个性化学习推荐研究综述
2022-01-18吴正洋
吴正洋,汤 庸,刘 海
华南师范大学 计算机学院,广州510631
随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力。学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统。在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等。这些学习资源由于内在关系可能组合形成一个复杂的结构,如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师。图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源。同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间。而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系。

图1 在线学习系统中学习资源的复杂关系Fig.1 Complex relationship of learning resources in online learning system
学习者通过与学习资源的交互达到认知提升的目的,但由于学习资源种类数量繁多且结构复杂,因此有必要在学习系统中嵌入个性化功能,以适应性地跟踪学习者的进展,并提供适合他们需要的学习资源。鉴于此,学习推荐系统(learning recommender system,LRS)应运而生。学习是一项具有综合性特征的活动,需要学习者长期持续的认知加工、情感投入乃至意志支撑。因此,与推荐系统在其他领域的应用不同,学习推荐不是为了预测或迎合学习者的潜在行为,而应该通过推荐的内容,辅助学习者在合适的学习进程中以合理的方式发现与其个性化参数相匹配的学习资源,从而保持学习者的积极性,并支持他们有效地完成学习活动。
根据以上目标,本文从学习推荐系统的研究中归纳了三个核心问题:第一个是学习者建模问题,即如何对学习者的学习风格、认知水平、情感状态等信息进行全面捕获,并有效地建立学习者模型。第二个是学习推荐对象建模问题,即如何发掘学习推荐对象与学习者个性化参数相关联的信息,并有效地建立学习推荐对象模型。第三个是学习推荐算法设计问题,即采用何种计算模式将学习者模型和学习推荐资源模型有效结合,从而提升比较、过滤、匹配等操作的效率和精度。此外,建构主义学习理论认为,学习活动是学习者认知构建的过程,且具有持续性和连贯性,因此,对推荐效果的评价和跟踪也是学习推荐系统应解决的重要问题。
1 个性化学习推荐系统框架
一个通用的学习推荐系统框架如图2 所示,该框架由三个子模块构成,即学习者建模、推荐对象建模以及推荐算法。学习者建模主要包括学习者状态表示算法以及学习者模型;学习推荐对象建模主要包括推荐对象状态表示算法以及学习推荐对象模型;推荐算法模块通过处理学习者模型和学习推荐对象模型,向目标学习者输出推荐结果。
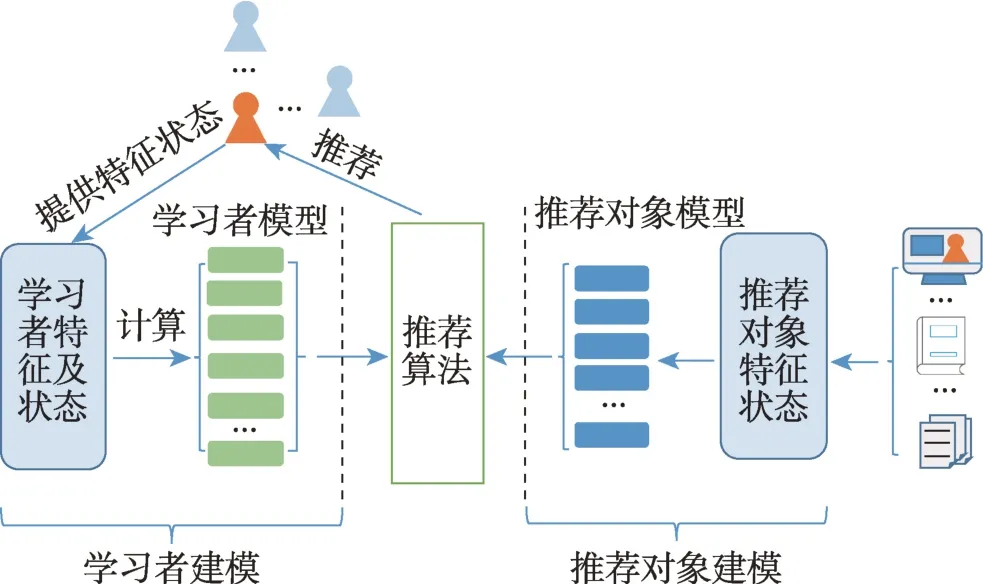
图2 学习推荐系统的框架示意图Fig.2 Schematic diagram of framework of learning recommendation system
对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题。所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式。在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等。学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义。学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型。推荐算法模块通过处理学习者和推荐对象模型,实现推荐。但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径。这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性,其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用。可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响。参考推荐系统对个性化学习推荐系统进行形式化定义:设P是学习者的个性化参数集合,函数表示学习者建模过程,(P)是学习者模型集合;P是所有可以推荐给学习者的对象的特征集合,函数表示推荐对象建模过程,(P) 是推荐对象模型集合。设函数可以用于计算推荐对象对学习者的推荐度,即((P),(P))→,是一定范围内的全序的非负实数,推荐的目标就是找到推荐度最大的那些对象,如式(1)所示:

由以上形式化定义可以看出,学习者建模、推荐对象建模以及推荐算法,是个性化学习推荐的3个关键技术,本文接下来将围绕这些内容展开介绍。
2 学习者建模
学习者建模是构建精准、优质、个性化学习推荐系统的先决条件。学习者模型应反映多方面的、动态变化的学习者个性化参数。文献[14]总结了19 项学习者个性化参数,并将其归纳为3 个类别:“为何学”“学什么”以及“如何学”。其中,“为何学”类别下的参数,是将学习目标和动机视为学习者的个性化差异;“学什么”类别下的参数体现了学习本质内容,即根据学习预期达到的知识点和技能目标等作为学习者的个性化差异;“如何学”类别下包含了更丰富的个性化参数,如学习偏好、学习风格以及面向学习内容所采用教学方法的相关知识背景等,这些参数可用于体现学习者的个体化学习方案差异。对于学习推荐系统而言,可根据应用场景考虑其中一项或多项参数的组合。如在线课程学习中,学习者的目标一般是在限定的时间(三个月或一个学期)内完成学习任务且取得好成绩。为此,学习者只需关注与自己的知识背景、能力水平等参数相匹配,且可以在限定的时间内完成的学习资源;接下来,学习者会在这些学习资源中挑选符合自己学习风格偏好的那些开展学习。因此,文献[7]从学习路径推荐视角,将学习者的个性化参数设置为学习目标、技能学习、知识背景、时间限制以及学习风格五个,每个参数从属的类别如图3 所示。

图3 学习路径推荐视角下的学习者个性化参数分类Fig.3 Classification of learners'personalized parameters from perspective of learning path recommendation
学习者建模应能获取、表示、存储和修改学习者的特征和状态,能通过推理,对学习者进行分类和识别,使系统更充分、更准确地捕获学习者的特征和状态。Chrysafiadi 等总结了九种学习者建模方法:覆盖建模(overlay)、原型建模(stereotypes)、摄动建模(perturbation)、机器学习技术建模(machine learning techniques)、基于认知理论建模(cognitive theories)、基于约束的建模(constraint-based)、模糊建模(fuzzybased)、基于贝叶斯网络建模(Bayesian networks)以及基于本体的建模(ontology-based)。可以看出,学习者建模除了要体现学习者的基本属性特征(如年龄、性别等)之外,还需体现学习者的认知状态(或知识掌握状态)、情感状态等,这类状态会随着学习活动的进行而变化。近年来,随着深度学习和特征工程相关研究的发展,学习者建模方法也在发展。本文接下来将结合近几年学习者建模方法的研究进展,并从学习者特征表示的视角将其归纳为显式的学习者建模方法、隐式的学习者建模方法以及语义式的学习者建模方法,如图4 所示。

图4 本文归纳学习者建模的三类方法Fig.4 Three types of learner modeling methods in this paper
2.1 显式学习者建模
显式的建模方法是通过提取系统或文档等明显的学习者特征或偏好描述数据,构成能够体现学习者独特性或相似性的表示方式。显式的学习者建模有利于将学习者模型与个性化参数直接对应。由于存在多种学习者个性化参数,在不同的应用需求下,显式学习者建模方法所描述的学习者特征可能也不同。文献[15]从学习者对被推荐对象的偏好出发,认为在学习路径选择上,学习者更关注研究的新颖性、权威性和普及性,并基于此提出了一个学习路径推荐方法,该方法以学习路径中所配置学习资源的新颖度、流行度和权威度3 个值的加权平均表示学习者模型。有的显式学习者建模方法直接采用了学习者对学习资源项目评分,如在文献[16]所提出的学习推荐模型中,将所有学习者对所有学习资源项目的评分形成一个矩阵,该矩阵的每一行即为一个学习者的向量表示。
有的方法通过采集学习者在不同系统中体现的个性化参数进行学习者建模,如文献[17]将学习者在多个系统中所表现出的不同学习目标进行组合后形成学习者模型。该方法对学习者的描述是基于其在多个系统中配置文件的前个标签,并重点描述该学习者在系统中的行为,即其最活跃的个性化特征。还有的研究通过直接调查获取个性化参数的方法进行学习者建模,比如文献[18]所提出的学习推荐模型就直接通过采集学习风格进行学习者建模,还为此开发了一套关于学习风格的在线调查表工具,使用学习风格分类法描述学习者的学习风格特征。文献[8]提出的学习推荐方法同样使用了在线问卷调查的方式收集更丰富的个性化参数,所形成的学习者模型除了学习风格之外,还包括学习者的学习进展。显式学习者建模高效直观,保留了推荐系统所需要的学习者特征,使学习者模型具有良好的可解释性,但在学习者特征缺少的情形下,显式的学习者建模方法往往失效。另一方面,当学习者与学习项目交互矩阵过于稀疏时,采用显式学习者建模方法也难以有效表现学习者与学习资源项目的交互行为特征。
2.2 隐式学习者建模
所谓隐式学习者建模,是指将显式的学习者特征数据或行为数据经过转换计算后得到一种可以描述学习者特征的向量。该向量的组成元素看似不是特征值的直观表示,但能表达学习者特征的语义信息。由于这种向量通常被称为“隐向量”,本文将这种建模方式称为“隐式学习者建模”。隐式学习者建模是当前学习推荐系统研究的热点,主要包括基于模型的方法、基于会话的方法和基于图的方法。
(1)矩阵分解
矩阵分解(matrix factorization,MF)已经广泛应用于推荐系统中,它基于的假设是:用户偏好受到少量潜在因素的影响,且项目的评分取决于其每个特征因素如何应用于用户偏好。MF 能够把“用户-项目”评分矩阵分解成两个或者多个低维矩阵的乘积实现维数的规约,用低维空间数据研究高维数据的性质,主要包括非负矩阵分解(non-negative matrix factorization,NMF)、广义矩阵分解(generalized matrix factorization,GMF)和概率矩阵分解(probabilistic matrix factorization,PMF)。其中NMF 方法是把用户对项目的评分矩阵R分解成两个实值非负矩阵U和V,使得≈,如图5 所示。
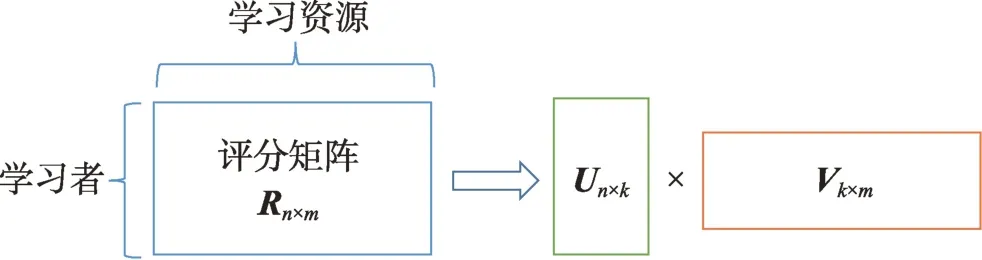
图5 矩阵分解示意图Fig.5 Schematic diagram of matrix factorization
采用矩阵分解进行学习者建模,通常先根据交互数据构建值为1/0 的矩阵,再将该矩阵分解为两个低维矩阵,其中一个矩阵的行数与学习者人数相同,每行即表示一个学习者的隐特征向量。凡有交互或评分行为的应用场景都可以考虑使用矩阵分解方法。比如在文献[24]中,采用了一个×的矩阵表示学习者在论坛上的表现,其中每行表示至少在课程的在线论坛上发布一次的学习者,每一列表示文中所定义的学习者在论坛中五种行为维度之中的某个类别标签(比如知识构建维度中的一个类别是“观察或意见声明”)。如果学习者发布至少一个帖子分配了的内容标签,则的每个条目C为1,否则为0。因此,是一个值为1/0 的矩阵,然后对采用贝叶斯非负矩阵分解(Bayesian non-negative matrix factorization,BNMF)方法生成学习者隐特征向量。文献[25]根据学习者课程学习记录,构建了“学习者-所选课程”矩阵,再采用PMF 方法并假设其条件概率符合高斯分布,将选课矩阵分解为学习者和课程的隐特征向量。文献[26]首先将学习者对学习资源的点击、阅读或使用看作一次“交互”,从而形成一个“学习者-学习资源”交互矩阵。采用GMF 方法将其分解为学习者和学习资源的隐特征向量,为了融入学习者与学习资源长时期交互的特征,该模型还结合长短期记忆网络(long short-term memory,LSTM)进一步生成学习者和学习资源的融合隐特征向量,并将两种特征向量进行组合后,共享同一个Sigmoid输出层。在使用过程中,将学习者与学习资源的交互记录作为输入数据,经过模型生成学习者对候选学习资源的交互概率,最后将交互概率最高的前几项学习资源推荐给学习者。
(2)自编码器


图6 自编码器结构Fig.6 Framework of auto-encoder
文献[31]提出的练习题推荐系统中,采用了两套结构相同的堆叠降噪自编码器(stacked denoising auto-encoder,SDAE)分别生成学习者隐表示和练习题的隐表示。SDAE 是降噪自编码器(denoising auto-encoder,DAE)的变体,DAE 的提出是为了防止过拟合,在自编码器输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性;而SDAE 就是将多个DAE 堆叠在一起形成一个深层网络结构,并且只在训练时才对输入进行加噪。与矩阵分解不同的是,自编码器能够将学习者多种特征所整合的高维向量进行降维,而矩阵分解则聚焦于表示学习者与学习资源的交互特征。
(3)基于上下文
学习者所受到的环境影响,难以通过主观调查获得。基于上下文的学习者建模方法能够适当将学习环境的信息融入学习者模型中。比如,有研究提出从社交网络中产生的信息作为特征提取的数据来源,用以更准确捕获学习者的潜在偏好。文献[33]以多媒体为媒介,将学习者看作社交网络中多媒体资源的提供者,基于他/她所学习的多媒体资源描述文本所表达的上下文信息,使用特征袋(bag of features,BOF)算法模型产生学习者的隐特征向量。另外还有研究认为,学习者作为群体中的成员也会受到所在班级环境的影响,文献[35]提出了一种基于班级上下文因素(class contextual factors,CCF)实现个性化学习推荐的方法。该方法所采用的班级上下文因素是学习者对课程知识点的掌握水平,并以此作为学习者的隐特征表示。
基于会话的推荐任务是指给定用户在会话中的上一次互动,预测用户对下一次出现项目感兴趣的可能性。对应的推荐方法采用了用户与项目在一段时间内的交互序列,因此,用于处理序列数据的模型,如循环神经网络(recurrent neural networks,RNN)、Transformer等被广泛使用。文献[38]根据学习者的答题记录,使用基于LSTM(RNN 的一种变体)的知识追踪模型(如图7 所示)预测学习者正确回答知识点的概率,由于练习题包含一个或多个知识点,可以基于此形成知识点掌握水平概率的向量表示,从而构建学习者模型。

图7 基于LSTM 的知识追踪模型Fig.7 Knowledge tracking model based on LSTM
近年来,注意力机制(attention mechanism)受到了推荐模型研究的关注,传统的注意力机制是面向源端和目标端的隐变量的计算,从而得到源端输入与目标端输出之间的依赖关系。自注意力机制(self-attention mechanism)是一种常用的注意力机制,它首先分别在源端和目标端进行,捕捉源端或目标端自身的隐变量之间的依赖关系;然后将源端和目标端的注意力结合,捕捉源端和目标端之间隐变量的依赖关系。因此,自注意力机制不仅可以得到源端与目标端隐变量之间的依赖关系,同时还可以有效获取源端或目标端隐变量之间的依赖关系。文献[39]使用自注意力机制,根据学习者在课程中的浏览点击记录,分别捕获查询、键和值的上下文信息,进一步生成注意力向量,表示会话中的线程。基于自注意力机制的表示生成模型如图8 所示。

图8 基于自注意力机制的表征生成Fig.8 Self-attention mechanism based representation generation
相比序列结构而言,图或网络结构更能表现学习环境下的真实情况。在基于图形结构的推荐系统中,数据以图形的形式表示,其中节点是用户、标签或资源,边是它们之间的事务或关系。文献[40]根据学习者、学习资源之间的关系为其添加排序标签,即以基于位置关系的排序对学习者进行表示。文献[41]提出将学习者和练习题作为实体,用边表示学习者回答练习,再根据学习者回答练习的正确率确定边的权重。文献[42]在实验部分提到了一种基于知识图谱表示的练习题推荐方法,该方法将学习者和练习题作为实体,并将学生回答练习的结果作为关系。基于知识图谱获得每个实体的低维向量,并进行关系学习,使图的结构和语义信息保持在向量中。
2.3 基于知识的学习者建模
所谓基于知识的学习者建模,是指基于领域知识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型。基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用。本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识。在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体。文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集。文献[46]提出了一个基于本体的MOOC 学习活动推荐方法。在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动。其中,学习者本体由4 个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征。采用本体技术可以将学习者建模扩展到多模态数据。文献[47]提出一种通过学习者的Facebook 帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化。文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模。该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识。
学习者建模方法应围绕学习者个性化参数,并尽可能保留学习者特征语义。本章将学习者建模方法归纳为显式、隐式和基于知识的方法。其中,显式学习者建模方法最直观,但在学习者特征数据缺少的情形下往往失效。因此,当前对学习者建模方法的研究比较倾向于隐式学习者建模,如基于模型的方法、基于会话的方法和基于图的方法等。基于模型的方法旨在通过模型从文本描述、上下文等非结构化的数据中提取学习者特征,常采用矩阵分解、自编码器等能够产生稠密向量的模型;基于会话的方法利用学习者与学习资源带有时序特征的交互数据,一般使用RNN 或其变体、注意力机制等模型处理数据,其本质是生成学习者在交互序列中下一个时间步状态的隐特征向量;基于图的方法则首先要将学习者、学习资源以及其之间的关系用图结构表示,然后采用随机游走或用于处理知识图谱表征的翻译嵌入(translating embeddings,TransE)模型生成关系图中学习者的隐特征向量表示。基于知识的学习者建模侧重于领域知识表示模型的构建,旨在通过构建完备的学习知识表示模型来预先设定学习者建模所涉及的特征,再通过实例化生成学习者模型。隐式学习者建模方法缺乏直观性,用于学习者隐特征表示的稠密向量只能间接反映学习者的相对状态,且向量维度往往需要通过模型训练调参才能确定。
3 学习推荐对象建模
学习推荐对象主要包括学习资源、好友以及学习路径。其中学习资源是学习活动中所使用的资源,包括习题、课程、教学视频、参考文献、考试卷等,相关推荐的研究较多。按来源不同可将学习资源分为两类:一类源自在线学习平台内部,在平台建设初期导入,并随着平台的运作不断更新和补充;另一类源自在线学习平台外部,学习者可以通过平台提供的链接访问。无论来源于内部或外部,在线学习平台都应对其进行统一标准化管理,标准化的内容包括资源的类型、所覆盖的知识点、难度、适用阶段、学习时间等。此外,为了提高检索效率,通常在学习资源管理系统中采用自动或半自动的语义化方法,从而为学习推荐对象的特征描述提供丰富的语义。学习推荐对象建模是学习推荐任务的重要部分,建模之前要考虑以下几个问题:
(1)从推荐对象提取的特征应与学习者的个性化参数相匹配。学习推荐对象可能具有多种属性特征,其中有些属性与学习者的个性化参数相关,比如推荐对象所包含的知识点与学习者对知识点的掌握情况相关;推荐对象的资源类型与学习者的学习偏好相关等。为了推荐的有效实现,在提取推荐对象属性特征时,应考虑与之匹配的学习者个性化参数。
(2)不同类型推荐对象的特征表示应该统一。在个性化学习推荐场景中,可能出现多种不同类型的推荐对象(如练习题、课程视频等),这些资源的属性特征不可能完全相同,但要反映同一学习者对这些不同类型资源的偏好时,就需要采用统一的特征表示方式,比如以评分作为对所有资源的表示。
(3)推荐对象的特征应符合算法模型的输入要求。用于推荐对象建模的特征,将成为推荐算法模型的输入,为了适应算法模型的有效运行,该特征应符合其输入要求。
学习推荐对象特征的获取是建模的首要任务。根据描述特征的获取方式,可将当前常用的学习推荐对象建模方法归纳为:静态方法、动态方法以及基于知识的方法三类。
3.1 学习推荐对象建模静态方法
学习推荐对象建模静态方法是指提取推荐对象显式特征中与学习推荐相关的那些来形成模型。比如直接采集学习推荐对象的文档描述,如文献[15]使用特征关键词集描述学习资源,其中包括:发表时间、引文次数、搜索频率、出版商影响以及作者影响力,然后使用加权关键词矢量方法,通过对推荐对象文档的统计分析得出对象的特征向量。直接提取文档描述虽然简单直观,但是往往难以体现推荐对象的内在差异性。有研究着眼于挖掘更深层次的特征,从推荐对象文本中提取特征,比如从简介、摘要、练习题的题干中提取。文献[53]提出了一个基于卷积神经网络(convolutional neural networks,CNN)的学习资源特征表示生成模型,提取学习资源中的文本信息(例如MOOC 平台中的课程介绍、学习资源的摘要等)的特征,生成低维度的隐向量表示,该模型的结构如图9 所示。
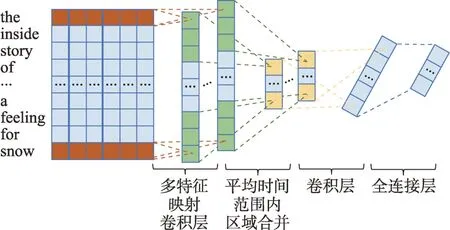
图9 基于CNN 的学习资源文本特征提取模型Fig.9 CNN-based learning resource text feature extraction model
文本特征提取的方法虽然比较多,但学习推荐系统的对象不一定都具有文本特征,或文本描述不充分,比如来自网络的学习视频、音频等多媒体学习资源,此时基于内容的学习推荐对象建模还需要结合多媒体内容分析领域的相关技术。静态方法利用学习推荐对象的明显特征对其建模,在特征描述丰富的前提下,能够直观且高效地达成建模任务,其所用特征的显著特点也有利于提高推荐的可解释性。
3.2 学习推荐对象建模动态方法
学习推荐对象建模可以采用“分类”和“交互”两种动态方法实现。“分类”即把推荐对象放入不同类别中,这样可以把同类学习资源推荐给相关的学习者。可以使用基于统计机器学习的分类方法如朴素贝叶斯(Naive-Bayes)、近邻(-nearest neighbor,NN)和支持向量机(support vector machine,SVM)等,也可以使用基于深度学习的方法。推荐对象的类别标签可以预先设置,也可以聚类生成。但是这两种方式都不能完全脱离人工参与,因为由自动聚类产生的标签对学习者来说可能并没有意义。“交互”则利用学习者与推荐对象的交互数据进行建模。文献[54]提出一种基于规则空间(rule-space)模型的推荐方法,该方法根据学习者在学习对象上的学习效果和学习进度等生成诊断表,并进一步将每个课程中学习对象描述为对于学习者的强弱学习状态。文献[55]提出一种基于贝叶斯个性化排序(Bayesian personalized ranking,BPR)算法的MOOC 课程推荐模型,该模型沿用了BPR 算法的成对排序思想,将一个正样本课程与随机采样的个负样本课程两两组合成个“正-负”样本对,然后将它们的编号通过嵌入矩阵转换生成嵌入表示。该方法中还采用了一种可以从成对样本中学习偏好排序的神经网络,用于捕获课程两两之间的偏好排序信息。动态方法利用了“资源-资源”之间的关系、“资源-学习者”之间的动态关系形成推荐对象特征,使对象模型具备了动态性,即能随着推荐对象在系统中随学习过程产生的状态变化而进行调整,有利于更好与不断变化的学习者特征匹配。
3.3 基于知识的学习推荐对象建模
基于知识的学习推荐对象建模方法也通常采用领域本体或知识图谱实现。学习资源本体的构建多采用半自动化或手工方式,同样离不开人工参与,难以避免主观偏差。文献[45]通过专家咨询,采用五种特征构建学习资源本体,即:格式、交互类型、交互级别、语义密度和学习资源类型。文献[57]为了提高学习资源本体构建的效率,采用了领域专家协作标注结合DOGMA的本体构建方法,框架如图10 所示。该方法在准备好包含相关知识数据的基础上,先进行清洗和修剪,凸显出实体、属性以及关系,并基于此建构推荐对象本体;在本体构建的过程中,再结合领域专家的协作参与不断完善和优化推荐对象本体。

图10 DOGMA 本体构建方法框架Fig.10 Framework of DOGMA ontology construction method
基于知识的方法本质上是借助专家参与,利用领域知识来补充学习推荐对象的描述,从而使推荐对象的特征更加丰富,对象模型更适用于相应的推荐算法。由于领域知识的加入,使学习推荐对象能够根据需要匹配多种推荐应用场景,且使相应的推荐算法具备了更高的可解释性。
4 学习推荐方法
本章将介绍学习推荐方法,这些方法是在学习者模型(第2 章所介绍)与推荐对象模型(第3 章所介绍)基础之上实现的。学习推荐方法中利用了学习者和推荐对象建模的功能,且这些功能会随着应用需求的差异而各不相同。本章重点介绍根据学习者和推荐对象模型进行计算、匹配、筛选、排序等用于推荐的算法模型。
许多个性化学习推荐方法参考了电子商务领域的商品推荐方法。这些方法把学习者看作电子商务平台的用户,把学习资源看作商品,以学习者在学习资源上的打分作为推荐模型的训练标签。常用的方法包括基于内容推荐(content-based recommendation,CBR)、协同过滤推荐(collaborative filtering recommendation,CFR)以及混合推荐(hybrid recommendation,HR)。此外,基于知识的学习推荐方法,以及基于会话的学习推荐方法也是研究的热点,本章将对这些方法进行介绍。
4.1 基于内容的学习推荐
基于内容推荐方法(CBR)是通过比较学习资源的属性特征与学习者的偏好,找到与学习者偏好最符合的学习资源。与电子商务中基于内容的推荐有所不同,基于内容的学习推荐可以借鉴学习领域的一些知识背景,比如学习风格模型。文献[62]通过人工定义若干推荐规则将学习资源的特征与学习者的学习风格模型进行关联,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐。也有研究将学习资源与学习者的知识掌握水平进行关联,如文献[63]提出了一种学习内容推荐方法,该方法首先采用特征选择模型提取学习资源的表示特征,再将表示特征根据学习者理解水平进行分类,从而在大量数据中识别出确切的学习资源内容,然后根据学习者的理解水平进行推荐。除了与学习资源的属性特征直接比较外,现有研究关注于提取学习资源的潜在特征,以及发掘其与学习者的关联。文献[53]提出的推荐方法通过历史学习资源的文本数据(内容本身或内容简介)结合学习者偏好训练CNN 模型。在使用时,该模型可以将输入的学习资源文本信息转换为学习资源的特征,然后结合学习者偏好预测评分进行推荐。基于内容的学习推荐方法离不开学习资源属性特征,一旦缺乏有用的特征数据,该方法的有效性将大为降低。
4.2 协同过滤学习推荐
协同过滤是推荐系统中的经典算法,其执行过程是根据“用户-用户”相似矩阵或者“项目-项目”相似矩阵比较找到最相似用户或项目,因此进一步可以分为基于用户的协同过滤(user-based CFR),如图11(a)所示,和基于项目的协同过滤(item-based CFR),如图11(b)所示。图11(a)和图11(b)中矩阵的行表示用户,列表示项目,矩阵内的元素表示用户对项目的评分,但两者的计算方式不同。如在图11(a)所展示的User-based 协同过滤中,将第2 行和第4 行分别作为用户和的项目偏好特征向量,通过计算其相似度来确定相似用户;在图11(b)所展示的Item-based 协同过滤中,将第1 列和第4 列分别作为项目和的用户偏好特征向量,通过计算其相似度来确定相似项目。

图11 协同过滤推荐使用的相似矩阵Fig.11 Recommended similarity matrix for collaborative filtering
在学习推荐场景中,该类方法则是基于学习者对学习资源的评分构建“学习者-学习者”相似度矩阵或“学习资源-学习资源”相似度矩阵,然后根据学习资源项目上的评分找到相似的学习者。NN 是协同过滤推荐方法中的常用算法,基于NN 的协同过滤推荐方法根据学习者或项目在相似矩阵中的表示,直接使用所有邻居进行项目之间的相似度计算,在相似矩阵很大的情况下导致了较高的时间复杂度。在推荐应用中,NN 通常采用单个距离度量方法进行相似度的计算,如Cosine、Jaccard、Manhattan等,由于这些指标本身的侧重点不同,可能会对系统的性能产生不同的影响。
4.3 混合学习推荐
混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的。混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略。如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构。文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模。然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐。对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量。文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型。文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性。该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐。文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度。文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐。
4.4 基于知识的学习推荐
学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源。基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识。而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障。使用本体对学习领域进行建模是基于知识学习推荐中的常用手段。在此过程中,除了可以用本体对学习者和学习资源的知识进行建模之外,还可以用它来描述学习场景中的要素。比如,文献[43]构建了E-learning环境中的学习行为标准本体。文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模。文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示。
近年来基于知识图谱的学习推荐方法受到了关注。文献[75]基于学习过程中已出现知识单元、目标知识单元、知识单元依赖等构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径。文献[15]构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者的学习目标和学习资源的特征表示推荐学习路径。
基于知识的学习推荐方法具有灵活性的语义描述域,文献[52]提出一种采用本体综合描述CBR、CFR、HR 等推荐算法,并选择性调用相关算法的课程推荐方法,该方法能够根据需求,对已描述的推荐算法进行动态调用。基于知识的学习推荐方法广受关注的主要原因在于:教学是一个有规律的活动,学习行为的目标明确,而且学习资源特征与学习者的需求之间的映射规则易于定制。但是,领域本体或领域知识图谱的构建也是一个需要人工参与,且耗时耗力的过程,所构建本体的合理性和完备性也会影响推荐的效果。此外,学习者的状态,如情感、知识水平并非一成不变,知识的描述如果没有合理的更新机制,则会导致学习路径固化,反而与“个性化”的初衷相悖。
4.5 基于会话的学习推荐
CBR 基于用户和项目的静态特征,而CFR 则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖。而且,CBR和CFR 通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”。此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态。因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径。近年来,基于会话(session-based)的推荐方法成为研究热点。采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练。文献[39]提出了一种基于会话的MOOC 课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表。在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素。文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF 预测学生的答题情况,最后根据预测结果进行练习题推荐。文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用LSTM 模型预测知识点出现概率并以此对练习题建模。在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表。
本文把近年来对个性化学习推荐方法的研究归纳为基于内容的学习推荐、协同过滤学习推荐、混合学习推荐、基于知识的学习推荐以及基于会话的学习推荐五类,并对各类代表性推荐方法中的部分指标进行了比较,如表1 所示。基于内容、协同过滤以及混合推荐属于传统的推荐方法,也被广泛应用于其他推荐场景,这三种方法相关的研究比较丰富。基于内容的推荐方法有利于直接将推荐对象特征与学习者个性化参数进行匹配,易于实现且高效,但无法获取学习者和推荐对象在学习过程中的变化。协同过滤基于学习者与推荐对象的交互历史,从行为数据挖掘学习者对推荐对象的潜在评价,这种方法有助于发掘学习者的潜在兴趣或新兴趣,从而提高推荐的质量,但协同过滤推荐存在冷启动、数据稀疏性等问题。混合推荐方法利用多个推荐算法协同合作,能够在一定程度缓解单个算法存在的问题,不同的混合推荐方法可能采用的混合策略不同,通常要根据具体的应用场景和数据情况而定。基于知识的推荐方法充分利用教育领域知识,使学习推荐系统具备良好的可解释性,但由于领域知识模型离不开人工参与,难以避免主观偏差。以上几种学习推荐方法多关注学习者的长期静态偏好,而忽略了他们偏好随时间的转移。基于会话的学习推荐全面考虑了学习者在前后会话间的状态转移,并将会话作为推荐的基本单元,有利于对学习者即时状态的获取。但由于是会话数据自身特征所驱动,基于会话的学习推荐方法在会话内部结构处理、会话之间关系建模等问题上还有待进一步研究。

表1 个性化学习推荐方法摘要及对比Table 1 Summary and comparison of personalized learning recommendation methods
4.6 学习推荐方法相关问题
随着在线教育和网络技术的蓬勃发展,开放式学习拓展了学习推荐系统的应用场景。在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触。开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异。为了解决这一问题,文献[80]以分布式MOOC 平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori 的改进分布式关联规则挖掘算法。文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据。有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源。如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享。此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)的一个实例,如图12 所示,由学习者、学习资源、教师等实体构成。文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN 的学习资源推荐方法。
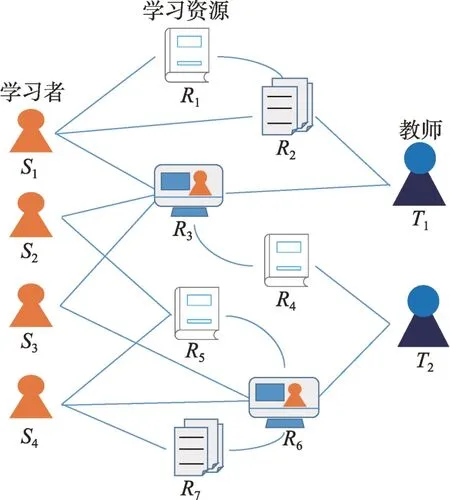
图12 异质学习网络中的实体关系示意图Fig.12 Schematic diagram of entity relationship in heterogeneous learning network
冷启动是推荐系统的常见问题。推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题。在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录。这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性。基于LSTM 网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的。文献[86]提出一种基于LSTM 模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM 网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题。面向个性化学习问题,文献[87]提出,在知识追踪模型中引入外部信息能够对冷启动起到有效缓解作用。文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题。文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示。此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题。文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势。文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐。
5 评估方法
学习推荐系统的评估通常围绕系统性能、用户体验和学习适用性三方面进行,本章将从这三方面对学习推荐系统的评估方法进行介绍。
5.1 系统性能
推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度。主要包括推荐预测的精度(accuracy)、召回率(recall)、1 分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等。有的研究同时采用多个指标的组合方式,以达到多角度评估的目的。比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和1 分数的评估。文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG 是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量。在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了1 分数,因为1 分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率。也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE)。虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一。
5.2 用户体验
文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关。一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题。为了解决这一问题,近年来研究人员对推荐的“偶然性”开展研究。文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意。为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化)。这必然会降低用户体验的满意度。因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量。新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好;多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意。新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响。文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估。对用户体验的评估也常采用人工方法。如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性。
5.3 学习适用性
学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估。在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐。然后通过比较三类学习者的成绩来开展学习适用性评估。文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性。文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据。与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性。其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别。此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估。文献[18]和文献[110]使用Felder-Silverman 学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性。文献[111]使用“自我-同行”评估方法,应用知识指示事件(knowledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响。
5.4 数据集与评估
目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类。课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX 数据集可用于评估基于学习风格的课程推荐,XuetangX 数据集可用于评估基于学习偏好的课程推荐,icourse163 数据集可用于课程学习中的主题推荐。对于学习资源推荐常采用Amazon 产品数据集、ASSISTment 学习平台数据集等,比如学习书籍推荐使用Amazon 的Book-Crossing 数据集、e-book 数据集,练习题推荐使用ASSISTment 数据集。对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集,所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估。
除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估。比如文献[60]从名为PLEM 的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009 年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS 的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集。
不同方法的评估角度和目的不相同,系统性能评估通常根据推荐系统在测试数据集上的表现来实现,本质上评估的是推荐系统对训练数据的学习能力表现,常使用精度、误差等指标来衡量;用户体验评估在于测量学习者对所推荐学习资源的感受,常通过对新颖度、多样性等指标的测量来评估是否出现推荐的过度专业化,从而弥补单纯准确性评估的不足;学习适用性则注重于所推荐的学习资源是否有利于学习效果和学习质量的提升,常通过学生成绩、学习时长等衡量。性能评估任务能够使用离线数据集完成,用户体验和学习适用性则可能需要加入真实教学场景中的实验。从现有的研究可以看出,对学习推荐系统的评估逐渐倾向于采用多种方法组合互为补充的方式,通过评估方法测量到学习推荐系统的不同效应也越来越丰富和多样化,尤其是对用户体验和学习适用性的评估,以及评估中所涉及到的数据隐私问题近年来也越来越受到研究人员的关注。
6 结束语
学习推荐是人工智能教育的核心研究内容,其目标是为学习者匹配到最适合的学习资源或路径,这种匹配并非仅仅迎合学习者的兴趣,而应该以激发和培养学习动机,提高学习者的学习积极性和持久性,达到提升学习效率为目标。鉴于此,本文从学习推荐系统的通用框架结构出发,将其分解为三个核心问题,即:学习者建模、学习推荐对象建模以及学习推荐方法。具体而言,在学习者建模方面,应根据需求组合多种学习者个性化参数构建学习者模型,并采用能够充分保留学习者特征语义的建模方法。在学习推荐对象建模方面,所提取的特征应与学习者的个性化参数相匹配,不同类型对象的特征表示应该统一,且符合算法模型的输入要求。在学习推荐方法方面,应以学习活动的开展为背景,并围绕学习者与学习资源的交互行为进行设计。学习推荐系统的总体设计思路,不能脱离学习活动的规律,且有必要适时结合人工评估,或真实教学场景下的实验开展用户体验和学习适用性的评价。在未来的研究中,学习推荐系统可能在学习者状态获取和表征,以及学习场景建模等方面产生新的发展。
(1)学习效果预测
学习效果预测是自适应学习的研究热点。学习推荐系统的目标之一是通过推荐对象提升学习效果,因此在推荐系统中融合学习效果预测,能够对推荐方法的适应性进行预检验,有利于及时调整和优化推荐策略。
(2)多特征学习状态表示
学习者的个性化参数较多,且认知水平、情绪状态、学习风格等多种特征会随着学习活动的开展产生变化。如何及时捕获这些特征的变化并进行有效表示,将是学习者建模研究的一个重要方向。
(3)基于网络理论和图方法的学习推荐
随着在线学习环境的拓展和形式的多样化,学习交互行为的类型越来越丰富,“学习者-学习者”“学习资源-学习资源”以及“学习者-学习资源”之间的关系越来越复杂,形成了复杂的图或网络结构。与线性结构相比,网络或图结构能够反映更真实的情境,表达更丰富的信息。因此,运用图计算和图神经网络技术对学习者建模和学习资源建模,并设计基于图的学习推荐算法模型,将是未来学习推荐研究的热点方向。
随着智慧学习和人工智能教育的广泛应用,个性化学习推荐技术也在不断发展,但这过程中还需对体系框架、学习者建模、学习推荐对象建模、推荐算法等核心关键技术进行持续探索。同时,还要甄别与其他推荐系统在推荐目标上的差异,深度融合教育学、心理学相关理论和方法,搭建针对用户体验和学习适用性的评估体系,并积极推广至学习系统中,促进在线教育的内涵发展,推动在线学习系统的技术创新。
