FLIGHT:Federated Learning with IRS for Grouped Heterogeneous Training
2022-06-29TongYinLixinLiDonghuiMaWenshengLinJunliLiangZhuHan
Tong Yin,Lixin Li,Donghui Ma,Wensheng Lin,Junli Liang,Zhu Han
Abstract—In recent years,federated learning (FL)has played an important role in private data-sensitive scenarios to perform learning tasks collectively without data exchange.However,due to the centralized model aggregation for heterogeneous devices in FL,the last updated model after local training delays the convergence,which increases the economic cost and dampens clients’ motivations for participating in FL.In addition,with the rapid development and application of intelligent reflecting surface (IRS) in the next-generation wireless communication,IRS has proven to be one effective way to enhance the communication quality.In this paper,we propose a framework of federated learning with IRS for grouped heterogeneous training (FLIGHT) to reduce the latency caused by the heterogeneous communication and computation of the clients.Specifically,we formulate a cost function and a greedy-based grouping strategy,which divides the clients into several groups to accelerate the convergence of the FL model.The simulation results verify the effectiveness of FLIGHT for accelerating the convergence of FL with heterogeneous clients.Besides the exemplified linear regression (LR) model and convolutional neural network (CNN),FLIGHT is also applicable to other learning models.
Keywords—federated learning,decentralized aggregation,intelligent reflecting surfaces,grouped learning
I.INTRODUCTION
In the information era,the explosion of data has laid a solid foundation for the development of artificial intelligence(AI)and deep learning(DL)[1].In particular,DL models enhance a wide range of intelligent applications,such as object detection[2],machine health monitoring[3],speech recognition[4],and machine translation[5].Training a network model with better performance needs to invest a large amount of data to extract the more accurate features,because of which obtaining more data is extremely important.In insurance,medical,and other industries,it is necessary to make full use of others’ data and model parameters to get a better network performance.However,there are isolated data among clients out of consideration and concern for data privacy.This promotes the development of federated learning (FL),by which clients are allowed to share model parameters on the premise of data privacy,thereby increasing the final performance of the network.
To date,there are two main types of FL,server-parameter and decentralized aggregation.In the server-parameter architecture,a server node exists to aggregate the parameters trained by client nodes with their local data[6].However,this scheme may waste a lot of time in communication when the communication conditions among the server and client nodes are harsh[7].Conversely,for the decentralized aggregation,the local update exchanges directly among participant client nodes without a central server to avoid costing much time on communication.
With the advancement of the sixth generation(6G)wireless communication and the Internet of things(IoT)technologies,a high number of intelligent devices are connected to the network,which makes FL important to improve the performance of wireless communication system[8-11].On the other hand,as an important technology for the next-generation wireless communication,intelligent reflecting surface(IRS)provides a new choice for improving the performance of communication system[12,13].The reflecting elements can proactively adjust the propagation channels to circumvent the unsuitable propagation conditions by causing independent phase shifts on the incident signals.In general,the model information communication process in the FL framework takes up a lot of time,which means that better communication circumstance can effectively reduce the time required for the convergence of the FL model.So far,IRS has been recognized as one tool to enhance wireless communication channels.Therefore,it is a natural idea to use the IRS to enhance the FL communication process[14-16].However,the communication and computing capabilities of these devices are vastly different so the high latency exists in centralized aggregation.Consequently,the development of decentralized FL algorithms is encouraged.
Federated averaging (FedAvg)[6]is a widely implemented algorithm in the server-parameter scheme.FedAvg utilizes the server node to collect and average the local model sent by client nodes,and then the server node distributes the updated model parameter back to client nodes.On the other hand,gossip learning[17,18]provides a way for FL to decentralized aggregation.The client node randomly selects one or more client nodes in each round of periodic update,and then exchanges local updates with the selected nodes.In this way,clients train and update the model asynchronously.However,due to the heterogeneity of the clients,e.g.,communication conditions and computing capability of the clients,gossip learning performs poorly under the condition of limited communication topology[19].A consensus-based FedAvg algorithm (CFA)is proposed in Ref.[20].Nevertheless,this algorithm lacks the topology constructing scheme among clients,and the network topology needs to be designed manually.In mobile networks,the dynamic change of communication environment leads to different latency,and thus the topology also needs to be adjusted dynamically to optimize the system performance.Therefore,this paper proposes a decentralized FL framework that can adaptively plan the topology of the system.
Due to the heterogeneity and diverse location distributions of clients,the key problem for constricting the optimal topology is how to choose better neighbors in the network to avoid extra latency of computation and communication.In this paper,we propose a framework of federated learning with IRS for grouped heterogeneous training (FLIGHT),in which the decentralized clients are grouped according to the similarity of computing power and communication quality,and then a pseudo-server (PS) is selected to aggregate the local DL model of the members in the same group so as to accelerate the convergence speed and shorten the latency.In addition,IRS is incorporated to enhance the communication rate in the model transmission process.When IRS is applied,the time required for the wireless transmission of the updated model is reduced,which means the convergence delay of FL caused by wireless communication is reduced overall.The process of the FLIGHT is generally divided into three steps:cost calculation,clients grouping,and federated training.The contributions of this paper can be summarized as follows.
·To abate the latency caused by communication and computation heterogeneity of the clients,we propose a federated learning framework with IRS for grouped heterogeneous training,i.e.,FLIGHT,in which clients are grouped to train FL models.
·Based on the cost due to computing and communications,we develop a greedy grouping algorithm to divide the clients into groups to accelerate the convergence of the FL model.
·We conduct a series of simulations to evaluate the performance of FLIGHT.The simulation results demonstrate that FLIGHT can effectively accelerate the convergence of the FL model.IRS can reduce the latency effectively in comparatively heterogeneous settings.
The rest of the paper is organized as follows.The system model is introduced in section II.Section III presents the FLIGHT framework in detail.The simulation results are discussed in section IV,and finally,the conclusion is drawn in section V.
II.SYSTEM MODEL
In this section,we first introduce the FLIGHT model.Secondly,the IRS-assisted communication system is introduced,and then the cost function is formulated.
A.FLIGHT Model
In the server-parameter scheme,there is a server node that aggregates the local parameters of client nodes and then sends the updated parameter back to the client nodes,as depicted in Fig.1(a).To begin with,clients train their models locally with their own data.Once the training on clientkis completed at timet,it will send its model parametersto the server node.When the server receives the model parameters of all clients,it will aggregate the models bywhereKdenotes the number of the clients,to obtain the updated modeland then send it to all the clients.However,in this way,the faster clients have to wait for the slower clients before starting the next round of training.Especially when the communication circumstances among the server and the clients are bad due to distance or obstructions,or the aggregation may be stuck if some clients always fail to upload the model parameters.
As demonstrated in Fig.1(b),FLIGHT selects the PSs from the clients to eliminate the true server node.After the PSs are chosen,they will pick their group members up and,similar to FedAvg,aggregate the members’ model parameters.This architecture is typically used when the system cannot find a server to connect all clients or the communication cost between the server and clients is unacceptable.
In FLIGHT,we consider a PS-selected decentralized FL system as shown in Fig.1(b),in which all clients construct a setM,with the size|M|.When groupsGare made,each normal client will be associated with a selected PS client.The PS clients take responsibility to aggregate the models trained by all the clients in the same group.We denote the set of clients in theith group asGi.Furthermore,we make connections among all the PS clients available.
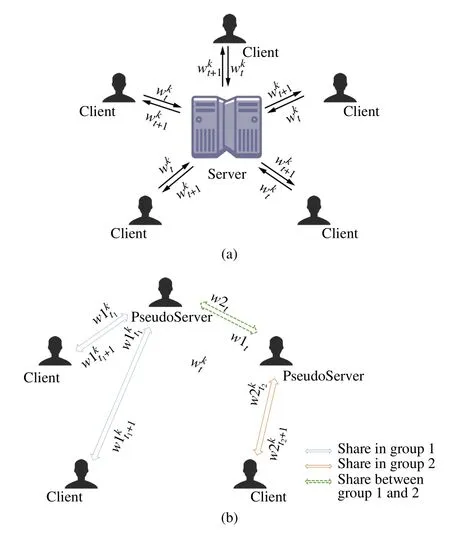
Fig.1 Two types of mode for FL:(a)Client-Parameter;(b)FLIGHT
Each client is assumed to have a part of local data,denoted as,k ∈M,to train the local model and get the local update,wherexjis the single data sample andyjis the corresponding label.The clients aim at training a DL model collectively,denoted asw ∈RQ,whereQrepresents the number of parameters of the model.Letf(xj,yj;w) denote the objective function corresponding to the data sample(xj,yj)calculated on modelw.As a result,the objective function of thekth client is defined by
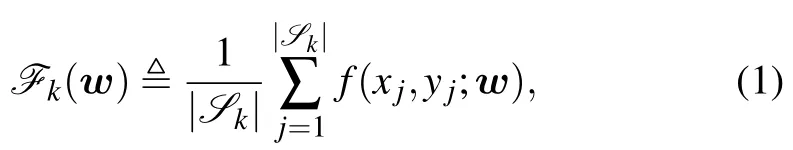
whilek ∈M.
In this case,the whole federated optimization model is defined as
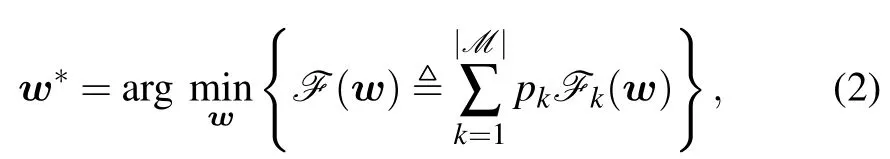
wherepkdenotes the weight of thekth client withpk≥0 and
B.IRS-Enhanced Communication System
The wireless communication network used in FLIGHT system is presented in Fig.2,where an IRS is deployed to enhance the communication among the clients.Suppose each client is equipped with a single antenna,and the IRS hasLphase shift elements.The considered scenario is that there might be obstacles among the clients so that the direct link is blocked or the received power of the direct link is negligible compared to that of the IRS-assisted link.It is assumed that a channel model with invariant channel state information(CSI)is applied during the whole training process.With these assumptions,the channel vector between theith client and thejth client can be expressed as follows:
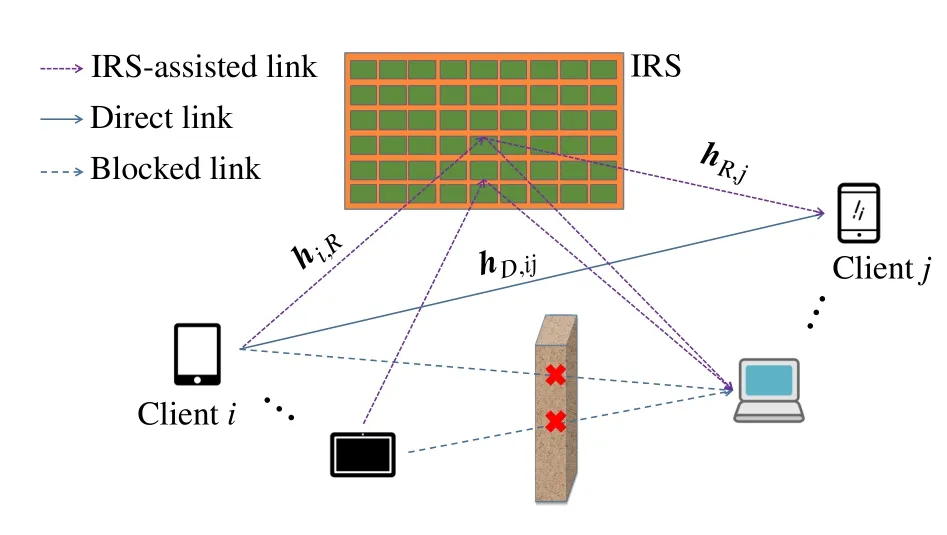
Fig.2 The communication system for FLIGHT,where an IRS is deployed to enhance the communication
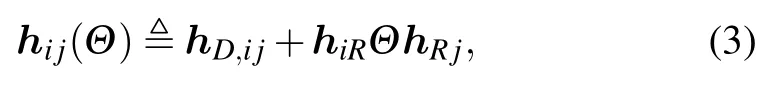
wherehD,i jdenotes the channel vector of the direct link between theith and thejth clients.hiRandhRjdenote the channel vector among theith client and IRS and the channel vector among IRS and thejth client,respectively.The diagonal matrixΘis the reflection matrix of IRS,i.e.,Θdiag(θ).We assume the amplitude reflection coefficients of the IRS are set as 1 and|θi|21,θi ∈θ.
Therefore,when theith client sends a signalxijto thejth client,the received signal can be expressed as
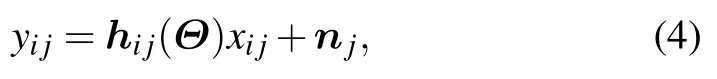
wherenjis an additive white Gaussian noise(AWGN)vector with the distribution ofNC.When the updated modelWkof FL is transmitted,xijstands forWk.
Then,the signal to interference plus noise ratio(SINR)of clientjcan be expressed as
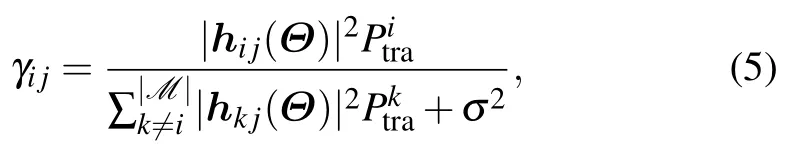
Therefore,the transmission rate from theith to thejth clients can be modeled as
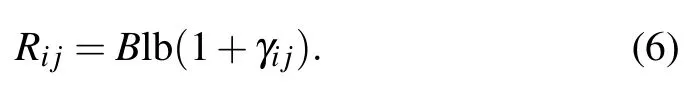
C.Cost Function
The shortcoming of FedAvg is that,due to the heterogeneity of client nodes,fast nodes must wait for slow nodes to upload their local updates before the server node aggregates,resulting in a waste of performance of nodes with high processing capacity(i.e.,fast computing speed).Meanwhile,the convergence speed of the FL model is also affected by the communication process.Therefore,to achieve a superior grouping performance,FLIGHT should distinguish both the differences in computing capability and the communication quality among the clients.
In FLIGHT,we useRand floating-point operations per second (FLOPS)fto denote the communication rate among clients and the computing capability of the client,respectively.Then,to determine the cost among the clients,we adopt the following strategy:
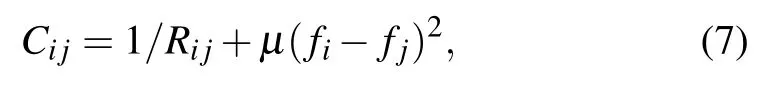
whereCi jsignifies the connection cost between clientsiandj.It indicates both the state of their communication as well as the disparity in their computing capability.The communication rate between clientsiandjis denoted by the variableRij.The FLOPSs are denoted byfiandfj,respectively.μis a parameter for adjusting the impact of the computing capability on the cost.
This formula depicts the matching degree among clients.Obviously,clients are naturally more motivated to choose other clients with a lower value ofCas their own group members,because the lower value ofCindicates a superior communication rate and more similar computing capacity among the clients.It is worth noting that the purpose of separating the clients is to reduce the ineffective waiting time for clients,which means clients are motivated to choose the clients with similar computing capability or the clients with lower computing capability but faster communication rate as a group.In this way,the lower value ofCmeans the stronger matching between the clients.This also implies that clients in the same group do not have to waste too much time waiting for cooperative members.
III.FLIGHT:FEDERATED LEARNING WITH IRS FOR GROUPED HETEROGENEOUS TRAINING
In this section,a framework based on grouping for FL is proposed as FLIGHT which can be applied in the decentralized scenario.The whole process of FLIGHT is provided in Algorithm 1 and mainly divided into three steps:cost calculating,clients grouping,and federated training.Specifically,the clients grouping algorithm is shown in Algorithm 2.


A.Cost Calculating and Clients Grouping
The performance of the entire system is constrained by the general FL technique due to communication limitations and heterogeneity among the clients.For example,if some clients in the system are in a poor communication state or have low computational capability,other clients will have to wait for these clients.As a result,(7)is presented to assess the matching degree of clients.
One solution to the problem is to divide the entire set of clients into a succession of groups in order to limit the number of clients with whom one client must cooperate.When forming groups,a greedy-based algorithm is required,as described in Algorithm 2,whereCminrepresents the lowest cost among all clients.In the ungrouped clients,clientKbfis the client with the most processing capability.The threshold for choosing clientkto be a member ofGbfis determined byε.
As a result,the PS selects a group of clients with a similar matching degree,reducing the latency caused by the heterogeneity of the clients.
B.Federated Training
In this case,groups work on FedAvg independently within the timeTcalled self-training time in which the PSs work as the role aggregating the models.After self-training timeT,PSs in all groups will communicate with one another to collect model information from data obtained by clients in other groups.Self-training will resume after each PS receives the other’s model parameter.Repeat the steps above until all the clients have the same model that is superior to the model trained solely with their own local data.
1)Local Training within the Group:Each client performs local training in theith iteration using the mini-batch stochastic gradient descent(mini-batch SGD)algorithm according to:

2) Model Aggregation within the Group:Once all the clients in the groupGkcomplete the computation,they send the updated model to the PS client ofGk.It is worth noting that the updated models are transmitted within the IRS-enhanced communication system discussed in section B.If time does not satisfy the conditions of the communication of PS clients,model aggregation will be performed within the group by the PS client as follows:
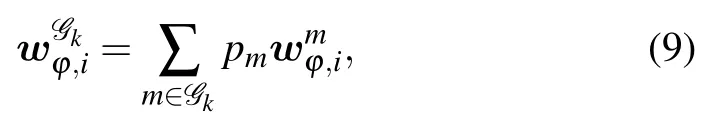
wheredenotes thekth group aggregated model in theith iteration before the(φ+1)th PS communication,Gkis thekth group.After aggregation,the latest model is sent back to the clients inGk,and the local model is updated by
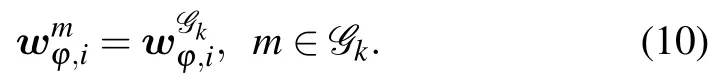
3) Model Aggregation among the Groups:Model information of each group will be shared when the time meets the PS communication conditions.Each group shares its model with all other groups,and then model aggregation is performed by all the PS clients.Finally,each client receives the aggregated model,which can be expressed as follows:
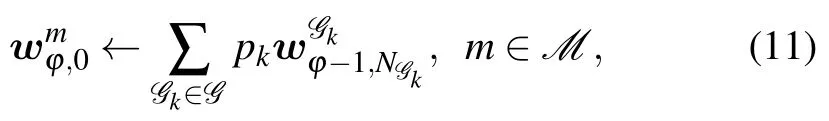
IV.SIMULATIONS AND DISCUSSIONS
In this section,both the linear regression model (LR) and the convolutional neural network (CNN) are simulated to verify the effectiveness of FLIGHT.The simulation settings are first introduced,including dataset and network structure.Then,the rationality of the simulation result is discussed and analyzed.The source code is developed with FedML[21],which is an open-source research library for federated learning.
A.Simulation on LR Model
We first evaluate the FLIGHT framework on the LR model with MNIST[22]dataset to compare the performance of different algorithms.
1)Scenario and Dataset:In our simulations,we consider the outdoor scenariowhich is provided by the Deep-MIMO dataset[23].In the simulation,it is assumed that the BSs are regarded as the clients with a single antenna to get the channels among the clients.In‘O1’scenario,the total number of BSs is 18,which satisfies the need for simulation.In addition,there are obstacles in the communication system meeting the need for IRS enhanced scenario.The top view of the‘O1’ray-tracing scenario is shown in Fig.3[23].To create a heterogeneous setting,we choose thetoand the BS9 toto be the client node with a single antenna.There are 15 clients in total.is activated as IRS.The relevant parameters adopted to create the channels are summarized in Tab.1.
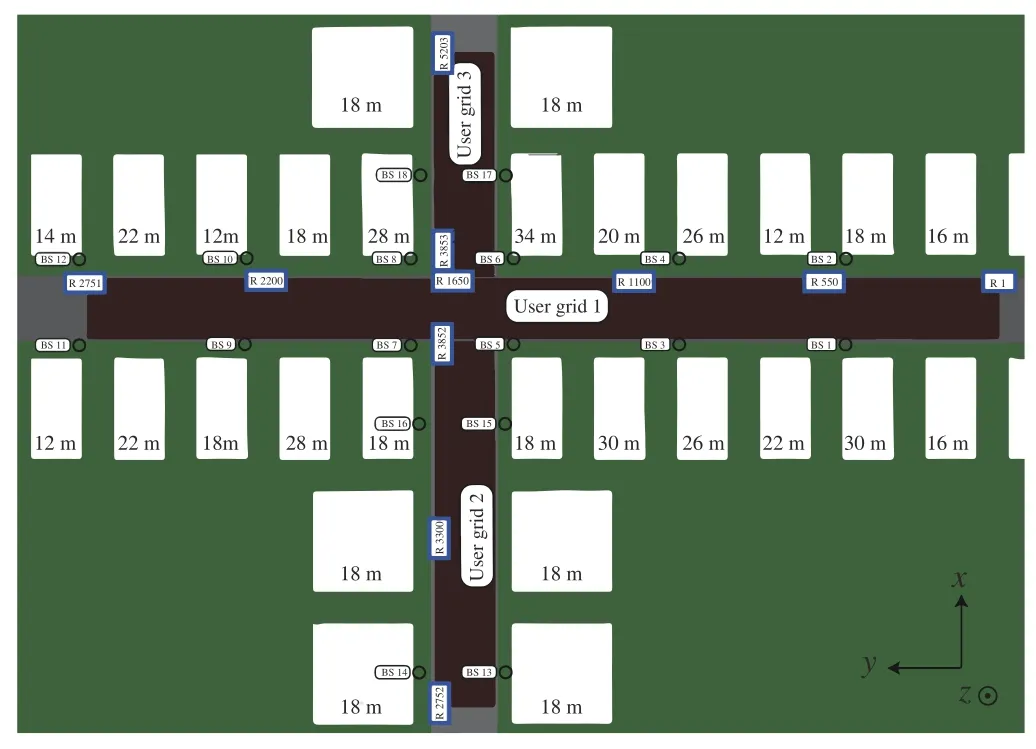
Fig.3 The topview of the‘O1’ray-tracing scenario[23]

Tab.1 Parameters of DeepMIMO dataset
The MNIST dataset contains 60 000 images for training and 10 000 for testing,each of which is 28×28 pixels in size.We set 15 clients in simulations and allocate the same amount of non-overlapping training data to each client.It is assumed that each client is able to communicate with all other clients.The same partition method is applied for testing data.Here,the simulation utilizes independent and identically distributed(IID) data,that is,the training and testing data are shuffled,and then partitioned into 15 clients.We train the MNIST dataset with the LR model of which the input dimension and output dimension are 728 and 10,respectively.In the training process,we set the learning rate to be 0.001,and set the size of mini-batch to 100.
The FLOPSf,which reflects the computational capacity of the client,are selected in random within the range of[0.05,1.5] giga floating-point operations (GFLOPs).Other FLIGHT settings are listed in Tab.2.The number of parameters of the model and the floating-point operations(FLOPs)required for one iteration are 7 290 and 14 5601The number of parameters of the model and the FLOPs required for one iteration are obtained by using OpCounter,which is an open-source model analysis library.,respectively.

Tab.2 Parameters of FLIGHT setting
To verify the effectiveness of FLIGHT in reducing the training latency in the heterogeneous scenario,we adopt the following FL frameworks for comparison.
·FedAvg[6]:This is a client-parameter-based FL framework,in which a server is required to collect and aggregate the models from the clients.Note that we set client sample factor to be 1,which means all clients are selected to participate in each model aggregation process.
·CFA[20]:This is a consensus-based federated learning framework with distributed fusion over an infrastructure-less network.The global model parameters are gained by the cooperation among the clients sharing the parameters with their neighbors.Note that we set two neighbors for each client.
·OPS[24]:This is a decentralized federated learning framework in which each node only needs to know its out neighbors rather than the global topology.Note that we assume a mutual trust relationship among the clients and we set two neighbors for each client.
2) Simulation Results:Fig.4(a) shows the initial thermal diagram that denotes the transmission rates among the clients.The stronger the communication connection among the clients,the deeper the color.As we can see in Fig.4(b),when IRS is incorporated in the system,the connection relationships among the clients that originally have comparatively inferior communication conditions have been significantly enhanced.
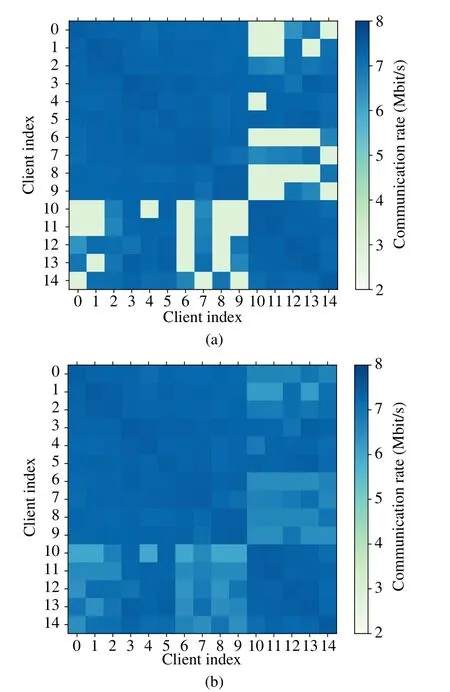
Fig.4 The effect of IRS on the transmission rate among the clients:(a)Transmission rate without IRS;(b)Transmission rate with IRS
We show the test accuracy over time in Fig.5.It can be observed that the test accuracies of FLIGHT and FLIGHTw/o-IRS increase rapidly at the early stage of the training process,and converge at 30 s.As we can see,the two curves of FLIGHT and FLIGHT-w/o-IRS are nearly identical in appearance.This is due to the transmission rates being less heterogeneous before using IRS in thescenario.When using IRS,the transmission rates among blocked clients are significantly improved,but the improvement of other transmission rates is negligible.This phenomenon,on the other hand,indicates that FLIGHT-w/o-IRS can perform as well as better transmission conditions in a less heterogeneous system.Comparatively,the training process of OPS lags far behind due to the frequent information exchanges among the clients and their neighbors,which requires more communication processes in the whole FL training process.It is worthwhile to note that although the training process of CFA is in the lead compared with FedAvg in the early stage,these two curves intersect at 15 s.This denotes that for the simple model and dataset,although CFA can reduce the communication latency compared with FedAvg,it is more important to aggregate all parameter information trained by the different clients.
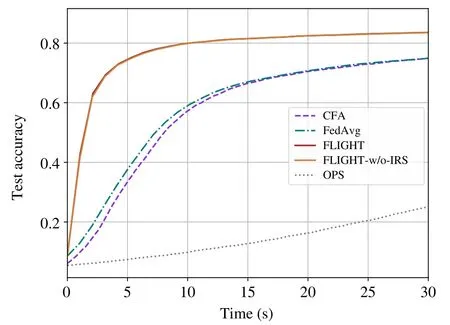
Fig.5 Accuracy of FLIGHT compared with other algorithms
The influence of different factors in FLIGHT is shown in Fig.6.The value ofμdenotes the relevance of computational capacity for calculating the value ofC,as discussed in section II.The greater the value ofμ,the more significant the computational capacity.It is worth mentioning that in the setting of simulation,the time cost for training locally is determined by the FLOPs required for training and the FLOPS of clients.Moreover,in the simulation scenario,the training time that every client needs to train all the data one epoch is longer than the time for communication among the clients.That means computing capacity is more essential when calculating the value of the cost.In Fig.6(a) and Fig.6(b),whenεis fixed to 2,the larger theμ,the relatively faster the loss reduces in the early training stage.The value ofε,on the other hand,represents the scope of the groups.As is shown in Fig.6(c) and Fig.6(d),whenμis fixed,the larger theε,the relatively more sluggish the loss reduces in the early training stage.This is because as the value ofεincreases,the group size grows,leading to the latency within the group increases.
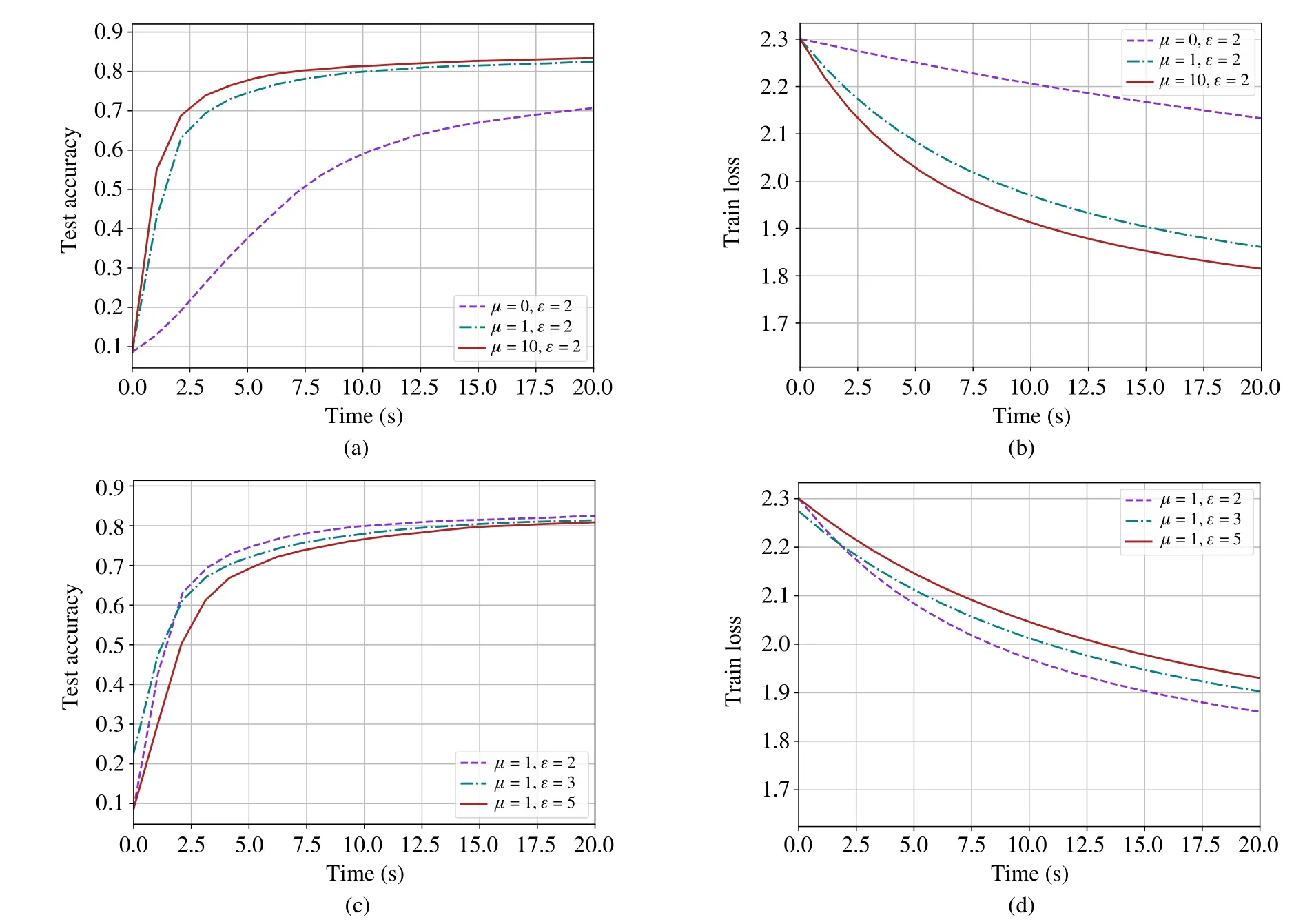
Fig.6 Test accuracy and training loss vs.time for the MNIST dataset(IID)with different values of factors in FLIGHT:(a)Test accuracy with different μ;(b)Training loss with different μ;(c)Test accuracy with different ε;(d)Training loss with different ε
B.Simulation on CNN Model
In this part,we evaluate the FLIGHT framework on the CNN model with CIFAR-10[25]dataset to compare the performance of different algorithms.
1)Scenario and Dataset:To validate the performance of the FLIGHT framework in a strongly heterogeneous scenario,we assume the number of clients is 15.FLOPSfof the client,which reflects the computational capacity of the client,and the communication rateRamong the clients are selected in random within the range of[50,250]GFLOPs,and[1.5,7]Mbit/s,respectively.When adopting the IRS to aid the communication,we assume the communication rates are selected within the range of[6,7]Mbit/s.The CNN model adopted is shown in Fig.7[26],which contains three convolutional layers followed by three fully connected layers.The number of parameters of the model and the FLOPs required for one iteration are 77 578 and 9 088 0001,respectively.It is worth noting that the model we use is not the state-of-the-art research for CIFAR-10,as our aim is to compare the performances of the different FL frameworks,not to achieve the highest accuracy on CIFAR-10.
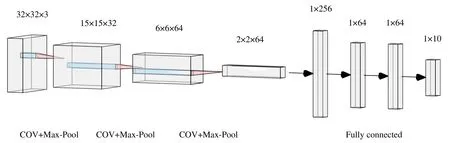
Fig.7 CNN model using in CIFAR-10 simulation
CIFAR-10 dataset contains 50 000 training examples and 10 000 testing examples,each of which is 32×32 pixels in size with three RGB channels.We partition the dataset into 15 clients each containing 3 333 training examples and 666 testing examples,respectively.We consider an IID setting.In the training process,we set the learning rate and the size of mini-batch to be 0.1 and 200,respectively.
2) Simulation Results:The testing accuracy and training loss over time are shown in Fig.8(a) and Fig.8(b),respectively.It can be observed that the accuracy of FLIGHT increases rapidly and gets to 77.89%at 300 s.In this heterogeneous setting,the benefits of using IRS are obvious.The accuracy of FLIGHT-w/o-IRS gets to 77.09%at 300 s.It is significant to note that when the model and dataset are complex in this setting,the convergence rate of CFA is comparatively faster than FedAvg.In addition,the burr of the loss curves of FLIGHT and FLIGHT-w/o-IRS in Fig.8(b)is smoother than that of other frameworks.
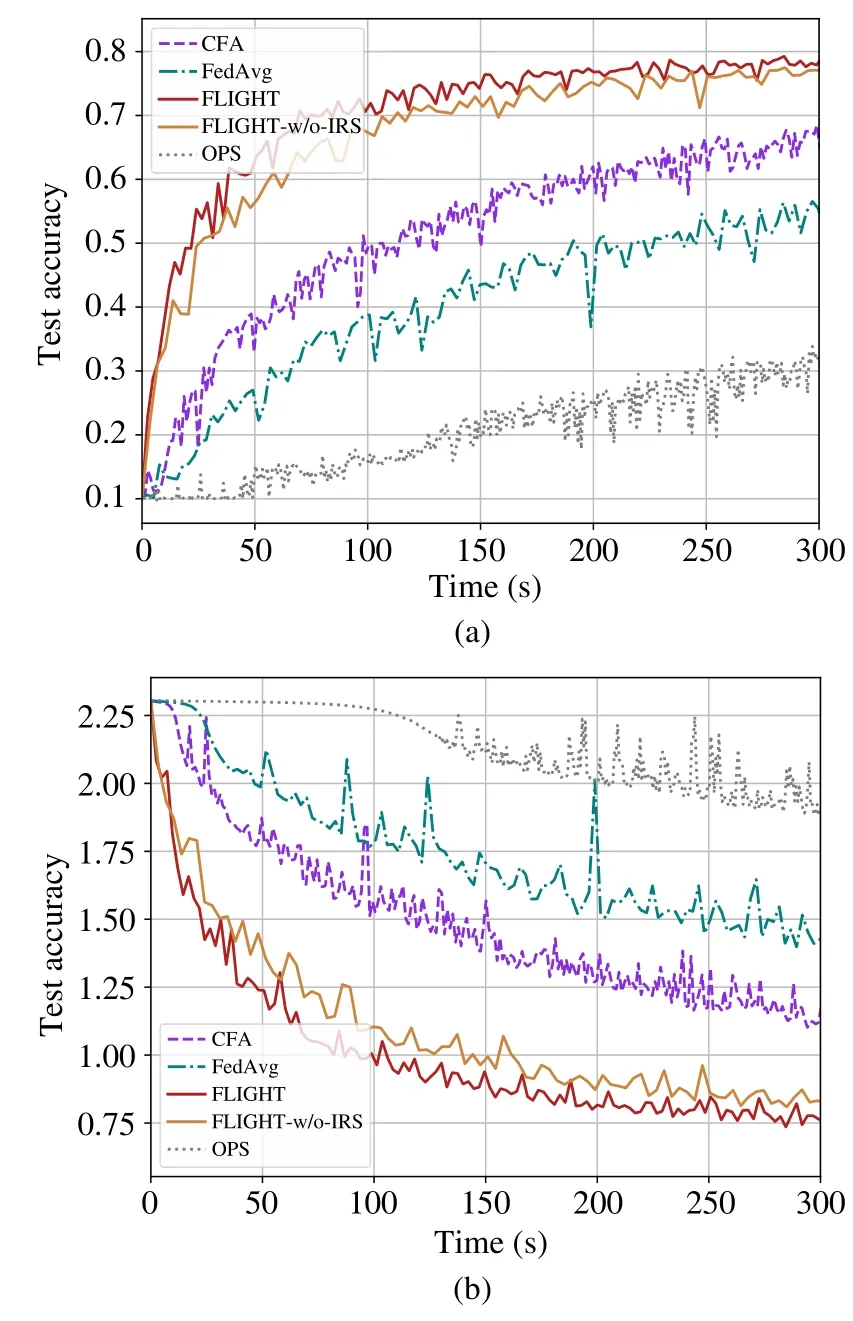
Fig.8 Test accuracy and training loss vs.time for the CIFAR-10 dataset(IID):(a)Test accuracy;(b)Training loss
Fig.9(a) and Fig.9(b) illustrate the performance of FLIGHT for the different numbers of clients.When the number of clients equals 15,FLIGHT can deliver greater results in a relatively shorter time.The time it takes to reach a point of convergence increases as the number of clients grows.This is because the number of local data examples determines the upper limit of model accuracy without cooperating with other clients.Thus,communicating with other clients is a significant way to improve the local model accuracy leading to more latency in the training process.
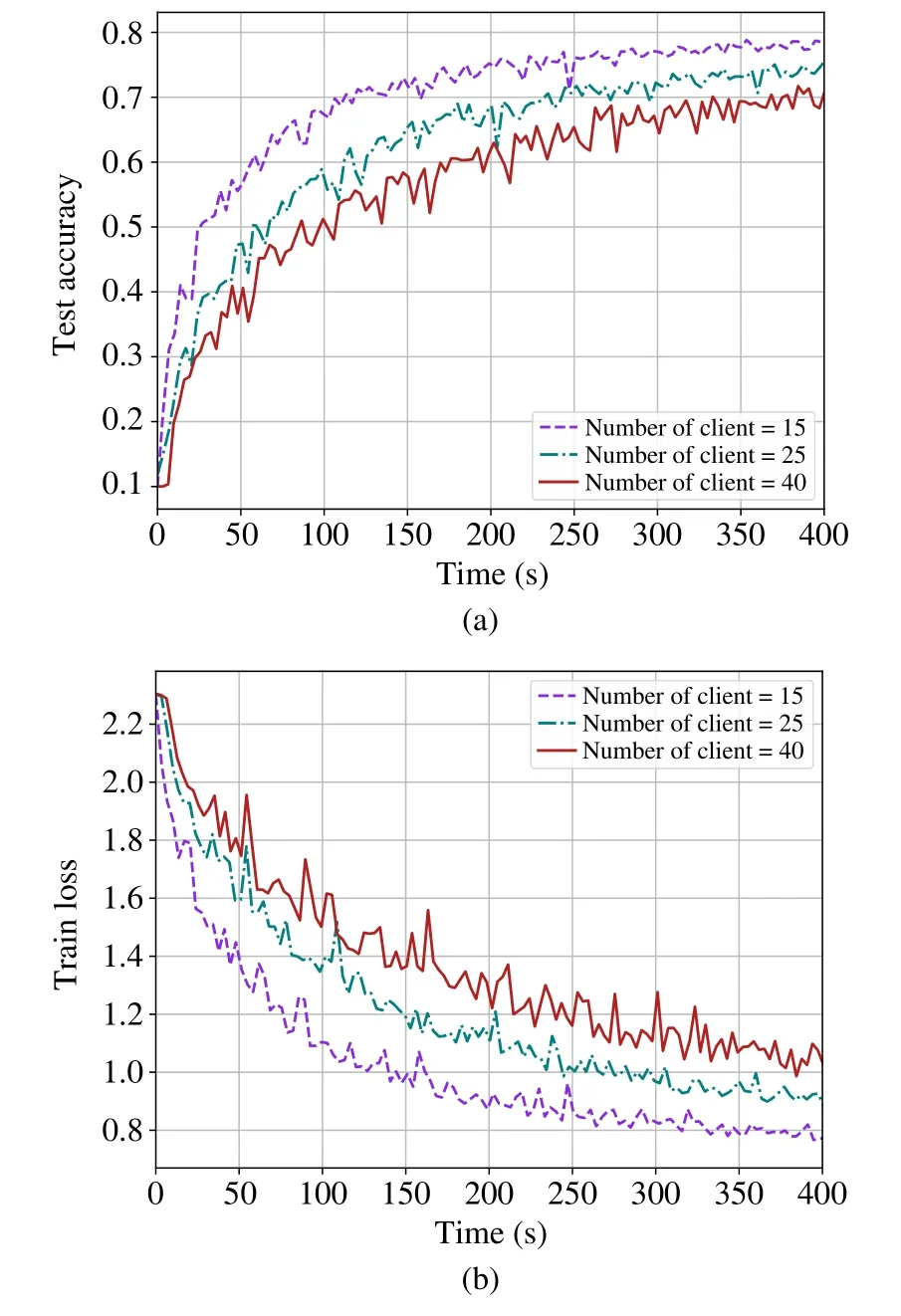
Fig.9 Test accuracy and training loss vs.time for the CIFAR-10 dataset(IID)with different number of clients:(a)Test accuracy;(b)Training loss
V.CONCLUSION
In this paper,we have proposed a decentralized FL framework with IRS for grouped heterogeneous training,i.e.,FLIGHT.In FLIGHT,we design the cost function based on the computing capability and the communication rate of each client.Then,the clients are divided into groups according to their cost functions by a greedy algorithm.The clients train locally and aggregate the FL model within a group,while the PSs update the global model among groups.In addition,IRS is incorporated into the FLIGHT system to assist the communication process.The experiments verified that FLIGHT substantially reduces the latency for training FL model and that IRS can effectively improve the speed the convergence in the comparatively heterogeneous setting.However,the partial participation of the client is not considered in FLIGHT,which means we assume all the clients can always maintain their communication and computation capabilities.For future works,it is worth investigating the grouping algorithm to further abate the training latency of FL with heterogeneous devices.Furthermore,it is beneficial to research how to optimize the IRS reflecting matrix in order to get better communication improvements.It would also be interesting to consider more practical scenarios with partial participation.
杂志排行

Journal of Communications and Information Networks的其它文章
- Channel Estimation for One-Bit Massive MIMO Based on Improved CGAN
- DOA Estimation Based on Root Sparse Bayesian Learning Under Gain and Phase Error
- Multi-UAV Trajectory Design and Power Control Based on Deep Reinforcement Learning
- A Lightweight Mutual Authentication Protocol for IoT
- Local Observations-Based Energy-Efficient Multi-Cell Beamforming via Multi-Agent Reinforcement Learning
- Rethinking Data Center Networks:Machine Learning Enables Network Intelligence