基于优化Q-learning算法的机器人路径规划
2022-02-02钱信吕成伊宋世杰
钱信,吕成伊,宋世杰
(1.中国电子科技集团公司第三十六研究所,浙江 嘉兴 314000;2.南昌大学信息工程学院,江西 南昌 330031)
路径规划是指在有障碍物的工作环境中,机器人依据某种评价标准,在运动空间中寻找一条可以避开障碍物的最优或者接近最优的路径[1]。路径规划的算法有很多,如人工势场法[2]、蚁群算法[3]、SARSA算法[4]、Q-learning算法[5]等,其中Q-learning算法作为一种可以探索未知环境模型的强化学习算法,成为近年来的研究热点。毛国君等[6]提出一种改进ζ-Q-learning算法,引入动态搜索因子,依据环境反馈动态调节贪婪因子ζ,提高了算法的收敛速度,Low等[7]将花授粉算法(FPA)与Q-learning算法相结合优化Q表初始值,加速Q-learning算法的收敛。虽然Q-Learning算法用于路径规划问题上的研究有不少,但如何解决其收敛速度慢、如何平衡探索与利用的关系等问题仍是现在研究的热点[8]。
为了提高Q-Learning算法的效率,本文融入先验知识,利用人工势场优化Q-learning算法的Q表初值,引导机器人在寻优初期就能选择更合适的动作;采用多步长策略,增加机器人的动作集,使机器人能够向更多的方向移动,增加其灵活性;动态调节贪婪因子,使机器人在寻优初期有更多的机会积累经验,随着迭代次数的增加,再增加机器人利用经验选择动作的概率,从而合理平衡探索与利用的关系。
1 Q-learning算法
Q-learning算法不需要构建模型,是强化学习中最经典的算法。该算法的基本流程[9]为:首先根据智能体的状态集S和动作集A建立一个Q表,智能体在当前状态s(s∈S)下选择动作a(a∈A)时将会获得环境反馈的奖励r,之后智能体会从当前状态s转移到下一状态s',并获得回报的估计值Q(s,a)。然后用估计值Q(s,a)对Q表进行更新,若智能体的动作行为得到环境奖励,Q(s,a)就会增大,若动作行为得到环境惩罚,Q(s,a)会减小。Q表的更新依赖动作价值函数,动作价值函数如式(1)。
Q(s,a)=Q(s,a)+α[R(s,a)+
γmaxAQ(s',a)-Q(s,a)]
(1)
式中:α表示学习率,是权衡上一次学习的结果和这一次学习结果的量,α∈[0,1]。Q(s,a)表示当前状态动作的估计值,Q(s',a)为下一状态动作的估计值。R(s,a)表示在当前状态s下执行某个动作a,环境立即给予的奖励值。maxAQ(s',a)表示在动作集A中选择使Q(s',a)最大的动作。γ表示奖励值的折扣因子,是考虑后续动作奖励对当前状态影响的因子,γ∈[0,1]。γ值接近1表示智能体会着重考虑后续状态的价值,即Q(s,a)的估计值不仅和智能体当前得到的奖励值R(s,a)相关,与Q(s',a)的奖励值也有很大的关联。γ值接近0表示智能体只考虑当前的利益影响,即Q(s,a)的估计值与当前得到的奖励值R(s,a)有很大关系,与Q(s',a)的奖励值关系较弱。
2 IMD-Q-learnig算法
为解决Q-learning算法用于路径规划时存在的收敛速度慢、难以平衡探索与利用的关系等问题,本文将从Q表初值、机器人移动步长以及贪婪因子等3个方面对Q-learning算法进行改进,为讨论方便,改进后的算法称为IMD-Q-learning。
2.1 Q表初始化
传统Q-learning算法在初始化时,一般是2个选择,使Q表的初值为0或者随机数[10],这使得机器人在探索环境的初期具有盲目性,导致寻优时间过长。本文引入人工势场法的思想并对其进行改进,有导向性地对Q表进行初始化,使移动机器人可以更快地适应障碍环境,提高算法的寻优效率。
人工势场法假设目标点和障碍物对机器人分别有引力势场和斥力势场[11],引力势场定义为
(2)
式中:Uatt(p)为引力势场;Φ为引力势场正增益系数;ρ(p,pgoal)为机器人当前位置p与目标点位置pgoal的欧几里得距离。显然机器人离目标点越远引力势场越小。
斥力势场定义为
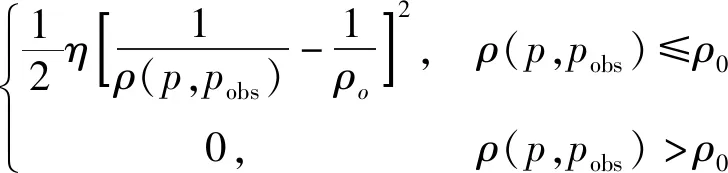
(3)
式中:Urep(p)为斥力势场;η为斥力势场增益系数;ρ(p,pobs)为机器人位置p与障碍物位置pobs的欧几里得距离;ρ0为障碍物的影响半径,显示机器人离障碍物越远所受斥力越小,当机器人离障碍物的距离大于ρ0时,所受斥力势场为0。
本文在Q-learning算法中引入势场的目的是引导机器人在算法初期的动作选择,使机器人能够更早地朝着目标点的方向移动,同时回避障碍物,因此本文中机器人的总势场不是传统的引力势场与斥力势场之和,而是引力势场与斥力势场的倒数之和,这样做的目的是使距离目标点近并且附近没有障碍物,即机器人的总势场为
U(p)=Uatt(p)+1/Urep(p)
(4)
式中:U(p)为机器人处于位置p时受到的总势场;Uatt(p)为机器人处于位置p时受到的引力势场;Urep(p)为机器人处于位置p时受到的斥力势场。
对式(4)进行归一化处理,得
(5)
式中:Umax(p)代表势场能最大的值。
Q表的初始值Q0(s,a)定义为
Q0(s,a)=r+γU'(s)
(6)
式中:γ为折扣因子;r为反馈奖励值,其值为

(7)
2.2 多步长策略
Q-learning算法一次只能移动一个步长,效率低[12],本文提出了多步长动作选择策略,增加机器人的动作集并优化Q-learning算法的动作选择,使移动机器人只进行一次移动,就可以达到传统算法多次移动的效果。
如图1所示,图中黑色方框为障碍物,其他为自由栅格,设A为机器人所处位置,以A为中心的虚线区域为机器人使用多步长可以一步到达的范围(此处假设最大步长为3),从A点到B点,使用单步长时,机器人一次只能移动一个栅格,需要移动5次才能到达B点,如图中曲线①,若采用多步长,机器人只需移动2次就能到达B点,并且路径更优,如图中曲线②。可见采用多步长策略不仅可以寻到更优的路径,而且算法的迭代次数少,路径中出现的拐点个数也少。
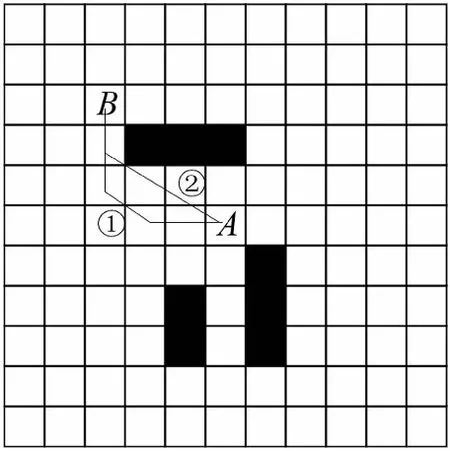
图1 多步长动作选择策略Fig.1 Multi-step action selection strategy
需要注意的是,采用单步长时,Q-learning算法共有8个动作可供选择[13],如图2所示,若采用多步长,Q-learning算法可供选择的动作将大大增加,并且步长越大可供选择的动作越多,图3所示为步长等于2时Q-learning算法可选择的动作。
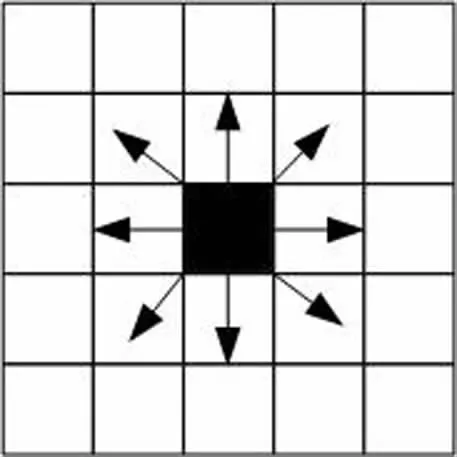
图2 步长为1时的动作Fig.2 Action when step size is 1
由于步长大时Q-learning算法的寻优效率更高并且路径更优,为鼓励机器人采用大步长,本文对Q-learning算法的奖励函数进行改进,即在原奖励函数的基础上,增加一个多步长动作选择奖励值,如式(8)所示。
(8)
式中:rx为多步长额外奖励值rx=(l-1)v;l为步长长度;v为单步移动的奖励,显然步长越大到达下一栅格得到的奖励就越大;而r1、r2和r3为常数,并且r1>r2>r3。
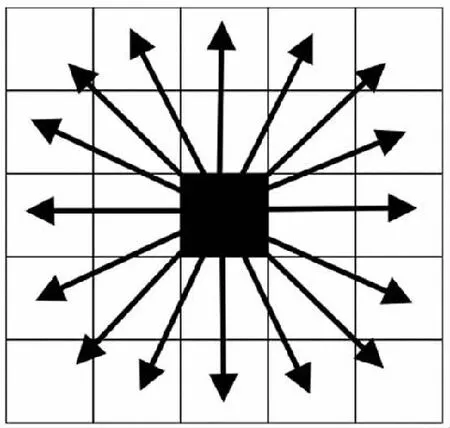
图3 步长为2时的动作Fig.3 Action when step size is 2
2.3 动态调节贪婪因子
探索与利用的关系是Q-learning算法的重点和难题[14],为更好地平衡探索与利用的关系,本文提出以迭代次数作为自变量的动态调节函数ζ(t)。
(9)
式中:e为自然对数底数;t为迭代次数;K1、K2为常数。动态调节函数ζ(t)在迭代初期取最大值,使移动机器人在寻优的初始阶段能对环境进行充分探索,增加对环境信息的利用率。随着迭代次数的增加,机器人已经学习到了一些寻找最优路径的经验,此时调节函数ζ(t)随着探索次数的增加而衰减,减少了选择随机动作的概率,增加了选择价值最大动作的概率。动态调节函数ζ(t)避免了机器人因贪婪因子值恒定而无法在探索过程中学习到经验,从而只能找到次优路径的问题。
3 仿真及结果分析
3.1 构建栅格地图以及设置参数


图4 栅格地图环境Fig.4 Grid map environment
3.2 仿真结果与分析
在上述环境下分别测试了以下4种算法:
(1)Q-learning算法;
(2)动态调节贪婪因子的Q-learning算法;
(3)优化Q表初值和多步长的Q-learning算法;
(4)IMD-Q-learning算法。
图5所示为上述环境下的最优路径,其中Q-learning算法最优路径的长度为33,拐点数为15。动态调节贪婪因子的Q-learning算法的最优路径长度为33,拐点数为14。优化初始值和增加动作的Q-learning算法的最优路径长度为11.06,拐点数为12。IMD-Q-learning算法的最优路径长度为6.9,拐点个数为8。
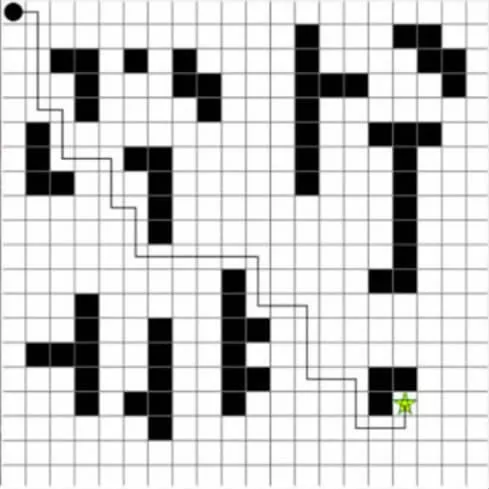
(a) Q-learning算法
算法收敛曲线如图6所示,图中用n代表迭代次数,m代表步数。其中Q-learning算法的迭代次数n为2 500,动态调节贪婪因子的Q-learning算法的迭代次数n为1 500,优化初始值和增加动作的Q-learning算法的迭代次数n为380,IMD-Q-learning算法的迭代次数n为290。

n/次(a) Q-learning算法
将上述参数列于表1,表中l为最优路径长度,n为迭代次数。可知,与Q-learning算法相比,本文所提出的IMD-Q-learning算法,其最优路径长度缩短了79.09%,拐点个数减少46.67%,算法效率提升了88.40%。
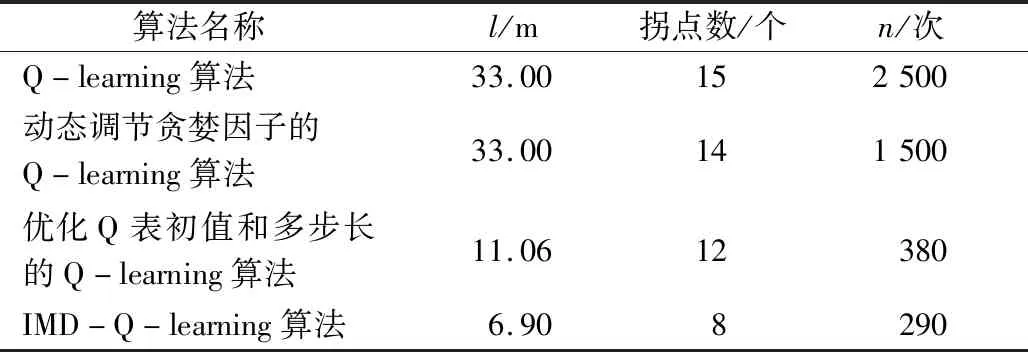
表1 路径综合评价表Tab.1 Path comprehensive evaluation table
4 结论
(1)采用改进后的势场对Q-learning算法的Q表初始值进行优化,将引力势场与斥力势场的倒数之和的归一化值作为Q表初值,从而在算法初期机器人经验不多的情况下引导机器人选择更合适的动作,能够更早地朝着目标点的方向移动,减少迭代次数。
(2)采用多步长策略,增加机器人的动作,使机器人一次可以移动多个步长,优化了寻优路径,并且减少了算法的迭代次数和路径中的拐点个数。
(3)采用动态调节贪婪因子,使机器人在寻优初期有更多的机会对环境进行探索,积累经验,随着迭代次数的逐步增加,机器人已经学习到了一些寻找最优路径的经验,此时慢慢增加机器人利用经验选择动作的概率,平衡探索与利用的关系。
(4)使用Python中的Tkinter库,构建20×20的栅格地图环境并进行仿真,结果证明,与Q-learning算法相比,改进后的IMD-Q-learning算法在最优路径、收敛速度等方面都得到了大幅度提升。
