基于Transformer的伪装物体检测模型
2022-05-20刘政怡张志立檀亚诚
唐 彬 ,刘政怡, 张志立, 檀亚诚
(1.合肥学院 人工智能与大数据学院,合肥 230601;2.安徽大学.a多模态认知计算安徽省重点实验室;b计算机科学与技术学院,合肥 230601)
伪装是自然界广泛存在的一种生物现象。生物学家发现,自然界的生物经常利用自己的结构和生理特征来躲避捕食者。例如,变色龙可以随着环境的变化而改变身体的颜色;螃蟹通常会找到与其外表相似的栖息地隐藏起来。这种通过改变自身颜色、形态而完美地融入周围环境的伪装能力通过欺骗观察者的视觉感知系统而成为保护动物的武器。如图 1所示的伪装物体几乎很难被人类肉眼识别。

图 1 伪装示例图(第一行是图像,第二行是伪装物体真值)
对伪装的最早研究可以追溯到上个世纪,Thayer 等人[1]在1918年系统地研究了伪装现象。一百多年过去了,生物学家们仍对研究这一重要的自然现象保持着热情。Cuthill等人[2]提出有效的伪装包括两种机制:背景模式匹配,即自身颜色与周围环境相似;混隐色,即与边缘环境相似的颜色,使带有迷彩标记的物体和背景之间的边界不明显。Pike等人[3]结合了几个显著的视觉来量化伪装,以模拟捕食者的视觉机制。Pan等人[4]提出一种基于三维凸包的伪装物体检测框架。Zhang等人[5]提出一种检测运动伪装物体的贝叶斯方法。除了这些传统方法之外,目前已有许多基于深度学习的伪装物体检测算法。Le等人[6]设计了一个通用的端到端网络用于伪装物体分割,将分类信息集成到像素级分割中;Yan等人[7]提出了一种以翻转图像为输入的对抗分割流,以增强主分割流对伪装物体检测的识别能力;Fan等人[8]提出了一个伪装物体检测数据集COD10K和一个伪装物体检测框架,将伪装物体检测研究提升到一个新的水平;之后,Fan等人[9]、Mei等人[10]和Xu等人[11]都基于模拟人类视觉机制的两阶段检测过程提出了伪装物体检测框架;Ren等人[12]、Zhang等人[13]、Li等人[14]和Liu等人[15]通过放大细微纹理差异、估计深度信息、联合训练显著目标检测任务和度量置信度来识别伪装物体;Sun等人[16]提出了一种上下文感知交叉融合网络用于伪装物体检测;Dong等人[17]提出一个集成了大感受野和有效的特征融合的统一框架;Lv等人[18]提出了一个基于排序的伪装物体检测网络,可以同时对伪装对象进行定位、分割和排序;Zhai等人[19]设计了一种交互的图学习模型用于伪装物体检测,将传统的学习思想从规则网格推广到图域;Yang等人[20]设计了概率表征模型,结合注意力机制,推断不确定区域,有效实现确定和不确定区域的共同推演;Ji等人[21]引入边缘检测加强伪装物体检测效果。这些仿生模型背后的共同想法是,探索和整合额外的线索到表征学习中,大大优于传统的方法。
近年来,Transformer在自然语言处理和计算机视觉图像领域大放异彩,刷新了许多研究任务的最高水平。相比于卷积神经网络(Convolutional Neural Network, CNN),基于Transformer的模型可以建模长程依赖,具有更好的全局特征。因此,本文借助Transformer实现伪装物体检测,发挥Transformer抽取特征的优势,实现伪装物体检测精度的提升。
1 提出的方法
1.1 概述
基于Transformer的伪装物体检测模型的总体框架如图 2所示,它是由一个Transformer主干编码器、一个特征增强模块、一个解码模块组成。其中特征增强模块包括高层的上下文探索模块和低层的细节注意力提升模块,解码模块也相应地包括高层解码块和低层解码块。
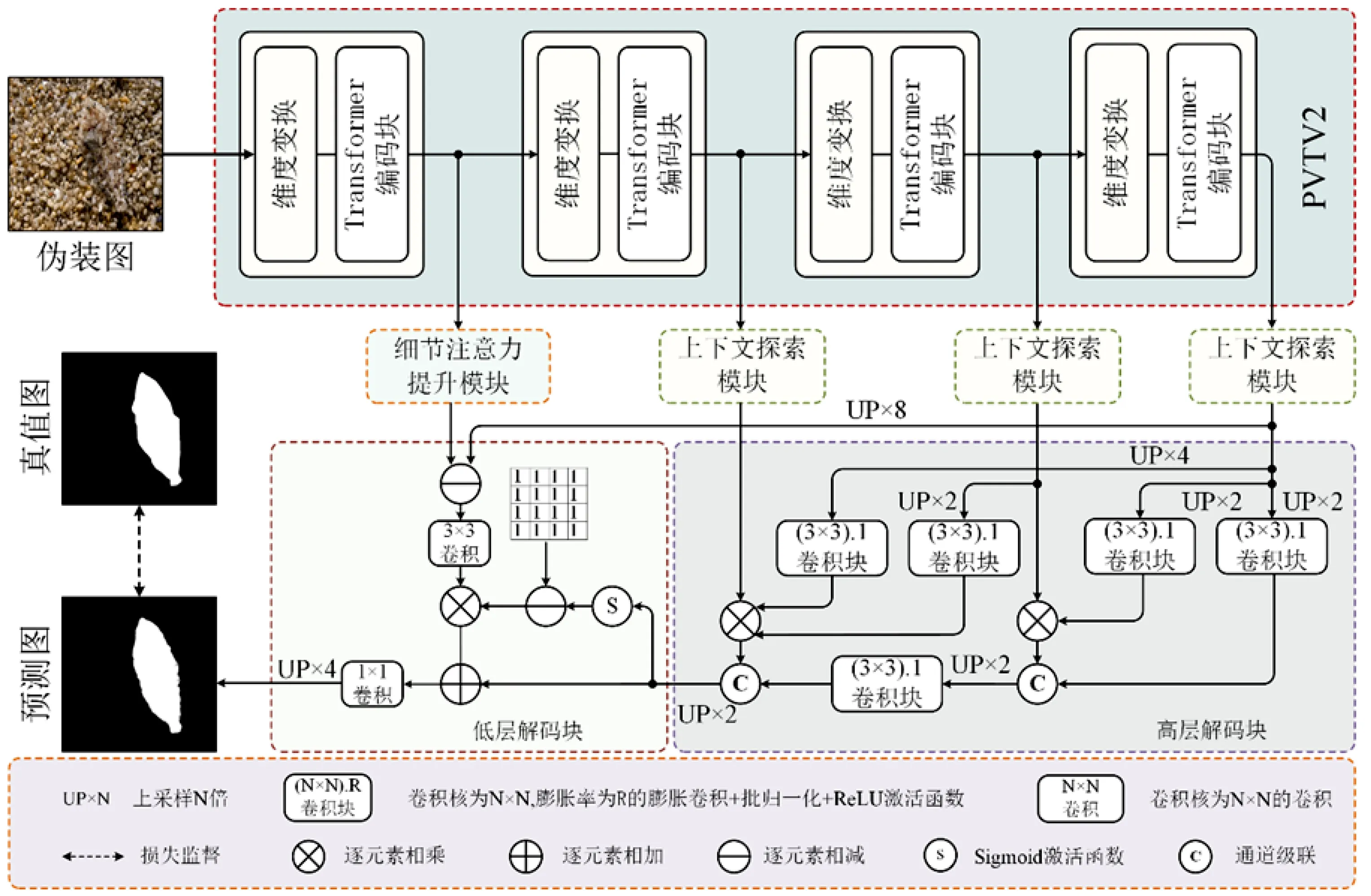
图 2 伪装物体检测模型
1.2 Transformer主干编码器
近年来提出的一些Transformer主干展示了强大的特征表示能力和对输入干扰的鲁棒性,特别是相比于ResNet等CNN主干,Transformer主干提取的特征表征能力更强。PVT[22]就是其中一种具有影响力的主干编码器。它在原有ViT[23]的基础上进行了一些改进,采用渐进式收缩策略产生类似CNN的多尺度特征图,利用空间裁剪注意力层降低计算代价。升级版本PVTv2[24]利用重叠切块,保证局部连续性;引入零填充位置编码,以深度感知卷积适应不同分辨率输入;改进空间裁剪注意力层为线性版本,进一步降低多头自注意力的计算成本。这些改进都保证了主干编码器抽取的特征兼具全局和局部特性,表达能力更强。
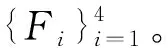
具体做法如下:PVTv2首先将输入的图像分割成重叠的块,然后将这些块送入多阶段Transformer编码块,其中的多头自注意力和前馈网络对块之间的关系进行建模。随着网络深度的增加,块的数量逐渐减少以产生层次的特征表示。考虑到计算代价和效率,采用了B2版本。[24]
1.3 特征增强模块
主干网络提取的层次特征中的高层特征包含丰富语义信息,低层特征保留了更多的细节信息。而伪装物体最大的特点就是与背景极其相似,因此在高层特征定位伪装物体时,应尝试多种尺度,提高感受野的丰富程度,确保产生正确的位置信息;在低层特征补充细节时,应尽量过滤低层特征的噪声。因此,在特征增强模块,采用分而治之的策略。对于高三层,设计了上下文探索模块,尝试尽可能多的感受野,以确保准确定位伪装物体;对于低一层,设计了细节注意力提升模块,在通道和空间上赋予重要的特征以更多的权重,以有效过滤噪声。下面分别介绍上下文探索模块和细节注意力提升模块。
1.3.1 上下文探索模块
上下文探索模块如图 3所示,其主要作用就是丰富高层语义信息的感受野,确保准确定位伪装物体。
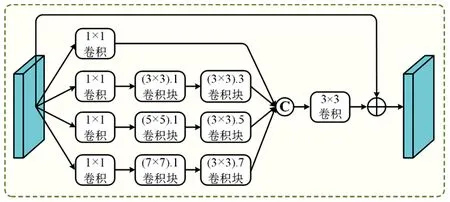
图 3 上下文探索模块
它由四个分支组成,每个分支上,首先利用1×1的卷积将特征的通道数降为64,然后在第k(k=2,3,4)个分支上分别运用膨胀率为1、卷积核为2k-1的膨胀卷积,再次运用膨胀率为2k-1、卷积核为3×3膨胀卷积。注意,每个膨胀卷积后跟批归一化和ReLU激活函数。接着,四个分支被级联在一起,再利用一个3×3的卷积将通道数降为64。最后,级联的特征与原始特征做一个残差连接,以保持更多的原始信息。具体公式如下:
(1)
1.3.2 细节注意力提升模块
细节注意力提升模块如图 4所示,其主要作用就是消除低层特征中的噪声,确保细节无干扰。它由通道注意力和空间注意力组成,通道注意力利用最大池化和平均池化压缩空间位置获得通道上的全局信息,再经过一个共享的两层感知机,分享各自的优势,形成两个维度上的通道注意力,最后二者相加,经过一个Sigmoid激活函数,生成通道注意力图Mc。空间注意力图的产生,则是对通道做最大池化和平均池化,然后通过卷积和Sigmoid激活函数,产生空间注意力图Ms。形成的通道注意力图和空间注意力图分别连续地乘到原始特征上,加强其在通道和空间方面的权重,突出有意义的通道和空间位置,弱化其余部分,以此消除噪声。具体公式如下:
(2)
(3)
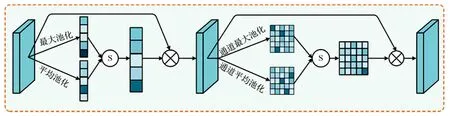
图 4 细节注意力提升模块
1.4 解码模块
伪装物体检测属于像素级别的分割任务,所以需要解码器进行解码,恢复图像分辨率。鉴于高层特征与低层特征各自的优势,在解码阶段,依然采取分而治之的策略。高层解码块利用乘法操作取交集,然后从最高层开始逐步级联、上采样、卷积,最后形成最优的高层特征。低层解码块则对高层的解码特征在边缘细节上加以优化,具体利用高层和低层的差异产生伪装物体边缘信息,再与高层特征产生的伪装背景图求交集,增强边缘线索,最后通过残差的方式加到高层解码特征上。下面分别介绍这两部分解码过程的具体细节。
1.4.1 高层解码块
(4)
其中,Up为上采样操作。
接着,递进地级联上采样进行高层解码,具体表示为:
(5)
1.4.2 低层解码块
低层特征虽然包含一些噪声,但是对于空间方面的细节信息描述得比较全面。因此,低层特征可以用来增强高层解码后的边缘信息。
首先,利用第一层特征与第四层特征的差异得到边缘信息
(6)
(7)
最后,将增强的边缘信息补充到高层解码特征上,这一步利用残差连接实现
(8)
解码完成后,通过1×1卷积和四倍上采样操作,产生伪装结果
(9)
2 实 验
2.1 实验设置
数据集包括CAMO[6]、CHAMELEON[8]、COD10K[8,9]和NC4K[18]。CAMO含有8个类别1,250张伪装图像,其中1,000张用于训练,250张用于测试。CHAMELEON是76张从互联网下载的图像,仅用于测试。COD10K包含从多个摄影网站下载的5,066张伪装图像,涵盖5个超类、69个子类,其中3,040张用于训练,2,026张用于测试。NC4K提供了4,121张图像,组成了目前最大的测试集。本文采用与SINetV2[9]一样的训练集,共计4,040张图像,是由CAMO 和COD10K的训练集组成,剩余图像用于测试。在训练和测试阶段,输入的图像被调整为352×352大小。评价指标包括PR曲线、S-measure、F-measure、E-measure和MAE。具体详见[9]。对比算法包括SINet[8]、ERRNet[21]、C2F-Net[16]、Rank-Net[18]、MGL[19]、JCOD[14]、PFNet[10]、SINet-V2[9]、UGTR[20],它们出自近两年的一些重要会议和期刊,如CVPR、ICCV、IJCAI、PAMI、PR。损失函数采用的是像素位置感知损失。[25]
2.2 结果和分析
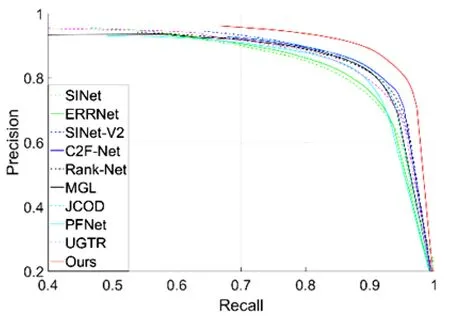
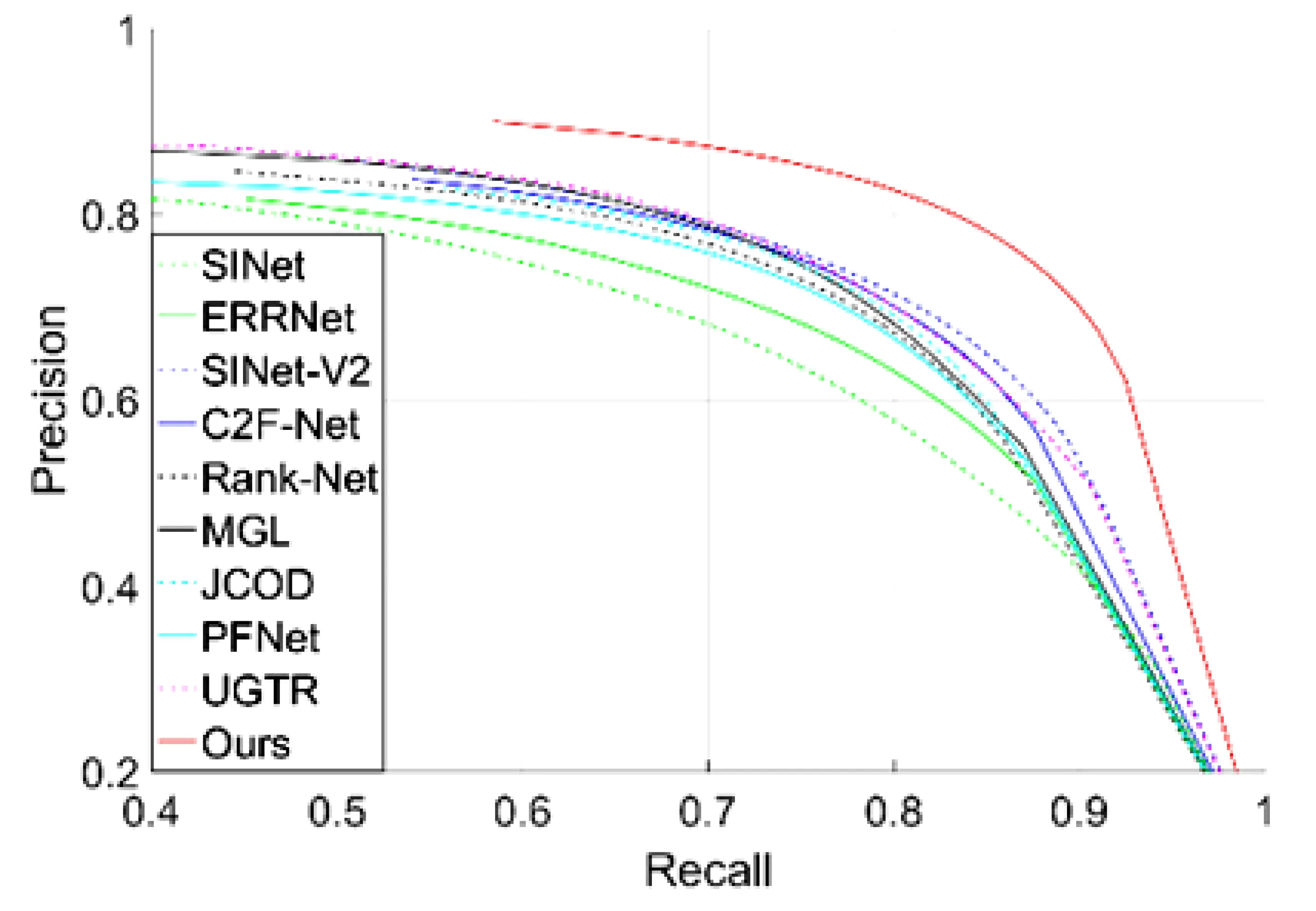
图 5显示了四个数据集上的PR曲线的对比。表1给出了四个数据集上评价指标的定量比较结果。PR曲线对比图清楚地表明本文设计的模型的曲线非常高,这意味着本文方法明显优于其他方法。此外,评价指标对比表也一致性地表明提出的模型的所有指标在四个数据集上的提升都较为明显,从而证明本文所提模型的有效性。这主要得益于Transformer主干的优势。
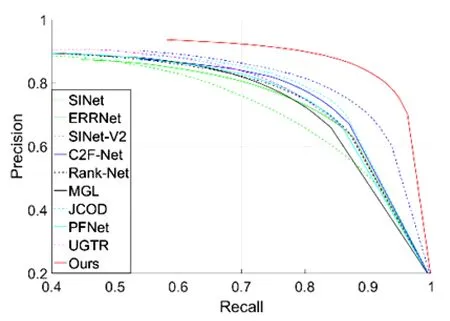
(a) CAMO
(b) CHAMELEON
(c) COD10K
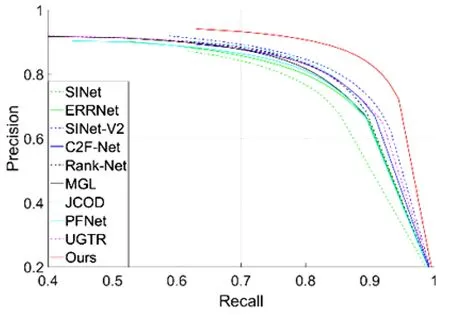
(d) NC4K图5 不同模型在四个数据集上的P-R曲线对比
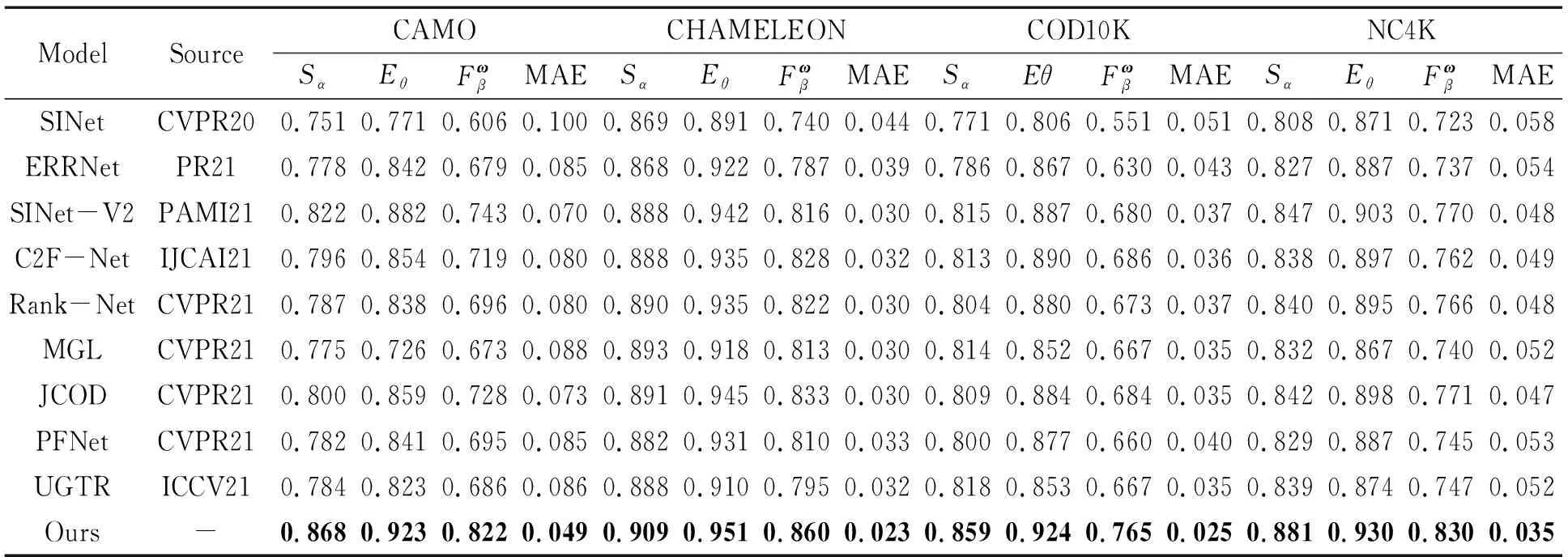
表1 不同模型在四个数据集上的S-measure、加权 F-measure、均值 E-measure、MAE指标对比
2.3 消融实验
(1)验证主干编码器的有效性。本文模型的主干编码器采用的是PVTv2。为了验证其有效性,采用ResNet50[26]作为主干编码器去代替PVTv2。从表2的对比结果可以看出,PVTv2的模型表现较ResNet50有大幅度提升。这也是本文模块在性能上全面超过目前已有的伪装物体检测模型的主要原因。

表2 主干编码器的有效性分析
(2)验证特征增强模块的有效性。特征增强模块包括高层的上下文探索模块(M1)和低层的细节注意力提升模块(M2)。表3展示了去掉这两个模块后的对比。从对比结果发现,模型的四项指标在CAMO、COD10K、NC4K数据集上都有小幅下降,从而验证了这两个模块的有效性。不过也发现CHAMELEON数据集上的结果存在一些偏差,这可能是因为这个数据集规模太小、仅有76张图像的原因。

表3 特征增强模块有效性分析
(3)验证解码的有效性。解码包含高层的递进解码(D1)和低层的边缘增强解码(D2)。表4展示了使用普通的逐层上采样、级联、卷积解码代替D1和D2的对比结果。从对比结果发现,模型的四项指标都有小幅下降,从而验证了这两个模块的有效性。其中CHAMELEON数据集依然存在一定的偏差,与其他三个数据集不一致,可能是该数据集数据较少引起的。
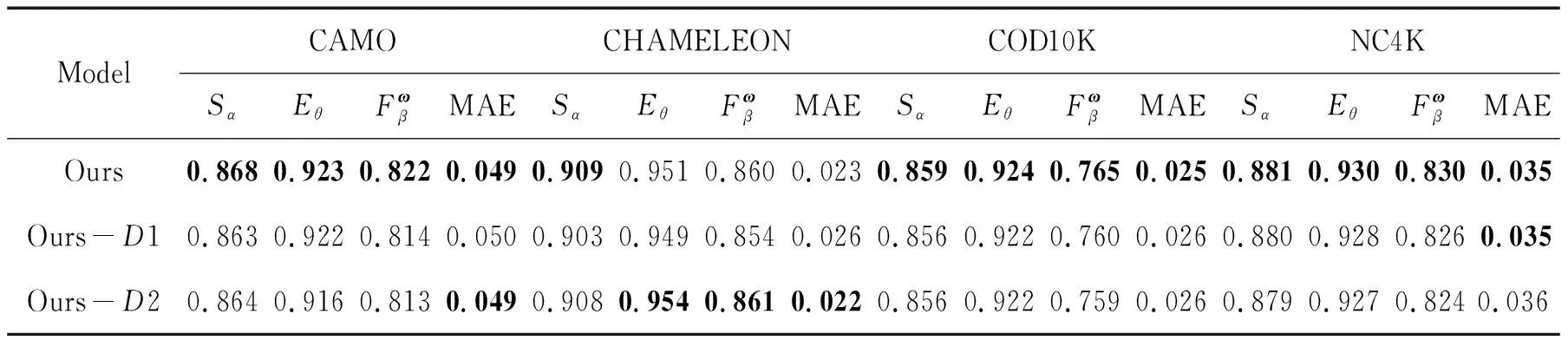
表4 解码的有效性分析
3 总 结
论文提出一种基于Transformer的伪装物体检测模型,该模型充分利用Transformer主干编码器的优势,提取更具判别性的特征。同时为了满足伪装物体检测的像素级预测任务,本文设计了特征增强模块,对于高层特征设计了上下文探索模块,提升高层特征感受野的丰富程度,对于低层特征设计了细节注意力提升模块,利用注意力机制过滤空间细节噪声。同时,本文也设计了分别针对高层和低层的解码器,高层部分实现了逐级相乘级联的解码过程,低层部分通过引入边缘增强优化物体边缘。整个模型在四个数据集上的整体表现优异,明显强于目前已有的基于卷积神经网络的伪装物体检测模型,从而验证了模型的整体有效性;同时,消融实验中,通过主干对比、各模块消除或替换也验证了模型中各个模块的有效性。
