基于VMD模型和BSA-KELM模型的高陡边坡位移预测模型研究
2022-02-22孙晓云王明明郑海青
孙晓云,段 绰,王明明,郑海青,靳 强
(1.石家庄铁道大学电气与电子工程学院,河北 石家庄 050043;2.河北金隅鼎新水泥有限公司,河北 石家庄 050200)
滑坡作为一种分布广泛、发生频繁且影响严重的地质灾害,直接威胁着人们的生命安全和财产安全。边坡位移预测作为一种避免滑坡地质灾害的有效手段,已经成为国内外众多学者的热点课题[1-2],具有重要的经济价值和社会意义。目前,常用的边坡位移预测模型可以分为两种,一种是基于力学模型和有限元方法,模拟边坡受多因素影响下的行为特征,进而采用数值方法预测边坡变形[3];另一种是以边坡变形监测资料为基础,结合数学模型进行分析预测,数学模型又可以分为时间序列模型[4]、神经网络模型[5]和各种耦合模型[6-7]。研究表明,对位移序列采用信号分析的方法进行数据预处理可以提高预测性能,基于信号分析的耦合模型受到研究者的广泛关注,周超等[8]提出了小波分解-极限学习机预测模型,但小波分析的分解效果取决于基函数的选取,自适应性差;韩永亮等[9]提出了局域均值分解模型(LMD)、蝙蝠算法优化的极限学习机模型,取得了不错的预测效果,然而LMD模型的迭代次数少,端点效应较轻,判断纯调频信号的条件需要试凑,影响了算法的精度;变分模态分解模型(VMD)相比于EMD模型、LMD模型等递归筛选模式[10],可以更好地分解原始序列。张妍等[11]对比了EEMD-LSSVM模型和VMD-LSSVM模型两种模型对风速预测结果,表明采用VMD模型进行分解可以获得更高的预测精度。
鉴于上述研究,本文以河北省某水泥厂边坡数据为例,首先采用VMD模型将边坡位移序列分解为一系列相对平稳的分量,再利用鸟群算法优化核极限学习机的模型参数,通过对每个分量构建BSA-KELM模型进行滚动预测,最后叠加各分量预测结果,实现边坡累计位移预测。
1 VMD和BSA-KELM预测模型
1.1 变分模态分解
变分模态分解(VMD)是2014年由DRAGOMIRETSKIY和ZOSSO在EMD模型的基础上提出的,不同于EMD模型的递归求解方式,VMD模型是一种非递归、自适应的信号分解方法[12]。其基本原理是把原始时间序列信号分解为K个调频调幅的子信号(IMF),每个IMF是中心频率不同的有限带宽。子信号表示公式见式(1)。
uk(t)=Ak(t)cos(φk(t))
(1)
式中:Ak(t)为瞬时幅值;φk(t)为相位。
VMD模型的具体步骤可以分为构造变分问题和求解变分问题。在设置好模态数K、上升步长τ和惩罚参数α等参数后,变分问题可以表述为满足K个IMF之和等于原始输入信号f的前提下,使得寻求的各IMF估计带宽之和最小,计算公式见式(2)。

(2)
式中:uk为分解得到的K个子信号;wk为各个子信号的中心频率。
引入二次惩罚项α和拉格朗日算子λ将式(2)变成无约束问题(式(3))。
L({uk},{wk},λ)=

(3)

(4)

(5)

1.2 核极限学习机
ELM模型是HUANG等[13]根据广义逆矩阵理论提出的单隐层前馈型网络。由于ELM模型的输入层到隐含层的连接权值和隐含层的偏置无需人为设定,所以其具有结构简单、运行速度快、泛化性能好等优点,因此在分类和回归问题上得到了广泛的应用。当给定训练样本S={(xn,yn),n=1,2,…,N},其模型表示见式(6)。
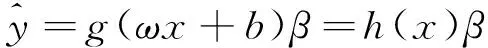
(6)
式中:ω为输入层和隐含层的权值;b为隐含层偏置;g(·)为激活函数;β为输出权重。
通过最小二乘法,求解线性方程组Y=Hβ,并且为了提高ELM模型的泛化性能,引入了正则化系数C,输出权重β表达式见式(7)。

(7)
式中:I为对角矩阵;Y为期望输出。
在此基础上,HUANG等又提出了KELM模型,以核映射替代ELM模型中的随机映射。 定义核矩阵Ω=HHT,矩阵元素ΩELMi,j=h(xi)h(xj)=K(xi,xj),其中,K(·)为核函数。此时KELM模型的输出函数可以表示为式(8)。

(8)
本文选取局部性强、泛化性好的径向基核函数,得到的表达式见式(9)。
K(xi,xj)=exp(-γ‖xi,xj‖2)
(9)
1.3 相空间重构
边坡位移含有非周期运动,具有混沌特性,研究混沌时间序列的基础就是采用相空间重构,在相空间中进行混沌模型的建立和预测。给定滑坡位移序列{x1,x2,…,xN},当设定好嵌入维数m和延迟时间τ,便可将一维时间序列重构成多维的状态空间,表达式见式(10)和式(11)。
Zt={y1,y2,…,yt}
(10)

(11)
式中,t=N-mτ+1。
选择合适的嵌入维数和延迟时间是相空间重构的关键,边坡位移中存在噪声干扰和估计误差,延迟时间不宜过大,并且由于边坡位移数据采样周期长、数据样本少,一般选取1作为延迟时间。而对于嵌入维数一般常采用试算法、饱和嵌入维法和虚假邻近点法,但是嵌入维数的选取与核极限学习机的拓扑结构有关,因此,本文采用鸟群算法确定嵌入维数的值。
1.4 鸟群算法
鸟群算法(BSA)是2015年基于鸟群行为提出的一种群智能优化算法。与粒子群优化算法、遗传算法相比,BSA算法具有优化精度高、收敛速度快、鲁棒性好等优点。BSA算法主要有鸟群的飞行、觅食和警戒三个群体行为[14],其依赖飞行行为跳出局部最优进行全局搜索,通过觅食行为记录个体和群体最后的解,通过觅食和警戒行为的随机切换搜索当前局部的最优解,通过飞行间隔FQ来平衡算法全局搜索和局部搜索能力。鸟群算法流程图如图1所示。

图1 鸟群算法流程Fig.1 Flow of bird swarm algorithm
2 评价指标和算法流程
2.1 评价指标
为了定量、准确地表示预测模型的精度,本文采用平均绝对误差(MAE)、均方根误差(RMSE)和拟合优度(R2)这三个指标对预测结果进行误差分析,具体表达式见式(12)~式(14)。

(12)

(13)

(14)
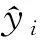
2.2 建模流程
本文提出的VMD-BSA-KELM预测模型建模流程如图2所示,具体步骤如下所述。

图2 VMD-BSA-KELM模型位移预测流程图Fig.2 Displacement prediction flow chart of VMD-BSA-KELM model
1) 使用VMD将原始的边坡位移序列分解为K个子序列。
2) 对各分量分别建立BSA-KELM预测模型,采用BSA算法对相空间重构的嵌入维数m和KELM模型中的惩罚系数C和核参数γ三个数值进行联合优化。
3) 将优化后确定的嵌入维数m代入相空间中对原始序列进行重构,将惩罚系数C和核参数γ带入KELM模型中建立最优模型进行预测。
4) 将各个子序列的预测结果叠加得到最终的边坡位移预测值。
5) 运用式(12)~式(14)进行误差分析。
3 应用实例
3.1 监测点实例分析
本文选取了河北省某水泥厂作为边坡位移监测地点,实际监测中划分了5个监测断面、13个监测点,监测点的布置如图3所示。每个监测点安装一套GNSS监测设备,点位数据通过本地局域网络传输到数据处理中心进行实时存储及数据处理,所有数据均可长期保存、不易丢失,数据可恢复性强,GNSS观测墩如图4所示。
选取了2019年6月—2020年5月实际测量的边坡位移数据进行案例分析,采用了变形量较大的监测点G123作为研究对象。采集数据样本共314个,采样周期为1 d,采用VMD-BSA-KELM预测模型对边坡位移进行提前一步的滚动预测。因采样周期为1 d,提前一步的预测即可提前一天预测出第二天的位移值,多步预测可以得出后几天的值,但是随着步数的增加,累计误差也会激增,因此本文只针对单步预测进行讨论。选取前250个数据为训练样本,后64个数据为测试样本,得到的边坡位移曲线如图5所示。
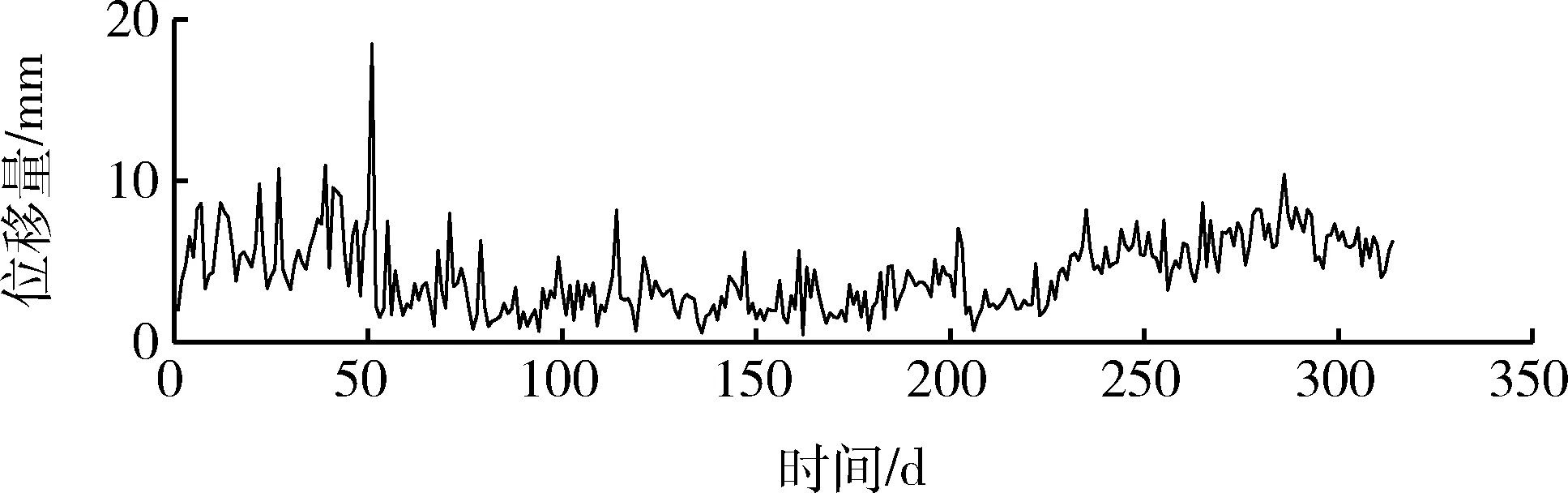
图5 边坡位移曲线Fig.5 Slope displacement curve
采用VMD对边坡位移序列进行分解,在分解过程中,K的取值直接影响着信号序列的分解效果,二次惩罚系数α的值也直接影响模态分量的带宽。本文采用观察中心频率的方法确定K的大小,取K值为5,具体规则可参见文献[15],α取VMD默认值2 000,分解后各分量的频谱如图6所示。
原始数据经过VMD模型分解之后分为5个模态分量,如图6所示。 从图6中可以看出,IMF1的平均振幅是5个模态分量中最大的,达到了4.259 mm,且变化趋势较为平缓,变化周期长,可以看作是边坡受自身内在因素影响的趋势项位移;IMF2和IMF3的平均振幅分别为0.522 mm和0.572 mm,变化趋势有规律性,变化周期短,可以看作是受降雨量、地下水位等外在影响的周期性位移;IMF4和IMF5的平均振幅分别为0.387 mm和0.394 mm,振幅小周期短, 随机波动性强, 且含有噪声分量较多,可以看作是受人为因素等影响的波动性位移。最后,对这5个模态分量分别建立BSA-KLEM预测模型,采用鸟群算法优化嵌入维数m和惩罚系数C和核参数γ三个数值。本文BSA初始参数见表1。

表1 BSA基本参数设置Table 1 BSA basic parameter settings

图6 VMD分解结果Fig.6 VMD decomposition results
预测模型取各分量前250个采样点进行训练,得到最优模型,将建立的最优BSA-KELM模型对5个模态分量分别进行预测,预测值如图7所示。从图7中可以看出,各个模态分量的预测精度都较高,曲线也很好地拟合了原始曲线,各分量评价指标见表2。将5个分量的预测值进行叠加,即可得到边坡位移的预测值。

图7 各分量预测结果Fig.7 Prediction results of each component

表2 各分量评价指标Table 2 Evaluation indexes of each component
为了验证不同模型的预测性能,建立了以下四种模型,并对结果与VMD-BSA-KELM预测模型进行对比分析。①KELM模型:直接建立KELM模型,对边坡位移序列进行1步的滚动预测;②BSA-KELM模型:采用BSA算法优化嵌入维数m、惩罚系数C和核参数γ三个数值的BSA-KELM模型;③EEMD-BSA-KELM模型:采用集合经验模态分解方法(EEMD)对位移序列进行分解,再使用BSA-KELM模型进行预测,EEMD分解结果如图8所示。

图8 EEMD分解结果Fig.8 EEMD decomposition results
所有的训练和测试均在Matlab R2016a软件下运行,采用Intel Core i7-9750处理器,16 G内存的计算机平台。各种预测模型结果如图9所示。
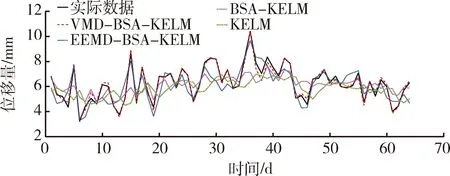
图9 四种模型预测结果曲线Fig.9 Curve of prediction results of four models
从图9中可以看出,直接对原始位移数据进行预测,预测值和实际值偏差较大,在各个突变点上均不能达到预测精度要求。当采用鸟群算法对预测模型进行优化,虽然精度有所提升,但是改善效果并不明显,其原因可能是在KELM模型参数选取时,参数本身偏离最优参数不大,导致鸟群算法提升的空间不大。但是,当采用了VMD模型或者EEMD模型对信号进行分解后,虽然预测时间增长,但是预测精度均优于直接预测的模型,说明合适的信号预处理技术可以有效降低边坡位移序列的突变特性,提高模型的预测性能和精度。
在两种采用了信号分解的模型中,VMD-BSA-KELM模型预测精度明显高于EEMD-BSA-KELM模型。主要原因是EEMD模型分解的高频部分仍表现出复杂的非线性,使得预测精度不佳,而高频部分所占幅值较大,导致整体预测精度下降,其根本原因还是基于递归过程的EEMD模型对原始信号分解不彻底。并且由于EEMD模型分解后的分量较多,各分量都要建立模型进行预测再求和,所以其运行时间也长于VMD-BSA-KELM模型。由于VMD模型对原始序列分解更为彻底,有效地降低高频分量的幅值,使得预测模型在31点、44点、61点等突变样本点的预测值更加接近实际位移值,有效地跟踪位移序列的变化。
从表3中可以看出,VMD-BSA-KELM模型平均绝对误差为0.165 9 mm,均方根误差为0.212 0,拟合优度达到了0.988,各种评价指标均优于其他模型,说明VMD-BSA-KELM模型在一定程度上可以提高边坡位移预测的准确性。

表3 四种预测模型评价指标Table 3 Evaluation indexes of four prediction models
3.2 其他监测点实例分析
为了验证模型的泛化性,选取了三个不同测量点的边坡位移数据分别建立了VMD-BSA-KELM模型,仍然使用前250个数据样本作为训练集,后64个数据样本作为测试集,进行提前一步的滚动预测。 预测曲线如图10所示,评价指标见表4。 三个测量点的平均绝对误差均在0.20 mm以下,均方根误差均在0.23 mm以下,拟合优度均达到0.98以上。

表4 不同测量点的预测结果Table 4 Prediction results of different measurement points

图10 不同测量点的预测曲线Fig.10 Prediction curves at different measurement points
4 结 论
1)直接对边坡位移序列建立预测模型,预测效果并不理想,精度较差。
2) BSA算法对KELM模型参数优化可以提高预测精度,但是提升空间有限。
3) 与EEMD模型相比,VMD模型更适合边坡位移序列的分解,分解更为彻底,VMD-BSA-KELM模型比EEMD-BSA-KELM模型预测精度更高,且运行时间更短。
