基于YOLOv3锚框优化的侧扫声呐图像目标检测
2022-12-26陈禹蒲马晓川
陈禹蒲 马晓川 李 璇
(1.中国科学院声学研究所中科院水下航行器信息技术重点实验室,北京 100190;2.中国科学院大学,北京 100049)
1 引言
侧扫声呐技术通过对海底散射物的散射回波进行处理获取海底地形地貌特征[1-2]。由于侧扫声呐能够直观地提供海底形态的声成像,且具有价格低廉、分辨率高等优点,其在水下目标探测和识别领域有广阔的应用前景[3-4]。然而,诸如声呐盲区、混响和多径等复杂的水下声传播特点导致了声呐图像中目标位置和类别的辨认往往需要专业人士进行解读,这就不可避免地会耗费大量的人力。因此,研究自主的声图像目标检测方法是十分重要的。
传统的声呐图像目标检测算法主要包括基于像素的检测,基于特征的检测和基于回波的检测三种[5],其基本思路为根据声呐图像中的高亮和阴影特性来对目标是否存在进行判决。当高亮与阴影同时出现在某一区域时,说明该区域可能存在目标。若高亮与阴影相连,则目标为沉底目标,若高亮与阴影分开,则目标为悬浮目标。然而,传统的目标检测方法依赖于准确的数学模型的建立,当数学模型和真实的水声环境存在差异时,算法的目标检测性能也会随之下降。
随着深度学习目标检测技术的发展,基于深度学习的声呐图像目标检测问题获得了诸多学者的关注。Faster R-CNN[6]作为一种两阶段的目标检测网络于2015 年被提出。它使用RPN(Region Proposal Network)网络生成候选区域,提升了RCNN系列网络[7-8]的检测速度,并利用锚框回归预测框的位置,提升了网络的目标检测性能。因此该网络作为R-CNN 系列中性能最好的网络,一经提出就受到声呐图像目标检测领域相关学者的关注。文献[9]较早地将Faster R-CNN 应用到声呐图像目标检测领域,通过对NSWC(Naval Surface Warfare Center)机构的公开声呐数据集进行处理,研究了Faster R-CNN 对水下物体检测的适用性。文献[10]在Faster R-CNN 的基础上设计了一个噪声生成网络和一个单独的噪声块来引入特定的噪声扰动,继而通过对抗训练提高了算法对噪声的鲁棒性。之后,为解决两阶段目标检测网络实时性和检测精度不佳的问题,科研人员相继提出了如SSD[11]目标检测网络和YOLO 系列网络[12-14]等单阶段目标检测网络。近年来,随着图像目标检测网络的发展日趋成熟,单阶段目标检测网络引起了声呐图像处理领域相关学者的关注。YOLOv3 是一种兼具实时性和检测精度的图像目标检测网络[15],具有很强的泛化能力[16-18]。因此,YOLOv3 作为单阶段目标检测网络的代表在声呐图像目标检测领域有着广泛应用。文献[16]针对有效样本小、信噪比低的声呐数据集,在YOLOv3 的基础上提出了YOLOv3-dpfin 网络架构,该网络通过双路径网络模块和融合过渡模块提取到了声呐图像的有效特征。文献[19]将YOLOv3 应用到声呐图像沉船目标的检测问题中,在原有的YOLOv3网络基础上额外添加了两个下采样特征层,并将采到的特征与原有的三尺度特征合并,提高了检测精度。文献[20]基于YOLOv3 提出一种障碍物区域检测算法,通过对声呐图像中的障碍物进行检测为AUV避障提供可靠信息。
为进一步提升YOLOv3 网络的目标检测性能,相关学者将目光转向了锚框优化的研究。锚框作为YOLOv3 网络的一个重要先验信息,其设计的合理性会影响到网络的检测性能。文献[21]论证了通过合理的方法对YOLOv3网络锚框进行优化可以提升网络的目标检测性能,进而提出了一种基于贝叶斯的锚框优化方法,获得了比原YOLOv3 网络更好的检测性能。文献[22]在单阶段目标检测器的基础上对锚框进行修剪,在提高检测效率的同时也提高了检测精度。文献[23]将锚框形状作为网络训练参数的一部分,能够提高检测器的检测精度,但也增加了计算负担。文献[24]针对RetinaNet网络无法检测宽高比较大的小目标问题,使用了Crow搜索策略来搜索锚框的最优尺寸,获得了更优的检测效果。文献[25]在YOLOv3 的基础上利用K-means++获得了更优的先验锚框尺寸。文献[26]中作者也指出有更多数据集信息的锚框对网络检测性能的提升是有帮助的。
本文使用的侧扫声呐数据集中小目标占比较多。为了在该数据集上获得更好的目标检测效果,本文在YOLOv3的基础上,提出一种锚框优化策略。首先使用K-Means算法对声呐数据集的目标框进行聚类,得到一组包含目标尺寸先验信息的锚框。然而对于本文的声呐数据集而言,由于目标框的尺寸相对整幅侧扫图而言偏小,得到的锚框尺寸会集中在较小的参数范围内,这样会导致YOLOv3 误将小目标映射到本应检测中大目标的特征层,从而导致无法提取合理的小目标特征。本文针对这个问题,设计了一个超参数映射关系来对聚类后的锚框进行拉伸映射,这样得到的锚框参数拥有着更好的先验信息,它既涵盖了侧扫声呐图像数据集的目标信息,也能合理利用到YOLOv3 的多尺度特征拼接特性,有效提高了网络的检测性能。
2 算法原理
2.1 YOLOv3网络结构
YOLOv3 网络结构首先利用Darknet-53 提取输入图片的特征,然后借助FPN(Feature Pyramid Networks)结构在获取到的特征图上进行目标的分类与位置的回归。YOLOv3 中没有池化层,所有的下采样都是通过卷积层完成的,通过卷积层来替代最大池化下采样层,带来了较好的性能提升,其整体结构如图1所示。
Darknet-53 由一系列卷积核为1*1 和3*3 的卷积块组成,每个卷积块都包含一个基本的卷积操作和一个BN(Batch Normalization)层,同时激活函数被设置为LeakyReLU,图1 中用Conv Block 来表示一个卷积块。此外Darknet-53 还借鉴了残差结构,在图中表示为Residual,它由两个卷积块组合而成。YOLOv3 使用了Darknet-53 的前52 层,并从中取出三个特征图用作后续处理,假定输入YOLOv3 的图片大小为416*416,则得到的三个特征图分别为52*52*256的特征图1、26*26*512的特征图2和13*13*1024 的特征图3,借助FPN 的结构,YOLOv3 对得到的特征图进行上采样处理,以保证两个特征图之间能够维度对齐,但不同于FPN 将两个特征图上的对应维度数值进行相加的方式,YOLOv3 对得到的特征图在通道数上直接进行拼接。

图1 YOLOv3网络结构Fig.1 The overview of YOLOv3
YOLOv3 在拼接好的特征图上又进行了一些卷积操作,相应得到了三个预测结果,如图1 所示,分别为13*13*N的预测结果1、26*26*N的预测结果2和52*52*N的预测结果3,其中N=3*(4+1 +C),C代表要预测的目标类别数,这三个预测结果就包含了YOLOv3进行分类和回归任务的所有参数。
2.2 锚框机制
YOLO[12]网络最早直接对预测框的宽高进行预测,这种检测方式下得到的定位准确性是比较差的,直到Faster R-CNN 网络提出使用锚框来帮助回归预测框位置,这种回归方式一经提出后就被各大主流目标检测网络所延用。锚框也是YOLOv3中的一个重要机制,它能给检测网络提供一定的先验信息,也有助于利用网络多尺度检测的特点,一组好的锚框可以让网络以更快的速度学习到更好的结果[13]。在YOLOv3 中,锚框会影响到预测框的位置回归和正负样本的选取,进而会影响到网络训练过程中损失函数的计算,在整个检测过程中起着至关重要的作用。
YOLOv3 中由9 个尺寸不一的初始框共同构成了一组锚框,它们按大小被分为3组,每组再分配给对应尺寸的预测特征层,分配过来的锚框宽高尺寸不变,但其中心坐标会随网格点变化,以保证预测特征层的每个网格点都匹配到初始锚框。具体的分配原则是将小尺寸的锚框分给大尺寸的特征层,而大尺寸的锚框分给小尺寸的特征层。因为随着网络特征提取的深入,层数越高细节信息越容易被忽略,所以大尺寸的特征层更适合检测小目标。有了锚框的先验信息之后,YOLOv3 就可以在锚框的基础上对预测框的位置进行回归,具体实现涉及到训练中的编码过程和预测中的解码过程。在训练过程中首先需要借助锚框对真实框进行编码,即求出锚框与真实框间的相对位置,记某锚框的中心坐标与宽高分别为ax,ay,aw,ah,某目标真实框的中心坐标和宽高分别为gx,gy,gw,gh,则两者相对位置dx,dy,dw,dh的计算方式如下

这一组相对位置参数就是YOLOv3在进行回归时的标签值,后续将用于计算网络损失,网络在训练的过程中会逐渐学习到锚框与真实框的相对位置关系。在预测过程中,需要结合锚框对网络输出的回归参数进行解码才能得到预测框真正的位置,记网络输出的回归参数为tx,ty,tw,th,则真正的预测框中心与宽高bx,by,bw,bh的值为
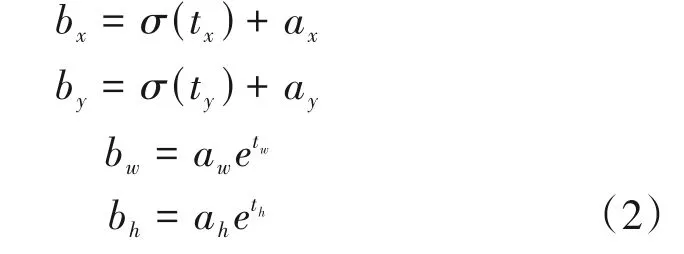
其中σ(·)代表对变量做sigmoid变换,目的是将中心点的偏移量限制在0~1 之间,使得预测框中心只会在一个网格内移动,而不会移动到别的网格去,导致框住其他目标。
锚框对于目标特征的提取和网络正负样本的选定也起着重要作用,YOLOv3 会选定与真实框交并比(Intersection over Union,IoU)最大的锚框尺寸来帮助回归预测框位置,同时也会将目标对应到该锚框所在的预测特征层来进行预测,从而影响目标特征的提取。YOLOv3 将与真实框IoU 值最大的锚框当作正样本,忽略掉IoU 值在某阈值之上的锚框,并将其余的当作负样本。在判定好正负样本后,才能对网络的损失函数进行计算,YOLOv3 包含定位损失Lloc、类别损失Lcla和置信度损失Lconf,定位损失Lloc只针对正样本,它用平方误差和来表示

类别损失Lcla也只针对正样本,它采用二值交叉熵来计算损失值,公式如下
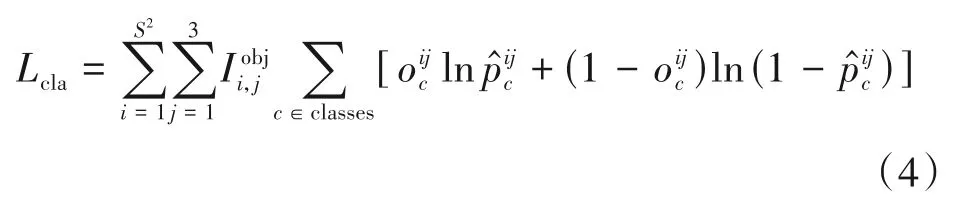
除开忽略样本外,其余的样本都需要计算置信度损失Lconf,它同样采用二值交叉熵来计算,公式如下
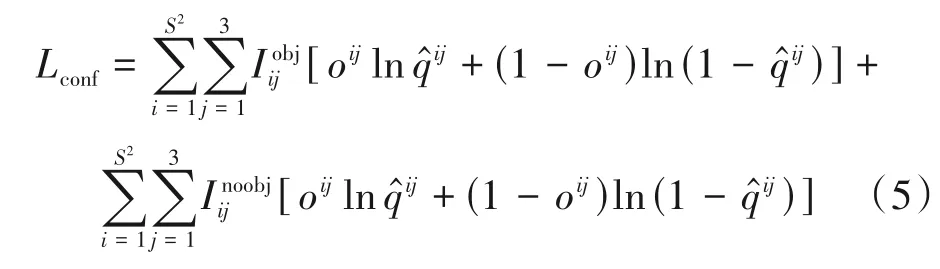
YOLOv3 为每种损失都设计了平衡系数,分别为定位损失系数λloc,类别损失系数λcla和置信度损失λconf,则可得到YOLOv3的损失函数为

可以看到在YOLOv3 损失函数的计算过程中,锚框尺寸会直接影响定位损失的数值,而类别损失和置信度损失由于与正负样本的数目有关,也会被锚框间接影响。总之,锚框作为预测框的一种先验信息,在整个网络的训练过程中都是十分重要的。
3 算法改进
本文考虑到锚框的重要性,给出了一种超参数锚框优化策略,首先使用K-Means 算法对侧扫声呐数据集的目标真实框宽高进行聚类,随后设计了一种超参数映射关系对得到的锚框进行拉伸,从而得到一组较优的先验锚框。在得到优化后的锚框后,将锚框设置为YOLOv3 的先验参数,再将数据集输入网络进行预测,整体的流程如下图2所示。

图2 算法流程图Fig.2 The flowchart of algorithm
3.1 使用K-Means算法获取锚框
YOLOv3 中先验锚框的宽高尺寸是通过KMeans 算法对COCO 数据集聚类得到的,考虑到侧扫声呐图像数据集中的目标大小不会和COCO数据集目标大小相同,所以需要对声呐数据集的目标真实框进行聚类,从而获得与目标尺寸更相关的锚框参数。K-Means算法的目标是针对数据集聚类得到k个簇中心,记有m个目标框的数据集为X={x1,x2,…,xm},其中分别为第i个目标框的宽和高,聚类得到的k个簇为C={C1,C2,…,CK},则K-Means 算法的目标是最小化误差函数E
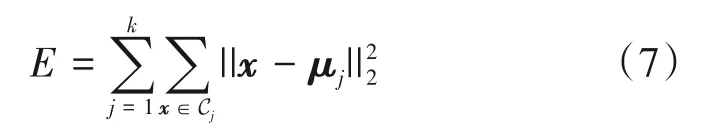
其中μj是簇Cj的均值点,最小化误差函数E即意味让簇内的数据点与簇中心的距离最近,此时聚类的效果最好。对于真实框宽高的聚类问题,YOLOv3没有使用式(7)中的欧式距离,而是改用IoU 距离来衡量簇中心与簇内数据的距离,IoU 距离DIoU的定义为
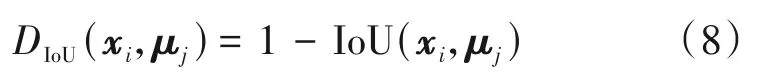
求IoU 值时,默认目标真实框xi与类中心框μj的左上角是重合的。此时误差函数可改写为
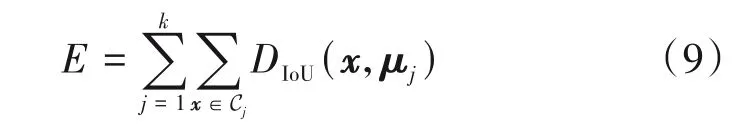
在确定了K-Means 算法中误差函数的定义后,需要最小化式(9),而该问题本质上是一个NP 难问题,所以K-Means 算法使用了迭代优化的方法,其优化步骤如下:
(1)随机选定k个点作为簇中心
(2)对于数据集中的每个目标真实框xi,都计算它到各簇中心μ0的IoU距离DIoU,并将框xi归类到距离最小的簇中心所在的簇中;
(3)对于第j个簇,将该簇的中位数当作簇中心μj;
(4)重复步骤(2)~(3),直到按式(9)计算的误差函数变化小于某阈值。
3.2 超参数锚框优化
由于侧扫声呐图像中小尺寸目标比较多,所以在聚类后会得到较多尺寸分布在同一范围的锚框,这会导致一些小目标无法被分配到相应的预测特征层进行训练,从而影响小目标的特征提取,进而影响网络的检测性能。对此,文中在聚类后的锚框基础上设计了一种超参数映射关系,使得锚框能够在包含目标真实框信息的同时也能更好地运用到YOLOv3的多尺度特性。
记聚类后获得的k个锚框为μ=(μ1,μ2,…,μk),其中μi=分别为第i个锚框的宽和高,定义超参数映射关系为
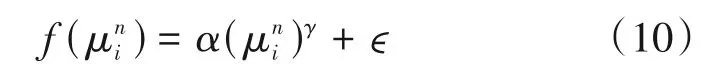
其中i=1,2,…,9,n∈{w,h}。根据式(10)的映射关系,我们可以将聚类后获得的锚框宽高映射为任意正整数,但由于图片输入YOLOv3 是有输入尺寸的,在进行映射操作时应该考虑到最大的锚框尺寸不能超过图片输入尺寸,且锚框的最小尺寸也不能过小,否则会导致基本框不住任何目标,所以我们需要先确定映射后的锚框最值尺寸。不妨设映射后的第一个锚框为尺寸最小锚框记为,最后一个锚框为最大锚框记为,同样地,记分别为映射前的最小锚框和最大锚框,已知后,再给定映射关系中的指数因子γ,就能解算乘子α与偏移量ϵ。我们可以对锚框的宽高分别做映射,记αw和ϵw为宽的映射参数,其计算方式为
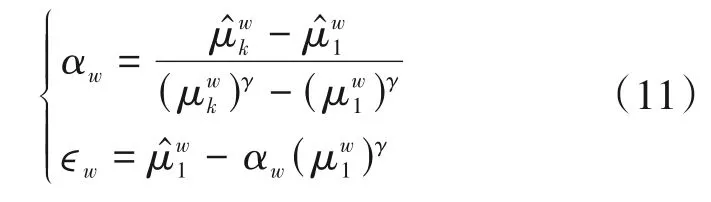
同理可计算高的映射参数αh和ϵh,则映射后的第i个锚框的尺寸为
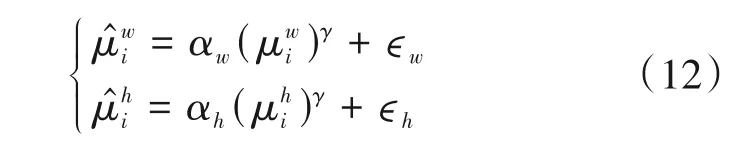
4 实验
4.1 数据集与实验平台
文中使用的侧扫声呐图像数据来自于2021 年夏季中国科学院声学研究所水下航行器团队于某海湾进行的海底侧扫实验。此次实验的侧扫区域面积为80 平方公里,实验时间长达2 个多月,共采集到了约26689张侧扫声呐图像。基于本文研究课题的应用背景,我们期望能从大量的侧扫声呐成像结果中利用算法筛选出具备一定人工特征的声呐目标,因此首先需要建立目标特征符合课题需求的侧扫声呐图像目标数据集。结合侧扫声呐的成像特点,我们按照以下几个原则来筛选符合本课题需求的目标:(1)在声呐图像中,目标区域应包含高亮和阴影特征。(2)目标的高亮和阴影区域尺寸不应过小。(3)图像轮廓具备明显的人工特征,如条状,块状和点状等。在前述的目标筛选条件下,我们从26689 张原始声呐图像中筛选出了符合课题需求的237 张目标数据。为了提高检测效果,增强算法的鲁棒性,利用旋转、翻转和颜色扰动的数据增强方式将数据从237 张扩充至948 张,并将数据集按9∶1的比例划分为训练集和测试集。图3中给出了一张侧扫声呐的图像数据示例。

图3 侧扫声呐图像示例Fig.3 Example of side scan sonar image
为验证算法的有效性,本文搭建了用于深度学习的实验平台,使用的操作系统为Ubuntu 20.04.1LTS,深度学习框架为tensorflow1.14,同时配置了CUDA10.0 和cuDNN7.4 来加速训练,主机的CPU 为AMD A10 pro-7800b r7,GPU 为GeForce GTX 1080Ti。
4.2 实验结果
对于网络的训练,本文使用了迁移学习来加速网络的收敛,将YOLOv3 在ImageNet 数据集上训练得到的主干特征提取网络的权重作为初始值,首先保持主干特征提取网络的权重不变,训练50 个epoch,学习率设为0.001,batch 大小为8 个,使用早停法进行训练,当10 个epoch 内验证集的损失函数值都没有得到改进,则停止训练。随后训练整个网络的权重,仍旧使用早停法训练50个epoch,但学习率降为0.0001,batch 大小降为4个。检测效果的评价指标使用mAP(mean Average Precision),它是目标检测领域较具代表性的评价指标,指的是各类目标P-R(Precision-Recall)曲线的平均面积。
4.2.1 锚框优化实验结果与分析
在训练过程中,将YOLOv3 的图像输入尺寸设置为416*416,首先在表1 中给出分别使用聚类COCO 数据集得到的锚框和聚类侧扫声呐数据集得到的锚框时,YOLOv3网络的检测效果。

表1 不同锚框的检测结果Tab.1 Detection results of different anchors
可以看到如果直接使用在侧扫声呐数据集上聚类得到的锚框,会带来一定程度的检测性能下降。这是因为侧扫声呐数据集中小目标的数量占比是非常大的,聚类后得到的锚框也会更容易分布在较小的尺寸范围内,而YOLOv3在训练过程中,会先求目标真实框与锚框的IoU 值,再决定将目标分配到哪一个特征层,这就有可能导致某一个本应分配给小尺度特征层的目标被误分到中尺度特征层,但中尺度特征层对于小目标的特征提取是不佳的,它已经模糊掉了很多的细节信息,从而导致训练得到的网络性能变差。在此之上,需要进一步对锚框进行优化来获得好的检测性能。
下面给出对聚类后的锚框进行映射后的实验结果,如图4所示,图中每个网格都代表了一组参数下映射得到的锚框,网格中的数值为YOLOv3 在该锚框下的检测结果,横坐标为超参数映射关系中的指数因子γ,取值为0.5,0.8,1,1.2 和1.5,纵坐标代表的是映射后的锚框最值尺寸和,间接代表了超参数映射关系中的乘子α与偏移量ϵ,具体的锚框最值尺寸列在表2 和表3 中,在图中用编号的形式简代之。图4(a)的锚框映射原则是保持原锚框的宽高比不变,以锚框的高为基准进行单维度的映射,其纵轴具体参数如表2 所示,图4(b)保持锚框宽高的独立性,进行了双维度的映射,纵轴参数如表3 所示。从图4 中能够得到结论,最佳的检测结果出现在双维度映射的情况,其mAP 值为83.86%。实验结果表明对聚类后的锚框进行超参数的映射拉伸是有效的,映射后的mAP 值提高了3.93%,相对于直接使用COCO 数据集的锚框,检测效果提升了1.18%。
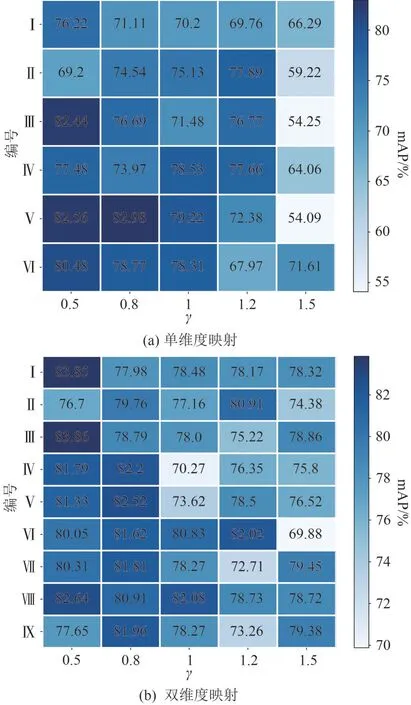
图4 不同参数下映射锚框后的检测结果Fig.4 Detection results of mapping anchors under different parameters

表2 单维度映射时的参数Tab.2 Parameters for one dimension mapping

表3 双维度映射时的参数Tab.3 Parameters for two dimensions mapping
为了进一步分析超参数映射锚框策略的有效性,图5 给出了数据目标真实框,聚类COCO 数据集获得的锚框,聚类侧扫声呐数据集获得的锚框和经过超参数映射优化后的锚框的分布图,它们分别用实心点,倒三角,加号和五角星表示。COCO 数据集锚框在中大尺寸区域偏离样本点较远,而声呐数据集锚框全部集中在小尺寸区域,基本忽略了大尺寸目标,经过超参数映射优化后的锚框既不会全部集中在小尺寸区域,也不会偏离中大尺寸目标过远,可以给网络带来更优的先验信息。
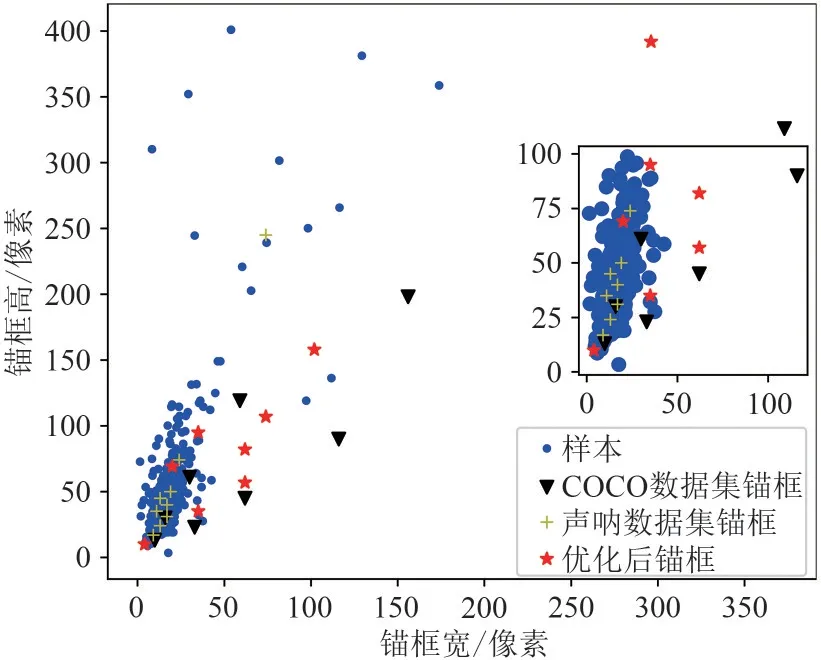
图5 不同锚框对比图Fig.5 Comparison of different anchors
4.2.2 非目标类数据下算法的检测效果
受限于侧扫声呐数据集中的有效目标样本数据量较少的问题,结合课题的应用背景,我们设计了非目标类数据下使用COCO 数据集锚框的YOLOv3 和锚框优化的YOLOv3 两种算法的对比实验,来验证本文所提算法对无目标图像的剔除能力。
本实验从未被选定为目标数据集的其余侧扫声呐图像数据中随机选取了3817 张非目标图像数据,用于测试算法剔除非目标类图像的正确率。这里的正确率定义为算法将图像判为非目标图像的数量与非目标图像的总数量之间的比值。由于目标检测网络的输出结果是包含预测置信度的,所以当给定不同的置信度阈值时,算法的判决结果也会发生变化,图6 给出了使用COCO 数据集锚框的YOLOv3 和锚框优化的YOLOv3 两种算法的检测正确率随置信度阈值变化的曲线。从实验结果可以看到,当置信度阈值提高时,两种算法的检测正确率都增大,这是因为置信度阈值设置得越高,算法越容易将图片判决为非目标。从图6中两条曲线的相对位置关系可以看出,锚框优化的YOLOv3 检测正确率始终高于使用COCO 数据集锚框的YOLOv3检测正确率,直到置信度阈值点为1时,两者同时达到100%的正确率。因此,对比看来,本文所提锚框优化策略能够提高YOLOv3在声呐数据集上的检测性能,有更优的检测效果。
图6 检测正确率随置信度阈值的变化曲线Fig.6 The curve of detection accuracy versus confidence threshold
4.2.3 不同检测算法的比较
额外选取Faster R-CNN和SSD来展示本文所提算法与其他目标检测网络的横向对比效果,检测效果如表4 所示,参与比较的算法有Faster R-CNN 目标检测网络,SSD 目标检测网络,使用COCO 数据集锚框的YOLOv3目标检测网络和本文所提的锚框优化YOLOv3 目标检测网络。可以看到Faster R-CNN在侧扫声呐数据集上的目标检测mAP 值为15.05%,是几种算法中效果最差的,其次是SSD,本文所提的锚框优化YOLOv3目标检测网络有着最佳的目标检测性能,其mAP 值达到了83.86%。实验结果说明了使用YOLOv3 目标检测网络,同时利用超参数映射策略来优化锚框,有最好的检测效果,在侧扫声呐图像数据集上是有效的。

表4 不同算法检测结果Tab.4 Detection results of different algorithms
4.3 检测结果展示
为了能够更直观的展示各检测方法的检测结果,图7 至图12 分别给出了不同背景,目标数量和目标大小情况下各算法的预测结果图,参与对照的有Faster R-CNN 目标检测网络,SSD 目标检测网络、使用COCO 数据集锚框的YOLOv3 目标检测网络、使用声呐数据集锚框的YOLOv3目标检测网络和本文所提的锚框优化YOLOv3目标检测网络。由于整幅侧扫声呐图像较大,为方便展示预测结果,我们在下面均以单侧图像为例来对比算法性能。
图7~图10 展示了不同情况下各算法对小目标的检测效果。图7为只含有单目标情况下不同算法对侧扫声呐图像的检测结果。图7(a)展示了原始声呐图像,并且用黄色方框在图中标注了目标位置。图7(b)~(f)分别为不同算法对图7(a)所示图像的检测输出结果。从结果中可以看出,Faster RCNN 在该图像中检测出了两个目标,出现了虚警情况;SSD 和使用声呐数据集锚框的YOLOv3 均未检出目标,出现了漏检的情况;使用COCO数据集锚框的YOLOv3 和本文所提的锚框优化YOLOv3 均正确检测出了目标位置,但是对比二者预测框的置信度可以发现锚框优化YOLOv3得到的预测框置信度高于使用COCO 数据集锚框的YOLOv3。因此对比来看,本文所提的锚框优化YOLOv3 具有最佳的检测效果。图8展示了侧扫声呐图像包含多个密集目标情况下不同算法的检测结果。从结果可以看出,对于多目标检测场景,各个算法均存在不同程度的漏检。SSD,使用声呐数据集锚框的YOLOv3 和使用COCO 数据集锚框的YOLOv3 漏检情况较为严重,SSD 和使用COCO 数据集锚框的YOLOv3 均只检测出一个目标,使用声呐数据集锚框的YOLOv3 则完全漏检;Faster R-CNN 和锚框优化YOLOv3 虽然存在漏检情况,但是整体检测性能仍优于另外三种算法。对比Faster R-CNN 和锚框优化YOLOv3 的检测结果可以发现,虽然两种算法均能检测出两个目标,但Faster R-CNN 预测框框选区域过大,没有锚框优化YOLOv3精确。图9和图10分别展示了背景较暗和海底存在碎石区两种情况下侧扫声呐图像的检测结果。从结果可以看出Faster R-CNN 在这两种背景下的检测性能均较差,未能检测出目标;另外四种算法都可以正确框选出目标位置。对比图9 的检测结果可以看到,锚框优化YOLOv3 对于两个目标的检测置信度均达到了0.99,获得了最高的检测置信度。同样从图10的结果中也可以看出,锚框优化YOLOv3具有最佳的检测性能。

图7 实验结果1Fig.7 Result 1

图8 实验结果2Fig.8 Result 2

图9 实验结果3Fig.9 Result 3

图10 实验结果4Fig.10 Result 4
图11 和图12 展示了各算法对较大尺寸目标的检测效果。从图11 中可以看出,Faster R-CNN,SSD和使用COCO 数据集锚框的YOLOv3 均未检测出目标,使用声呐数据集锚框的YOLOv3 和本文所提的锚框优化YOLOv3 均正确检测出了目标位置,且两种方法的检测置信度相同。从图12中可以看出,五种检测算法均能框选出目标,但是本文所提的锚框优化YOLOv3 得到的检测置信度低于使用COCO 数据集锚框的YOLOv3 和使用声呐数据集锚框的YOLOv3。综合上述检测结果可以发现,本文所提的锚框优化YOLOv3 在对小目标数据进行检测时,检测率和置信度较高,具有较好的检测性能。但是本文方法在检测较大尺寸目标时,出现了检测置信度低于使用COCO 数据集锚框的YOLOv3 和使用声呐数据集锚框的YOLOv3的情况。这说明相较于小目标,本文方法对较大尺寸目标的检测性能略有下降。综上所述,本文算法比较适用于小目标占比较多的侧扫声呐数据集。

图11 实验结果5Fig.11 Result 5

图12 实验结果6Fig.12 Result 6
5 结论
针对侧扫声呐图像的目标检测问题,在YOLOv3 目标检测网络基础上,设计了一种超参数锚框优化策略,对聚类后的目标真实框使用超参数映射。实验结果表明,YOLOv3 网络在优化后的锚框上能取得更优的检测效果,其mAP 值达到83.86%,相较原本的YOLOv3 锚框参数,检测性能提升了1.18%,说明了超参数锚框优化策略的有效性。然而本文方法对于小目标较为密集的区域仍然存在漏检的情况,如何针对侧扫声呐图像的目标特点来提升检测率将成为我们下一步的研究内容。
