A review of the research and application of deep learning-based computer vision in structural damage detection
2022-01-21ZhangLingxinShenJunkaiandZhuBaijie
Zhang Lingxin, Shen Junkai and Zhu Baijie
1. Institute of Engineering Mechanics, China Earthquake Administration, Harbin 150080, China
2. Key Laboratory of Earthquake Engineering and Engineering Vibration of China Earthquake Administration, Harbin 150080, China
Abstract: Damage detection is a key procedure in maintenance throughout structures′ life cycles and post-disaster loss assessment. Due to the complex types of structural damages and the low efficiency and safety of manual detection, detecting damages with high efficiency and accuracy is the most popular research direction in civil engineering. Computer vision (CV)technology and deep learning (DL) algorithms are considered as promising tools to address the aforementioned challenges.The paper aims to systematically summarized the research and applications of DL-based CV technology in the field of damage detection in recent years. The basic concepts of DL-based CV technology are introduced first. The implementation steps of creating a damage detection dataset and some typical datasets are reviewed. CV-based structural damage detection algorithms are divided into three categories, namely, image classification-based (IC-based) algorithms, object detection-based(OD-based) algorithms, and semantic segmentation-based (SS-based) algorithms. Finally, the problems to be solved and future research directions are discussed. The foundation for promoting the deep integration of DL-based CV technology in structural damage detection and structural seismic damage identification has been laid.
Keywords: deep learning; damage detection; computer vision; loss assessment
1 Introduction
After an accelerated period of construction in critical infrastructure in the past few decades, civil infrastructures all around the world have entered a maintenance period. On the one hand, as the durability of the structure decreases, common types of damage begin to occur on the surfaces of structures. On the other hand, affected by strong winds, destructive earthquakes,and other external forces, varying degrees of damage to infrastructures will occur. How to detect damages and assess the relative condition of structures has always been a research hotspot in the field of civil engineering.Original structural damage detection methods are based on manual inspections. However, damage detection results from manual inspections are subjective, and the efficiency and safety of the detection process are poor.To reduce the limitations of naked-eye observations and improve detection accuracy and efficiency, automatic detection technologies were introduced. According to the type of data used, automatic damage detection methods are divided into vibration-based methods, vision-based methods, and acoustic emission-based methods. The vibration-based detection methods evaluate the condition of structures by analyzing physical quantities, as collected through the use of various sensors. Vibrationbased detection methods have been widely used for the SHM (structural health monitoring) system of long-span ridges, dams, and high-rise structures (Tanget al., 2019;Kankanamgeet al., 2020). However, these vibrationbased detection methods rely heavily on the data collected by sensors, which requires the use of a complex data acquisition system and transmission system to monitor the state of a structure. Once the system installed,it is often limited to accessing the sensors. Another drawback is that it is impossible to detect damage to a large number of structures without sensors. Vision-based detection methods evaluate structural health conditions by analyzing images collected by cameras. Based on this evaluation, vision-based detection methods can be applied to pavement damage detection, disaster loss assessment and other application scenarios without using sensors. Similar to vibration-based methods, acoustic emission-based methods rely on a signal collected by acoustic emission sensors to monitor or predict the damage state and damage development of structures. On the one hand, the acoustic emission-based method has the same drawback as the vibration-based method, that is, the sensor system needs to be arranged in advance. On the other hand, benefiting from its advantage in detecting internal damages to structures, acoustic emission-based methods have been widely applied to detect initial cracks in reinforced concrete (RC) beams, corrosion damage of steel, initial yield and failure of pre-stressed concrete beams, and so on. (Salamoneet al., 2012; Goszczynńska 2014; Ercolinoet al., 2015; Yoonet al., 2000)
Computer vision (CV) technology, which originated in the 1950s, is a complex interdisciplinary subject. The initial computer vision technologies were mainly used in the analysis and recognition of two-dimensional images,such as optical character recognition, damage detection of workpiece surfaces, analysis and interpretation of aerial images, etc. These types of traditional CV technology have also been widely used in the structural damage detection field. (Abdel-Qaderet al., 2003; Liuet al., 2014; Yeumet al., 2015) However, limited by data acquisition technology, data storage technology and computing power, CV technology can only recognize objects through manually extracted features in a long period in the past. Its detection accuracy and efficiency are far inferior to that of manual identification. In recent years, with the development of deep learning (DL)algorithms and the cost-performance improvement of computer hardware, CV technology has also ushered in an explosive period of development. At present,DL-based CV technology has been widely applied in handwriting recognition (Yanget al., 2015), license plate recognition (Montazzolliet al., 2018), and face recognition (Taigmanet al., 2014). Some researchers have also adopted DL-based CV technology to detect structural damage.
Spenceret al. (2019) summarized the advances in CV-based structural inspection applications and monitoring inspections. From the perspective of data science and engineering, Baoet al. (2019) emphasized the importance of DL algorithms in SHM. Dong and Catbas (2020) gave a general overview of the concepts,approaches, and real-life practices of CV-based structural health monitoring at the local and global levels. Yuanet al. (2020) summarized the research status of ML in the SHM field from multiple perspectives, such as enhanced vision inspection, impact diagnosis, and so on.Bao and Li (2021) shed light on the principles for MLbased SHM from ML-based anomalous data detection,ML-based signal processing methodology, CV-assisted SHM, and artificial intelligence-based (AI) disaster management. The above four reviews summarized the development and application of CV and ML in SHM from multiple viewpoints, such as data processing, visionbased damage detection, and vision-based response measurement. There is no doubt that the above reviews made remarkable contributions to the development of CV-based and DL-based structural damage detection. As outlined above, the existing review literature summarizes the application of artificial intelligence and big data analysis in structural health monitoring from a broader perspective. As an important research direction, many scholars have carried out much research about visionbased structural damage detection. However, there is no review article that comprehensively summarizes the research and application of DL-based CV in the field of structural damage detection. Furthermore, this article systematically summarizes the current state of relevant research from multiple perspectives, such as principles,data sets, algorithms, and detection of objects. In addition, this article also provides future research directions in this field based on current research, as well as existing problems and challenges. In general, this article will provide references for further research and the application of DL in the fields of structural damage detection.
2 The basic concepts of DL-based CV technology
Computer vision is a technology that uses cameras,computers and other related equipment to simulate biological vision. In 1962, neurophysiologists Hubel and Wiesel (1962) conducted visual experiments on cats and found that the visual processing of cats always starts with a simple structure similar to a specific edge. In the same year, the first instrument that can convert pictures into grayscale values understood by binary machines appeared, which became the basis for using computers to process digital images. Subsequently, many excellent techniques based on feature engineering emerged in the field of CV technology, including local scale invariance,directional gradient histograms, spatial pyramids,mathematical morphology operations, etc. (Otsu, 1979;Canny, 1986; Haralicket al., 1987; Lowe, 1999). The above-mentioned feature engineering-based algorithms have been widely used in actual engineering applications(Abdel-Qaderet al, 2003; Fujitaet al., 2006; Iyer and Sinha, 2006). However, feature engineering-based CV technology relies heavily on manually selected features,such as corner points, edges, and gray continuity.Hence, the generalization ability and robustness of these methods is poor. To deal with the problem, researchers have attempted to combine CV technology with machine learning (ML) algorithms. Their goal is to use the nonlinear mapping capabilities of ML algorithms to improve the robustness of traditional CV technology.
The history of ML can be traced back to the 1940s.The neuron model (McCulloch and Pitts, 1943) was first proposed, and later new models such as the singlelayer perceptron, (Rosenblatt, 1958) ANN (artificial neural networks) (Yao, 1999), and the support vector machine (SVM) (Suykens and Vandewalle, 1999) were gradually proposed. ML-based CV techniques were also adopted to deal with some damage detection tasks(Hoang, 2018; Wanget al., 2017; Fujitaet al., 2017;Chenet al., 2011). The addition of ML algorithms has enhanced the robustness of feature engineering-based CV technology, but shallow features limit the ML-based model′s ability to process images with complex noise interference. Compared with traditional ML algorithms,DL has more hidden layers, more reasonable structures,and better optimization methods, which can extract higher-level features automatically. Hence, DL-based CV technology has gradually become mainstream in the field of CV. Common DL models include the deep belief network (DBN) (Hinton and Salakhutdinov, 2006), the convolutional neural network (CNN) (LeCunet al.,1989), and the recurrent neural network (RNN) (Mikolovet al., 2011), etc. Among the aforementioned DL models,the convolution kernel in CNN has the characteristics of translation invariance, rotation invariance, and scale invariance, which can make CNN more suitable for processing image data and extracting image features.The prototype of CNN is a Neurocognitron model, which was proposed by Fukushima in 1988 (Fukushima, 1988).The neurocognitive machine is composed alternately of a simple cell layer (S-Layer) and a complex cell layer(C-Layer). The S-layer can extract the local features of its input layer, while the C-layer is locally insensitive to stimuli from the exact location. The S-layer and C-layer are the prototypes of the convolutional layer and the pooling layer in CNN. In 1989, LeCun proposed LeNet based on the Neurocognitron machine (LeCunet al., 1989). Compared with ANN, CNN has two significant advantages, namely, weight sharing and local perception. Weight sharing means that the parameters in the convolution kernel can be shared each other, which can greatly reduce the complexity of the network. The weight sharing mechanism also takes advantage of the spatial correlation of the image, allowing the CNN model to automatically extract features. The local perception mechanism reduces the number of model parameters by reducing the number of connections between two adjacent layers of neurons.
The CNN model is mainly composed of the input layer, convolution layers, the pooling layer, the fully connection layer, and the output layer, as shown in Fig. 1.The convolutional layer is responsible for extracting image features. The pooling layer is responsible for additional features extraction and dimension reduction of feature maps, thus reducing the complexity of the model. The fully connection layer is used to plot the feature maps to a probability of belonging to a certain class of the image. The relation between the input layer and the output layer can be expressed by a complex nonlinear function, as shown in Eq. (1):
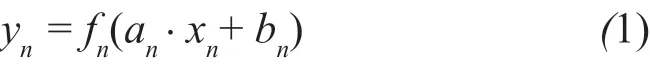
where,ynis the output tensor,xnis the input tensor,fnis the activation function,anandbnare the weight parameters and bias parameters, respectively. In 1989, LeCunet al.applied CNN to a handwritten digit recognition task for the first time and achieved 99.5% recognition accuracy(LeCunet al., 1989). However, due to the high cost of providing the training required to apply this method,CNN was ignored by researchers for a long time. In 2006,Hintonet al. proposed DBN and put forward several views, including: (1) the artificial neural network with multiple hidden layers has an excellent characteristic learning ability, (2) the difficulty of training for a deep neural network can be effectively overcome by layerwise pre-training (Hinton and Salakhutdinov, 2006). In 2012, Hintonet al. also deepened the CNN model and proposed a series of new technologies such as ReLu activation function, the dropout operation, and image augmentation (Hintonet al., 2012). The ReLu activation function not only solved the problems of gradient disappearance and gradient explosion during the training process, but also accelerated the convergence of the network. The proposal of Dropout reduced the overfitting phenomenon caused by the model being too deep. Image augmentation technology is proposed to reduce the overfitting phenomenon by increasing training samples through image translation, horizontal mirror transformation, rotation, etc. Moreover, stateof-the-art CNN architectures have achieved a less than 5% error rate (Heet al., 2016) on the 1000-class ImageNet classification problem (Denget al., 2009).In addition to CNN, other deep learning models have also been introduced into structural damage detection,such as RNN, generative adversarial networks (GAN)(Goodfellowet al., 2017), and so on. In contrast to CNN,RNN can process arbitrary input sequences based on the flow of internal memory. The structure of GAN is even more peculiar. There are two models in GAN, one of which is a generator; the other is a discriminator. The purpose of the generator is to learn as much as possible about real data distribution, and the purpose of the discriminator is to try to correctly distinguish whether the input data comes from real data or from a generator.
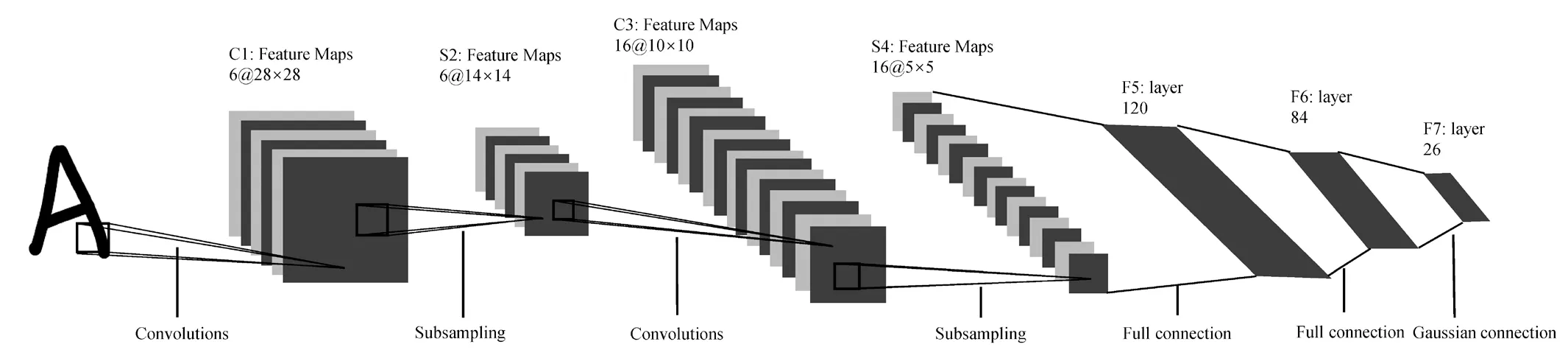
Fig. 1 Architecture of CNN (figure adopted from LeCun et al. (1989))
It can be seen from the history of CV that data sets and DL algorithms are the most important components of modern CV technology. The ImageNet dataset launched by Professor Li Feifei promoted the application of DL in the field of CV (Denget al., 2009). In terms of algorithms, DL-based image classification (IC), DLbased object detection (OD), and DL-based semantic segmentation (SS) have also enriched the application of CV technology. Among them, DL-based IC algorithms usually use CNN to identify the category of an image.The DL-based OD algorithms can not only identify the category of the target object but also locate the position of the target object in the image, as shown in Fig. 2. DLbased SS algorithms can classify and label target objects at the pixel level, as shown in Fig. 3. Considering the importance of data sets and algorithms in DL, this article will summarize the research and application progress of DL-based CV technology in damage detection from these two perspectives.

Fig. 2 Object detection (Ren et al., 2015)
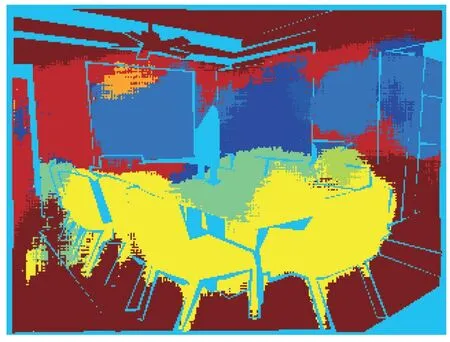
Fig. 3 Semantic segmentation (Badrinarayanan et al., 2017)
3 Damage detection data set
DL is a data-driven algorithm. High-quality structural damage data sets can not only improve the performance of the DL-based model but also promote the application of DL in the field of structural damage detection. Hence,establishing a structural damage data set is the first step in introducing DL-based CV technology into the field of structural damage detection. The establishment of a structural damage dataset involves two important steps:image acquisition and image annotation. The process of collecting images of damage to the surface of the structure through various digital cameras or smartphones is called “image acquisition”. The process of manually classifying the collected images or using image annotation tools to mark the target area in the images is called “image annotation”. This section will introduce the damage detection dataset from three aspects: image acquisition, image annotation, and common damage data sets.
3.1 Image acquisition
Collecting damage images is the first step for creating a damage detection data set. With the development of various technologies, the tools used for image collection have gradually diversified. The most common collection tools include digital cameras (Huanget al., 2017; Chaet al., 2017; Niet al., 2019a; Kimet al., 2019; Kim end Cho, 2019; Xuet al., 2019a, 2019b), mobile phones (Shiet al., 2016; Maedaet al., 2018; Zhanget al., 2016),driving recorders (Banget al., 2019), Google Street View Static API (Yuet al., 2020), etc. Digital cameras became the main tool for image acquisition due to their high quality of imaging and wide zoom range. With the development of mobile phone camera technology, new equipment, such as miniaturized high-pixel sensors and telephoto lens have been integrated phones, and in turn into mobile phones. Hence, mobile phones now have an image quality that is comparable to that of an expensive digital camera. In addition, compared to digital cameras,mobile phones are smaller and more convenient for shooting. However, digital cameras and smartphones have the same drawbacks: (1) the captured images are not continuous and the ability to obtain an overall image of a structure is poor, (2) they cannot be used to capture images of large-span, high-rise structures. To solve the above two problems, UAV (unmanned aerial vehicles) are useed to collect images of damage. First,UAV can customize a trajectory and program a route in a personalized way to systematically collect images of detected objects (Kang and Cha, 2018). Second, the UAV platform displays excellent maneuverability and versatility. Hence, it can adapt to complex environments and can be used for long-span bridges, dams, and highrise buildings. Due to the above two characteristics, in recent years UAV has become one of the most popular tools for image acquisition. Xionget al. combined UAV and GIS to collect multi-directional images of damage to buildings following earthquakes (Xionget al., 2020).Qiet al. used a rotor UAV to collect a large number of images of scene showing earthquake damage in the Lushan earthquake disaster area (Qiet al., 2016). Yanget al. used UAVs to collect many images containing surface spalling and crack damage to bridge structures(Yanget al., 2017).
With the popularity of consumer UAVs and highpixel mobile phone photography, image collection will become increasingly easy. After a sufficient number of damage images is collected, those images must be annotated before they are included in a data set that can be input into the DL model for training purposes.
3.2 Image annotation
Most of the damage detection algorithms mentioned in this article centered on the supervised learning algorithm, that is, when the category of the sample is known, the sample is classified by adjusting the parameters of the DL model. In supervised learning algorithms, the categories of samples need to be manually labeled. For different types of tasks, image annotation methods are also different. For IC tasks,image annotation means artificially labeling each image with a label belonging to a certain category. Taking the task of identifying cracks using IC-based methods as an example, the labels of cracks and non-cracks can be set to 1 and 0, respectively. Annotating images used for OD and SS tasks requires special image annotation tools. Table 1 briefly summarizes several mainstream annotation tools and their characteristics. As shown in Table 1, the image annotation tools are divided into two categories, namely, annotation tools for an OD task and an SS task. As shown in Fig. 4, annotation tools for an OD task usually use bounding boxes to label objects,while for an SS task, the annotation tools will label the objects along the contour.
3.3 Common damage data sets
By summarizing the literature, the damage detection data sets are mainly divided into three categories,namely, the crack detection data sets, the multi-category damage detection data sets, and the multi-level damage detection data sets. As the most intuitive damage index for characterizing various structural damage, cracks have many related data sets, so they are regarded as a separate category. The multi-class damage detection data set contains images of and labels for multiple damage categories. Taking rebar-concrete structures as an example, there are four types of damage, namely,concrete cracks, concrete spalling, rebar exposure, and rebar buckling. The multi-level damage detection data set is composed of damage at multiple levels such as structure and component, which are used to detect global and local damage, respectively. Table 2 lists the representative data set, the scale of the data set, and the input image size. As shown in Table 2, the scale of the data set is quite different, which is mainly related to the type of the task, the size of the original image, and the algorithm used.

Fig. 4 Labeled result of dataset (Lin et al., 2014)
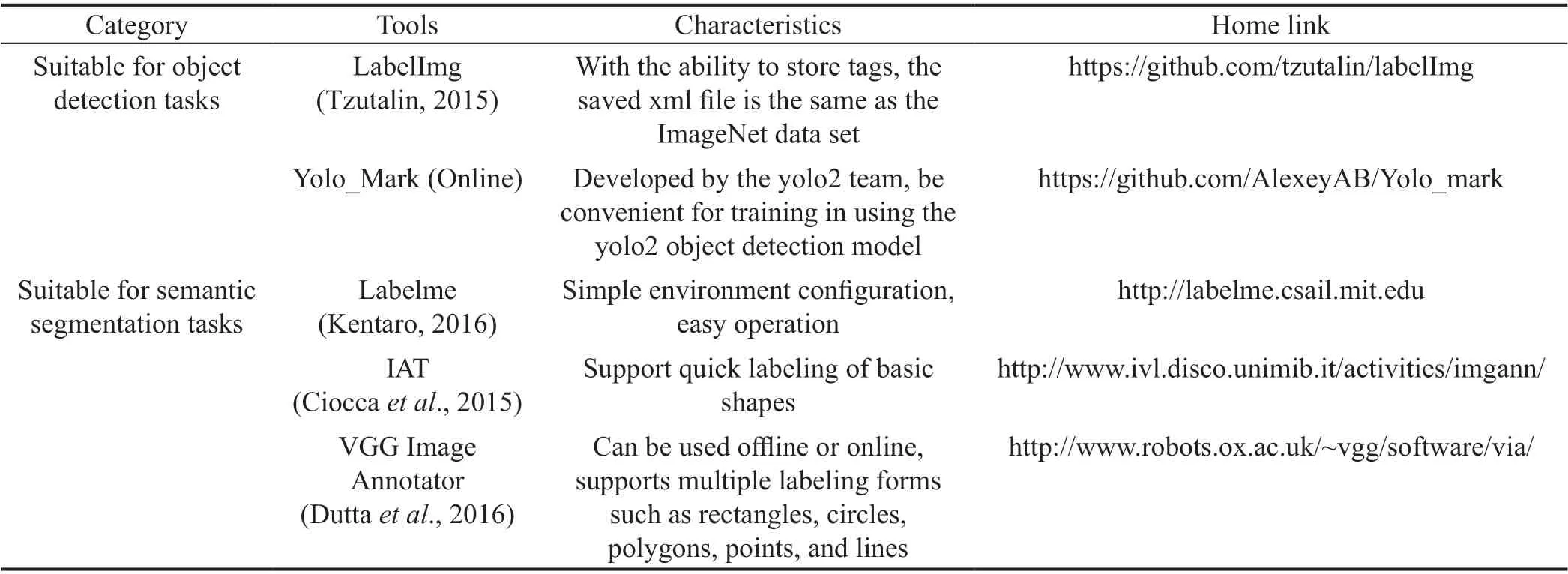
Table 1 Common image annotation tools
3.3.1 Crack detection data set
The CV-based crack detection algorithm is a popular research direction employed in the field of structural damage detection. Therefore, researchers have produced many data sets for training for the use of crack detection algorithms. The crack detection data set is divided into two categories, which include the data set used to train for the IC-based model and the data set used to train for either the OD-based or SS-based model.
Data set for IC-based model.The size of the original image is very large. Directly taking the original image as an input vector will not only take up too much video memory, but also reduce the efficiency and accuracy of training. To overcome this problem, the original image is often cut into several sub-images by by using a sliding window. For example, Xuet al. (2019a) used a window with a resolution of 64×64 sliding on raw images collected from the surface of a steel box girder, thereby obtaining 67,200 sub-images. These sub-images were divided into three categories: crack images, background images and handwriting images, as shown in Fig. 5. The databank (DB) dataset produced by Chaet al. (2017) for detecting concrete surface cracks contains 332 original images. Among them, 277 pictures have a resolution of 4928×3264, and 55 pictures have a resolution of 5888×3584. Chaet al. cropped 277 original images into 40,000 sub-images with a resolution of 256×256 as the training set, and the remaining 55 images were used as the test set to test the performance of the model. Niet al.(2019a) collected 800 original images with a resolution of 4000×6000 using a Canon EOS M3 camera, then cropped them with a sliding window with a resolution of 224×244. A total of 130,000 sub-images were obtained,including 65,319 crack sub-images and 64,681 noncrack sub-images. Chen and Jahanshahi (2017) used the same method to obtain 296,804 crack sub-images, taken from video images. In order to enhance the model’s ability to detect cracks in various directions, these crack images were rotated and flipped. A total of 147,344 crack images and 149,460 non-crack images were obtained.

Fig. 5 Dataset created by Xu et al. (2019a)

Table 2 Common damage detection dataset
Data set for OD-based or SS-based model.As contrasted with the data set used to train for using the IC-based model, the production process of the data set used to train to use the OD-based and SS-based model requires the assistance of image annotation tools. Kimet al. (2019) used the VGG annotation tool (Duttaet al., 2016) to mark cracks in the collected images; the annotation results are shown in Fig. 6. Banget al. (2019)used the LEAR image-tagging tool (Marszalek and Schmid, 2007) to mark 527 images that were collected by using black-box cameras. Zhanget al. (2020) labeled the images of cracks at the pixel level, as shown in Fig.7. The use of annotation tools can effectively improve the efficiency of manual image annotation.
The above two methods of creating crack detection data sets have their own advantages and disadvantages.The method of making a data set for training to use the IC-based model is relatively simple, but the detection accuracy of the model trained for the data set is low.The advantage of the method of producing data for the OD-based or SS-based model is that the labeled crack region is more accurate. However, the annotation toolsbased method is more difficult, and the process is more complicated.
3.3.2 Multi-class damage detection data set
The purpose of establishing a multi-class damage data set is to train to use a model that can detect multiple types of damage. In actual engineering structures,there are many other types of damage rather than crack damage, such as concrete spalling, rebar exposure,and rebar buckling, or corrosion in steel structures. In order to identify multi-damage types, Chaet al. (2018)employed a bounding box to mark the damage region.The marked areas of damage included surface cracks in concrete structures, bolt corrosion and surface corrosion in steel structures, etc. Xuet al. (2019b) also used a similar method to manually mark the damage on the surface of a concrete column by using a bounding box.To accurately identify the cracks and spalling damage to a concrete structure, 278 images showing spalling damage and 954 images revealing cracking damage were manually labeled by Yang at the pixel level (Yanget al., 2017). Similarly, Liet al. (2019) created a multiconcrete damage detection data set by the use of a matting operation in a Photoshop operation. In general,the establishment of multiple damage data sets enriches the scope of damage detection algorithms.
3.3.3 Multi-level damage detection data set

Fig. 6 Crack detection dataset based on polygonal regions (Kim et al., 2019)
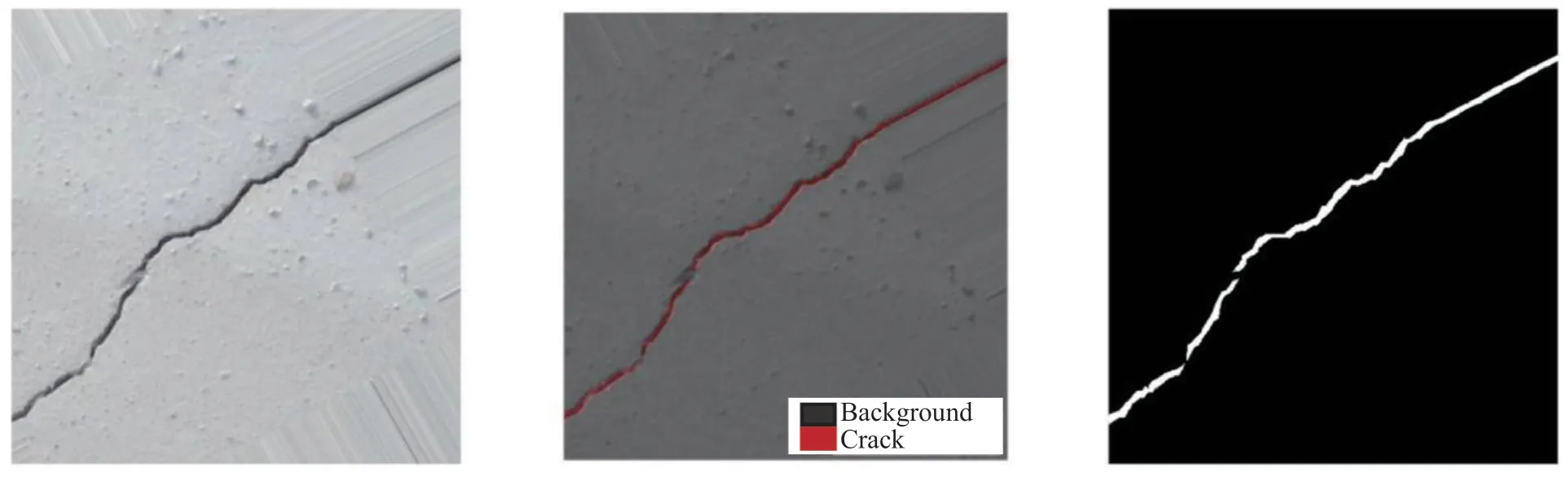
Fig. 7 Crack detection dataset based on pixel labeled (Zhang et al., 2021)
Due to the large number and types of images collected at a post-earthquake scene, how to use these images for structural damage detection is a challenging task. The purpose of establishing a multi-level damage detection data set is to make full use of the image data to more efficiently classify the damage state of the structure. For example, a data set created from structure-level images can train one to use a model that can identify whether the structure is collapsed. The damage state of the key components can be assessed by the model trained for by using a data set consisting of component-level images collected at a post-earthquake scene. To detect structural damage in post-disaster areas, Yeumet al.(2018) produced two types of data sets, which were used to detect whether the overall structure collapsed and to identify the damaged components. To detect multi-class damages and multi-level damages, Gao and Mosalam(2018) proposed a data set named Structural ImageNet.As shown in Fig. 8, the data set classified damage images taken on three levels, namely, the structure level,the component level, and the pixel level. The structurelevel data sets are used to train the overall damage detection model or identify the type of structures. The Component-level data sets are used to train for using the component identification model, the local damage detection model, and the damage severity detection model. The pixel-level data sets are mainly produced to identify the surface materials of the components and damage that needs to be quantified, such as concrete cracks and spalling. Liang (2019) established a multilevel bridge damage detection data set that included the overall damage identification of a bridge system, pier identification, and pier surface spalling identification.For the component-level detection task, bounding boxes are used to mark the pier. For the pixel-level detection task, the spalling region on the surface of piers was marked by using pixel-level annotation tools.
4 DL-based structural damage detection methods
In this section, the applications and methodologies of DL-based structural damage detection algorithms will be reviewed and summarized. According to the difference in detection accuracy and the basic framework used, these methods can be divided into three categories,namely, IC-based damage detection algorithms, ODbased damage detection algorithms, and SS-based damage detection algorithms. Taking the crack detection task as an example, Fig. 9 presents the detection results using three types of methods. As shown in Fig. 9, the IC-based methods use fixed-size boxes to detect the crack regions. Compared to IC-based methods, the size of the box used in the OD-based method varies with the size of the crack area. It is worth noting that because the size of the box that was used is much larger than the width of the crack, the detection results of these two methods still contain a large amount of background area.The detection accuracy of the SS-based algorithms has reached the pixel level, which is of great significance for the quantitative analysis of local damage. In addition, the IC-based methods have a wider range of applications,which can detect local damage and judge the overall damage state of a structure. Most of the OD-based and SS-based algorithms can only be used to detect local damage.
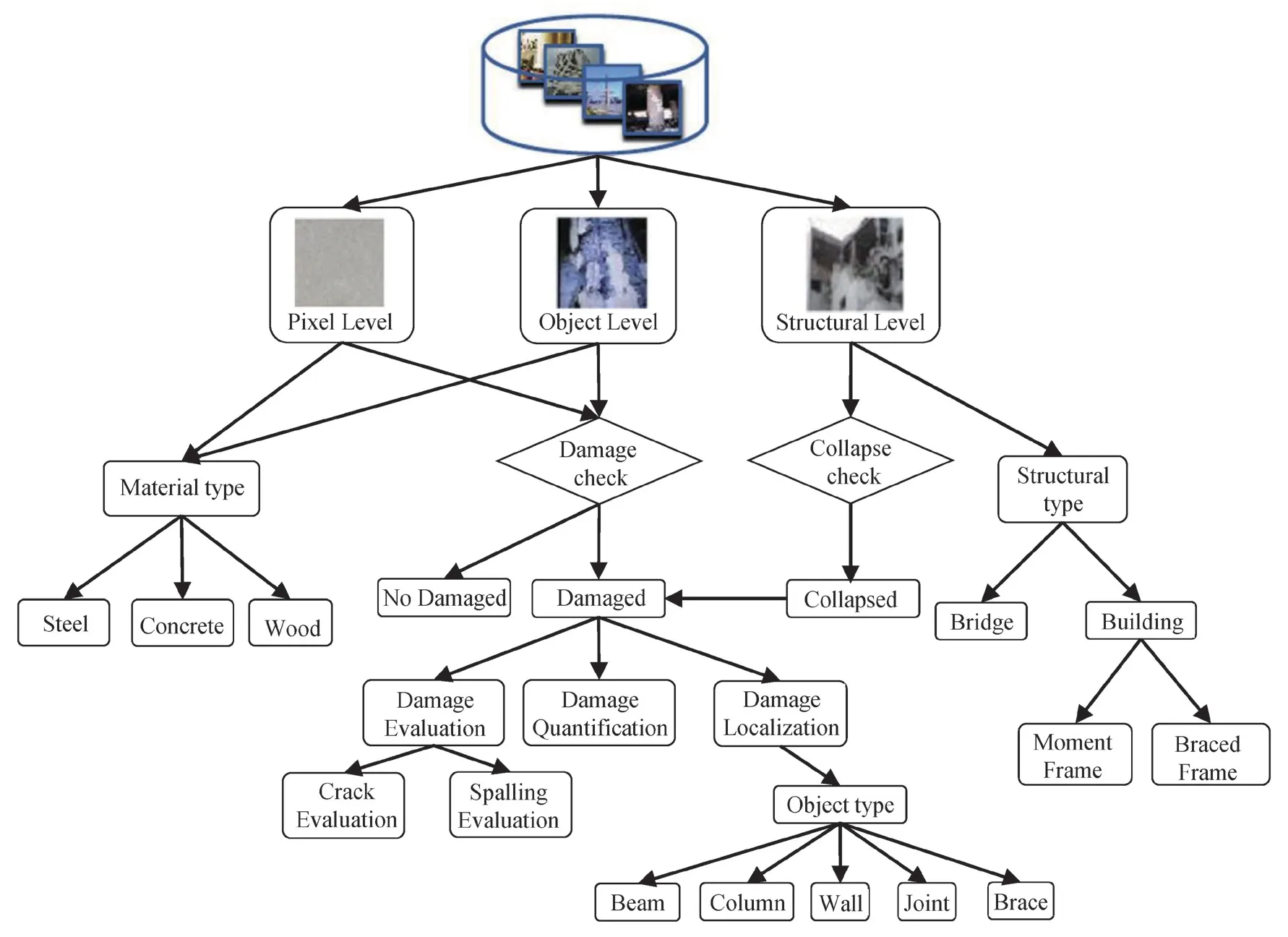
Fig. 8 Hierarchical chart of Structural ImageNet (Gao and Mosalam, 2018)
4.1 IC-based methods
The goal of IC-based methods is to classify whether the image/image patch contains damage. According to the different levels of detection objects, IC-based algorithms are divided into local damage detection algorithms and global damage detection algorithms. Due to the limitation of the storage space of the GPU, the size of the input image of the IC-based model is also limited during the training process. The size of the image collected in the actual project is relatively large, so the raw images need to be cut into sub-images or resized into small size images during model training and testing.Generally, for the task of detecting local damage, such as cracks or spalling, the raw images will be cut into sub-images and then input into the model for training purposes. For the global damage detection tasks, the raw images will be resized to small-size images. In this part of the process, the IC-based damage detection algorithms will be analyzed and summarized in detail from the aspects of local damage detection and global damage detection.
4.1.1 Local damage detection
According to the classification of the structure type,local damage to a structure is divided into road damage,building structure damage, and bridge structure damage.Among the local types of damage, crack damage is the most widely distributed and the most obvious local type.Figure 11 presents the implementation process of the ICbased crack detection algorithm.
Pavement damages.In 2016, Zhanget al. (2016)first proposed a road crack detection algorithm based on DCNN (deep convolutional neural networks) and compared it with an SVM-based detection method. The results showed that the detection accuracy of the road crack detection algorithm based on DCNN was greatly improved when compared to the SVM algorithm. Nhat-Ducet al. (2018) compared the differences between edge detection and CNN-based methods in pavement crack detection. The integrated and fully automated feature extraction capabilities of the CNN model made the detection accuracy of the CNN-based method much higher than that of the edge detection-based manual feature extraction method. To further improve the efficiency of model training, Gopalakrishnanet al. (2017)introduced transfer learning (TL) into the pavement crack detection method that is based on DCNN. The TLbased damage detection model could significantly save on training costs and improve training efficiency. To identify multiple types of pavement damage, Shaet al.(2018) designed three different CNN-based road damage detection models, namely, the disease detection model,the crack disease extraction model, and the pit slot disease extraction model. The above pavement damage detection algorithms can only identify these types of damage. To quantitatively analyze pavement cracks in more detail, Tonget al. (2018) proposed a pavement crack width detection model based on DCNN.
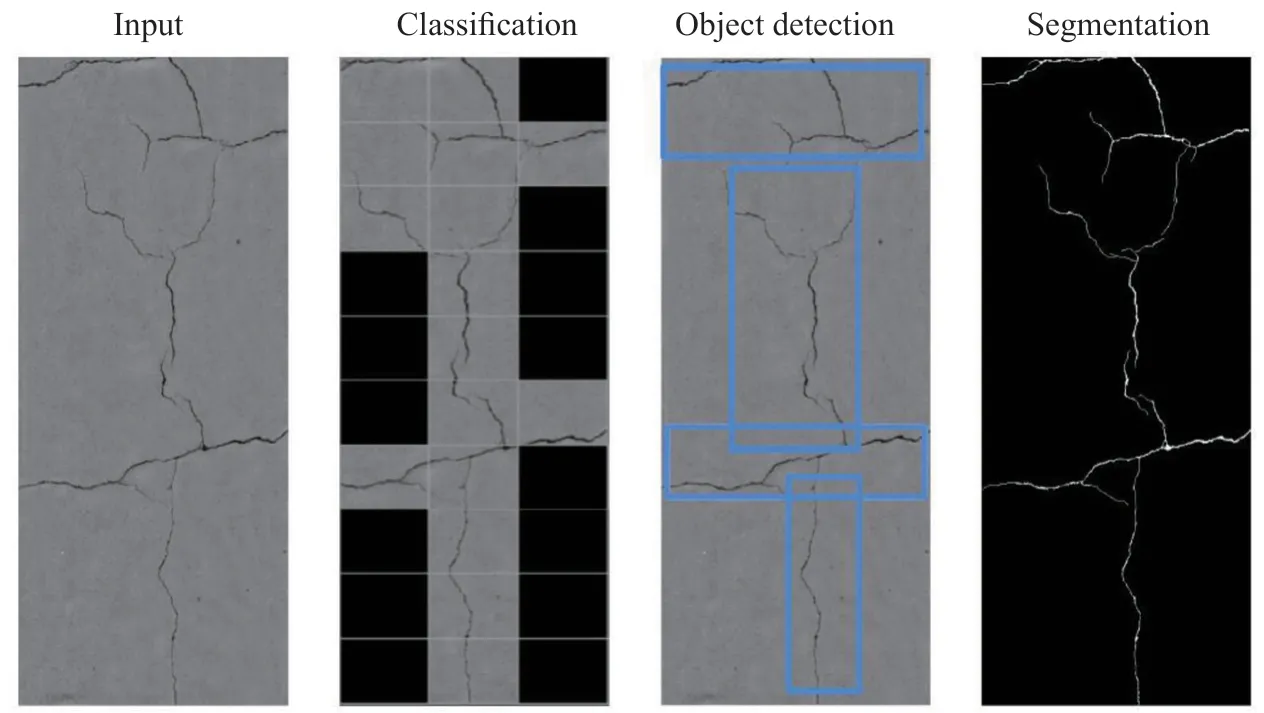
Fig. 9 The detection results of three types of methods (Hsieh and Tsai, 2020)
Building damages.Reinforced concrete structures account for the largest proportion of building structures.Consequently, there are many studies on damage detection on concrete surfaces. In 2017, Chaet al. (2017)proposed a CNN-based algorithm for detecting cracks in concrete. The new method was compared in detail with the traditional Canny edge detection algorithm and the Sobel edge detection algorithm. The comparison results showed that the new method had a higher detection accuracy and a stronger generalization ability. Dorafshanet al. (2018) also compared the performance of concrete crack detection algorithms based on DCNN and edge detection. The results showed that the DCNN-based model had more powerful detection capabilities than was the case for edge detection algorithms. Kimet al. (2019)compared the performance of the SURF-based (speedup robust features) crack detection models and DCNNbased model on concrete surface crack detection tasks.At the same time, they also found that combining CNN or SVM with local or global features can effectively improve detection accuracy. Compared with the damage detection method that is based on traditional IPT-based(image processing technology) technology, the CNNbased damage detection algorithms show a greater improvement in detection accuracy and robustness.Except for constructing a new developed CNN model and retraining for all parameters, many researchers chose to adopt general CNN models and train for the use of some of the parameters to realize transfer of model performance. Kimet al. (2018) used TL technology on the fine-tuned AlexNet (Hintonet al., 2012) to train to use a CNN model that can detect five types of damage. The five types of damage are: Crack, Joint/Edge (Multiple Line),Joint/Edge (Single Line), Intact Surface, and Plant. As the non-crack areas in the actual image have crack-like features, this method showed non-crack areas in more detail. Atha and Jahanshahi (2018) studied the impact of input images on the detection accuracy of the CNNbased model by changing the size and color space of the input image. In addition, the influence of different CNN models on the performance of steel structure corrosion damage detection has also been studied. The results showed that to achieve the best detection performance,the following four conditions must be met: the size of the input image is 128×128 pixels, the color space is RGB or YCbCr, the CNN model is VGG16 (Simonyan and Zisserman, 2014), and transfer learning is adopted. Chowet al. (2020) proposed an AI (artificial intelligence)-based method that can detect different types of concrete structure damage in various environments. The method included three main modules, which are responsible for detecting damage, extracting damage and classifying damage, respectively. First, the approximate distribution of damage in the image was obtained by using the convolutional self-encoding module. Next, threshold analysis is used to extract the damage area. Finally,transfer learning is used to classify the damaged area.This hybrid method could eliminate the interference of light, shooting distance and shooting angle to accurately detect various types of damage to concrete. Janget al.(2019) proposed mixing visual images and infrared thermal imaging images and studying the influence of the CNN model, including training for the use of mixed images with regard to detection reliability.
Bridge damage.Zhuet al. (2020) developed a CNNbased bridge crack detection method. The accuracy of the proposed method is higher than that when using classical machine learning algorithms (MLAs). Xuet al. (2019a)improved the CNN model and proposed employing FCNN (fusion convolutional neural networks) to detect cracks on the surface of a steel box girder. To improve the speed of bridge crack detection, Liet al. (2019)proposed a hybrid method that combines CNN with image pyramid and ROI (region of interest) methods.To achieve real-time detection and improve the level of visualization, Yanget al. (2017) combined the CNNbased bridge damage detection algorithm with the UAV platform. Alipour and Harris (2020) proposed a model that can detect bridge cracks from images with different textures in a stable manner. The images in the data set used by these various existing crack detection models are relatively single, resulting in a trained model that is unable to identify cracks appearing in other materials. To solve this problem, three domain adaptation techniques,namely, joint training, sequential training, and ensemble learning, are proposed and implemented to develop robust crack detection models that can eliminate material environment interference. Except for the CNN-based methods, Xuet al. (2018) proposed an identification framework based on a restricted Boltzmann machine(RBM) for crack identification and extraction from images containing cracks and complicated backgrounds inside the steel box girders of bridges.
Other types of damage.IC-based damage detection algorithms are not only applied to the damage detection of pavement, buildings, and bridges, but also are widely used in various structures such as nuclear power plant components and gas turbines in power plants.Mohtashamet al. (2020) combined image processing technology with DCNN and applied this new method toward crack detection on the surface of gas turbines.The results prove that smoothing and median filtering of an image can effectively improve the crack detection accuracy of DCNN. Chen and Jahanshahi (2017)proposed an algorithm that can detect internal cracks in nuclear power plant components in real time in video. This algorithm combines the CNN classification model with the Naive Bayes data fusion scheme, which overcomes the shortcomings of the fixed bounding box scale used by the IC-based damage detection algorithm.Unlike Chen, who used the Naive Bayes data fusion scheme to locate cracks, Schmuggeet al. (2016) used the Spatial-Temporal Grouping method to locate cracks on the surface of nuclear power plant components.
The DL-based IC algorithms greatly improved the accuracy and robustness of local damage detection, but they cannot perform end-to-end damage detection. Endto-end means that the input and output of the DL model are both images. Since local damage occupies a relatively small amount of an entire picture, it is necessary to crop the original picture into smaller sub-images and then classify the sub-images. The output result based on the IC algorithm is a result vector, which needs to be further processed to visualize the damage detection result in the form of a picture.
4.1.2 Global damage detection
In addition to using the IC algorithm for detecting local damage, many researchers also applied it to global damage detection and disaster loss assessment. For example, Yeumet al. (2018) proposed the IC-based model to identify collapsed houses following disasters.This model can automatically divide the images of the post-disaster scene into four categories: collapsed buildings, damaged buildings, irrelevant images, and undamaged buildings, an approach which effectively improved the efficiency of image summarization in the post-earthquake data collection process. To improve the training efficiency of the CNN-based model, Gaoet al. (2018) adopted TL technology for the global damage detection model. TL not only effectively improves training efficiency, it also reduces overfitting caused by insufficient data. Although TL can improve training efficiency, it is still a challenge to adjust the hyperparameters of the model during the training process. To select appropriate hyperparameters during the training process, Liang (2019) adopted Bayesian methods to optimize the hyperparameters of CNN when training for the bridge system damage detection model. The above algorithms for determining the overall damage of structures are all based on damage images taken on the ground, and Xionget al. (2020) extended the application scope of the algorithm for global damage detection. They combined the IC model with the UAV platform to identify the global damage status of 66 multi-story buildings in the former Beichuan County.The IC-based global damage detection algorithm can judge the overall damage state of a structure from a macro perspective.
However, structural damages are complicated, and the damage state is also diverse. Table 3 is provided to give a clear view of the research status of IC-based damage detection methods.
4.2 OD-based methods
From the perspective of implementation principles and ideas, the OD algorithm is an improvement over the IC algorithm. IC-based local damage detection algorithms mainly include two steps. First, a sub-window is adopted to slide over the original image to generate sub-images. Then an IC model is used to classify the sub-images. The size of the window used by the IC model is often fixed, but the size of local damage in the original image is not fixed. Although some researchers have proposed several methods such as naive Bayesian fusion methods to merge several fixed-size windows into large windows (Chenet al., 2017a; Chen and Jahanshahi,2017), the implementation process of this method is still complicated. In addition, since the image classification model recognizes each sub-image in the image one by one, many calculations are required to detect the target.Hence, based on the IC algorithm, an OD algorithm that combines the region concept was proposed to overcome the challenges encountered by using the IC algorithm.The OD algorithm mainly includes two modules: the location module and the detection module. In the location module, several candidate-bounding boxes are generated through the use of the selective search method. In thedetection module, feature extraction and classification are used to classify the candidate-bounding boxes. Taking the R-CNN (Regions with CNN features, RCNN) model as an example, Girshicket al. (2015) added the concept of region candidates based on CNN. This method first used the selective search method to search and generate a large number of candidate regions, and then used CNN to perform feature extraction on this region. The output of CNN will be passed to SVM to discriminate the category of objects in the object frame. Finally, linear regression was used to continuously tighten the bounding box.Since the RCNN model needs to generate a large number of candidate regions by continually searching, detection speed is extremely slow. To improve detection speed,Fast R-CNN (Girshick, 2015) and Faster R-CNN (Renet al., 2015) essentially made two improvements based on RCNN: (1) proposing the ROI pooling operation, (2)and the proposal of RPN. ROI pooling can transform the input vectors with different sizes into a fixed-scale feature vector. ROI pooling enabled the Fast RCNN model to output fixed-dimensional feature maps even for inputs of different dimensions, providing support for the use of softmax classifiers. The proposal of RPN also improved the detection efficiency of the object detection algorithm. Table 4 summarizes the specific methods used in each step of the R-CNN series of algorithms. The above-mentioned RCNN series algorithms all must first generate a large number of candidate regions, and then perform classification and positioning. However, the step of generating candidate regions consumes too much computing resources, resulting in a decrease in detection efficiency. Therefore, Liuet al. (2016) proposed using the SSD algorithm (single shot multibox detector),which combines the location module and the detection module into a forward operation. Compared with the R-CNN series of algorithms, the SSD algorithm omitted the step of generating candidate regions, which greatly improved the speed of training and detection. Owing to the end-to-end advantages of OD algorithms, they have been widely used in local damage detection, such as concrete wall spalling detection, crack detection, and steel structure corrosion detection.
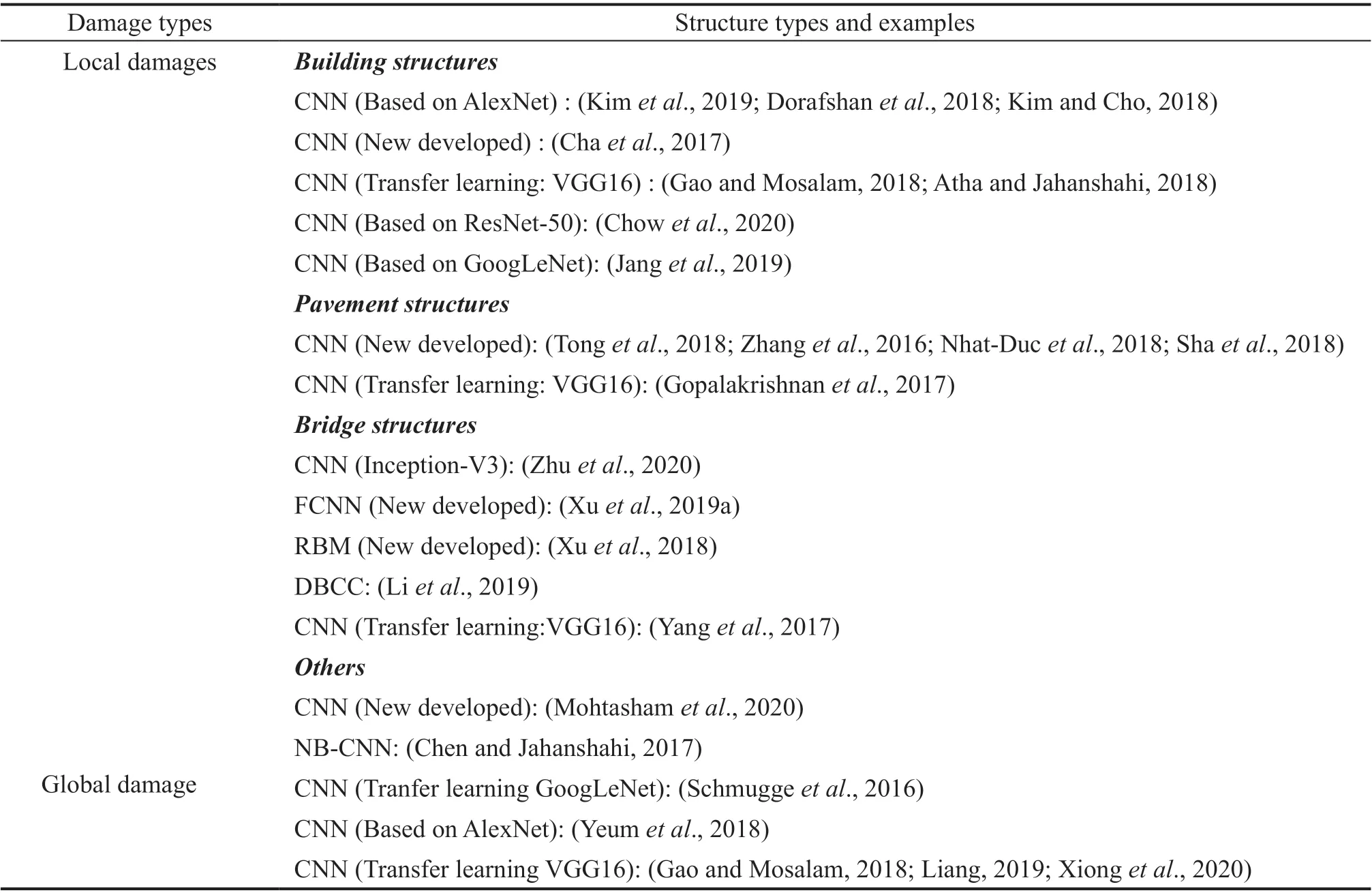
Table 3 Summarization of the applications and methodologies for IC-based damage detection methods
Yeumet al. (2018) first applied the RCNN model to detect the peeling damage of the wall in a post-disaster scene, but the detection accuracy is only 59.36%.Xue and Li (2018) improved the RCNN model. They constructed a CNN model for image classification based on VGGNet (Simonyan and Zisserman, 2014)and GoogLeNet (Szegedyet al., 2015) and combined it with RPN. Xuet al. (2019b) developed a Faster R-CNNbased algorithm for detecting concrete columns, and the accuracy of identifying various damages on the surface of concrete columns reached about 80%. Chaet al. (2018) established an automatic detection model for a variety of common types of damage of steel and concrete structures, based on Faster R-CNN. The detection result is shown in Fig. 10. Liuet al. (2017)applied TL to the Faster R-CNN model and established an automated system for creating a quality evaluation following construction. Ghoshet al. (2020) established a post-disaster building damage detection model based on Faster R-CNN. The model can detect four different types of damage, namely, surface cracks, spalling, severe damage with exposed rebars and severely buckled rebar.Wanget al. (2019) proposed a Faster R-CNN-based model for detecting damage to brick masonry structures.Moreover, an automatic damage detection system based on smartphones was developed, which realized real-time damage detection in brick masonry structures. Although the above algorithms can accurately and automatically detect and locate damage, the RCNN series of algorithms have defects, such as too many candidate regions and large model calculations. Therefore, Maedaet al. (2018)proposed a pavement disease detection model based on SSD (Liuet al., 2016). The damage detection speed of the new model in a 300×300 image on a PC (personal computer) has reached 30.6 ms per image. Similarly,Jiang and Zhang (2020) also established a real-time crack detection model based on SSDLite-MobileNetV2.The more lightweight SSD model has significantly improved detection speed. The detection speed on the XIAOMI 8 smartphone has reached 175.4 ms per image.
It can be seen in Fig. 10 that the detection result of the OD-based damage detection algorithm cannot effectively distinguish the boundary and contour of the damage. Even if some researchers use smaller boxes to mark the damage, the problem of loss of edge details of any damage remains. For small crack damage and rust damage, the area of the damaged area is an important indicator for evaluating the state of the component.Therefore, more accurate detection of such damage is required. Table 5 is provided to give a clear view of the research status of OD-based damage detection methods.
4.3 SS-based methods
Compared with the IC-based methods and OD-based methods, the SS-based damage detection algorithms can not only detect the damage category but also segment the damaged area along the edge. SS-based damage detection algorithms have experienced a process starting from manual feature extraction and extendingto automatic feature extraction. In the stage of manual feature extraction, SS algorithms mainly relied on various edge operators, filters, threshold segmentation, and other such methods (Abdel-Qaderet al., 2003; Nishikawaet al., 2012; Kimet al., 2017). However, manual extraction is too shallow to deal with the complex noise contained in images. The DL-based SS algorithm is an algorithm that can autonomously learn and extract higher-level image features. A large amount of image data brings stronger generalizational ability to DL-based SS algorithms. Common DL-based SS models include fully convolutional networks (FCN) (Longet al., 2015), Unet(Ronnebergeret al., 2015), SegNet (Badrinarayananet al., 2017), DeepLab (Chenet al., 2017b), etc. The architecture of the FCN is shown in Fig. 11. In this particular figure, FCN replaces the fully connected layer in the CNN with a convolutional layer, so that the output is changed from a one-dimensional result vector to a two-dimensional result vector. Subsequently, Unet and SegNet strengthen the connection between low-level features and high-level features based on FCN. At the same time, they also strengthen the up-sampling process,making the model a symmetrical encoding and decoding structure, which greatly improves segmentation accuracy.The DeepLab series of algorithms proposed the atrous convolution operation and combined DL model with the conditional random field (CRF). The proposal of the atrous convolution ensured that the model would fix the dimension of the feature maps throughout the feature extraction process. The addition of CRF considered the spatial relationship between adjacent pixels. Most of the methods that have currently been applied to damagedetection have relied on the encoder-decoder model, such as FCN, Unet and SegNet.

Table 4 The structure of the R-CNN series of algorithms
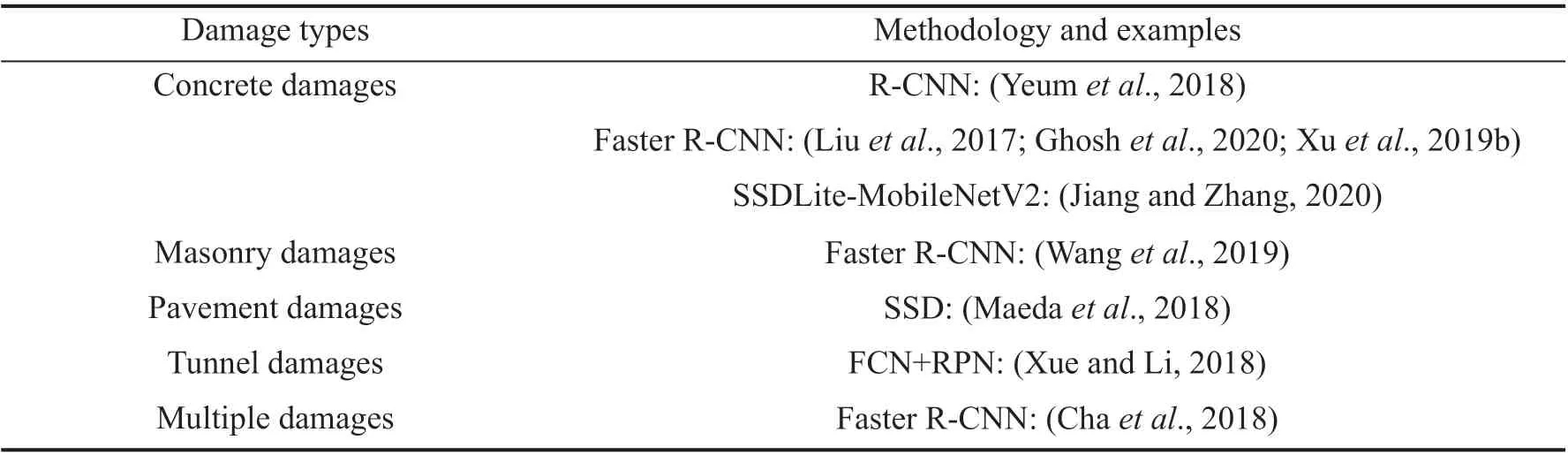
Table 5 Summarization of the applications and methodologies in OD-based damage detection methods

Fig. 10 Damage detection methods based on object detection (Cha et al., 2018)
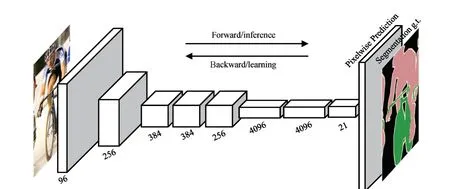
Fig. 11 Structure of FCN (Long et al., 2015)
The advantage of coding and decoding structures is that they can perform pixel-level damage detection end-to-end. For example, the FCN-based CrackPix model proposed by Alipouret al. (2019) has a detection accuracy of 92.1% for crack pixels. At the same time, the detection results of the CrackPix model are compared with traditional edge detection and adaptive threshold detection. The results from this comparison show that the detection accuracy of the CrackPix model is much higher than that is the case with traditional IPTs. Dung(2019) proposed a symmetrical FCN model to achieve pixel-level crack detection. The encoding path of the model uses VGG16, and the decoding path uses transposed convolution and upsampling to reconstruct the corresponding segmented image. Since the purpose of the encoding path is to extract the features of various types of damage, any CNN model that can extract features of damage can be adopted, such as VGG16(Yanget al., 2018; Alipouret al., 2019; Dung, 2019; Renet al., 2020), GoogLeNet (Niet al., 2019a), DenseNet(Meiet al., 2020; Meiet al., 2020; Li and Zhao, 2020),or ResNet (Banget al., 2019). Although the above models can effectively segment the damage, the shallow decoder path cannot effectively restore and locate the features extracted by the complex encoder path. To further improve detection accuracy, FCN models with symmetrical structures, such as U-Net and SegNet, are widely used in pixel-level damage detection. Huyanet al. (2020) proposed the CrackU-net model based on U-Net, using maximum pooling instead of average pooling and the pixel-scale cross-entropy function as the loss function. However, CrackU-net was trained for based on the use of a large-scale data set. To verify the performance of this U-net-based model in small-scale data sets, Liuet al. (2019) adopted Focal Loss, which is based on the U-net model, to solve the training problem caused by sample imbalance. The detection results show that the improved U-net model can also achieve high detection accuracy on small-scale data sets. The detection results are shown in Fig. 12(a). Compared with the IC-based method, the proposed SS-based method allows for pixel-level detection, with greater accuracy.Zhanget al. (2021) tried to find a crack segmentation model that balances detection accuracy and detection efficiency by changing the depth of U-net. Many other scholars have carried out pixel-level detection of various types of damage, such as cracks and spalling, that are based on this symmetrical FCN model (Liang, 2019;Janget al., 2021). The above methods are all designed for single damage detection. Liet al. (2019) proposed using the SegNet-based method for detecting multiple types of damage to the surface of concrete structures,including cracks, spalling, efflorescence and holes. As shown in Fig. 12(b), the accuracy of the detection results of multi-class damage at the pixel-level is very high.
This encoder-decoder-based SS algorithm performs well in segmenting damage to continuous areas. However,due to the structural defects of these algorithms, there are some speckle-type noises in the segmentation results.Hence, some researchers have performed pre-processing operations on the input image or post-processing operation on detection results to improve detection accuracy. Baeet al. (2021) performed super-resolution processing on the input image; the result showed that the detection accuracy of the model with super resolution pre-processing was higher than that of the original model, which lacked super-resolution. Yanget al. (2018)performed simple mathematical morphology operations on the crack images processed by FCN. This postprocessing operation not only removed the discrete noise but also filled the holes inside the cracks, which also improved the detection accuracy regarding conventional cracks. Meiet al. (2020) proposed combining the SS model with the depth-first search (DFS) algorithm. This new method effectively removes the noise scattered outside the crack area and improves the accuracy and robustness of crack detection. Obviously, the addition of pre-processing or post-processing can significantly remove the noise scattered outside the crack skeleton,thereby improving detection accuracy.
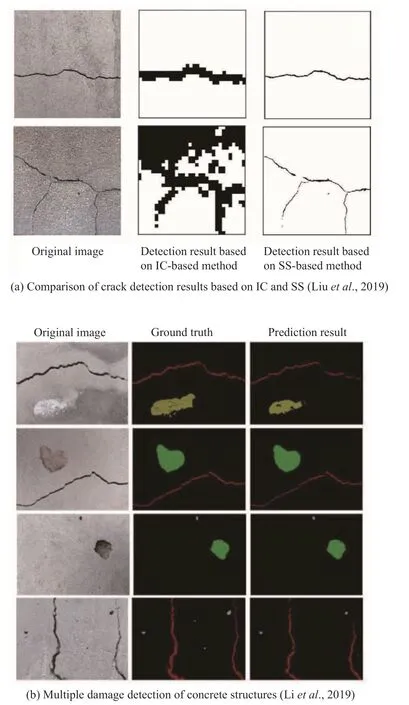
Fig. 12 Damage detection result based on semantic segmentation
In addition to the aforementioned SS model based on the encoder-decoder structure, researchers have also implemented pixel-level damage detection based on other DL models, such as Faster R-CNN, Dilated CNN, RNN, GAN (Generative Adversarial Networks)(Radfordet al., 2015), etc. Zhanget al. (2017) designed a type of network architecture based on CNN, named CrackNet, which employs 360 feature maps extracted by filters as input and achieves pixel-level crack detection on pavement surfaces. However, the computational resources consumed by the algorithm were huge, as it took nine days to complete the training for the model.Feiet al. (2019b) removed the maximum pooling layer and the fully connected layer, based on VGGNet. The number of parameters of the new model (without the maximum pooling layer) is greatly reduced and the efficiency of detecting images is higher than is the case with CrackNet. Niet al. (2019b) proposed a hybrid method that combines a multi-scale CNN classification model with IPTs to detect thin cracks. In addition to the CNN-based pixel-level detection methods mentioned above, Zhanget al. (2019) developed an RNN-based pixel-level crack detection method, named CrackNet-R.Since RNN considers the correlation of adjacent crack pixels, the detection accuracy of CrackNet-R is much higher than that of CrackNet. Zhanget al. (2020)proposed a pavement crack detection algorithm based on GAN. In the pavement crack detection task, the problem is that the FCN model is difficult to converge due to the imbalance of crack pixel and background pixel data, which always has been a challenge with regard to detecting pavement cracks. GAN can make the model detect cracks accurately while retaining the model′s ability to detect the background. Other researchers also use GAN to segment cracks (Zhanget al., 2020; Mei and Gül, 2020).
The SS-based algorithms overcome the shortcomings of IC-based and OD-based algorithms, not only for realizing end-to-end damage detection but they also improve detection accuracy. However, SS-based pixellevel damage detection algorithms also have obvious defects. On the one hand, these methods can only be used to detect local damage and cannot be used to detect overall structural damage. On the other hand, since semantic segmentation consumes additional computing resources, when processing a large number of images it is necessary to use an appropriate model according to the requirements of damage detection accuracy. Table 6 is provided to give a clear view of the research status of SS-based damage detection methods.
5 Conclusion and prospects
This paper presents an overview of the current stateof-the-art research on and applications for CV-based structural damage detection. First, the concepts of CV and DL are presented. Then, common image collectiontools and an image annotation tool for creating data sets are summarized. Based on existing damage detection data sets, the characteristics and production ideas of various data sets are summarized. Finally, taking some representative algorithms as examples, information about the latest progress the field of damage detection,plus improvements in the application of DL-based CV technology in this context are summarized and reviewed in detail. DL-based CV approaches have advantages in non-touch damage detection from a long-distance and low-cost application perspectives. Additionally, the pretrained DL model has been shown to process images more rapidly and accurately. DL-based CV technology has solved numerous problems that existed in the area of structural damage detection, but some problems still exist when that technology is extended to engineering applications. Below we list several research directions that are currently in urgent need of exploration.
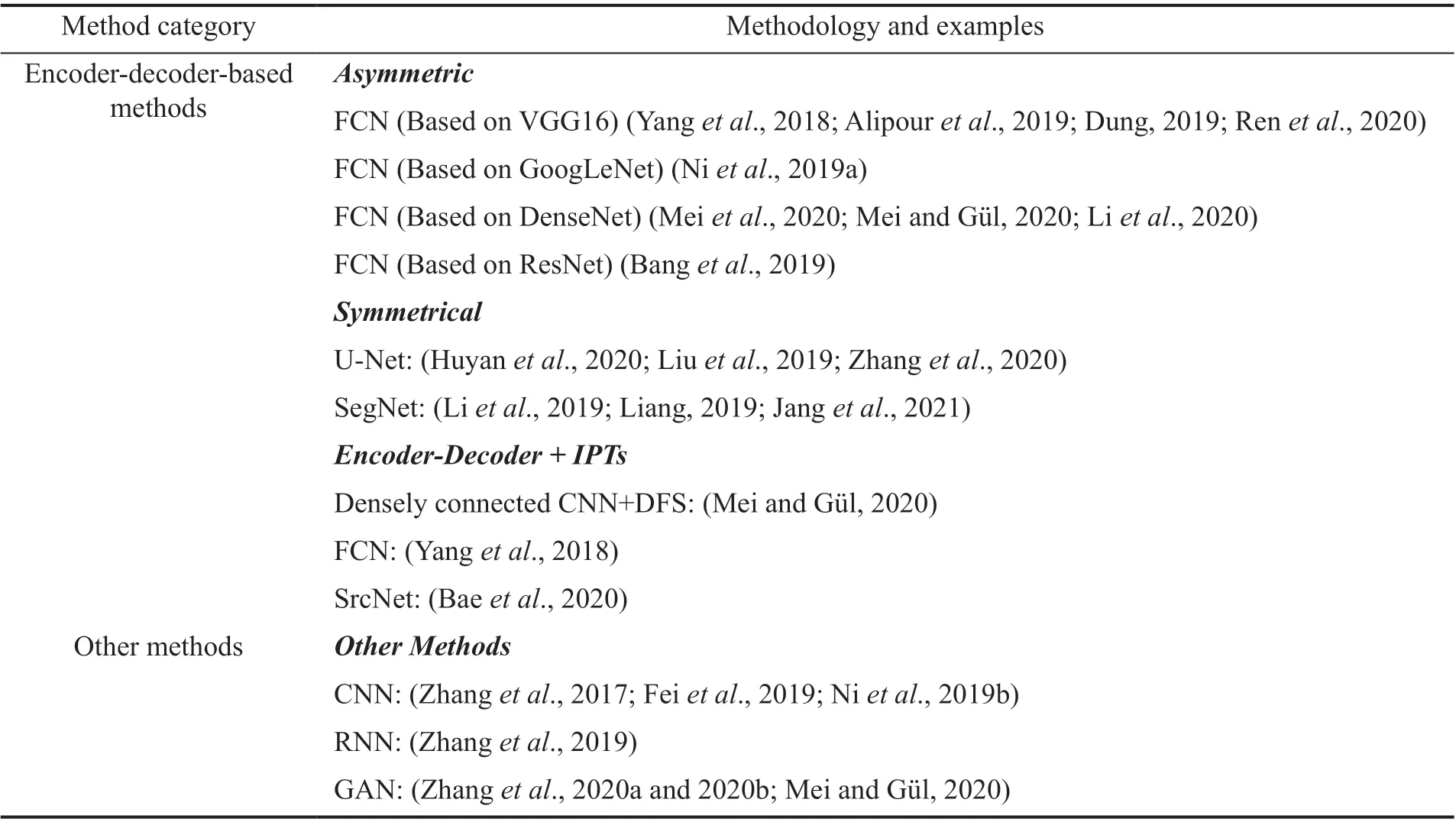
Table 6 Summary of the applications and methodologies of SS-based damage detection methods
(1) Establish a unified damage data set. DLbased methods are highly dependent on the scale and quality of a given data set. Several standard data sets for deep learning tasks such as image classification,object detection, and semantic segmentation have been established in other fields. Although many self-made data sets have emerged in the field of civil engineering, both the richness of image categories and the standardization of data sets lag behind popular data sets established in other fields. Therefore, the establishment of a high-level public damage detection data set is currently the most urgent need in the field of damage detection.
(2) Combine visible detection damage results with content analysis. Current damage detection can only output the damage type or level of damage, and this output still needs to be interpreted manually. Content analysis is a method that uses artificial intelligence to automatically analyze the characteristics and relationships of several objects in one image. By Combining the content analysis and the detection damage results of the images, the spatial correlation information and development trend of different damages will be automatically resolved.Therefore, how to solve these problems and realize automatic detection in a true sense—that is, input images and output reports—remains a challenge.
(3) Combine surface damages with inner damages.Visually based damage detection can only identify damage on the surface of a structure. However, vibrationbased methods and acoustic emission-based methods can reveal the inner damage state of a structure through data captured by various sensors. By combining the surface damage obtained based on CV with inner damage that is acquired based on monitoring data, the damage state of the current structure can be judged more accurately.At present, these three types of methods are basically in a state of independent research. How to effectively combine these three categories presents a challenge for researchers to solve.
(4) Quantifications of local damages. Since the type of damage detected by visually based damage detection methods is surface damage, it is unclear whether this damage presents a threat to the surface of a structure.At present, there are relatively few studies on evaluating the true damage state of structures by quantifying the damage detection results obtained by CV technology. Jiet al. used the proposed vision-based crack measurement method (Jiet al., 2020) and the deep learning-based crack segmentation algorithm (Miaoet al., 2021) to evaluate the damage level of a beam-to-wall joint specimen. This study provides a solution to construct a relationship between the vision-based detection result and the true damage state of structures. Furthermore,how to correlate detected visible damage with physical properties (including stiffness, strength, and deformation capacity) is another challenge that researchers must address.
(5) Combine relationship with finite element modeling (FEM). Because the surface damage detected by visual inspection cannot assess the actual damage state of a structure, it is possible to create FEM for numerical analysis through collected images. Based on 3D point clouds and light detection and ranging (LiDAR), some researchers have studied how to use these data sets to create an FEM (Conde-Carneroet al., 2016; Songet al.,2018; Huet al., 2019). By combining the relationship between visible damage and degradation in physical properties that are obtained by the abovementioned research results with the FEM reconstructed by compiling collected images, analyzing the safety status of the overall structural system will serve as an important direction for future research.
Acknowledgement
This study was financially supported by the National Key R&D Program of China (Grant No.2017YFC1500606), National Natural Science Foundation of China (52020105002), and Heilongjiang Touyan Innovation Team Program.
杂志排行

Earthquake Engineering and Engineering Vibration的其它文章
- Experimental study of vertical and batter pile groups in saturated sand using a centrifuge shaking table
- Analytical evaluation and experimental validation on dynamic rocking behavior for shallow foundation considering structural response
- Effect of geofoam as cover material in cut and cover tunnels on the seismic response of ground surface
- Dynamic response of concrete face rockfill dam affected by polarity reversal of near-fault earthquake
- Analyzing uncertainties involved in estimating collapse risk with and without considering uncertainty probability distribution parameters
- Theoretical and experimental studies on critical time delay of multi-DOF real-time hybrid simulation