结合注意机制和局部擦除的行人重识别方法
2022-03-26贺南南张荣国李建伟
贺南南,张荣国,王 晓,李建伟,胡 静
(太原科技大学 计算机科学与技术学院,太原 030024)
行人重识别旨在通过匹配查询图像,通过在不同位置的非重叠摄像机视图中搜索行人[1]。由于在照明、遮挡、分辨率、人体姿势、视角、服装和背景方面的巨大变化,使得行人重识别任务具有很大的挑战性。近年来,基于深度学习的行人重识别方法显示了良好的检索性能,因此,引入了基于深度学习的方法[2-6]来学习对这些变化具有鲁棒性的鉴别特征和表示,从而达到更高的识别率。
有些方法直接从行人图像中提取有用的全局特征,全局特征不考虑一些局部信息,因此,在具有挑战性的行人重识别任务中仅仅使用全局特征已经不能达到性能要求。为此提取更加的复杂的局部特征是解决这一不足有效的方法。很多基于姿态的方法试图定位不同的身体部位并对齐它们的相关特征,Zheng等人[7]先用姿态估计的模型估计出行人的关键点,然后用仿射变换使得相同的关键点对齐。一些基于局部的方法[8]则使用粗划分或注意选择网络来改进特征学习。sun等人[4]提出PCB,在卷积网络后提取特征图,并在水平方向划分为均匀的6个区域,代表人体的抽象部件特征。
这种基于姿势的网络通常需要额外的身体姿势信息。基于局部的网络需要使用特定的划分机制,例如水平划分,这需要同一个人的身体部位相对对齐。本文提出了一种更加简单有效的基于注意局部擦除的行人重识别方法。
1 相关工作
注意机制。许多方法将注意机制引入到深度模型中,利用注意机制来捕捉和聚焦注意区域以解决行人识别中的错位的问题。Li等人[8]提出了一种多任务学习模型,将硬区域级和软像素级的注意联合起来学习,产生更具区分性的特征表示。Tay等人[10]提出了一个属性注意网络,将行人属性、行人局部信息以及身份类别集成在一个统一的学习框架中。
重排序。在获得图像特征后,大多数现有的方法选择L2欧氏距离来计算排序或检索任务的相似度得分。而一些方法使用额外的重新排序以提高识别的准确性。Zhong等人[11]提出了一种结合原始距离和Jaccard距离的倒数编码重排序方法。
度量学习。在深度度量学习中,深度模型能够通过图像特征向量在嵌入空间的L2距离直接学习图像的相似性。度量损失主要有对比损失、三元组损失和四元组损失。此外,硬样本挖掘方法如距离加权抽样、硬三重挖掘和裕度样本挖掘对于最终的检索精度也是至关重要的。
2 结合注意机制和局部擦除的学习网络
2.1 网络整体结构
本文方法的网络体系结构如图1所示,使用了ResNet50作为主干网络,并对该网络进行了修改:(1)去除了网络最后的一个空间下采样操作,从而可以获得更大尺寸的特征图;(2)移除 ResNet50 网络最后的全局平均池化层和全连接层。
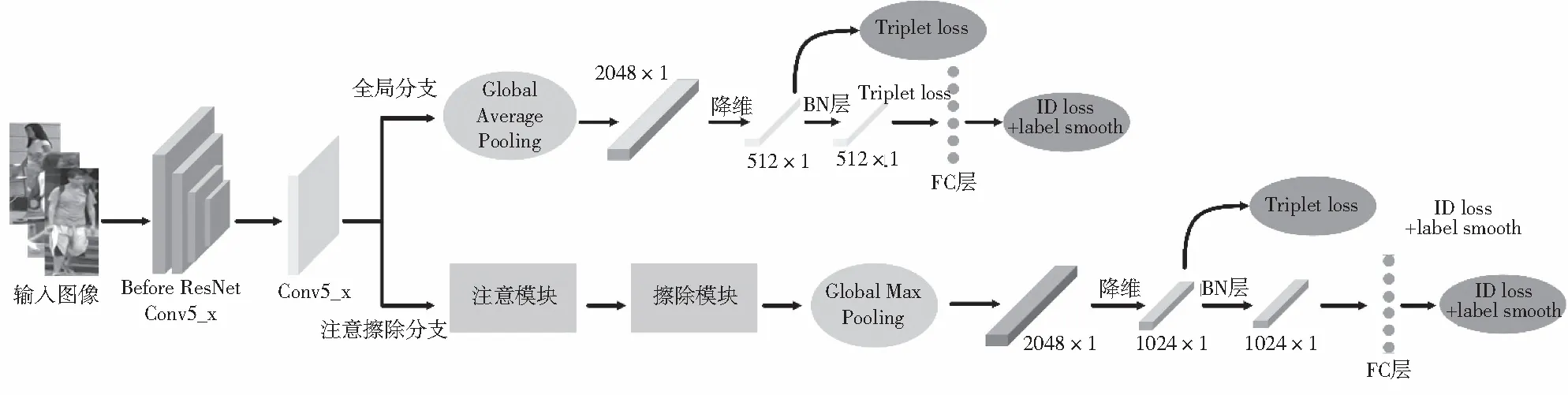
图1 网络整体结构图
在卷积神经网络中,网络层数越多提取细节与抽象能力越丰富,但是随着网络层数的增加会出现梯度爆炸和梯度弥散的问题,而残差网络ResNet有效解决了这一问题,因此,本文选用ResNet50[9]作为主干网络。
本文方法网络结构由两个分支构成,全局分支提供全局特征表示,同时可以监督注意擦除分支的训练,有利于注意擦除分支能够学习良好的特征映射。注意擦除分支,通过主干网络输出特征张量,然后将特征张量输入到位置注意模块(PAM),再输入到擦除模块,在擦除模块中将会随机擦除一批输入图像的同一区域。两个分支在训练阶段均使用ID损失和三元组损失进行多损失联合训练。
在测试阶段,将全局分支和注意擦除分支提取的特征串接为最后的特征。
2.2 位置注意模块
位置注意模块(PAM)可以用来捕获和聚集空间域中语义相关的像素,如图2所示。输入特征映射A∈RC×H×W,其中H×W是特征图大小。首先通过批量归一化和ReLU激活进入卷积层产生特征映射B,C,D∈RC×H×W,然后计算像素关联矩阵S∈RN×N,其中N=H×W.然后最终输出特征图E:

图2 位置注意模块结构图
(1)
式中:γ是权重超参数,训练时随机初始化,C是通道总数。Sij的计算方法为:
(2)
2.3 局部擦除模块
将一批输入图像输入到主干网络,经过卷积等操作输出特征张量,然后随机擦除相同的一个区域,即每个特征张量都根据设置进行擦除,本文设置擦除宽度比为1,高度比为0.3.如图3所示,本文方法在实验中使用三元组损失,因此,将三元组损失图像组进行随机擦除,使得擦除区域的所有单位为零。删除相同的区域有利于特征映射中语义对齐,加强局部特征的学习。擦除模块在训练过程中不需要改变保持概率的超参数。

图3 局部擦除模块结构图
2.4 损失函数
2.4.1 标签平滑
本文方法使用交叉熵损失函数[12]进行身份预测,将图像输入后,通过该函数对图片对进行各自身份标签的预测,损失函数为:
(3)
其中:qi代表目标概率,pi代表预测行人属于标签i的预测概率,i代表输入行人图像类别,y代表行人标签,数据集中每一个行人都有对应的标签,假如输入行人图像,若y属于类别i,则其值为1,反之为0.
在行人重识别中,测试集的行人身份不出现在训练集中。因此,防止行人重识别模型的训练标签过拟合是非常重要的。文献[13]中提出了一种防止分类任务过度拟合的方法标签平滑(Label Smoothing)。因此,qi的结构变为:
(4)
其中ε为常数,代表标签的错误率,将ε设为0.1,当训练集不太大时,标签平滑方法可以显著改善模型的性能。
2.4.2 三元组损失函数
三元组损失可以有效地解决类间相似、类内差异问题,因此,我们使用了难样本三元组损失[14],该损失函数的公式为:
(5)
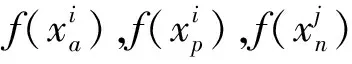
2.4.3 联合损失训练
本文方法采用标签平滑损失和三元组损失对模型进行联合训练,使用这两种损失来约束相同的特征,但是这两种损失的目标在嵌入空间是不一致的。ID损失需要构造多个超平面以将嵌入空间分离到不同的子空间。每一类的特征在不同的子空间中,因此,余弦距离更适合用ID损失优化模型。三重态损失是由欧氏距离计算的,它增强了欧氏空间的类内紧性和类间可分性。如果使用这两个损失来优化特征空间,那么它们的目标可能不一致。
为了使这两种损失结合起来更好的提高性能,本文在特征层和分类器层之间加入批量归一化(BN)层,将BN层之前的特征表示为ft,让ft通过BN层得到特征fi,在训练阶段分别使用ft和fi计算三元组损失和ID损失。最后,本文模型的总的损失函数为:
L=LID+Ltriplet
(6)
2.5 算法步骤
结合注意机制和局部擦除分支网络的行人重识别主要是图像经过主干网络后,提取特征映射,分别输入到全局分支和注意擦除分支中,经过池策略、降维等一系列操作,最后通过交叉熵损失、三元组损失进行联合训练。具体的算法流程步骤如下:

Algorithm:结合注意机制和局部擦除方法的算法步骤 Step1.输入行人图像。Step2.在Conv5_x提取行人图像特征图。Step3.在全局分支中对特征图采用全局平均池化后输出2048维特征。Step4.将该特征进行降维处理,输出512维特征。Step5.将该特征输入到BN层中处理。Step6.将BN层之前的特征和BN层之后的特征分别输入到Tripletloss和IDloss中。Step7.在注意擦除分支中对特征图采用全局最大池化后输出2048维特征Step8.将该特征进行降维处理,输出1024维特征。Step9.重复Step5,Step6步骤。
3 实验结果与分析
3.1 数据集与评估指标
3.1.1 数据集
为验证本文方法的有效性,在Market-1501[15]和DukeMTMC-reID[16]两个行人重识别数据集上进行实验,并和现有的几种方法进行比较。
Market-1501数据集一共包含了1 501个行人的32 668张图片,该数据集在6个不同摄像头下进行采集,图片由DPM[17]自动检测,Market-1501数据集中分为训练集和测试集,训练集中有12 936张图片,包含了751个人,测试集中有19 732张图片,包含了750人。
DukeMTMC-reID数据集一共包含了1 404个行人的36 411张图片,该数据集在8个不同的摄像头下进行采集。数据集中也分为训练集和测试集,训练集中有16 522张图片,包含了702个人,测试集中有17 661张图片,与训练集相同,包含了702个人。
3.1.2 评价指标
本文实验中使用了行人重识别中常用的评价指标,累积匹配特性曲线(CMC)中的Rank-1、Rank-5、Rank-10和平均精度均值(mAP)两种评价指标。
累积匹配特性曲线中的Rank-n是指在搜索结果中n张图片的正确率。Rank-1是指第一位检索正确的概率,Rank-5是指前五张图像中检索正确的概率,Rank-10是指前十张图像中检索正确的概率。
平均精度均值能够更加全面的衡量行人重识别算法的性能,它是将平均精度AP求和再取平均,公式为:
(7)

3.2 实验设置
本文实验使用了深度学习框架Pytorch,Python版本为3.6.实验平台为64位的Ubuntu18.04操作系统,并使用NVIDIA GTX 1660Ti GPU进行训练。
在实验中将输入图像尺寸调整为384×128,然后使用随机翻转对数据进行增强。在训练过程中,采用SGD优化器进行参数更新,其中动量衰减因子为0.9,权重衰减因子为0.000 5.本文实验共训练120次,初始学习率设置为0.01,在40次,80次,100次迭代后学习率缩小0.1倍。batch大小设置为32,模型训练总损失为每个损失加权之和。
3.3 不同分支的实验结果分析
为了验证本文提出方法的有效性,在Market-1501和DukeMTMC-reID数据集上进行了实验。分析了所提方法中每个成分的有效性以及参数的影响。表1,表2为测试双分支结构在这两个数据集的有效性,分别对全局分支(分支1)、注意擦除分支(分支2)以及本文提出的双分支结构进行实验。
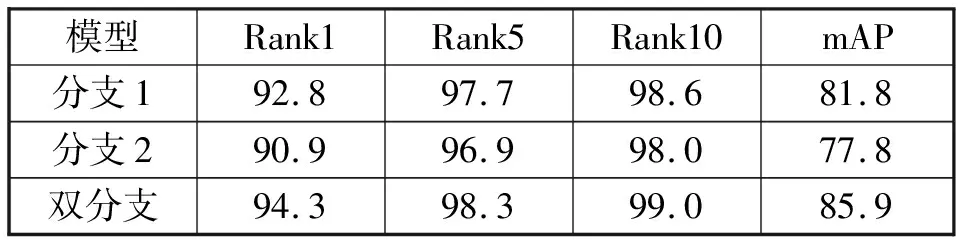
表1 在Market-1501数据集上使用不同设置的结果
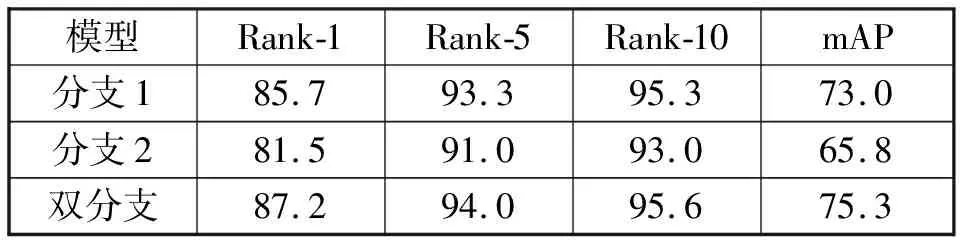
表2 在DukeMTMC-reID数据集上使用不同设置的结果
通过表1和表2数据可以观察到,双分支结构的性能要高于全局分支和注意擦除分支的性能。在Market-1501数据集上进行实验可以看到双分支结构的Rank-1和mAP分别为94.3%和85.9%.在Rank-1上双分支结构与其它两种结构相比分别提升了1.5%、3.4%.在mAP上双分支结构与其它两种结构相比分别提升了4.1%、8.1%.在DukeMTMC-reID数据集上进行实验可以看到双分支结构的Rank-1和mAP分别为87.2%和75.3%.在Rank-1上双分支结构与其它两种结构相比分别提升了1.5%、5.7%.在mAP上双分支结构与其它两种结构相比分别提升了2.3%、9.5%.
全局分支可以学习到显著的全局特征,但是不能够学习到具有区分性的特征,而注意擦除分支可以学习到细粒度的区分特征。这两个分支结构的性能远远低于双分支结构的性能,说明了将这两个分支组合到一起,可以使得全局分支监督注意擦除分支的训练,有利于注意擦除分支能够学习良好的特征映射。而注意擦除分支也可以提供更加细粒度的特征,这两个分支相互加强,大大提升了识别性能。
3.4 批量归一化层对实验的影响
为了验证加入批量归一化层的有效性,将本文提出方法在有无批量归一化层的情况下进行比较,另外实验其它设置相同。表3为在Market-1501数据集下进行对比,表4为在DukeMTMC-reID数据集下进行对比。通过实验结果所示,在这两个数据集上加入批量归一化层后的方法的性能都高于未加入批量归一化层的方法的性能。在Market-1501数据集上Rank1和mAP分别提升了0.4%和2.5%,在DukeMTMC-reID数据集上Rank1和mAP分别提升了2.1%和3.4%,证明了加入批量归一化层的有效性。

表3 在Market-1501数据集上有无批量归一化层实验结果

表4 在DukeMTMC-reID数据集上有无批量归一化层实验结果
3.5 与现有方法的比较
为了验证本文所提方法的有效性,将本文算法与现有的八种方法进行比较,分别为PCB、DaRe、GSRW、SGGNN、Deep-CRF、IANet、Triplet Loss、PIE.表5为在Market-1501数据集和DukeMTMC-reID数据集上对比结果。由表5数据可得,本文提出的方法在两个数据集上的 Rank-1和mAP与现有的这几种方法比较均有明显的提升,本文方法通过设计注意擦除模块,进一步加强局部特征的作用,弥补了信息的缺失,与基线相比较算法时间大大增加,但是在精度上得到了很大的提高,并优于其他现有的方法,证明了本文方法的有效性。

表5 与现有行人重识别方法的比较
图4展示了本文方法在数据集Market-1501上的检索结果,图5展示了在数据集DukeMTMC-ReID上的检索结果。如图所示,最左边行人为查询行人,1到10为从左到右相似度分数最高的10张图片,即rank10的查询结果。如图所示可以展示出本文方法能够有效的检索出正确的结果。

图4 在Market-1501数据集的检索结果

图5 在DukeMTMC-reID数据集的检索结果
4 结论
本文提出了一种结合注意机制和局部擦除的行人重识别方法,通过设计注意局部擦除网络,更好的提取局部区域的特征。本文网络结构是由全局分支和注意擦除分支组成的双分支网络,全局分支提取全局特征并在训练中监督注意擦除分支的训练,注意擦除分支则可以加强局部区域的注意特征学习。最后使用两种损失函数进行联合训练优化,而且在这两种损失之间设计了归一化层结构,有效的解决了两种损失的不能同步收敛的问题。实验结果表明,本文提出的方法在 Market-1501、DukeMTMC-reID 数据集上性能与目前主流的方法相比取得了很大提升,表明了本文方法在行人重识别方面的确可行有效。
