Channel Estimation for One-Bit Massive MIMO Based on Improved CGAN
2022-06-29YongliAnJingjingYueLeiChenZhanlinJi
Yongli An,Jingjing Yue,Lei Chen,Zhanlin Ji
Abstract—In the one-bit massive multiple-input multiple-output (MIMO) channel scenario,the accurate channel estimation becomes more difficult because the signals received by the low-resolution analog-to-digital converters (ADC) are quantized and affected by channel noise.Therefore,a one-bit massive MIMO channel estimation method is proposed in this paper.The channel matrix is regarded as a two-dimensional image.In order to enhance the significance of noise features in the image and remove them,the channel attention mechanism is introduced into the conditional generative adversarial network (CGAN) to generate channel images,and improve the loss function.The simulation results show that the improved network can use a smaller number of pilots to obtain better channel estimation results.Under the same number of pilots and signal-to-noise ratio(SNR),the channel estimation accuracy can be improved by about 7.5 dB,and can adapt to the scenarios with more antennas.
Keywords—channel estimation,massive MIMO,conditional generative adversarial network,attention mechanism,denoising
I.INTRODUCTION
Massive multiple-input multiple-output(MIMO)is one of the key technologies of fifth generation (5G) mobile communications.By deploying massive antenna arrays on the base station(BS)or the access point,massive MIMO significantly improves the spectral efficiency of the system and the multiplexing capability among multiple users.Under the condition that the system bandwidth and base station density remain unchanged,the system capacity is greatly improved with the increase of the number of base station antennas,and the anti-interference ability is strong,which greatly improves the data transmission rate.However,current massive MIMO systems are typically equipped with high-resolution analogto-digital converters (ADC),which leads to high power consumption and hardware complexity[1].Massive MIMO with one-bit ADC can be used as an alternative solution to alleviate the system cost and power consumption issues in practical deployments,but it will incur a certain performance penalty,and since the heavily quantized received signals from the lowresolution ADC and exposure to channel noise make accurate channel estimation more challenging.
In recent years,with the emergence of the concept of deep learning,deep neural networks (DNN) have been applied to the physical layer design by researchers in the field of wireless communication[2-8],and the method of image processing in the field of computer vision has been extended to the field of communication[9,10].It opens up new ideas for solving the channel estimation problem.Ref.[11] regards the channel matrix as a two-dimensional image processing,and uses deep learning-based image denoising and super-resolution reconstruction methods for channel estimation.Ref.[12]combines denoising convolutional neural networks(DnCNN)[13]with an iterative sparse signal recovery algorithm,and allows the neural network to learn from noisy channels through supervised learning to obtain more accurate estimation results.In the one-bit ADC massive MIMO system scenario,the correlated neural network can be used to obtain better channel estimation performance under certain conditions,so as to achieve a good balance between the computational complexity and the number of pilots[14,15].Ref.[16] proposed a generative supervised DNN model for channel estimation using generative models and multi-layer neural networks.Ref.[17] uses conditional generative adversarial network (CGAN) to predict real channels by adversarially training two deep learning networks,which not only learn the mapping from quantized observations to real channels,but also learn an adaptive loss function to properly train the network.
However,these studies still have a lot of room for development in improving the accuracy of channel estimation.In order to improve the denoising generalization ability and estimation accuracy,this paper combines the channel attention mechanism to improve the conditional generative adversarial network,a CGAN network architecture based on the attention mechanism,channel attention-CGAN (CA-CGAN),is proposed.The quantized received signal and pilot sequence are processed into two-dimensional images,the conditional generative adversarial network is used as the basic framework,and the channel attention mechanism is designed as the denoising encoder in the U-Net generator,to improve the accuracy of the system channel estimation of the one-bit ADC massive MIMO.
Compared with the traditional method,the deep learning method can discover the hidden relationship between the input and output through data-based training,and effectively combat the nonlinear distortion introduced by hardware damage such as low precision,to obtain a method more suitable for practical massive MIMO systems.Compared with the generative supervised DNN model in Ref.[16],the generative adversarial network (GAN) loss introduced by the CGANs’architecture is more robust and easier to generate more realistic channels.Compared with the work in Ref.[17],the CA-CGAN architecture with an attention mechanism added to the generator removes the influence of noise,improves the accuracy of channel estimation,and is more robust in varying scenarios (e.g.,different lengths of pilot sequences,different SNRs,and different numbers of BS antennas).
II.SYSTEM MODEL
We consider a single-base multi-user massive MIMO system scenario with one-bit ADCs,and its channel estimation framework is shown in Fig.1.There areKsingle antennas equipped with users and BS withMantennas,each BS antenna is equipped with two one-bit ADCs.The channel data between the BS and multiple users are generated using the DeepMIMO framework[18].The framework is constructed from data sets generated by deep learning algorithms based on accurate ray tracing data simulated by wireless InSite,a ray-tracing simulator developed by Remcom,which can compute synthetic channel characteristics for BS-user pair in each channel path.
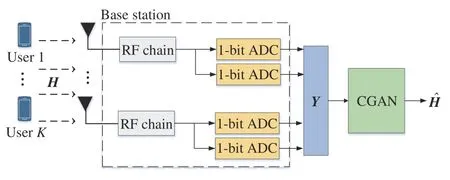
Fig.1 one-bit ADC massive MIMO channel estimation framework
Specifically,for thelth channel path between thekth user and the BS,calculate the elevation angles of departure(AoD)and azimuth angleat the BS,and the elevation angles of arrival (AoA)and azimuth angleat the user side.Also,compute the phasethe received powerand the transmission delaybetween the BS and thekth user in channel pathl.
Construct the channel vectorhk ∈CM×lbetween the BS and userkbased on the above channel parameters:

whereBis the system bandwidth anddis the antenna spacing.Finally,the channel matrixH ∈CM×Kbetween theKusers and the BS can be defined as
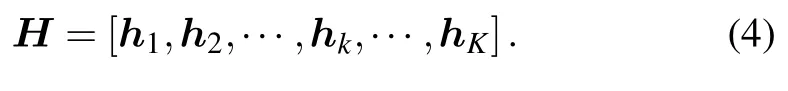
As depicted in Fig.1,we perform channel estimation at the BS by utilizing the pilot signals from users,Kusers simultaneously transmit pilot sequences with the length ofτto the BS.Then,the received signalY ∈CM×τat the BS after one-bit quantization is expressed as
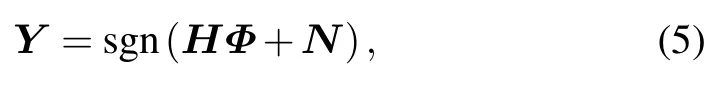
whereΦ ∈CK×τrepresents the pilot matrix composed of pilot sequences sent byKusers,each user’s pilots inΦis mutual orthogonal.N ∈CM×τis the noise matrix sampled from Gaussian distribution on the BS.The signum function sgn(·)is an element-wise operator for one-bit quantization defined as
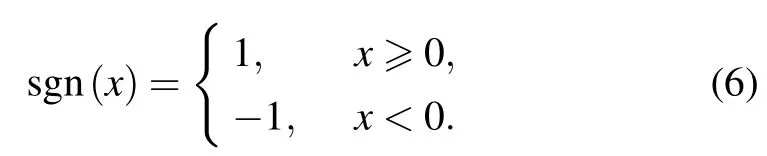
Thus,Yis a quantized signal where its element takes values from the set{1+j,1-j,-1+j,-1-j}.
The ultimate goal of channel estimation is to minimize the error between the estimated channel matrixand the real channel matrixH,whereis estimated from the received signalY.In order to recover the channel matrixfrom the highly quantized received signalYand the known pilot sequenceΦ,this paper will combine the channel attention mechanism to improve the CGAN architecture,which improves the accuracy and robustness of channel estimation using a generative adversarial network model.
III.CHANNEL ESTIMATION MODEL BASED ON CA-CGAN
A.CGAN Structure Based on L1 Loss
Conventional GAN is used to train a generative model based on an adversarial model.The basic idea is that the generator and the discriminator play against each other.The generator G learns the distribution of the input data to generate very real images,and the discriminator D needs to distinguish the generated image from the real image.But the generator learns the mapping from random noise to real data with instability and randomicity.For this reason,researchers propose CGAN,which introduces a conditional variableyand learns the mapping from conditional input to real data.In this paper,CGAN is utilized to learn the mapping relationship between the received signalsYand the pilot sequenceΦto the real channel matrixH.The received signalY,the pilot sequenceΦand the channel matrixHare regarded as two-channel images with the dimensionsM×τ×2,K×τ×2,andM×K×2,respectively.And the two channels of the image represent the real and imaginary parts of the complex matrix.
As shown in Fig.2,there are two neural networks as generator and discriminator respectively.The generator is responsible for estimating the channel matrixfrom the conditional input jointly composed of the quantized received signalYand the pilot sequenceΦ.The discriminator can identify the given input as either real label“1”or fake label“0”.
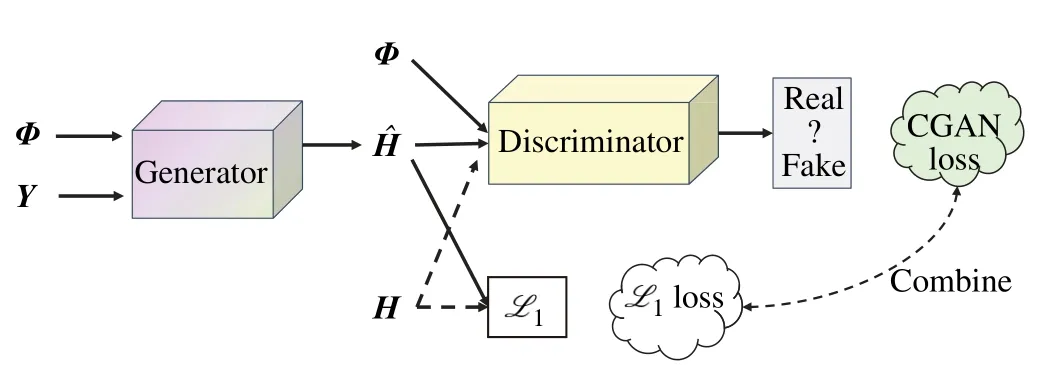
Fig.2 CGAN based on L1 loss structure diagram
The use of traditional loss functions in CGAN is beneficial to optimize the generator,and the generator must not only fool the discriminator,but also generate real images as much as possible.L2loss produces smoother images.Because it is equivalent to fitting the actual data of multiple peaks with a unimodal Gaussian distribution,the final generated sample is essentially an average of the sample data,resulting in a blurred image.TheL1loss,which can tolerate outliers,will mitigate such effects (relatively sharp).For this purpose,theL1loss is used instead of theL2loss,because theL1loss encourages less blur,making the generated image closer to the real image in pixels.Therefore,the loss function of CGAN consists of the following two parts:

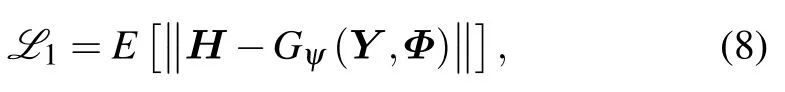
whereGψdenotes the generator parameterized byψ,generate an estimated channel matrix(i.e.,Gψ(Y,Φ)) that is more similar to the real channel matrixH.Dθdenotes the discriminator parameterized byθ.
Finally,the objective function of CGAN can be obtained as
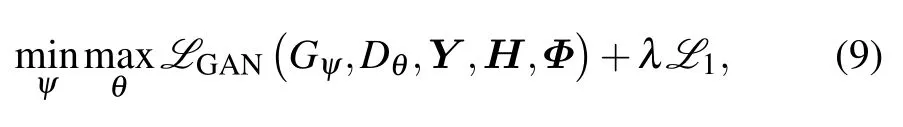
whereλis the importance coefficient ofL1loss.Once the trained generator is obtained,it can be used to perform channel estimation based on the newly input received signalYand the pilot sequenceΦ.
B.Channel Estimation Model Based on CA-CGAN
The generator of CA-CGAN adopts the U-Net architecture[19].U-Net uses a skip connection structure to combine the feature maps of the encoder and decoder through concatenate layers,so that the features extracted by the downsampling layer can be directly transferred to the upsampling layer to preserve the pixel-level details of different scales and resolutions.In the image super-resolution reconstruction task,researchers propose a channel attention mechanism[20],which autonomously learns to assign the weights of channel features,and performs weighting operations with the original feature channels.In this paper,an encoder is designed to enhance and remove image noise by introducing a channel attention mechanism.The specific structure is shown in Fig.3.The channel attention mechanism first uses the global average pooling operation to convert the global spatial information of the channel into the statistics of each channel,and then uses the 1×1 convolutional layer and the ReLu activation function to downsample the number of feature channels,and then uses 1×1 convolution restores the number of channels before,and finally uses the Sigmoid function to obtain the weight of each channel.
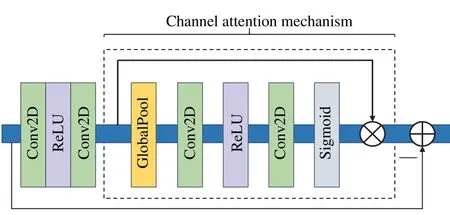
Fig.3 Channel attention encoder
The generator architecture is shown in Fig.4,first using one upsampling layer and one convolutional layer to rescale the input to the same size as the real channel matrix,and then using the channel attention encoder block in the U-Net architecture,through two 3×3 convolution layers extracts features,utilizes the channel attention mechanism to enhance the noise characteristics,and obtains significant noise features after fusion and removes them.The captured useful features are then passed to the next encoder block,continuously reducing the influence of noise factors and increasing the resolution of the generated channel image.The normal encoder block consists of a convolutional layer,a LeakyReLU activation layer,and an instance normalization layer.The decoder block is composed of an upsampling layer,a convolutional layer,and an instance normalization layer.The convolution kernel adopts a size of 4×4.To avoid the mode collapse problem caused by the generator generating samples with little variation to trick the discriminator,the tanh activation function is used to normalize the output value of the generator to [-1,1].At the same time,in order to make the generator generate more realistic channels,consider stacking residual blocks(ResBlock)to fully extract and utilize the effective information in lowresolution images.
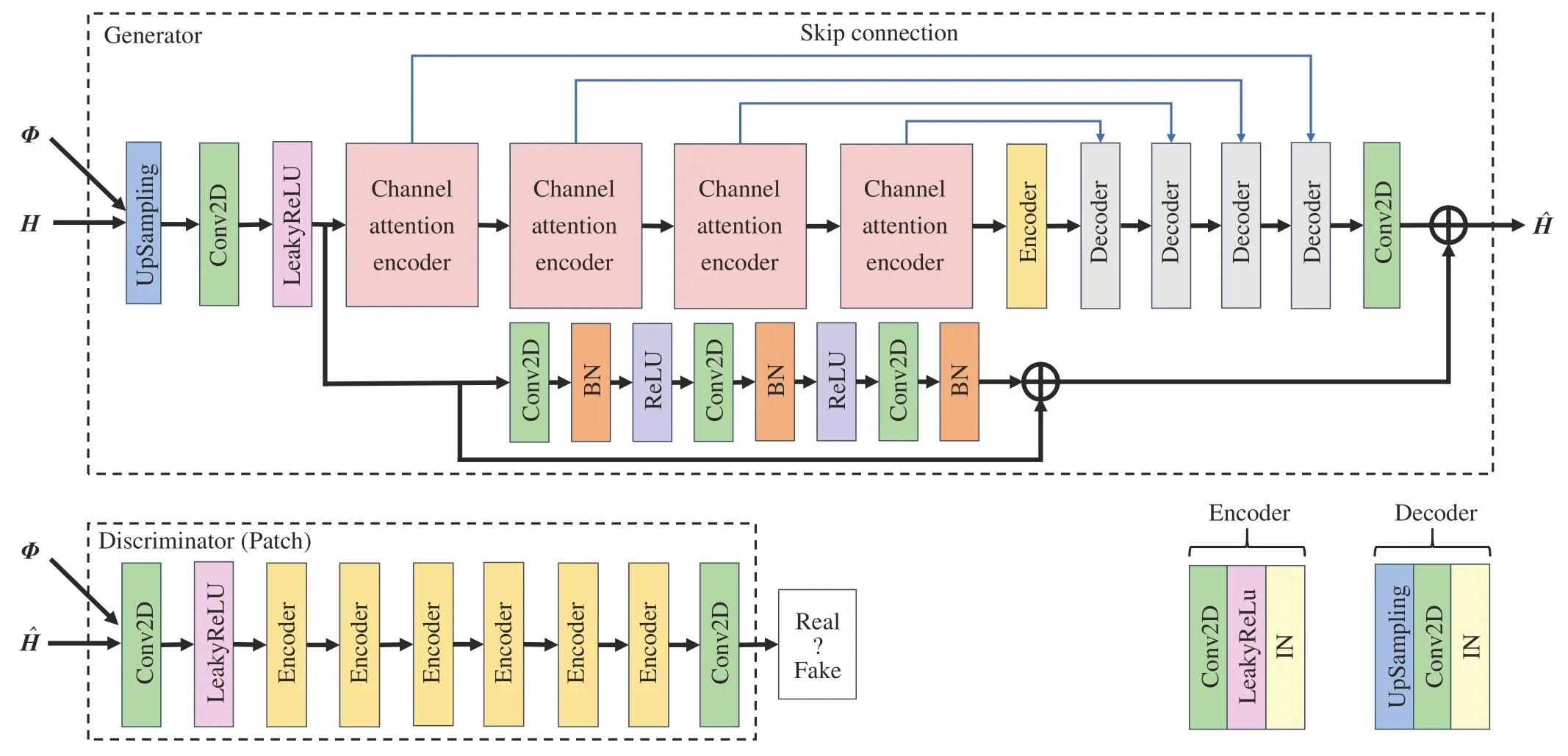
Fig.4 CA-CGAN network architecture
The discriminator adopts a simple convolutional neural network,and the goal is to distinguish whether the input is the real channel imageHor the channel imagegenerated by the generator.The specific structure is shown in Fig.4.In order to improve the recovery ability of detailed information,the discriminator adopts the idea of PatchGAN[21].PatchGAN uses convolution to map the input to anN×Nmatrix.Each element in the matrix represents a receptive field in the original image,corresponding to a patch of the original image.The discriminator takes the means to make a comprehensive judgment to make the image clear with certain high resolution and high detail preservation.The discriminator consists of one convolution layer,one LeakyReLU activation layer,and six ordinary encoder blocks,where the size of the convolution kernel is 4×4.The last layer uses the fully connected layer to replace the convolutional layer to obtain the receptive field,and then averages the receptive field to obtain the final output,indicating whether the input is a real channel image.
IV.SIMULATION ANALYSIS
This section verifies the performance of channel estimation using the CA-CGAN network architecture in different scenarios through simulation.Among the channel estimation methods using noisy pilots,the experimental results of Ref.[17]prove that the performance of the CGAN estimation method is superior to the traditional channel estimation methods,CNN and U-Net,and has certain comparability.Therefore,this section mainly examines the performance comparison between the CA-CGAN approach and the traditional least square(LS)channel estimation algorithm,and the CGAN estimation method.
A.Simulation Parameters and Evaluation Criteria
Channels are generated based on wireless InSite ray tracing to construct indoor sub-6G massive MIMO scenarios.The top view of the scenario is shown in Fig.5.The scene of ray tracing is an indoor massive MIMO scene with an area of 10 m×10 m×5 m room with two conference tables.The distributed antennas are evenly arranged in a part of the ceiling,2.5 m away from the ground.The 32 random users are distributed in a part of the room,at 1m height.As for the propagation model,each channel path can undergo a maximum of two reflections before reaching the receiver.
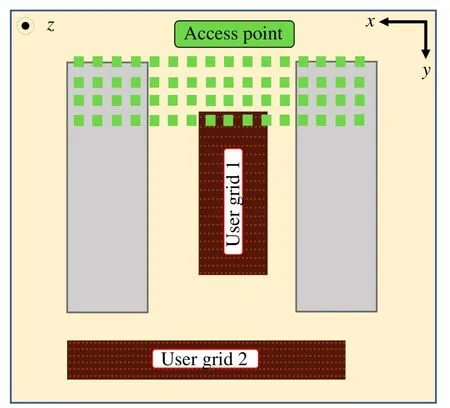
Fig.5 The top view of the indoor massive MIMO scenario
DeepMIMO simulations are used to generate four different numbers of BS antenna channel datasets.Among them,the number of antennas on the BS side are set toM64,M128,M192,andM256,and the number of users is fixed atK32.All other parameters are set by default,where the antenna spacing is the half wavelength,the bandwidth is 0.01 GHz,and the number of multipaths isL10.
The size of the channel matrixHcontained in the channel dataset is 64×32,128×32,192×32,and 256×32,respectively.Based on the channel matrix datasets and the pilot sequences,the one-bit quantization method is used to generate the corresponding datasets of the received signals,and white Gaussian noise with different signal-to-noise(SNR)ratios of-10 dB to 30 dB is superimposed on the received signals.All datasets are divided into training sets,test sets,and validation sets according to the proportion of 50%,40%,and 10%,respectively.To train the proposed network model to speed up the convergence under low SNR and maintain stability under high SNR,the generator adopts the Adam optimization algorithm,the discriminator applies the RMSProp optimization algorithm,and the learning rates are respectively set to 2×10-4and 2×10-5.
In this paper,the mean square error (MSE) is utilized as the evaluation standard to measure the degree of difference between the real channel matrixHand the estimated channel matrix,and to evaluate the channel estimation performance.Its expression is
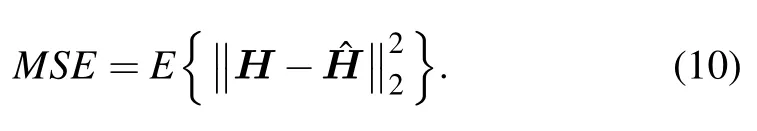
B.Complexity Analysis
To show the complexity of the generator in the CA-CGAN model,we compared it with CGAN in terms of the number ofnetwork parameters,FLOPs,and inference time.The results are shown in Tab.1.

Tab.1 Comparison of model complexity
It can be seen from Tab.1 that the complexity of the network architecture CA-CGAN proposed in this paper is slightly higher than that of CGAN.Although adding channel attention module will increase the complexity of the model,it can effectively alleviate the contradiction between the complexity of the model and the expression ability.We hope to improve the representation ability of the model without“excessively”increasing the complexity (mainly model parameters)of the model.
C.Analysis of Simulation Results
First,to visually see the performance improvement obtained by the CA-CGAN method,the SNR is set to 0 dB,the pilot sequence length is 8,and the real components of the real channel matrixHand the estimated channel matrixare plotted as pseudo-color images,the color corresponds to the data value of the channel matrix,and the visualization of the channel matrix is shown in Fig.6.From Fig.6(a) and 6(b),it can be seen that the real channel and the channel images generated by CA-CGAN are very similar,indicating that the method generates channel details well.For the CGAN method,a more ambiguous result is obtained,as shown in Fig.6(c).Therefore,using the CA-CGAN architecture can produce more realistic channel estimation results.
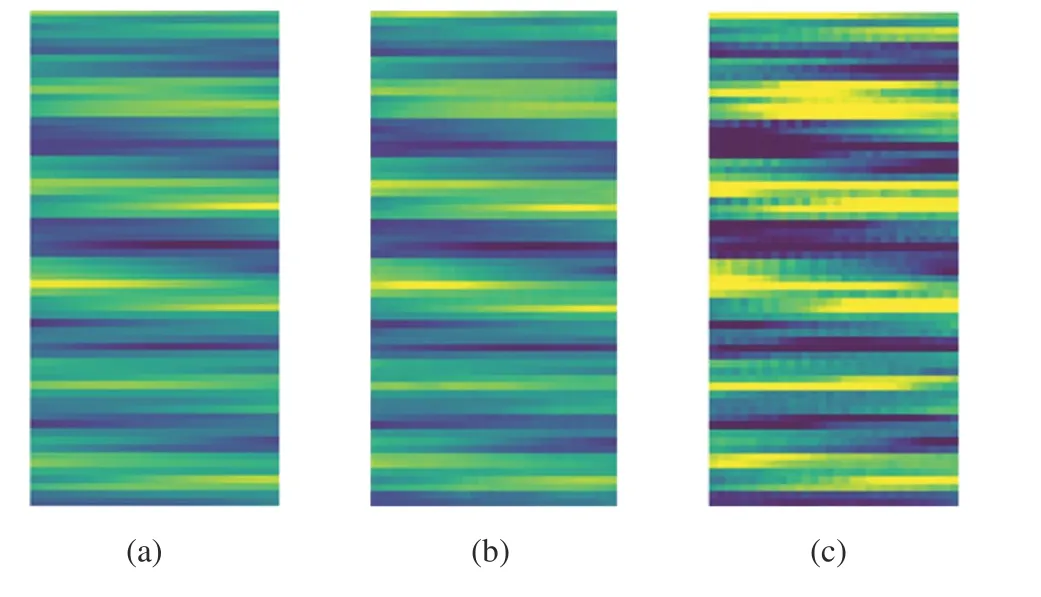
Fig.6 Visualization of channel estimation by different methods:(a) real channel;(b)CA-CGAN estimated channel;(c)CGAN estimated channel
To compare the performance between CA-CGAN and CGAN and the traditional LS algorithm at different SNRs,the range of SNR is set to vary from-10 dB to 30 dB.The simulation results are shown in Fig.7,which shows the MSE values obtained by channel estimation using several methods.As can be seen from Fig.7,the traditional LS method performs poorly.The estimation errors of several methods decrease with the increase of SNR.No matter how the pilot sequence length and SNR change,the channel estimation error of CACGAN is always smaller than that of CGAN,especially the estimation error of CA-CGAN with pilot sequence length of 4 is significantly lower than CGAN with pilot sequence length of 8.Since the channel attention mechanism is added to remove the influence of noise during the training and learning of the CA-CGAN network model,the channel estimation accuracy of CA-CGAN is significantly higher than that of CGAN under the same SNR.When the pilot sequence length is 8 and the SNR is 25 dB,the channel estimation accuracy of CACGAN is about 7.5 dB higher than that of CGAN.In addition,it can be seen from Fig.7 that when the pilot sequence length increases,the estimation error of CA-CGAN decreases,but the performance gap is not large.
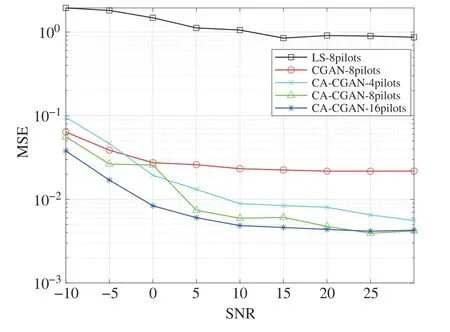
Fig.7 MSE performance comparison of various algorithms under different SNR
Considering that the BS deploys different numbers of antennas,the SNR is fixed as 0 dB,and the channel estimation performance of CA-CGAN and CGAN is investigated.The simulation results are shown in Fig.8.As can be seen from Fig.8,with the increase of the number of BS antennas,CACGAN still maintains good performance even when the length of the pilot sequence is small,and with the increase of the length of the pilot sequence,the performance has significant improvement,and although the estimation error of the CGAN method is reduced,the performance gain is not obvious when the length of the pilot sequence is increased from 8 to 16.At the same time,under the same pilot sequence length,when the number of BS antennas increases to 256,the MSE value of CA-CGAN increases slightly,but it is still better than the performance of CGAN.
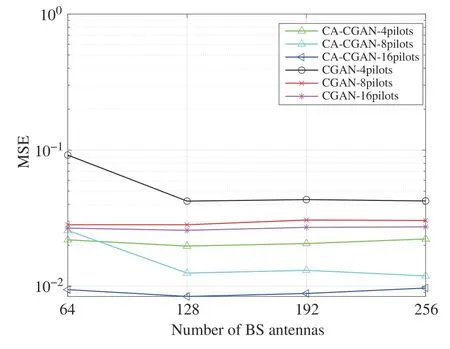
Fig.8 MSE performance of different algorithms with the number of base station antennas
V.CONCLUSION
Using one-bit ADC instead of high-resolution ADC can greatly reduce the receiver cost and power consumption of massive MIMO systems,but utilizing traditional methods for channel estimation will cause serious performance losses.Some deep learning-based methods are affected by noise and have low estimation accuracy.In this paper,the conditional generative adversarial network is improved by combining the channel attention mechanism,and the CA-CGAN channel estimation method is proposed,which adaptively learns the real loss from the data.The simulation results show that the network model proposed in this paper can obtain better channel estimation performance with a smaller number of pilots,making the generated channels more realistic.Utilizing lowprecision ADC at BS can reduce energy consumption and equipment costs associated with a large number of antennas.Signals quantized by low-precision ADCs still suffer from nonlinear impairments,although our work strives to eliminate them.On this basis,our future work will conduct research on high-precision ADC massive MIMO channel estimation.
杂志排行

Journal of Communications and Information Networks的其它文章
- 6G-Enabled Edge AI for Metaverse:Challenges,Methods,and Future Research Directions
- Resource-Constrained Edge AI with Early Exit Prediction
- FLIGHT:Federated Learning with IRS for Grouped Heterogeneous Training
- Local Observations-Based Energy-Efficient Multi-Cell Beamforming via Multi-Agent Reinforcement Learning
- A Lightweight Mutual Authentication Protocol for IoT
- Multi-UAV Trajectory Design and Power Control Based on Deep Reinforcement Learning