改进人工蜂群算法的云任务调度
2022-04-20任金霞杜增正王兴康
任金霞,杜增正,王兴康
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
云计算是融合发展了分布式计算、网格计算、虚拟化、网络存储等计算机和网络技术的新兴计算模型。云系统中有大量且多样异构的资源、不同用户的任务和服务请求。对于这种情况,如何合理地分配云系统中的资源,执行用户的海量任务并满足其服务请求,同时实现负载均衡、最佳时间等目标,是云计算领域研究的难点与热点之一。
云计算环境下的任务调度[1-2]是一个非确定性多项式难(non-deterministic polynomial-hard,NP-Hard)组合优化问题。文献[3]结合贪心算法和数据节点分配,减少了云任务的总完成时间。文献[4]提出的Min-Max算法将大小任务同时进行调度,提高了负载均衡。但上述传统算法有一定局限性,不能很好地满足用户的多样需求。所以,近年国内外许多学者使用遗传算法[5-7]、蚁群算法[8-9]、鸟群算法[10-11]、蝗虫算法[12]和粒子群算法[13-14]等智能优化算法来解决云任务调度中的难题。文献[15]提出了一种基于改进遗传算法的云任务调度策略,对最小任务完成时间进行优化。文献[16]提出了一种改进蚁群算法的云任务调度策略,减少了任务完成时间,降低了虚拟机资源利用率,均衡了负载。文献[17] 提出的反向学习法和交叉操作的改进乌鸦搜索算法,降低了任务完成成本和完成时间。文献[18]提出了微生物遗传算法和改进粒子群算法融合的云计算任务调度算法,该算法减少了任务完成时间和成本,并且优化了虚拟机负载。
人工蜂群算法[19](artificial bee colony algorithm,ABC)仿照了蜂群觅食的行为,是一种易实现、参数少的群智能算法。本文提出了一种改进人工蜂群算法(improved artificial bee colony algorithm,IABC),将算法全局最优解与蜜蜂邻域搜索后的解进行概率交叉,增强算法对蜜源的开发能力且保持探索能力,加快算法收敛速度;观察蜂的灵敏度,通过配合蜜源的信息素来选择蜜源,增加种群多样性以避免算法陷入局部最优。
1 云任务调度问题的描述
目前,云计算使用谷歌公司于1995年推出的Map/Reduce编程方式,其原理是将需要执行的问题分为Map和Reduce两部分,用户传送的任务被Map程序拆分为若干小的子任务,通过云虚拟化技术,这些子任务按照一定的调度方式被调度给虚拟服务资源,Reduce程序整合计算结果,最后输出。在这个过程中,各个云任务、虚拟机是相互独立的,且云任务在虚拟资源中被并行执行,每个子任务只能被一台虚拟机执行。
为了方便分析,云计算任务调度可抽象为m个子任务在n个虚拟机上执行(m>n),调度目标为尽可能小的任务完成时间。T={t1,t2,t3,…,tm}为m个子任务集合,ti(i=1,2,3,…,m)为第i个子任务;VM={vm1,vm2,vm3,…,vmn}为n个虚拟机集合,vmj(j=1,2,3,…,n)为第j个虚拟机;则任务-虚拟机的分配关系用m×n矩阵TVM表示,如下式:
(1)
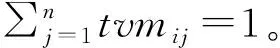
则任务在虚拟机上的执行时间用矩阵ETC表示,如下式:
(2)
其中:etcij为子任务ti在虚拟机vmj上的执行时间。
单个任务执行时间etcij可表示为:
(3)
其中:lengthi为子任务i的长度;mipsj为虚拟机j的处理性能。
将最小任务完成时间作为优化目标,任务完成时间是最后一个任务在虚拟机上的时间Makespan:
(4)
其中:sum(j)为分配到虚拟机vmj上总的任务数量。
2 改进人工蜂群算法的云任务调度
人工蜂群算法的蜜源表示任务调度中各种可能的调度方式,蜂群通过各种方法找寻蜜源即搜寻最优解的过程,根据适应度函数寻得的最优蜜源即最优解。在云任务调度中,最优蜜源即最佳任务分配方法。人工蜂群算法中有采蜜蜂、观察蜂和侦查蜂3种蜜蜂群体。采蜜蜂和蜜源有一定关系,蜜源是采蜜蜂此刻正在获取的食物,观察蜂通过采蜜蜂传递的蜜源信息选择蜜源进行开采,若采蜜蜂蜜源开采达到了开采限度但未更新位置,变为侦查蜂随机搜索新的蜜源位置。
2.1 初始蜜源的产生
初始阶段,蜂群没有先验知识,此时全部蜜源为侦查蜂,算法任意产生N个初始侦查蜂,同时N代表采蜜蜂数目,也是初始化蜜源的数量。第i个蜜源的位置是Xi=(xi1,xi2,xi3,…,xiD)(i=1,2,3,…,N),这里D为优化问题的维度。在云任务调度中,假设云任务个数为m,虚拟机个数为n,则蜜源的维度D等于云任务的个数m,蜜源维度的编号为云任务ID,蜜源某个维度的值为云计算虚拟机ID,代表一个云任务需映射到一个虚拟机,由此,蜜源(可行解)便可以表示云任务和虚拟机的映射关系。人工蜂群算法中随机产生初始可行解的公式是:
xij=xminj+rand(0,1)(xmaxj-xminj),
(5)
其中:xij为蜜源位置;j∈{1,2,3,…,D},为D维解向量的分量;xmaxj和xminj分别为维度的最大值和最小值;rand(0,1)为0到1之间的随机数。
2.2 搜索策略的改进
在人工蜂群算法中,观察蜂通过采蜜蜂分享的蜜源信息选择蜜源进行开采,蜜源的适应度值越大,被选择的概率越高,该蜜源进行邻域搜索的观察蜂数目就越多,会使算法具有较强的邻域搜索能力。采蜜蜂阶段和观察蜂阶段用式(6)进行邻域搜索,算法会在探索方面强而在开发方面弱。为了弥补开发方面的缺陷,文献[20]从粒子群算法中得到启发,提出全局最优人工蜂群算法来提高人工蜂群算法的开发能力,算法搜索阶段为式(7)。
vij=xij+α(xij-xkj),i≠k,
(6)
其中:xij为蜜源位置;vij为邻域内搜索得到新蜜源的位置;i,k∈{1,2,3,…,N},j∈{1,2,3,…,D};α为[-1,1]上的随机数。
(7)

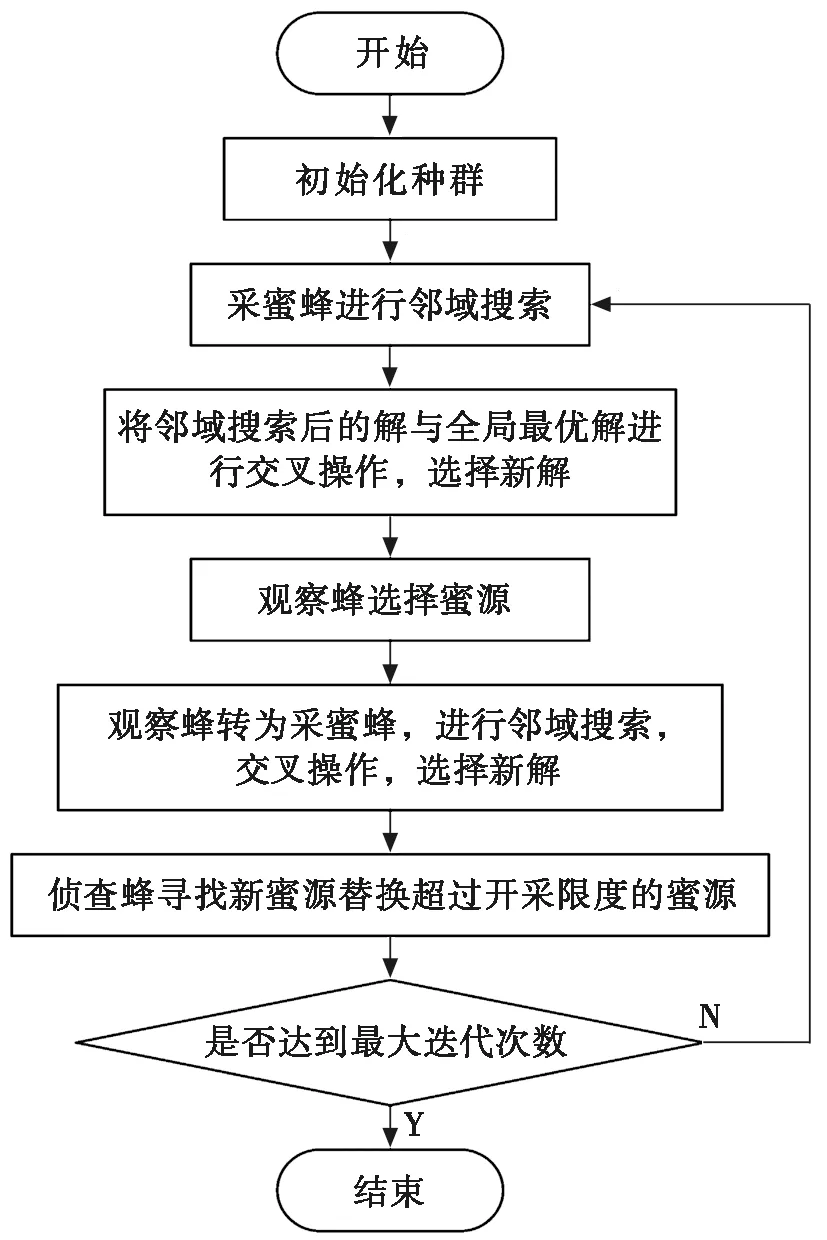
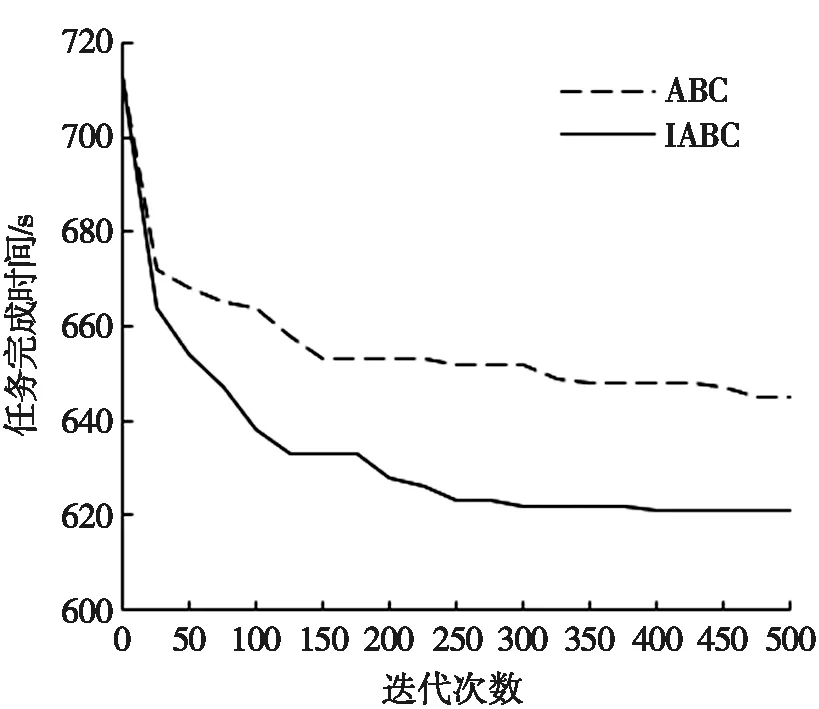
由于式(7)的第3项平衡算法探索与开发能力时会一定程度降低算法全局搜索能力,提出一种结合全局最优引导的蜂群算法和交叉操作的改进策略。将采蜜蜂邻域搜索后的解与全局最优解进行交叉操作,对蜜源位置的每一维度随机产生一个数rand,rand在0到1之间均匀分布,如果rand (8) 这种简单地与全局最优值交叉虽然会使算法开发能力提升很多,但不利于人工蜂群算法的探索,需要兼顾算法的搜索能力,防止算法早熟,建立如下公式: (9) 在人工蜂群算法中,按照轮盘赌策略,观察蜂会选择适应度更好的蜜源,较差蜜源将被放弃,这会降低种群的多样性且影响算法寻优能力,使算法早熟而陷入局部最优。自由搜索算法中有灵敏度的概念,通过与蜜源的信息素配合选择区域,可扩大选择蜜源的范围。搜索区域的信息素配合其灵敏度,使算法具有导向性。通过这种选择方式,任何适应度的蜜源都可能被选到,种群多样性更丰富,可防止算法陷入局部最优,且优秀的蜜源被选择的概率更大,保证了观察蜂选择蜜源的方向。 该方法为:计算N个蜜源的适应度值f(X)并找出最大和最小适应度值,计算第i个蜜源的信息素O(i),之后随机生成第i个观察蜂的灵敏度S(i)~U(0,1),若第i个观察蜂的灵敏度S(i)≤O(i),则进行邻域搜索,选择更优的蜜源;若S(i)≥O(i),则蜜源位置不变。蜜源信息素计算公式如下: (10) 其中:fi为第i个蜜源的适应度函数值;fmin为最小适应度值;fmax为最大适应度值;O(i)为第i个蜜源的信息素。 IABC算法流程如图1所示。 图1 IABC算法流程图 本文算法步骤如下: 在项目水资源论证阶段,对项目区实行严格的水资源论证审批制度,项目规模和布局以取水总量控制指标为指导,项目取水不得突破国家下达的地表水和地下水取水总量控制指标,对于已达到或超过控制指标的地区,不得新增取水,对于接近控制指标的地区,限制新增取水。地下水超采区内不得新增取用地下水,生态脆弱区限制地下水开采,防止出现生态环境问题。 步骤1 初始化参数,设置人工蜂群算法最大迭代次数,蜜源停留最大搜索次数和蜜蜂种群数,其中采蜜蜂和观察蜂各一半。 步骤2 初始化种群,按照式(5)随机产生初始解,将云任务随机分配给虚拟机。 步骤3 采蜜蜂对蜜源邻域搜索产生新位置,将算法全局最优解与蜜蜂邻域搜索后的解进行概率交叉得到新解,依据贪婪准则对原解和新解进行比较,选出任务调度中任务完成时间少的蜜源。 步骤4 观察蜂获取采蜜蜂摇摆舞传递的蜜源信息,计算蜜源信息素,根据灵敏度和蜜源的信息素的关系选择蜜源。 步骤5 观察蜂变成采蜜蜂邻域搜索当前的解,并将全局最优解与其概率交叉得到另一解,按贪婪策略选择新的解。 步骤6 若蜜源达到开采限度,采蜜蜂转化为侦察蜂,产生新的蜜源。 步骤7 若达到算法终止迭代次数,则返回当前所有蜂群找到的最优解和最少任务调度完成时间,算法结束。 CloudSim[21]是澳大利亚墨尔本大学网格实验室和Gridbus项目联合研发的云计算仿真平台,它主要模拟云环境,对不同服务模型的调度策略进行测试。为测试本文算法在云计算任务调度中的效果,在Intel i5处理器、12 GB内存、Windows 10操作系统下,使用CloudSim平台进行测试。对本文改进算法(IABC)、人工蜂群算法(ABC)和蚁群算法(ant colony optimization,ACO)在云计算任务调度的收敛速度、任务完成时间和负载不均衡度3个方面进行比较分析。 图2 算法收敛性对比 测试算法在收敛速度上的优劣。在200个云任务和10个虚拟机的调度规模下,通过算法迭代次数与任务完成时间的关系,对IABC和ABC的收敛速度进行比较分析,算法中采蜜蜂和观察蜂规模各为200。多次实验取平均值,实验结果如图2所示。 从图2中可以看出:IABC的收敛效果比ABC好,IABC和ABC在前100次迭代收敛速度都很快,且IABC比ABC的收敛速度更快。主要是因为交叉操作和全局机制引入到人工蜂群算法中,概率交叉全局最优解与采蜜蜂邻域搜索后的解,会增强算法对蜜源的开发能力和算法的方向性,算法在最优解附近的开发能力也得以提升,且加快了算法的收敛速度。IABC在迭代250次后逐渐趋于平稳,且任务完成时间比ABC少。 测试算法在云任务完成时间上的优劣。设置虚拟机数量为10,云任务数量分别为40、80、120、160和200的情况下,比较IABC、ABC和ACO这3种算法在云任务调度中的任务完成时间并进行分析,实验结果如图3所示。 从图3中可以看出:IABC比另外两种算法所需的任务完成时间更短,优化效果更好。随着云任务数量的增加,任务完成时间也在增加。当任务数为40时,IABC的任务完成时间比ABC、ACO分别少8 s和20 s,任务数逐渐增多,各算法任务完成时间差增大,当任务数到200时,IABC的任务完成时间比ABC、ACO分别少24 s和35 s,减少了3.7%和5.3%。这是因为IABC算法中全局最优解与蜜蜂邻域搜索后的解进行概率交叉,增强了算法对蜜源的开发能力且保持探索能力,改进的选择策略可以增强种群的多样性,避免算法过早早熟而陷入局部最优。IABC在局部搜索和全局搜索方面都发挥作用,在规模较大的云计算任务调度上效果更明显。 测试算法的负载不均衡度(degree of imbalance,DI),DI可以衡量虚拟机之间的不平衡程度。本文使用标准差来表示不均衡度DI,DI值越小,各虚拟机之间的负载量越接近,负载均衡度越好,调度策略就越合理。DI[22]表示为: (11) 其中:AL是虚拟机的平均负载,为虚拟机平均任务完成时间;Timej为虚拟机vmj的负载,即虚拟机vmj上任务完成时间;n为虚拟机数量。 云任务数为40、80、120、160和200的情况下,比较分析IABC、ABC、ACO这3种算法的负载不均衡度DI,如图4所示。 图3 任务完成时间对比 图4 算法的DI值对比 从图4中可以看出:随着任务数量的增加,3种算法的DI值也在增加,且IABC的DI值比ABC和ACO的DI值小,表明在任务调度中,任务完成时间短的情况下,IABC比ABC和ACO负载不均衡度低,可实现更好的负载均衡,各虚拟机之间负载量更接近。 对人工蜂群算法进行改进,用于云计算任务调度中,以最小任务完成时间为目标。把全局最优机制和交叉操作运用到人工蜂群算法中,增强蜂群开发能力的同时保证蜂群向周围搜索的能力,加快算法收敛速度。在观察蜂选择策略中,引入灵敏度的概念,增加了种群多样性,避免算法陷入局部最优。IABC在收敛速度、任务完成时间和负载均衡方面的表现较为优越。
2.3 选择策略的改进
2.4 改进人工蜂群算法的任务调度流程
3 仿真结果与分析

4 结束语
