基于特征融合和注意力的图像分类研究
2022-05-20彭曦晨
彭曦晨,葛 斌,邰 悦
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232000)
针对上述问题,本文提出了一种基于特征融合和注意力的图像分类方法,该方法的主要特征,一是采用全局平均池化代替全连接层来缓解过拟合现象;二是考虑卷积通道之间的权重关系,通过挤压和激励模块整合特征图的特征信息,提高模型的分类效率;三是结合特征融合的方法,形成独立模块附加在网络上,最终实现整体网络性能的提升。
1 相关工作
Huang等[3]发现连接网络中的输入和输出层,可以构建层数深、精度高的卷积神经网络结构,提出了网络更窄、参数更少的密集卷积网络,加强了特征传播和特征重用。Farahnakian等[4]提出一个早期融合特征的网络框架应用于海洋环境图像识别,通过融合特征的方法使网络能够更高效地检测复杂环境中的目标。He等[5]提出了残差网络(Residual Network,ResNet),利用残差分支连接每一层的输入和输出,构造出超过1000层的网络结构,一定程度上解决了梯度消失和梯度爆炸问题。Lin等[6]基于多尺度特征构建了特征金字塔结构,每一个特征阶段定义为一个金字塔等级,使用上采样方法集合多尺度特征,加强骨干网络的特征表达能力。Wang等[7]基于注意力的加权方法引入集成学习中,提出了一个更高效的集成学习分类器,将基分类器中的知识转移到最终分类器,使性能较高的分类器获得了更多的关注,证明了注意力机制的有效性。Sun等[8]发现干扰像素会削弱光谱空间特征的判别能力,提出了一种光谱空间注意力网络,将注意力模块嵌入光谱分类模型,抑制干扰像素的影响。上述方法和模型通过特征融合和注意力机制得到了很好的实验结果,证明了方法的可行性,为研究提供了思路和基础。
2 网络结构设计
本文提出挤压和激励-双峰网络(Squeeze and Excitation-Bimodal Peak Net)模块,简称为SE-BIPNet模块,此独立模块可以附着在任意网络上。在分类层中,使用全局平均池化[9](Global Average Pooling,GAP)代替全连接层,有效地缓解过拟合现象。在不改变原网络的前提下,提取出卷积过程中不同尺寸的特征图,并将其进行特征融合操作,改变了传统卷积神经网络的输出方向。结合通道注意力模块,使模型选择性地强调有用的特征,抑制不太有用的特征[10]。提高原网络的分类效率。
2.1 全局平均池化
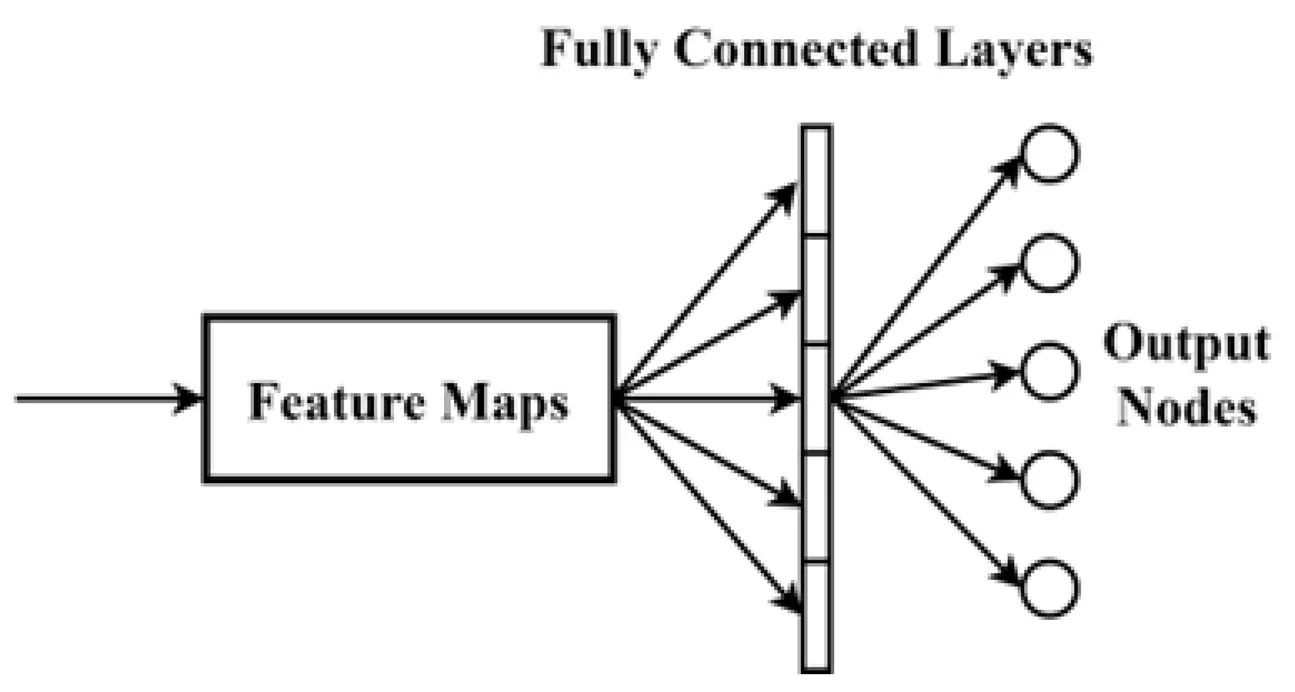
传统的卷积神经网络的分类层,如图1(a)通常使用全连接层(Fully Connected layer,FC),将最后一层C×H×W的特征图展平并向量化,再使用SoftMax激活函数分类,如式(1)所示,
(1)
其中,y1为全连接层的输出,x为输入,n为神经元个数,ω为神经元权重。
(a)传统全连接层
(b)全局平均池化方法图1 全连接层与全局平均池化方法对比
将特征提取层获得的特征信息分类,得到分类结果,但是在模型训练的过程中,可能会出现过拟合的现象,导致模型损失函数收敛值较高,准确率较低。由于全连接层连接复杂,即便引入丢弃(dropout)方法,按设定的概率切断与某些神经元的连接,破坏了各个神经元之间的相关性,明显的增加了训练时间,需要更多的迭代次数来达到预期的性能。
水利体制机制改革稳步推进。组织起草《水利部关于深化水利改革的指导意见》。出台《关于深化小型水利工程管理体制改革的指导意见》。继续深化国有水管单位体制改革。深入开展行政审批制度改革,积极推进简政放权。加快完善水利投入稳定增长机制。财政专项资金管理逐步规范,预算管理机制更加健全。水价改革全面深化。基层服务体系建设成果丰硕。水利扶贫、水库移民、水利援疆和援藏工作稳步推进。
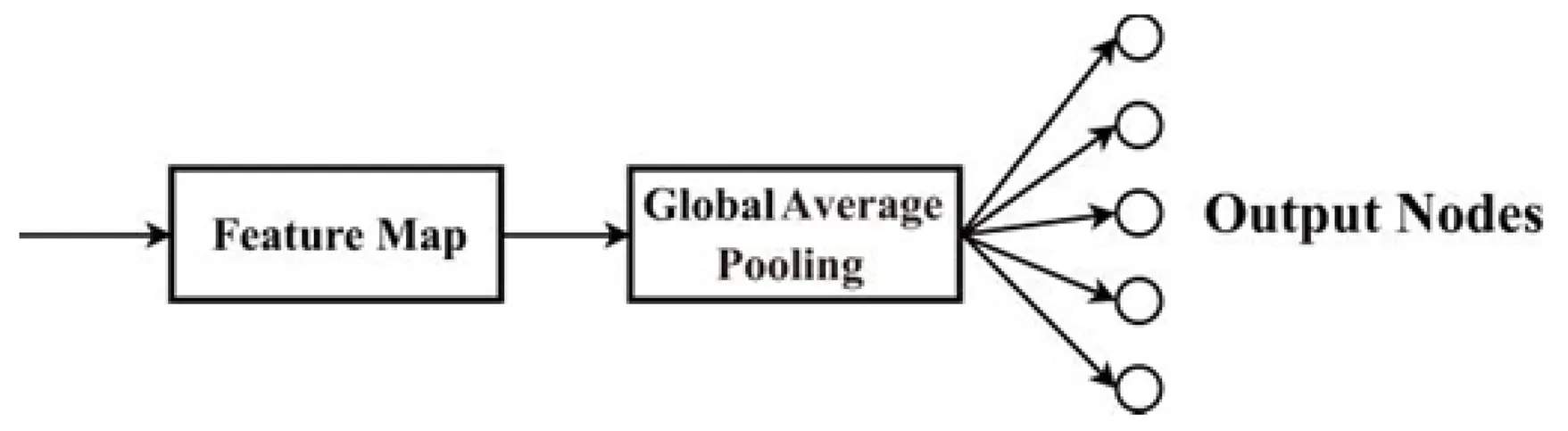
GAP方法本质上是对整个网络结构做正则化防止过拟合,如图1(b)对上一层传入的每个特征图的所有像素值求平均值,得到代表每个特征图的数值,直接连接输出层通过SoftMax函数按概率大小分类。如式(2),
(2)
其中,y2为GAP方法的输出,f为特征图,n为特征图个数。
GAP方法可以输入任意大小的图像,无需错综复杂的连接,不会破坏神经元之间的相关性。假设存在训练数据集不足的情况,降低了过拟合的风险,比使用dropout方法的全连接层更加有效。
2.2 挤压和激励模块
挤压和激励模块(Squeeze and Excitation,SE)是在原网络在特征提取的过程中,考虑卷积通道之间的权重关系,强调特征提取中有利的特征信息,抑制通道之间无用的特征,提高模型的分类效率。
如图2所示,SE模块的组成分别为:全局平均池化层、使用ReLU激活函数的全连接层和Sigmoid激活函数的全连接层。首先使用全局平均池化层将特征图转化为通道的向量,即为挤压操作,如式(3)所示,
(3)

图2 SE模块模型
其中,H和W分别为特征图的高度和宽度,k表示通道的第k个元素,S和δ分别为输入和输出。输入尺寸为C×H×W,输出尺寸为C×1×1。
再使用如式(4)的ReLU激活函数的全连接层和式(5)的Sigmoid激活函数的全连接层,即为激励操作,式(6)所示,
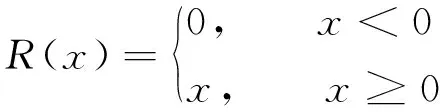
(4)
(5)
E=σ(M2R(M1S))
(6)
其中,E为激励操作的输出,S为上一层的挤压操作操作的输出,M1和M2为两个不同的权重矩阵。
最后进入Scale模块,SE模块的输出是将输入通道和其它各通道的权重进行乘法运算,得到尺寸从C×1×1又变为C×H×W。虽然输入和输出特征图的尺寸大小没有改变,但是通过自适应的方法,重新分配了各个通道之间的相关性权重,加强网络对通道相关性的表达能力,提高网络中有效信息的权重。SE模块中还存在一个超参数ratio,通过大量的实验证明,ratio为16时模型的性能最佳。
2.3 SE-BIPNet模块
大部分卷积神经网络模型在特征提取过程中,浅层网络的特征信息表达能力弱且特征模糊,而深层网络的特征图分辨率低但语义性强。[11]根据不同网络模型设置分支数量不同,本文在原网络的各层中设置5个分支输出,输出不同尺寸的特征图,如图3所示,改变前一层特征图的尺寸适应后一层特征图,两层输出进行相加运算,循环此操作,最终输出包含了所有特征图的特征信息,增强网络中的特征传播能力。
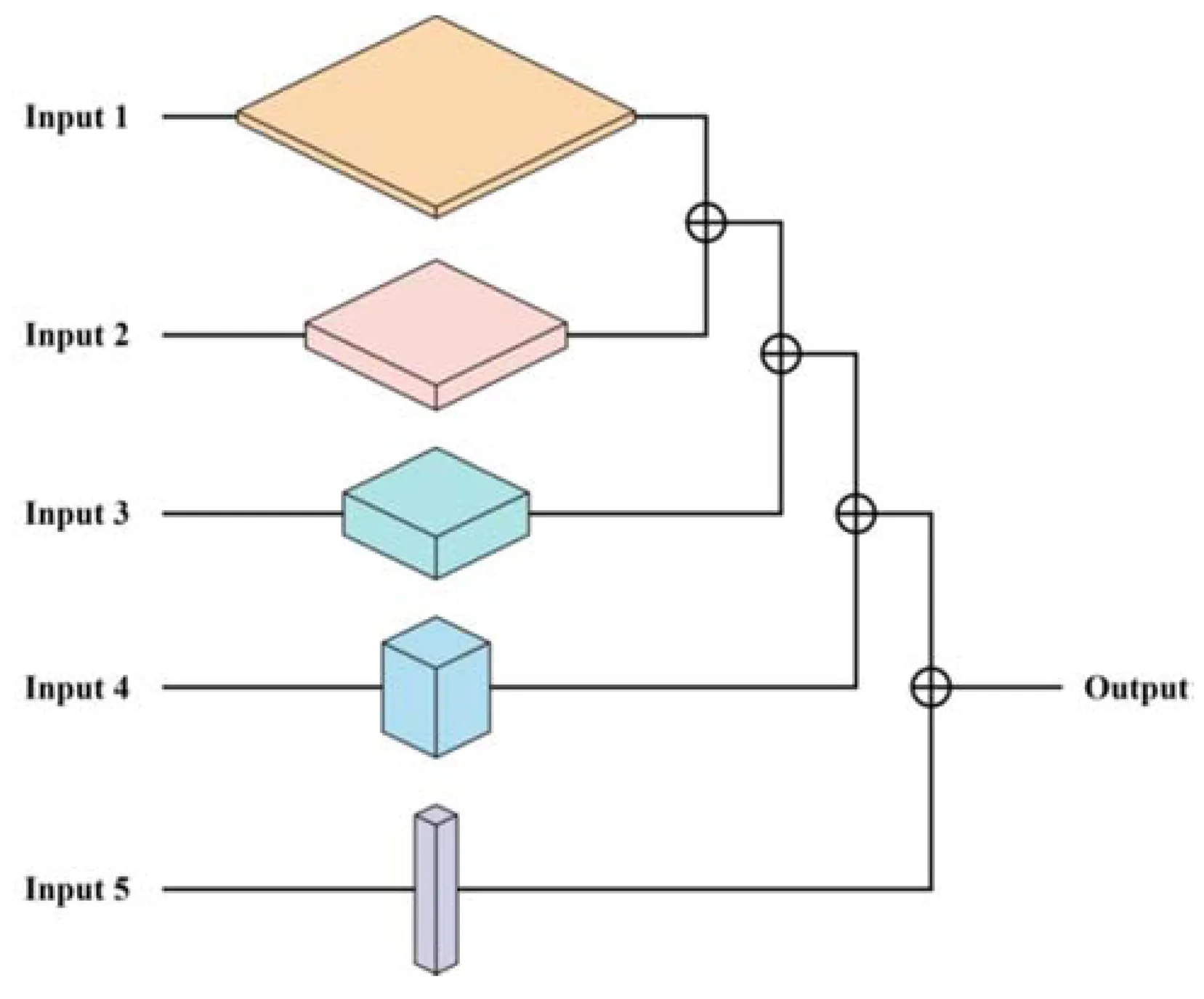
图3 SE-BIPNet立体模型图
本文整体网络结构如图4所示,为了避免附加模型的参数量过大,使用1×1大小的卷积核[12]改变各输入的通道大小。提出DownSize模块,因为深层网络的语义表征能力强,包含的特征信息多,所以使用3×3的卷积核,为了改变特征图的大小,将步距设置为2 ,填充(padding)为1,使用此卷积核不仅能够改变特征图尺寸,还能再次进行特征提取操作。不同层特征图有着不同的分辨率和语义表达能力,浅层网络语义表征能力弱,所以浅层网络中的DownSize模块不同于深层网络的DownSize模块,这里使用步距为2,大小为2的池化核,不进行卷积操作。
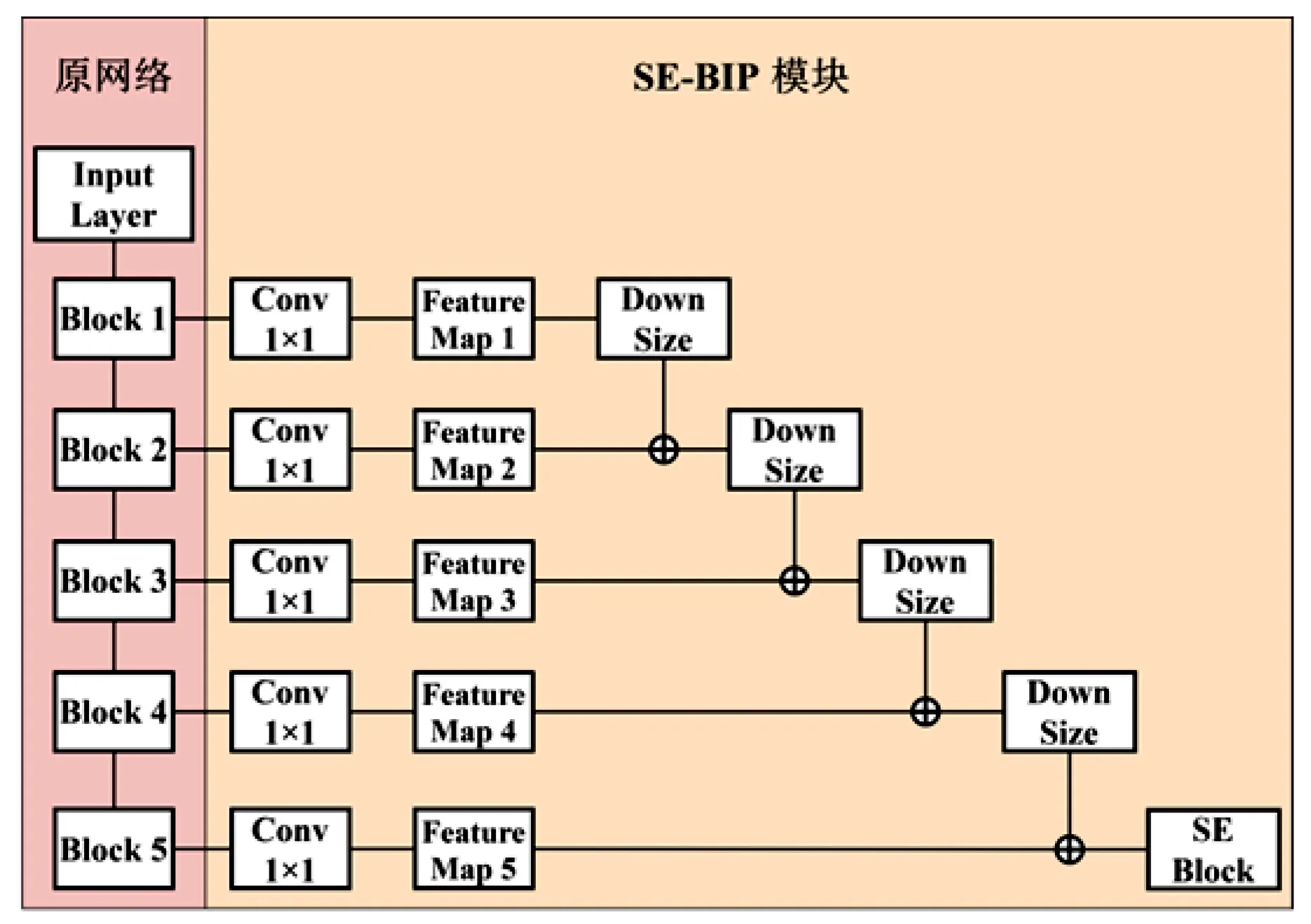
图4 SE-BIPNet平面模型
3 实验结果和分析
本文所使用的硬件配置为inter i5-10400F CPU,NVIDA Geforce3060 Ti显卡和16G内存,在Windows 10 64位系统下,实验在Pytorch框架下使用Python3.6.0运行。
3.1 实验数据集
Kaggle花子分类数据集共3670张分辨率不同的花子类图片,由玫瑰花、雏菊、向日葵、蒲公英和郁金香五种花子类组成,数据集中存在小目标图像和灰度图像,增加了分类难度,训练集和测试集分别占90%和10%。
CIFAR-10数据集共有汽车、飞机、鸟、猫、鹿、狗、蛙、船、卡车和马十个类别,图片的尺寸为32×32,数据集共有50 000张训练集图片和10 000张测试集图片。
3.2 评价指标
选取准确率(Accuracy,Acc)和交叉熵损失函数[13]的收敛速度作为评价指标,其计算公式(7)(8)如下,
(7)
式中TP表示正类被预测为正类的数目,即为真正类(True Positive);TN表示负类被预测为负类的数目,即为真负类(True Negative);FP表示负类被预测为正类的数目,即为假正类(False Positive);FN表示正类被预测为负类的数目,即为假负类(False Negative)。

(8)

3.3 实验参数设置
对于CIFAR—10数据集,由于数据集图片数量大,将批量大小(Batch Size)设置为128;学习率为0.1;交叉熵函数作为损失函数;一个周期(Epoch)为一次正向和反向传播,Epoch数量设置为200;优化器选择随机梯度下降。
对于Kaggle花子分类数据集,批量大小设置为16;学习率为0.000 1;损失函数为交叉熵函数;Epoch为 200;优化器选择自适应矩估计。
3.4 Kaggle花子分类数据集对比实验
验证SE-BIPNet附着在模型上性能提升的效果,选择常用的图像分类模型VGG16[14]在相同的实验设置环境下进行对比。为了避免参数量过大影响测试准确率,需要保证输出通道个数的合理性,VGG16模型中设置输出五个不同尺寸大小的特征图,将这五个输出通道作为SE-BIPNet的输入1、输入2、输入3、输入4和输入5。由图5可知,VGG16在迭代200次时准确率收敛值为86.26%,SE-BIPNet-VGG16准确率向90.38%收敛,从第1次迭代到第200次迭代,本文所提模型的性能一直高于原模型,最终准确率提升了4.12%。在训练损失的表现上,损失函数的收敛速度大幅快于原网络,损失函数在收敛过程中也比原网络更加稳定,没有大幅度震荡现象。改变原网络的输出方向,融合了不同尺寸大小的特征图,结合注意力机制,使模型有选择性的提取特征信息,验证了SE-BIPNet附加于网络上的有效性。
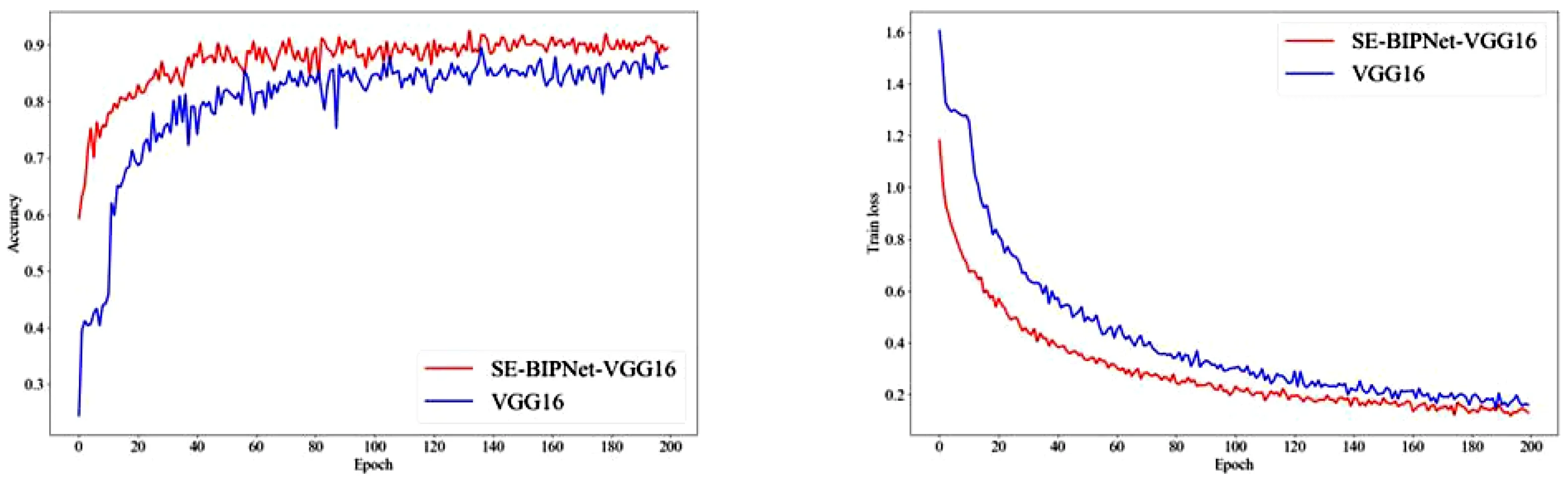
(a)VGG16和SE-BIPNet-VGG16准确率对比 (b)VGG16和SE-BIPNet-VGG16损失值对比图5 VGG16和SE-BIPNet-VGG16测试准确率和训练损失差异对比
为了验证SE-BIPNet在不同深度模型的提升效果,再选取VGG19模型作为原网络,VGG19相比VGG16增加了3层卷积层,同时增大了模型的参数量。实验结果如图6所示,SE-BIPNet-VGG19测试准确率为90.11%,原网络的测试准确率为84.06%,准确率提升了6.05%,由于VGG19在深层网络增加了3层卷积层,深层网络能提取到更多的特征图语义信息,所以特征融合的表现效果显著。损失函数的收敛速度比原网络快,在训练过程中损失值低代表训练效率有所提高。

(a)VGG19和SE-BIPNet-VGG19准确率对比 (b)VGG19和SE-BIPNet-VGG19损失值对比图6 VGG19和SE-BIPNet-VGG19测试准确率和训练损失差异对比
VGG16和VGG19引入SE-BIPNet模块性能获得大幅提升,进一步评估所提模块的性能,尝试将此模块附着在不同的网络模型上,验证对不同模型的泛化性能。AlexNet[15]使用大小为11×11、5×5和3×3的卷积核,在原网络上设置4个输出分支与SE-BIPNet模块连接。为适应Kaggle花子分类数据集,在不改变原网络的特征提取层的前提下,改变了原网络的分类层参数。实验结果如图7所示,AlexNet的准确率为82.41%,SE-BIPNet-AlexNet准确率为85.71%,准确率提升了3.3%。

(a)AlexNet和SE-BIPNet-AlexNet准确率对比 (b)AlexNet和SE-BIPNet-AlexNet损失值对比图7 AlexNet和SE-BIPNet-AlexNet测试准确率和训练损失差异对比
3.5 CIFAR-10数据集对比实验
使用CIFAR-10数据集验证SE-BIPNet在不同数据集的有效性,表1给出了上述模型在CIFAR-10数据集上的准确率对比结果。
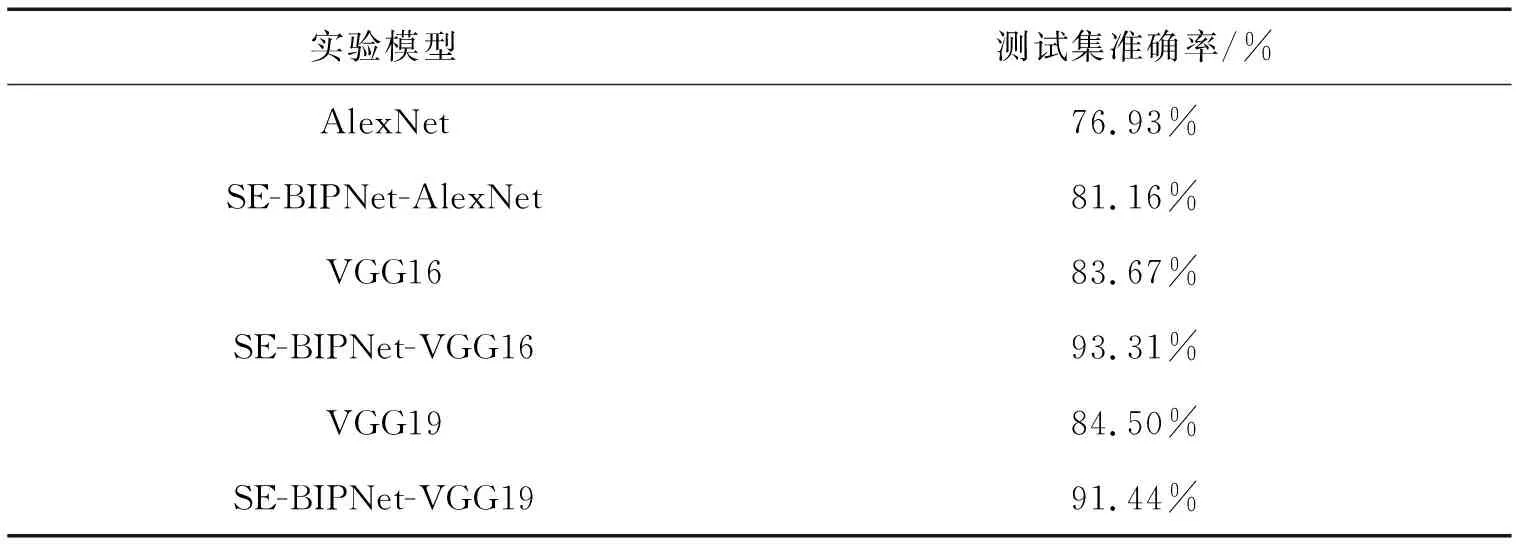
表1 CIFAR-10数据集在不同模型上的准确率对比
SE-BIPNet-AlexNet与原网络相比准确率提升了4.23%,SE-BIPNet-VGG16比原网络提升了9.64%,SE-BIPNet-VGG19比原网络提升了6.94%。VGG16相比于VGG19,仅仅少了3层卷积层,但VGG16在相同实验设置下训练过程中对CIFAR-10的分类准确率更高,因此加入SE-BIPNet后模型提升效果更显著。
3.6 消融实验
探究各个网络模块对原网络分类提升的效果,选取测试准确率为评价指标,选取VGG19为原网络、不引入SE模块的BIPNet-VGG19和整体网络在Kaggle花子分类数据集上进行比对,实验结果如表2所示。
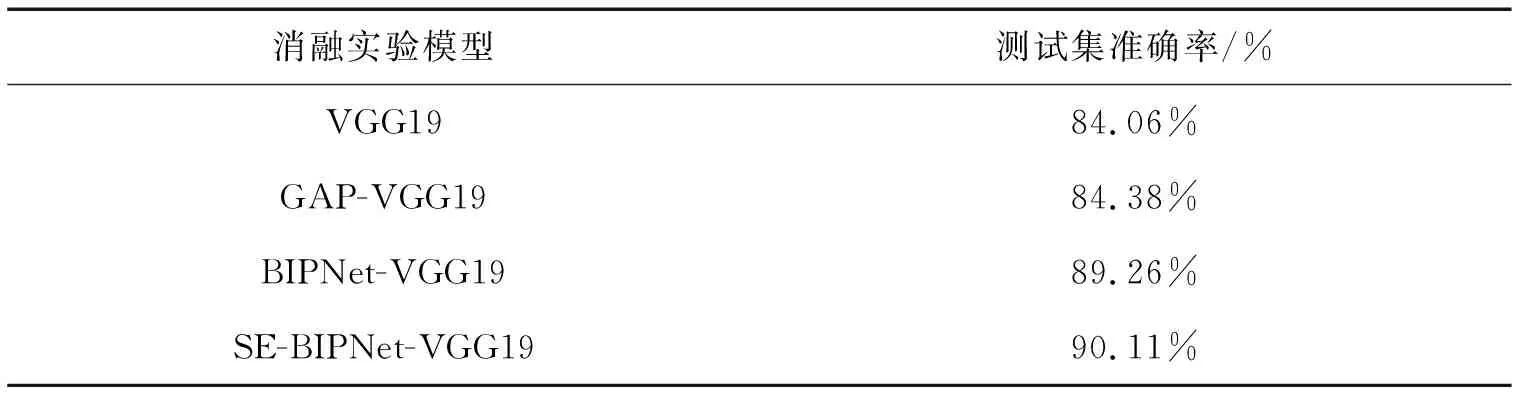
表2 SE-BIPNet-VGG19的消融实验结果
结果显示引入GAP模块比原网络的分类准确率提高了0.32%,使用BIPNet模块比仅使用GAP模块准确率提高了4.88%,相较于原网络提升了5.2%,证明了引入不同特征图融合特征信息的有效性,添加注意力模块比没有此模块的BIPNet-VGG19提高了0.85%,整体网络比原VGG19网络准确率提高了6.05%。
4 结束语
本文基于不同尺寸特征图的特征融合方法,结合全局平均池化代替全连接层,引入通道注意力机制,构建了独立的SE-BIPNet模块。选取常用的图像分类网络如VGG16、VGG19和AlexNet,将本文所提出的独立模块附加于这些网络,在Kaggle花子分类数据集和CIFAR-10数据集上证明其有效性。实验证明分类测试准确率有显著的提升,训练过程中损失函数的收敛速度更快。在之后的工作中,将继续研究特征融合和特征选择,有效提高网络的性能。
