基于深度学习的图像去噪研究
2022-03-10胡超秀
胡超秀
(山西师范大学 教育科学学院,山西 临汾 041000)
引言
在实际生活中,由于复杂环境的影响,图像在传播过程中很容易受到噪声的干扰,从而使图像中添加了很多种类不同的噪声,使图像变的模糊,更可能使图像失去了原来的特征,进而导致在图像识别、分割、提取、检测等方面出现错误。
为了获得高质量高精度的图像,便于为图像的后期处理提供精准的图像数据,首先需要为图像去噪。图像去噪一方面是要去除图像的噪声,另一方面是尽可能的不去改变图像原有的特征,保留原图像足够多的特征。对于不同种类的噪声,图像去噪的方法也不相同,如加性噪声,乘性噪声,量化噪声等。传统的图像去噪方法有空域和变换域滤波、基于图像自相似性、基于稀疏表达、基于马尔科夫场等,这些方法在去噪的同时也失去了一些原本的特征。
近年来,深度学习技术不断完善,在图像处理方面取得了很高的成就。图像去噪技术也得到了发展,但还存在不足之处,需要继续着手于深度学习在图像去噪方面的研究,尽可能的降低图像中的噪声,提高图像去噪效果,从而提高图像质量,为后期的图像处理提供精准的数据,提高图像处理的准确性。
在图像去噪的传统算法中,在图像保真度和视觉质量方面效果较好的是NLM[1]算法和BM3D[2]算法,都很大程度依赖计算机性能,计算时间太长,远不能满足实时计算的需求。十几年来,卷积神经网络在图像处理方面取得了一定成功。用深度学习技术实现图像去噪的方法也得到了发展。Xie等人利用多层的全连接网络的去噪自编码实现图像去噪[3],Burger等人提出利用多层感知器(MLP)实现图像去噪[4],Mao等人在2016年提出了利用网络结构深的卷积编码器[5]实现图像去噪。基于卷积神经网络的图像去噪这一方法在图像处理方面取得了很大成果,因为CNN具有局部感受域[6]这种结构,加快了训练速度,减少运算数量。Zhang等人在2017年提出了利用深度卷积神经网络[7]实现图像去噪效果。但是,这些基于卷积神经网络的图像去噪算法还没有得到广泛应用,去噪效果的改进还需要大量的数据模型来支持。因此,基于深度学习的图像去噪算法还有待进一步研究实现。
1 神经网络相关理论
1.1 神经元
神经元是人脑的基本计算单元,它会将接收到的信号进行处理,若神经元感知到这个信号处理后满足神经元的某一阈值,它就会被激活,并将信号传导至下一神经元。人工神经网络是一种从信息处理角度模仿人脑神经元的数学模型。其大致结构如图1所示:
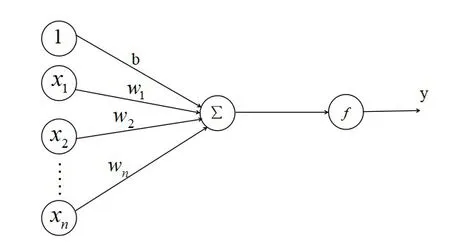
图1 神经元模型
图1中x=(x1,x2,…,x n)为输入数据,w=(w1,w2,…,w n)为权重,b、f、y分别代表偏置、激活函数、数据的输出。神经元将输入x和与之相对应的权重w相乘然后再将其相加得到一个总输入,数学表达式是:

然后这个值作为激活函数f的自变量得到y i:

常用的激活函数有sigmoid型函数和tanh函数。sigmoid取值范围为[0,1]。Sigmoid[8]函数为:

1.2 感知器
感知器是较为简单的一种神经网络。不同的感知器,实现的神经网络的功能也是不一样的。整个过程中,数据由输入层进入神经网络,接着逐层向后传递,直至到达输出层,如图2所示:
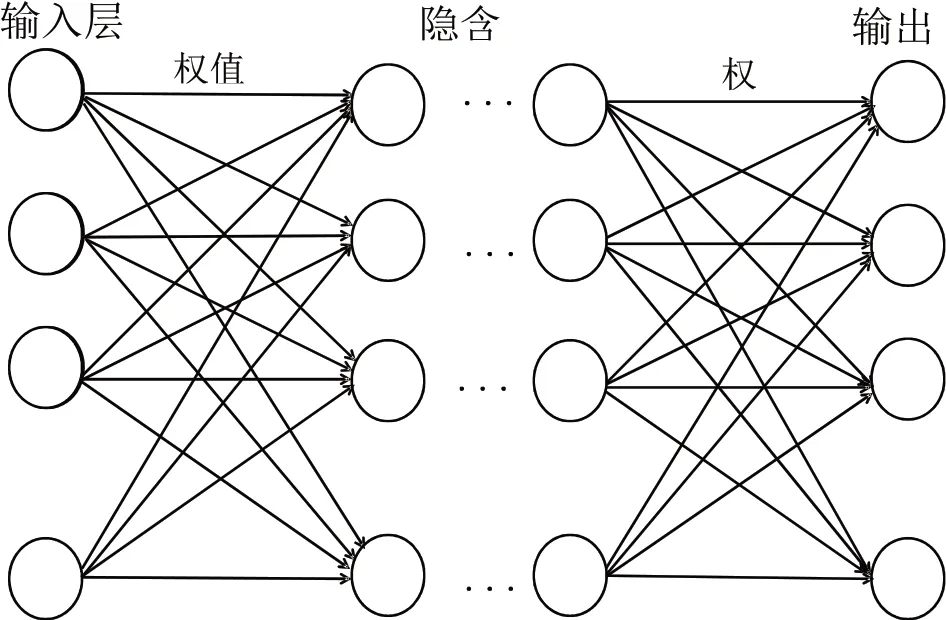
图2 前馈神经网络模型图
1.3 BP网络
BP神经网络算法由两部分组成,分别是信息的正向传播和误差的反向传播。具体结构如图3所示。
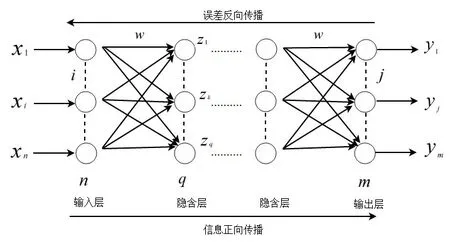
图3 神经网络结构图
反向传播基于梯度下降算法,前向传播的实际输出与期望输出之间差值被定义为误差信号[9],公式如下:

m表示样本数,yi为实际值,y0为输出值。通过调整网络参数来使实际输出越来越接近预期输出。
权重w的更新为:
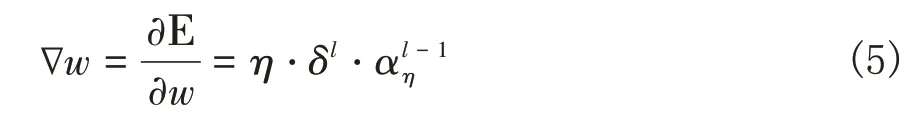
同理可得b的更新为:

1.4 卷积神经网络
1.4.1卷积神经网络
卷积神经网络是一种前馈神经网络[10],它是根据生物的视觉和知觉机制来构建的,可进行监督学习,也可进行非监督学习。图像输入像素的一个小窗口就叫做局部感受野。每个隐含层的神经元只与输入神经元的一小部分区域连接。如图4所示:
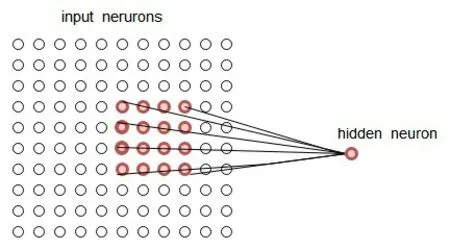
图4 局部感受野
1.4.2 卷积神经网络的特点
卷积神经网络通过采用局部连接的方式,来减少网络中的参数数量,进而提高学习效率。
卷积层中的卷积核作用于整张图片(如图5),首先从输入层输入图像,然后对图像的不同位置进行卷积,最终得到的卷积结果就是输入图像的特征。在卷积神经网络中,被同样结构的卷积核进行卷积,实现了权重共享,这导致网络中的计算量大大降低。
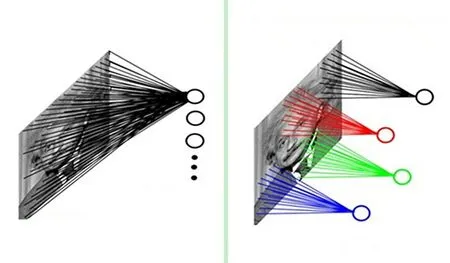
图5 卷积核作用过程
1.4.3 ReLU激活函数
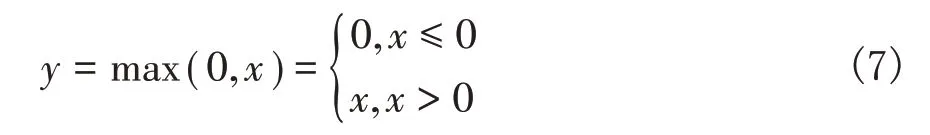
ReLU激活函数在神经网络中稀疏表达能力较强,ReLU在梯度下降算法中速度较快,并且缓解了S型函数中梯度弥散问题。
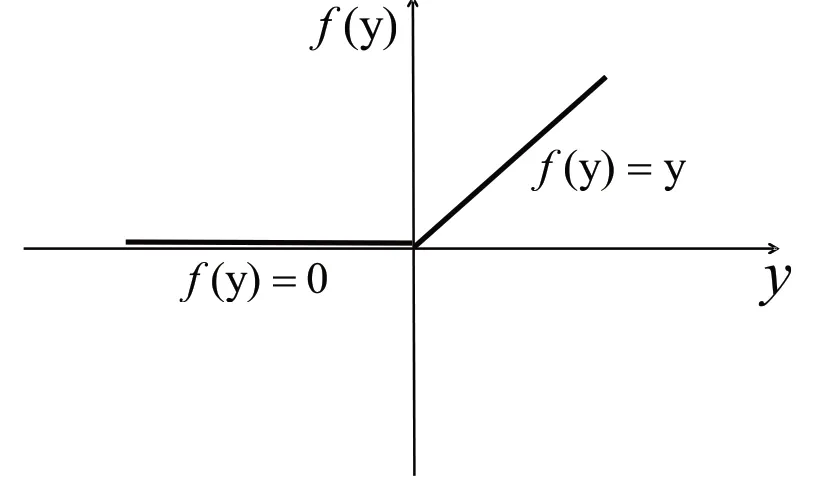
图6 ReLU激活函数
2 图像去噪原理及其卷积神经网络模型
2.1 图像去噪原理
噪声会直接影响视觉感官效果,甚至会使图片丢失原本特征,使图像变得模糊,从而不能从中提取出重要信息,而图像去噪是利用技术手段使图片恢复到原来的样子,进而提高图像质量,为后续的图像处理提供清晰的图像数据。
2.1.1 噪声模型
噪声模型分为两种,分别是:加性噪声和乘性噪声。其中加性噪声可以表示为:
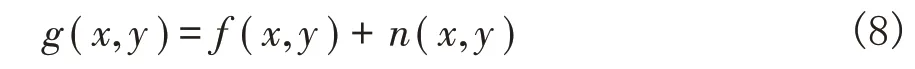
其 中f(x,y)、n(x,y)、g(x,y)分 别 为 原 始 图像、添加的噪声、有噪声的图像。常见的噪声有很多种,但由于我们平时看到的图像大多数都是经过数码相机、成像设备得到的,所以本文主要是研究在深度学习技术上加性高斯白噪声的去除问题。
2.1.2 常用的图像去噪算法
基于深度学习的图像去噪算法是通过学习图像的细节特征而实现的图像去噪。随着深度学习技术的不断发展,通过尝试不同方法来实现图像去噪,并取得了一定效果。
一种是通过卷积神经网络实现图像去噪,由于这种神经网络具有稀疏连接和权值共享等特点[11],使网络中的参数大大降低,提升训练速度,使得卷积神经网络在图像处理识别方面取得了良好的效果。
另一种是通过自编码器实现图像去噪,这种方式可以很好的去学习图像的细节特征,它的学习方式是无监督的学习方式[12]。
2.1.3 图像去噪效果评价
在图像去噪方面,通常需要判断图像的去噪效果,一般评价图像的去噪效果有两个常用的方法,本文主要通过PSNR(峰值信噪比)[13]和SSIM(结构相似性)来检验图像的去噪效果。
PSNR(峰值信噪比)是通过均方误差(MSE)实现的。两个图像之间PSNR值越大,则越相似。两幅大小均为m*n的灰度图像A(i,j)和B(i,j)的均方差公式为:
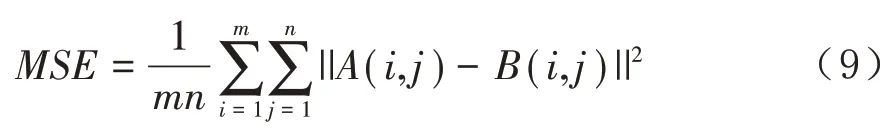
在此基础上,PSNR为:
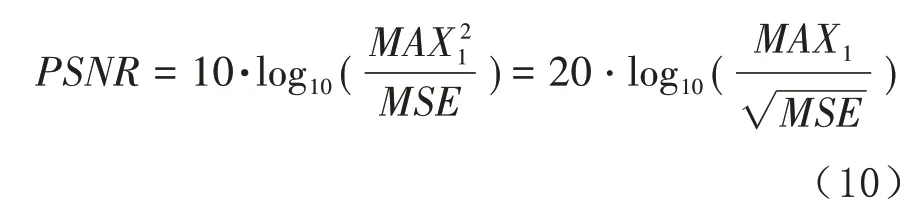
SSIM是通过比较两幅图像的结构相似性来判断去噪效果,其值最大为1。SSIM评价模型为:
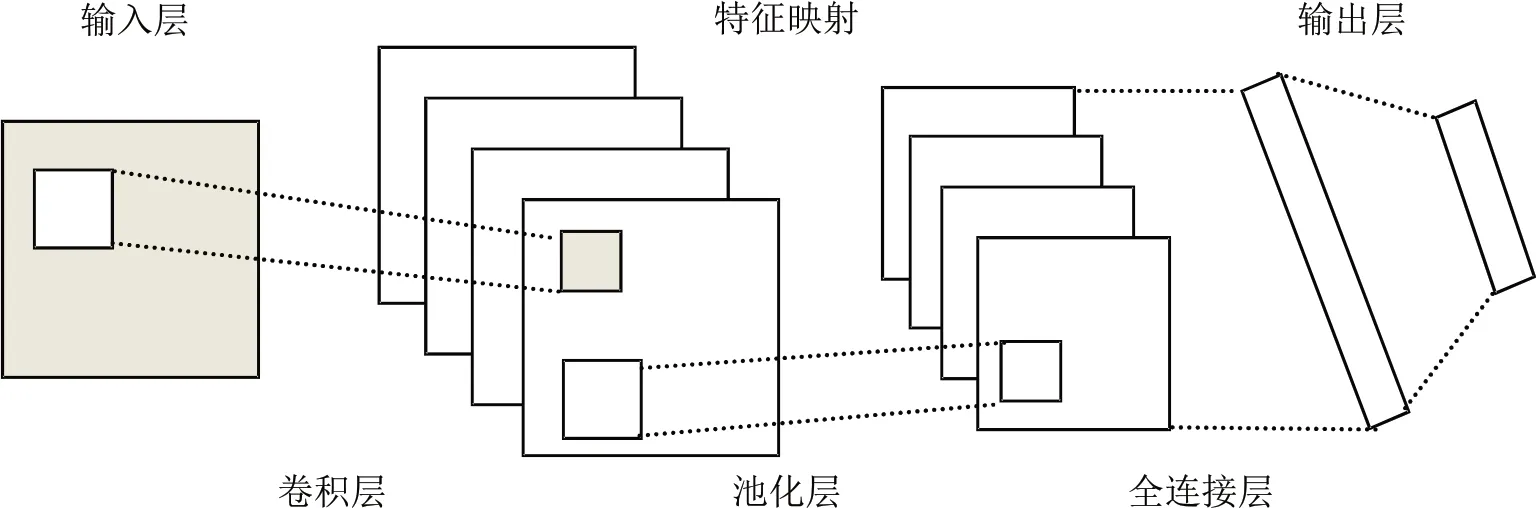
图7 简单的CNN网络结构
2.2卷积神经网络模型
卷积神经网络一般结构为:
2.2.1 输入层
输入层可处理多维数据。卷积神经网络是使用梯度下降来学习的,就需要对输入特征进行标准化处理,有利于提升算法的运行效率和学习表现。
2.2.2卷积层
卷积层内包含多个卷积核,利用卷积核可以有效提取输入数据的特征。在卷积神经网络中,绝大多数输入数据的特征提取都要用到卷积层的卷积操作。内积运算是将两个向量对应的标量先相乘,再求和的运算。卷积操作可以理解为内积。原理图如图8所示。
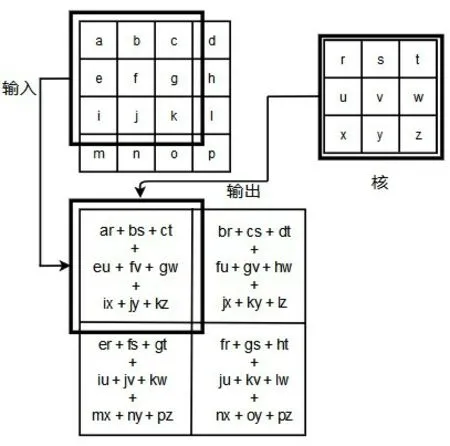
图8 卷积过程
2.2.3池化层
在卷积过程中,常用的池化技术就是均值池化(Average Pooling)、最大池化(Max Pooling)。均值池化是取区域内所有值的平均值作为最后的输出数据,最大池化是取所有值之中的最大值作为最后的输出数据。池化层进行池化操作的目的是缩小图片的尺寸,减小计算量便于处理。池化的作用体现在降采样。池化层在考虑传播方向时,不需要再次考虑更新权重问题,因为它一般不设置参数值。由于相邻像素或区域相关性较大,所以底层信息可能会存在一定的冗余,利用池化层正好可以解决这一问题。池化操作的池化规模一般为2×2。如图9为一个简单的池化过程:
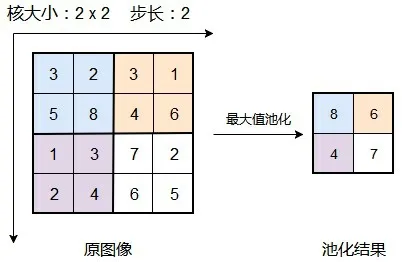
图9 简单池化过程
2.2.4 全连接层
在输出数据之前,至少要加上一层全连接层,它能增强网络的非线性映射能力,限制网络的大小,还可以用来收集更多的信息,尽量地保证网络的性能。全连接层中,每一神经元与前一层的所有神经元相连接,计算表达式为:
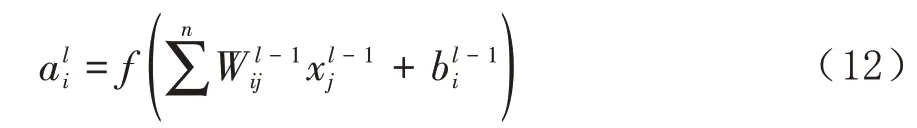
3 基于深度学习的图像去噪实验与分析
3.1 CNN去噪模型
在本次实验中使用的卷积神经网络结构由输入层、卷积层、输出层构成。由于整个网络都用了大小为3*3的卷积核,使得网络变得很简单。
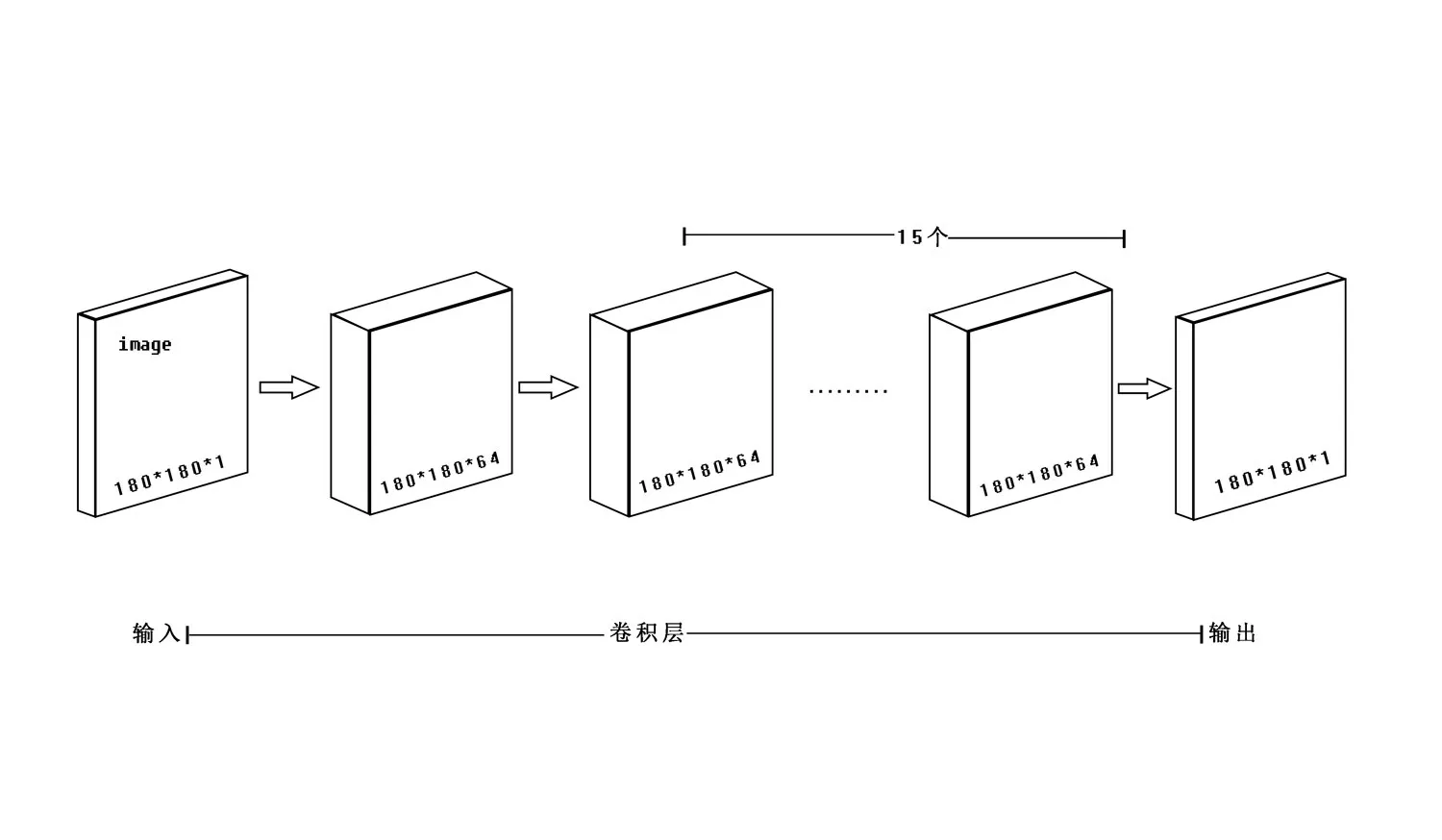
图10 实验中的卷积神经网络结构图
如下表1为每一层的具体数据:

表1 网络层次结构
3.2 实验数据

图11 数据集
本文中采用的是具有明显细节不同特征的400张灰色图像作为数据集来训练模型,以下为数据集的一部分。
这些数据集具有不同的细节特征,有远景、近景,有人脸、动物,这样丰富的数据集使训练出来的的模型并不只适用于某一类图像去噪,而是使训练出来的模型可以广泛运用在不同类型的图像去噪中,从而使模型具有更好的适用性。
本文选取的测试集如图12所示:

图12 测试集
3.3 参数设置
由于是深度网络,所以不需要人工提取图片的特征,直接在输入层将图像输入。本文采用个400个图像大小为180*180的图片来训练模型,卷积层采用了大小一样的卷积核。学习率在网络模型的训练中是一个很重要的参数,学习率如果设置的太小,会使训练时间过长,收敛速度过慢,在长时间的参数更新中,一直会有微弱的噪声。但是,如果学习率设置的太大,会使模型的误差增大,使得网络性能降低。所以,我们在不同的网络中应选择合适的学习率,本文将梯度下降算法学习率设置为0.001。随着迭代次数的增大,去噪效果会越来越好,但是当迭代的次数增大到一定程度时,去噪效果就达到了一个稳定的状态。此刻,就不再需要增加迭代次数了,本研究中将网络迭代次数设置为50次。
3.4 实验结果与分析
首先对实验中采用的测试集,通过添加不同的噪声进行去噪,分别采用噪声标准差为σ=10,15,20,25,35对测试集中的数据进行对比,然后对实验结果进行对比分析。
σ=10时:

经过对比,在不同噪声下的去噪效果,可以发现5幅图中不同的Denoised图像清晰度逐渐降低,但整体去噪效果还是不错的,保留了原始图像的细节特征。实验结果可以很好的说明在不同噪声下的去噪效果,最后与其他去噪实验做对比来更好的说明本研究实验的去噪效果。如表2所示:
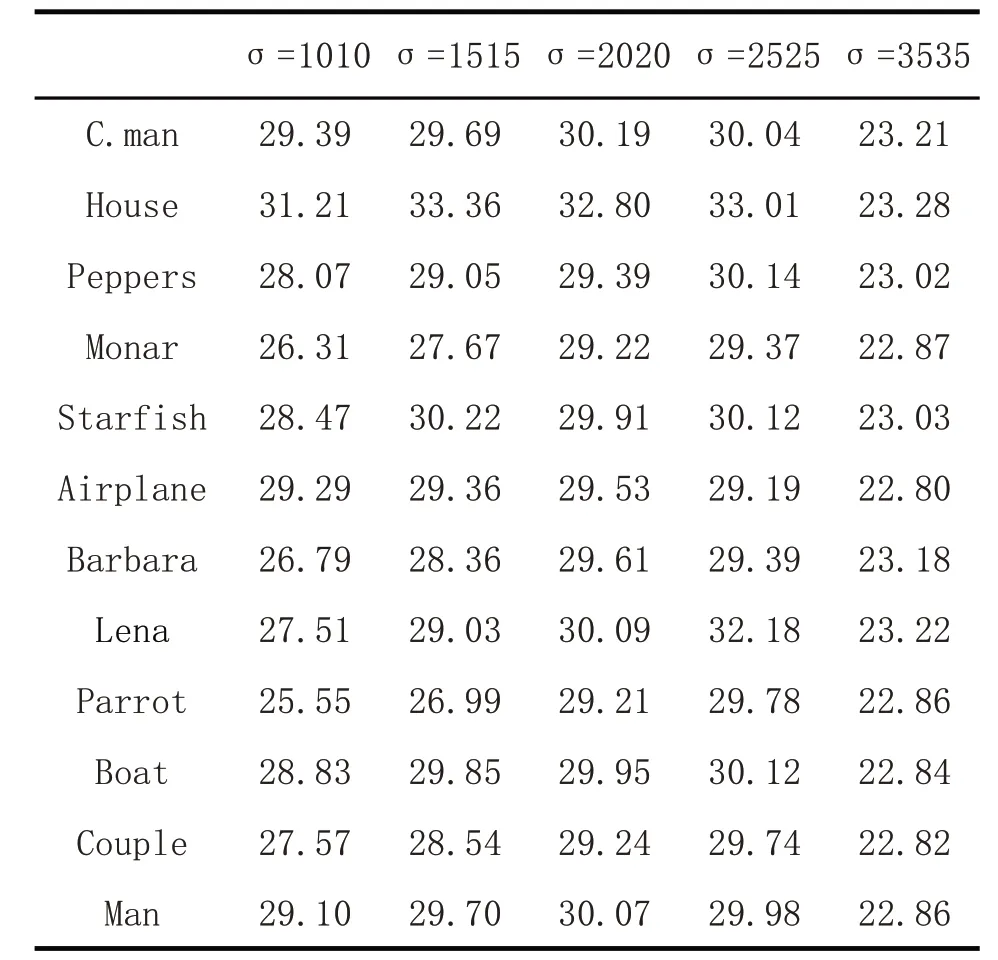
表2 不同噪声下的峰值信噪比
本文采用邓正林去噪实验中的数据[14]与本研究中的数据进行对比,在噪声水平为σ=25时与BM3D、WNNM、MLP在相同测试集下的结果。如表3所示。
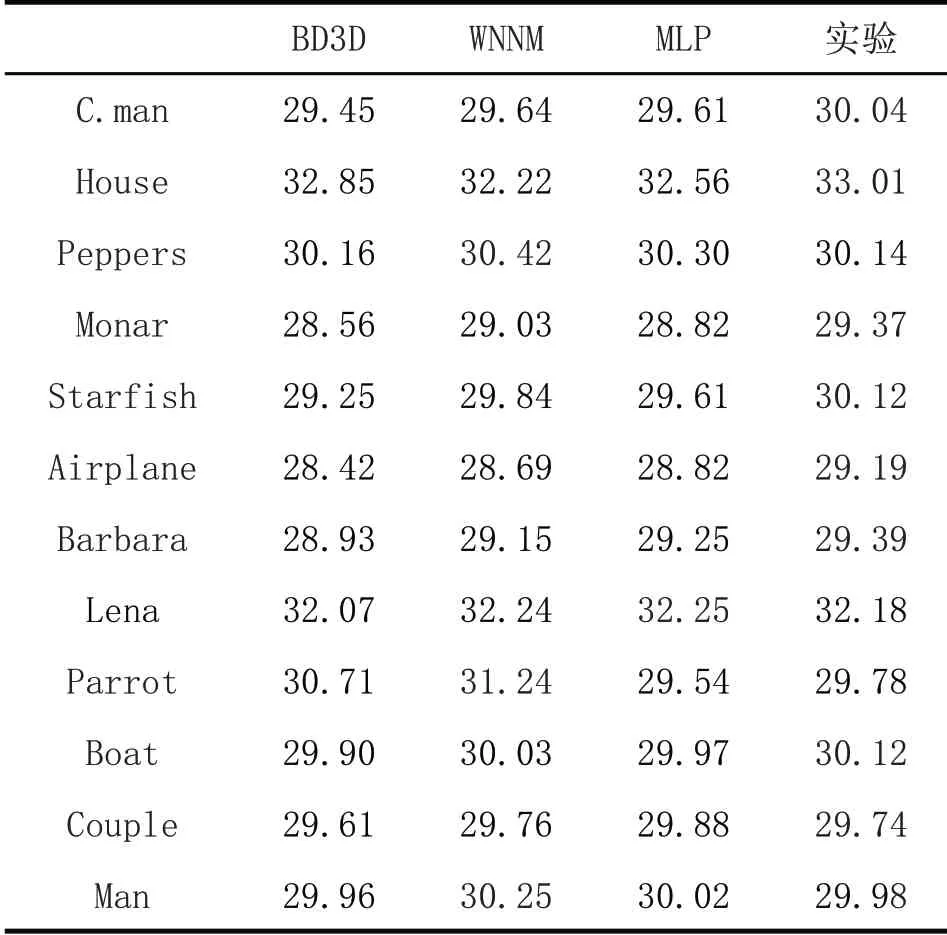
表3 测试集在噪声水平为25时不同去噪算法的去噪结果
通过数据对比分析可以看出,本文的图像去噪效果整体上要优于其它去噪算法的去噪效果。个别图像由于训练模型的数据集小,硬件条件不足,导致某些细节特征未被训练。在以后的研究中将增大训练的数据集,以便达到更好的去噪效果。
4 结语
深度学习在图像识别方面取得了很大的成功,促进了图像去噪的发展,使得在图像处理研究方面有了更好的的发展。深度学习是一种对提取的特征进行学习的技术,它可以模拟出人脑中的神经网络结构,使其具有学习能力。通过对大量数据进行训练,最终可以达到一个良好的效果。
综上所述,本文构建的去噪网络可以获得真实清晰的去噪结果,避免了图像去噪结果中出现边界伪像的现象。
