K-VQA:一种知识图谱辅助下的视觉问答方法
2020-09-10高鸿斌毛金莹王会勇
高鸿斌 毛金莹 王会勇
摘 要:依照所回答的问题类型区分,图像和文本的视觉问答大体分为2类,第1类是可以从图像中直接获取答案的问题,第2类是需借助外部知识获取答案的问题。目前的视觉问答方法只能在一类问题上具有较高的准确率,回答另一类问题的技术尚不成熟。为了扩大可回答的问题类型,设计了一种知识图谱辅助下的视觉问答方法——K-VQA。在基于深度学习VQA的基础上,通过查询知识图谱区分问题类型,对不同类型的问题采用最合适的方法进行回答,对于需借助外部知识进行回答的问题,利用图像和问题中的信息判断回答问题所需的实体和属性,抽取知识图谱中的三元组,获取问题答案。结果表明,不同的视觉问答技术适用于不同类型的问题,K-VQA方法既能回答简单问题也能回答推理性问题,准确率高达56.67%。因此,作为知识图谱辅助下的视觉问答方法,K-VQA可以回答更多类型的问题并获得较高的准确率,对于深入研究VQA和VQA方法具有重要的参考价值。
关键词:知识工程;视觉问答;外部知识;知识图谱;三元组
中图分类号:TP392 文献标识码:A
文章编号:1008-1542(2020)04-0315-12
doi:10.7535/hbkd.2020yx04004
如今,越来越多的智能机器人被研发出来并走进人们的生活,其中非常关键的一点是其与人之间的沟通与交流,但是交流并不仅限于语言沟通,更多时候需要依据其他外部知识(如图片、视频、音频等)进行对话,因此出现了大量将文本和图片、视频、音频等进行结合的多模态技术,其中视觉问答(visual question answering,VQA)技术是研究的热门话题。VQA技术旨在通过提取指定图片和文本中的关键信息,给出问题所对应的准确答案。一般视觉问答通过深度学习的方法,分别提取图像和问题的特征,采用不同方式的特征融合机制进行处理,并获得答案。
随着知识图谱的不断开放,大量知识图谱(knowledge graph,KG)也在VQA中得到運用。已知的较大知识图谱包含从Wikipedia词条中抽取的DBpedia[1]、Google的Freebase[2]、融合Wikipedia,WordNet[3]和GeoNames的多语言知识图谱YAGO[4]等。基于知识图谱的VQA方法,或将知识图谱中的三元组整合为整段文本信息来辅助回答问题,或使用不同方式获取需要被查询的实体和关系,查询到的三元组中的尾实体即为问题的最终答案。关于VQA技术,大多数研究着重采用深度学习的方式,进行大量图像和文本的特征提取训练,提高所提取特征的准确率,进而获得更准确的答案。这种方式对于回答“What color is this T-shirt?”“What animal is in the picture?”这类问题准确率较高,但并不适用于回答“What is the material of the shoes?”等类问题,而采用基于知识图谱的方式可以较为准确地回答第2类问题。
定义1 简单问题。问题答案存在于图像信息之中,可通过对图像的直观描述获取答案。
定义2 推理性问题。问题答案仅靠图像中的信息无法获取,需要借助外部知识获取答案。
目前的VQA模型只能在一类问题上获得较高的准确率,但在另一类问题上回答的准确率较低。为了扩大可回答的问题类型,本文设计了一种知识图谱辅助下的视觉问答方法K-VQA,在基于深度学习VQA的基础上,通过查询知识图谱,既能回答简单问题也能回答推理性问题,并能获得较高的准确率。
1 VQA方法
1.1 基于深度学习的VQA方法
基于深度学习的视觉问答系统现有架构大多数为多模态双线性框架,此类视觉问答系统的设计方法最早由MALINOWSKI等[5]提出。基于深度学习的视觉问答系统处理过程大体分为4步:1)提取图像信息特征并进行向量表示,一般采用卷积神经网络(convolutional neural networks, CNN)[6-8]、长短期记忆网络(long short-term memory, LSTM)[9]、VGG Net[10]、ResNet-152[11]等;2)处理自然语言文本并进行特征向量表示,一般采用词袋、LSTM[6-9]、门控循环单元(gated recurrent unit, GRU)[12]等;3)采用不同算法将知识特征向量进行融合;4)得到的特征向量经全连接层和Softmax层后得到最终答案。其中对于多模态知识的融合是双线性VQA架构中的关键步骤。
VQA多模态知识融合比较简单的方法是简单元素乘法结合方式[5]。此外还包含FUKUI等[6]提出的MCB(multimodal compact bilinear pooling)方法、KIM等[7]提出的MLB(multimodal low-rank bilinear attention networks)方法、YU等[8]提出的MFH(multi-modal factorized high-order pooling approach)多模态融合方法和BEN-YOUNES等[13]提出的MUTAN方法。虽然基于深度学习的VQA已获得了较高的准确率,但依旧存在一些不足:一是不能较准确地回答推理性问题,二是其向量融合机制和最终答案的获取具有不可解释性。为了准确回答推理性问题,产生了基于知识图谱的方法。
1.2 基于知识图谱的VQA方法
随着知识图谱的出现和完善,越来越多的自然语言处理问题采用语义解析的方式,结合现有知识图谱进行翻译和问答。现有的基于知识图谱的VQA系统并不多,知识图谱在其中起到的主导地位也不同。WU等[14]对知识图谱的使用只是增加了数据源;WANG等[15]提出Ahab方法,将提取出的图像信息整合为三元组形式,从知识图谱中查询出与图像信息相关的所有三元组,将这两部分三元组整合为“推理链”,通过这条推理链推理出答案;WANG等[16]对Ahab方法进行了改进,提出了FVQA(fact-based visual question answering)方法,可以回答更多的开放性问题。基于知识图谱的VQA方法依旧存在不足,首先是不能较准确回答简单问题;其次,将知识图谱三元组扩充为描述文本增加回答问题依据,依旧采用深度学习的方式,使得推理性问题的回答不具备可解释性,并且Ahab方法只对回答实体间相似性的问题有效,局限性过大。
基于以上研究工作,本文利用知识图谱和深度学习的知识,设计了K-VQA方法,在保证回答简单问题较高准确率的基础上,也可准确地回答推理性问题,并且可以回答更多类型的推理性问题。
2 K-VQA方法
2.1 问题定义与方法概述
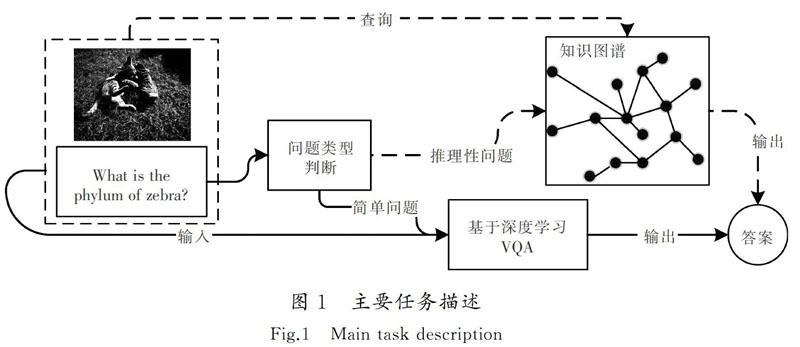
为了使视觉问答系统可以较准确地回答简单问题和推理性问题,本文在深度学习VQA的基础上,使用知识图谱进行辅助,如图1所示。通过对问题类型的判断,选择是否借助知识图谱进行回答,并将推理性问题进一步分类,通过判断问题文本单词词性是否包含明确的实体确定其在三元组中的属性,采用不同方式查询知识图谱。其中如何回答推理性问题,以及怎样查询知识图谱是本文的核心任务。
定义3 可直接查询问题(directly answerable question,DQ)。DQ文本中包含明确的需要被查询的实体,通过此实体可以直接查询知识图谱,获得相关三元组,并得到最终答案。
定义4 不可直接查询问题(not directly answerable question, N-DQ)。N-DQ中不包含明确的实体,一般采用“what animal”“what thing”等短语代替实体,无法直接查询知识图谱,需要借助在图像中识别出的实体,将问题转换为可直接查询问题,进而查询知识图谱。
K-VQA方法的目的是通过借助知识图谱,增加基于深度学习VQA可回答问题的类型,并增加可回答推理性问题的种类。方法概述如图2所示。通过文本分类将问题分为简单问题和推理性问题,将问题类型进行判定以后,方法分为以下3条路线。
路线1:回答简单问题。现阶段回答简单问题的最优方法即深度学习的方法,因此,本文对简单问题采用该方法进行回答。将图像和问题文本分别通过深度学习模型提取出特征向量,之后进行特征融合并最终输出答案。
路线2:回答推理性问题DQ。此类问题可以直接提取出文本中的实体和属性,采用三元组“实体-属性-值”,通过提取出的实体和属性查询知识图谱获得三元组中的值,即答案。
路线3:回答推理性问题N-DQ。这种推理性问题需要借助图像中的实体,首先对图像进行目标检测,然后查询知识图谱,判断与问题有关联的实体,进而明确实体,通过查询到的图像实体和问题文本中提取的属性查询知识图谱,最终获得答案。
2.2 问题类别判定
为了提高问题分类的准确率,采用基于Boosting算法的深度学习文本分类器对问题进行文本二分类。创建多个推理性问题,结合VQA数据集中的简单问题,将问题文本手动标记为S(simple,简单)和R(reasoning,推理)2种标签,将Boosting分类器在已标记好标签的问题上进行训练,使用训练后的最优模型实现对简单问题和推理性问题的分类。如图3所示,将问题输入到Boosting分类器后进行分类,其中前2个问题分类结果为R,即推理性问题,通过查询知识图谱获得答案;第3个问题判定为S(简单)问题,通过深度学习VQA获得问题答案。
由于VQA数据集中涵盖大量的简单问题,动物领域数据集AR-KVQA中涵盖丰富的关于动物类别的不同问题样式,因此目前K-VQA可以回答大部分简单问题和关于动物类别的推理性问题。
2.3 简单问题VQA处理方法
FaceBook在2018年发布了基于PyTorch的Pythia[17]深度学习框架,用来处理视觉和语言任务,并构建了深度学习视觉问答模型Pythia。此框架现已实现Pythia和LoRRA等模型,支持vqa,vizwiz,textvqa等数据集,且Pythia模型表现最为优异。仅使用训练集,准确率可达66.70%;使用训练集和验证集,准确率可达68.31%。本文基于深度学习的VQA模型采用Pythia模型,Pythia模型以bottom-up top-down(up-down)[18]模型为基础并稍作改動,特征融合采用元素乘法代替特征串联。
基于深度学习的VQA图像和问题都采用深度学习模型进行特征提取,再采用不同算法进行特征融合,最终输出答案。如图4所示,Pythia模型中图像和文本分别通过深度学习模型Faster-RCNN模型和GRU模型进行特征提取,分别输出特征向量后,将2种特征向量采用元素乘法进行融合,融合后的特征通过全连接层和Softmax层后得到答案。
2.4 推理性问题VQA处理方法
当问题需要借助知识图谱进行回答时,图像处理采用目标检测准确率较高的mask-RCNN方法[19],该方法采用MS COCO数据集,可以实现分类、语义分割和目标检测等功能。本文利用目标检测功能,获取图片中的实体名称。首先将文本采用NLTK进行命名实体识别,输出单词词性,然后通过词性判断文本中的实体和属性。为了可以更准确地回答推理性问题,采用基于规则的方式设计回答推理性问题的方法。DQ和N-DQ分别包含特有关键词和短语,将DQ和N-DQ按照特定关键词进行区分,通过这些特定关键词抽取要被查询的实体和属性。
定义5 集合NK(not directly answerable question keywords)。该集合中包含N-DQ中特有的关键词。当问题中不包含需要被查询的明确实体时,问题中就会包含需要被查询实体的上位词,如 “animals”“plants”“things”等。
定义6 集合P(property)。该集合中包含三元组“实体-属性-值”中代表属性的关键词,如“phylum”“class”“order”“material”等。
定义7 集合U(useless)。该集合中包含的关键词属于无用单词,该类单词为文本中既不是需要被查询的实体,也不是属性的名词,会干扰对实体和属性的抽取,如“belong”“picture”等。
由于判断DQ和N-DQ的关键词词性均为NN(名词)和NNS(名词复数),因此筛选出问题文本中词性为NN和NNS的单词。DQ和N-DQ采用NLTK识别出单词词性以后,分别采用不同的规则到知识图谱中进行查询,算法如图5所示。步骤如下:1)输入问题文本Q和集合NK,P,U;2)通过匹配关键词,判断问题中是否包含集合NK中的单词;3)若包含,则将其判断为N-DQ推理性问题,那么实体采用图像中的实体,属性采用问题所包含的P集合中的关键词,最终输出图像实体和属性;4)如果问题中不包含集合NK中的单词,则将其判断为DQ推理性问题,然后删除问题文本中所包含的集合U中的单词和集合P中的单词,剩下的名词则为实体,属性采用问题所包含的P集合中的关键词,最后输出文本实体和属性。
在文献[14]中,知识图谱作为其中一个数据源,推理性问题采用深度学习算法进行回答,最终答案的获取依旧具有不可解释性。在文献[15]和文献[16]中,提出的算法采用基于模板的方法,对推理性问题的回答具有可解释性,但其涉及的推理性问题大多为列举2个实体间相同的特点,对于属性的界定很模糊,并且对于实体的确定有时会基于模板中实体所处的位置,并不准确。本文提出的算法可获得明确的实体和属性,从而更准确地回答推理性问题。
图6中展示了DQ和N-DQ两种问题的处理方法。问题文本“What phylum do the animals in the picture belong to?”中的名词包括“phylum”“animals”“picture”“belong”,其中“animals”为集合NK中的关键词,因此将该问题判断为N-DQ,需借助图像实体。图像通过深度学习模型Mask-RCNN识别出实体为“cat”,按照三元组“实体-属性-值”的方式,通过此实体名称和问题中所包含的集合P中的属性名词“phylum”,查询知识图谱并输出三元组中的值,即答案。
“What phylum do cats belong to?”中名词包括“phylum”和“cats”,不包含集合NK和集合U中的关键词,判定为DQ,因此将集合P中的关键词“phylum”删掉后剩下的即为实体“cat”,按照三元组“实体-属性-值”的方式,通过实体名词和属性关键词“phylum”,查询知识图谱并输出三元组中的值,即答案。
图6中分别说明了DQ和N-DQ对2个问题模板的回答方法。但由于问题模板数量有限,因此为了扩大可回答推理性问题的范围,本文将模板进行问题拓展。一个问题模板可以拓展为多种类型的问题,不同的问题可以通过匹配同类型的模板进行回答,如图7所示。其中“$e”指代实体,“$e1”“$e2”指代不同实体。模板“What phylum do $e belong to?”可以拓展为“Do $e1 and $e2 belong to the same phylum?”等不同问题形式。这些拓展问题采用NLTK识别出词性为名词的单词,使用名词与模板进行匹配,通过模板查询知识图谱,进而输出答案。当这些名词匹配到多个模板时,将多个模板的答案一并输出。
图8展示的为匹配模板流程图。输入模板和通过NLTK识别出的名词,将名词按顺序在模板中进行关键词查找。由于模板中仅包含一个实体和一个属性,因此只需匹配到同时包含2个名词的模板即可。匹配模板步骤如下。1)输入模板和名词n—名词m。2)首先匹配名词n,若有模板包含名词n,则筛选出这部分模板,继续匹配名词(n+1);若不包含名词n,则查询模板中是否包含名词(n+1),以此类推,直到名词n=名词(m-1)。3)删除已经匹配到的模板,防止同一模板被重复匹配。4)最终筛选出的模板中若包含名词(n+1),则输出同时包含2个名词的模板;若不包含名词(n+1),则继续匹配名词(n+2),以此类推,直到匹配至名词m。5)若匹配至名词m后依旧没有匹配到2个名词,说明该名词无法匹配到模板,则名词n=名词(n+1),并返回步骤2。
2.5 查詢知识图谱
当问题为推理性问题时,需要借助知识图谱进行回答。DBpedia数据来源范围广,包含实体信息多,因此本文选用此知识图谱。如何从图像中正确筛选出需要的实体,如何得到推理性问题的最终答案,都需要通过查询知识图谱得到结果。
N-DQ问题需要借助图像中的实体进行回答,但是图像中并不只存在一个实体,因此对图像实体进行判别。本文采用查询知识图谱的方式,步骤如下:1)通过深度学习模型对图像进行目标检测;2)确定问题领域,集合NK中包含被查询实体中的上位词,即代表领域的关键词,因此通过识别问题文本中所包含的集合NK中的关键词来判断问题领域;3)将检测到的实体和属性“type”输入到知识图谱中,查询实体是否为需要的实体;4)得到需要的实体后,即可获得N-DQ问题的答案。
如图9所示,首先通过Mask-RCNN模型识别出图像中“Cat”和“Shoe”2个实体,然后判断问题所属领域,问题文本中包含NK中的关键词“animals”,因此判断问题属动物领域,之后通过图像识别出的实体和关系“type”到知识图谱中进行查询,“Cat”实体类型为“Animal”“Shoe”实体类型为“Thing”,因此“Cat”为需要被查询的实体,最后通过此实体名称和问题文本中所包含的集合P中的属性名词,到知识图谱中进行查询。
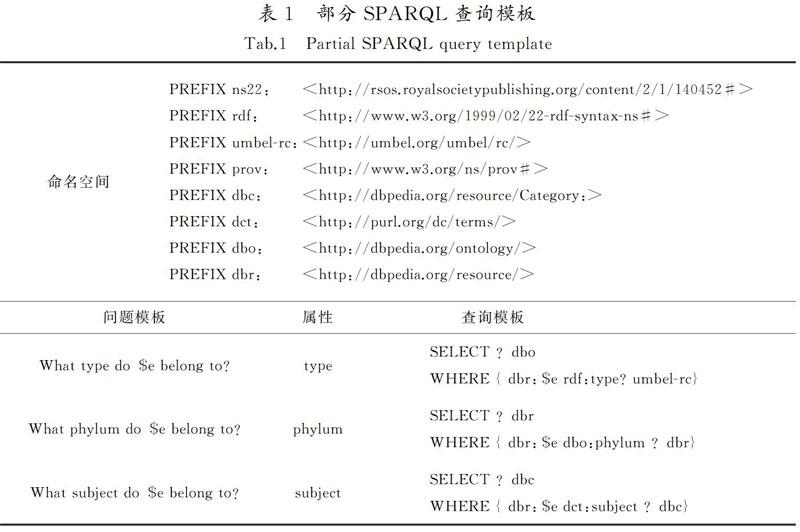
对知识图谱采用SPARQL查询,构成知识图谱的核心为三元组。本文采用“实体-属性-值”的三元组形式,通过实体和属性,查询知识图谱最终得到值,即答案。不同的问题模板对应着不同的SPARQL查询模板。部分查询模板如表1所示,表1中列举了部分命名空间。当查询图像中哪个实体是需要被用到的实体时,采用属性为“type”的查询模板,将“$e”替换为要被查询的实体后查询知识图谱。在回答推理性问题时,得到要被查询的实体和属性,找到属性对应的模板,将实体替换为被查询实体,最后到知识图谱中进行查询。
3 实验部分
在深度学习模型Pythia的基础上使用知识图谱进行辅助,增大Pythia模型可回答问题类型的范围,通过对數据集的问题类型进行区分,验证深度学习VQA方法和知识图谱VQA方法对不同问题类型的适用性。设置了一系列实验评估所提出方法的性能,将整个K-VQA分为2部分,一是深度学习模型Pythia,二是基于知识图谱的KB-VQA方法。KB-VQA方法即K-VQA中将问题借助知识图谱进行回答的部分。将Pythia,KB-VQA和K-VQA方法分别在不同数据集上进行实验。
3.1 数据集
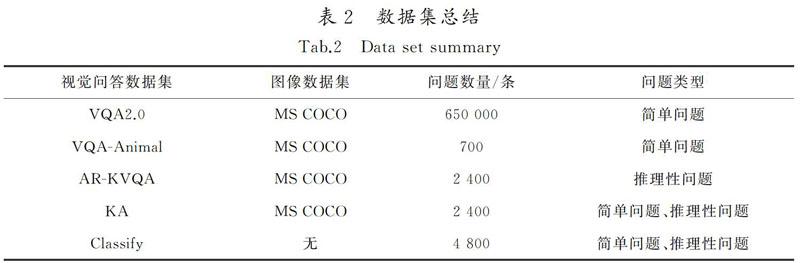
虽然存在包含大量推理性问题的数据集,但是KB-VQA[15]和FVQA[16]并未公开,而OK-VQA[20]中的问题大部分类型为“Which breed of dog is this?”,这些问题是无法通过查询知识图谱得到准确答案的,依旧需要对图像进行大量的训练。使用深度学习的方式获得图像中实体种类的准确答案,不适用于K-VQA的实验。本文建立了动物领域数据集AR-KVQA,从MS COCO动物领域图片中随机抽取800张,对每张图片随机提出3个问题,构成AR-KVQA数据集,答案为通过查询DBpedia知识图谱得到的简单词汇。AR-KVQA中共有8类问题,分别为动物的界、门、纲、目、科、属、种及化石范围类型的问题。将AR-KVQA数据集分为1 200条训练集、500条验证集和700条测试集。
VQA[21]数据集是覆盖图片最多、问题答案正确率最高的数据集。本文对简单类型问题数据集选用VQA2.0,通过动物名称关键词筛选出VQA2.0数据集中关于动物的问题。为了进行适用性任务实验和对K-VQA性能进行评估,设定了2个数据集:一是从VQA数据集筛选出的动物问题中随机抽取700条,形成VQA-Animal数据集;二是从VQA筛选出的动物问题中随机抽取1 200条数据集,从AR-KVQA中随机抽取1 200条数据集,形成一个既包含简单问题又包含推理性问题的KA数据集,该数据集包含2 400条数据,其中训练集1 200条,验证集200条,测试集700条。为了进行问题分类实验,设定了Classify数据集,该数据集由2部分组成,一是随机定义的2 400条与动物类别相关的推理性问题,二是从VQA2.0中随机抽取的2 400条动物领域的简单问题。数据集的信息总结如表2所示。
3.2 参数设置
为了使Pythia模型可以在AR-KVQA数据集上获得较高的准确率,将Pythia模型在AR-KVQA训练集上进行训练,并设置不同的迭代次数,如图10所示。实验表明,迭代次数越高,准确率越高,当迭代次数达到200时,准确率达到最高。因此本文选择训练200次,既可以保证准确率也可以保证效率。
为了使Pythia模型可以在KA数据集上获得较高的准确率,将Pythia模型在KA训练集上进行训练,并设置不同的迭代次数,如图11所示。实验表明,训练到200次时准确率最高。
K-VQA的性能受文本分类、深度学习VQA及知识图谱的影响,其中深度学习VQA已选择了表现优异的Pythia模型,对于查询知识图谱本文也规定了方法。为了使K-VQA性能更优异,文本分类的准确率不能过低,这个临界值受模型Pythia和KB-VQA的影响。在不考虑简单问题和推理性问题判断正确个数差异,即将2类问题判断正确个数平分的情况下,形成了式(1)。将问题数量N乘以文本分类准确率TA的值平分,分别作为简单问题和推理性问题分类的正确数量,并以Pythia模型完全无法回答推理性问题,以及KB-VQA模型无法回答简单问题为前提。分类正确的问题数量分别乘以Pythia准确率PA和KB-VQA准确率KVA,再除以问题数量N,若这个值分别大于模型Pythia和KB-VQA在KA数据集上的准确率PKA和KVKA,则证明K-VQA的性能更加优异。
通过式(1)的推导,TA的临界值如式(2)所示,将数据带入到式(2)中,粗略得到问题文本分类准确率TA不得低于72.96%。
3.3 问题分类任务
将问题文本分为S(简单)问题和R(推理性)问题2大类,以区分问题是否需要借助知识图谱进行回答。分类器采用Boosting算法,将Classify数据集作为训练集,分类器在Classify数据集上进行分类训练。
1)评价标准
选取训练结果最优时的模型作为最终进行问题判别的模型。
2)结果及结论
文本二分类已经非常成熟,采用Boosting算法进行分类训练的准确率可达到100%,将模型在KA数据集的测试集上进行测试,实验结果如表3所示。结果表明,采用此模型可以达到文本分类准确率的最低要求并且远远高于临界值,相较于推理性问题,简单问题文本分类的准确程度更高。
3.4 适用性任务
视觉问答领域较多采用深度学习的方式,且其常用数据集为VQA,可获得较高的准确率。VQA数据集中关于动物领域的问题主要围绕动物的种类、位置、动作及状态提问,多为简单类型问题。基于知识图谱的VQA方法一般采用FVQA等包含大量推理性问题的数据集。为了验证不同模型所适应的不同问题类型,以及不同类型数据集对不同模型的影响程度,将深度学习模型Pythia和KB-VQA模型在动物领域简单问题数据集VQA-Animal、推理性问题数据集AR-KVQA上进行实验。
1)评价标准
采用人工方式判断最终答案准确与否。在VQA数据集的动物领域中,包含很多无法回答的问题,例如“Is this a female cat?”“Dose the elephant look sad?”等判断动物性别和情绪的问题,以及询问动物之前或以后准备做的事情的问题,Pythia模型会随机选择答案来回答,这些问题无论是在基于深度学习VQA还是在基于知识图谱的VQA中都无法得到回答,因此此类问题是单纯靠图像无法回答的问题,应直接将其归纳为回答错误的问题。
2)结果及结论
表4为深度学习模型Pythia在AR-KVQA数据集以及VQA-Animal数据集上的准确率。由表4可以看出,由于將所有关于动物情绪和性别、年龄的问题都判断为错误,因此模型在VQA-Animal上的准确率要低于68.31%。Pythia模型在AR-KVQA数据集上的准确率明显低于在VQA-Animal数据集上的准确率,说明深度学习VQA模型不适合回答需借助外部知识回答的问题。
深度学习模型需要分别对图像和文本进行特征抽取训练才可提高准确率,若只训练其中一项,那模型整体的准确率将很低。由于AR-KVQA数据集中的问题需要借助外部知识回答,图像信息除实体以外基本没有帮助,即便Pythia在AR-KVQA数据集上已进行训练,但几乎只有文本特征可以发挥作用,因此Pythia在AR-KVQA数据集上的准确率要远远低于在简单问题数据集上的准确率。
为了进一步印证不同模型与不同数据集之间的影响,将KB-VQA在AR-KVQA数据集和VQA-Animal数据集上进行测试,结果如表5所示。由于KB-VQA方法对于无法回答的问题答案全部为No,因此虽然简单问题在知识图谱中查询不到结果,但是简单问题存在一部分答案为Yes/No的问题,因此在KB-VQA方法上VQA-Animal数据集仍有部分问题被
答对,但准确率远远低于AR-KVQA数据集。表5中KB-VQA模型在AR-KVQA数据集上的准确率明显大于在VQA-Animal数据集上的准确率,说明KB-VQA模型不适合回答可直接从图像中获取信息的问题,但适用于回答需借助外部知识回答的问题。KB-VQA在AR-KVQA数据集上的准确率达到64.88%,说明本文针对推理性问题提出的方法可以较准确地回答该类问题。
3.5 K-VQA性能评估
为了判定本文所提出的K-VQA方法既可以有效回答简单问题又可以回答推理性问题,并获得较高准确率,将深度学习模型Pythia,KB-VQA及K-VQA分别在KA数据集上进行实验。
1)评价标准
视觉问答的评价标准一般包括准确率和MALINOWSKI等[5]提出的WUPS评价标准,该标准基于WUP[22]标准来计算输出答案和标准答案之间的语义误差。WUPS标准适用于答案获取存在一定随机性的视觉问答,本文中推理性问题答案是固定的,该标准对本文的系统并不适用,因此采用准确率对本文的K-VQA方法进行评估。如果K-VQA方法在KA数据集上的准确率比Pythia和KB-VQA模型更高,则证明本文所提出的方法相比于Pythia和KB-VQA方法可以回答更多类型的问题。
2)结果及结论
结果如表6所示。深度学习模型Pythia在KA数据集上的准确率相较于KB-VQA要高一些,这是由于Pythia在推理性问题上的准确率比KB-VQA在简单问题上的准确率高。K-VQA在数据集上的准确率要明显高于Pythia模型和KB-VQA模型。由于问题分类中推理性问题判断准确率较低,导致一部分推理性问题采用Pythia回答,所以推理性问题的准确率较低。实验结果表明,K-VQA能回答更多类型的问题,并且能获得较高的准确率。
3.6 效果展示
本文提出了K-VQA方法,借助处理图像及文本的深度学习模型、相关知识图谱和查询语句相关知识,在深度学习VQA模型的基础上采用知识图谱进行辅助,可以回答更多类型的问题并获得较高的准确率。图12展示了问题分别使用Pythia,KB-VQA及K-VQA时输出的答案。图12中简单问题若在Pythia中答对,则在K-VQA中一般也可以答对;若推理性问题在KB-VQA中答对,那么在K-VQA中也有较大几率可以回答正确;若问题在Pythia或KB-VQA中都无法回答正确,那么K-VQA也无法回答正确。
4 结 论
1)设计了一种知识图谱辅助下的视觉问答K-VQA方法,既可以回答简单问题又可以回答推理性问题。通过分类器对问题类型进行判断,简单问题运用深度学习VQA进行回答,推理性问题借助知识图谱进行回答,提高了回答问题的准确率。
2)将深度学习的VQA模型Pythia、基于知识图谱的VQA模型KB-VQA以及K-VQA,分别在包含简单问题和动物类型的推理性问题数据集上进行实验。结果表明,本文提出的K-VQA方法表现更优异,准确率达到56.67%。
3)创建了知识图谱视觉问答数据集AR-KVQA,包含关于动物类别的多种问题样式,可以回答大多数关于动物的简单问题和关于动物类型的推理性问题,准确率较高。该数据集可以拓展延伸到植物领域,如“What is the phylum of pine?”等,也可以拓展延伸到其他物体,如“What materials of the shoes?”等。
本文提出的视觉问答方法可以回答符合模板的问题以及与模板相关的问题,虽具有一定的局限性,但对于回答问题的准确率有一定的保障,并且随着模板数量的增加,可回答问题的数量也将成倍增加。但是,由于实体名称的差异,以及知识图谱的单一性,导致部分推理性问题不能在知识图谱中查询到答案。因此,后期工作将扩大数据集,进一步增加模板数量,扩大可回答问题的范围,增加知识图谱,解决实体名称差异性问题,提高方法的适用性。
参考文献/Reference:
[1] AUER S, BIZER C, KOBILAROV G, et al. DBpedia: A nucleus for a web of open data[C]//
Asian Semantic Web Conference.Busan Korea:DBLP,2007:722-735.
