自动导向小车与加工设备多目标集成调度的聚类遗传算法
2022-01-24邹裕吉宋豫川王馨坤
邹裕吉 宋豫川 王馨坤 王 毅
重庆大学机械传动国家重点实验室,重庆,400044
0 引言
大规模定制化和多品种小批量的生产模式逐渐成为车间生产的主流。该种模式下,产品种类繁多且工艺流程各不相同,导致物流系统具有任务多、流程变化大、动态实时性强、实时性高等特点。AGV作为一种集成了多种先进技术的物流装备能很好地满足这种需求[1],因此越来越多的车间使用AGV来完成工件的运输任务。这种情况下,AGV和加工设备的协同工作对提高生产效率至关重要。传统的车间调度方案往往不考虑AGV在车间生产的作用,对现代化生产车间的指导性存在不足,因此,面向复杂生产环境的AGV与加工设备的集成调度越来越受学者的关注。
AGV和加工设备集成调度问题可以分为三个子问题:加工设备调度、AGV调度、AGV路径规划。为降低问题的复杂性,有学者在不考虑路径冲突的前提下对该问题展开研究。ULUSOY等[2]将AGV和加工设备集成调度作为研究对象,假设AGV在只能沿路径单向行驶的情况下,应用遗传算法求解调度问题,并建立标准算例库。此后,许多学者按照这种思路求解AGV与加工设备集成调度问题,即将AGV在不同机器之间的运行时间假设为常数,而实际生产车间中,AGV往往沿着固定的轨道运行且可双向行驶,因此AGV之间发生路径冲突是不可避免的。于是有学者开始研究考虑路径冲突的AGV与加工设备的集成调度问题。SAIDIMEHRABAD等[3]建立了一个由车间调度和无冲突路径组成的数学模型,提出的二阶段蚁群算法先解决AGV的分配问题,再解决AGV的无冲突路径规划问题,分析了不同数量AGV下的最大完工时间的变化情况。LYU等[4]提出一种改进遗传算法来求解以最大完工时间为优化目标的AGV和加工设备的集成调度问题,实验结果表明:在可解决AGV冲突的情况下,单道双向路径的路网系统可以进一步提高生产效率。多目标优化不会只注重一个目标的优化,可以平衡生产系统的各项指标,逐渐引起大家的重视。REEDYB等[5]研究了AGV与加工设备集成的多目标调度问题,以最大完工时间、工件平均流动时间和工件平均拖期为优化目标,在非柔性作业车间中不考虑路径冲突的前提下,提出一种混合遗传算法。刘二辉等[6]提出一种改进花授粉算法来求解AGV和加工设备的集成调度问题,在AGV可以自由行走的环境中,将最大完工时间和AGV利用率作为优化目标,从系统可靠性、成本、效率等多个角度分析并确定系统最优的AGV数量,该方法不足之处在于将两个目标独立优化,不是真正意义上的多目标优化。
综上所述,考虑路径冲突的AGV和加工设备集成调度的多目标优化问题研究还较少,笔者以最大完工时间、AGV运行时间和机器总负荷为优化目标构建优化模型。该问题是多个NP-hard问题的叠加,解空间庞大且复杂,精确算法难以在可接受的时间内求得最优解。启发式算法往往可以快速得到最优解或者次优解,更适合这种类型问题。遗传算法是一种启发式算法,具有全局搜索能力强、鲁棒性较好[7]等优点,在多目标优化领域已经有比较多的应用。
交叉是遗传算法中的重要操作,在很大程度上决定算法性能[8],而原始的交叉操作具有一定的随机性和盲目性,因此许多学者通过引导交叉操作来提高算法的性能[9-11]。聚类是数据挖掘领域中常用的一种方法,在进化算法中用来提取个体之间的相似度。越来越多的研究将聚类算法和智能优化算法结合来提高算法性能[12-14]。本文通过聚类算法得到的相似度将种群分为多个子种群,引入鲸鱼优化算法[15]中的收敛因子来限制交叉父代的子种群来源,从而提高算法性能。解集的分布性是多目标优化另外一个重要的性能。NSGA-Ⅱ算法的非支配排序和拥挤距离可在一定程度上保证Pareto最优解集的均匀性和分布性,但在计算拥挤距离时只计算相邻个体的距离并不能完全反映多样性。本文提出的基于自适应网格距离的选择方法可以避免边界个体必被选中,并能更好地增强种群的多样性。
1 问题描述及数学模型
1.1 问题描述
传统的作业车间调度问题不考虑工件在不同加工设备之间的运输时间。本文所研究的问题中,工件的运输时间不可忽略且随着路况变化,不仅要为每道工序分配负责其运输的AGV,还要为AGV规划无冲突的路径以确定精确的运输时间。假设有n个需要加工的工件,m台可以用于加工的机器,工件i有gi道工序。每道工序至少存在1台可加工的机器,工序的加工时间和机器的加工能力有关。每台AGV可以在任意机器及仓库之间运输工件,假设AGV的行驶速度恒定不变,因此运输时间只取决于运输距离及路途中的冲突状况。AGV的任务周期由两部分组成,首先AGV从当前位置行驶到当前工序加工机器所在位置,然后将工件运输到下一道工序加工机器所在位置。工件的所有工序都完成之后,需要运送回仓库,根据2.1节编码方法,为所有工件增加一道虚拟工序,该道工序的加工时间为0,加工机器位置为仓库所在的位置,用以分配将工件运输到仓库的AGV。为了简化问题,作在以下假设:
(1)工件和AGV的初始位置为仓库,从仓库出发时,所有AGV以随机顺序按照固定的间隔时间出发;
(2)各AGV运输能力相同,每次只能完成1个工件的运输任务;
(3)加工机器的工件缓冲区无限大;
(4)AGV完成运输任务后停靠在机器旁;
(5)机器不能同时加工多个工件且一旦开始加工便不会中断;
(6)工件加工准备时间及装卸时间算在加工时间中;
(7)所有路段在同一时刻只允许1台AGV通过,且任意路段可容纳AGV的车身,不存在AGV占用两个车道的情况;
(8)不同工件之间的工序无加工先后约束,同一工件之间的工序存在加工先后约束;
(9)调度周期内AGV与加工设备不会发生故障,AGV电量充足。
1.2 数学模型
为了便于模型的建立和描述,引入如下符号和变量。变量xijk用以限定一道工序只能由一台加工设备完成加工,即有
式中,Oij表示第i个工件的第j道工序。
变量zijw限定每道工序的运输任务只能由一台AGV负责,即有
式中,Rw表示编号为w的AGV。
变量apqijk表示在同一台加工设备上加工的工序(加工顺序)的关系,即有
变量βpqijw表示由同一台AGV负责运输的工序(运输顺序)的关系,即有
变量δwst表示AGV对节点的占据情况,即有
变量εsrt表示节点的锁定情况,即有
1.2.1目标函数
本文提出AGV与加工设备集成调度问题的3个优化目标如下:
(1)最大完工时间最小,即
f1=min(max(C1,C2,…,Cn))
(1)
(2)
(3)

(2)AGV运行距离最短,即
(4)
(3)机器总负荷最小,即
(5)
式中,pijk为工序Oij在加工设备Mk上加工所需时间。
1.2.2约束条件
根据以上假设条件以及实际生产情况,给出如下约束条件:
(1)任意一道工序必须选择1台且只能选择1台机器完成加工,即
(6)
(2)任意一道工序最多只能选择1台AGV进行运输,即
(7)
(3)AGV负载出发时间不早于AGV空载结束时间和上一道工序完工时间,即
(8)
(9)

(4)AGV负载结束时间为负载开始时间与负载运行时间之和,即
(10)
(5)AGV空载出发时间不早于上一次运输任务的负载完成时间,即
(11)
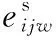
(6)AGV空载结束时间为AGV空载出发时间与空载运行时间之和,即
(12)
式中,eijw为编号w的AGV负责工序Oij运输任务时,AGV空载阶段的运行时间。
(7)工件开工时间不早于AGV负载结束时间、前道工序的完工时间以及前一道在机器上加工工序完工时间,即
(13)
(14)
(15)

(8)工序完工时间为工序开工时间与加工时间之和,即
(16)
(9)在AGV进入某个路段之后和驶出该路段之前的时间段内,不允许其他AGV进入,路段出口处的节点标识值εsrt=1。
(10)同一时刻任意一个节点只容得下1台AGV,即有
(17)
式中,H为调度周期。
2 算法描述
2.1 问题编码
AGV和加工设备的集成调度问题可以分为三个子问题:工序排序、机器分配、AGV分配,因此,本文采用三段式编码对应3个子问题。如图1所示,工序编码段中的基因和工件号对应,从左至右的数字为工件的工序号。第一个基因上第一次出现的3表示3号工件的第一道工序,第4个基因位上第二次出现的3表示3号工件的第二道工序。机器和AGV编码段中的基因与工序一一对应,如机器编码段的前3个基因2、4、3表示工件1的三道工序分别选择2号、4号与3号机器进行加工。

图1 个体编码示意图Fig.1 Individual coding diagram
2.2 基于自适应聚类的交叉策略
聚类是一种无监督学习方法,可发现数据之间的联系。采用聚类对种群分类后,同一子种群内的个体相似度大,不同子种群之间的个体相似度小。相似度大的个体之间进行交叉会以较大概率产生质量更高的解,提高算法局部搜索能力;相似度小的个体之间进行交叉可产生多样性更强的解,增强算法的全局探索能力。鲸鱼优化算法[15]中的收敛因子可以平衡算法的探索与开发,本文以此为基础,通过非线性收敛因子来限制遗传算法交叉个体的来源。
2.2.1基于海明距离的自适应聚类算法
聚类方法中,距离是广泛应用的一个度量指标。对于本文研究的组合优化问题,海明距离能更好地反映个体之间的相似度,因此本文将海明距离作为聚类的依据。K-means作为一种经典的聚类算法,具有原理简单、容易实现、收敛快等优点。分类数目是聚类算法的重要参数之一,算法的聚类效果与给定的分类数目有很大的关系,而Canopy算法[16]作为一种“粗聚类”算法,能较快求得一个种群的最优分类数量,因此,本文首先采用Canopy聚类算法对种群进行初步聚类、得到分类数量,使聚类数量随种群进化自适应变化,然后应用K-means聚类算法将种群进行聚类。
在Canopy算法中设置最大迭代次数,统计所有迭代所获得的结果,最佳分类数量k1取出现频率最高的结果。每次迭代中,Canopy算法以阈值(种群所有个体之间海明距离的平均值与5倍方差的和)T2对种群进行迭代运算。开始运算时,随机选择一个个体作为聚类中心。有了聚类中心之后,从种群列表中随机选择个体,计算其到各聚类中心的距离,如果距离小于T2,则将该个体归入该聚类中心的子种群,并从种群列表中删除;如果该个体到所有聚类中心的距离都大于T2,则以该个体为中心创建一个类,并将该个体从种群列表中删除。所有个体按照相同的方式进行分类,直到种群列表为空,最终得到本次迭代的分类数量。然后,采用K-means方法从种群中随机选择k1个个体作为聚类中心点,计算剩余个体到各聚类中心的海明距离,将个体分到距离最小的类,算法流程见图2。

图2 Canopy算法流程图Fig.2 Canopy algorithm flow chart
2.2.2父代来源选择策略
对遗传算法而言,前期侧重于全局探索,应以更大的概率进行异组交叉以找到全局最优解,后期在得到部分较优解的情况下,侧重于局部开发,应进行同组交叉,提高解的质量。鲸鱼优化算法的收敛因子随迭代而变化,可记录算法的迭代信息,用以判断个体在更新过程中是否向最优个体靠近,能很好地平衡算法的全局探索和局部勘探。鲸鱼优化算法中收敛因子随着迭代次数线性变化。研究表明非线性收敛因子可进一步提升算法的性能[17],因此,本文设计一种非线性收敛因子:
A=a(2r1-1)
(18)
(19)
式中,r1为0~1之间随机生成的数;td为当前的迭代次数;tmax为最大迭代次数。
来判断种群个体进行异组交叉还是同组交叉。如果A>1/2,则选择异组交叉,否则选择同组交叉。由式(19)可知,A的取值为[0,a],a随着迭代的进行,从2减小到0,前期以较大的概率进行异组交叉,后期进行同组交叉。
同组交叉,即在同一个子类里面随机选择两个个体进行交叉。为使所有个体都能进行同组交叉,子种群个体数量应为偶数,因此需对个体数量为奇数的子种群进行调整,在子种群中移除或增加部分个体使群个体数量为偶数。首先计算个体最多的子类中离其聚类中心最远的个体到其他个体数量为奇数的子种群聚类中心的距离,然后将该个体从该子类中删除,添加到离聚类中心距离最小的子类中,如果到多个子类的最小距离相等,则随机选择其中一个子类。重复以上操作直到所有子类中的个体数量变为偶数。异组交叉需要从不同的子类中选择父代个体进行交叉。每个子类中的个体数量有差别,为尽量让所有个体都能和异组的个体交叉,本文采用基于个体数量的选择方法,即随机选择种群中的一个个体与当前个体数量最大的子类中随机选择的一个个体进行交叉,重复该操作直到完成种群交叉。
2.2.3交叉操作
对基于工序的编码方式而言,改进优先操作交叉(improved precedence operation crossover,IPOX)是一种十分合适的交叉算子,具体操作为:随机选择部分工件,使这些工件所有工序的绝对位置不变,使其他工件工序之间的相对位置不变。这不仅可以避免产生不可行解,还能保证工序在父代中的顺序约束。本文对工序序列采用的IPOX见图3。多点交叉作为一种经典交叉方式,具有操作简单、易于实现等优点[7],依据机器和AGV的编码特点,本文对加工设备和AGV系列采用多点交叉的方式进行交叉,见图4。

图3 IPOX交叉示意图Fig.3 IPOX crossover diagram
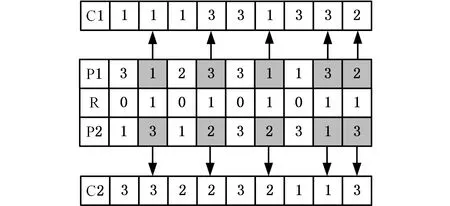
图4 多点交叉示意图Fig.4 Multipoint crossover diagram
2.2.4自适应个体交叉概率
种群中的个体质量参差不齐,所有个体的交叉概率相同会导致质量较好个体信息的流失,因此,本文给每个个体分配一个交叉概率。算法进化过程中,如果一个个体经过很多代都没有被淘汰,表明其质量较好,将该个体存在的代数称作生存长度。非支配等级是另外一个常见的个体质量指标,因此本文使用生存长度、非支配等级衡量个体的质量。质量高的个体应该以更大的概率进行交叉,进而将优良基因传给后代,本文中种群个体自适应交叉概率为
(20)
式中,Pc为设置的初始交叉概率;l为当前个体生存长度;lmax为当前最大的生存长度;r为当前个体的支配等级;rmax为当前种群的最大支配等级。
2.3 变异操作
变异是遗传算法进化过程中的重要操作,对改善算法的局部搜索能力有极大的帮助,在一定程度上可防止算法早熟。笔者考虑产生后代的可行性,采用两种方式对新生成的个体进行变异操作:①对于工序编码段,随机互换染色体中的两个基因;②对于加工设备编码段,随机选择染色体中的一个位置,然后在该位置对应工序的可加工设备集中随机选择加工设备来替换当前加工设备。AGV编码段的变异操作也是如此。
精英保留可保证不会丢失最优个体,本文采用一种精英保留的环境选择方法,将父代种群和子代种群合并后选择较优个体以维持种群大小,其中,从父代种群中保留的个体称为精英个体。新生成种群保留较多精英个体表明种群难以生成更好的解,种群进化进入停滞,可能陷入局部最优,此时应当增大变异概率:
P′m=Pm+(1-Pm)z1/z
(21)
式中,Pm为设置的初始变异概率;z1为精英个体数量;z为种群规模。
2.4 基于聚类数量的扰动因子
个体之间的相似度在算法后期会越来越大,使得种群丧失多样性。本文提出一种基于聚类数量的扰动因子,具体做法为:种群经过Canopy算法粗聚类后,如果聚类数量连续多代小于阈值,则随机生成一部分个体替换支配等级最大的个体,并强制进行一次异组交叉。
2.5 基于网格的环境选择
本文参考文献[18]的方法,设计一种基于支配等级与网格距离的环境选择方法,对目标空间进行网格划分并计算每个个体的网格坐标。网格划分数对于划分效果至关重要,文献[19]提出一种基于目标数和种群规模的划分方法,其中的网格划分数为

(22)

为将边界的点纳入网格坐标中,需要对目标空间的上下限进行扩容,即有
(23)
(24)
式中,fm(X)为优化目标值,um、lm分别为扩容后的上下限。
扩容后,个体网格坐标为

(25)
(26)
式中,dm为单位网格的大小。
衡量同一支配等级个体的拥挤度的指标为
(27)
gt(x,y)=
(28)
G(x)越大,密集程度越大。环境选择时,选择拥挤度小的个体可使种群包含更强的多样性,使得算法朝着各个方向进化,因此优先选择拥挤度小的个体,以增强算法的全局探索能力。
2.6 基于时间窗的Dijkstra算法
柔性制造系统中,AGV沿着固定的路线往返于机器和仓库,因此可将车间抽象为一个拓扑地图,将机器和仓库抽象为节点,将可行的路段抽象为可双向通行路径,如图5所示,AGV在运行地图上可沿固定的轨道双向行驶,行进过程中可能遇到的路径冲突主要有4种:节点占用冲突、路口冲突、相向冲突和赶超冲突。本文假设AGV的行驶速度不变,因此最后一种冲突不予考虑,见图6。目前,解决路径冲突的策略主要有等待和二次规划。相向冲突采用等待策略是无法解决的,只能采用基于二次规划的方法。对于节点冲突和路口冲突,等待策略和二次规划都能解决冲突,但二次规划可能缩短AGV的行驶时间,也可能导致新的冲突甚至死锁,增加算法的计算量,因此本文采用等待法解决节点冲突和路口冲突。

图5 车间地图Fig.5 Workshop map

(a)相向冲突 (b)路口冲突
时间窗方法是一种经典的冲突检测方法,给有AGV通过的路段添时间窗,以将路段锁定一段时间,当有AGV要通过该路段时,通过时间窗是否重叠来判断是否有冲突。Dijkstra算法可以快速求得两点之间的最短路径,但地图中的节点和路段变多时,算法的求解时间会急剧延长。本文研究的问题中,AGV只往返于机器和仓库之间,地图并不复杂,Dijkstra算法较合适。综上,本文采用基于时间窗的Dijkstra算法为AGV规划路径。
2.7 解码
将正规性指标作为优化目标时,最优调度结果必定存在于主动调度集中,因此,本文采用一种基于插入式贪婪解码的主动解码方法,在不延后已安排工序开工时间的前提下,通过查找满足条件的加工设备空闲时间段将工序加工插入,使当前工序尽可能早的开工。与传统调度问题不同的是,本文研究的问题考虑工件的转移时间,所以工序的最早可开工时间为负责该工序运输任务的AGV负载结束时间。机器被安排加工任务后,空闲时间被分割成多段,如果在工序最早可开工时间之后能插入加工设备空闲时间段即
t≤min(t1,t2)
(29)
t1=ei-sit2=ei-j
(30)
式中,ei为空闲时间段i的结束时间,i=1,2,…,nI;nI为空闲时间段的数量;si为空闲时间段i的开始时间;j为本道工序运输任务的负载结束时间。
2.8 时间复杂度分析
本文所提算法进行交叉、解码、非支配排序所耗费的时间远远大于其他操作所耗费的时间,而解码为算法必不可少的部分,所以只讨论交叉和非支配排序部分的时间复杂度。
假设种群规模为N,个体维度为w,聚类数量为m,则普通交叉操作的时间复杂度为O(Nw)。本文交叉操作首先需要进行聚类,然后再进行交叉重组,时间复杂度为
T=O(Nw)+O(mNw)+O(Nw)=O(Nw)
(31)
本文用快速非支配排序方法计算个体的支配等级,用网格距离替换拥挤距离,所以其时间复杂度和快速非支配排序的时间复杂度一样,也为O(NlgN)。
2.9 算法流程
图7所示为本文所提算法的总流程,其中,mc为聚类数量小于3的持续代数。种群在经过初始化之后进入算法迭代阶段。算法迭代阶段内,首先对种群进行聚类,根据提出的交叉重组策略进行交叉操作后再进行变异操作,最后根据所提的环境选择方法保持种群规模。
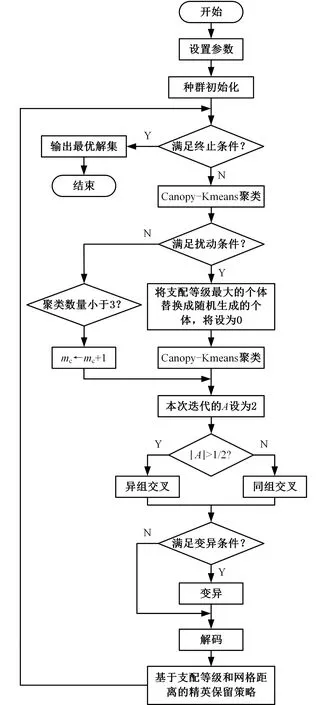
图7 算法流程图Fig.7 Algorithm flowchart
3 实验分析
为检验本文算法在求解多目标AGV和加工设备集成调度问题的性能,在MATLAB 2019a的编程环境,Intel Core i5-8500 CPU(3.0GHz主频)、8.0GB内存的运行环境下开展以下实验。
3.1 算法对比
3.1.1非柔性算例对比
文献[5]在不考虑AGV路径冲突的前提下,以最大完工时间、工件平均流转时间、工件平均延误时间为优化目标,研究AGV与加工设备集成调度问题,为了方便表示,用PGA表示文献[5]算法,用MACGA表示本文算法。表1所示为两个算法获得的非支配解优化目标值,所得解用向量表示,向量中的元素依次表示最大完工时间、工件平均流转时间、工件平均延误时间。所有案例运行在单向单道的地图中,不考虑AGV之间的冲突,所有工序只能由一台加工设备负责加工。本文算法的关键参数设置和文献[5]相同,最大迭代次数设为100,种群规模设为80,交叉率设为0.8,变异概率设为0.4,AGV数量设为2。PGA的结果为文献[5]的原始数据,MACGA的结果为算法独立运行5次的最优结果。表1中,红色的解会被另一个算法Pareto解集中的解支配,可以发现,MACGA所获得的Pareto解集中未出现任意一个解被支配的情况;随着解空间的增大,MACGA支配解的优势更明显。另外,案例1中两个算法均能获得4个非支配解,最大完工时间和平均流转时间的最小值相等,本文算法能获得平均拖期的更优值。案例2中,PGA能获得6个非支配解,MACGA能获得8个非支配解,PGA能获得更小的最大完工时间,MACGA能获得更小的平均流转时间和平均拖期。随着案例解空间的增大,从案例3开始,MACGA在Pareto解集的数量及各目标最小值均优于PGA。

表1 非柔性算例Pareto解集
3.1.2柔性算例对比
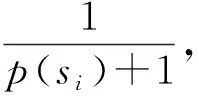
表2中的各算法独立运行5次,算法的参数如下:最大迭代次数100,种群规模80,交叉率0.9,变异率0.1。NSGA-Ⅱ、SPEA2均采用锦标赛的选择策略,交叉池大小为种群大小的90%。SPEA2外部存档集的大小为40。Me栏中的红色数字表示算法获得解集的3个优化目标值的平均值都为最优,由表2可发现,MACGA的Me在多个算例的运算结果中优于SPEA2和NSGA-Ⅱ,且所有算例不存在3个优化目标值都为最劣的情况,这表明MACGA获得解集的整体质量要优于其他两种算法。当没有解可以支配某个体时,该个体的Ev<1,某个体的支配个体越多,其Ev越小。除了算例2中AGV数量为3时的情况,其他情况下MACGAP解集中最小的Ev都是小于1,说明MACGA获得的Pareto解集至少存在一个不被另外两种算法所得解集个体支配的解。算例规模较小时,3种算法性能相差不大,不同算法所得解之间基本不存在支配的情况,但算例规模增大后,MACGA的优势更加明显。Me和Ev可以反映解集的收敛性,从收敛性角度而言,本文所提算法具有一定的优越性。SP越小,Pareto解集分布越均匀,算法可以朝着各个方向进化。57个算例中,MACGA在43个算例所得Pareto解集的SP均优于SPEA2和NSGA-Ⅱ。3种算法中,SPEA2在所有算例中的运行时间最短;与NSGA-Ⅱ相比,在相同算例的情况下,MACGA的运行时间更长,但都不会超过NSGA-Ⅱ算法运行时间的1.2倍,说明MACGA并不会由于所提的操作使得运行时间大幅增加。
3.2 算法分析
将本文所提出的算法用于求解算例,算例的运行地图为图8,加工信息见表3,表中的信息包括工件的加工路线及其对应的加工时间,每道工序有多个可加工设备。
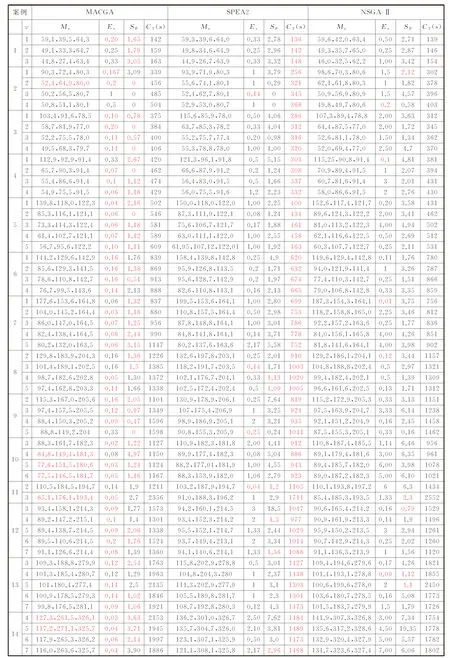
表2 不同算法求解的算例结果
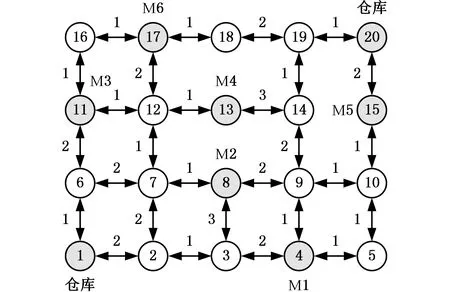
图8 案例车间地图Fig.8 Case workshop map

表3 加工信息表
表4所示为最大完工时间TC、AGV运行时间TT以及机器总负荷TM的最小值随AGV数量增多而变化的情况。由表4发现,不管AGV数量怎么变化,机器总负荷的最小值都收敛到145。最大完工时间随AGV数量的增多先减小后不变,这是因为最大完工时间在AGV不多的情况下受AGV数量的制约,加工机器有较多空闲时间;AGV数量增多后,加工机器成为制约最大完工时间的因素,出现工件运输完成、等待机器执行加工任务的情况,所以AGV增加到一定数量后,最大完工时间不会随之减少。AGV运行时间随AGV数量的增多一直在缩短,因为AGV数量增多时,AGV分配的解空间增大,存在使运行时间更短的分配情况。

表4 各目标在不同AGV数量下的值
图9所示为AGV数量为3的情况下,初始值、迭代10次、迭代100次Paterto解集的分布情况,可知,随着迭代的进行,算法得到的Pareto曲面逐渐收敛。

图9 Pareto前沿变化Fig.9 Pareto front change
图10、图11分别为AGV数量为3情况下的生产甘特图和各路段的时间窗图。图10包括各加工设备的加工任务以及各AGV的运输任务,其中,不同颜色表示不同的工件,O表示加工阶段,第一个下标为工件号,第二个下标为工序号,ET表示空载运行阶段,AGV的不同颜色表示相应工件的负载运行阶段。由图10可看出,最大完工时间为84 min,各工序的开工时间均不早于在同一加工设备上加工的前序工序的完工时间以及负责该工序的AGV负载完成时间,AGV的空载开始时间均在工件的前道工序完工时间之后,负载开始时间均在空载完成时间之后,满足数学模型中的约束条件。各路段时间窗未出现重叠的情况,也不存在同一时刻AGV出现在不同路段的情况,说明基于时间窗的Dijkstra算法可以有效地为AGV规划无冲突的路径。

图10 甘特图Fig.10 Gantt chart

图11 各路段时间窗Fig.11 Time window of each road section
4 结论
本文在考虑AGV冲突的情况下,对AGV与加工设备集成调度问题展开研究,提出一种改进的交叉操作,采用了基于自适应聚类算法的父代来源选择策略和个体自适应交叉概率;为加强解集的多样性,引入了一种基于网格坐标的环境选择策略。
AGV的电量对AGV的调度会产生一定的影响,且实际生产中,机器和AGV可能会发生故障。因此,考虑AGV电量和车间异常等因素的集成调度更贴近生产实际,这将是接下来的研究方向。
