不平衡数据分类的改进k-GSMOTE方法
2022-06-02徐玲玲迟冬祥黄彦乾曹钧烨
徐玲玲, 迟冬祥, 黄彦乾, 曹钧烨
(上海电机学院电子信息学院,上海 201306)
不平衡数据主要是指生活和生产中采集或获取到的各类存在类别数量不平衡的数据,常表现为数据集中于某一类数据的数量显著多于另一类或剩下其他几类的数量[1]。以二分类的分类任务为例,设M为数据样本集合,S1、S2分别为数据集的两个子集,且有S1∪S2=M,S1∩S2=Ф。若满足|S1|<|S2|,则将M称为不平衡数据集,其中|S|表示集合S的个数。用不平衡比例(Imbalanced Ratio,IR)来表示两类样本间的不平衡程度,s1、s2分别为两个子集元素的个数,IR具体计算公式如下:

IR的值越小,数据集中样本不平衡比例越大;IR的值越大,不平衡比例越小。以工业生产中产生的数据展开描述,实际生产工作的设备大部分处于正常运行状态,故障发生的频率很小,因而收集到的数据大多处于正常状态,异常的故障数据量很少,正常与异常设备故障数据数量之间存在明显的不平衡现象,由此可将工业生产设备运行数据视作工业不平衡数据。传统的机器学习模型通常基于数据平衡的假设,这一假设使分类器在训练过程中易偏向数量较多的多数类正常样本,忽略样本量极少的异常少数类样本对分类模型的贡献,将使具有巨大研究价值的少数异常类样本的分类准确率降低,可见传统的机器学习模型无法适用于不平衡数据[2-3]的分类。在实际工业生产过程中及时发现潜在故障设备,不仅能避免因设备故障导致的大量生产材料及财产损失,也能最大可能降低设备故障导致设备操作人员面临的安全隐患,因而构建基于不平衡数据内在特征的分类算法迫在眉睫[4-7]。
数据不平衡现象广泛存在于各行各业,越来越多的专家学者投身对其研究讨论。向鸿鑫等[8]综合论述了近年来处理不平衡数据集分类任务较为常见的方法。Garcia 等[9]提出了一种进化欠采样方法,旨在从原始训练集中选择数据样本的最佳子集,使用不同的适应度函数,在不平衡数据集的类分布和分类器性能之间取得良好的平衡。文献[10-11]为了修正支持向量机对多数类偏差形成的偏移决策边界,引入权重参数以调整支持向量机的分类函数,提高少数类对分类器的贡献,迫使分类平面向多数类倾斜,消除了数据不平衡对支持向量机产生的负面影响。目前较为成熟的不平衡数据处理分类路线大体上可以分为两类[12]:一类是从数据自身层面通过特征选择或重采样技术重新调整数据样本数量的分布结构,以期降低数据集不平衡度;另一类是从分类模型层面对现有处理平衡数据的分类算法进行改进,使其适应于不平衡数据的内在特征,以提高分类器的分类性能。本文主要立足于数据自身层面,提出了一种基于几何合成少数类过采样技术(Geometric Synthetic Minority Oversampling Technique,GSMOTE)算法改进的k-GSMOTE 过采样方法,为少数类样本进行过采样,从而增加少数类样本的数量,进而提高少数类的分类性能。
1 GSMOTE过采样方法


图1 以输入空间的原点为中心的单位超球体截面

图2 新生成点矫正变换示意图
2 改进的k-GSMOTE过采样方法
本文提出了一种基于GSMOTE 算法改进的k-GSMOTE 过采样方法,与原算法相比,结合了k-means[14]聚类的GSMOTE 过采样技术不仅能够有效缓解SMOTE[15]过采样合成新样本过程中产生噪声、边界样本合成不当等现象的发生,还能有效缓解常被忽略的类内不平衡问题。

图3 新生成点变形变换示意图
为了更好地描述k-GSMOTE 过采样方法的实现过程,给出了k-GSMOTE 算法的详细伪代码描述,算法中主要包括的输入参数有:k-means 均值聚类个数k∈[3,20]、多数类样本集Smaj、多数类样本的数量nmaj、少数类样本集Smin、采样比率r∈(0,1)、需要新合成样本总数N、最近邻选择策略αsel、少数类选择策略中的k近邻个数x、截断因子αtrunc∈[-1,1]、形变因子αdef∈[0,1],其中N、x、αsel、αtrunc、αdef均为根据不平衡数据的特点进行设定的超参数,且有N=nmaj·[ ]r/(1-r) 。算法的输出是新生成的少数类样本集Sgen,随后便可将其加入原始不平衡数据集中,从而降低数据集的不平衡度。k-GSMOTE算法的流程描述如下:
输入k,Smaj,nmaj,Smin,r,x,αsel,αtrunc,αdef
输出Sgen
步骤1 对输入的原始不平衡多数类Smaj、少数类Smin以及k-means 均值聚类个数k,通过以下聚类函数进行聚类划分,返回k-means 均值聚类簇集S。
Function KMeans(Smaj,Smin,x):
returnS
步骤2 对聚类簇集S中的少数类子群集合成新样本,首先在少数类子群中任意选择一个少数类样本xcenter,本文从3种采样策略中选择少数类采样策略,即αsel=Smin,此时k-GSMOTE 合成新样本的近邻选择策略与SMOTE 一致。在xcenter的k近邻中选择构成单位超球体表面的一点xcenter,超球体半径R=‖ ‖xcenter-xsurface。单位超球体的构造函数如下:

其中,向量vi是由正态分布N(0,1)中p个随机数生成;r为服从均匀分布U(0,1)中的随机数。函数返回值为单位超球体上初始生成的新样本xgen。
步骤3 构造投影向量x//和垂直向量x⊥,矫正新生成的样本xgen,使其不偏离由xcenter和xsurface构造的单位超球体(即为设定的样本合成安全区域),x//将生成的xgen投影到与xcenter和xsurface相关联的单位超球体,x⊥则将生成的点垂直朝向xgen和e//定义的同一单位超球体。构造公式为

步骤4 在投影向量x//和垂直向量x⊥的共同作用下,运用截断变换函数Truncate()、形变函数Deform()以及平移缩放函数Translate()对新生成少数类样本点xgen进行一系列的规范变换。以上涉及的变换函数如下所示:

步骤5 最后将新生成的少数类样本xgen加入Sgen样本集中,即Sgen←Sgen∪{xgen}。
重复以上步骤,直到满足|Sgen|<N,最终完成了整个生成新样本的全过程。
3 算法验证与讨论
以上介绍了k-GSMOTE 过采样算法所需要的主要超参数,本文实际实验过程中的参数设置如 下:αsel=′auto′、αtrunc=1.0、αdef=0、k=5、r=0.5。实验环境如表1所示。

表1 实验环境
以玻璃类型不平衡数据集为例,通过对玻璃类型不平衡数据进行k-GSMOTE 过采样操作,过采样前后对比如图4所示。

图4 经过k-GSMOTE过采样处理前后对比
图4(a)中玻璃类别标签的取值依次降低,数据集整体呈现明显的不平衡现象,数量少的少数类样本对分类的贡献很低,能够预想到若将该原始不经过任何处理的不平衡数据用传统的分类模型进行学习训练,将使对少数类样本的识别变得异常困难;图4(b)则是经过k-GSMOTE 过采样后各类样本数量的比较,当采样比例r设置为0.5时,多数类样本数量和少数类样本数量基本达到平衡。
本文所使用的玻璃不平衡实验数据集主要有序号、镭、钠、镁、铝、硅、钾、钙、钡、铁(Id、Ra、Na、Mg、AI、Si、K、Ca、Ba、Fe)等10 个属性特征,类别标签有7 种不同的取值。玻璃类型不平衡数据集类别标签数量分布及比例,如表2所示。数据集类别标签的取值存在明显的不平衡,占比最高是类别为2 的标签,其值为35.5%,而最少的类别6 仅占4.2%,少数类样本和多数类样本之间的不平衡比约为1∶8,属于典型的不平衡数据集。工业玻璃数据集的分类任务是根据以上提及的9 种化学成分特征在工业玻璃中的含量,推断该玻璃可能的类型,最终达到确定该玻璃用途的目的。
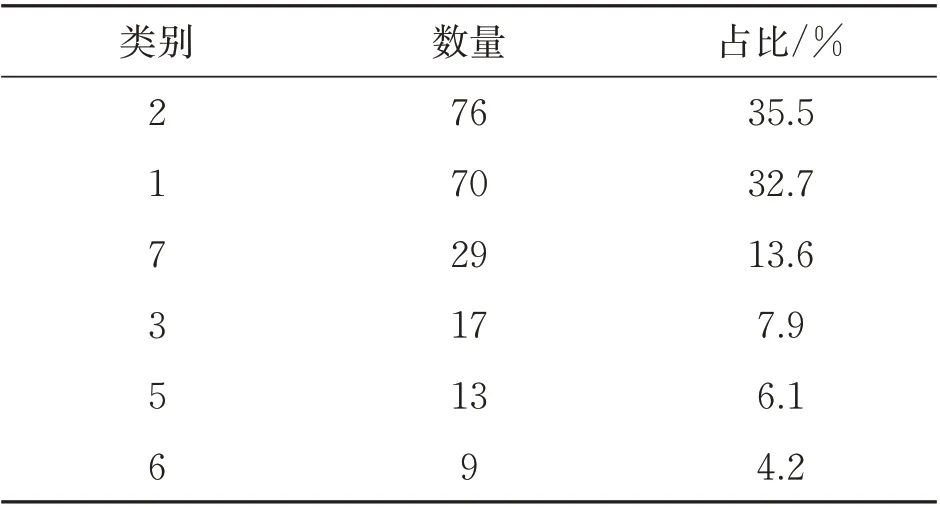
表2 玻璃不平衡数据集类别标签数量分布及比例
实验过程中设置了未经过采样处理的玻璃数据集、经过GSMOTE过采样和k-GSMOTE过采样后的玻璃数据集3组分类进行对比实验,分类过程中将玻璃类型不平衡数据集划分为训练集(Train)和测试集(Test)两个子集。表3~表5分别展示了以上3组对比实验在逻辑回归(Logistic Regression,LR)、K近邻(K-Nearest Neighbor,KNN)、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)、线性支持向量机(Linear Support Vector Machine,LSVM)、核支持向量机(Kernel Linear Support Vector Machine,KSVM)以及朴素贝叶斯(Naive Bayesian,NB)等7组基础分类器上的分类评估结果,对比3组对照组在测试集上准确率、F1分数、召回率、精确率以及均方误差等5个分类评价指标,可以看到经过本文分类算法处理后,7组基础分类器的分类性能在未经采样处理以及经过GSMOTE过采样的基础上逐步得到了改善。表中加粗数据表示该分类评估指标中的最优值。

表3 未经过采样处理的玻璃数据集分类评价结果
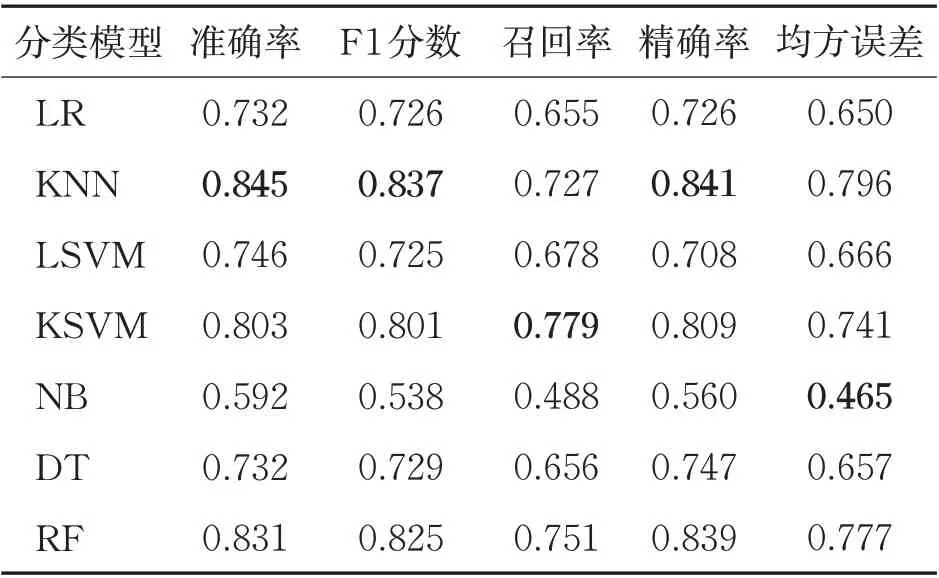
表4 经过GSMOTE过采样后的玻璃数据集分类评价结果

表5 经过k-GSMOTE过采样后的玻璃数据集分类评价结果
此外,由表3可知,未经过k-GSMOTE 过采样的分类准确率取值最高的随机森林分类器仅为0.833。结合表5 可知,在原始不平衡数据分类效果最差的NB 分类器,经过本文k-GSMOTE 过采样方法采样后分类训练模型整体的分类准确率从0.500 提升到0.633。以上实验结果均展示了本文机器学习分类模型在处理工业玻璃不平衡数据分类任务上的可行性和有效性。
为了进一步提高本文算法的说服力,避免单一片面实验数据可能带来实验结论的偏差,在已公开的不平衡信用卡欺诈检测数据集中,用本文提出的改进k-GSMOTE过采样方法进行一系列对比分析实验。由于信用卡欺诈检测是二分类任务,根据其内在属性特征,采用的分类评价指标主要有AUC值、F1分数、召回率以及均方误差。未经过处理的不平衡数据在LR、DT、RF、集成学习(AdaBoost 和XGBoost)、神经网络(Artificial Neural Network,ANN)以及LightGBM 等不同基础分类器上的分类评估结果,与经过本文k-GSMOTE过采样方法采样后的不平衡数据在不同基础分类器上的分类评估结果分别见表6、表7。

表6 未经过处理的分类评估结果

表7 经过k-GSMOTE过采样后分类评估结果
对比表6、表7 可知,本文基于k-GSMOTE 的过采样方法在各项指标上均呈现出较好的发展趋势,实验结果验证了本文算法的可靠有效。
4 结 语
长期以来,不平衡数据的分类一直是机器学习领域的一个重要的研究课题。在数字信息化时代,海量数据逐渐在生活和工业生产中占据半壁江山,大数据使世界变得更精确的同时,也带来了前所未有的数据分析挑战,广泛存在各行各业的数据不平衡现象无疑增加了数据挖掘的难度。机器学习技术的日趋成熟足以让传统的分类算法在平衡数据集上取得较为满意的分类效果,而面对不平衡数据集传统分类算法常常劳而无功。受GSMOTE 过采样方法的启发,k-GSMOTE 方法针对前者的不足进一步改进了合成新少数类的方法,将采样区域衍生至超球体的几何区域,以扩展线性插值机制;通过k-means 聚类划分巧妙地解决了众多分类算法普遍忽略的类内不平衡分类问题,使不平衡数据分类问题不再受限于类内不平衡,在经典的玻璃不平衡数据集和不平衡信用卡欺诈检测数据集上,各类评价指标普遍得以大幅提升,验证了本文改进算法的有效性。
