基于改进YOLOv2 的电力标志牌检测∗
2022-03-18孙玉玮马青山
孙玉玮 傅 靖 马青山 张 斌
(1.国网江苏省电力有限公司南通供电分公司 南通 226006)(2.南通华远科技发展有限公司 南通 226007)
1 引言
近年来,随着经济发展,社会对电力的需求越来越高。为了推动电网智能化发展,基于图像处理技术的电力作业管控平台[1]逐渐被应用于电力巡检工作中。其中,电力安全标志牌检测可以传达警告和操作提示等信息[2],是电力作业管控平台的重要内容。
电力场景中的安全标志牌通常有显著的颜色、图形或文字等特征[3]。传统的标志牌检测算法主要是根据颜色、形状和边缘等特征进行设计[4]。此类特征一般受限于数据集的数量与固定的特征结构,易受环境影响,尤其在光照不均或存在遮挡的情况下难以识别[5]。相反,基于深度学习的目标检测方法在大量训练集上进行反复迭代,自动学习图像特征信息。在深度网络中,浅层网络提取到纹理和颜色等特征,而深层网络抽取带有语义信息的高维度特征。多层次的特征使得深度学习方法具有较强的鲁棒性。深度学习在电力行业中有着广泛应用,如电力开关的状态识别和输电线路部件识别与缺陷检测[6]。本文主要将深度学习技术应用到电力安全标志牌检测中,提高电力场景中安全标志牌检测精度。
基于深度卷积神经网络的目标检测算法大致可分两个研究方向[7]:两阶段目标检测网络和一阶段目标检测网络。更快速区域卷积神经网络Fast⁃er-RCNN[8]是两阶段目标检测网络中具有代表性的检测网络,通过两个分支分别实现目标的分类识别与检测定位。Faster-RCNN 检测效果较好,但网络结构复杂且耗时高。一阶段目标检测网络主要有YOLO(You Only Look Once)系列[9]。与两阶段目标检测网络相比,一阶段目标检测网络仅使用一个分支实现目标的端对端检测与识别。一阶段目标检测网络结构较简单,且能更好地平衡检测速度和精度,在工程应用中更受欢迎。
YOLO 系列的目标检测网络有YOLOv1[9]、YO⁃LOv2[10]和YOLOv3[11]。YOLOv1网络中全连接层限制了图片尺寸且一个网格(Cell)只能得到一类物体的检测结果,在应用上有一定限制。YOLOv2 使用Darknet-19 作为基础网络,同时引入锚框(An⁃chor)机制。其中,每一个网格中锚框的类别相互独立,实现了每个网格的多类别输出。与YOLOv2相比,YOLOv3使用了更大的骨干网络Darknet-53,对多个尺度的特征层进行融合并在不同尺度的特征层上分别进行检测,增加了网络对于不同尺度目标的识别效果。另外,从数据角度看,深度卷积神经网络是一种数据驱动的算法。但是,在电力安全标志牌检测方面尚无公开的数据集,这成为深度学习检测电力安全标志牌的障碍。
为此,本文建立了针对电力安全标志牌检测的数据集。电力安全标志牌检测存在以下两个问题:1)算法实时性要求较高;2)电力标志牌几何特征变化不大,但尺寸较小、角度多样和容易被遮挡。YO⁃LOv3耗费计算资源较多,为了保证算法实时性,本文使用YOLOv2作为基础网络。为了解决标志牌尺寸小等难题,在原始YOLOv2 网络中引入SegNet[12]的索引池化(Index Pooling)结构以恢复精准的特征信息,从而提高电力安全标志牌的检测精度。
2 基于索引池化的YOLOv2
2.1 YOLO_IP
在YOLOv2 网络结构中,输入的图片经过一系列卷积后得到32 倍下采样的特征图。将下采样后的特征图映射到输入图像,不同映射单元的特征用来预测此单元内的目标。尽管每个特征点都设置了一系列长宽比不同的锚框以适应不同尺度形状的目标,但下采样步长过大会导致锚框尺度难以覆盖到小目标。
本文通过提升特征图分辨率和增加输入图像对应的锚框密度,提高对小目标的覆盖率。同时,在上采用的过程中使用索引池化技术以精准恢复特征信息。改进后的YOLOv2 命名为YOLO_IP(YOLO Index Pooling)。图1 显示了YOLO_IP 的网络结构,梯形表示基础网络Darknet-19,平行四边形为特征图,虚线框为池化掩码。Darknet-19 最后输出的特征图结合池化掩码进行上采样,增加输出特征层分辨率的同时限制上采样过程中非目标信息的引入。上采样后的特征图与相同大小的浅层特征进行融合,融合更多的上下文信息有助于目标位置的回归。
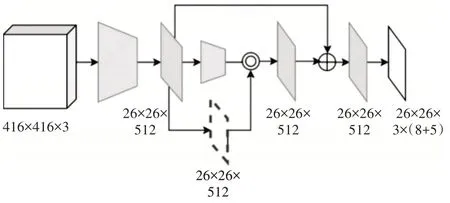
图1 网络结构,◎利用池化掩码上采样操作,⊕通道尺度上的拼接操作。
对于目标位置的预测,计算公式如式(1)~(4):
式中,(tx,ty,tw,th)为网络预测值对应于输出特征网格中心点的偏移与宽高,cx,cy为对应特征网格的索引坐标,(bx,by,bw,bh)为检测目标对应于输出特征的坐标,pw,ph为锚框相对于输出特征的宽高。sigmoid 函数限制当前预测框的中心不会超出当前单元中心而偏移到相邻单元。
2.2 锚框密度分析
在YOLOv2 网络中,预测层特征分辨率较低,对应输入图像的锚框密度较小,锚框中心与目标中心距离较远。网络需要学习到较大偏移量去拟合目标位置,增加了网络对目标学习的难度。为此,可以通过增加预测层特征图尺寸,以增加输入图像上锚框密度,减少锚框与目标位置之间的距离。
如图2 中(a)和(b)所示,圆点表示锚框对应到输入图像中的位置,星形为目标框中心位置。图2(a)和图2(b)左侧显示了锚框映射到输入图像的分布密度,图(a)和图(b)右侧显示了锚框与目标框的相对位置。图(a)中由于下采样步长过大,锚框密度过低,导致目标框中心位置距离最近的锚框中心较远,网络学习困难。图(b)比图(a)的锚框密度高。对于相同的目标框,图(b)中锚框能够更好地覆盖目标,减少目标框位置与锚框之间的偏移距离,减轻网络对目标的学习难度。
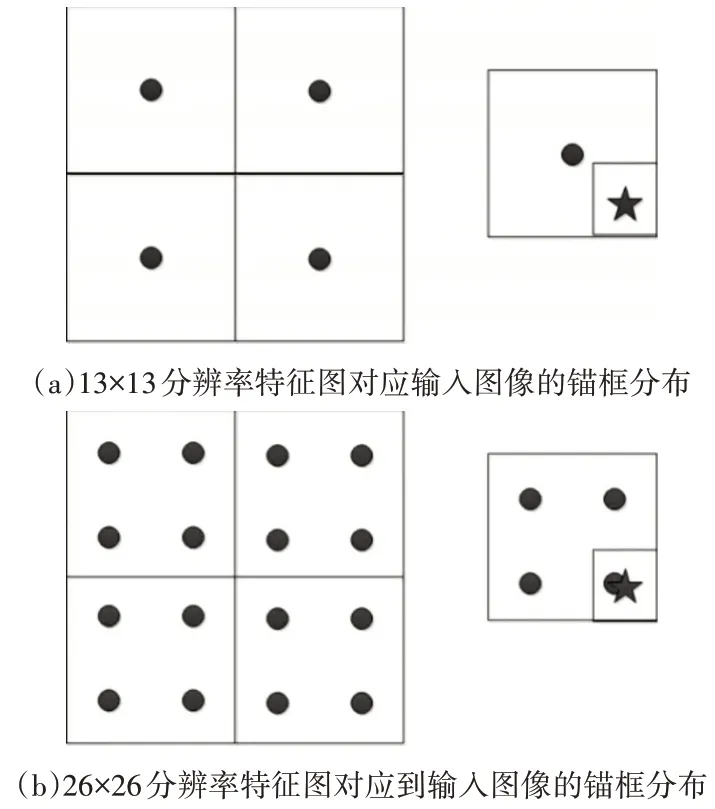
图2 两种分辨率特征图对应输入图像锚框密度对比
针对电力标志牌检测数据的检测,采集的图片样本分辨率为1920×1080。为防止网络训练过程中尺寸缩放导致的图像畸变,样本图片均按照其最长边以零像素值将分辨率补齐至1920×1920。其中,通过统计较小电力安全标志牌的区域,平均为60×60 像素大小,约占图像大小的1/(32×32)。YO⁃LOv2 最后的输出特征图中每一个特征点对应的区域占原始图像的1/(13×13),其比例远大于电力安全标志牌所占比例。
YOLO_IP 网络输入尺寸为416×416,对应的检测层特征尺寸为26×26。每个特征点映射回原始图像的网格占原始图像的1/(26×26)。同时通过对电力安全标志牌数据集进行尺度聚类,得到三种锚框尺寸:(0.57,0.67)、(1.87,2.06)和(3.33,5.47)。三种锚框分别对应特征图尺寸(Feature Size)、输入尺寸(Input Size)与原图尺寸(Image Size)见表1。
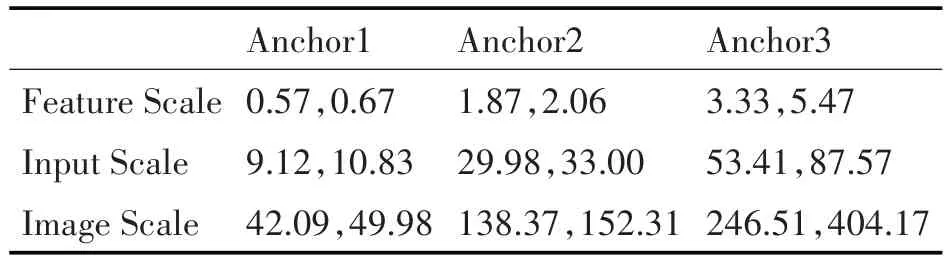
表1 表锚框与原图对应尺寸
最小尺寸的锚框对应到原图尺寸为42.09×49.98 能够覆盖到较小的标志牌区域,有利于训练初期网络的召回率提升,从而增加训练速度。
2.3 索引池化
YOLO_IP需要较高预测框密度,因此需要提高输出层特征图分辨率。直接使用浅层高分辨率的特征图的方法会丢失网络深层的语义信息[13],而直接通过对深层特征进行插值上采样方法增加特征图尺寸会无差别地将特征复制到邻近位置,容易引入误差。
为此,本文采用索引池化技术恢复深层特征分辨率,精准地恢复深层语义信息在高分辨率特征图中的位置,减少误差引入。索引池化技术首次出现在语义分割网络SegNet 中。SegNet 使用索引池化恢复特征图的编码信息。具体地,在解码阶段根据编码阶段记录的索引恢复相应位置的值,从而达到更好更精细的语义分割效果。
如图3所示,4×4大小的特征图经过索引池化,得到2×2 大小的特征图,同时保存了最大值对应的位置掩码(Index Mask)。另外,对2×2 的特征图进行上采样(Index Upsample),结合最大值位置将特征图结果从2×2大小恢复到4×4大小。
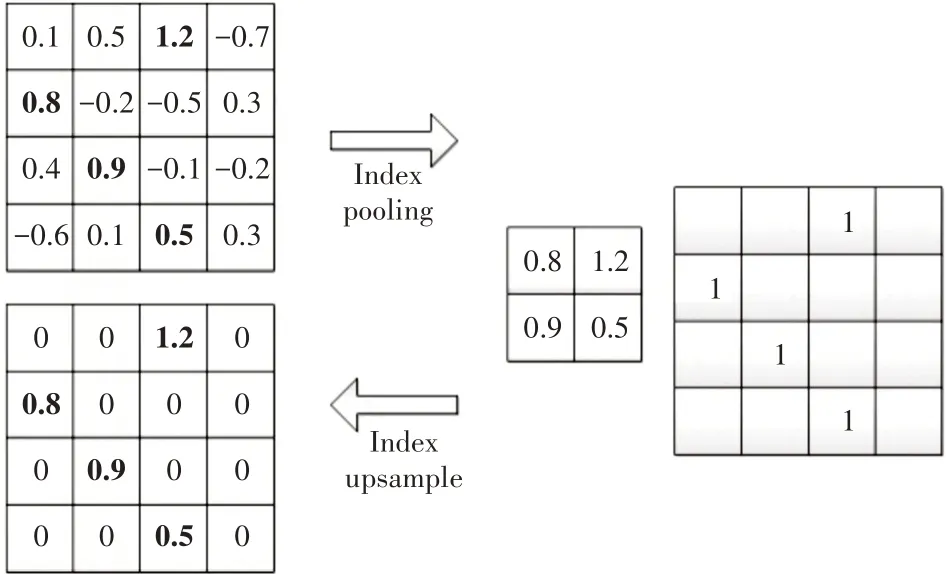
图3 索引池化
索引池化保留了最大值对应的位置掩码信息,可用来精准恢复高分辨率特征图中的特征信息。在YOLO_IP 中使用索引池化恢复深层特征分辨率,限制了非激活位置信息的引入,从而突出目标位置的特征信息,提升网络对目标分类识别的准确度。
2.4 损失函数
训练所使用的损失函数如式(5):
式(5)中K为预测层特征图尺寸,M为先验框个数,C为类别数。
式(7)中在真实标注对应网格处计算预测框的坐标损失,分为中心点偏移损失与宽高损失。其中diffx,diffy为真实标注中心与其所在网格中心之间的偏移量,predx,predy为网络在网格处预测得到的预测框中心与该网格中心之间的偏移量。anchorw,anchorh为先验框宽高,w,h为真实标注的宽高,使用(2-w*h)平衡检测框尺寸。
式(8)使用sigmoid 交叉熵损失计算真实标注对应网格处类别损失,̂为类别标签,c为网络预测值。
scaleiou、scalecoord和sacleclass用来控制损失各组成部分的权重,均设置为1。
3 数据处理与实验
3.1 数据划分
电力安全标志牌多分布于电力场景中,数据采集困难且危险系数高。目前尚无开源的电力安全标志牌检测的检测数据集。因此,本文使用监控摄像头采集变电站中含有电力安全标志牌的视频数据,挑选常见的8 种电力安全标志牌,自制一个电力安全标志牌检测数据集(Electricity Safety Sign 8,ESS8),如图4所示。

图4 电力安全标志牌示例图
通过对摄像头采集到的视频数据进行抽帧和筛选,最终得到5000 张含有安全标志牌的图像,分辨率为1920×1080。对其进行人工标注,同时采用旋转和镜像的方式增强数据。最终得到12000 张增强数据,其中10000 张作为训练集,2000 张作为测试集。
3.2 实验分析
实验中所使用的硬件包括显卡GTX 1080 Ti、Intel(R)Xeon(R)CPU 和251G 内存。所使用的系统为Ubuntu16.04,深度学习框架使用Caffe。
为验证索引池化结构的有效性,增加了对比网络YOLOv2_26×26,其通过简单上采样方式将预测层特征分辨率提升至26×26。使用相同数据集对YOLOv2、YOLO_IP 和YOLOv2_26×26 进行训练与测试。三个网络均使用随机梯度下降法(Stochas⁃tic Gradient Descent,SGD)优化策略进行优化,基础学习率设置为0.0001,进行60000 次迭代,每次迭代的Batch Size设置为3。
网络召回率和网络损失分别如图5和图6。图5 反应了网络锚框对正样本的召回率,计算公式如式(9):
其中,TP为正确检测到的正样本个数,FN为错误检测到的负样本个数。当预测框与真实框的交并比大于0.5时判断为正样本,否则为负样本。
由图5 可知,YOLO_IP 与YOLOv2_26×26 的初始召回率都较原始YOLOv2 高。因此,使用更大分辨率的特征图增加了锚框命中目标位置的概率。但YOLOv2_26×26 提升预测层分辨率的同时引入过多无关信息,使得网络波动较大。
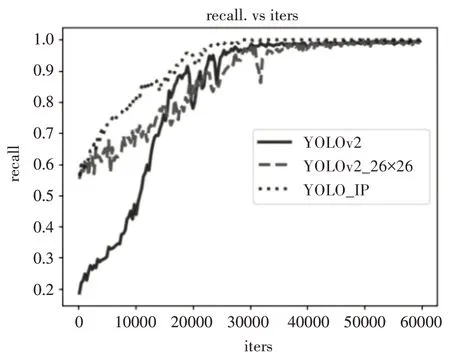
图5 网络召回率
图6 为训练过程中三个网络的损失曲线。经过60000次迭代训练,三个网络能够收敛,其中YO⁃LO_IP收敛最快。

图6 网络损失
使用测试集对三个网络进行评估,计算8 个类别的平均精准度均值mAP[14]式,如式(10)所示:
其中c为类别个数,i表示类别的索引,平均精度(Average Precision,AP)为每个类别的平均精准度。本文使用mAP作为检测结果的评价指标。
表2 为各个网络在标志牌检测数据集上的对比。YOLOv2_26×26 的mAP 较原始YOLOv2 高0.4%,说明提升输出层分辨率有助于提高网络对安全标志牌的检测能力。YOLO_IP 较YOLOv2_26×26 的mAP 提高2.8%,表明了YOLO_IP 采用索引池化恢复高分辨率特征,能达到更好的检测效果。同时,与其他单阶段检测网络在本数据集上做了对比实验,如表3 所示。SSD[15]网络虽然使用了多层特征融合的方法,由于本文中数据集尺度差别较小,融合后反而消弱了最佳尺度的特征比重,表现较差。YOLOv3 使用三层特征检测输出,能够单独使用合适的尺度特征进行预测输出,其mAP 可以达到74.8%。与SSD 和YOLOv3 相比,YOLO_IP 的mAP最高。标志牌目标总体较小,而池化索引可以高效恢复高分辨率特征图中标志牌的特征信息,因此总体精度较高。
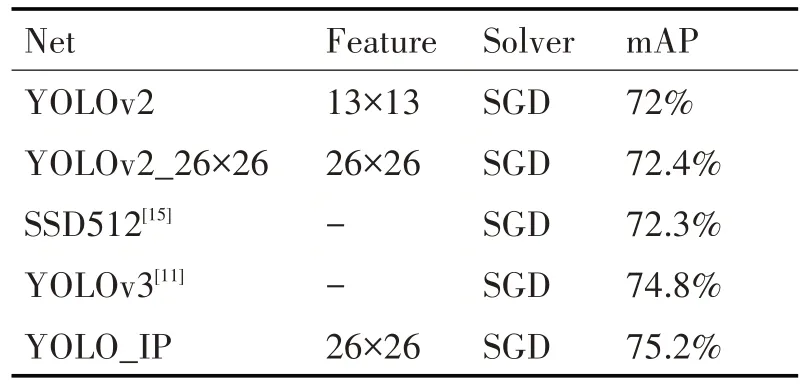
表2 网络对比
4 结语
为利用深度卷积神经网络解决复杂场景下电力安全标识检测的问题,本文构建了专用于电力安全标志牌检测的数据集ESS8,包含8个类别的安全标志牌数据。以YOLOv2 为基础网络,通过增加预测层特征图尺寸以增加输入图像上的锚框密度。另外,在原始YOLOv2 网络中增加索引池化机制,精准地恢复目标特征信息。实验表明,与原始网络相比,改进后的网络具有更强的标志牌检测能力。与同类检测方法相比,本方法可以在标志牌检测数据集上获得最高的平均精度均值,提升了智能电力安全作业系统的电力标志牌的检测识别能力,推动电力智能化,保障电力生产安全。未来的研究工作主要有三点:1)采集更多场景下的标志牌视频,提高数据集样本数量,帮助训练大的网络;2)结合人体姿态估计,实现精准报警;3)将索引池化机制应用到其他任务中,如绝缘手套检测、安全帽检测和电力安全带检测。
