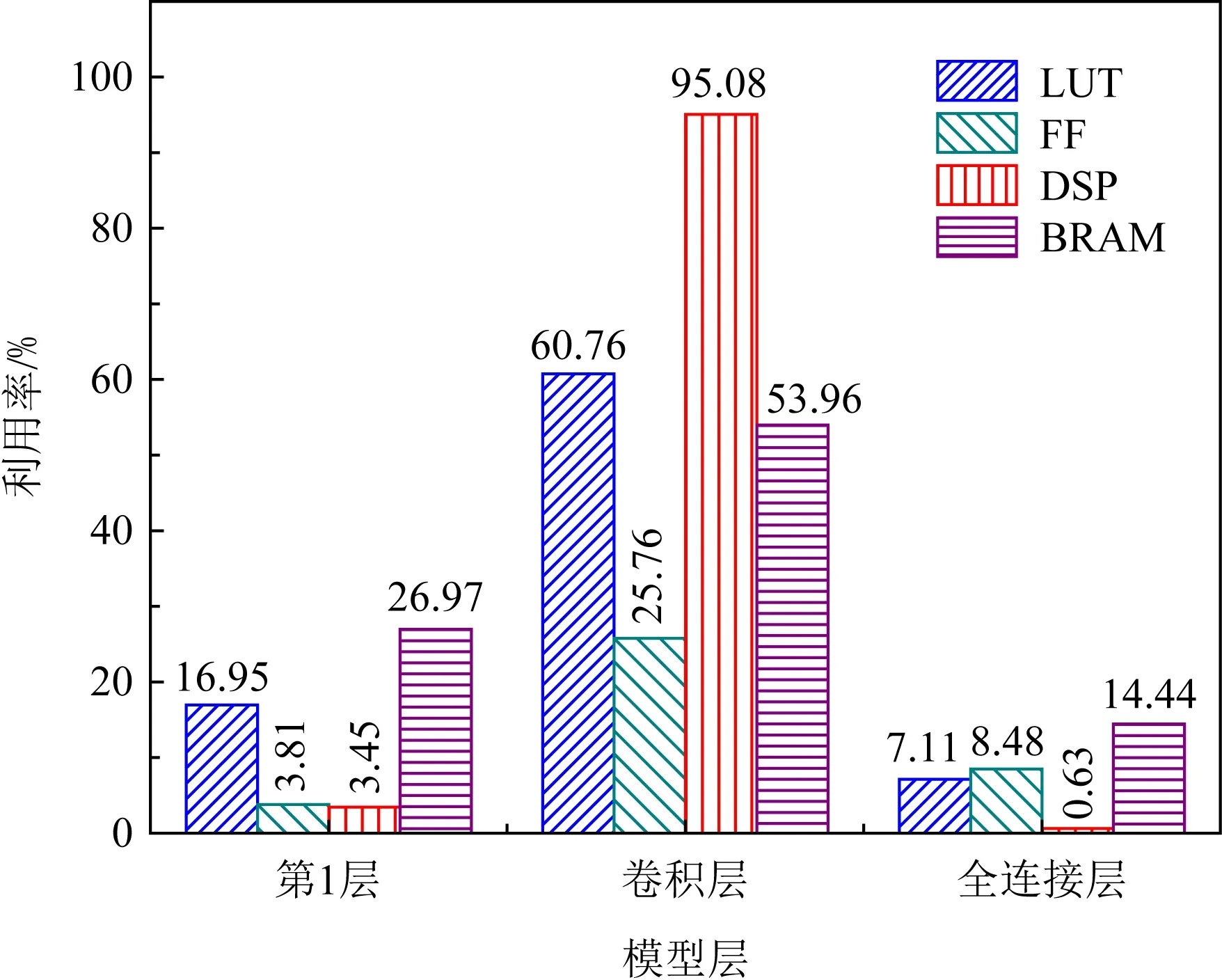
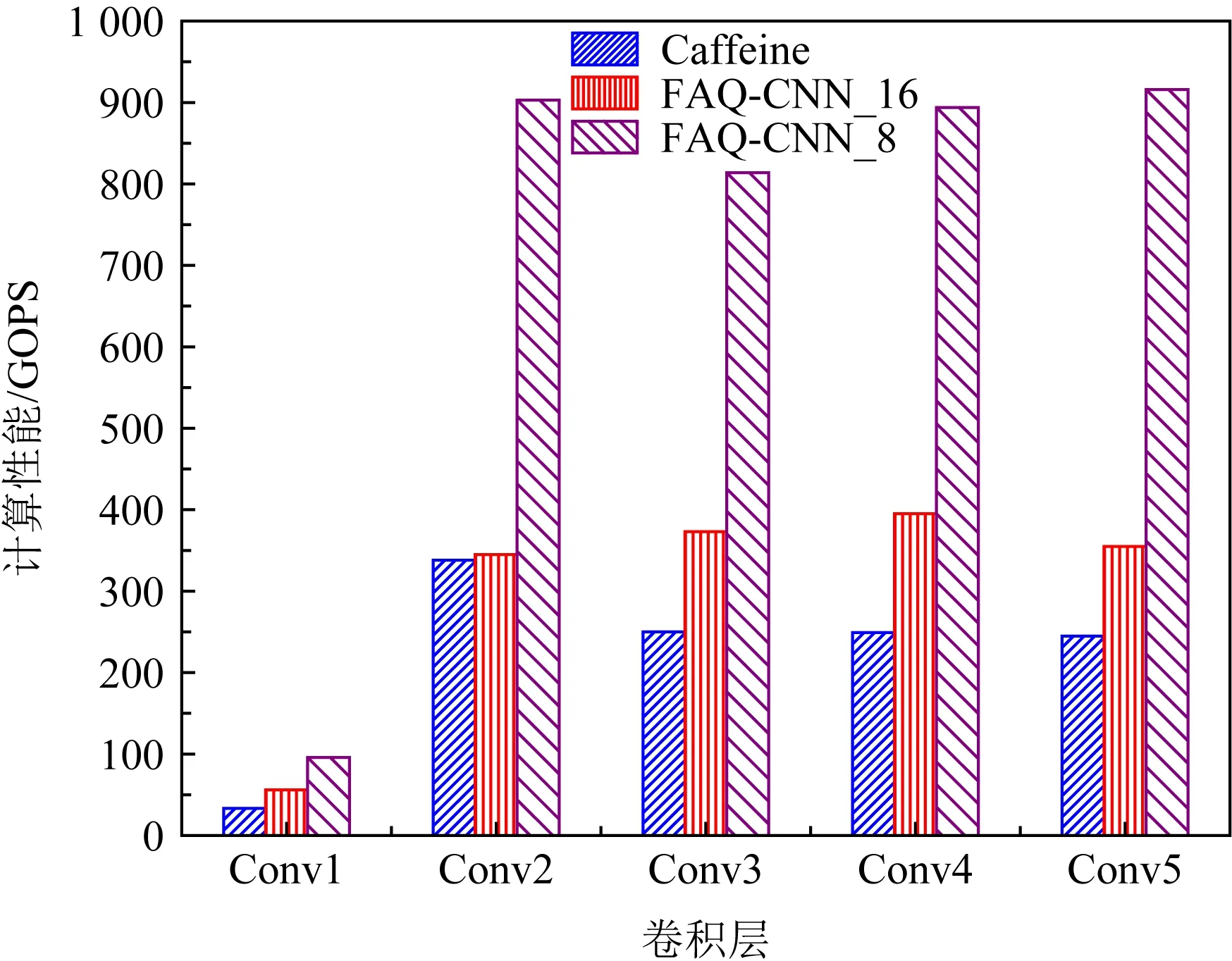
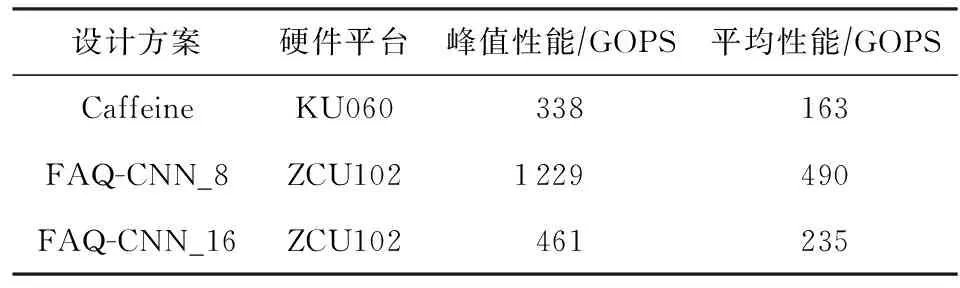
4.5 资源配置优化与性能对比
5 总 结
