改进的局部线性嵌入及其混成数据降维算法∗
2022-03-18马思远
马思远 贺 萍
(河北经贸大学信息技术学院 石家庄 050061)
1 引言
随着数据收集和数据存储功能技术的发展,高维数据的处理已经成为图像、视频、文本文档等许多领域的重要问题。通常情况下,高维数据集中存在大量不相关和冗余的特征,这增加了数据处理、知识挖掘和模式分类的难度[1~2]。而降维可以将高维数据投影到低维子空间,滤除一些噪声和冗余信息[3]。
主成分分析(PCA)是一种经典的非监督学习的机器学习算法,常用于解决数据降维、异常分析、算法加速和数据可视化等问题,已经广泛应用于图形分类、模式识别和机器视觉等领域;基于核的主成分分析是对主成分分析方法的一种线性推广,与PCA 相比,核PCA 具有有效获取数据的非线性特征、对原始空间中的数据分布情况无要求且计算复杂度基本没有增加等优点,这些特点使核PCA在诸多领域应用后取得了很好的效果。局部线性嵌入(LLE)是一种广泛使用的图像降维方法,可以学习任意维度的局部线性的低维流形,实现简单,计算量相对较小,可以保持数据局部的几何关系。
本文的创新点如下:1)对局部线性嵌入进行了改进,选择最短路径算法计算样本点间的距离,改进样本点的相似度量方式;2)使用改进的局部线性嵌入降维局部数据集,基于核的主成分分析降维整个数据集。在基准数据集上的实验表明,本文提出的方法在一定程度上提高了PCA 对平移的鲁棒性,表现出良好的分类性能。
2 相关工作
目前常用的降维方法可以分为两种类型,包括基于特征选择的方法[4~7]和基于特征变换的方法[8~10]。基于特征选择的降维方法是根据特定条件对原始特征进行排序,然后选择排名最高的特征以形成子集。其中,基于Fisher 评分[11]、基于信息获取[12]、基于互信息[13]和基于基尼系数[14]进行的特征选择方法是经典的特征选择方法。特征选择方法可以有效地去除不相关的特征,但原始集的潜在结构将可能被破坏[15]。基于特征变换的降维方法的本质是通过指定的变换函数将高维数据映射到低维空间,这种降维方法通常会保留要素之间的原始相对距离,并有助于覆盖原始数据的潜在结构,因此不会造成大量信息丢失。其中,主成分分析(Principle Component Analysis,PCA)[16]、局部线性嵌入(Local Linear Embedding,LLE)[17]、等距映射(Isometric Feature Mapping,Isomap)[18]、局部切空间排列(Local Tangent Space Alignment,LTSA)[19]、随机近邻嵌入(T-Distribution Stochastic Neighbour Embedding,t-SNE)[20]、拉普拉特映射(Laplacian Ei⁃genmap,LE)[21]是典型的基于特征变换的降维方法。
PCA算法是一种常用的降维算法,具有去除噪声、无参数限制、简化计算过程等优点。近年来提出了许多与PCA 结合提高数据分类性能的改进算法。Meng 等[15]利用聚类策略与混合运算相结合的方法,提出一种基于特征选择和分组特征提取的新型快速混合降维算法。该方法使用两种不同的特征选择方法删除不相关的特征,利用特征之间的冗余度将特征分组为一定数量的簇,使用PCA对簇进行提取保留有效特征,该方法不仅可以去除数据的无关信息和冗余信息,而且考虑了集合的潜在结构、数据大小和维度的多样性。为了解决判别分析(Linear Discriminant Analysis,LDA)小样本问题,一些研究者将PCA 与LDA 结合,首先使用PCA 提取特征,删除原始数据的空间,然后使用LDA 实现进一步的维数缩减[22],但此方法将降维过程分为两个独立的部分,忽略了PCA对LDA的影响。Zhao等[23]在此基础上提出了一种组合PCA 和LDA 的降维算法(JPCDA),用规则参数γ平衡PCA和LDA对模型的影响,使用正规化项提取对LDA 重要的有效信息,该方法不仅不需要考虑类内散布矩阵的奇异性,还解决了LDA的小样本问题。蓝雯飞等[24]为了降低数据集降维时间,提出了一种融合PCA和LLE的降维算法(PCA_LLE),既保留了数据的全局结构,同时保持高维的数据拓扑结构在低维中不变。
但PCA的缺陷在于其空间复杂度比较高[25],且不能应用于非线性降维。为了将PCA 成熟的思想更好地应用于非线性降维,且在一定程度上减少核PCA[26]的高计算复杂度,本文提出了一种基于LLE思想与核PCA 相结合的方法,在该算法中首先对LLE 进行了改进,使用最短路径算法计算两个样本点间的测地距离;在此基础上使用局部线性嵌入与核主成分分析(KPCA)混成的降维算法对数据集进行降维。最后在基准数据集上进行了算法性能对比,在Isolet 以及Yale 数据集上取得较好的实验效果。
3 基本概念
3.1 PCA算法
主成分分析又称主元分析、K-L 变换,它由Pearson于1931年首次提出。PCA 的基本思想是提取原始数据中的主元,减少数据冗余,使得数据可以在低维特征空间被处理,同时保持原始数据的绝大部分信息,从而解决高维数据存在的问题。
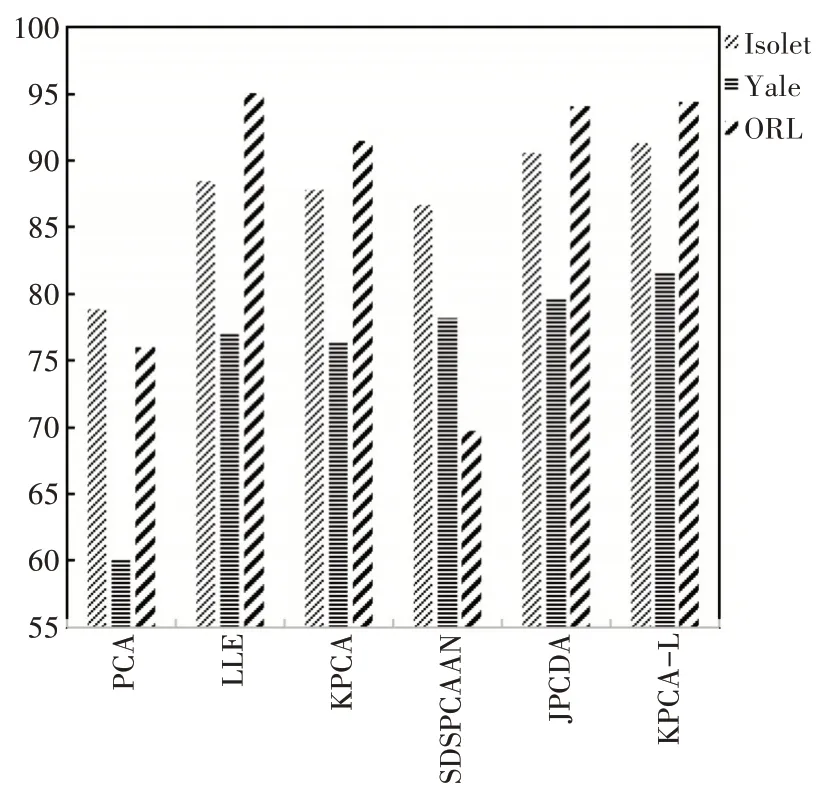
PCA是线性降维方法,该方法通过分析计算矩阵的特征值、特征向量,将n维特征映射到r(n 输入:数据集U为m个n维的样本u1,u2,…,um。 Step1:用U的每一维进行均值化,即减去这一维的均值。 Step2:用式(1)计算样本的协方差矩阵。 Step3:对矩阵C进行特征分解,求出协方差矩阵特征值λi及对应的特征向量qi。 Step4:将特征向量qi按对应特征值λi降序排列成矩阵,取前r行组成矩阵P。 输出:V=PTU,V为U降到r维后的数据。 为了缩小投影的误差,需要选取合适的r值,可用式(2)确定r值。 其中m表示特征的个数,式(2)中计算的是数据原始点与投影后的点的距离总和。εerror表示误差,误差越小说明保留的主成分越多,降维的效果越好。 核方法采用非线性映射将原始数据由数据空间映射到特征空间,进而在特征空间进行对应的线性操作。设xm和xn为数据空间中的样本点,数据空间到特征空间的映射函数为ψ,核方法的原理是实现向量的内积变换,如式(3)所示。 应用比较广泛的核函数有以下几种形式: 1)线性核函数 2)高斯径向基核函数(RBF) 3)多层感知器核函数(MLP) 4)P阶多项式核函数 核PCA是标准PCA 的一种核化形式,核PCA将数据投影到非线性函数的特征空间,可以实现输入空间到特征空间的转换,非线性主成分可以通过核函数进行定义,如线性核函数、径向基核函数、多层感知器核函数、以及P阶多项式核函数。因为径向基核函数有良好的可控性和代表性,所以它作为本文中核PCA的核函数,如式(8)所示。 其中σ2表示带宽参数,可以通过式(9)的取中值尺度估计公式计算。 传统的核PCA 算法的基本思想是通过核函数将低维空间中线性不可分的数据映射到更高维的空间中,使其在高维空间中线性可分。为了提高降维速度以及复杂度,KPCA-L 算法在原始数据映射之前首先对原始数据进行预处理,接着使用改进的LLE 方法对原始数据进行局部降维,再使用核PCA进行全局降维。 LLE 算法是一种局部特征保持算法,基本思想是假定高维观测空间中每个数据样本点与其邻近点位于流形的一个线性局部领域,则每个数据点可以由其领域中的近邻点线性表示,保持每个数据点与领域中的近邻点线性关系不变,将高维观测空间中的数据映射到低维空间中。设给定特征向量集合X={x1,x2,…,xN},xi∊RD,N代表特征向量个数,通过LLE 算法降维后得到输出向量Y={y1,y2,…,yN},yi∊Rd,其中d≪D。LLE 算法步骤如下。 步骤1:计算出每个特征向量xi的k个近邻点,选取距离每个特征向量xi最近的k个特征向量作为样本点xi的k个近邻点。 步骤2:计算重构权值矩阵,对于每个特征向量xi计算由k个近邻点得到的近邻权值矩阵,定义误差函数ε(w) ,如式(10)所示。 其中xj(j=1,2,…,k)是xi的k个 近 邻 点,wij(i=1,2,…,N;j=1,2,…,k)是xi和xj之间的权值且满足式。 矩阵化公式(10)需满足如下约束条件:当xj不是xi的近邻点时,wij=0;反之则。 对xi的k个近邻进行局部加权重建获得重构矩阵W,如式(11)~(12)。 其中为k×k矩阵,如式(13)。 步骤3:将图像所有的特征向量投影到低维空间中,使输出数据在低维空间中保持原有的结构。由特征向量xi的近邻局部重建权值矩阵和其近邻点特征向量,计算出特征向量xi在低维嵌入空间的输出向量yi,其中投影过程中使得代价函数ϕ(Y)达到最小,如式(14)所示。 其中yi是xi的输出向量,yi(j=1,2,…,k)是yi的k个近邻点,且 其中I是单位矩阵。 传统的LLE 方法中需要计算样本点之间的欧氏距离来查找k个近邻点,低维空间中使用欧氏距离计算简单,但高维空间中的复杂性会使欧氏距离作为两个样本点的相似度量不可靠[27],因此在此使用最短路径算法计算两个样本点的距离,从而改进传统的LLE方法。具体DLLE算法如算法1所示。 算法1 DLLE 输入:初始数据集X。输出:降维后数据集Y。 1)X={x1,x2,…,xN},xi∊RD×N;//输入数据集 2)Bellman-Ford(); //用最短路径算法计算样本点xi和xl之间距离 3)fori=1toN 7)end。 8)xi(j=1,2,…,k); //寻找每个样本点xi的k个近邻点 //计算重构权值矩阵W 10)M=(I-W)T(I-W); //计算半正定矩阵 11)calculate_value(M); //求解特征值和特征向量 12)Return Y; //Y为M矩阵第2 至第d+1 最小特征值对应的特征向量 13)end。 DLLE算法的详细描述如下: 步骤1:输入数据集X,用Bellman-Ford 算法计算样本点xi和xl之间的测地距离,按距离的升序排列。 步骤2:计算样本点xi和xl的非对称距离,寻找每个样本点xi的k个近邻点。 步骤3:计算重构权值矩阵W。 步骤4:计算半正定矩阵M,输出矩阵Y。 KPCA-L算法的详细描述如下: 步骤1:将数据集X按照4.2节中DLLE算法对数据进行降维预处理。 步骤2:降维后数据集Y进行核函数处理映射到高维空间,使数据线性可分,然后对矩阵进行去中心化处理,计算协方差矩阵,求解特征值与特征向量。 步骤3:将特征向量按特征值由大到小排列,保留前r个特征向量构成矩阵P,最后输出降维后的数据集V。 算法2 KPCA-L 输入:初始数据集X。 输出:降维后数据集V。 1)X={x1,x2,…,xN},xi∊RD×N;//输入数据集 2)DLLE(); //用DLLE对数据集进行预处理 //将数据集进行核函化 4)decentrate(); //在高维空间进行去中心化处理 6)calculatevalue(); //求解特征值与特征向量 7)calculater(); //计算非线性主成分 8)returnV; 9)end。 在本节中,本文提出的KPCA-L 算法将执行在3 个基准数据集上,通过与其他几种方法相比较,验证算法的有效性。 1)Isolet数据集 Isolet 数据集中包含来自30 个主题的1560 个样本,每个样本都有617个特征描述。 2)Yale数据集 Yale 数据集中包含15 个不同主题的165 张灰度面部图像。每个对象有11 张图像,这些图像具有不同的面部表情或配置:中心光,戴眼镜,快乐,左光,不戴眼镜,正常;右光,悲伤,困倦,惊讶和眨眼。 3)ORL数据集 ORL数据集中包括40个人的400张图像,每个人有10 张图像,这些图像是在不同的时间,不同的光线下拍摄,有各种面部表情,例如微笑或不笑,睁眼或闭眼等。 在此实验中所有图像都将降采样为32×32 的大小。每个数据集随机划分为一个训练集(60%)和一个测试集(40%),表1为样本的数据信息。 表1 样本数据信息 我们比较了五种不同维度降维方法的性能: 1)PCA[16],它是一种广泛使用的无监督降维方法,目的是找到低秩矩阵。当数据点位于高维空间中时,可以通过线性或非线性投影来获得数据的结构。 2)LLE[17],它是一种非线性降维方法,能够使降维后的数据较好地保持原有流行结构。 3)KPCA[26],它是一种非线性降维方法,解决PCA不能处理非线性数据的问题。 4)SDSPCAAN[28],它保留全局和局部数据结构,集成监督性稀疏PCA 和带有自适应的聚类投影。 5)JPCDA[23],它是一种PCA 联合LDA 的方法,避免小样本量问题。 6)KPCA-L,一种非线性降维方法,将LLE与核PCA 结合,降低算法复杂性,保持数据原有流行结构。 图1 显示了三个数据集上所有降维方法的分类精度结果。从图中可以看出与其他方法相比,在Isolet 数据集上KPCA-L 方法相对PCA、LLE、KP⁃CA、SDSPCAAN 和JPCDA 分 别 提 高 了12.49%、2.86%、3.52%、4.67%和0.77%;在Yale 数据集上相对于PCA、LLE、KPCA、SDSPCAAN 和JPCDA 分别提高了21.7%、4.56%、5.27%、3.47%和2.07%;在ORL 数据集上KPCA-L 方法相对PCA、KPCA、SD⁃SPCAAN 和JPCDA 分别提高了18.44%、2.94%、25.75%和0.38%。从图中可以看出本文所提出的方法的分类准确性有明显地提高,在Isolet 数据集上尤其明显。从图中可以看出KPCA-L 方法优于PCA 方法,因而LLE 和KPCA 的有效结合可提取出更具有代表性的特征。 图1 三个数据集上不同降维算法的分类准确性 高维数据降维一直是图像、视频、文本文档等领域研究的热点,本文将改进的LLE 与核PCA 结合,有效提取非线性特征,LLE 采用局部线性逼近非线性,保持了数据整体的几何性质。在基准数据集上的实验结果表明,该方法在一定程度上能提高PCA对平移的鲁棒性,提高分类的准确率。3.2 核PCA
4 KPCA-L算法
4.1 LLE算法
4.2 改进的LLE(DLLE)
4.3 KPCA-L算法
5 实验
5.1 数据集

5.2 比较算法
5.3 实验结果
6 结语
