深度学习中的单阶段小目标检测方法综述
2022-01-18李科岑王晓强李雷孝杨艳艳
李科岑,王晓强+,林 浩,李雷孝,杨艳艳,孟 闯,高 静
1.内蒙古工业大学 信息工程学院,呼和浩特010080
2.天津理工大学 计算机科学与工程学院,天津300384
3.内蒙古工业大学 数据科学与应用学院,呼和浩特010080
4.内蒙古农业大学 计算机与信息工程学院,呼和浩特010011
目标检测是计算机视觉的一部分,根据整张图像内容进行描述,并结合目标物体的特征信息,确定该物体的类别与位置。目标检测将目标的定位和识别合二为一,能够在特定的环境下实时且准确地检测出目标。目标检测技术常用于人脸检测、智慧交通、无人驾驶、遥感目标检测、行人计数、安全系统等各大领域。随着深度学习的发展,卷积神经网络(convolutional neural networks,CNN)被广泛应用,基于深度学习的目标检测技术将目标检测推向发展新高潮。其中,在追求速度与精度并行的算法中,基于深度学习的单阶段目标检测算法脱颖而出。与其他深度学习目标检测算法不同的是,单阶段目标检测算法结构简单,可以直接检测图像输出结果,没有候选区域的分类,因此相比其他深度学习目标检测算法速度更快,计算效率更高。典型的单阶段目标检测算法包括YOLO(you only look once)系列和SSD(single shot multibox detector)系列。但在单阶段目标检测算法的研究过程中出现了很多问题,例如模型检测精度较低,尤其对小目标及遮挡目标的检测更为困难。为解决单阶段目标检测与两阶段目标检测之间的精度差距,Lin 等人提出RetinaNet,解决了正负样本不均衡的问题,改进了背景样本的权重,使得模型更能关注较难检测的样本。
由于小目标物体分辨率较低且特征信息不明显,如何更精准地检测到小目标是目标检测领域的热点研究问题。文献[11]针对视频目标检测算法面临的挑战,从骨干网络、算法结构和数据集等方面总结了改进后的视频目标检测算法的优势和劣势。文献[12]针对边界/语义增强、全局/局部结合和辅助网络三方面的基于深度学习的显著性目标检测进行对比分析。文献[13]总结了目标类别检测核心技术与该研究的难点和发展方向。文献[14]从单阶段目标检测、两阶段目标检测以及结合生成对抗网络等方面总结了各种算法的改进过程。这些综述在目标检测的基础上从数据类别、检测特点以及算法改进等方面总结了当前主流的目标检测研究趋势。但目前存在的基于深度学习的目标检测文献综述仅综合了各种算法的优缺点,未系统地从某一方面归纳目标检测的改进方法。
综上所述,本文从单阶段目标检测算法的角度出发,总结了在此基础上改进的适用于小目标检测的方法。通过优化Anchor Box、引入注意力机制、优化残差网络和密集连接模块、特征融合、特征增强、引入其他网络、改进损失函数等几个方面的研究,总结归纳了基于深度学习的单阶段小目标检测的最新研究成果及未来的研究方向。
1 小目标检测简介
1.1 小目标的定义
在目标检测中对小目标的定义有两种方式,即相对尺寸的定义和绝对尺寸的定义。相对尺寸是根据国际光学工程学会(Society of Photo-Optical Instrumentation Engineers,SPIE)的定义,小目标为在256×256 像素的图像中目标面积小于80 个像素,即小于256×256 像素的0.12%就为小目标。另一种是绝对尺寸的定义,在MS COCO数据集中,尺寸小于32×32像素的目标被认为是小目标。2016年,Chen等人将小目标定义为在640×480 像素的图像中,16×16 像素到42×42 像素的目标。Braun 等人针对交通场景中的行人和非机动车驾驶人等数据,认为在30 像素到60 像素且被遮挡小于40%的物体是小目标物体。在航空图像数据集DOTA与人脸检测数据集WIDER FACE中将像素值范围在10 像素至50 像素之间的目标定义为小目标。在行人识别数据集CityPersons中,定义高度小于75 像素的目标为小目标。对于航空图像中的行人数据集TinyPerson,则将小目标定义为分辨率在20 像素至32 像素之间,而且进一步将像素值范围在2 像素至20 像素之间的目标定义为微小目标。总的来说,小目标没有精确唯一的定义,需要根据应用场景确定。
1.2 小目标检测的难点
小目标物体在图像中覆盖的区域较小,像素值在几十像素甚至几像素之间,其分辨率较低,特征信息涵盖较少,缺乏特征表达能力。经调研,导致小目标物体在检测过程中精度较低的原因主要有以下几点:
(1)特征信息较少。在常用的小目标数据集中,小目标样本分辨率较低,标注面积占比小,包含的特征信息不明显,且易受噪音点的干扰,进而导致模型无法对小目标进行精确定位。
(2)卷积神经网络的下采样率较大。卷积神经网络及其衍生算法是小目标检测的主流算法。在检测过程中,经过不断地下采样和特征提取,输出的特征图尺度会不断缩小。这很有可能导致下采样步幅大于小目标的尺寸,以致向下传递的特征图中可能未包含小目标的特征信息。
(3)数据集中正负样本分布不均。在大多数目标检测数据集中包含的小目标样本数占比较小,而大中目标样本数量居多。在训练过程中,模型会更关注大中目标样本,而忽略小目标样本,使得小目标样本只出现在样本集中很少被训练到的位置,为网络适应数据集带来困难。
(4)先验框设置不合理。在设置Anchor Box 时,可能只有一小部分与小目标的真实目标框(Ground Truth)重叠,并且Anchor Box 宽高比多变,很难精确定位到小目标物体。
(5)交并比阈值设置不合理。目前大部分检测器的匹配策略是用检测生成的Bounding Box 与Ground Truth 之间的交并比(intersection over uion,IoU)来划分正负样本。一般设定Bounding Box 与Ground Truth之间IoU≥0.5 所对应的Anchor Box 中的目标为正样本,其余为负样本。自定义阈值会对正负样本的选取造成很大的影响,而且该匹配方式更适合大中目标样本,容易出现小目标样本匹配较少、大中目标样本匹配较多的问题。
2 基于深度学习的单阶段小目标检测优化方法
2.1 优化Anchor Box
YOLO V3 算法使用-means 聚类从Ground Truth 中得到一些不同宽高比的框,即Anchor Box,并通过实验的方式在这些Anchor Box 中找出了9 个最优值。但通过这种方式产生的Anchor Box 往往定位不准确,容易造成正负样本不均衡的问题。同时,基于不同面积和宽高比的锚点框是一组预先定义的超参,通常的锚点框分为大、中、小三类尺寸,对于小目标数据集,固定锚点框得到候选框的设计方式会约束目标检测模型。
周慧等人提出自适应锚点框(adaptive anchor boxes,AAB)。该方法采用基于形状相似距离的DBSCAN(density-based spatial clustering of application with noise)聚类算法生成Anchor Box,提高了对目标区域的定位技术。采用基于形状相似距离的DBSCAN 聚类结果如图1 所示。
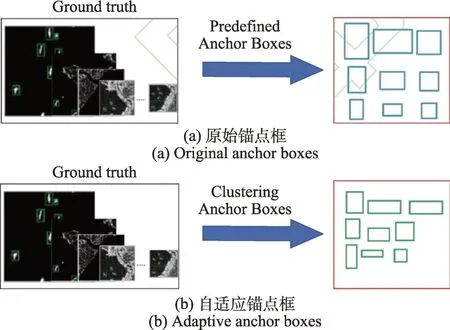
图1 原始锚点框与自适应锚点框对比Fig.1 Comparison of original anchor boxes and adaptive anchor boxes
从图1 中可以看出自适应锚点框相比原始锚点框尺寸变化较大,能适应不同尺寸的目标,应用于SAR图像的船舶目标能更好地反映目标的尺寸信息。
改变聚类方式可以训练得到不同的Anchor Box。采用DBSCAN 结合-means 的聚类形式产生Anchor Box,解决了-means 需要手动设定值的问题。李云红等人在DBSCAN 聚类之后,将经过误差平方和计算得到的值作为-means 聚类算法的输入,然后对数据集进行训练得到聚类候选框。改进后的算法提升了小目标物体与遮挡目标物体识别的准确率。罗建华等人和刘家乐等人采用-means++聚类的思想来代替-means 提取先验框中心点。但后者通过-means++聚类算法初始化Mini Batch-means的方法对数据集进行训练得到先验框,相比前者的设计大大加快了数据集的聚类时间。Mu 等人改进SSD 算法中Default Box 的设置,使用-medoids 算法计算Default Box 的初始横纵比,优化了传统SSD 算法的训练过程,缓解了应用在水面目标检测领域定位和分类不准确的问题。
通过改变聚类机制可以充分体现不同聚类算法对训练产生的Anchor Box 的友好程度。但一些聚类算法对输入参数较敏感,不能处理离群点或边缘点,对于密度不均匀的数据集,聚类效果差异较大。
2.2 优化网络模型
在目标检测的过程中往往需要骨干网络(Back-Bone)作为目标的特征提取器,常见的骨干网络有VGG-Net、SPPNet、ResNet、MobileNet、DenseNet、GoogleNet、ShuffleNet等。
YOLO V3 模型采用DarkNet-53 作为骨干网络,但对于特定的数据集,BackBone 中不同尺度对应的特征重要性不同。MobileNet_YOLO V3模型采用MobileNet 作为骨干网络,将标准卷积换为深度可分离卷积,使用逐通道卷积和逐点卷积的方式,优化了标准卷积中对所有通道都进行操作的缺陷。王建军等人通过稀疏训练统计不同尺度特征图中无效特征图的比例来调整网络深度,进而改善网络模型的性能。DarkNet-53 作为骨干网络时不能满足实时性要求。Li等人参考ShuffleNet和通道注意力机制中SENet(squeeze-and-excitation network)的思想构造BackBone,在保证速度的同时提升了准确度。
虽然YOLO V3 借助残差网络的思想实现了三尺度预测,融合了多特征信息,但其模型结构较复杂,损失了一定的检测速度,且其改进算法在提升小目标检测精度的情况下,忽略了大、中目标的检测效果。2020 年4 月,Bochkovskiy 等人在Redmon 等人的研究基础上提出YOLO V4 模型。该模型借鉴跨阶段局部网络(cross stage partial network,CSPNet)的思想,构造CSPDarkNet53作为骨干网络,降低了模型中参数的运算量,丰富了梯度组合信息。但在YOLO V4 模型中随着网络层数的不断加深,过多的卷积操作直接导致小目标特征信息的减少甚至消失,尤其对遥感小目标更是如此。谢俊章等人分析了遥感目标尺寸较小且分布密集的特点,简化了YOLO V4的特征提取网络。同时为防止网络退化和梯度消失,采用残差网络取代连续的卷积操作,将深层特征信息加深提取,提升了密集小目标检测的准确率和召回率。
Jocher提出YOLO V5 模型,该模型分为YOLO V5s、YOLO V5m、YOLO V5l、YOLO V5x 四种。与YOLO V4 模型不同的是,YOLO V5 提出两种结构的CSPNet,并分别用于特征提取阶段与特征增强阶段。其次,YOLO V5 在骨干网络中引入Focus 模块,该模块可以实现特征图的切片操作,降低特征图尺寸,提升通道数。各模型在COCO 数据集测试性能如图2所示。其中,YOLO V5s网络结构最简单,AP精度最低,但可用于检测大目标,保证最快的检测速度。

图2 YOLO V5 算法性能测试对比图Fig.2 Comparison chart of YOLO V5 algorithms performance
在YOLO 网络结构的基础上设计轻型网络结构可以加快网络训练速度。Pan 等人使用DenseNet作为YOLO-Tiny 模型中的BackBone,将自身的特征层用作所有后续层的输入,提高了网络的特征利用率,减少了冗余参数。李航等人借鉴DenseNet 设计了slim-densenet,使得特征可以跳过部分网络层直接传递至后端网络,并将网络中7×7、5×5、3×3 的卷积层改为深度可分离卷积,进一步加快了特征在模型中的传递。轻量级的网络架构主干网络较浅,难以提取出更深层次的语义信息。对于特定领域的数据集,轻量级网络检测精度高,速度快,训练效果好。但由于官方数据集中含有的数据类型较多,模型泛化能力较差,导致检测精度降低。优化YOLO 系列模型中的骨干网络如表1 所示。
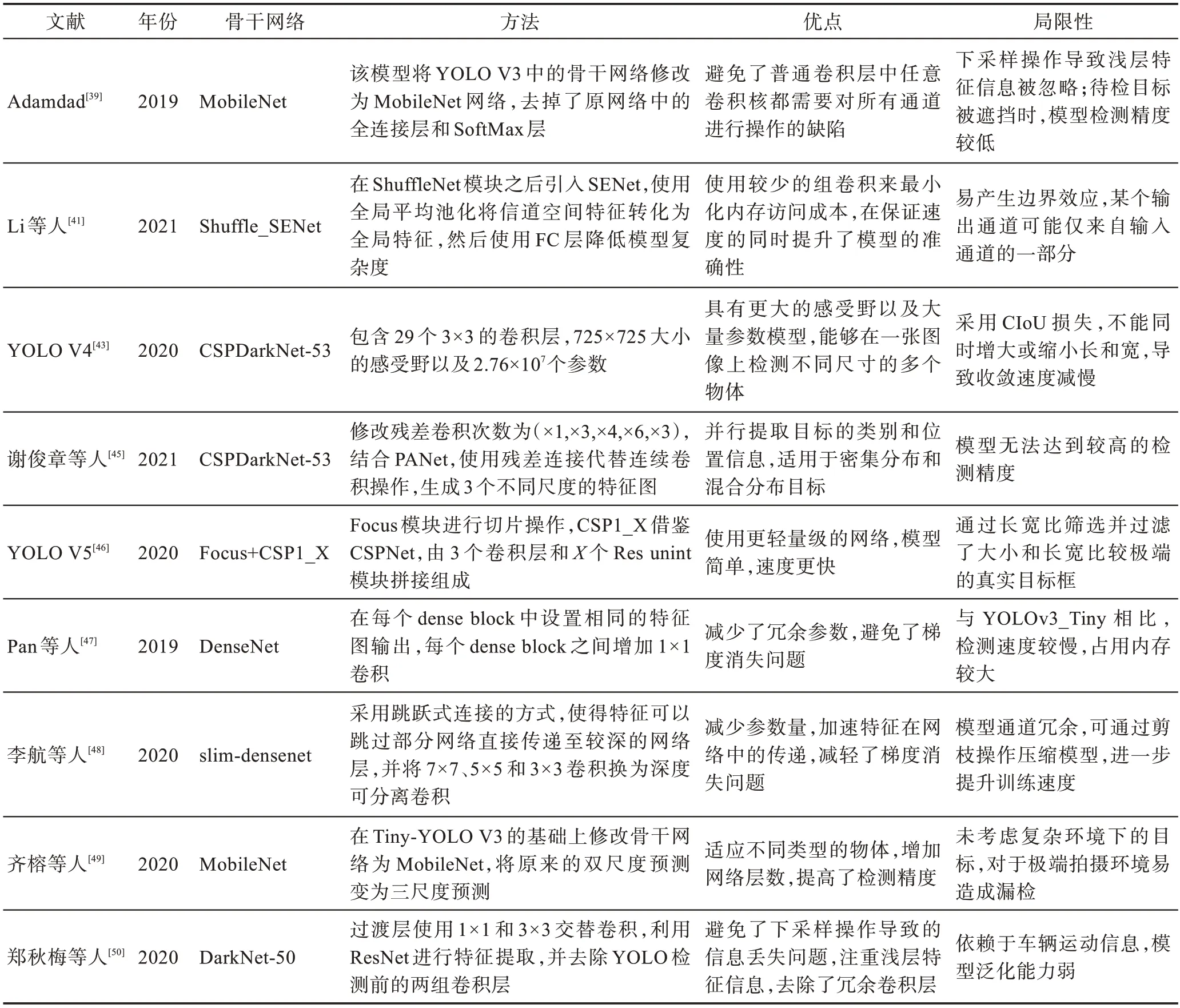
表1 优化YOLO 系列模型中的骨干网络Table 1 Optimizing backbone network in YOLO series models
SSD 算法中采用VGG16 作为骨干网络,但未进行批量归一化操作,使得梯度更新不稳定。并且深层特征图位置信息弱,对深层次的特征信息学习能力不足,对小目标检测不友好。为提取更多的特征信息,需要增加更多的网络层数,但直接增加会存在模型损耗问题。ResNet 网络构造残差块解决了由于卷积层加深而导致的模型退化问题。利用这一优点,Fu 等人提出DSSD(deconvolutional single shot detector)检测器。该模型将SSD 中的骨干网络修改为ResNet101,同时增加Deconvoluational 模块和Prediction 模块,提升了模型对小目标物体的识别和分类能力。张侣等人在骨干网络中引入注意力机制和ResNet 的思想,并在残差模块外层增加skip connection 构成嵌套残差结构,大幅提升了网络的特征提取能力。赵鹏飞等人采用分组残差的方式重新构建DarkNet-53,结合不同特征通道的特征信息,大幅提升了模型对通道特征信息的利用。
虽然ResNet 解决了梯度消失等问题,但该网络具有较明显的冗余性,对每层的目标信息提取能力不足。引入DenseNet 可以实现特征的重复利用,降低冗余。Shen 等人提出DSOD(deeply supervised object detectors)算法,该模型无需预训练,可直接从零开始训练检测模型。其骨干网络基于DenseNet,能够为检测器提供深度监督,避免梯度消失的问题。在此基础上,奚琦等人通过实验对比分析,将DenseNet 作为骨干网络,并对其进行改进,最大程度地保留了目标物体的细节信息,提升了对小目标物体的检测。优化SSD 骨干网络如表2 所示。
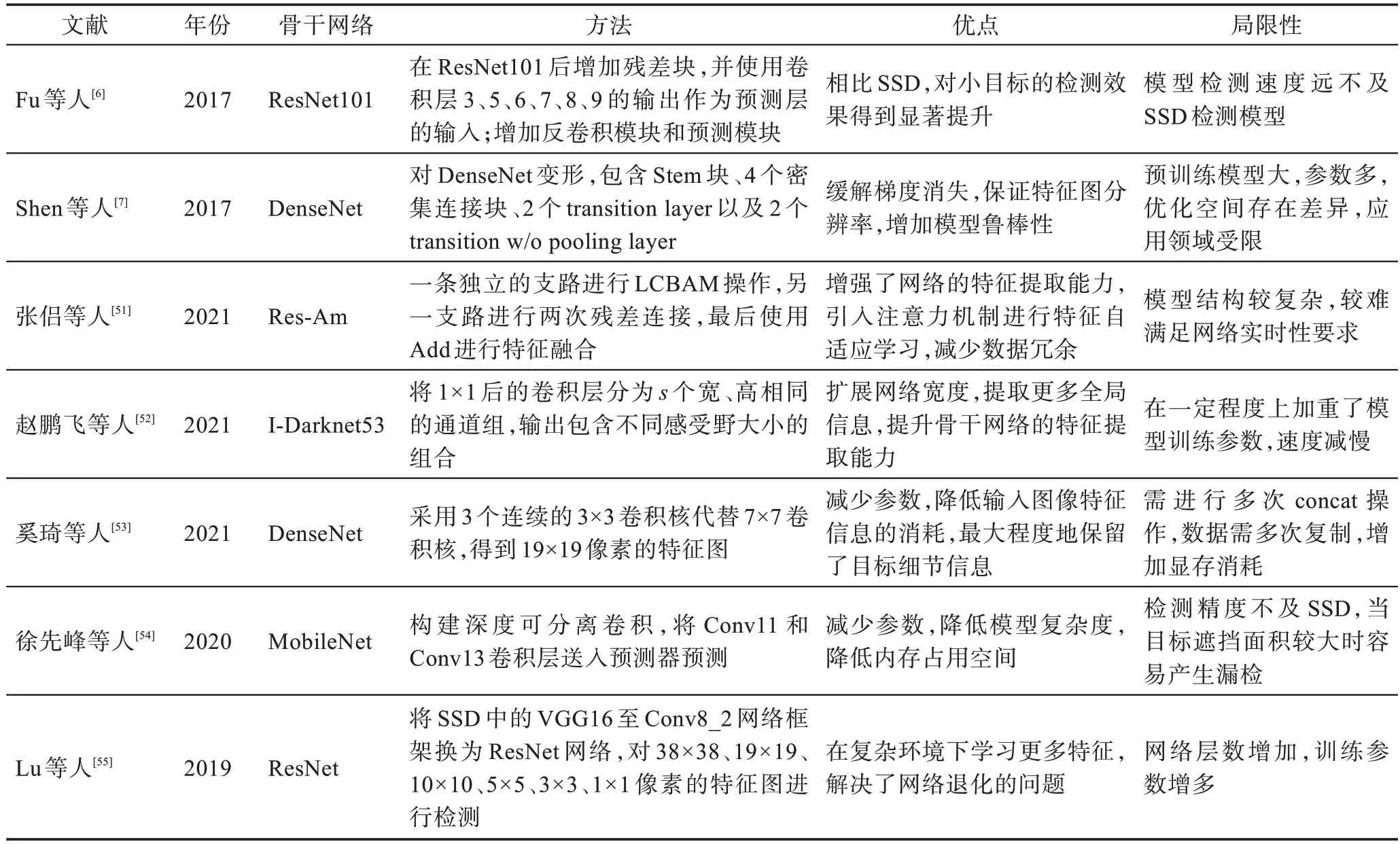
表2 优化SSD 骨干网络Table 2 Optimizing SSD backbone network
为满足RetinaNet 网络在小目标检测领域的实时性要求,Cheng 等人提出Tiny-RetinaNet。该网络结合特征金字塔网络(feature pyramid network,FPN)提出MobileNetV2-FPN 作为骨干网络,采用轻量化的深度可分离卷积模块减少参数,然后结合Stem Block和SENet 减少原始图像的信息丢失。在PASCAL VOC2007 和PASCAL VOC2012 数据集上的mAP 分别为73.8%和71.4%。
根据骨干网络各自拥有的性能,可以将其优点很好地应用在单阶段目标检测中作为特征提取网络,减少模型训练参数,加强特征的前向传播。不同的优化骨干网络算法在公共数据集上的测试结果如表3 所示。虽然改进骨干网络后的检测精度已得到大幅提升,但目前骨干网络仍存在模型较复杂、泛化能力较弱的问题。如何在加强小目标特征提取能力的同时减少内存消耗,仍是小目标检测的重点关注问题。并且当小目标处于复杂的背景环境时,传统的骨干网络易受背景信息的干扰,对小目标的特征提取能力不足,不能很好地适应小目标。
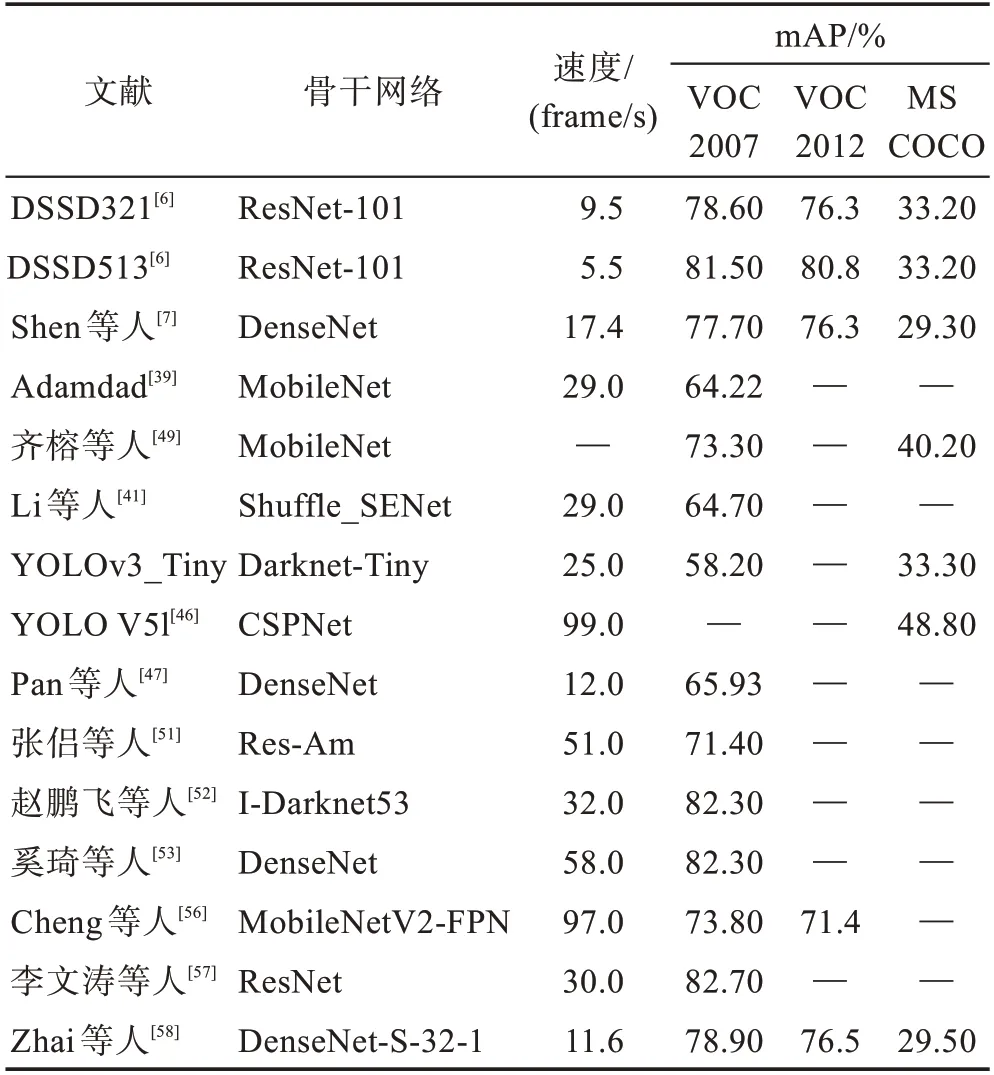
表3 不同算法在公共数据集上的测试结果Table 3 Results of different algorithms in public datasets
针对小目标检测来说,当卷积神经网络想要学习更多的特征信息时,就需要加深网络结构,模型会变复杂。同时,小目标本身特征表达能力较弱,因此对小目标特征信息的增强是必不可少的。引入通道注意力机制和空间注意力机制往往可以使神经网络关注与任务相关的通道和区域,然后为其分配合适的权重。通道注意力机制中的SE(squeeze-andexcitation)如图3 所示。

图3 SE 模块Fig.3 SE block
图3 中对于任意给定的变换:→,特征通过Squeeze 操作,获得通道响应的全局分布,形成通道描述符;然后通过Excitation 操作,学习对各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,特征图被重新加权;最后将输出结果直接馈送至后续层。
徐诚极等人为使边界框定位更加准确提出Attention-YOLO。该算法结合两种注意力方式,将只引入通道注意力机制和同时引入两种注意力机制进行对比,最后在残差连接时加入二阶项来减少特征融合过程中的信息损失,得到泛化性能更好的网络。在目标检测网络中,浅层特征图缺乏小目标的上下文语义信息。为了提升MobileNet_YOLO V3 的检测能力,张陶宁等人提出多尺度特征融合注意力网络(multi-scale feature-fusion attention network,MSFAN)。该网络设计了一个特征融合注意力机制,特征融合模块获取特征的全局空间信息,注意力机制产生通道间的非线性关系。两者结合提升了网络前向传播时的特征表达能力,充分提取了小目标的细节信息。Li 等人针对小目标和遮挡目标提出YOLO-CAN,该模型在残差结构中引入注意力机制,然后通过上采样融合不同尺度的特征图,提高小目标物体的特征表达能力。
结合注意力机制可以使模型聚焦于局部信息。李文涛等人针对SSD 算法的不足设计了一种邻域局部通道注意力模块。该模块首先对各通道分别进行不降维全局平均池化;通过1×1 卷积来获得各通道及其个邻域通道间的局部交换信息;对每个通道进行权值重分配。然后在特征融合模块提出包含通道注意力机制的Bottleneck 模块。该模块将融合之后的特征缩减,得到7 组不同尺度的特征图,实现了不同通道间的信息交互。麻森权等人针对SSD 算法目标信息提取不充分的问题,提出在SSD 模型中引入注意力机制,并通过特征融合抑制无关信息,提高检测精度。赵鹏飞等人采用高效通道注意力模块(efficient channel attention module,ECAM),加深对不同通道重要性的学习,加强浅层特征的感知能力。
RetinaNet 算法不能充分提取不同阶段的特征信息,使用密集检测造成了大量的无用边界框,占用了不必要的存储空间。同时,该算法忽略了边界框回归的重要性,导致边界框回归不准确。于敏等人引入多光谱通道注意力(multi-spectral channel attention,MCA)模块优化RetinaNet 的骨干网络。在ResNet中插入MCA,提取不同信息的频率分量并将其合并,以此来强化不同阶段特征信息的提取。不同注意力机制融合策略在公共数据集测试结果如表4 所示。
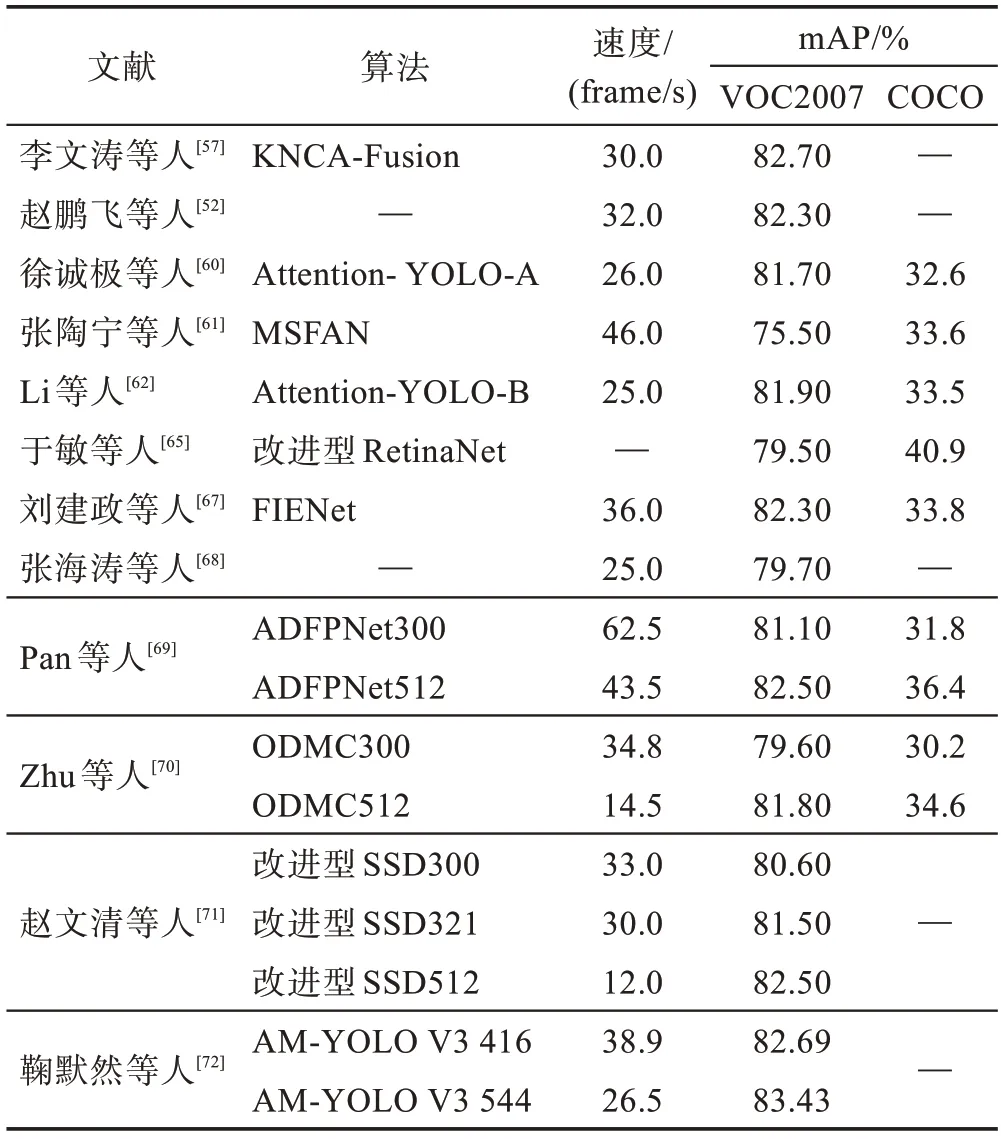
表4 引用注意力机制在公共数据集上的测试结果Table 4 Test results of using attention in public datasets
复杂环境下的小目标物体易受背景信息的影响,特征提取网络能够提取的语义信息十分有限。在目标检测特征提取过程中,浅层特征图含分辨率较高的特征位置信息,可用来提升边界框回归精度,但其语义信息较少,易受噪音点的干扰;深层特征图含较强的语义信息,但其分辨率较低,细节表达能力较差。引入特征融合与特征增强模块可以有效地将两者结合,取长补短,提升对小目标的检测能力。
为实现小目标细粒度检测,郑秋梅等人将YOLO V3 中的3 个尺度检测扩展为4 个尺度检测,分别对13×13、26×26、52×52 像素的特征图进行2 倍上采样操作,并将其与浅层特征图进行级联,分别检测融合后4 个分支上的特征信息。而对于图像背景信息较复杂的小目标,多尺度检测利用高分辨率特征会引入过多的背景噪声,造成模型收敛速度缓慢甚至难以收敛的结果。宋忠浩等人针对YOLO V3中未区分不同特征之间重要性的差异,提出具有加权策略的自适应特征融合,使得不同尺度的特征图在融合阶段具有不同的权重。改进后的模型在DIOR遥感数据集上的mAP 达到60.3%。为加强通道间的特征交互,鞠默然等人在特征融合模块之后加入SENet,利用自动学习特征通道间的重要性输出各尺度的预测结果。
在SSD 检测器中,由浅层生成的小目标特征缺乏语义信息,并且小目标严重依赖于上下文。针对此问题Li 等人结合FPN 的思想将轻量级的特征融合引入SSD,合并不同层的特征图生成特征金字塔,充分利用了小目标特征信息。Shi等人提出FFESSD(single shot object detection with feature enhancement and fusion)。该方法采用SFE(shallow feature enhancement)模块增强浅层语义信息,采用DFE(deep feature enhancement)模块使深度特征映射具有关于输入图像的更多信息。赵鹏飞等人为丰富浅层特征信息,提出特征增强模块(feature enhancement moudle,FEM),并将经过FEM 模块后的特征图与通道降维后的特征图进行拼接。但通道拼接操作忽略了各通道之间的相互关系,因此在融合操作后又加入ECAM(efficient channel attention module)模块充分挖掘小目标的上下文特征信息。不同特征融合策略在公共数据集测试结果如表5 所示。

表5 不同特征融合策略在公共数据集上的测试结果Table 5 Test results of different feature fusion strategies in public datasets
特征融合与特征增强能够结合浅层与深层的特征信息,充分利用多尺度输出。但特征融合的串联操作不能反映通道间的相关性,特征之间信息交互不完全。而注意力机制可以通过不同的权重分配学习通道间的特征信息。采取特征融合与注意力机制结合的方法能够加强特征的提取能力。但如何合理地使用注意力机制以及合理地进行特征融合仍是未来的研究方向。
在传统的深度学习目标检测算法中会结合一些网络结构,融合这些网络结构的优点可以使网络模型具有更好的泛化能力。传统的目标检测网络经过不断的卷积之后,得到分辨率很低的特征图,损失了空间结构。赵文清等人针对关联度较高的数据集,改进HRNet网络并引入长短期记忆网络(long short term memory,LSTM),构建了一种高分辨率的网络结构。该模型采用先降低分辨率再提升分辨率的特征串联交互方式提高模型性能。
鲁博等人对YOLOv3-Tiny 做出改进,在原网络模型的基础上引入Bi-FPN 特征金字塔结构,并重新定义了一种上采样模式,丰富了目标的语义信息,提高了对小目标检测的精确度。潘昕晖等人在YOLO V3 的基础上结合了CSPNet。该网络将某一特征层分为两部分,一部分经少量处理与特征提取后的另一部分融合,形成局部过渡层;然后通过分块合并,使梯度路径的数量变为原来的两倍,实现了更丰富的梯度组合,加强了模型自主学习能力,降低了内存消耗;之后引入Bi-FPN 网络对特征进行增强,通过自顶向下以及自底向上的方式对特征层进行新一轮融合,实现了对小目标检测效果的明显提升。
在单阶段目标检测算法中引入其他功能的网络结构,不仅能增强小目标的检测能力,还可以根据不同网络结构的功能适应不同环境下的小目标,如对密集型数据的处理以及对关联性较强数据的处理。但是该类方法需要针对特定的数据融合恰当的网络结构,对普遍的小目标数据不适用,迁移学习能力较弱。
2.3 优化交并比函数
IoU 是进行目标检测算法性能评价的一个非常重要的函数,交并比的值代表预测框和真实框交集和并集的比值。周慧等人利用聚类生成的Anchor Box 计算自适应IoU 阈值(adative threshold section,ATS)。ATS首先选取候选样本中心点与Ground Truth中心点距离最小的为候选正样本;其次计算每个候选正样本与Ground Truth的IoU值,并计算每一层特征图IoU 的均值和方差;最后规定若其IoU 值大于该层IoU均值和方差之和,则认为是正样本,否则为负样本。
但若预测框和真实框之间不相交,如图4 所示,IoU 的值为0,无法得到优化方向。

图4 两目标框IoU 为0Fig.4 IoU of two boxes is 0
为解决这一问题,Rezatofighi 等人提出GIoU(generalized intersection over union)来优化两个目标框的面积。对于任意的两个预测框和真实框、,首先找到、的最小闭包区域,并计算其面积A;然后计算闭包区域中不包含、的区域占闭包区域的比值;最后使用IoU 减去该比值得到GIoU,如式(1)所示。
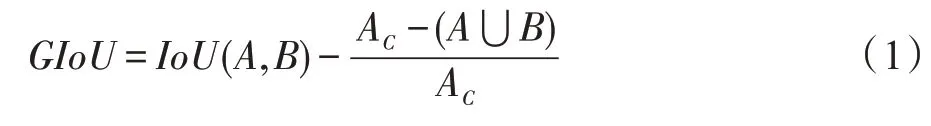
Yang 等人使用GIoU 代替YOLO V3 模型 中的IoU,进一步提高了目标检测的定位精度。邹承明等人对GIoU 进行讨论,优化网络中真实框与预测框的重叠度。但若、重叠,此时的GIoU 便退化为IoU。因此,Zheng等人提出DIoU。DIoU可以最小化两个目标框之间的距离,DIoU的表达式如式(2)所示。

式(2)中,表示预测框与真实框中心点的距离,表示两者闭包矩形的对角线长度。
Liang 等人采用DIoU 作为YOLO V3 模型中的边框回归机制,考虑了Ground Truth 与Anchor Box 之间的距离和重叠率,使得边界框回归更加稳定,避免了IoU、GIoU 等训练过程中出现的发散问题。潘昕晖等人引用DIoU 并对其做出改进,对分子上的欧氏距离开平方降低其权重值,然后在DIoU 中加入惩罚项,来控制预测框的宽高尽快地向真实框的宽高靠近。改进后的DIoU 表达式如式(4)所示。
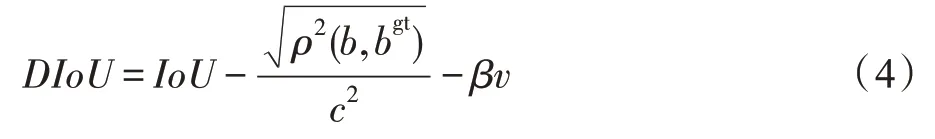
式(4)中,用来衡量长宽比的一致性,为人工设置的惩罚项。
但若两个目标框的中心点重合,长宽比不同时,DIoU 便不再发生变化,因此在DIoU 的基础上Zheng等人又提出CIoU。CIoU 总结了两个目标框之间的重叠面积、中心点距离和长宽比,相比DIoU 来说CIoU 的收敛效果更好,其表达式如式(5)所示。
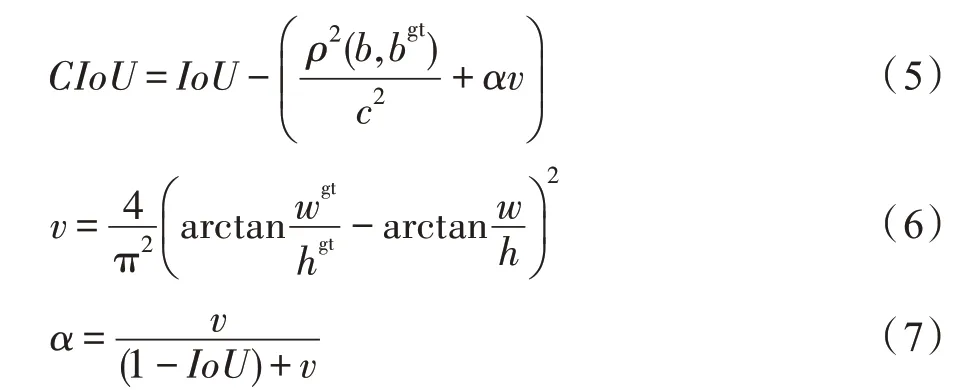
式(6)中,和表示真实框的宽和高,和表示预测框的宽和高。
Li 等人总结了YOLO V3 中GIoU 的优缺点,采用CIoU 计算预测框与真实框的宽高比。将CIoU 损失作为Bounding Box 的回归损失,有效地提高了模型训练过程中Bounding Box 的收敛速度,使模型检测的准确性达到了预期的效果。
随着对交并比函数的不断优化,目前的交并比函数已经考虑到预测框与真实框之间的面积比、中心点距离比以及长宽比,并且可以全面且综合性地评价两个目标框之间的重合程度,能很好地适应各种情况的目标数据,使得预测框可以尽可能地向真实框靠近。但对于IoU 阈值的选取大多还是自定义阈值,未能充分地考虑正负样本之间的平衡性。此外,CIoU 作为目前最优的交并比函数并不是每次都能达到最好的训练结果,对交并比函数的选取还应视实际情况而定。
2.4 优化损失函数
传统的YOLO 损失函数包含定位损失、置信度损失以及分类损失。YOLO 采用误差平方和的方式计算损失函数,其表达式如式(8)所示。
对于不同的检测方法选取不同的损失函数会得到不同的收敛效果。通过改进YOLO、SSD 算法的损失函数,可以使小目标物体的定位和检测更加准确。单美静等人对Tiny YOLO 进行改进,提出L-YOLO模型。该模型使用高斯损失函数作为边界框的定位损失,同时考虑到定位的不确定性、边界框置信度以及类别概率,降低了对目标的误检和漏检。L-YOLO的高斯边界框定位损失如式(9)所示。
为了加快损失函数的收敛速度,解决正负样本不均衡的问题,越来越多的人参照RetinaNet 中的损失函数将Focal Loss 函数作为边框损失,既解决了正负样本不均衡的问题,也解决了较易分类样本与较难分类样本不均衡的问题。Focal Loss函数表达式如(10)所示。

其中,用来平衡正负样本的权重;为经过激活函数的预测输出,其值在(0,1)之间;(1-)聚焦较难训练的负样本,且≥0。
张炳力等人针对夜间小目标检测效果差的问题,分别优化了RetinaNet 网络的分类损失和定位损失。在分类损失中分别对正负样本设置系数并增加与IoU 关联系数,在中心点的定位损失中引入综合预设框、目标框以及预测框信息的系数,消除了模型对不同大小目标框的敏感度。
张思宇等人针对行人检测将SSD 损失函数改为二分分类损失函数,为使损失函数更快地收敛,将与按1∶1 的比例进行计算,并将正则化项加入损失函数。郑秋梅等人针对小目标输出损失函数较小的问题对待检测物体宽高进行加权,降低大目标误差对小目标检测的影响,改进后的损失函数使用平方和损失且考虑真实边框的尺寸,加速了模型收敛。
在目标检测任务中损失函数的主要功能是保证定位更加准确,识别精度更高。然而不同的模型所需的损失函数不同,对于预测框分类和回归的结果也不同。在选取损失函数时,应通过实验综合评价损失函数对模型的影响,取长避短,提升对小目标的定位和识别精度。
2.5 其他方法
针对YOLO 系列算法实现多尺度检测进行改进,结合特征金字塔的思想,可以提取不同尺度的特征分支,既利用了更多的高分辨率特征信息,又未对模型收敛速度造成影响,在实时性和检测精度之间实现了较好的平衡。同时,增加检测尺度、使用图像分割以及根据不同尺度分配不同Anchor Box等方法可以增强小目标的识别能力,满足不同尺度特征图对不同Anchor Box 的敏感程度。
但大多数的多尺度检测采用FPN 来解决目标实例尺度变化对模型检测的影响。FPN 旨在根据内部多尺度对目标进行检测分类,特征金字塔中的特征图不能完全包含目标检测任务,且每层特征图仅包含本层特征信息,在实际检测时与小目标实例的外表差异较大。针对该问题,Zhao 等提出M2Det,采用多层次特征金字塔(multi-level feature pyramid network,MLFPN)实现不同尺度目标检测。MLFPN 主要包含三部分,即特征融合模块(feature fusion module,FFM)、U 型模块(thinned U-shape module,TUM)和尺度特征聚合模块(scale-wise feature aggregation module,SFAM)。其中,FFMv1 融合骨干网络的基本特征信息;TUM 产生多尺度特征,并利用TUMs 和FFMv2 提取多层次多尺度特征;SFAM 通过多尺度特征拼接以及自适应注意力机制聚合特征信息。M2Det在MS COCO 数据集上的训练速度达84.7 frame/s,mAP 达41.0%。
特征输出受感受野区域内像素点的影响。感受野过大,易导致模型过拟合;感受野过小,难以学习深层次的复杂特征信息。为使浅层特征图的感受野适应小目标检测,王鹏等人在不同尺度的特征层后加入空洞金字塔模块和特征空洞金字塔模块构成新型网络结构PDSSD(pyramid dilated SSD),扩大卷积核感受野,增强对小目标的特征提取能力。在PACCAL VOC 数据集上,输入尺寸为512×512 像素的mAP 可达82.1%。张新良等人为保证模型能够保留更多的特征信息,在SSD 模型中融合多维空洞卷积算子(multiple dilated convolution,MDC)和多层次特征的深度网络来提升小目标物体的检测能力。在VOC2007测试集上,MDC模型mAP达到80.4%。陈灏然等人在SSD 特征提取网络中加入RFB(receptive field block)结构,通过多分支卷积和空洞卷积获得不同尺度的感受野,加强对小目标的检测。该模型在VOC公开数据集上mAP 为81.8%。
在目标检测中通常需要以某个设定的IOU 阈值来筛选正样本和负样本,IoU 阈值的不合理设置会对小目标的检测结果造成影响。宋云博等人设计了平行级联网络,使用前一级的输出作为下一级的输入,IoU 阈值逐级提升,保证不同级别的分类器和回归器在越来越高的样本质量上进行训练。该模型在COCO 数据集上的AP 达到44.2%。
目前大部分的目标检测都基于Anchor,但基于Anchor 会引入过多的超参数,且锚框的尺寸固定,不利于处理形变较大的目标。Law等人设计了Corner-Net,该算法未涉及Anchor 的概念,整个模型不基于预训练。该模型提出检测Bounding Box 的一对角点来检测目标,并使用Corner Pooling 来定位角点。CornerNet 在COCO 数据集上的AP 达到42.1%。但CornerNet 检测角点来定位目标需要同时输出热图、偏移和嵌入,若检测结果丢失任何一个角都会导致该目标漏检,并且该算法需要精确的偏移和正确的嵌入来生成准确的紧密边界框。虽然使用Ground Truth 偏移量代替预测偏移量可以提升一定的检测精度,但角点检测和分组仍有很大的改进空间。
为进一步改进CornerNet,Duan 等人提出了CenterNet。该算法将目标检测问题转变为中心点预测问题,通过预测目标中心点偏移量和宽高来获取目标矩形框。在COCO数据集上的AP提高到47.0%,但训练速度不及CornerNet。
Tian等人设计了FCOS(fully convolutional onestage object detection)。该算法直接将特征图上的每个位置都作为训练样本,若某一位置落入任何真实边框则认为该位置为正样本。但若标注真实框重叠,该位置映射到原图中会落在多个真实边界框中,产生模糊样本问题。该算法采用FPN 进行多级预测解决模糊样本问题,并引入center-ness 抑制由于距离中心位置较远而产生的低质量预测边界框。FCOS算法的提出显著减少了模型参数数量,通过消除锚框避免了复杂的IoU 计算以及边框回归,降低了对内存的空间占用率。
3 常用小目标数据集
最近研究表明,利用数据量更大的数据集能有效地提升目标检测的性能。为了更好地研究小目标数据,逐渐出现了很多针对小目标检测的数据集。这些数据集大都包括人脸检测数据、行人检测数据、遥感图像数据、红外检测数据、航空拍摄数据、医学影像数据等。在交通应用场景中的数据集包括EuroCity Persons数据集和交通灯数据集等;航空领域中的数据集包括DOTA、AI-TOD、iSAID和BIRDSAI数据集等;在行人检测领域的数据集包括TinyPerson、WiderPerson和NightOwls数据集等。相关小目标检测数据集如表6 所示。

表6 相关小目标检测数据集Table 6 Small object detection datasets
各种小目标数据集检测结果如图5 所示。其中,(a)(b)(c)(d)表示行人 检测数据集,(e)(f)(g)(h)表示航空图像数据集。这些待检小目标在图像中占比较小,分辨率较低,存在较复杂的背景环境,并且一些小目标密度较大,存在遮挡,适用于提升小目标检测的研究。

图5 小目标数据集检测结果Fig.5 Detection results of small object detection datasets
4 总结与展望
本文系统地阐述了近年来对基于深度学习的单阶段小目标检测算法的研究。首先总结了小目标物体研究的难点;其次从优化Anchor Box、优化骨干网络、在模型中引入注意力机制和其他网络、对不同尺度的特征图进行特征融合、优化IoU 和损失函数等几个方面详细地总结了优化小目标检测的方法;最后介绍了常用的小目标数据集,使得小目标检测能根据不同的领域具体分析其目标特征。虽然目前小目标检测在精度上得到了很好的提升,单阶段目标检测技术也保证了模型的运行速度,但总的来说对各领域小目标的检测仍未达到理想的效果。结合上述分析,提出以下几点。
(1)构建高分辨率轻量级网络。目前大多数网络模型通过卷积和下采样操作提取出的特征图分辨率较低,不利于小目标的特征分析。在今后的研究中可以考虑高分辨率轻量级网络,得到语义丰富且定位精确的特征图。
(2)构建大规模数据集。到目前为止已经出现越来越多的小目标数据集,但这些小目标数据集大都针对各自的领域,样本仍存在分布不均、数量不足的问题。构建小目标检测数据集时可以运用数据增强的方法扩充数据量,调整样本分布,降低数据的不平衡性。
(3)结合上下文信息。在小目标检测的过程中可以充分利用小目标的区域特征,结合上下文信息增强对小目标的检测。但引入一些网络增强区域特征时会增加复杂度,因此平衡网络的复杂度和精度是未来较为重要的研究方向。
(4)优化特征融合方式。通过一些简单的特征融合可以增强小目标的特征表达能力,但没有规律地一味融合反而会降低小目标检测的准确度。因此,研究合适的特征融合方式并采取恰当的上采样操作对提升小目标检测十分重要。
(5)提升模型可迁移性。目前的小目标检测技术通常是为研究某一特定领域而制定的,检测技术可迁移性较差,无法适应复杂变换的场景。因此,研究可迁移性较好的网络模型可以有效地提升小目标检测技术。
综上所述,基于深度学习的单阶段小目标检测技术已成为小目标检测的主流。通过对单阶段目标检测的不断改进与优化,大幅提升了小目标的检测精度。但目前网络模型仍存在模型较复杂、检测精度较低的问题,因此提升小目标检测技术仍需要较长时间的发展。
