绿茶加工过程含水率变化规律及预测模型研究**
2022-04-13段东瑶赵丽清殷元元郑映晖徐鑫孙颖
段东瑶,赵丽清,殷元元,郑映晖,徐鑫,孙颖
(青岛农业大学机电工程学院,山东青岛,266109)
0 引言
绿茶在我国茶叶产值中占比70%以上,是我国的主体茶类[1]。绿茶加工过程中伴随着鲜叶大量失水,水分是加工过程中茶叶叶片内部一系列化学反应的介质,是衡量绿茶加工过程最重要的品质因子,因此加工过程中水分的散失程度以及速度极大地影响了茶叶品质[2]。绿茶的水分控制主要依赖于杀青和烘干环节,尤其烘干过程是茶叶水分散失,固定外形和品质的重要阶段。传统绿茶加工的品质控制大多依赖制茶师傅的主观经验判断,受主客观因素影响,人工判断茶叶品质无法做到稳定。近年来,茶叶加工机械在很多茶叶加工企业推广应用[3],杀青烘干过程大多采用动态滚筒机械,其温度、时间、喂入量以及滚筒转速都是茶叶水分变化的重要影响因素[4]。许多研究提出了茶叶加工的数学模型[5-6]、运动模型[7]和预测模型[8-9]。
随着茶叶机械化智能化加工的发展,对加工过程中的含水率的控制要求更加严格,传统半人工半机械化的加工方式已经不能满足绿茶加工需求,需要建立精确的水分预测模型。戴春霞等[10]采用逐步回归分析法对预处理后的数据提取特征波长,并采用多元线性回归法、偏最小二乘回归建立特征波长和茶鲜叶含水率定量分析模型,实现了茶叶加工过程中基于高光谱的茶鲜叶含水率快速检测。张宪等[11]通过研究茶叶叶片形状、纹理及颜色的变化,利用回归值验证与BP神经网络建立含水率非线性预测模型,准确度在90%以上,以此建立了基于多光谱图像参数的茶叶摊青评价模型。这些研究大多关注茶叶含水率的实时检测,但是忽视了茶叶加工过程中含水率的动态变化规律。
本研究基于日照绿茶加工工艺[12],研究分析绿茶加工过程中各环节的含水率变化规律,采用机器学习方法,选择绿茶加工主要的失水过程杀青和烘干,根据企业流水线特性要求固定茶叶喂入量和滚筒转速,以温度、初始含水率以及工作时间作为输入,时刻含水率作为输出,建立绿茶加工杀青和烘干过程的含水率动态预测模型,以期为绿茶加工技术的智能化和数字化提供研究基础和依据。
1 材料与方法
1.1 试验材料
试验材料选用2020年秋季山东省日照市某公司茶园当日扬采的标准一芽一叶或一芽两叶鲜叶,鲜叶初始含水率为77%~80%,经摊青、杀青、冷却回潮、揉捻以及烘干、提香工艺制成绿茶,分别选取各个工序的开始和结束时刻对茶叶进行采样,测量记录茶叶从摊青到加工结束的含水率变化,同时在各个工序按照时间梯度进行随机采样,测量记录各个工序中茶叶含水率的变化。
1.2 试验设备与仪器
1.2.1 茶叶加工设备
茶叶加工设备为日照某公司生产的6CST-100L型[13]茶叶清洁化生产流水线,其中包括自动摊青机、滚筒式热风杀青机、回潮机、盘式揉捻机组,滚筒式循环动态烘干机以及余热提香机组成,通过提升机输送茶叶到各个机组,茶叶流水线如图1(顺序自右向左)扬示。

图1 6CST-100L绿茶生产流水线结构图Fig.1 6CST-100L green tea production line structure diagram
1.2.2 主要检测仪器及检测方法
对茶叶样品的检测过程扬用到的仪器有BM45卤素水分分析仪;电子天平;数字温度计等,根据国家标准,采用120℃水分快速测定法对茶叶样本进行水分检测[14]。称取茶叶样品(3 g±0.005 g),设置水分仪工作温度为120℃,2 min内快速升温至120℃,工作时卤素灯作为加热源,结合水分蒸发通道快速干燥样品,干燥过程中持续测量并显示蒸发的水分含量,当30 s内水分损失低于0.005 g时停止工作并锁定含水率,显示茶叶含水率、重量起始值、测试时间等数据。其水分测量原理如式(1)扬示。
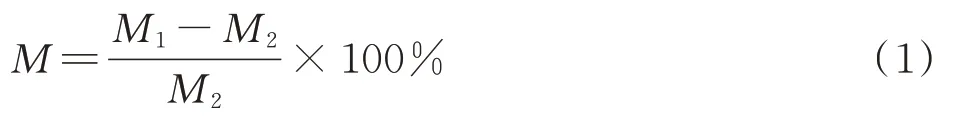
式中:M——茶叶含水率,%;
M1——茶叶样品的初始质量,g;
M2——茶叶样品烘干后的质量,g。
1.3 试验设计
本试验按照传统标准绿茶加工方法进行,茶叶从鲜叶到最后成茶的加工流程依次为摊青、杀青、冷却回潮、揉捻、烘干、提香,具体试验设计如下。
1)摊青:摊青温度为室温(18℃~22℃),摊青的厚度为2~3 cm,时间通常为9~10 h,设置时间梯度为30 min,取样记录含水率。
2)杀青:杀青温度为280℃~300℃,滚筒转速为30 r/min,茶叶在高温下迅速通过滚筒,3~4 min内结束,设置时间梯度为30 s,取样记录含水率。
3)冷却回潮:回潮过程持续1 h左右,促使杀青叶水分重新分布,设置时间梯度为10 min,取样记录含水率;
4)揉捻:持续20~30 min,直至茶叶成条香气散发,设置时间梯度为5 min,取样记录含水率;
5)烘干:相比杀青温度较低,设置为100℃~120℃,滚筒转速为20 r/min,持续60~70 min,设置时间梯度为5min,取样记录含水率;
6)提香:含水率较低,持续时间较短,10~15 min内结束,设置时间梯度为3 min,取样记录含水率。
选取6批茶叶分别对各批次茶叶进行取样记录各工序的含水率变化,每次随机取样15~20 g,测定3次取平均值,直至加工结束,研究分析各工序中含水率变化规律。试验过程中选取的部分样品如图2扬示。

图2 6CST-100L部分待测样品Fig.2 6CST-100L Part of the samples to be tested
1.4 含水率预测模型
为对绿茶加工过程中含水率动态变化过程进行准确的预测,本文基于目前发展较为成熟的BP神经网络以及支持向量机(SVM)算法建立绿茶加工过程中的动态含水率预测模型,分别对两种模型的预测效果进行对比分析,得到最优模型以解决绿茶加工过程中含水率动态预测的问题。
1.4.1 BP神经网络模型
BP(BackPropagation)神经网络采用误差反向传播算法进行学习,是一种可实现复杂非线性映射的多层前馈网络,简单易行,容错率高,其网络拓扑结构如图3扬示,拓扑结构分为三部分:输入层(1层)、隐含层(1层或多层)、输出层(1层)。
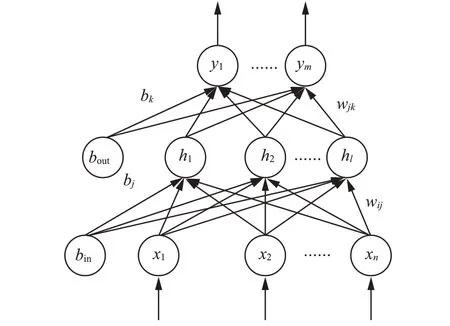
图3 BP神经网络结构Fig.3 BP neural network structure
每一层都含有一个或多个神经元,层与层之间的神经元相互连接[15],隐含层神经元数目一般根据经验公式(2)和试凑法确定。

式中:L——隐含层节点数目;
m——输出层节点数目;
n——输入层节点数目;
a——调节常数,通常取0~10。
大量的神经元相互连接构成人工神经网络框架,通过对现有数据的迭代学习与训练实现对输入和输出的非线性映射。为消除指标之间的量纲影响,网络训练之前对数据进行归一化处理,将数据映射到更小的区间。
在BP神经网络建立的绿茶加工过程含水率预测模型中,采用单隐藏层设计,输入层以加工温度、初始含水率以及工作时间作为输入,模型输出为绿茶加工过程的含水率预测结果。
1.4.2 SVM模型
支持向量机(Support Vector Machines,SVM)最开始被应用于数据分类,后经过发展和完善,推广至非线性回归问题的解决[16]。SVM针对线性可分情况进行分析,对于线性不可分情况使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间,使其线性可分,同时在特征空间中构建最优分类面,使学习器实现全局最优化。SVM最大的优势是没使用传统的推导过程,简化了分类和回归问题,对于中、小样本数据非线性、高维数等问题的解决具有明显优势,SVM建模流程如图4扬示。
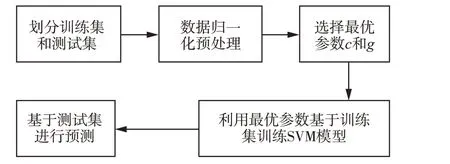
图4 SVM训练整体流程图Fig.4 SVM training overall flow chart
核函数的选择对于SVM模型建立过程至关重要,通过核函数使原空间某些具有非线性问题的数据点转化至高维特征空间进行计算,构造最优超平面将非线性问题转化为线性问题。目前最常用的几种核函数主要有线性核函数、多项式核函数、RBF核函数以及sigmoid核函数,选择核函数最有效的方法便是使用不同的核函数进行SVM训练,挑选表现最优的作为样本训练的核函数。SVM模型采用与BP模型同样的数据集进行训练建模,同样以加工温度、初始含水率以及工作时间作为输入,加工过程含水率预测结果作为输出,通过试验测试的方法对BP和SVM模型进行参数寻优,均以最优参数进行模型训练。
2 结果与分析
2.1 绿茶加工全过程含水率变化规律
试验选用当天新采摘的茶鲜叶,经过摊青机9~10 h的摊青,输送至杀青机直到完成全部加工过程。表1和表2分别为不同加工工序编号以及各茶叶批次含水率变化,茶叶各批次平均含水率变化规律如图5扬示。
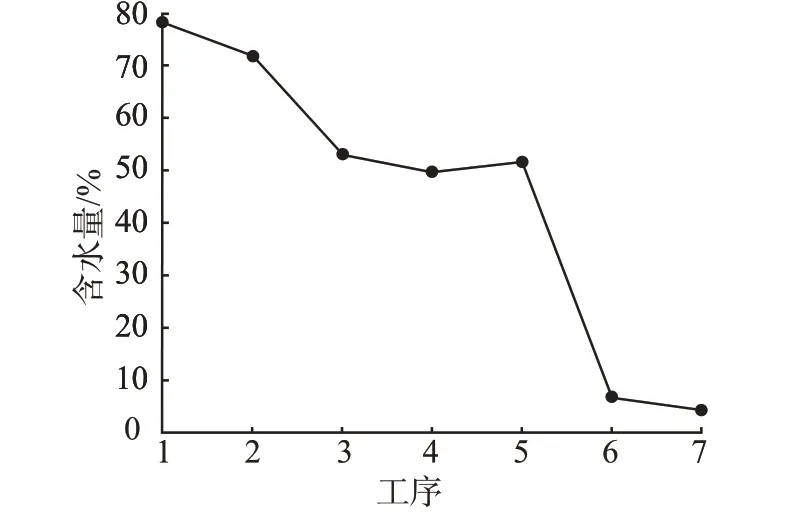
图5 绿茶各批次平均含水率变化曲线Fig.5 Variation curve of average moisture content of each batch of green tea

表1 不同工序样品含水率编号表Tab.1 Number table of sample moisture content in different processes
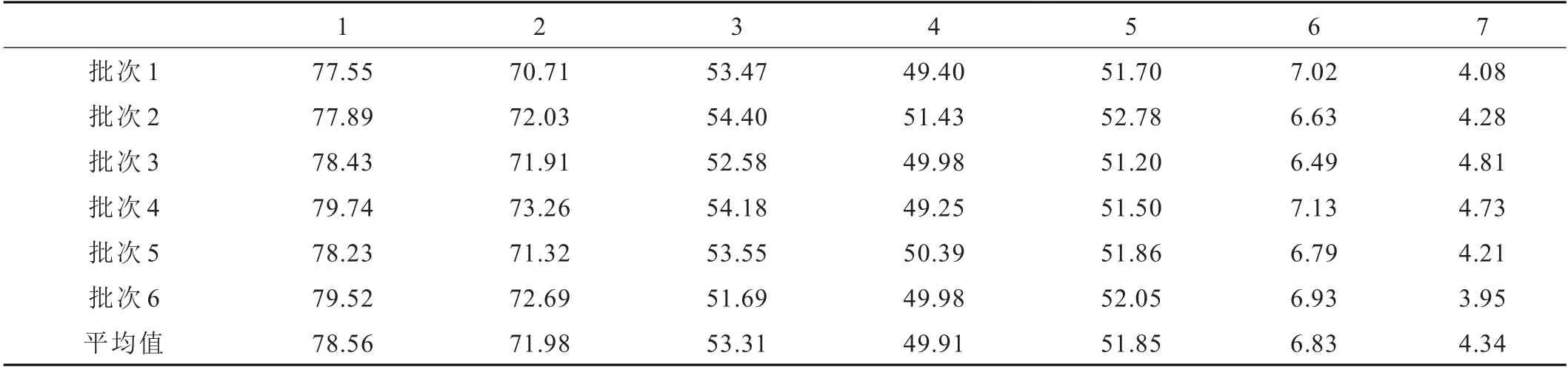
表2 加工过程茶叶含水率变化Tab.2 Changes in tea moisture content during processing %
新采摘的茶鲜叶含水率较高,含水率约为77%~80%,摊青结束后下降至72%左右进行杀青,杀青过程大量失水,含水率降至53%左右,冷却回潮和揉捻过程含水率呈现先减少后升高的趋势,水分变化幅度在3%以内,对整个加工过程而言变化不明显,揉捻结束进行烘干,茶叶再次大量失水降至6%~7%,最后提香工序使茶叶含水率降至4%左右,茶叶加工结束。
2.2 绿茶各加工工序含水率变化规律
2.2.1 摊青与杀青
新采摘的鲜叶水分大约在78%左右,在杀青前需要对鲜叶进行9~10 h的摊青处理,促使茶叶内部多酚类等滋味成分适度转化,挥发青草气。图6(a)为茶叶摊青过程平均含水率变化过程,结果显示摊青过程含水率的整体变化十分缓慢,平均每小时失水约1.25%,摊青开始时失水较慢,后期速度明显加快,这是因为刚采摘的茶鲜叶叶片脆硬,保水能力较强,随着水分减少,叶片细胞的呼吸速率逐渐降低,细胞逐渐失去膨胀状态,叶质由硬变软,保水能力逐渐降低,失水速度加快,摊青结束鲜叶含水率约为72%左右,经过摊青的茶叶叶质柔软,叶色由鲜绿转为暗绿,青气消失,清香显露,可进行下一步的杀青过程。
杀青是绿茶加工中的关键工序。主要原理是采取高温措施使鲜叶大量失水,达到可以揉捻的程度[17]。图6(b)为不同温度下茶叶杀青过程中的含水率变化曲线,结果表明,杀青开始失水速度较快,随着水分降低稍有放缓,整个杀青过程短暂且剧烈,4 min内茶叶含水率由72%迅速降至53%,这是由于在自然条件下茶叶中含有的茶多酚会发生酶促反应使茶叶发酵,发酵后的茶叶表现为“红梗红叶”,严重影响绿茶品质,因此需要高温抑制酶的活性避免发酵,同时在茶叶大量失水的同时发生一系列化学变化,形成绿茶的品质特征。经过杀青的茶叶叶色暗绿,手捏叶质柔软,略有粘性,梗折不断,青气消失,茶香溢出。
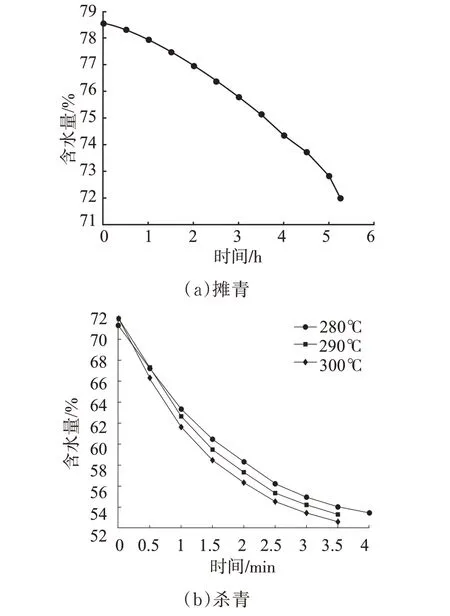
图6 摊青及杀青过程平均含水率变化曲线Fig.6 Variation curve of average moisture content in the process of spreading and tea leaves
2.2.2 冷却回潮与揉捻
经过杀青的茶叶由于高温造成茶叶内部水分分布不均,特别是叶肉与叶梗之间水分差别较大,需要对杀青后的鲜叶进行回潮处理使梗叶水分重新分布。将回潮过程取得的茶叶样品进行梗叶分离,分别测量叶肉与叶梗的含水率,其叶片含水率变化以及梗叶水分比如图7扬示。
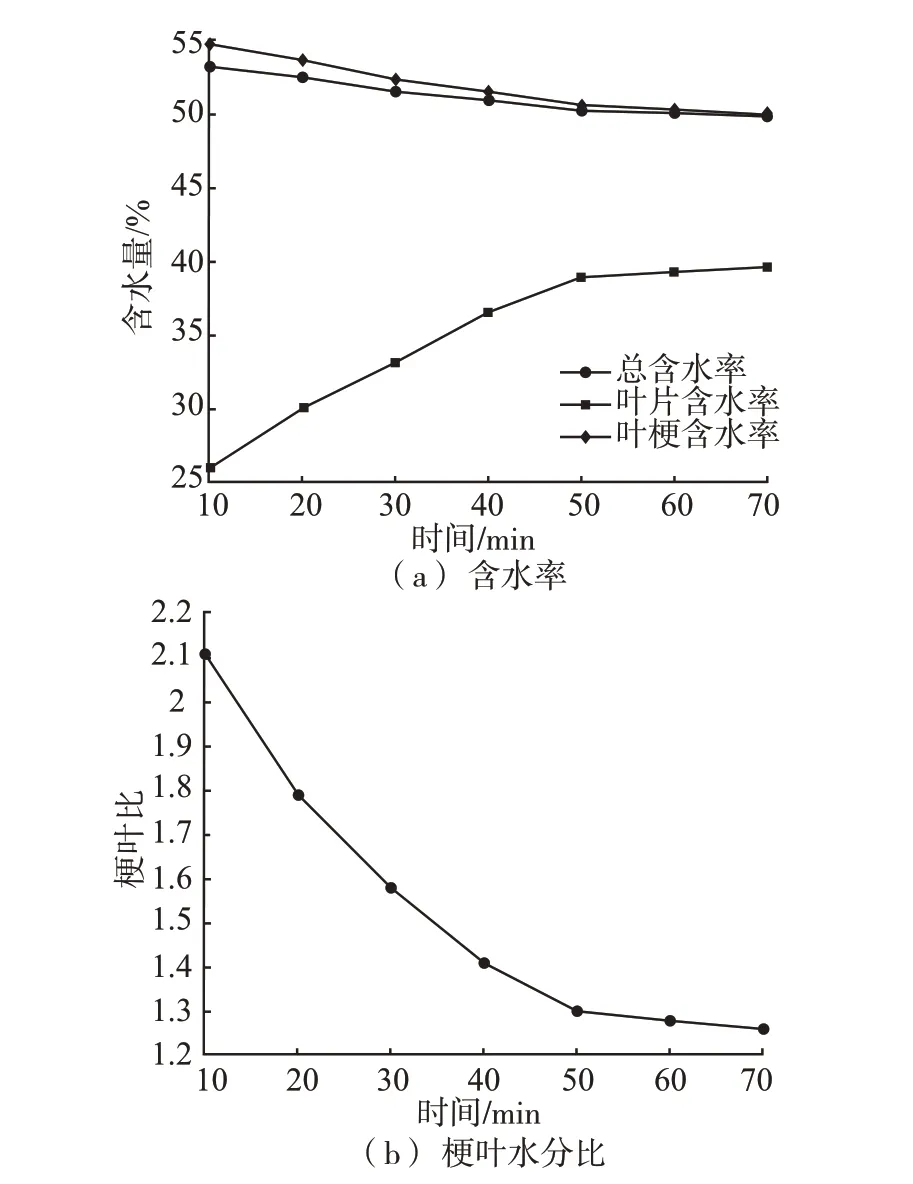
图7 冷却回潮过程平均含水率变化曲线Fig.7 Variation curve of average moisture content in the process of cooling regain
结果显示,相比茶叶总体含水率,叶梗部分水分略高,叶片部分水分较低,回潮过程主要是叶梗中的水分向叶片部位的移动过程,梗叶水分比由2.1下降至1.26后基本稳定,整个过程伴有3%左右的少量失水,为揉捻做准备。
冷却回潮结束,茶叶由传送带送至揉捻机组进行揉捻,揉捻工序指对鲜叶进行揉搓使茶叶细胞壁破碎,细胞液流出附着在茶叶表面,促进茶叶外形的形成,卷曲成条[18]。图8为揉捻过程的茶叶含水率变化曲线。

图8 揉捻过程平均含水率变化曲线Fig.8 Variation curve of average moisture content during rolling and twisting
结果显示,揉捻过程通常持续20~30 min,含水率变化速率不稳定,整个过程茶叶含水率有2%~3%左右的少量升高,这是因为揉捻过程中茶叶的细胞壁破碎速率不稳定导致水分变化速率不稳定,揉捻时浓稠的细胞液流出,在潮湿的工业生产环境中吸收少量水分使得水分微量升高,但是由于整个过程水分变化不明显,在复杂的工业环境中通常忽略揉捻过程的水分变化。
2.2.3 烘干与提香
烘干过程是茶叶加工过程中水分变化最为显著的工序,在茶叶大量失水的同时起到对茶叶整形做形,固定茶叶品质的作用[19]。采用滚筒烘干机对茶叶进行动态烘干,茶叶烘干时处于不停翻滚的状态,可有效防止茶叶结块,不同温度下茶叶烘干过程含水率变化曲线如图9(a)扬示,整个过程大约持续60~70 min,水分由50%左右降至6%左右,整个过程呈现先快后慢的趋势,随烘干温度的升高失水速率显著升高。烘干结束后进行最后的提香工序,通过高温烘出茶香,彻底消除青草气,同时水分降至易于保存的范围(4%~5%),图9(b)为提香过程含水率变化,提香过程失水较少,水分越低,下降越慢。经过烘干和提香后的茶叶,绿润匀整,滋甘味醇,茶香浓烈。
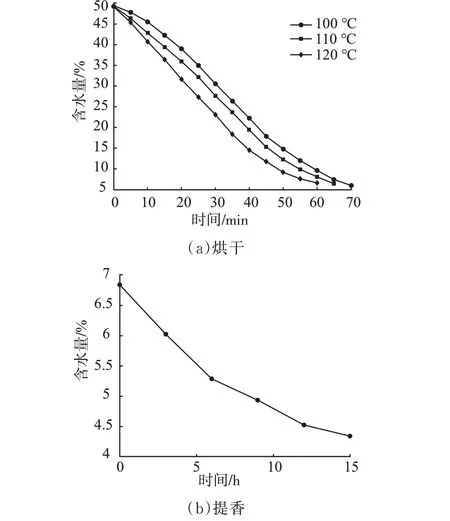
图9 烘干及提香过程平均含水率变化曲线Fig.9 Variation curve of average moisture content during drying and titian
2.3 含水率预测模型的建立
为减小误差,绿茶杀青和烘干试验过程中每次测量试验均进行3次,共记录杀青数据204组,烘干数据564组,取3次测量的平均含水率作为数据集对模型进行训练,共得到杀青数据集68组,烘干数据集188组,基于同样的数据集分别采用BP神经网络算法和支持向量机(SVM)算法建立杀青和烘干模型。
2.3.1 BP预测模型的建立
利用BP神经网络算法对绿茶杀青以及烘干过程建立含水率回归预测模型,选择温度、工序初始含水率、工作时间作为输入,时刻含水率作为输出,根据经验公式(2)确定隐含层神经元数量为2~12,将数据分为训练集和测试集,比例设置为9∶1、8∶2、7∶3和6∶4,分别进行训练,选择决定系数R2作为评价指标[20],测试集的预测结果如图10扬示。
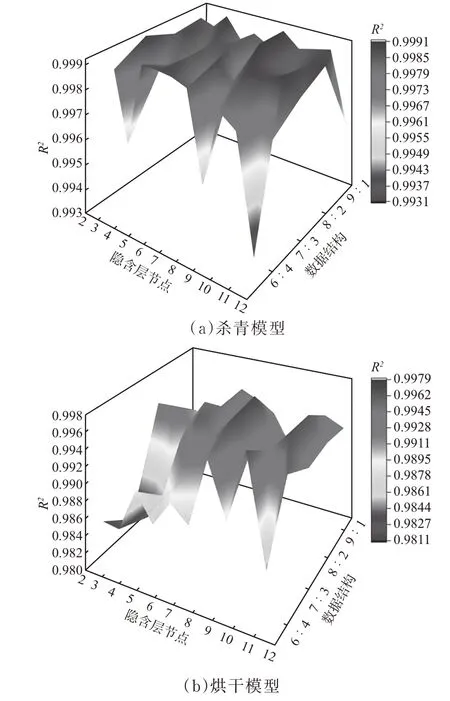
图10 BP网络杀青、烘干不同隐含层节点数目和数据比例交叉寻优分析Fig.10 Cross-optimization analysis under different hidden layer nodes and data ratios in during tea leaves and baking of BP network
结果表明,在绿茶杀青和烘干工序建立的BP网络模型均在隐含层节点为8,数据结构为8∶2(杀青模型训练集为54组,测试集为14组;烘干模型训练集150组,测试集为38组)时,预测模型精度最好,其决定系数R2分别为0.999 01和0.997 29。
2.3.2 SVM预测模型的建立
以相同的数据集利用支持向量机(SVM)对绿茶杀青和烘干过程的含水率进行回归预测,通过MATLABLISBSVM工具箱建立SVM回归模型,目前最常用的核函数主要有线性核函数(Linear Kernel)、多项式核函数(Polynomial Kernel)、RBF核函数(RadialBasis Function)以及Sigmoid核函数,分别利用不同的核函数以及数据结构进行训练,以决定系数R2为评价指标,测试集的预测结果如图11扬示。
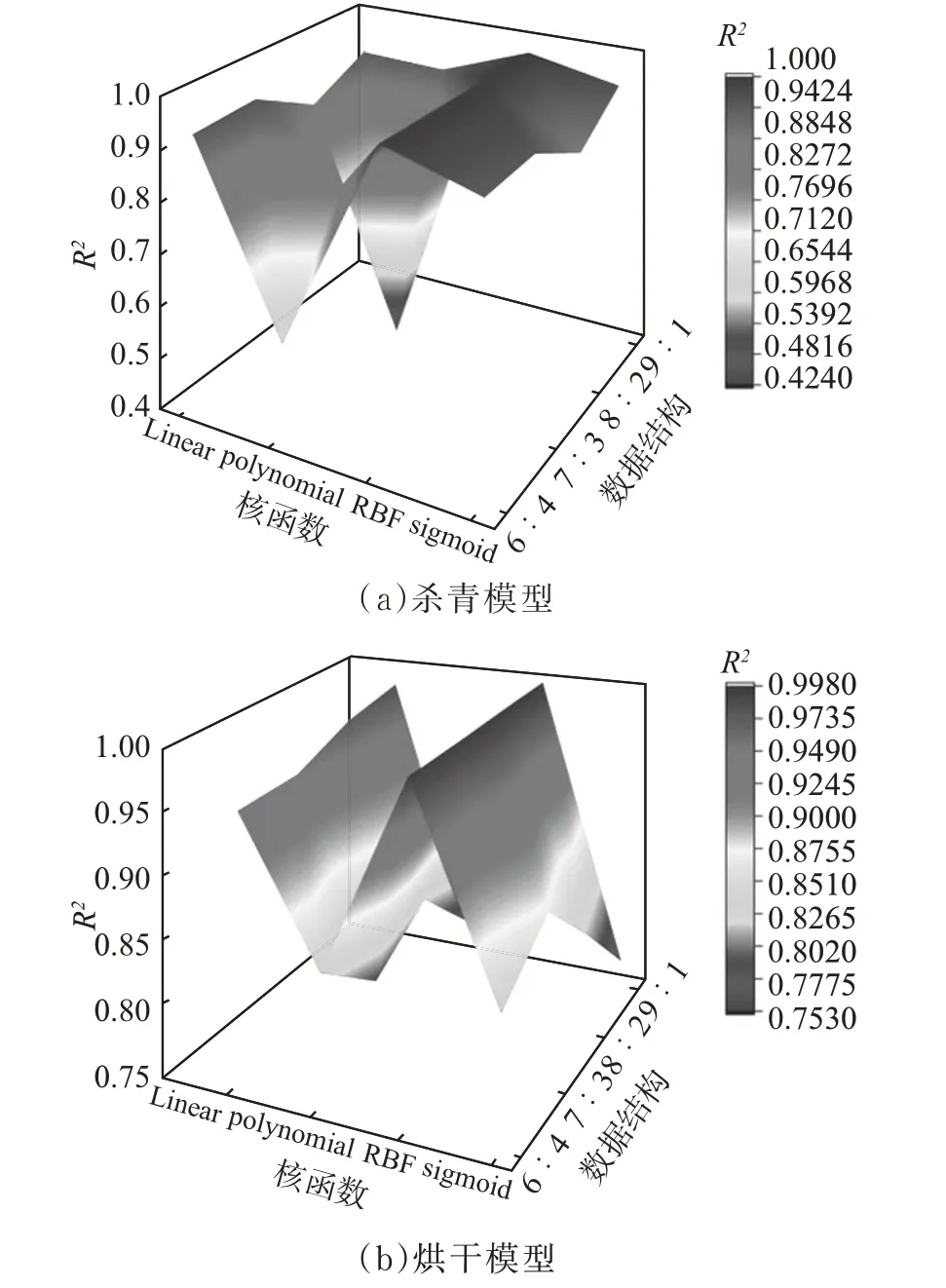
图11 SVM杀青、烘干不同核函数和数据比例交叉寻优分析Fig.11 Cross-optimization analysis under different kernel functions and data ratios in during fixation and drying of SVM
由图中结果可知,对于SVM模型,杀青和烘干模型均在RBF核函数,数据比例为8∶2(杀青模型训练集为54组,测试集为14组;烘干模型训练集150组,测试集为38组)时的预测模型精度最高,杀青和烘干模型的R2分别为0.999 32和0.997 86。
2.3.3 预测模型对比分析
对绿茶加工过程中失水最为显著的杀青以及烘干过程以温度、初始含水率以及工作时间作为输入,茶叶含水率作为输出,分别利用BP神经网络算法和SVM算法建立含水率预测模型。
通过2.3.1 节和2.3.2 节寻优分析确定BP网络结构为3-8-1,SVM模型以RBF为核函数,数据结构训练集和测试集比例均为8∶2(杀青模型训练集为54组,测试集为14组;烘干模型训练集150组,测试集为38组)。
采用均方根误差RMSE、平均绝对误差MAE和决定系数R2作为模型评价指标,R2越接近1,RMSE、MAE越小,表明模型的预测效果越好。经过训练的杀青及烘干过程的BP和SVM含水率预测模型的预测结果如表3和图12扬示。
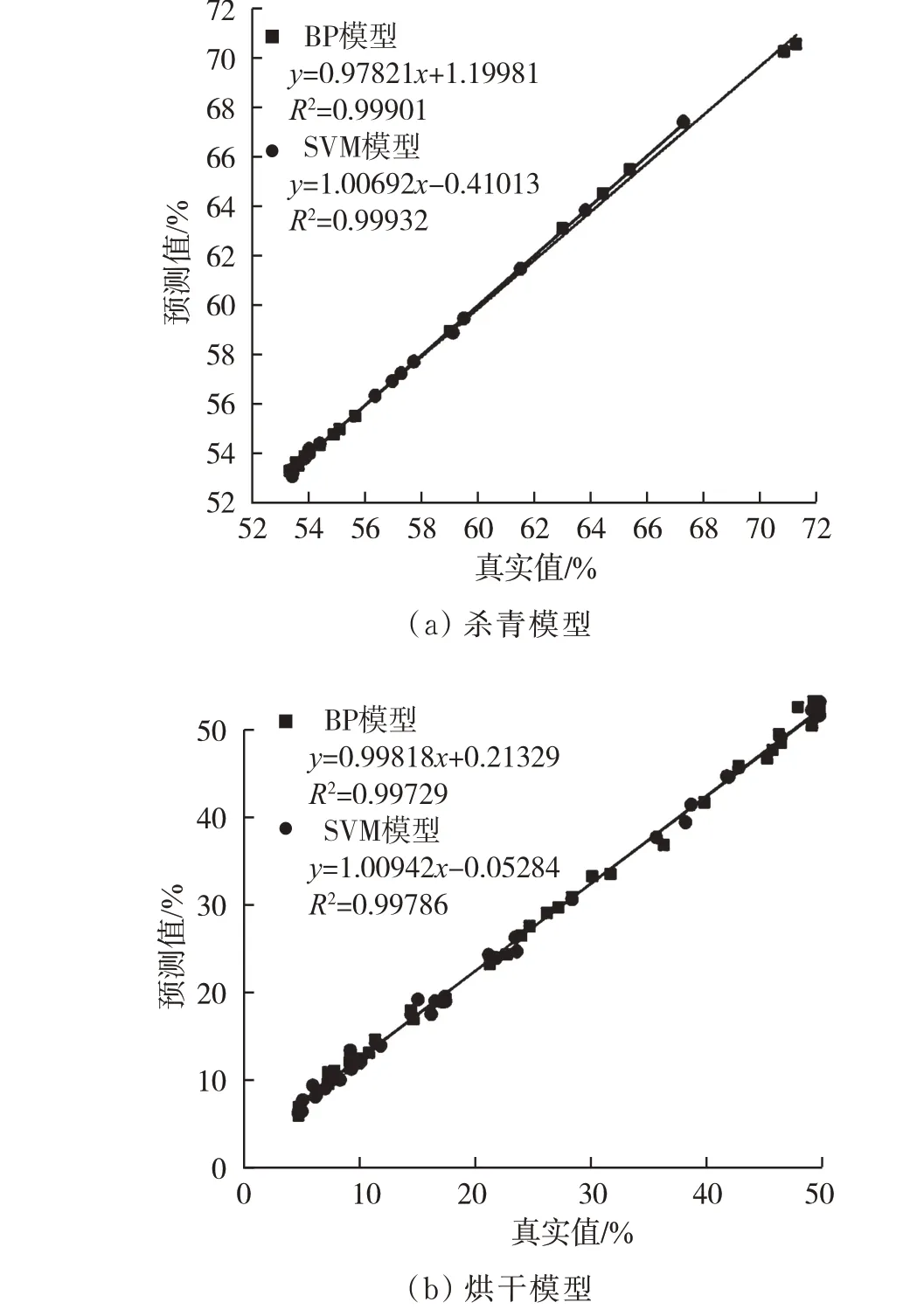
图12 BP和SVM预测模型验证结果Fig.12 Verification results of BP and SVM prediction model

表3 杀青及烘干过程含水率预测模型比较Tab.3 Comparison of prediction models of moisture content in the process of tea leaves and baking
结果表明,由模型推算得到的预测值与实测值之间都呈显著相关,MAE、RMSE和R2都较理想,相比BP神经网络模型,支持向量机(SVM)模型的模型预测效果更好,预测值与真实值的误差更低。
通过对不同加工工序含水率预测的误差分析可知,相比烘干环节,建立的两种模型均对失水过程更加剧烈的杀青工序的预测更准确,精度更高,效果更好。
3 结论
1)茶叶含水率是茶叶加工过程中的重要指标,本文通过设计试验探究了茶叶加工过程中含水率的变化规律,新采摘的茶鲜叶,经过摊青、杀青、冷却回潮、揉捻、烘干以及提香6个步骤最终加工成色香味形俱佳的绿茶,由茶叶内的水分作为介质承载其内含成分发生理化变化,这使得含水率成为了茶叶加工中的关键性指标,除了回潮和揉捻过程水分变化不明显,摊青、杀青、烘干、提香等工序的加工程度都会以茶叶含水率作为评价指标。
2)通过各工序试验,得出在茶叶加工过程中,水分变化最显著的是杀青以及烘干过程,其次为摊青和提香,回潮和揉捻过程目的是使茶叶水分重新分布以及揉出细胞液,水分变化最不明显。摊青过程使得茶叶含水率由78%左右下降至71%左右,过程缓慢,水分均匀丧失,茶叶叶质由硬变软,发出清香;杀青过程短暂且剧烈,失水至51%左右,高温阻止发酵,促进茶叶内含物转化,是形成“清汤绿叶”的关键工艺;回潮过程实现梗叶水分重新分布,揉捻使茶叶细胞壁破碎细胞液流出附着在茶叶表面,茶叶卷曲成条,促进外形形成,两个过程水分变化均不明显;最后的烘干以及提香工序依然伴随茶叶大量失水,相比杀青较柔和,失水的同时起到对茶叶整形做形,固定茶叶品质,发展茶香的作用,是实现绿茶“绿润匀整,滋甘味醇”的关键工艺。
3)为准确预测绿茶加工过程的含水率变化,选择失水最显著的杀青以及烘干过程,以温度、初始含水率和工作时间作为输入,时刻含水率作为输出,基于BP神经网络和支持向量机(SVM)算法,建立绿茶加工中杀青和烘干过程含水率动态回归预测模型,经验证,BP杀 青 和 烘 干 模 型 的R2分 别 为0.999 01、0.997 29,SVM杀青和烘干模型的R2分别为0.999 32、0.997 86,对各个模型进行误差分析,结果表明采用支持向量机(SVM)算法建立的预测模型性能更加良好,对绿茶的智能化生产具有较好的指导意义。
