齿轮性能退化评估的时序重构模型
2022-02-13张龙黄婧吴荣真宋成洋王朝兵
张龙,黄婧,吴荣真,宋成洋,王朝兵,2
(1.华东交通大学机电与车辆工程学院,南昌330013;2.中车戚墅堰机车有限公司,江苏常州213011)
减少停机时间成本和实现接近零的停机时间是预诊断的最终目标[1]。然而,在实际发生故障之前,如果没有对剩余使用寿命的准确预测,就不可能实现预诊断的所有优点。不准确的预测信息可能会导致不必要的维护,例如部件的早期更换等。性能退化评估(Performance degradation assessment,PDA)是实现预诊断的前提与基础,对充分实现预测维修的潜力起着至关重要的作用。
齿轮作为旋转机械的关键部件之一,其性能的好坏直接决定着设备工作性能的优劣。其一旦发生故障,将直接影响到机械设备的正常安全运行甚至造成重大安全事故[2]。因此如何对齿轮实现在役状态监测和性能退化评估具有重大意义。
对设备的信号进行合适的状态特征提取是故障诊断与预测的前提[3]。振动信号由于具有信息量大、易采集等优点而被广泛采用。常见的基于振动信号的设备状态特征提取可分为时域统计分析(均方根值、峭度、歪度)、频域分析(幅值谱分析、倒频谱分析)、时频域分析(二次型时频分布、小波分析)以及时序模型分析(自回归滑动平均模型、AR 模型)等[4-8]。其中,时序模型分析法,尤其是自回归时序(Autoregressive,AR)模型分析方法,其模型参数因具有表征系统状态的能力且对系统的状态变化敏感程度高,而在故障诊断领域中应用广泛。如文献[9]利用经验模态分解对齿轮信号进行预处理后,再AR 模型表征齿轮振动信号系统,将其自回归系数的混沌特征参数导入支持向量机中,完成齿轮故障诊断。文献[10]先利用小波变换技术对齿轮原始振动信号进行降噪处理,提取降噪后的振动信号的AR 模型系数作为特征,结合主成分分析实现了齿轮故障诊断。
性能退化评估的本质为将待测样本信号与无故障基准模型之间进行相似性度量。近年来,一些概率相似度的性能退化评估模型被相继提出,如隐马尔科夫模型(Hidden markov model,HMM)、高斯混合模型(Gaussian mixed models,GMM)等。基于概率相似度评估模型的核心为建立无故障下的密度模型并以此进行异常检测。如冯辅周等[11]首先提取正常状态下滚动轴承振动信号的小波相关排列熵,并将其作为特征向量构建无故障状态下的HMM模型进行性能退化识别。Heyns等[12]将GMM和负对数似然值相结合进行齿轮状态识别,计算每段信号的负对数似然值作为度量偏离正常信号密度分布的指标,计算信号的角度同步平均来检测是否出现故障,完成对齿轮箱故障位置和故障程度的判断。
基于特征提取的概率相似度评估模型期望通过合适的信号处理方法对相应数据进行深层次的信息挖掘,以提高特征对故障程度的敏感性、一致性等。但在实际应用中仍存在一些问题:1)需要足够大的样本用以训练;2)计算复杂,GMM 及HMM 等的训练和测试过程复杂;3)过早饱和现象,当HMM等概率评估模型方法表明待测样本与无故障基准模型的相似度为零时,存在设备并未完全进入真正失效状态的状况,即模型极限值早于真实失效值。
基于重构的性能退化评估方法通过建立无故障基准模型对待测信号特征向量进行重构,将重构后的差异性来度量设备性能劣化程度。如Zhan 等[13-14]以自适应自回归模型为基础,首先建立一个多工况下健康齿轮振动信号残差最小的折中模型,最后通过残差信号的3σ准则或K-S测试得到性能退化程度指标,有效的避免了概率相似度评估模型所存在的过早饱和现象。
稀疏表征最早由Hubel和Wiesel[15]在1951年研究猫的视觉感受细胞中提出。其基本思想是在过完备字典中以尽可能少的原子实现该信号的简洁表达,近年来大都被运用于机械故障诊断领域当中[16-18],而尚未将其运用于机械设备PDA当中。字典学习作为稀疏分解的一大关键步骤,其本质为一种模式识别方法,将其运用于PDA 的核心思路为通过建立系统或设备健康状态下过完备字典,并以此字典实现对待测特征向量的特征重构,利用待测特征向量于重构特征向量之间的差异性来反映系统或设备的健康状态。
综上所述,本文首先利用AR 模型提取信号的AR 系数作为其特征向量,以此来表征信号的状态特征。将得到的AR 系数作为特征向量输入正常运行状态下得到的字典模型中进行最优重构估计,结合引用的均方根误差作为故障程度指标实现齿轮的性能劣化评估。
1 理论基础
1.1 AR 模型
AR 模型作为一种随机信号参数化建模的重要方法,其将随机噪声定义为白噪激励线性系统的响应,通过参数模型对信号进行描述[19]。AR 模型的参数对系统状态变化敏感,且能够表征系统状态特征,故将其作为多变量状态估计的输入参数。
取时间序列x(t),AR 模型的分析阶数为p,则关于时间序列的p阶AR 模型可以表示为
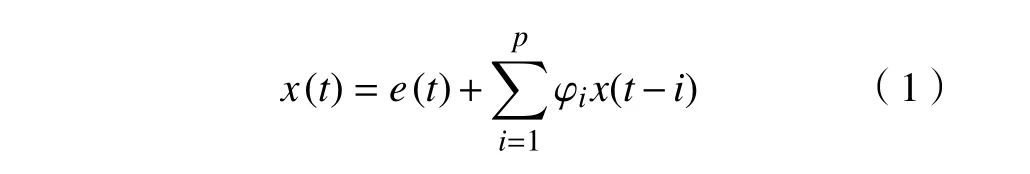
式中: e(t)为 AR 模型的残差; φi为第i 项的系数。
AR 模型参数估计的本质为选取合适的AR 系数使模型的残差 e(t)为高斯白噪声。本文用最小二乘法和BIC准则分别计算模型系数和选择模型阶数。具体步骤如下:
1)首先确定一个AR 模型合适的分析阶数p,这里取分析阶数p分别取1,2,···,100;
2)通过最小二乘法分别求的各阶次下的自回归参数 φi(i=1,2,···,100),构造式(1)所示的AR 模型,进而得到残差 e(t);
3)分别计算各阶次残差 e(t)的BIC 值,根据所得BIC值最小确定各阶次所对应的最优阶数。
1.2 稀疏表示理论
信号稀疏表示是信号处理中一个重要的领域,目的是在已知的冗余字典中找到较少的原子线性组合来表示信号。假定一个信号矩阵Y={y1,y2,···,yn,}, 字典 D={d1,d2,···,dk,},且D 为过完备冗余字典,即k≫n,根据稀疏理论,信号Y 可以分解为
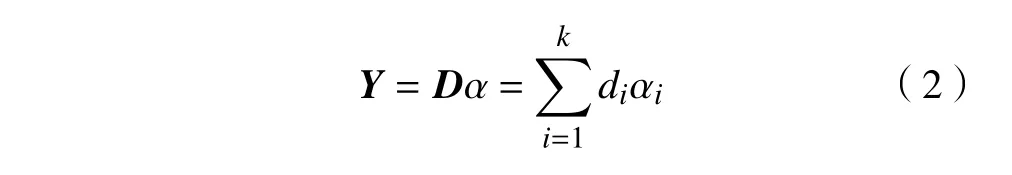
式中:α为Y 在字典D 下的稀疏表示系数,α=[α1,α1,···αk]T。
由于 k ≫n,表达式欠定,需要增加约束条件得到最优解的系数,在稀疏问题中需要得到最少非零值的系数[20],其表达为

式中‖·‖0为l0范数,代表一个向量中非零值的个数[21]。
但是在实际求解中 l0范数是难以优化求解的,会导致NP难问题, l1范 数是 l0范数的最优凸近似,l1范 数相较 l0范数更容易优化求解,其优化式为
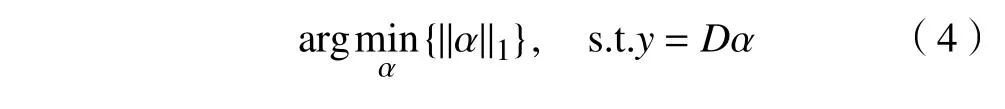
式中 ‖·‖0为 l1范数。
式(4)可以转化为
式(5)的字典求解部分可以写成[21]
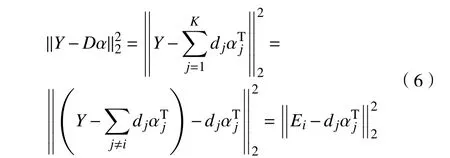
稀疏表示过程可分为字典学习和信号的稀疏编码两部分。最优方向法(Method of optimal directions,MOD)[22]和KSVD(K Singular value decomposition)[21]等算法通常用于字典学习,基追踪(Basic pursuit,BP)、匹配追踪(Matching pursuit,MP)[23]和正交匹配追踪(Orthogonal matching pursuit,OMP)[24]等算法通常用于求稀疏编码。在本文中采用KSVD进行字典学习,OMP进行稀疏编码。由于字典学习和稀疏编码属于同一个优化求解过程,所以在本文中两者统称为字典学习。
1.3 字典学习算法
KSVD属于迭代算法的一种,它通过对字典原子稀疏编码和更新字典原子两部分来更好地拟合数据。更新字典原子时对误差矩阵进行SVD分解,根据误差最小原则,更新后的字典原子和对应的系数使用误差最小的分解项代替。
KSVD的实现步骤如下:
1)字典初始化:初始字典选择训练样本集Y ∈Rm×n中随机的K 个列向量,D(0)∈Rm×K,K<n。设置迭代指标J=1。
2)稀疏编码:利用步骤1得到的字典D(J),对样本集中每一个样本 Yi通过OMP算法计算系数向量 αi。
3)字典更新:每次更新一列,逐列更新字典D={d1,d2,···,dk,}。当更新字典第i 列原子 di时,误差矩阵 Ei的表达式为
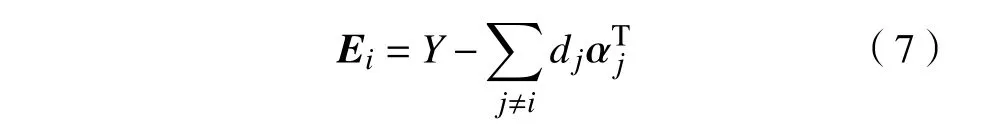
式中 αTj为α 中的第j 行。
取出稀疏矩阵第i 行向量 αTj中不为0的集合xTi和对应的位置索引集 ωi:
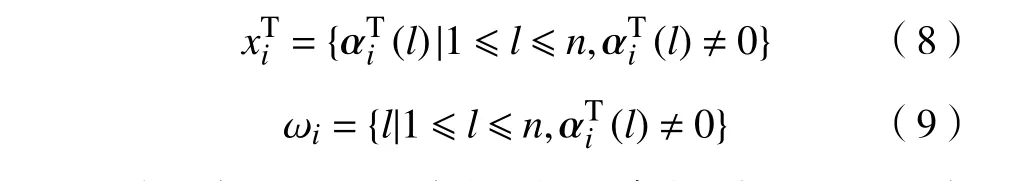
从 Ei中取出 ωi对 应的列,组合得到 Ei′,对 Ei′进行奇异值分解为Ei′=UΔVT,取U 的第1列来替换第i 列的字典原子 di,取Δ(1,1)与V 的第1列的乘积x′Ti=Δ(1,1)V(:,1)T来 替换 xTi,完成更新。设置J=J+1。
OMP的实现步骤如下:
步骤1对于给定的正交字典,计算信号 yi和每个字典原子的内积,找到内积最大时对应的字典原子 dr1,该原子为 yi最匹配的原子,其表达式为
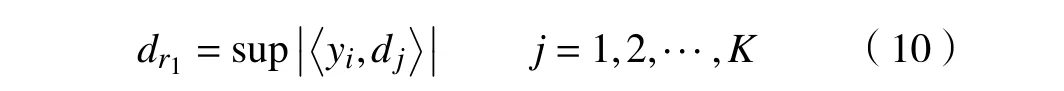
yi第一次分解可被分解为 dr1的垂直投影分量和残值两部分,其表达式为
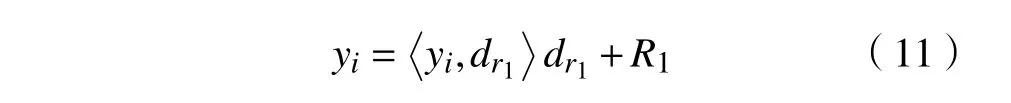
步骤2对残差 R1同样进行步骤1的分解,可得到第二次分解。分解次数根据稀疏度或精度要求确定。经过K 步分解后,可得残差 RK的表达式为
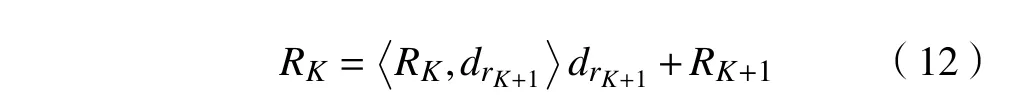
步骤3 yi信号分解计算式为
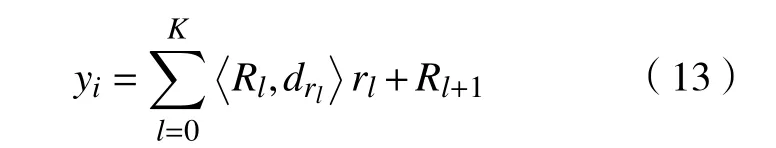
式中R0=yi,即可完成OMP分解。
2 基于字典学习的性能退化评估模型
使用字典学习算法建立性能退化评估模型,训练阶段使用无故障样本的AR 模型系数作为字典学习的训练数据进行KSVD计算,可得到对应的基准字典Dnormal,该字典只适用于无故障状态信号的稀疏表示,其他故障状态的信号在Dnormal上不能很好地进行稀疏表示。当测试信号的AR 系数与无故障样本的AR 系数相似程度较高时,在Dnormal上 进行稀疏表示得到的重构AR 系数和残差与测试信号的AR 系数和残差误差较小,表明该测试信号故障程度较小。同理当测试信号在基准字典得到的重构AR 系数和残差的重构误差较大时,表明该测试信号与无故障状态信号差别较大,此时故障程度也较大。使用均方误差(Mean squared error,MSE)来检测重构值和原值之间的偏差,并作为故障程度评估的指标DI。MSE 表达式为
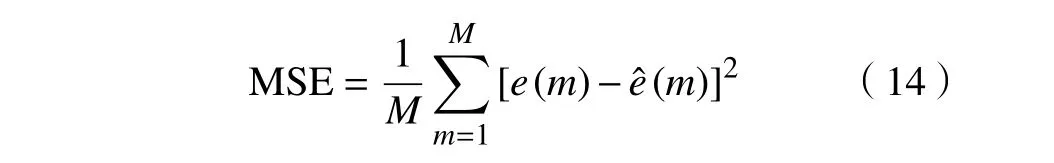
基于自回归模型和字典学习对齿轮故障程度进行评估的流程如图1所示。
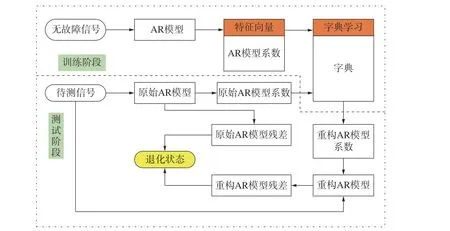
图1 齿轮性能退化评估流程图
齿轮性能退化评估主要过程如下:
1)采集齿轮无故障信号构建自回归模型,得到无故障信号的AR 模型系数和残差,将AR 系数进行KSVD计算得到基准字典 Dnormal。
2)计算待测齿轮信号的AR 模型系数和残差es,使用OMP在基准字典Dnormal上计算AR 系数的稀疏系数并重构AR 系数,带入待测信号的AR 模型中计算重构残差 er。
3)计算残差 es和重构残差 er的MSE值,作为退化指标DI来评估齿轮故障程度。
3 疲劳实验数据分析
3.1 数据说明
实验数据来源于法国CETIM 的齿轮全寿命实验数据[25]。实验对象为一级减速齿轮箱,圆柱齿轮齿轮箱详细参数见表1。
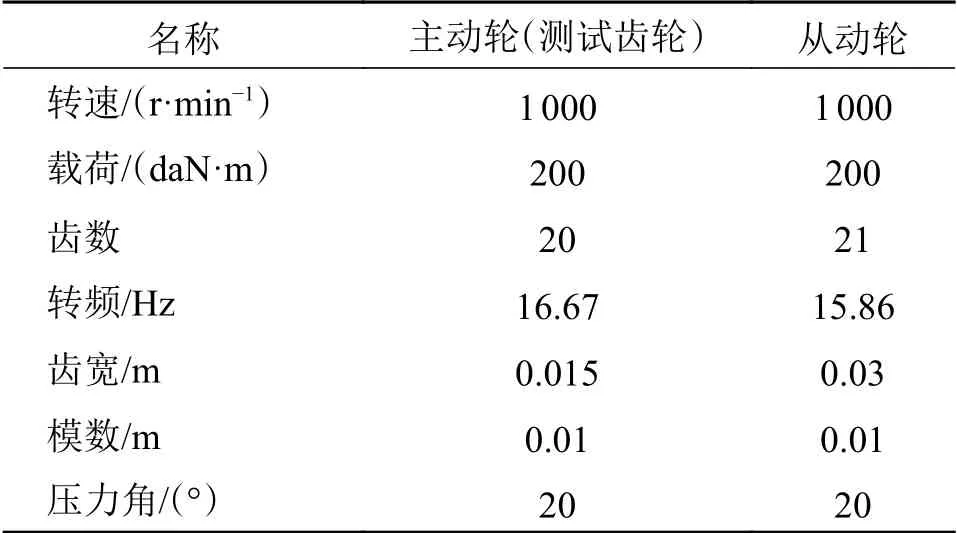
表1 圆柱齿轮齿轮箱参数
驱动马达转速为1000 r/min,齿轮啮合频率为330 Hz,信号采样频率为20000 Hz,以主动轮为测试齿轮,每天采样一次,每次采样时长3 s,一次采样60000个数据点。每天采样结束后停机一次观测齿轮的状况,观测结果如表2所示。在第6 d 测试齿轮的第二齿出现剥落,但直到失效前剥落范围并没有扩大,在第8 d 第十六齿出现早期剥落并在第12 d齿轮全面剥落后停机。图2a)和图2b)为主动轮第10 d 和第11 d第二齿发生剥落故障的齿面照片,可以看出此时故障程度相同(图中黑色圆圈表示齿面剥落面积,面积的尺寸大小可反映故障的严重程度),而从图2c)看出第11 d第十六齿的剥落面积较大。结合图3可知,剥落故障只有在剥落面积较大时才能在时域波形图上变现出明显的冲击特征,所以齿轮的失效主要是由第十六齿的较大面积剥落引起。

表2 齿轮箱疲劳试验每日停机观测结果

图2 齿轮故障程度
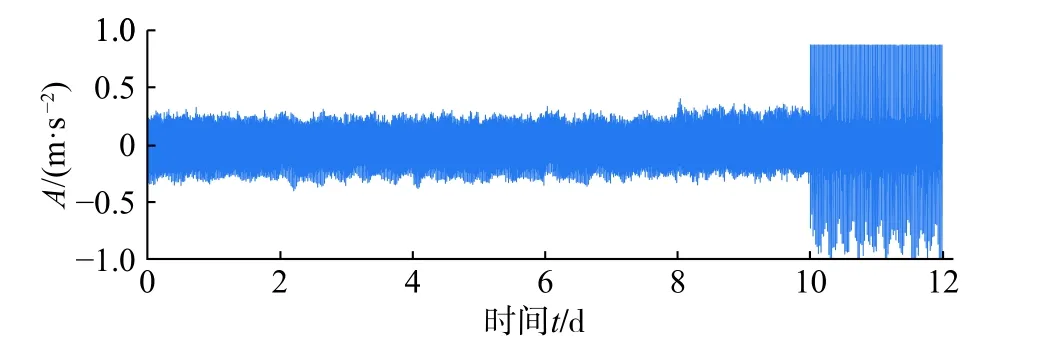
图3齿轮全寿命时域图
图3 是齿轮全寿命的时域波形图,图3中第1 d到第10 d 的振动信号幅值变化不大,在第11 d 幅值才增大,有明显的瞬态冲击成分,齿轮进入失效状态。图4是齿轮信号在第1 d,第10 d 和第11 d的包络谱,第1天到第10 d 齿轮的啮合频率及其谐波分量能量较大(fm为啮合频率,2fm为谐波分量),可以反映此时齿轮为正常状态。第11 d 的包络谱以转频为主,此时齿轮出现局部异常。
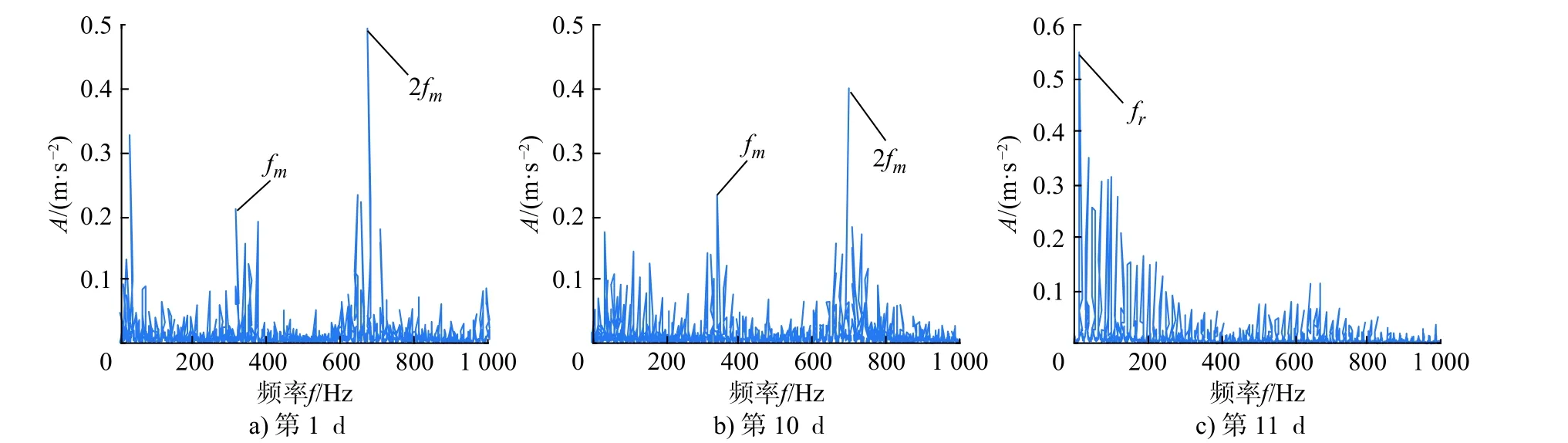
图4 部分信号包络谱
3.2 性能退化评估
首先计算常用的6个时域指标,将齿轮数据中每天的数据作为一个样本,共12个样本,时域指标图如图5所示。在图5中均方根值、峭度值和波形因子在前10个样本即前10 d 变化不大,在11个样本之后发生较大面积剥落时才发生显著变化,而且均方根值在前10 d 还呈现下降趋势,可能的原因是前几天齿轮处于磨合状态,振动能量较大。峰值因子、脉冲因子和裕度因子后期曲线与实际观测结果较为一致,但前期的故障趋势并不明显。时域指标图表明常用时域指标不能很好地反映齿轮故障的趋势,对早期故障不敏感。
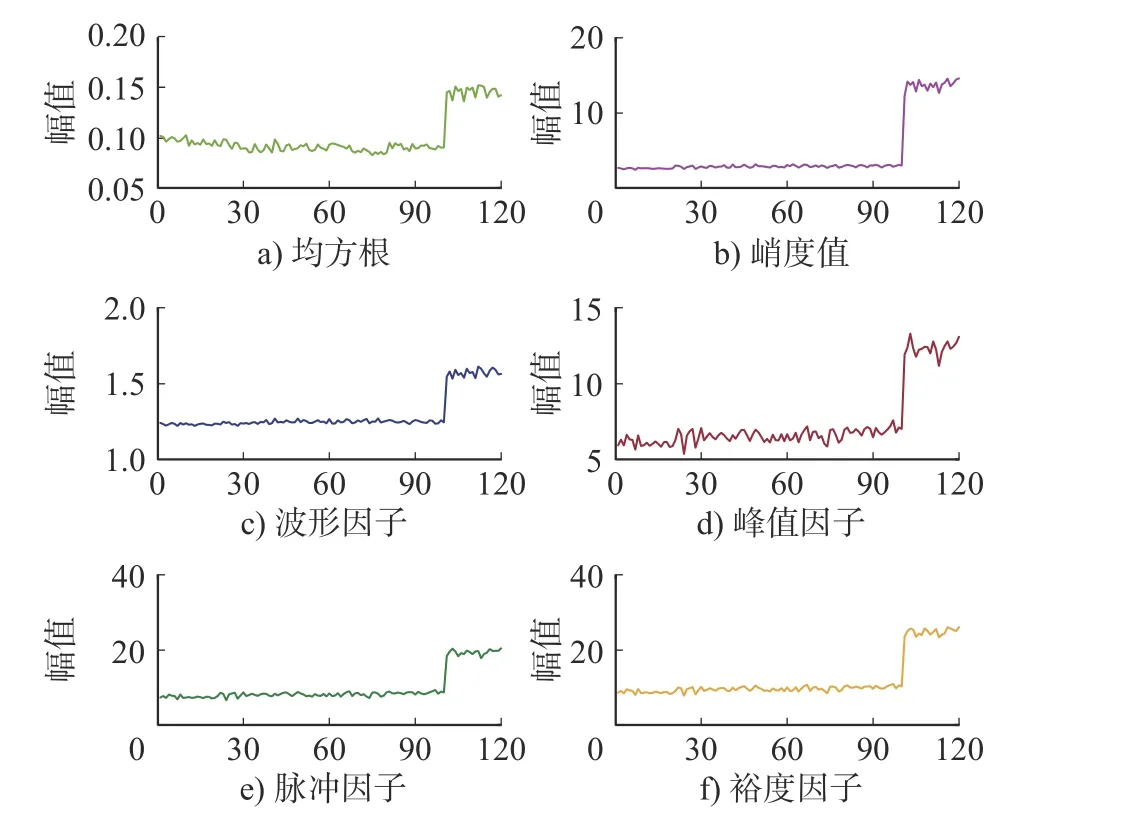
图5 齿轮时域指标图
使用上述所提模型对齿轮数据进行性能退化评估。将原始数据按时间顺序分割为120个样本,每个样本包含6000个数据点,其中每10个样本对应一天的采集数据。根据1.2节所述,在字典学习中为了得到冗余字典需字典原子个数大于字典维数,而字典原子维数与信号段维数相同,这就需要在实际操作中采集更多的信号样本。针对本案例数据信号样本较少的情况,可将原始数据进行扩充来丰富训练样本。
训练阶段使用前35个样本作为测试样本,为避免相邻信号段间的人为边界干扰并保持因划分产生的冲击时移的鲁棒性[26],使用循环移位的方式对样本数据进行扩充,将每个基准样本段进行10次循环移位后扩充为10个样本段,扩充后得到350个测试样本。图6为循环移位过程。其中x1为原始信号,x2为循环移位后的新信号,n为信号数据点数,n1为循环移位的位数,n2为固定不动的位数。整个过程为:将样本信号段x1的前n1个数据点顺序不变移动到信号段的末尾,生成新的信号段x2,完成一次循环移位。本文中n1=1。
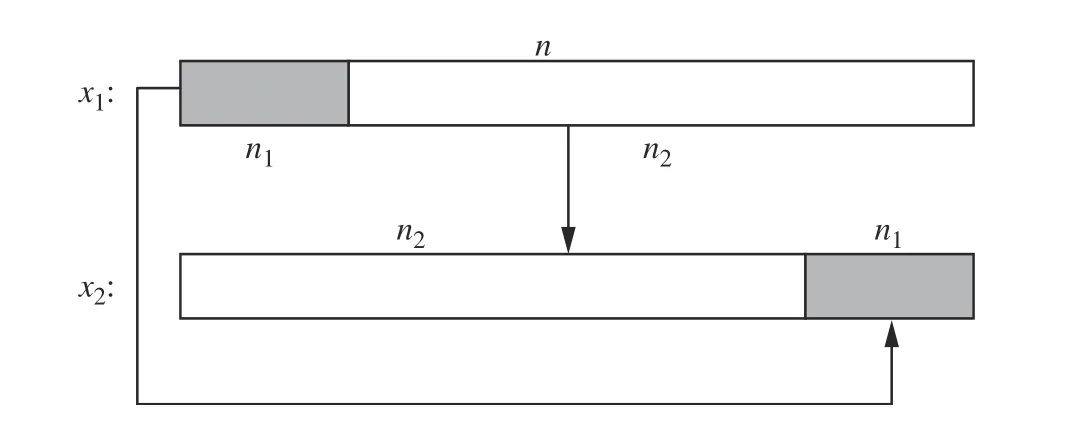
图6 循环位移
AR 模型建立阶段,采用BIC准则确定最佳模型阶数,BIC值变化曲线如图7所示,可知最佳模型阶数r=80,使用Burg 算法可计算得到训练样本的AR 系数。
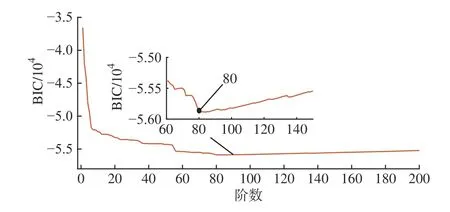
图7 BIC 值变化曲线
使用所提模型进行评估前需要先对超参数进行优化选择。模型中涉及到的主要参数有字典原子维数n,字典原子个数K,训练样本的样本数N,稀疏度L,迭代次数I。由上述已知字典原子维数n= 80,训练样本原子数N =350,为对剩余的超参数进行优化,本文采用单因素分析法。即分析某一参数时,将其他参数固定,来检验此参数对模型的影响。引入均方根误差(Root mean square error,RMSE)作为评价标准,RMSE 表达式为
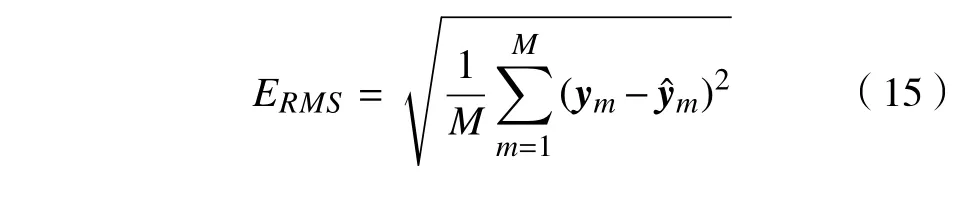
对字典原子个数K 进行分析时,为保证字典是冗余字典,选择K 的取值范围为80~340,间隔为10,其他两个参数分别随机设置为L=14,I =30,使用KSVD和OMP算法进行字典学习重构,得到不同字典原子个数对应的均方根误差变化如图8所示。由图8中可知当K =270时重构误差最小,且满足冗余字典的要求。而随着字典原子维数的增大,K 越趋近于训练样本原子数时重构误差变得越不稳定,综合分析后K 取270。
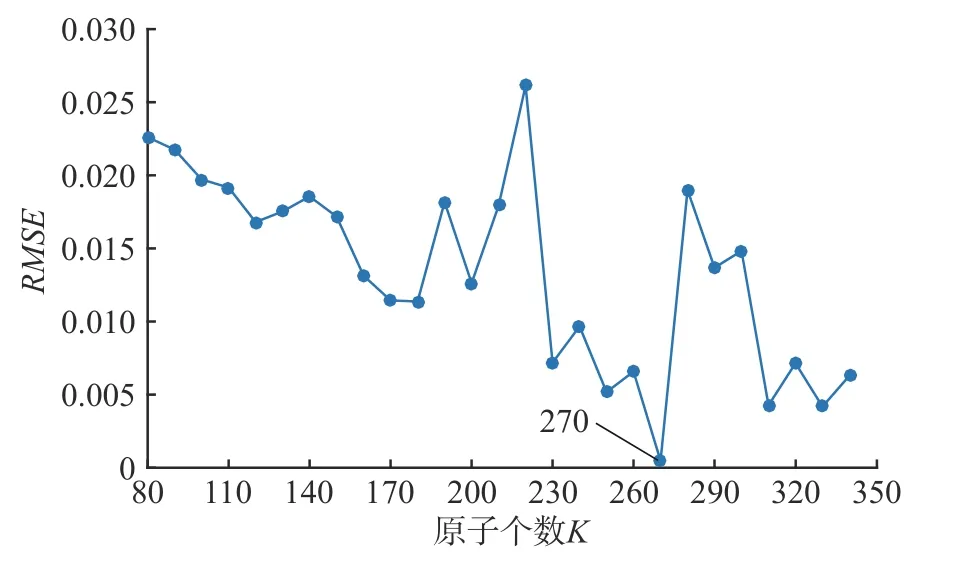
图8 字典原子个数K 值不同时的RMSE
分析稀疏度L对重构误差的影响时,字典原子维数n,训练样本原子数N,字典原子个数K 均已确定,选择稀疏度L的取值范围为1~40,间隔为1。图9为不同稀疏度L对应的均方根值误差变化,图9中可以看出当L=12时重构误差最小,且随着稀疏度L的增大重构误差趋于稳定。而L的增加,会使计算时间显著增加,故L选择12较为合适。
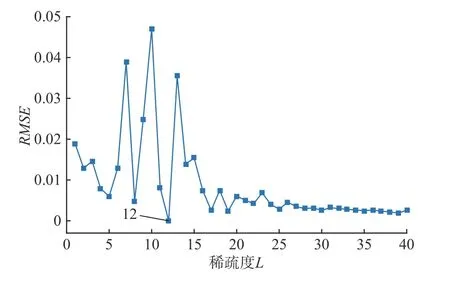
图9 稀疏度L 不同时的RMSE
最后对迭代次数I 进行分析,设置I 的取值范围为1~ 40,间隔为1。不同迭代次数对应的均方根值误差变化如图10所示。图10中可以看出,I =32时RMSE 最小,选取最优参数I = 32。
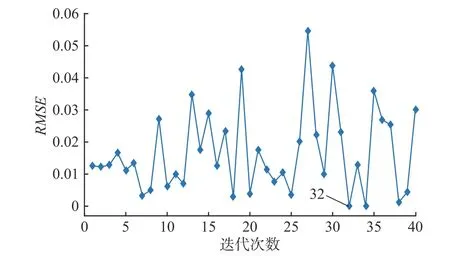
图10 迭代次数I 不同时的RMSE
综上分析,字典学习的主要参数选择为:字典原子维数n=80,字典原子个数K =270,训练样本原子数N = 350,稀疏度L=12,迭代次数I =32。
将齿轮全寿命数据输入模型中,得到齿轮性能退化评估结果如图11所示。实线为故障程度指标DI 值,点划线为3σ 自适应报警阈值。从图11中可以看出,前40个样本即前4 d 的DI 值较低,齿轮处于正常状态。曲线在第41个样本处超过了一级报警阈值,并在第41个样本到第80个样本的DI 值出现反复波动,可认为此时出现早期故障。第81个样本处出现第二次增幅,超过了二级报警阈值,表现出故障程度的加深。第101个样本处退化曲线发生较大增幅,之后一直处于较高的幅值,表明此时齿轮失效。
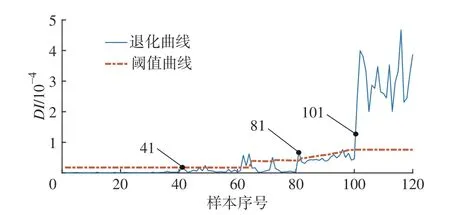
图11 前35 个样本训练的齿轮性能退化曲线
将退化曲线与表2的停机观测结果进行对比,可以看出退化曲线的3个故障阶段与观测结果大致吻合。观测结果显示第6 d 结束时观测到齿轮出现剥落,而退化曲线在第5 d 的样本处出现波动异常超过报警阈值,评估结果比肉眼观测结果提前一天发现早期故障,可能的原因有两种:一是本文的退化评估方法存在问题出现误报,或者并不适用于当前所用案例;二是在第5 d 时已经出现了剥落裂纹,但由于裂纹较小肉眼不容易观测,故观测人员认为第5 d 没有出现故障。退化曲线在第9 d 时有激增,超过第二报警阈值,而观测结果为第8 d 出现第十六齿的早期剥落,可能原因为第8天结束时才产生剥落,随着剥落程度的加深,第9 d 的剥落增大使退化曲线出现明显增幅。
针对上述问题进行进一步分析,如果第5 d 时第二齿就出现了剥落,则认为第41个样本到第80个样本都处于同一故障水平,如果使用前50个样本作为训练样本训练字典,则字典中包含了早期故障成分,可能会使前80个样本都可得到误差较小的重构而被判定为无故障状态。分别使用前40个样本和前50个样本进行训练,得到如图12和图13所示性能退化曲线。从图12和图13可以看出使用前40个样本训练得到的结果和前35个样本训练得到的结果是一致的,而使用前50个样本为训练样本得到的性能退化曲线前80个样本的DI 值都处于较低水平,到第81个样本才发生激增超过报警阈值,因此表明之前推断正确,即第50个样本处已经产生早期故障。
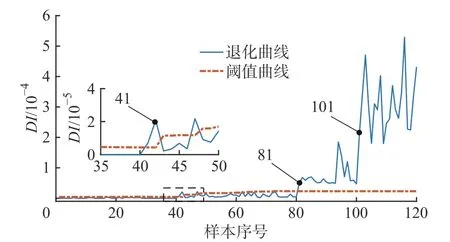
图12 前40个样本训练的齿轮性能退化曲线
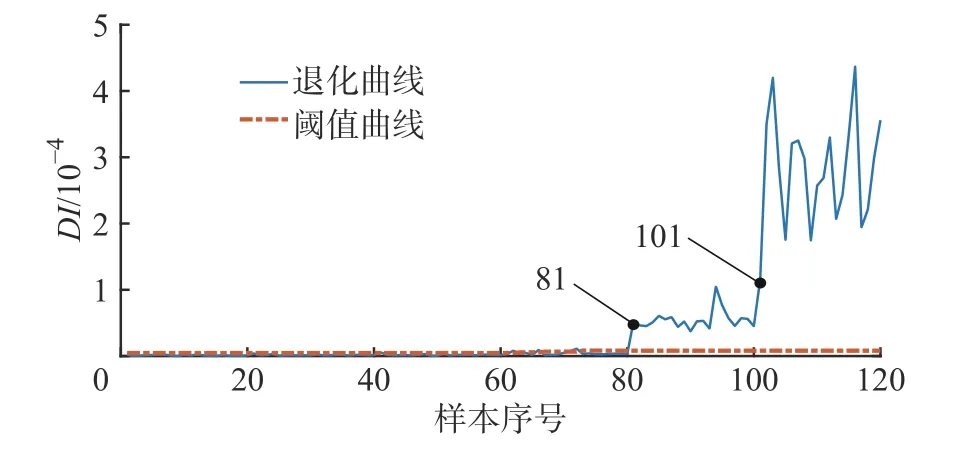
图13 前50个样本训练的齿轮性能退化曲线
文献[27]也对该齿轮数据进行了分析,将数据特征进行LLP降维后使用基于概率相似度的耦合隐马尔可夫模型进行性能退化评估,评估结果如图14所示。文献[27]中将退化过程也分为了4个阶段:第1阶段第1 d ~5 d,为无故障阶段;第2阶段为第6 d~8 d,由于第二齿开始剥落指标出现波动,进入轻微故障阶段;第3阶段为第9 d ~ 10 d,由于第十六齿的剥落故障程度进一步加深;第4阶段为第11 d ~12 d,齿轮严重剥落进入失效阶段。与本文方法进行对比,本文所得结果在轻微故障阶段的指标波动较为明显,且在第5 d 时监测到早期故障的出现,表明本文方法对故障更加敏感。在第十六齿剥落的早期阶段,两种方法的评价结果都显示在第9 d 出现剥落,晚于观测结果,可能的原因是第十六齿的早期剥落响应被第二齿的剥落所淹没,表明所提方法对故障位置的检测还有待加强。总体而言本文所提方法对故障程度的评估更为准确。
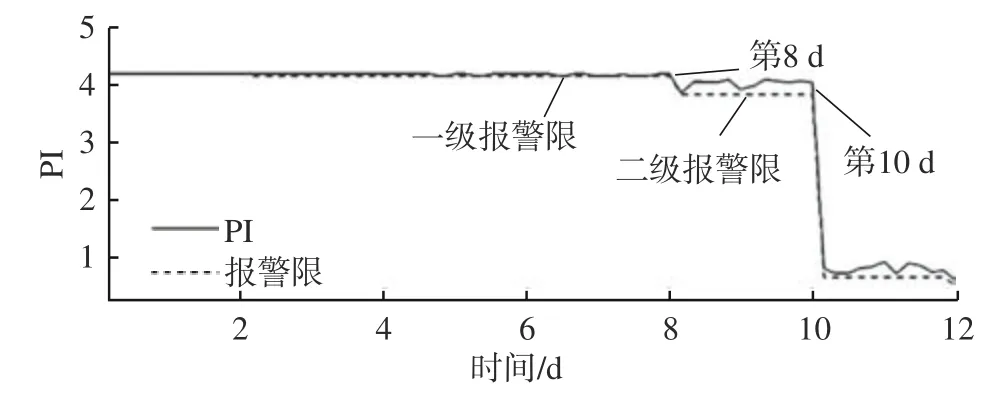
图14 基于LLP和耦合隐马尔可夫模型的齿轮退化评估结果
4 结论
论文针对基于概率估算模型的评估方法存在的过早饱和现象,将目前运用于故障诊断领域的字典学习引入其中,提出一种基于AR 模型和字典学习相结合的齿轮性能劣化评估方法。通过全寿命疲劳试验数据分析处理,发现在整个性能退化曲线中,故障程度指标DR 值与故障发展趋势的一致性更好;相比与传统的时域指标,该方法能更为及时地发现轴承早期故障,为设备维护提供更为精确的数据基础。
