基于DBNet和CRNN算法的端到端企业实体识别
2022-07-02王戈黄浩汪沛洁郑昕
王戈,黄浩,2,汪沛洁,郑昕
(1.湖北大学物理与电子科学学院,铁电压电材料与器件湖北省重点实验室,湖北 武汉 430062;2.中国科学院上海微系统与信息技术研究所,无线传感网与通信重点实验室,上海 200050;3.湖北大学计算机与信息工程学院,新能源与智慧物联实验室,湖北 武汉 430062)
0 引言
文本检测是目标检测的范畴之一,与文本检测相关联的概念就是文本识别,可以大致分成专用和通用两种类型.就前者而言,证件识别以及车牌识别就是典型的专用文本识别,其针对特定场景进行设计、优化以达到最好的效果.通用文本识别则拥有比较好的泛性,但由于场景的不确定性,常会造成传统的算法难以达到精度高和速率快的效果[1].随着深度学习的不断发展,文本识别的效果有了质的飞跃.相比于传统算法,基于深度学习的自然场景文本识别算法有着识别精度高、效率高及鲁棒性好等优点[2].基于深度学习的企业实体识别是自然场景文本识别的一个重要领域[3],涉及文字检测、文字识别、命名实体识别等3种技术.这几类方法的优略势[4]对比如表1所示.不难发现,现有方法大多局限于室内或特定情景下,固定形式的命名识别,在准确率和识别速率上还有较大提升空间,难以满足难度更大的自然场景下,存在的光照、文字遮挡、弯曲、背景复杂的企业实体识别[18].因此提出基于DBNet与CRNN,配合CTC loss的检测与识别端到端模型,尝试在企业实体识别领域进行研究,实现准确率和识别速率的优化,且考虑到移动端算力的有限性,在保证精度和速率的前提下,使用MobileNetV3 _large _x0.5作为Backbone.

表1 各类方法优略势对比表
1 文本算法流程
传统的检测与识别算法流程如图1所示,步骤复杂冗余,造成检测与识别的效率低,显然不适合更复杂的自然场景企业实体识别的应用.

图1 传统的检测与识别算法流程
本研究的算法流程如图2所示,整个算法基于DBNet,结合CRNN与CTC loss实现端到端的检测识别.图像输入后,即可依次进入检测模块和识别模块.同时,识别模块能将结果反馈给检测模块,优化检测模块的准确性.依照算法流程介绍检测模块、文本模块2个部分.

图2 本文中算法流程
1.1 文本检测文本检测需要在输入图片中定位文本的位置,并采用一定的算法绘制出包含文字的检测框,为后面的文字检测框矫正和文字识别模块提供输入[19],本文的检测网络结构如图3所示.
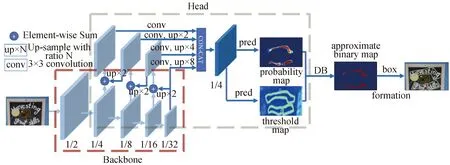
图3 文本检测网络结构
文本检测网络结构的核心就是使用了DBNet算法做分割.如图4所示,大部分分割的检测模型用图4中蓝色流程做后处理,其设置一个固定的阈值,把分割图转化成二值化图,然后用一些启发式的方法(如聚类)把像素处理成文字行;而本文的方法使用的是红色流程,把二值化的操作放到网络里面同时优化,这样每个像素点的阈值都可以自适应地预测,即DBNet主要使用可微分二值化作为基于简单分割网络的文本检测器.可微分二值化公式如式(1)所示:
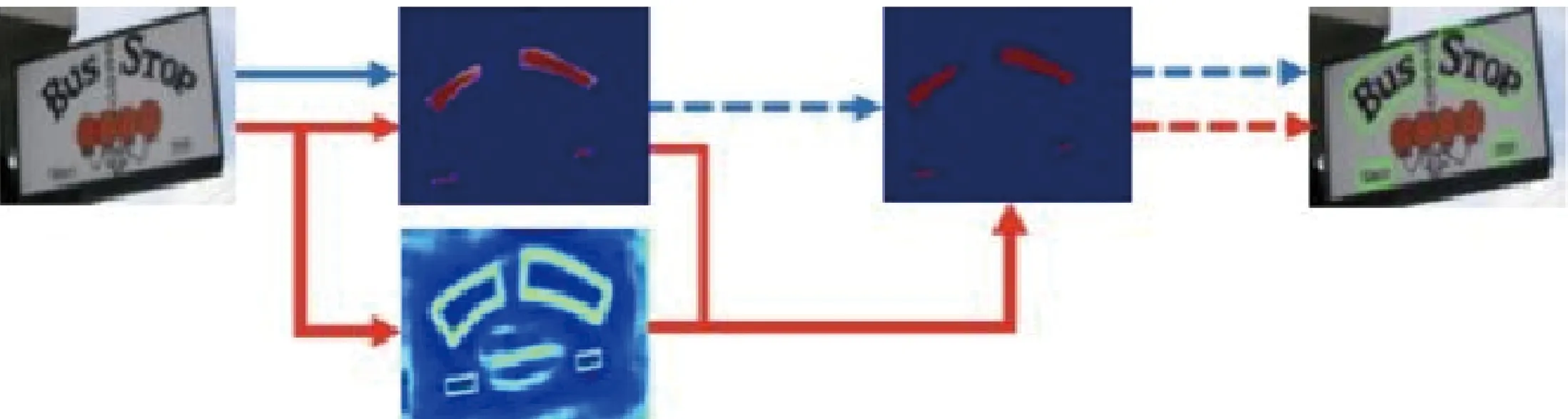
图4 分割网络结构(蓝线为传统流程,红线为本文中流程)
(1)
考虑到移动端的实际算力,Backbone将从Mobilenet系列和ShuffleNet系列中进行选择,各个网络在移动端模型的精度指标与其预测耗时、模型存储大小的变化曲线如图5所示:

图5 不同模型推理精度及时间与模型大小的关系
综合考虑模型大小、精度与推理时间,折中选择MobileNetV3 _large _x0.5作为Backbone.
文本检测器的头部与FPN (Lin et al. 2017)架构相似,融合不同尺度的特征图,以便提高小文本区域检测的效果.为了方便合并不同分辨率的特征图,使用1×1卷积将特征图缩减到相同数量的通道.根据He和Yang等人在2018年MTWI上的文章显示使用学习率预热机制可以帮助提高图像分类的准确率.在训练过程开始时,使用过大的学习率可能导致数值不稳定,因此使用较小的学习率.为了避免模型修剪造成的模型性能下降,本研究使用FPGM (He et al. 2019b)[20]如图6所示,对原始模型中不重要的子网络进行查找.
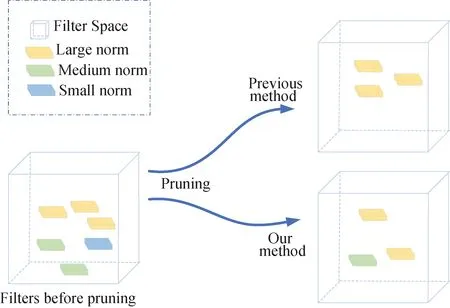
图6 FPGM图
图像经过文本检测模块得到的文本框有可能是倒立的,为了不影响后面的文本识别模块,因此中间需要加入文本框方向矫正模块[21].本研究为了提高方向分类器的准确率,高度和宽度分别设为48和192.同时,对在线量化进行了改进,预先从激活中删除了一些异常值.剔除异常值后,模型可以学习到更合适的定量尺度.对激活值进行预处理的普通PACT法公式如式(2)所示.

(2)
普通PACT法的激活值预处理是基于ReLU函数进行的,所有大于某个阈值的激活值都将被截断.但是MobileNetV3的激活函数有ReLU和Hard swish两种,使用普通PACT量化会导致较大的量化损失.因此,对激活预处理的公式进行了修改,以减少量化损失,并且在PACT量化参数中加入了系数为0.001 的L2正则化,提高模型的鲁棒性.修改后的公式如式(3)所示:
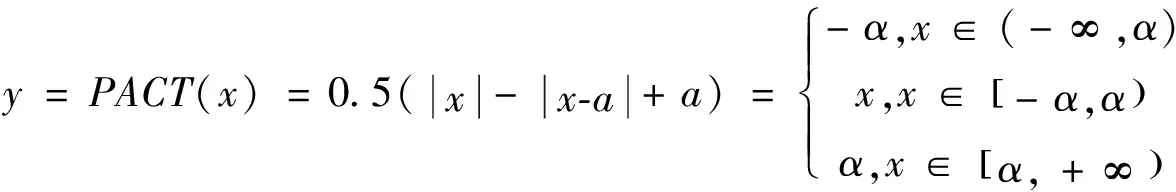
(3)
1.2 文本识别文本检测模块的输出结果将作为文本识别模块输入,文本识别使用CRNN,CRNN是CNN(卷积神经网络)与RNN(循环神经网路)的结合,整个网络结构可以分为3个部分:1)Convlutional Layers:CNN提取图像像素特征;2)Recurrent Layers:循环网络层是一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征;3)Transcription Layers:CTC归纳字符间的连接特性,将RNN输出做softmax后,为字符输出.整个CRNN网络结构如图7所示.

图7 CRNN网络结构
由于一张图片中一般都有不止一个文本框,因此还要从最终文本识别结果中找出企业名称,本文中增加了企业命名实体识别模块,算法逻辑流程如下:1)若识别的文本框数量N仅有1个,则去除文本框中的符号,识别结果即为实体名.2)若识别的文本框数量N大于2个,且识别文本框中面积最大的文本框Smax识别文字长度小于预定阈值,则去除文本框中的符号,该文本框中文字为店名.3)若识别的文本框数量N大于2个,且识别文本框中面积最大的文本框Smax识别文字长度大于预定阈值,则首先计算该文本框的宽高比,若宽高比超过预设阈值,且文本框中文字内容不包含字典集中的已有内容,则舍弃,对面积次之的文本框进行判定;若宽高比未超过预设阈值,且文本框中文字内容包含字典集中的已有内容,则去除文本框中的符号,该文本框中文字为店名.
2 实验结果及分析
2.1 实验配置实验可在Windows/Mac/Linux操作系统中进行,采用Python语言编程实现.
2.2 实验数据集SynthText数据集[22]是大型计算机生成的数据集,该数据集包含约80万张图像,其中有大约800万个合成单词.这些图像不是自然场景图像,而是通过将自然背景图像与渲染的文本融合而创建的.该数据集中每一个文本目标都对文本的字符及字符边界框进行了标注,由于数据集规模大,常被用作预训练数据集.因此,本研究利用该数据集对模型进行预训练.
ICDAR2019-MLT数据集[23]为多场景自然文本检测与识别的数据集,含有众多自然场景图片,该数据集比ICDAR2017数据集的难度更大.由于数据集庞大,本研究使用的是MLT19_TestImagesPart1中的部分图片作为测试集.
此外,本论文自采集有1 600张图片,按商铺的类型,分别在商业街商铺、市场类商铺、社区商铺、住宅底层商铺、百货商场、商务写字楼以及企业园区等8种类型的商铺各采集了200张图片.这些数据是在不同天气、不同背景、不同拍摄角度、不同的清晰程度下的不同命名方式的图片,数据的背景一般包括行人、车辆、路边建筑、商家的货物以及各类广告设施,与其他公开数据集相比,自采集数据集是专门针对企业实体识别领域研究的,具有较高的不相似性、挑战性以及针对性.
2.3 实验细节首先在SynthText数据集上进行预训练,训练初设置学习率为0.000 1,在训练后期使用更小的学习率0.000 01.为适应MobileNetV3网络,将CRNN中向下采样特征映射的跨步从(2,2)修改为(2,1),将第二个向下采样特征的步幅从(2,1)修改为(1,1),并在最终的损耗函数中加入L2正则化以避免过拟合,采用学习率预热和PACT量化的方法进一步提升模型的准确率和效率.从SynthText数据集获得预训练的权重后,然后在自采集的数据集中选取800张作为训练集,进行二次训练来对模型微调,最初将学习率设置为0.000 01,每250个周期降低为原来的1/5.
2.4 评估指标为了更客观地测评各种方法的检测性能,实验采用目前文字检测领域内有3个重要评估指标[24]:准确率(Precision,P)、召回率(Recall,R)、综合评价指标(F-measure,F)[25].其中,准确率P表示正确预测的正样本与所有检测结果之间的比率,其定义式如式(4)所示:
(4)
召回率R表示检测得到的正样本和所有手工标注的真实样本之间的比值, 其定义式如式(5)所示:
(5)
综合评价指标F是准确率与召回率的调和平均值, 该值是评价文本检测方法性能的综合指标,其定义式如式(6)所示:
(6)
由于准确率(P)与召回率(R)之间时常会出现矛盾的情况,不能很好的定性分析方法优劣.因此,本文中就采取综合评价指标(F-measure,F)评估方法,一般来说F的值越高,算法的性能就越好.
2.5 实验结果分析为了验证方法的有效性,在ICDAR2019(MLT19_TestImagesPart1)数据集上选取图片,在相同的实验环境和实验平台上进行测试,并与现有流行的模型结果进行了比较.
测试结果如表2所示,采用基于分割的方法PixelLink和PSENET、基于文本边界框的方法SPCNET和SegLink作为本位算法的对比模型,所提方法均在同一设备环境中复现.本文中方法的准确率为79.56%,召回率为70.82%,F值为74.94%.不难发现,本研究算法的模型具有较好的识别效果.
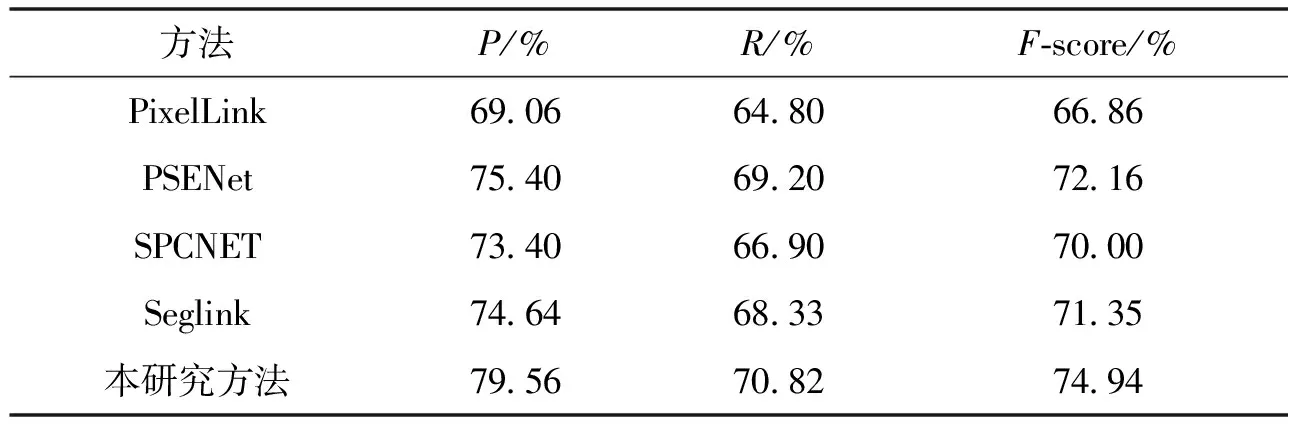
表2 数据集ICDAR2019(MLT19_TestImagesPart1)实验数据
为了保证结果为非偶然性,使结果在企业实体识别上更具针对性,本研究在自采集的数据集下对各方法文本检测速度进行了对比实验.其中,识别速率通过FPS(帧率)的大小来反映速率的快慢所有实验均在同一程序环境中进行测试,如表3所示,我们可以看到,本研究提出的方法在识别速率和准确性之间取得了良好的平衡,虽在识别速率上与PixelLink差距稍大,但整体识别性能F值却最优.

表3 文本识别速率对比实验结果
另外,本研究展示部分实验过程和结果,展示图如图8所示.

图8 部分识别过程及结果展示图
3 结束语
自然场景文本检测是计算机视觉与模式识别领域中的一个新兴的研究课题,具有重要的理论意义和实际应用价值.目前国内外许多学者对该课题展开了大量研究,然而由于复杂自然环境中存在文本背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等问题,使得该技术离商用仍然有一定距离.针对这些问题,本研究提出基于DBNet的超轻量企业实体识别模型,在自然场景下对弯曲、横向及纵向多类型文本可生成较高可信度的二值图,解决自然场景下检测速度慢、对弯曲文本检测效果差的问题,将循环神经网络(RNN)与卷积神经网络(CNN)结合成CRNN,配合CTC loss实现端到端企业实体识别,解决了自然场景下识别的文本序列不定长问题.实验结果表明,本研究提出的算法准确率及识别速率上表现出优异的结果,增加的命名实体识别模块,使得该技术可以实际应用于企业实体识别.然而,目前基于这套模型对于弯曲文本的检测仍然具有局限性,在较多复杂背景的情况下,识别速度较慢.因此,如何解决弯曲文本及复杂背景的检测与识别问题,是自然场景文本检测与识别的关键突破点,它会是未来研究的热点方向.相信随着越来越多的学者参与计算机视觉与机器学习领域的研究,将促进自然场景文本识别在诸如自动驾驶、无人机等领域的相关应用快速落地.
