HOPE:a heterogeneity-oriented parallel execution engine for inference on mobiles①
2022-02-11XIAChunwei夏春伟ZHAOJiachengCUIHuiminFENGXiaobing
XIA Chunwei(夏春伟),ZHAO Jiacheng,CUI Huimin,FENG Xiaobing
(*Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,P.R.China)
(**School of Computer Science and Technology,University of Chinese Academy of Sciences,Beijing 100190,P.R.China)
Abstract
Key words:deep neural network(DNN),mobile,heterogeneous scheduler,parallel computing
0 Introduction
Deep neural networks(DNNs)are increasingly adopted in mobile applications and have become the core building blocks of top apps[1].Typically,for these applications,the inference latency is a significant issue for users.Meanwhile,mobile platforms are emerging towards heterogeneous embedded systems[2],which integrate a variety of computing devices into a mobile system-on-chip(SoC).These mobile computing devices exhibit huge diversity in performance,power consumption,memory capacity and programming interface[3].
To efficiently exploit the heterogeneity and support artificial intelligence(AI)applications on heterogeneous mobile platforms,several frameworks are proposed.For example,TFLite[4]could run inference workload on graphics processing unit(GPU)through GPU delegate or other accelerators through the Android neural networks API(NNAPI).MNN[5]supported running DNN models on mobile GPU through OpenCL,OpenGL,Vulkan or Apple Metal.These mobile frameworks provide fundamental support for running a DNN model across different platforms.However,there still lacks heterogeneity models to automatically distribute a DNN model across the on-chip processing units.To address this challenge,MOSAIC[6]used a heterogeneity-,communication-,and constraint-aware model slicing approach to distribute a DNN model across computing devices on a heterogeneous platform.However,MOSAIC considers the DNN model as a linear model without exploring the inter-operation parallelism.On traditional CPU-GPU hybrid servers,researchers have proposed a number of approaches for dynamically scheduling parallel tasks to heterogeneous hardware[7-11],and a representative work is StarPU[12].However,these runtime heuristics are not applicable to mobile platforms.The reason is that DNN models have some special directed acyclic graph(DAG)topology structures,which are built from layers or blocks with similar structure and sizes,especially for large models.But StarPU is unaware of the DAG topology characteristics,thus missing the opportunity of globally determining the scheduling policy and causing performance loss.Ref.[13]proposedμlayer which accelerates each NN layer by simultaneously utilizing heterogeneous computing devices on mobile SoCs.
To materialize the optimization,there are several major challenges.Challenge 1:trade-off between performance and scheduling time.Scheduling on mobile platform requires an acceptable scheduling time to obtain the execution plan.StarPU is lightweight but the performance is degraded,leaving the optimization opportunity submerged.Challenge 2:communication overhead.Running DNN operators to heterogenous computing devices will introduce communication overhead which requires careful consideration.For DNN frameworks with CPU and GPU kernels using different data layout,μlayer will introduce significant data layout translation overhead.
In this paper,HOPE,an end-to-end lightweight heterogeneous inference framework is proposed to distribute a DNN model coordinately on different computing devices of a platform.The key insight is that many DNN models exhibit inter-operation parallelism and enable different operations to be executed in parallel on multiple computing devices.Meanwhile,the topology characteristics of DNN models can be used to seek for an optimal scheduling solution.HOPE first profiles the computation latency for each DNN operator,together with the communication cost of each tensor between every two computing devices.Then,the problem is formalized as an integer linear programming(ILP),and for complex DNN models that require an extremely long time for ILP solver,HOPE partitions a graph into multiple subgraphs and solves ILP for each subgraph individually.
For challenge 1,two distinct algorithms are proposed.The ILP based scheduling method is proposed for best performance but longer scheduling time,while the heuristic method is designed to get the execution plan much faster with moderate performance.Typically,it takes several seconds for the ILP based algorithm to get the execution plan while it takes less than one second for the heuristic method.A heuristic algorithm is also proposed to partition the DNN model into multiple modules,with each module containing several operators.Finally,HOPE includes an execution engine for simultaneously launching modules to different computing devices according to the execution plan.Experimental results demonstrate that HOPE can reduce up to 36.2% inference latency(with an average of 22.0%)than MOSAIC,22.0%(with an average of 10.2%)than StarPU,respectively,and 41.8%(with an average of 18.4%)thanμlayer,compared with the stateof-the-art work.
1 Problem formalization
The problem of scheduling a dataflow graph model across multiple heterogeneous computing devices can be formalized as the following.
A dataflow graph can be described withG(V,E),whereVrepresents the set of vertexes andErepresents the set of edges.Typically,a vertexvi∈Vrepresents an operator like convolution in DNN models.While an edge(vi,vj)represents that operatorvjdepends on the output of operatorvi.Therefore,vjcannot start executing untilviis finished.Given a dataflow graph modelG(V,E),and a setDcontaining all computing devices of the target platform,for eachvi∈V,its execution time on devicedjiscli,j;for each(di,dj)pair(di,dj∈D),the communication cost isC(di,dj)(T)if a tensorTis required to transfer fromditodj.The algorithm’s objective is to find out an execution planRdetermining the execution devicedjfor each nodevi,which minimizes the end-to-end latencyτ(R,G).An execution planR(b,ψ)contains two parts,i.e.,a mapping matrixbindicating the target device for eachvi,and an order matrix arrayψindicating the execution order of the operators mapped to each device.InR(b,ψ),bis a two-valued mapping matrix recording the selected device for each operator,with each elementbi,jrepresenting whether the nodeviis scheduled to the devicedj,i.e.,

ψis a matrix array,and thej-th element is a matrix representing the execution order of the operators mapped todj,i.e.,

2 ILP-based theoretically optimal solution
In this section,firstly,the parallel DAG execution problem is formalized as an ILP,by considering the computation time of each node and communication cost between computing devices.Then a graph partitioning algorithm is proposed to reduce the graph complexity for the ILP solver.
2.1 ILP formulation
2.1.1 Node latency
The overall processing latency of a nodevion a devicedjcomes from two parts.The first part is the kernel computation latencycli,jof nodevion the computing devicedj.If nodeviis not supported bydj,cli,jis set to infinite(+∞).The second part is the communication latency of receiving tensors fromvi’s predecessors.In particular,for the predecessorvj,the communication latency fromvjtoviis denoted asC(d(vj),d(vi))(T),whered(vj)andd(vi)represent the computing device forvjandvirespectively,Trepresents the tensor transferred fromvjtovi.Furthermore,whenvihas multiple predecessors,its total communication cost is computed by aggregating the tensors from all its predecessors,i.e.,
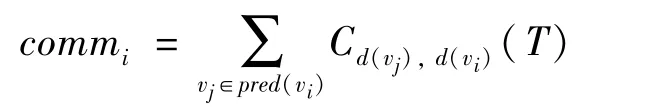
Therefore,the processing latencyti,jof nodevion devicedjcan be formalized to the following expression.

(bi,j-bk,j)×C(d(vk),d(vi))(T)describes whether there is communication overhead between the predecessorviand nodevk.If nodeviand nodevkare distributed to different devices(for example nodevkis dispatched on CPU and nodeviis dispatched on GPU),then the output tensor produced by nodevkneeds to be transferred from CPU memory space to GPU memory space.If(bi,j-bk,j)is less than zero,thenbi,jmust be zero andbk,jmust be one.The right side of the inequation is less than zero and the equation is always true.In other words,on deviced(vj)vertexvidoes not bring any constraint on vertexvj.Note that the communication from the predecessors can overlap with the execution of operators that have no precedence constraints withvi.
2.1.2 Objective function
The objective is to minimize the execution time of the computation graph,thus an auxiliary variablesti,jis introduced to describe that nodevistarts its execution on devicedjat timesti,j.The end-to-end computation latency of the DNN model is the interval from the starting time of the first node to the completion time of the last node.Therefore,the objective is to minimize the end-to-end latency.
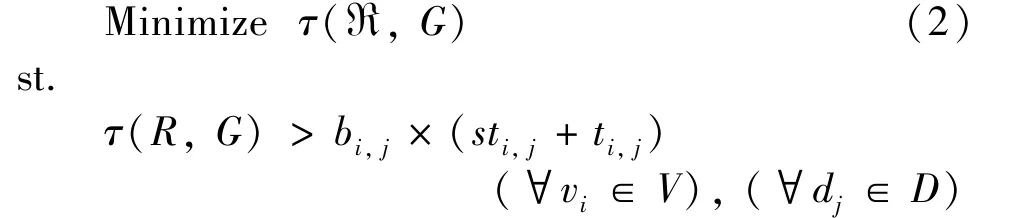
2.1.3 Graph topology constraints
For nodeviand nodevk,if there is an edge(vi,vk)∈E,the graph topology constraint must be satisfied:
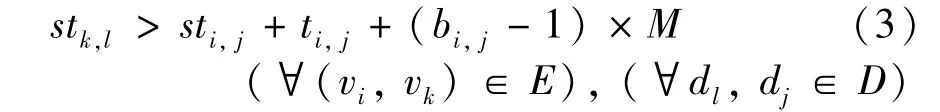
This constraint describes that for any nodevkon any devicedjit cannot start execution until all its predecessor(s)viare finished.Ifbi,jis 0,the constraint will always hold true.Note thatMis a sufficient large positive number.
2.1.4 Device constraints
In this paper,it is assumed that a computing device will not be shared by multiple operators simultaneously,thus at any time there can be at most one operator running on each device.And the execution of a task cannot be interrupted.If there is a path from nodevito nodevj,the device constraint would be naturally satisfied since the graph topology constraint guarantees thatvjwould start aftervi.Therefore,only pairs of nodes that have no path introduce the following constraint.
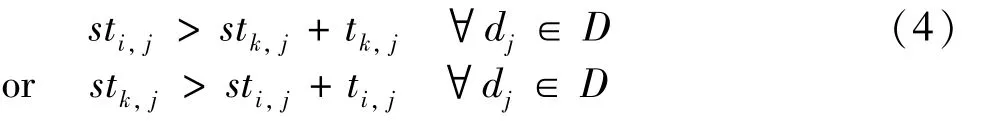
This constraint illustrates thatviandvkcan be executed in any order but cannot execute in parallel on devicedj.An auxiliary variableψi,k,jand a sufficiently large numberMare introduced for the ILP formalization,as
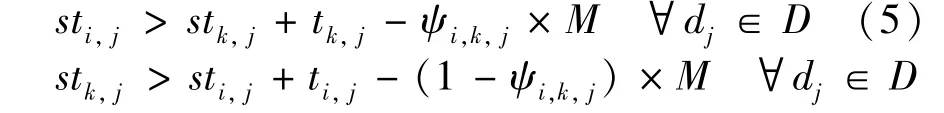
whereψi,k,jis a binary variable which describes the execution order of nodeviandvk.If it equals to 0,viwould execute aftervk,and vice versa.
2.1.5 Node constraints
Each node is expected to be executed only once:
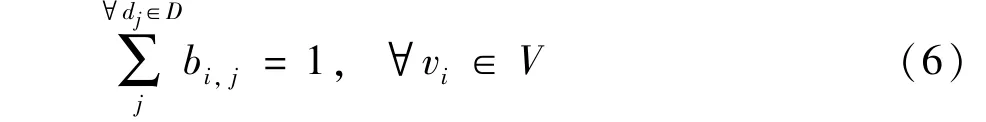
2.1.6 Summary
With constraint Eqs(1)-(6),the problem can be solved by using a standard ILP solver,e.g.,GLPK[13].Finally,the execution plan is expressed using two variables,bi,jdescribing the device placement of the nodes,andψi,k,jdescribing the execution order of the node pairviandvk.
2.2 Graph partitioning problem
The graph partitioning problem is formalized as follows.Given a DAGG=(V,E)and an imbalance parameter∊,find an acyclick-way partitionP=V0,V1ofVsuch that the balance constraint
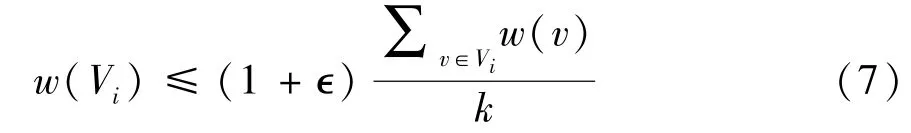
is satisfied and the vertex cut is minimized.The set{V0,V1}represents the two subgraphs’vertexes of the graphG.w(v)is the weight of vertex and is set to 1 for all the vertices.w(Vi)is the sum ofw(v)for all vertexvinVi.To find a proper partitioning point,the concept of upward rank is included,and is defined as
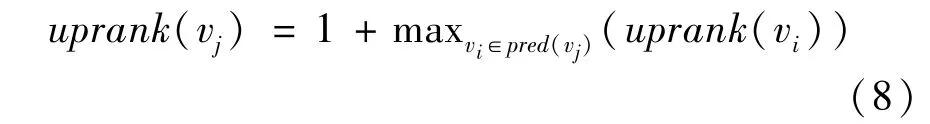
Intuitively,the upward rank ofviis the longest path from the input vertex(es)ofGtovi.The upward rank of all the vertexes in a DAG can be computed in a single traversal ofGin the topology order with a time complexityO(|V|+|E|).The upward rank value of vertexes is used to partition the DAG into subgraphs by recursively partitioning the subgraphs until all the subgraphs have the number of vertices less thanNT.NTis set to 12 in the evaluation and can be configured.
Algorithm 1 shows the pseudo-code of the partitioning approach with up rank.The algorithm tries to find an appropriate upward rank value that partitionsGto two parts with approximate number of vertexes and minimize the vertex cut.The algorithm first computes the upward rank value of each vertex in the graph using equation(line 1).Then the minimum and maximum upward rank value is computed(lines 2-3).After that the algorithm counts the number of vertexes with every upward rank value by traversingG(lines 5-6).Then by the increasing order of up rank,the accumulated number of vertexes is summed up(lines 7-8).The variable accUprank[rank]represents how many vertexes there are whose upward rank value is less or equal than rank.Then the algorithm traverses all the upward rank values and finds in which upward rank value the balance constraint can be satisfied and the vertex cut can be minimized.Then the partitioning result with the minimum vertex cut is obtained(lines 9-18).The computational complexity of this partitioning algorithm isO(|V|log(|V|)).The balance factor∊is set to 0.2 in this paper and if no balanced partition can be obtained,the algorithm will increase the∊by 0.1 until a valid partition scheme is found.

Fig.1 shows an example of graph partitioning using upward rank.The number in the vertex is the upward rank.There are 6 vertexes whose upward rank value is less than or equal to 5 and 7 vertexes whose upward rank value is greater than 5.If partitioning the graph with upward rank 5,the balance constraint is satisfied as(1+0.2)=7.8,and the vertex cut is 1,which is also minimized.The coarse graph withV0andV1being the vertexes is also acyclic.
3 Heuristic scheduling algorithm
In this section,a greedy algorithm is proposed to rapidly obtain a near-optimal execution planRe,including the device placement of each operator and the execution order of the nodes on each device.The key pointis that the algorithm schedules a batch of operators for which the optimal execution plan is obtained.Furthermore,operators having the minimal starting execution timestwould be scheduled first,where the minimal starting execution time of an operator is defined as the maximal completion time of all its predecessor nodes.
3.1 Greedy search algorithm
First,the algorithm greedily selects the top-Knodes that have the minimal starting execution time,by sorting the starting execution time of all operators in the increasing order,and these top-Knodes would be the candidate operators for scheduling.Second,the algorithm enumerates all possible operator-to-device mappings and selects the mapping leading to the minimal completion time of theseKoperators.If a DAG hasynodes and the target mobile platform hasxdevices,the heuristic-based algorithm’s computation complexity isO(yk×xk).The algorithm empirically setkto 4 for two computing devices and 3 for three computing devices.Finally,the algorithm updates the successor operators of theseKnodes for their starting execution time using the computed completion time of theKnodes.Algorithm 2 shows the pseudo-code.
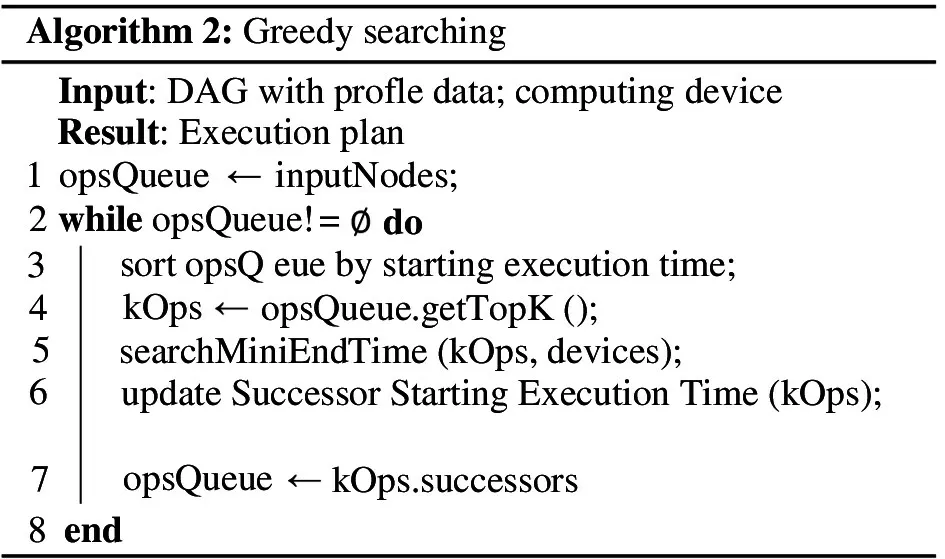
3.2 Node merging for heuristic algorithm
In DNN models,there exist several short running operators that have very low computation latency comparing with the computation-intensive operators.For example,on the Redmi,the latency of ReLU is less than 0.1 ms while that of Conv2D may be more than 3 ms.This observation motivates us to introduce node merging algorithm.For a short running operator,if it has only one predecessor,the algorithm prefers to dispatch it to the same computing device as its predecessor.The merged node is called super-op.The algorithm first runs the node merging algorithm then calls the heuristic scheduler to generate the execution plan.The merged nodes within a super-op will be scheduled to the same device.For frameworks that support kernel fusion,HOPE’s scheduler will schedule the fused kernels as a whole.
4 Framework
Fig.2 shows the HOPE framework.First,a DNN model is fed to the benchmarking engine,which collects the execution time of each node on each computing device of the target platform,together with the communication cost between each pair of devices for the tensors in the model.Second,graph pre-processing partitions the DAG into several smaller modules,with each module consisting of a number of super-ops,as discussed in subsection 4.2.Third,the heterogeneityaware scheduler leverages the scheduling algorithm in subsection 2.1(ILP-Scheduler)or subsection 3.1(GS scheduler)to generate an execution plan that determines the execution order of all nodes and the target device for each node.Finally,the HOPE heterogeneous execution engine uses the generated execution plan and launches the parallel execution across different computing devices.
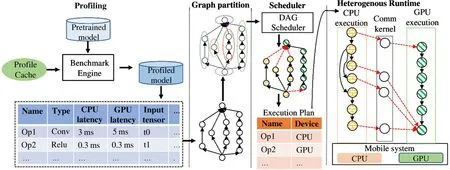
Fig.2 System overview
4.1 Benchmarking engine
The benchmarking engine serves to collect all the profiles that are needed by the scheduler.First,it runs the DNN model,launches each node to each available computing device,and records the corresponding execution time.Second,it collects the information for all tensors passed between adjacent nodes,including their shape and layout information,synthesizes benchmarks to mandatorily transfer each tensor between any pair of computing devices,applies the corresponding layout transformations when necessary,and records these execution time as the communication cost.In some cases,communication will not introduce extra cost,e.g.,transferring a tensor between a big core and a little core of one unique CPU,thus,such communication cost is set to zero.Typically,a variety of computing devices support different tensor layouts via vendor-provided or third-party libraries.For convolution operations,CPU implementation uses the data layout of NC4HW4[5],while GPU with OpenCL implementation uses the layout of OpenCL image object with the shape being(C/4×W,N×H,4)in the MNN framework.The profiling overhead of the communication cost and layer-wise computation latency is limited,less than 10 min for one DNN model.And performance variation is low(around 1%)thus this paper only reports the average results.The number of tensors with different shapes is much less than the number of operators,there are 1049 operators but only 39 tensors with different shapes in NASNET-large.
4.2 Heterogenous execution engine
The heterogeneous execution engine reads an executionplan and executes the DNN model by launching each operator to its target computing devices.Before execution,the execution engine first inserts necessary data transfer and layout transformation statements according to the determined execution plan.Fig.3 shows an example of inserting a communication operator to transfer and transform the tensor 1 from CPU memory space to GPU memory space.
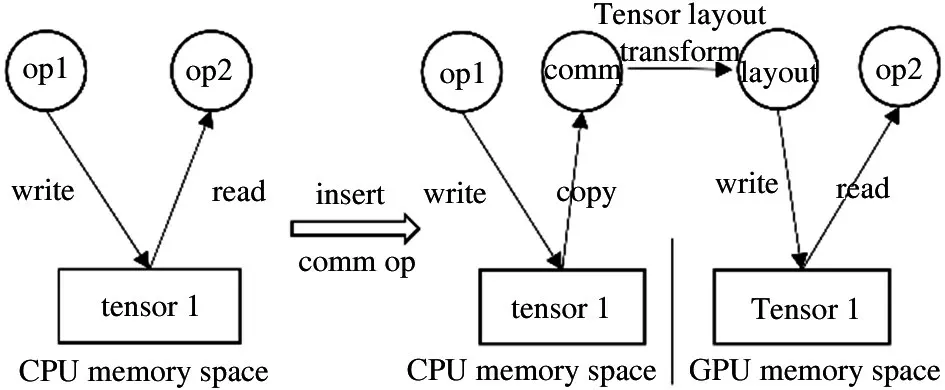
Fig.3 Example of inserting communication operator
The execution engine creates an individual thread for each computing device,with the main thread serving for the CPU big core.To avoid interference across the threads of each computing device,HOPE uses sched_set_affinity API to bind each thread to a dedicated CPU core.Users can configure the number of threads for operators running on CPU.The execution engine introduces a queue for each computing device to keep the nodes that are placed on the device according to the execution plan.Each operator has one flag executed to indicate whether the operator has been executed.After oneoperatorviisexecuted,the engine traverses all its successor operatorsvkin the order determinedby the executionplan.Fora given successorvk,ifit isready forexecution and ismapped to the same device,it will be launched;if it is ready for execution but mapped to another device,the engine would notify the thread of the target device and launch the operator on the corresponding device.Otherwise,the thread would keep sleeping.
4.3 Tensor caching
Motivated by the observation that a tensor would be used multiple times on a device,HOPE introduces a tensor-oriented optimization named tensor-caching.After a tensor has been transferred and transformed to a device,it would be cached on the target device,so that when the tensor is reused the corresponding communication cost can be eliminated.As soon as no operator will read it,the tensor will be freed.
4.4 Optimizing CPU and GPU communication
For the mobile systems in which CPU and GPU share the same physical memory and support shared virtual memory,HOPE provides an optimization to eliminate the memory copy in the communication between CPU and GPU.Specifically,OpenCL provides a few mechanisms to avoid costly memory copy between CPU and GPU.HOPE utilizes the CL_MEM_ALLOC_HOST_PTR flag provided by OpenCL to create OpenCL buffers and the clEnqueueMapBuffer API to map the OpenCL buffer to a host pointer.Then the CPU can update the mapped OpenCL buffers to transform tensor data layout directly without additional memory copy.
5 Evaluation
5.1 Platform and benchmark
Mobile systems.The experiments are conducted on 3 commercial mobile phones including Redmi Note 4x(low-end(LE)with Snapdragon 625),Xiaomi 9SE(medium-end(ME)with Snapdragon 712),HUAWEI P40(high-end(HE)with Kirin 990),ranging from low-end to high-end mobile platforms.
DNNs and datasets.HOPE is evaluated on seven most popular CNNs including Inception-v3(INV3)[14],Inception-v4(IN-V4)[15],PNASNET-mobile(PN-M)[16],PNASNET-large(PN-L)[16],NASNETlarge(NAS-L)[17],and SqueezeNet(SQZ)[18],and one long short-term memory(LSTM)[19]model which follows the configuration in DeepSpeech[20].All the CNN models are trained on the ImageNet dataset.The LSTM has one layer with 1024 hidden states and 10 time steps.The workloads include the DNN models both highly optimized for mobile systems(e.g.,PN-M and SQZ)and models for highest accuracy(e.g.,INV4 and PN-L).Further,the evaluated CNN models exhibit widely different number of operators ranging from 40 to 1049,which indicates that efficient scheduling algorithms are required to place the numerous operators to computing devices for heterogeneous parallel execution.
Implementation.The latest version of the GNU linear programming kit(GLPK)is used to solve the ILP formulation.The heterogeneous execution engine is written in 5000 LOC in C++.The graph partitioning and scheduling algorithms are written with 4000 LOC in Python.
5.2 Overall performance
To investigate the effectiveness of HOPE in terms of inference latency with different computing device combinations and configurations,a series of comparative experiments have been conducted.MOSAIC,the state-of-the-art heterogeneous execution engine for DNN model inference,and StarPU’s dequeue model data aware ready(DMDAR)policy,a most suitable and classical heuristic that is used a reference heuristic in many recent scheduling studies used in comparison with the proposed approaches.On the LE mobile system 4 CPU cores are used,and all the 2 big cores on the ME and HE mobile systems and their GPU for evaluation.Note that StarPU does not use all the CPU cores on the big LITTLE architecture mobile platforms.The reason is that the framework is unaware of the heterogeneous processing architecture and will distribute workloads evenly to big and little cores.The little cores would slow down the computation without carefully scheduling.HOPE is aware of the heterogeneity of CPU clusters,and the detailed experimental results is shown in subsection 6.5.Fig.4 shows the normalized inference latency of the seven DNN models on the three mobile systems.For each DNN model,six different versions are evaluated:CPU only(CPU),GPU only(GPU),CPU and GPU with MOSAIC as the scheduler(MOSAIC),CPU and GPU with StarPU’s(DMDAR)policy(StarPU),CPU and GPU with HOPE’s heuristic scheduler(HOPE:GS),and HOPE’s ILP scheduler HOPE:LP version.All the inference latency of each version is normalized to the GPU version.
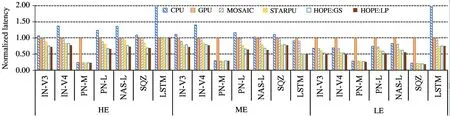
Fig.4 Normalized inference latency on the three mobile systems
The tensor cache optimization is enabled by default for all versions.Fig.4 demonstrates the effectiveness of HOPE’s ILP and heuristic scheduler.First,HOPE significantly outperforms the performance of MOSAIC.Specifically,HOPE with ILP scheduler exhibits 23.4%,24.1%,2.9%,29.4%,31.1%,21.3%,23.3% lower latency than the MOSAIC version of the seven DNN models respectively of the three mobile systems on average.This is because HOPE can schedule the DNN operators to different computing devices and run them in parallel.Second,HOPE with ILP scheduler exhibits 13.7%,9.1%,2.9%,17.9%,18.0%,10.0% and 0% lower latency than the STARPU version.HOPE:LP significantly reduces inference latency by finding the optimal solution for each subgraph and globally determining the scheduling policy.Third,HOPE:GS also reduces the inference latency by 8.2%,3.2%,0.5%,12.9%,11.7%,0.0% and 0.0% compared with StarPU version.The performance gain comes from two aspects.The first is that HOPE:GS merges nodes before scheduling and the potential communication cost is reduced.The second is that HOPE:GS schedules nodes in a larger search window(withKnodes)while StarPU considers only one node.Note that for LSTM there is no computation reduction compared with StarPU.
The reason is that the cell has only four gates and the structure is rather simple.The experimental results clearly demonstrate the effectiveness of HOPE in that it can effectively reduce the inference latency than MOSAIC and StarPU.HOPE exhibits a similar inference latency to that of the CPU alone version with PNAS-M on all the three mobile systems.This is mainly because the PNAS-M is specifically optimized for CPU inference.For instance,it takes 43 ms running PNAS-M with CPU while 183 ms with GPU on the HE.
5.3 Scalability with CPU performance
Next,consider the peak performance ratio between CPUs and GPUs across mobile SoCs varies[3],the frequency of the CPU cores varies to investigate the performance scalability of HOPE scheduler.The LE is chosen as the mobile system and the available CPU frequency ranges from 652 MHz to 2016 MHz.The maximum,medium and minimum CPU frequencies in the CPU’s scaling_avaliable_frequencies list and GPU are used for evaluation.Fig.5 shows the normalized inference latency of each version on the DNN models.HOPE:LP reduces up to 26.4%(with an average of 19.2%),25.2%(with an average of 17.5%)and 29.1%(with an average of 22.1%)inference latency than the MOSAIC version,and 17.2%(with an average of 10.8%),20.4%(with an average of 9.3%)and 17.0%(with an average of 10.3%)inference latency than the StarPU version,with the minimum,medium and maximum CPU frequencies respectively.Similar observations can be found for the HOPE:GS version.Experimental results show that HOPE still outperforms the MOSAIC version and the StarPU version when the peak performance ratio between CPU and GPU varies.
5.4 Comparison withμlayer
This work targets at full-precision DNN model inference thus HOPE is compared againstμlayer using FP32.μlayer runtime is implemented on ARM compute library(ACL)as described in Ref.[13].One benefit of using ACL rather than MNN is that NEONand OpenCL-based kernels in ACL utilize the same data layout,and no data layout conversion overhead is introduced when CPU and GPU need synchronization.
Fig.6 shows the normalized execution latency of μlayer and two scheduling algorithms of HOPE.The results show that HOPE:GS can reduce the computation latency by up to 32.9%(HE),32.8%(ME)and 25.4%(LE)over single-layer acceleration ofμlayer.HOPE:LP can reduce the computation latency by up to 40.6%(HE),35.9%(ME})and 28.0%(LE).The reason is that single-layer acceleration ofμlayer needs fine-grained CPU-GPU synchronization for each layer while HOPE does not.Note that for LSTM HOPE does not reduce the latency overμlayer as HOPE and μlayer partition the LSTM cell with the same split ratio.HOPE can reduce 25.8% and 21.3% computation latency on average for the HE and ME platforms,respectively,while only 8.0% for LE.The reason is that the performance of the CPU and the GPU on the LE platform is severely imbalanced.
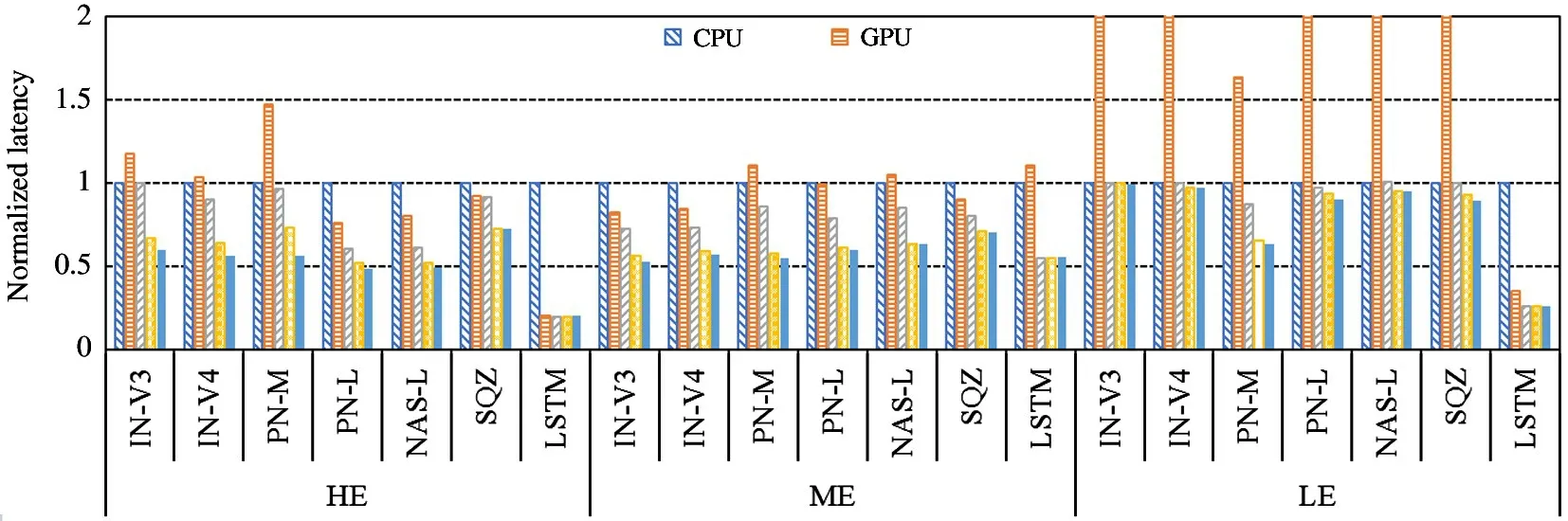
Fig.6 comparison withμlayer
5.5 CPU big+LITTLE
Mobile SoCs adopted big LITTLE technology to balance the performance and power efficiency.The‘LITTLE’processors are designed for maximum power efficiency while‘big’processors are designed to provide maximum compute performance.HOPE can schedule the DNN models considering the heterogeneous processing architecture of CPU.The awareness of big LITTLE of HOPE is evaluated by using 2 big cores+4 little cores on the HE mobile system.The communication overhead can be eliminated when using big and little clusters as they share the same memory space and tensor layout for computation.Fig.7 shows the result.Specifically,HOPE with HOPE:LP reduces 15.7%,2.2%,2.6%,9.8%,8.3%,3.2% and 0%inference latency than StarPU.HOPE can efficiently reduce the inference latency and improve the QoS when using only CPU.HOPE:GS exhibits similar performance as STARPU for there is no communication cost and HOPE:GS cannot obtain benefit from merging nodes.
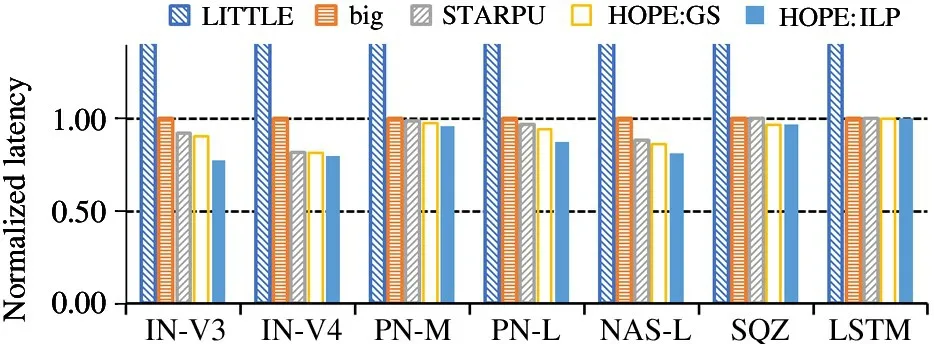
Fig.7 Normalized latency with big LITTLE cores
6 Conclusion
In this paper,HOPE,a heterogeneity-oriented parallel execution engine for DNN model inference on mobile systems is proposed.HOPE profiles operator’s computation latency of the accurate models,pre-processes the DAG to modules,and schedules the DAG with an ILP-based or a greedy-based algorithm to determine the near-optimal heterogeneous execution plan.The experimental results show that HOPE can significantly reduce the computation latency compared with the stateof-the-art work including MOSAIC,StarPU andμlayer.In the future,DNN models with control-flow will be supported and policies will be proposed to dynamically schedule operators.Furthermore,the potential benefits of collaborative execution on accelerators like NPU and DSP will also be explored.
杂志排行

High Technology Letters的其它文章
- Design and implementation of near-memory computing array architecture based on shared buffer①
- Adaptive cubature Kalman filter based on variational Bayesian inference under measurement uncertainty①
- Design and experimental study of active balancing actuator driven by ultrasonic motor①
- Trajectory tracking control of characteristic model for nonplanar hex-rotor UAV①
- The adaptive distributed learning based on homomorphic encryption and blockchain①
- Joint utility optimization algorithm for secure hybrid spectrum sharing①