基于BiLSTM的生猪音频识别
2022-05-20查文文陈成鹏辜丽川
邵 睿,彭 硕,查文文,陈成鹏,辜丽川,焦 俊
(安徽农业大学 信息与计算机学院,合肥 230036)
0 引 言
猪声包含丰富信息,是判断生猪行为的依据,通过识别生猪音频可以分析生猪行为[1],有助于生猪福利养殖。提取声学特征和构建声学模型是生猪音频识别的关键,在早期相关研究中,Ferrari等人[2]通过分析猪声信号的均方根和峰值频率,对患病猪只咳嗽声实现有效识别。Exadaktylos等人[3]分析猪咳嗽声、打呼噜声、尖叫声中高能量部分的功率谱密度,利用模糊c-均值聚类算法,对不同猪声进行分类。徐亚妮等人[4]提取梅山母猪咳嗽声功率谱密度特征,用改进的模糊C均值聚类算法对猪咳嗽声和尖叫声进行识别,效果良好。文献[5-6]提取猪声信号的MFCC,提出用SVM模型对生猪的患病叫声进行监测的方法,满足了识别需要。
随着深度学习技术发展,深层神经网络对声学特征进行多层非线性处理,将声学特征转换为不变性、鉴别性的特征,以实现猪声的识别。黎煊等[7]用深度信念网络实现对猪咳嗽声的识别,效果良好;赵健等[8]通过构建基于DNN-HMM声学模型对连续的猪咳嗽声进行建模,针对连续猪声中的咳嗽声实现有效识别;苍岩等[9]用MobileNetV2网络对不同状态下猪只声音谱图进行分类识别,通过谱图优化、模型压缩,模型取得较高的识别精度。
生猪音频信号是时序信号,提取生猪音频信号MFCC,构成多帧的猪声特征向量序列。对于多帧的猪声特征向量序列,当前帧不仅与前面多帧有联系,也与后面多帧有联系。[10]BiLSTM网络分别沿前向时序和后向时序处理猪声特征向量序列,充分捕捉前后多帧间的时序信息并对生猪音频进行声学建模,形成基于BiLSTM网络的声学模型,实现对5种猪声的有效识别。本文算法整体流程如图1所示。
1 试验数据采集与处理
1.1 生猪音频采集
生猪音频采集于安徽蒙城京徽蒙生猪养殖基地,采集对象为10只150kg左右的长白猪。采集工具为飞利浦VTR5110录音笔,采用单声道录制,采样频率为44100Hz,采样精度为16位,采样格式为wav。
1.2 猪声音预处理
为了尽可能减轻噪声污染、减少非猪声信息,需要对生猪音频信号去噪及端点检测。
1.2.1 基于维纳滤波的生猪音频信号去噪
猪场环境中存在低频的风机运行声,猪声采集的过程中也有金属撞击声、鸟鸣声等高频噪声,而猪声的频率主要集中在10KHz内[11]。因此,猪声频率与多种环境噪声的频段重叠,传统带通滤波器难以对采集的猪声进行有效去噪。本研究借鉴了语音去噪中效果较好的维纳滤波[12],维纳滤波器是一种基于最小均方误差准则的平稳过程去噪的最优估计器。
假设采集的音频信号x(n)由猪声信号s(n)和猪场噪声信号v(n)叠加而成,维纳滤波器传递函数是(n),滤波器输出信号是y(n)=(n),即猪声信号的估计值。维纳滤波器的输入输出关系如图2所示。
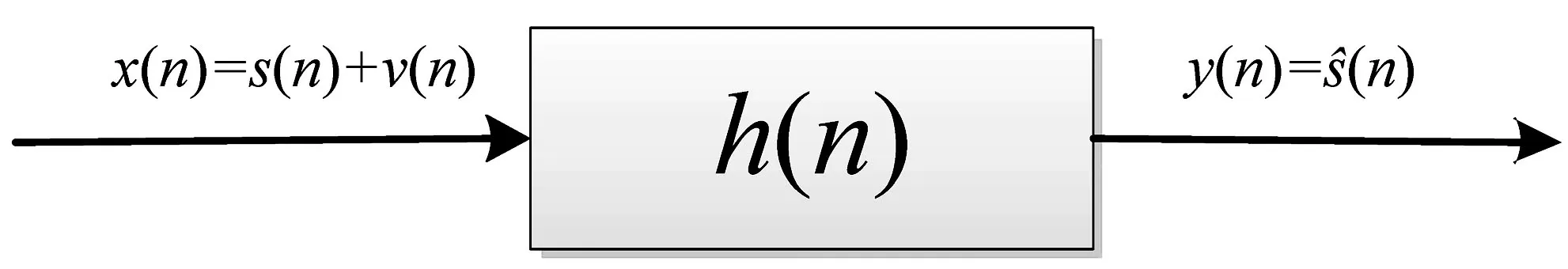
图2 维纳滤波器的输入输出关系
猪声信号s(n)与滤波器输出信号(n)之间的误差记为e(n),维纳滤波器按最小均方误差准则使得E[e2(n)]达到最小,根据正交性原理,最佳的传递函数h(n)对任意m均满足下式。
E[{s(n)-(n)}·x(n-m)]=0
(1)
通过计算音频信号x(n)和猪场噪声信号v(n)的功率谱得到音频信号的先验信噪比,用先验信噪比计算维纳滤波器传递函数h(n),得到滤波器输出信号(n),即音频信号去噪后的猪声信号。
如图3所示,对比生猪发情声信号经维纳滤波处理前后的波形图,可知滤波后的生猪发情声信号噪声明显减少,且原信号基本没有发生失真。
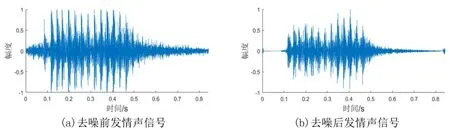
图3 猪发情声维纳滤波前后的对比图
1.2.2 生猪音频信号端点检测
端点检测可以有效减少生猪音频信号特征提取的运算量,本研究借鉴文[13]中对生猪音频信号处理效果较好的基于改进的EMD-TEO(经验模态分解的Teager能量算子)倒谱距离的端点检测算法,确定生猪音频信号的起止点。步骤如下:
(1)采用EMD(经验模态分解)算法将生猪音频信号分解为多个基本模式分量。
(2)再利用TEO(Teager能量算子)对模态分量进行处理,获得其能量谱作为第一个判决参数。
(3)引入短时倒谱距离方法,计算倒谱距离作为第二个判决参数。
(4)根据(2)、(3)中得到的判决参数,设置阈值做出判决,确定生猪音频信号的起止点。
1.2.3 MFCC提取
MFCC是一种基于人耳听觉特性的特征参数,有较好的鲁棒性。利用音频频率与梅尔频率倒谱系数成非线性对应关系,将线性频谱映射到非线性的梅尔频率频谱中。13维MFCC反映猪声静态特征,13维MFCC的一阶、二阶差分反映猪声动态特征,故用39维MFCC特征可以包含猪声中更多特征。[8]
这5种猪声样本的MFCC三维图如图4所示。
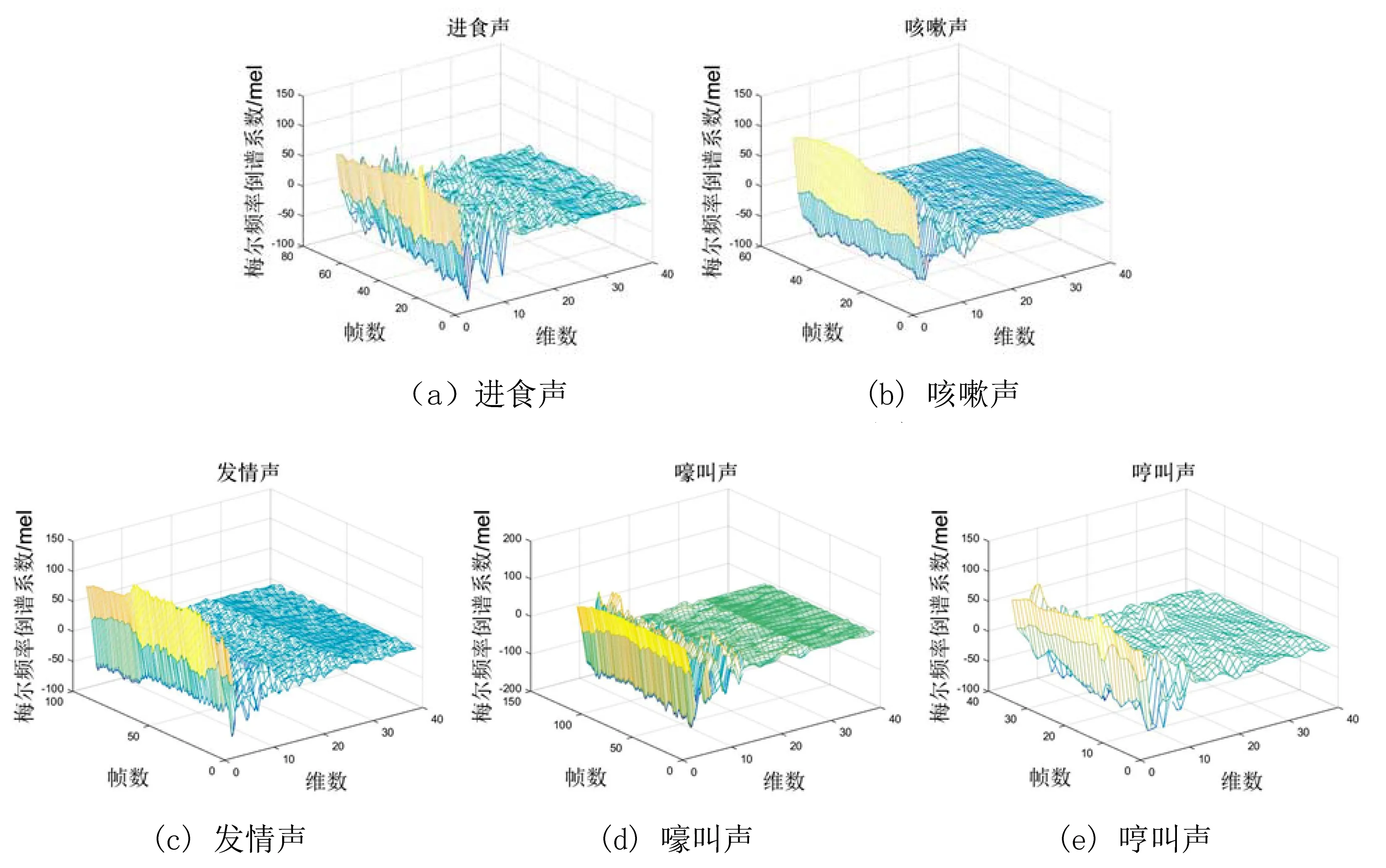
图4 猪声样本的MFCC图
每种猪声样本的标签用独热码表示,即进食样本、咳嗽样本、发情样本、嚎叫样本、哼叫样本分别用[1,0,0,0,0]、[0,1,0,0,0]、[0,0,1,0,0]、[0,0,0,1,0]、[0,0,0,0,1]标记。
2 生猪音频识别模型
2.1 长短时记忆单元(Long Short Term Memory,LSTM)
LSTM网络是对循环神经网络(Recurrent Neural Network,RNN)的改进,它克服了RNN梯度消失的问题,可以对序列中有效信息进行长时记忆。[14-18]LSTM用内部自循环结构来控制信息流,通过输入门、遗忘门、输出门3个非线性门控单元和1个记忆单元来控制信息的流通和损失,解决了RNN中神经元的长期依赖问题。一个完整的LSTM内部结构如图5所示。
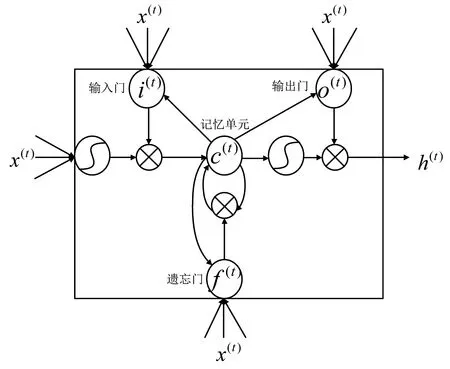
图5 LSTM结构图
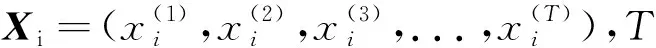
(2)
(3)
(4)
(5)
(6)
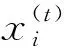
2.2 BiLSTM网络
LSTM网络按某一顺序处理序列,BiLSTM网络就是在LSTM网络中使用两套连接权重分别沿前向时序和后向时序[19,20]对同一序列进行建模。BiLSTM网络结构图,如图6所示,x(t)表示序列中第t帧的特征向量,其中t=1~T,T是样本序列中的总帧数。在BiLSTM网络中,x(t)被LSTM网络分别沿前向时序和后向时序处理并输出信息h(t)。
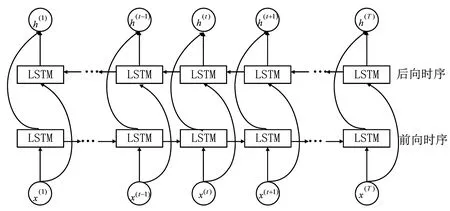
图6 BiLSTM网络结构图
2.3 模型构建
本研究以构建的猪声识别网络(PigVocalizations net,PVnet)为声学模型,如图7所示,PVnet模型由2层BiLSTM网络层(BiLSTM1和BiLSTM2)和3层全连接层(FC1、FC2和FC3)构成。FC1和FC2用非线性激活函数ReLU和正则化方法Dropout技术[21]来避免训练过拟合,正则化参数值取0.05(即丢弃5%的神经元),FC3用函数Softmax分类。
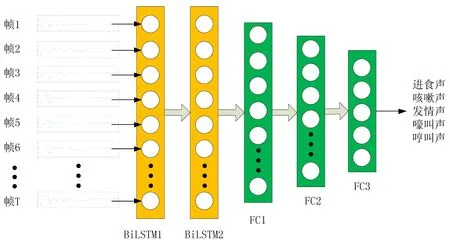
图7 PVnet3声学模型结构图
输入PVnet模型的样本是大小为T×39特征序列,T为样本所包含的帧数,39为特征向量维数。样本首先经BiLSTM1处理,输出大小为T×78的特征序列,再经BiLSTM2处理,输出大小为1×156的向量。1×156的向量依次经FC1、FC2和FC3处理,分别降维到1×20、1×10、1×5,最后利用Softmax函数计算出样本的分类概率向量[S1,S2,S3,S4,S5],其中S1、S2、S3、S4、S5分别表示样本属于进食声、咳嗽声、发情声、嚎叫声、哼叫声的概率。
Softmax计算公式为:
(7)
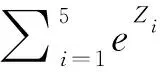
3 试验结果及分析
本试验采用的CPU为Inter(R)Core(TM) i7-9700,内存16G,GPU为NVIDIA GeForce RTX 2080Ti,操作系统为Window 10,深度学习框架为TensorFlow,版本号1.13.1。PVnet模型训练参数如表1所示。

表1 PVnet模型训练参数
加权交叉熵函数公式如下:
猪声样本共有3750个,其中进食、咳嗽、发情、嚎叫和哼叫的样本分别为1290、400、310、930和820个。不同类样本的数量相差较大,不利于模型训练,为了克服样本数量不平衡问题,单个样本的损失函数采用可以调整不同类别样本在损失函数上的权重的加权交叉熵损失函数。
训练模型时,改进每个训练批次中第i个(i=1,2,...,32)样本属于第j类(j=1,2,3,4,5,1~5分别表示进食声、咳嗽声、发情声、嚎叫声、哼叫声)的交叉熵损失函数,
(8)
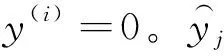
(9)
βj是训练集中第j类的样本数占样本集的样本总数比值。
进一步可得代价函数如下:
(10)
3.1 模型性能测试
由于猪声样本集属于不平衡样本集,PVnet模型采用准确率(Accuracy,Acc)来衡量模型整体的分类性能是不准确的。因为可能存在准确率很高,但模型对少数类样本分类效果不佳的情况。故用总体识别率(Total Recognition rate,TRrate)来衡量PVnet模型的整体分类性能,计算公式如下:
(11)
Acc(j)表示第j类样本的识别准确率,其中j=1,2,3,4,5(1~5分别表示进食声、咳嗽声、发情声、嚎叫声、哼叫声)。
采用5折交叉验证方法,3750个猪声样本被随机分成5份大小相同的互斥子集,每个子集包含750个猪声样本。每次用4个子集的并集作为训练集,余下的1个子集作为测试集。对PVnet模型进行5次训练和测试,PVnet模型在测试集上5次试验结果如表2所示,
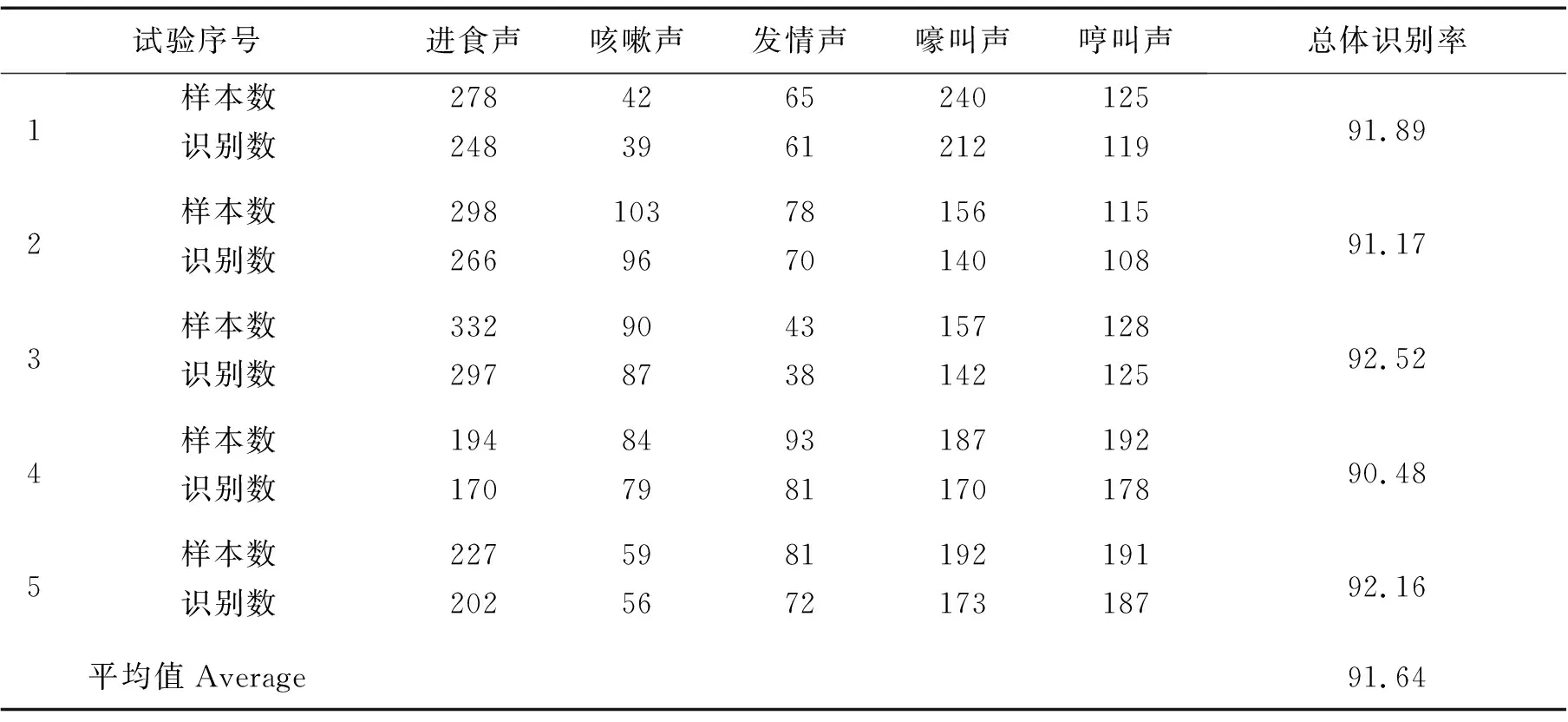
表2 PVnet模型的5折交叉验证结果
由表2知,各组PVnet模型的总体识别率均高于90%,最高为92.52%,5组总体识别率均值为91.64%,表明基于BiLSTM的声学模型有稳定的识别性能和较高的识别精度。
3.2 算法应用测试
为了对基于BiLSTM模型进行算法应用测试,以样本集外两段时长为1.22h和2.83h的生猪音频为测试语料。经预处理、MFCC提取、人工标记得391个猪声样本,其中进食、咳嗽、发情、嚎叫、哼叫的样本分别有103、63、52、78、95个。由表2知,PVnet模型的最佳试验组是第3组,将其命名为PVnet(3)。391个样本在PVnet(3)模型上进行算法应用测试,用大小为5×5的混淆矩阵表示模型对5种样本的分类结果。矩阵中任意一个元素xij,表示真实标记为j的样本被预测为i的数量,其中i、j=1,2,3,4,5(1~5分别表示进食声、咳嗽声、发情声、嚎叫声、哼叫声)。
如图8所示,PVnet(3)模型总体识别率为90.70%,对进食、咳嗽、发情、嚎叫和哼叫的样本识别率分别为88.35%、93.65%、90.38%、88.46%、92.63%。可知PVnet模型有一定的泛化性能,对5种样本均能较好识别。
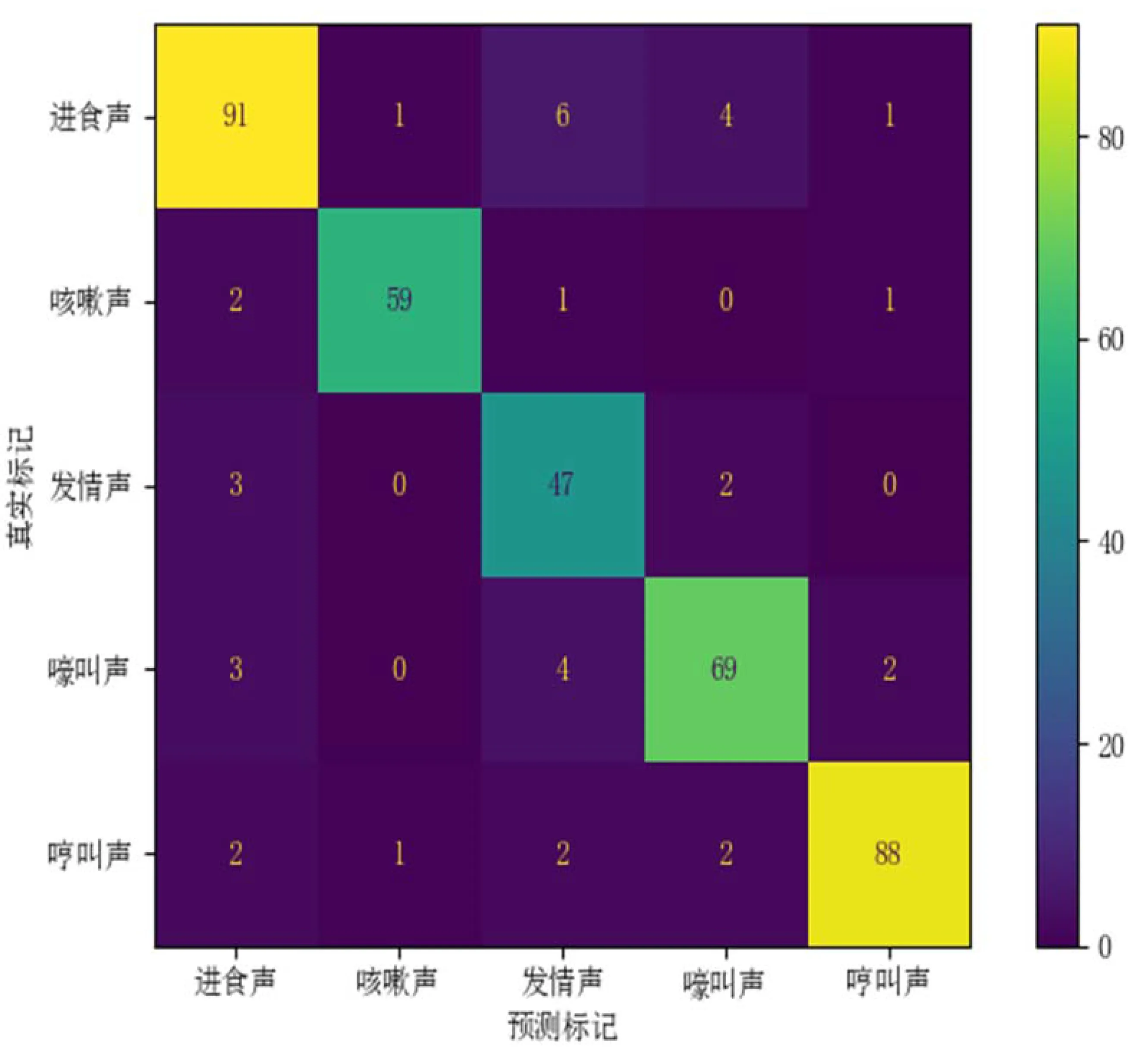
图8 混淆矩阵
4 结 论
本研究以长白猪进食声、咳嗽声、发情声、嚎叫声和哼叫声为研究对象,提出了对5种生猪音频进行识别的方法,构建了基于BiLSTM的生猪音频识别模型(PVnet模型),在猪声样本集下对PVnet模型进行5折交叉验证试验。结果表明,5组PVnet模型的总体识别率均达到90%,最高组为92.52%,表明PVnet模型对生猪音频能稳定有效识别。进一步,用391个样本集外的猪声样本对PVnet(3)模型进行算法应用测试,PVnet(3)总体识别率为90.70%,结合混淆矩阵可知PVnet模型对5种生猪音频均有较好的识别效果,且具有泛化性能。
