一种基于深度学习的恶意代码克隆检测技术
2022-03-08沈元严寒冰夏春和韩志辉
沈元,严寒冰,夏春和,韩志辉
(1.北京航空航天大学 计算机学院,北京 100083; 2.国家计算机网络应急技术处理协调中心,北京 100029)
克隆检测主要包括源代码检测及二进制代码检测,广泛应用于漏洞发现、代码克隆检测、用户端崩溃分析等。随着科技的日益发展,大量的物联网设备投入使用,恶意代码分析变得越来越重要。据Gartner分析在2017年时全球已经有84亿物联网设备投入使用,比2016年增长31%,2020年达到204亿[1]。而物联网的快速发展,导致各种网络攻击及恶意代码也随之增多。因此,恶意代码分析变得十分迫切。
同时,由于针对企业或政治动机的高级持续性威胁(APT)攻击的快速增长,APT攻击已经成为网络安全领域的热门话题,这需要安全从业者快速分析恶意软件之间的同源性来确定APT攻击背后的群体。当获得新的恶意代码时,试图检测其是否是通过其他恶意代码的源代码进行编译得到的[2]。众所周知,同家族样本或同类型样本之间存在大量共享代码库。
但是出于不同目的,APT组织包含不同族和不同类型的恶意代码,如Duqu、Stuxnet和Flame属于同一个APT组织[3-7]。大多数恶意软件研究人员致力于分析、检测、家族分类等,但这些努力无法从根本上解决恶意软件的同源性识别问题。因此,安全从业者需要更加关注恶意软件的同源性分析,并发现不同恶意软件之间的同源性,进而挖掘攻击背后的APT组织。
学术界通过利用恶意代码克隆检测来解决恶意软件同源性问题。因此,为了满足处理大样本的需求,需要提出一种能够自动化进行的恶意软件克隆检测技术,从而识别恶意软件的同源性,大量减少了人工分析的工作量,提高了效率。
本文通过对每个恶意软件样本进行静态反汇编分析,再根据函数的控制流图(CFG)构建其自定义函数的反汇编代码文本,以及整个样本的系统函数调用图(AFCG)做为恶意软件的特征进行提取并向量化,换句话说,将恶意软件建模成一种语言,其可行性已经由Awad等[8]验证。构建了一个神经网络模型来对数据样本集进行分类。实验表明,本文方法可以有效地进行恶意代码克隆检测与分类,且获得了较高的准确率和召回率。
同时,本文方法已经证明了自动实现恶意软件克隆检测有助于帮助恶意软件分析师和决策者做出更快的判断,并可以作为自动分析的第一步。
本文的主要贡献如下:
1)将公共威胁情报中的样本集分类到不同的APT组织,并构建APT组织的样本数据库,其中提取了约6 900个样本和约80万个自定义函数。
2)提出了一种新方法,首先对每个恶意样本进行静态反汇编分析,根据样本函数的CFG构建其自定义函数的反汇编代码文本,以及整个样本的AFCG为恶意软件的特征。然后,利用之前构建的神经网络模型CNN-SLSTM,将卷积神经网络(CNN)模型与改进的递归神经网络长期短期记忆(LSTM)模型相结合,对APT组织样本进行分类。
3)通过广泛评估,同时与MCrab模型[9]进行了对比表明,改进模型(GMCrab)优于MCrab模型,可以有效地进行恶意代码克隆检测与分类,且获得了较高的检测率。
1 相关工作
代码克隆检测技术有很多种方法,如传统方法中的静态抄袭检测或克隆检测,包括基于字符串的检 测 方 法[10-12]、基 于 令 牌 的 检 测 方 法[13-15]、基于语法树的检测方法[16-18]和基于程序依赖图(PDG)的检测方法[19-22]。有些方法是基于样本的源代码进行检测,不适用于实践中,尤其不适用于恶意代码。在基于动态标记的方法中,Tamada等[1]提出为Windows应用程序进行API标记;Schuler等[23]提出为Java程序进行动态标记。但是,由于它们依赖于动态分析,很难将其扩展到其他架构并适应嵌入式设备,而且在动态分析中的代码覆盖率问题是一个固有的挑战。
由于研究证明了将机器学习和深度学习技术应用于代码分析的有用性,White等[24]进一步提出了用Deep Repair来检测源代码片段之间的相似性。Mou等[25]提出了基于程序抽象语法树和基于树的CNN来对源代码片段进行克隆检测。Liu等[26]使用了其代码特征调用来表征二进制函数。针对不同架构的相似性检测,Feng等[27-28]提出了一种跨架构二进制相似性检测的解决方法,分别利用传统机器学习和深度学习将函数的CFG转换为用于相似性比较的向量。文献[29]引入了一种选择性内联技术来捕获函数语义,并提取了不同长度的部分踪迹来对函数建模。
虽然恶意代码属于二进制代码中的一种,但因其自身的独特性,并不能完全使用于上述的检测方法。因此在本文中,通过参考上述方法,提出了一种通过利用恶意代码进行反汇提取的新特征来构建恶意代码的克隆检测特征向量,其主要利用恶意软件AFCG及自定义函数的语义特征并结合深度学习技术,通过构建神经网络模型对恶意代码进行克隆检测并对APT组织进行分类。
2 本文方法
2.1 系统模型
本文提出了一种基于深度学习的恶意代码克隆检测技术,该技术可以快速、有效地检测出恶意代码之间的相似性,识别出该恶意代码相关的APT组织类别信息。
本文原型系统模型如图1所示。包括以下主要步骤:①APT样品采集;②原始特征提取;③利用Siamese网络对特征进行清洗,由于一些恶意代码应用了较多的开源库,下载了大量开源库,并使用局部敏感哈希算法通过匹配去除大量公共函数;④分类模型。其中,第①步旨在从公共威胁情报中收集APT攻击的样本。第②步利用反汇编技术提取样本的AFCG及自定义反汇编代码作为样本的原始特征。第③步进行特征向量化并用来作为模型的输入。第④步构建一个神经网络模型来对带有标记的APT组织样本进行分类。系统模型的使用场景如图2所示。通过对已有的知识库进行训练,并建立模型,当发生新的APT攻击时,病毒引擎将首次分析样本。当没有强大的IoC(indicators of compromise)信息(如IP地址、域名、URL等)来确定APT攻击背后的组织时,可以使用该系统来预测和判断攻击背后与之相关的APT组织,并进一步指导领域专家做出判别。

图1 原型系统GMCrab工作流程Fig.1 Prototype system GMCrab workflow

图2 GMCrab部署图Fig.2 Deployment of GMCrab
2.2 恶意代码特征提取
无论是对恶意代码进行检测还是分类,恶意代码的特征提取在整个工作流程中都起着至关重要的作用。
1)恶意代码文本特征。CFG是二进制分析中常用的特征。因此,根据自定义函数的CFG,先通过利用IDA Pro进行反汇编构成CFG,将非循环路径上每3个代码块中的反汇编代码构成1句长语句。根据CFG的执行路径,可以将图3分解为3个块来获得一系列块,如式(1)所示。使用3个序列块中的反汇编代码形成1个块表示该自定义函数的文本。最终对构造的文本进行规范化,并统一标记变量名称和内存地址,以提高系统模型在后续分类任务中的准确率和召回率。


图3 CFG样例Fig.3 CFG example
2)恶意代码AFCG。在本文中,系统函数指的是调用操作系统提供的API函数,如Window系统的MSDN中的API。图4为一个关键函数的示例,该函数调用了2个API,其API序列为Get-FileAttributesA→GetLastError。函数调用图表示样本中函数间的调用关系。由于需要使用AFCG,但是非系统调用函数在整个样本的占比很高,导致系统函数间可能不存在直接的调用关系,需要通过给图的边加入权值来代替图中的非系统调用函数,即AFCG(在函数调用图的基础上将非系统调用的函数去除压缩而成)。将有向无权的函数调用图压缩为有向带权值的AFCG,其权值的赋值遵循以下4个原则:

图4 系统函数调用示例Fig.4 Example of system function call
①若2个系统函数间存在直接调用关系,则权值为1。
②若2个系统函数间不存在直接调用关系,则权值为经过的非系统函数个数加1。
③若2个系统函数间存在多条调用路径时,权值为最短路径跳数。
④若2个系统函数间存在的调用路径都经过另外1个系统函数,则这2个系统函数间不存在直接的有向带权值路径。
3)数据清洗。收集了3 000个良性样本,同样利用反汇编技术收集了约2万个自定义函数的代码片段。利用对等网络架构,通过计算代码片段的局部敏感哈希值进行相似性计算,从而去除与其相似的恶意代码库中提取的函数。最终利用剩下的函数库作为输入特征进行分类。
3 基于深度学习克隆检测算法
本文模型沿用文献[9]中的CNN-SLSTM 模型,该模型的结构如图5所示,其由2个部分组成:①C-LSTM模型中的CNN模型;②改进的SLSTM模型,即引入了结构特征。详细的模型介绍如下:
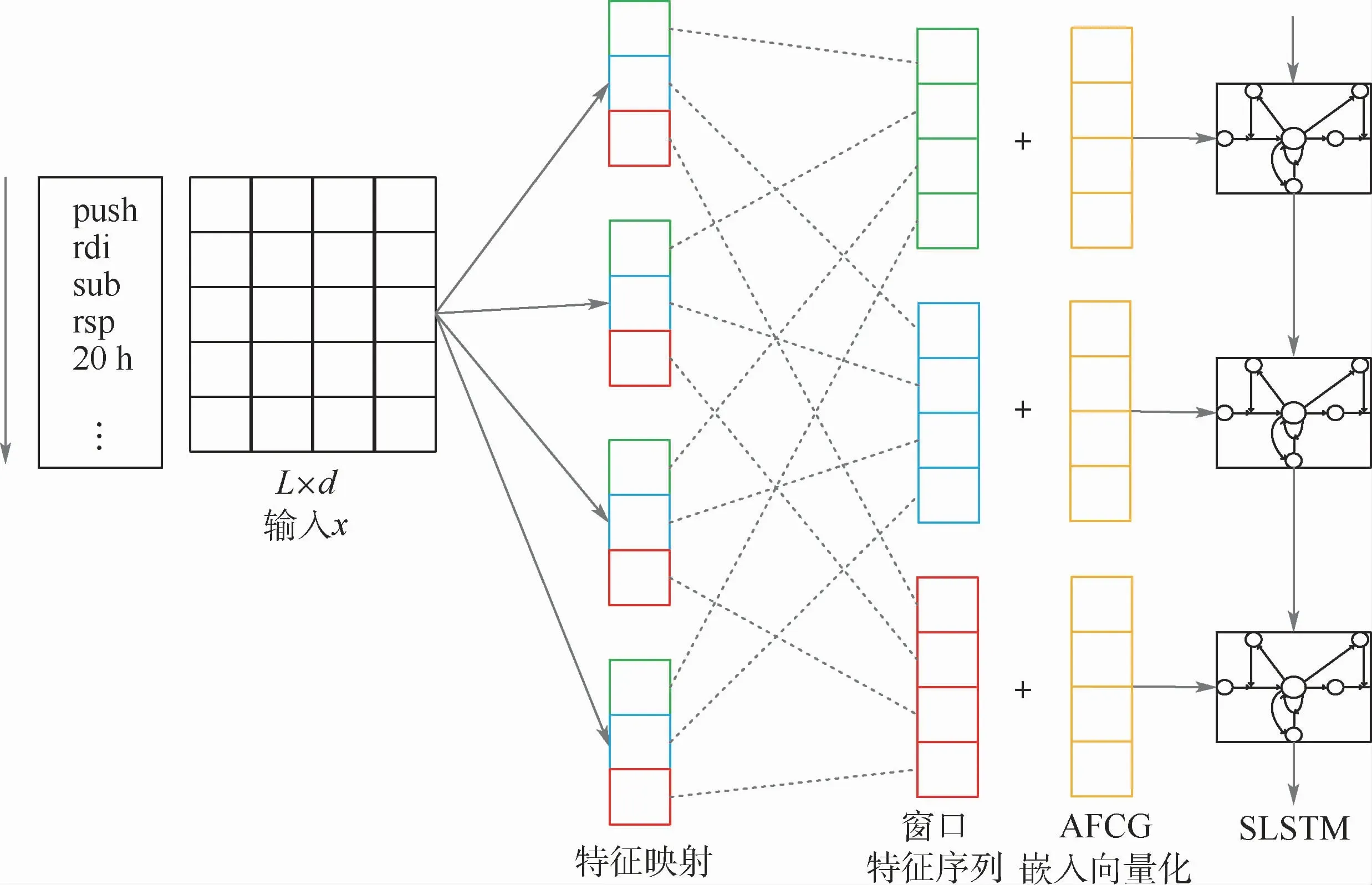
图5 语义模型的CNN-SLSTM的体系结构Fig.5 Architecture of CNN-SLSTM for semantic model
1)通过CNN进行特征提取。对构成的文本特征进行建模,CNN利用卷积滤波器提取句子不同位置上的n-gram 特征,该方法表现出色。文献[30]描述的n-gram特征提取方法即对从样本中提取的CFG反汇编代码文本执行相同的处理。对于文本中的每个位置i,都有1个带有k个连续单词向量的窗口向量Xi,表示为
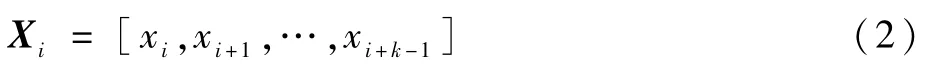
式中:xi∈Rd为反汇编代码文本中第i个字的d维子向量;k为滤波器的长度。
滤波器w 用于生成新的特征映射,公式如下:

式中:L为文本的长度。
特征映射的每个元素ci的产生如下:

式中:b为一个偏置项,b∈R;f为非线性函数(如sigmoid、双曲正切等);w为权值。
选择ReLU作为本文实验的滤波器,通过把滤波器应用于每个窗口xi以产生特征图。

式中:ci为使用第i个滤波器生成的特征映射;每行C∈R(L-k+1)×n,Ci为从位置i处的窗口矢量的n个滤波器生成的新特征表示。
在这些处理步骤之后,可以得到1个高级窗口表示,其将被用作下1个SLSTM模型的输入之一。本文只进行卷积而不在特征映射上应用max-over-time池化操作来获取最大值。这是因为在LSTM被指定用于序列输入,如果使用池化,则会破坏由CNN提取的高级窗口特征。
2)SLSTM 网络。众所周知,RNN[31-32]中的问题在于:在训练期间,梯度向量的分量可以在长序列上呈指数增长或衰减[33]。梯度爆炸或消失的问题使得RNN模型难以学习序列中的长距离相关性,而已经提出的LSTM 模型可以解决特定学习长期依赖性的问题。本文结合恶意代码同源性研究问题,将对应于样本的系统函数调用图结构特征引入标准LSTM模型,并称之为SLSTM。
如图5所示,SLSTM 模型的输入由2个部分组成:①CNN提取的高级窗口表示;②AFCG的嵌入表示。同一个样本中的每个自定义函数的CFG对应相同AFCG,即每个自定义函数的反汇编代码文本对应同样的AFCG结构特征。在图5特征映射层和窗口特征序列层中,相同颜色的块对应于同一窗口特征,虚线将窗口的特征与源特征图连接起来,并且黄色块表示与样本对应的AFCG嵌入向量,其与CNN模型学习的窗口特征一起被输入到SLSTM 模型中。整个模型的最终输出的是SLSTM的隐藏单元。
参考Dai等[34]提出的图形嵌入网络,将AFCG表示为g=<V,E>,其中V和E分别为顶点和边的集合。此外,图中的每条边e都具有附加特征xe,对应AFCG中的边的权值。图形嵌入网络将先计算每个顶点v∈V的p维特征μv,再将g的嵌入向量μg计算定义为这些顶点的聚合,公式为

将μg表示为结构向量S,将由c维图形嵌入和由CNN模型获得的高级窗口表示生成的新连续表示馈送到SLSTM模型中。
在每个时间将SLSTM单元定义为Rd中的向量集合:输入门it、遗忘门ft、输出门ot、存储器单元ct和隐藏状态ht。在模型中,将结构向量S添加到输入门、遗忘门、单元和输出门。改进后的LSTM模型公式如下:

式中:b为偏差项;d为SLSTM 单位的数量;xt为当前时间步的输入;σ为逻辑sigmoid函数,其输出为[0,1];⊙表示数组元素依次相乘;PiS是对原始LSTM等式的修改。
遗忘门控制擦除存储器单元的每个单元的量,输入门控制每个单元的更新量,输出门控制内部存储器状态的曝光。SLSTM 可以处理时间序列数据以学习长期依赖关系,因此,选择其作为CNN模型的下一个输入模型来学习代码段中的依赖关系。最终在SLSTM 模型的最后1个步骤中将softmax层添加到隐藏状态的输出以进行分类。
4 实验与结果
4.1 数 据 集
本文利用2年时间收集了约8 000例不同APT组织样本,其中大部分来源于公共威胁情报,利用情报中的样本哈希值,通过VirusTotal进行检索与筛选,获得与该组织对应的样本文件。基于大量的公共威胁情报,构建了APT组织的样本数据库,并从10个APT组织的6 972个样本中提取了680 718个自定义函数。将这些自定义函数形成数据集并进一步以8∶2的比例随机分为训练数据集和测试数据集,还使用了10%的训练集进行交叉验证,相关统计数据如表1所示。
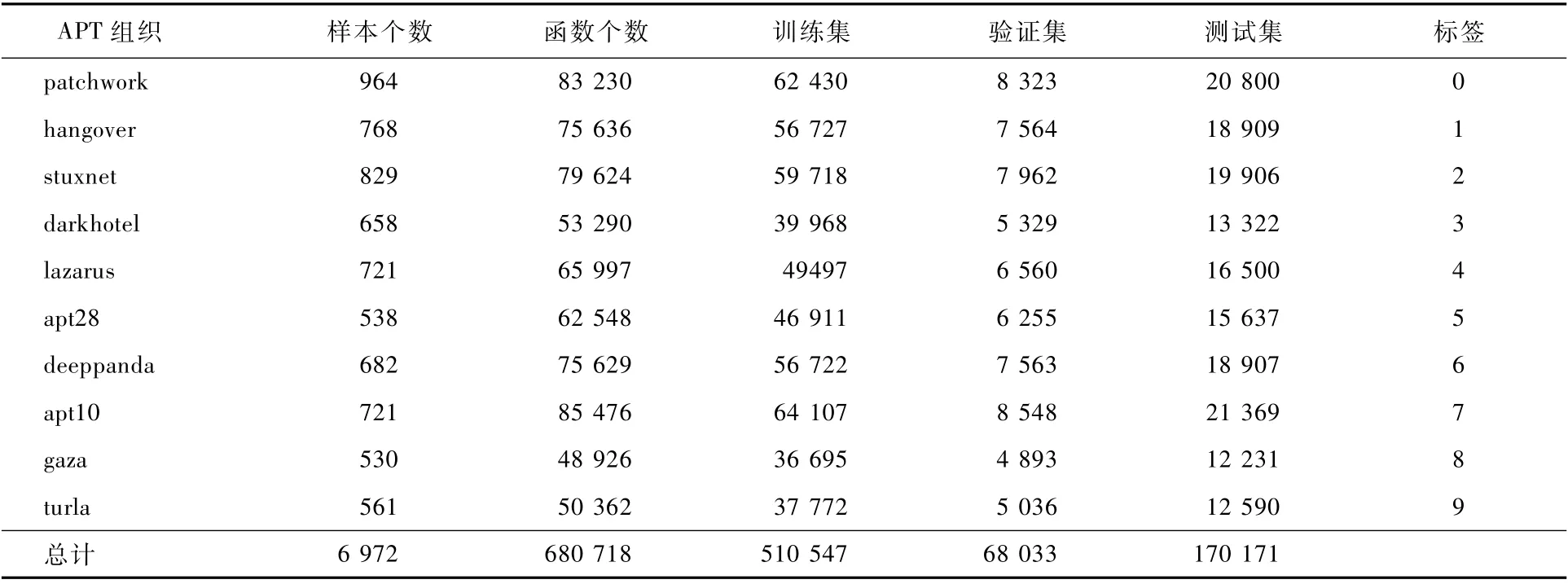
表1 APT组织样本数据集Table 1 APT group samples dataset
4.2 实验环境
在Python中使用TensorFlow实现了本文的模型。利用GPU进行模型训练。在文本表示中,使用word2vec向量初始化单词向量。在最终设置中,使用了整数线性单位,过滤窗口设置为3、4和5,每个过滤窗口得到100个特征图,SLSTM 的内存尺寸为100,随机失活率为0.5,mini-batch设为50,这些值是通过开发集上的网格搜索选择的。本文的模型在单词序列馈送到卷积层之前,将dropout应用于单词向量,并在softmax层之前将其输入到LSTM模型的输出。使用Adadelta更新规则,通过随机梯度下降在乱序的mini-batch上进行训练,同时还在softmax层的权重中添加了因子为0.001的L2正则化。
4.3 模型比较
选择MCrab模型作为比较的基线,2个模型的对比结果如图6所示。此外,还选择了一些比较先进的文本分类方法进行比较,如表2所示。将本文模型与其他模型进行比较,发现CNN-SLSTM模型优于其他模型。总的来说,本文模型显示出强大的竞争力。这说明CNN-SLSTM模型可以学习AFCG的结构特征和其反汇编代码的文本特征。AFCG的结构特征在恶意代码克隆检测问题中具有重要意义。此外,C-LSTM模型的性能优于单个CNN模型和单个LSTM模型,这意味着使用CNN模型提取高级文本表示在学习跨序列的长期依赖性中起着重要作用。在CNN模型中,将其与来自word2vec的预训练向量、微调词向量和多通道进行比较,具有动态k-max汇集的DCNN模型[35]。对于LSTM模型,将其与2个树状结构的LSTM 模型进行了比较[36],同时也与LSTM模型和Bi-LSTM模型进行了比较。此外,将改进的GMCrab模型与MCrab模型进行了对比,发现在准确率上略优于MCrab模型,原因在于:在恶意样本特征提取后做了较好的特征清洗及新特征的选择,提高了模型准确率。
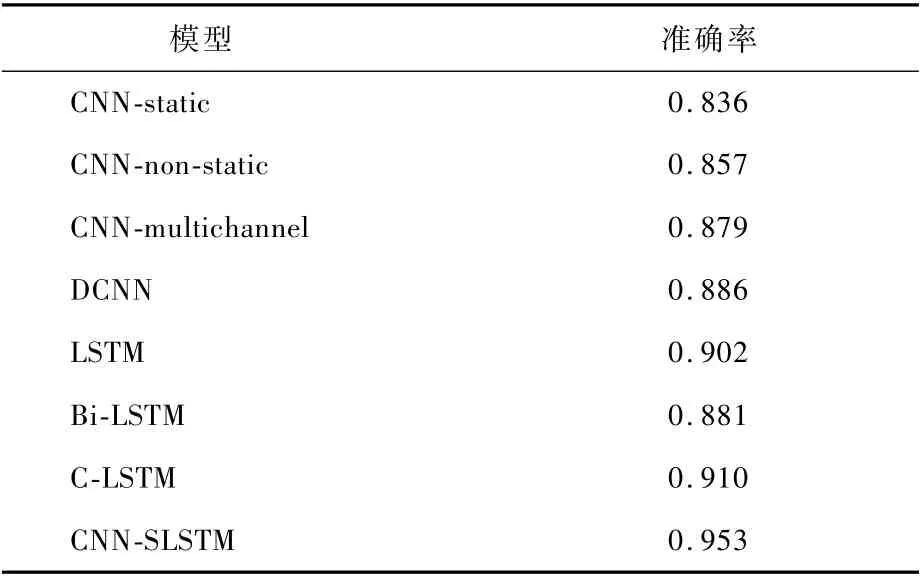
表2 不同模型比较Table 2 Comparison with different models

图6 不同模型的准确率和损失率对比Fig.6 Comparison of accuracy and loss for different models
4.4 模型分析
本节从以下3个方面评估本文模型:①卷积层中不同滤波器配置对模型性能的影响;②数据量对模型性能的影响;③模型在恶意软件同源性分析中的可行性。
1)过滤器大小。在本文模型中,使用CNN模型通过过滤器捕获本地n-gram文本特征。在2种情况下进行了滤波器长度为3,4和5的研究:具有相同滤波器长度的单个卷积层和多个卷积层,并行不同长度的滤波器。对于第1种情况,每个n-gram窗口在卷积之后被转换成卷积特征,并且窗口表示的序列被馈送到SLSTM 模型中。第2种情况使用了不同尺寸的滤波器,因此,在每个卷积层之后获得的窗口数量是不同的。根据最大滤波器长度切割窗口序列来获得最小窗口数。最终每个窗口由来自不同卷积层输出的串联表示。
2)数据大小。为了进一步检查本文方法在不同大小数据集上的性能,以1∶100的采样比率为每个APT组织选择样本,并将数据集分成2个不同大小的数据集。基于上述模型评估了不同大小的数据集,发现SVM在小数据集上的表现优于本文方法。
本节通过介绍数据集、实验环境,以及对实验进行评估,表明了与其他分类器相比,本文方法更具有优势。
5 结 论
本文利用2年时间收集了多达8 000例不同APT组织样本,同时提出了一种新方法,通过对每个恶意软件样本进行静态反汇编分析,再根据函数的CFG构建其自定义函数的反汇编代码文本,以及整个样本的AFCG作为恶意软件的特征相结合,利用神经网络模型(CNN-SLSTM)对APT组织样本进行分类。
通过广泛评估并与MCrab模型进行对比,结果表明,改进GMCrab模型优于MCrab模型,可以有效地进行恶意代码克隆检测与分类,且获得了较高的检测率。但是,一些APT小组恶意模仿其他APT组织的编码风格,会影响模型判断,以后将努力解决这个问题。此外,将扩展数据集添加更多APT组织样本,并更全面地进行恶意软件克隆检测分析。
