图嵌入模型综述
2022-01-18袁立宁王晓冬
袁立宁,李 欣,王晓冬,刘 钊
1.中国人民公安大学 信息网络安全学院,北京100038
2.天津市公安局河西分局 科技信息化支队,天津300202
3.天津市公安局河东分局 科技信息化支队,天津300171
4.中国人民公安大学 新型犯罪研究中心,北京100038
图是复杂系统中常用的信息载体,可以表示现实中许多复杂关系,如社交网络、犯罪网络、交通网络等。图结构作为一种非欧几里德数据,很难直接应用卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)等深度学习方法。为了构造用于图数据挖掘的特征表示,图嵌入将节点映射到低维空间,生成保留原始图中某些重要信息的低维向量。目前,图嵌入不仅在节点分类、链接预测、节点聚类、可视化等复杂网络上的机器学习任务中获得成功,还广泛用于社交影响力建模、内容推荐等现实任务。
早期的图嵌入算法主要用于数据降维,通过邻域关系构建相似度图,将节点嵌入低维向量空间,并保持相连节点向量的相似性。这类方法通常时间复杂度高,很难扩展到大型图上。近年来,图嵌入算法转向扩展性强的方法。例如,矩阵分解方法使用邻接矩阵的近似分解作为嵌入;随机游走法将游走序列输入到Skip-Gram生成嵌入。这些方法利用图的稀疏性降低了时间复杂度。当前,很多综述对图嵌入方法进行了归纳与总结,但存在两大局限:一是部分综述仅涉及传统方法介绍,许多新模型没有纳入研究;二是这些综述只关注静态图嵌入或动态图嵌入,忽略了二者之间的关联性。
本文对图嵌入方法进行全面系统性综述,有以下三方面的贡献:(1)提出一种新的图嵌入分类法,同时对静态图和动态图方法进行分类;(2)对现有模型进行系统性分析,为理解现有方法提供新视角;(3)提出了四个图嵌入的潜在研究方向。
1 图嵌入相关定义及符号表示
1.1 问题定义
图)图通常表示为=(,),其中表示节点集,表示边集。
(静态图)给定图=(,),如果节点和边的状态不随时间变化,图为静态图。
(动态图)动态图可以按时间分成一系列演化图G=(,,…,G,表示演化图的数量。每个演化图G=(V,E表示节点和边在时刻的状态。动态图包含快照型和连续时间型(见图1)。快照型动态图按时间序列将动态图分解为等间隔的静态图;连续时间型用多个时间戳标记每条边来保留节点间的连接变化。
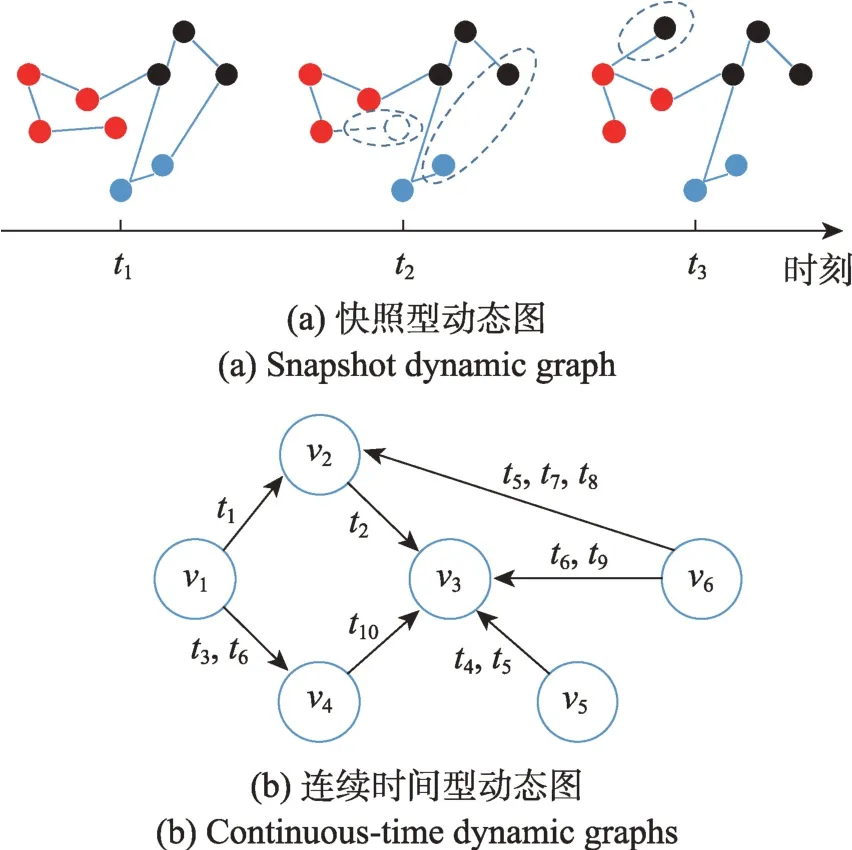
图1 快照型和连续时间型动态图Fig.1 Snapshot and continuous-time dynamic graphs
(一阶相似度)一阶相似度描述节点之间的成对邻近度。如果节点v和v之间存在一条边,v和v的一阶相似度为边权重w;如果在v和v之间没有边,一阶相似度为0。
(二阶相似度)二阶相似度描述节点邻域结构的相似度。假设w=[w,w,…,w]表示节点v与其他节点的一阶相似度,那么v和v的二阶相似度由w和w的相似程度决定。
(图嵌入)图嵌入将每个节点映射成低维向量表示(见图2),同时保留了原始图中某些关键信息。映射函数通常定义为:v→Y∈R,其中为嵌入向量的维度。

图2 图嵌入的一般过程Fig.2 General framework for graph embedding
1.2 符号表示
本文常用符号及其定义见表1。

表1 符号及定义Table 1 Symbols and definitions
2 图嵌入分类
本章提出一种新的分类方法,用于现有图嵌入模型的分类。按照模型所使用的算法原理将静态图和动态图模型同时分为五大类:基于矩阵分解的图嵌入、基于随机游走的图嵌入、基于自编码器的图嵌入、基于图神经网络(graph neural networks,GNN)的图嵌入和基于其他方法的图嵌入。图3 为分类思路及内容体系构建,图4 为图嵌入模型的分类汇总。
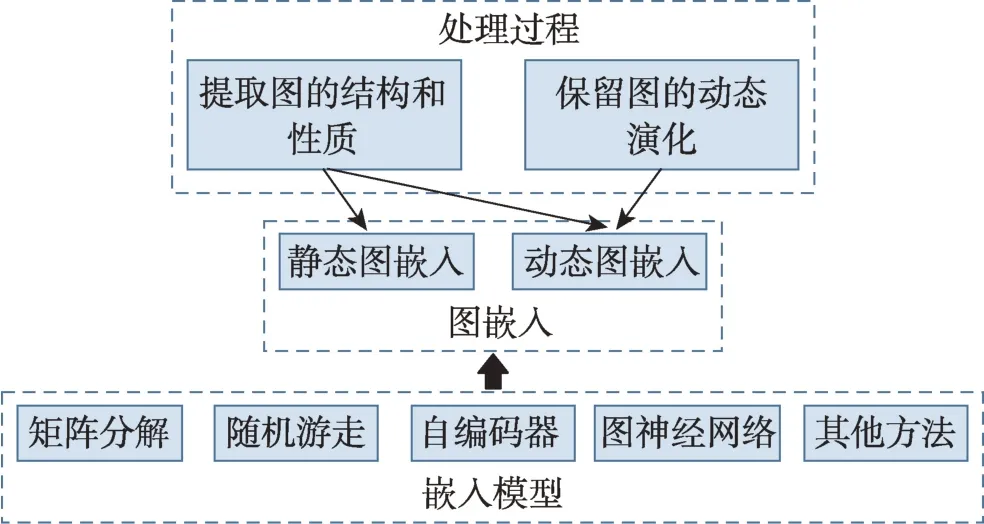
图3 图嵌入内容体系Fig.3 Content system of graph embedding
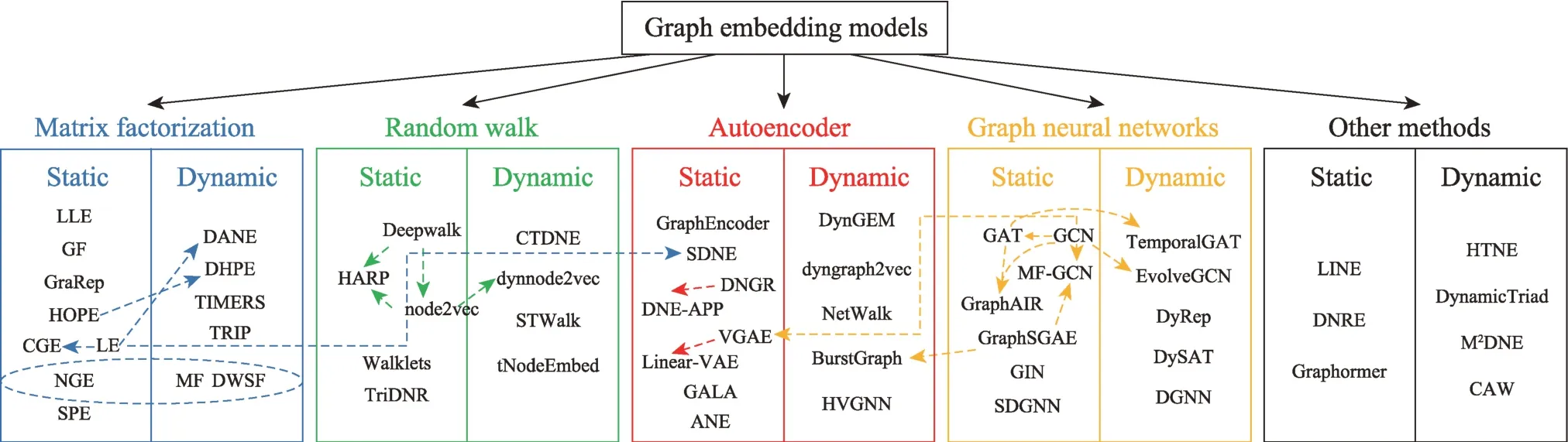
图4 图嵌入模型分类汇总Fig.4 Categorization and summary of graph embedding models
2.1 基于矩阵分解的图嵌入
基于矩阵分解的图嵌入通过分解节点关系矩阵获得低维嵌入。不同的关系矩阵采用的分解方法不同,例如邻接矩阵通常使用奇异值分解(singular value decomposition,SVD)的方法生成节点嵌入,而属性矩阵通常使用特征值分解的方法。
基于矩阵分解的静态图嵌入模型对节点关联信息矩阵和属性信息矩阵进行特征分解,然后将分解得到的属性嵌入和结构嵌入进行融合,生成节点的低维嵌入表示。图5 说明了矩阵分解和静态图嵌入生成的一般过程。
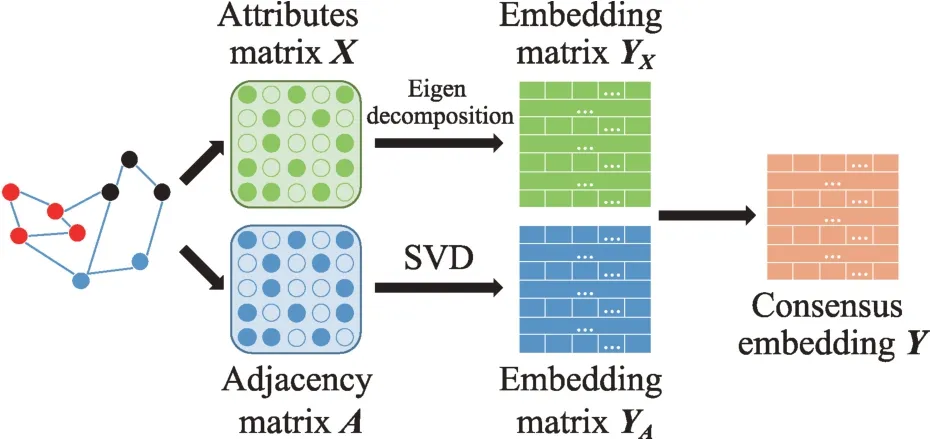
图5 基于矩阵分解的静态图嵌入模型框架Fig.5 Framework of eigenvalue factorization in static graph embedding
局部线性映射(locally linear embedding,LLE)将每个节点表示为相邻节点的线性组合,构造邻域保持映射(见图6)。具体实现分为三步:(1)以某种度量方式(如欧氏距离)选择个邻近节点;(2)由个近邻线性加权重构节点,并最小化节点重建误差获得最优权重;(3)最小化最优权重构建的目标函数生成。目标函数的表达式为:

图6 LLE 步骤Fig.6 Steps of LLE

式中,W为节点与节点的权重系数。作为一种重要的降维算法,LLE 在降维时能够保持样本的局部特征,并通过稀疏矩阵特征分解的方式适当降低了计算复杂度。但是,该模型对值的选择十分敏感,对最终的降维结果有极大影响。
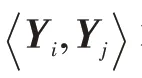
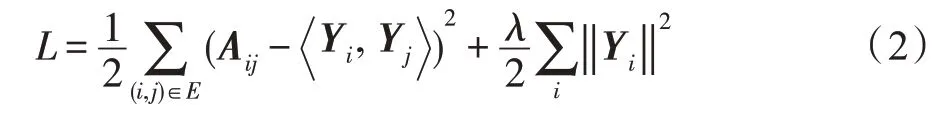
由上式特性可知,在节点数量较多、嵌入维度较大时,模型计算会产生极大的内存占用。为此,GF 设计了一种最小化簇外一阶邻居数量的图分割算法,保证图结构信息无损,提升模型计算效率。
GraRep分别构建1 到步的对数转移概率矩阵{,,…,T},将T中所有负值元素替换为0,使T为正步对数转移概率矩阵,以减少噪声。最后,使用SVD 分解T得到节点表示Y,并将{,,…,Y}进行合并,得到最终嵌入。GraRep 能够在嵌入中整合全局结构信息,但训练过程中涉及矩阵运算和SVD,计算复杂度极高,难以扩展到大规模图数据。
非对称传递性可以刻画有向边之间的关联,有助于捕捉图的结构。为了保留有向图中的非对称传递性,HOPE采用了一种保持高阶相似度的嵌入方法,在保留非对称传递性的向量空间中生成图嵌入(见图7),训练中使用L2 范数进行优化:
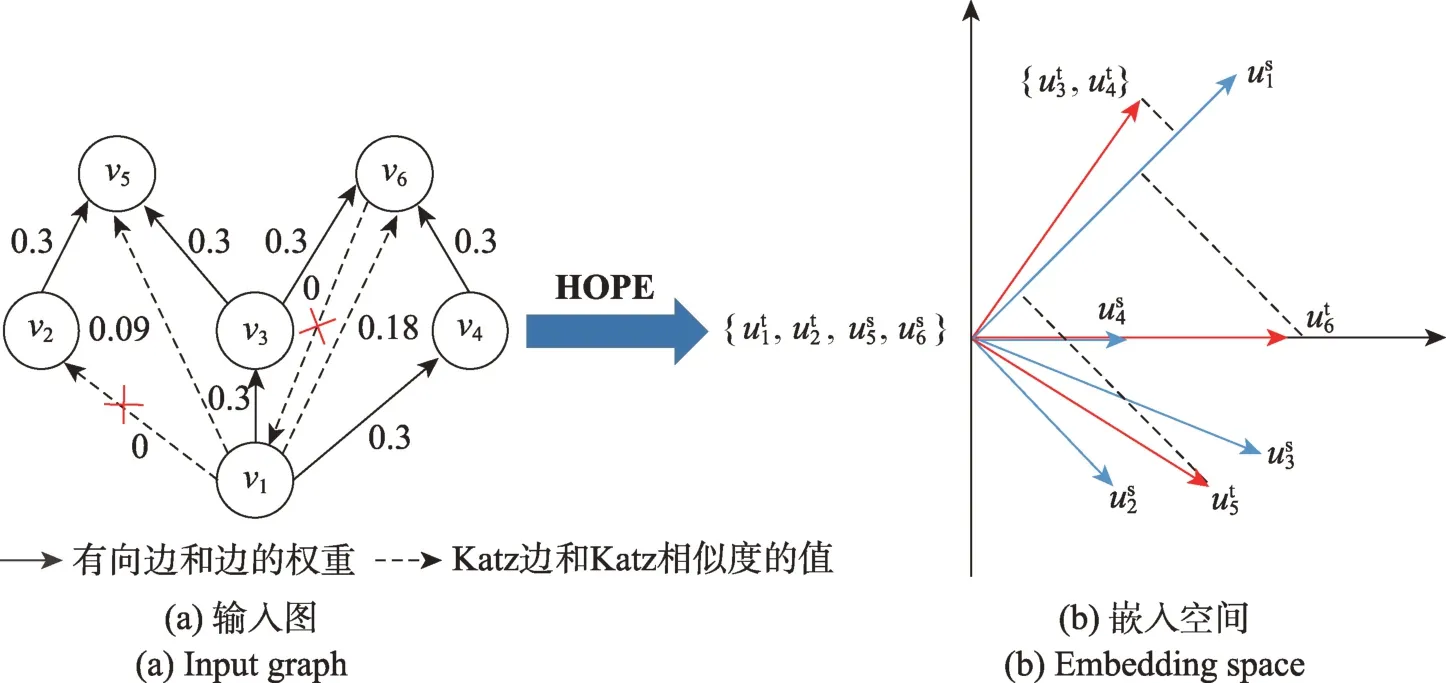
图7 HOPE 模型框架Fig.7 Framework of HOPE

式中,为源嵌入,为目标嵌入。许多相似性度量可以反映非对称传递性,如Katz指标、Adamic-Adar分数等,用于构建相似度矩阵。此外,HOPE 使用广义SVD(generalized singular value decomposition,GSVD)分解,适当降低了计算复杂度,但是低阶GSVD 逼近能力有限,限制了模型表达能力。
在原始图上,本征图用于保留节点间有利关联,惩罚图用于保留节点间的不利关联。为了综合本征图和惩罚图的特点,NGE(non-negative graph embedding)引入非负矩阵分解(non-negative matrix factorization,NMF)生成嵌入表示。NMF 将数据矩阵分解成低阶非负基矩阵和非负系数矩阵,并使用L1 损失作为目标函数。在此基础上,NGE 将和分成两部分:=[,];=[,]。由于(,)和(,)是互补空间,可以通过叠加的方式重构原始数据,的目标函数可以由惩罚图目标函数进行转换。将NMF 的L1 损失和和目标函数相结合,可得NGE 的目标函数为:
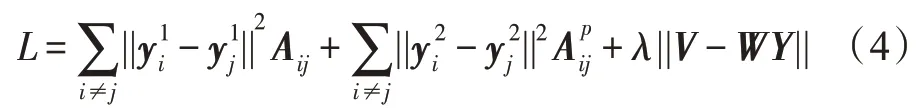
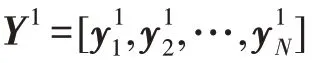
拉普拉斯特征映射(Laplacian eigenmaps,LE)与LLE 相似,也是从局部近似的角度构建数据之间的关系。具体而言,LE 使用邻接矩阵建立包含局部结构信息的嵌入表示,并要求相连节点在嵌入空间中尽可能地靠近。因此,LE 的目标函数为:

由上式可知,LE 的目标函数强调权值大的节点对,弱化权值小的节点对,导致原始图中的局部拓扑结构被破坏。为了增强图嵌入的局部拓扑保持性,柯西图嵌入(Cauchy graph embedding,CGE)引入距离的反函数来保持节点在嵌入空间中的相似关系。因此,CGE 将LE 的目标函数改写为:

相比LE,CGE 的目标函数更加强调短距离,即确保局部越邻近的节点在嵌入空间的距离越接近。

从矩阵分解的角度看,图的动态演化实质上是原始矩阵的不断变化。基于矩阵分解的动态图方法利用特征分解构造图的高阶相似度矩阵,然后利用矩阵摄动理论更新图的动态信息。矩阵摄动理论可以高效更新图的高级特征对,同时避免了每个时刻的重新计算嵌入矩阵。图8 是基于矩阵分解的动态图嵌入的一般过程。
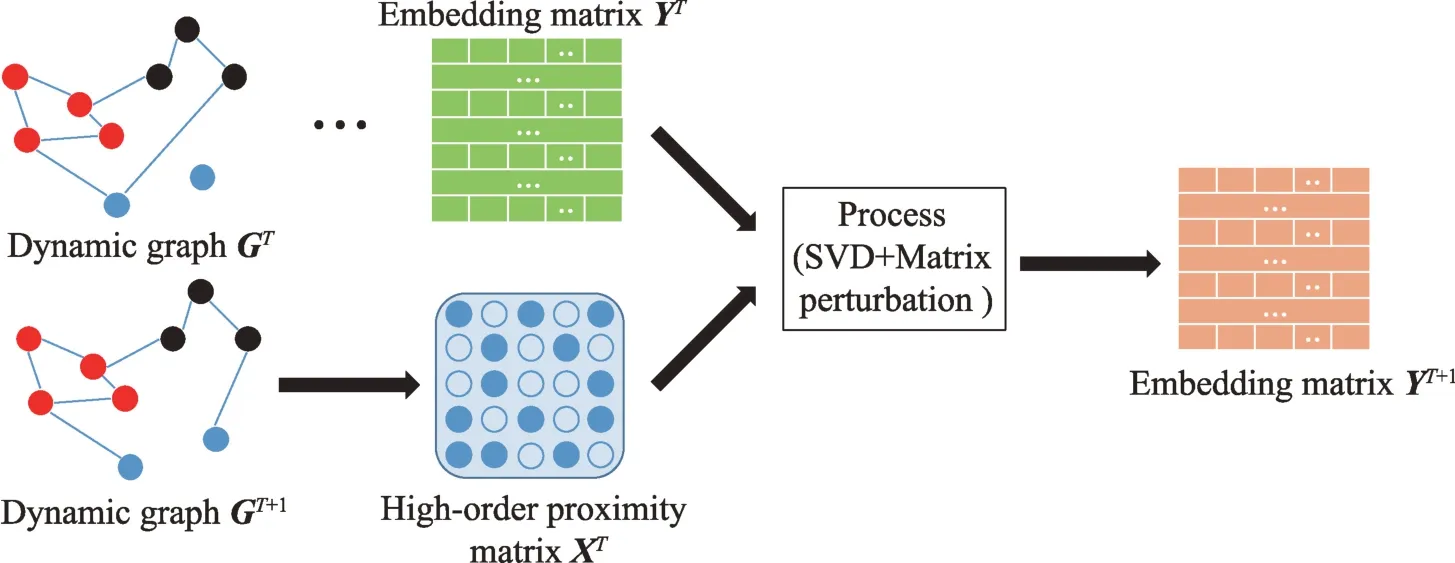
图8 基于矩阵分解的动态图嵌入模型框架Fig.8 Framework of matrix factorization in dynamic graph embedding


图9 DANE 模型结构Fig.9 Framework of DANE
DHPE同样采用分布式框架:静态部分,DHPE与HOPE 相似,将GSVD 分解Katz相似度矩阵转换为广义特征值问题,使每个时刻生成的低维嵌入保留节点的高阶相似度;动态部分,DHPE 使用矩阵摄动理论更新GSVD 的结果。此外,模型假设图中节点数恒定(添加或删除的节点为孤立节点),使每个时刻图的变化转化为边的变化。DHPE 能够在保持高阶相似性的同时更新节点嵌入,其增量计算方案有效提升了动态模型的计算效率。
Chen 等人提出了TRIP 和TRIP-BASIC 两种在线算法跟踪动态图的特征对,其核心思路是利用矩阵摄动理论对图的特征对进行更新。TRIP 和TRIPBASIC 引入图中三角形个数作为属性信息构建特征函数,然后将特征对映射成属性向量。上述模型能够有效追踪特征对、三角形个数和鲁棒性分数随时间的动态变化,但是模型的误差会随着时间推移不断积累。
由于增量矩阵的更新采用近似值的方式,导致生成嵌入的过程中误差不断积累。为解决上述问题,TIMERS采用SVD 最大误差界重启算法,设置SVD 重新启动时间,减少时间上的误差积累。该模型的核心包含两部分:(1)增量更新,通过函数近似地更新前一时刻的结果;(2)SVD 重启,通过设置误差阈值,确定执行SVD 重启时刻,重新计算最优SVD结果,并最小化重启次数。
MF通过构造携带重要特征的矩阵因子,使潜在的NMF 特征有效地表达动态信息。为了充分利用不同时刻的拓扑信息,MF 对嵌入空间的邻接关系矩阵进行整合,找到在各个时刻一致的嵌入矩阵和系数矩阵,并通过最小化Frobenius 范数使各时刻Y和、W和差异最小。基于NMF 加权表示相似性指数的MF 比基于静态表示相似性指数的方法具有更好的性能。
DWSF采用使用Semi-NMF和弱监督分解(weakly supervised factorization,WSF),将数据矩阵分解为标签矩阵和嵌入矩阵(=,其中是非负的,和没有约束),然后使用标签传播(label propagation)算法初始化标签矩阵因子,将类标签从有标签的数据实例传播到无标签的数据实例,最后将控制信息量的平滑度项与Semi-NMF 相结合,优化模型参数生成嵌入。DWSF 将有限的监督信息合并为类别标签,在每次迭代中动态更新,大幅提升了模型在分类任务上的表现。
2.2 基于随机游走的图嵌入
受word2vec的启发,基于随机游走的图嵌入方法将节点转化为词,将随机游走序列作为句子,利用Skip-Gram 生成节点的嵌入向量。随机游走法可以保留图的结构特性,并且在无法完整观察的大型图上仍有不错的表现。
基于随机游走的静态图嵌入模型通过随机游走获得训练语料库,然后将语料库集成到Skip-Gram 获得节点的低维嵌入表示。
Deepwalk使用随机游走对节点进行采样,生成节点序列,再通过Skip-Gram 最大化节点序列中窗口范围内节点之间的共现概率,将节点v映射为嵌入向量Y(见图10):

图10 Deepwalk 模型结构Fig.10 Framework of Deepwalk
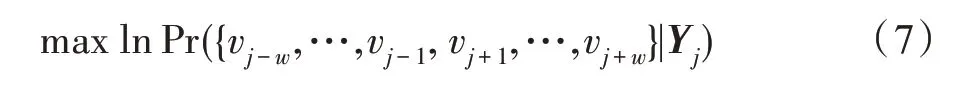
生成的嵌入将节点之间的关系编码在低维向量空间,用于捕捉邻域相似性和社区结构,学习节点的潜在特征。Deepwalk 不仅在数据量较少时有较好的表现,还可以扩展到大型图的表示学习。由于优化过程中未使用明确的目标函数,使得模型保持网络结构的能力受到限制。
node2vec在Deepwalk 的基础上,引入有偏的随机游走(见图11),增加邻域搜索的灵活性,生成质量更高、信息更多的嵌入表示。通过设置和两个参数,平衡广度优先搜索(breadth-first sampling,BFS)和深度优先搜索(depth-first sampling,DFS)策略,使生成的嵌入能够保持社区结构等价性或邻域结构等价性。虽然node2vec 能够保持更多的一阶相似度和二阶相似度信息,但仍然缺少明确的目标函数来保持全局网络结构。

图11 node2vec中的随机游走过程Fig.11 Random walk procedure in node2vec
Deepwalk 和node2vec 采用随机游走探索节点局部邻域,使得学习到的低维表示无法保留图的全局结构,同时使用随机梯度下降求解非凸的目标函数,使生成的嵌入可能陷入局部最优解。为了解决上述问题,HARP将原始图中的节点和边递归地合并在一起,得到一系列结构相似的压缩图。这些压缩图有不同的粒度,提供了原始图全局结构的视图。从最粗略的形式开始,每个压缩图学习一组嵌入表示,并用于初始化下一个更细化的压缩图的嵌入。HARP能够与Deepwalk 和node2vec结合使用,提升原始模型性能,生成信息更丰富的嵌入表示。
利用分层Softmax,Deepwalk 目标函数可以改写为矩阵分解的形式:
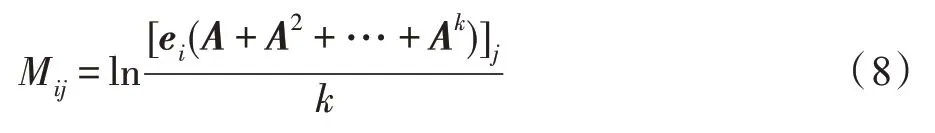
式中,M是以节点为起点为终点的长度为的路径期望值;e是one-hot 向量,其第个元素为1 其余元素为0,A的不同幂次代表了不同的尺度。可见Deepwalk 已经隐式地建模了从1 到阶的多尺度依赖关系,但无法单独访问不同尺度。为了显式地构建阶关系,Walklets修改了Deepwalk 的采样过程,在随机游走序列上跳过-1 个顶点。除此之外,模型的优化和嵌入生成方式均与Deepwalk 相同。相较于Deepwalk,Walklets 能够捕获节点与社区之间不同尺度的层次结构,进而显式建模多尺度关系,保留更丰富的节点从属关系信息。
TriDNR是首个利用标签信息进行表示学习的深层神经网络模型,能够同时利用网络结构、节点特征和节点标签学习节点嵌入表示(见图12)。具体而言,TriDNR 使用两个神经网络来捕获节点-节点、节点-单词、标签-单词之间的关系。对于网络结构,通过随机游走序列最大化共现概率来保持图中节点间的邻近关系;对于节点特征,通过最大化给定节点的单词序列的共现概率捕获节点与单词的相关性;对于节点标签,通过最大化给定类别标签的单词序列的概率建模标签与单词的对应关系。最后,使用耦合神经网络的算法将三部分信息合并为节点嵌入。

图12 TriDNR 模型结构Fig.12 Architecture of TriDNR model
基于随机游走的动态图嵌入模型将每条边与对应时刻相关联,使随机游走序列由一系列包含递增时刻的边所连接的节点构成,最后利用Skip-Gram 模型将每个节点映射成维向量。
Sajjad 等人将图嵌入的生成过程分为两步:首先,更新动态图上的随机游走序列。与直接在静态快照上从头开始随机游走相比,更新算法保持了随机游走的统计特性。然后,在给定前一时刻的嵌入表示以及更新后的随机游走序列的条件下,利用Skip-Gram 模型对嵌入表示进行更新。CTDNE则利用时间随机游走从连续型动态图中学习包含时间信息的嵌入表示。实际上,CTDNE 采用的时间随机游走与静态图方法相似,但约束每个随机游走符合边出现的时间顺序,即边的遍历必须按照时间递增的顺序,由于每条边包含多个时间戳,使得同一节点可能在游走中出现多次。时间信息的引入减少了嵌入的不确定性,使CTDNE 在众多任务上的表现优于Deepwalk 和node2vec等静态模型。
在动态图中应用静态方法存在两大问题:(1)对每个快照都进行随机游走非常耗时;(2)不同快照的嵌入空间并不一致。为解决上述问题,Mahdavi 等人在node2vec 的基础上,提出了动态图嵌入模型dynnode2vec。该模型在快照上运行node2vec 获得嵌入向量以及训练后的Skip-Gram 模型。对于后续快照,在两个连续快照之间执行以下步骤:(1)为演化节点生成随机游走序列;(2)使用动态Skip-Gram将前一时刻学习到的嵌入作为初始权值,结合演化节点的随机游走生成当前时刻嵌入。由于动态图是逐渐演化的,即大多数节点的邻域保持不变,dynnode2vec 仅对演化节点进行随机游走大幅提升了模型效率。
STWalk是一种无监督节点轨迹学习算法,通过捕捉给定时间窗口内节点变化生成嵌入表示。该模型将当前时刻快照上的随机游走定义为空间游走,过去时刻快照上的随机游走定义为时间游走,从而捕捉节点的时空行为,然后利用Skip-Gram 生成节点轨迹的嵌入表示。STWalk 有两种不同的变体:STWalk1 同时考虑空间游走和时间游走来学习嵌入表示;STWalk2 将空间游走和时间游走建模为两个子问题并分别求解,然后组合两个结果获得最终的嵌入表示。上述模型仅使用图的结构信息学习捕获节点轨迹时空特性的低维嵌入,未考虑节点特征和标签信息。
Deepwalk 和node2vec 模仿单词嵌入作为节点嵌入表示,而tNodeEmbed模仿句子嵌入作为节点嵌入表示。句子中每个单词不仅代表节点随时间变化的向量,还捕捉了节点角色和连接关系的动态变化。为此,tNodeEmbed 使用联合损失函数优化两个目标:(1)三维特征空间中节点的静态邻域;(2)图的动态特性。tNodeEmbed 使用node2vec对节点嵌入进行初始化,将不同时刻的节点表示进行对齐,然后根据给定的图分析任务和过去时刻的节点嵌入联合学习,使生成的嵌入既保留图的结构和动态信息,又适用于特定任务。
2.3 基于自编码器的图嵌入
自编码器(autoencoder,AE)是一种人工神经网络,包含编码器和解码器两部分,用于无监督地构造输入数据的向量表示。通过对数据中的非线性结构进行建模,自编码器使隐藏层学习到的表示维度小于输入数据,即对原始数据进行降维。基于自编码器的图嵌入方法使用自编码器对图的非线性结构建模,生成图的低维嵌入表示。
基于自编码器的图嵌入方法起源于使用稀疏自编码器的GraphEncoder。其基本思想是将归一化的图相似度矩阵作为节点原始特征输入到稀疏自编码器中进行分层预训练,使生成的低维非线性嵌入可以近似地重建输入矩阵并保留稀疏特性:

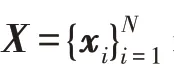
SDNE利用深度自编码器以及图的一阶、二阶相似度,捕获高度非线性的网络结构。SDNE 包含有监督组件和无监督组件(见图13),用于保持节点的一阶和二阶相似度。有监督组件引入拉普拉斯特征映射作为一阶相似度的目标函数,使生成的嵌入捕获局部结构信息。无监督组件修改L2 重建损失函数作为二阶相似度的目标函数,使生成的嵌入捕获全局结构信息。对一阶和二阶相似度联合优化,增强了模型在稀疏图上的鲁棒性,使生成的嵌入同时保留全局和局部结构信息。
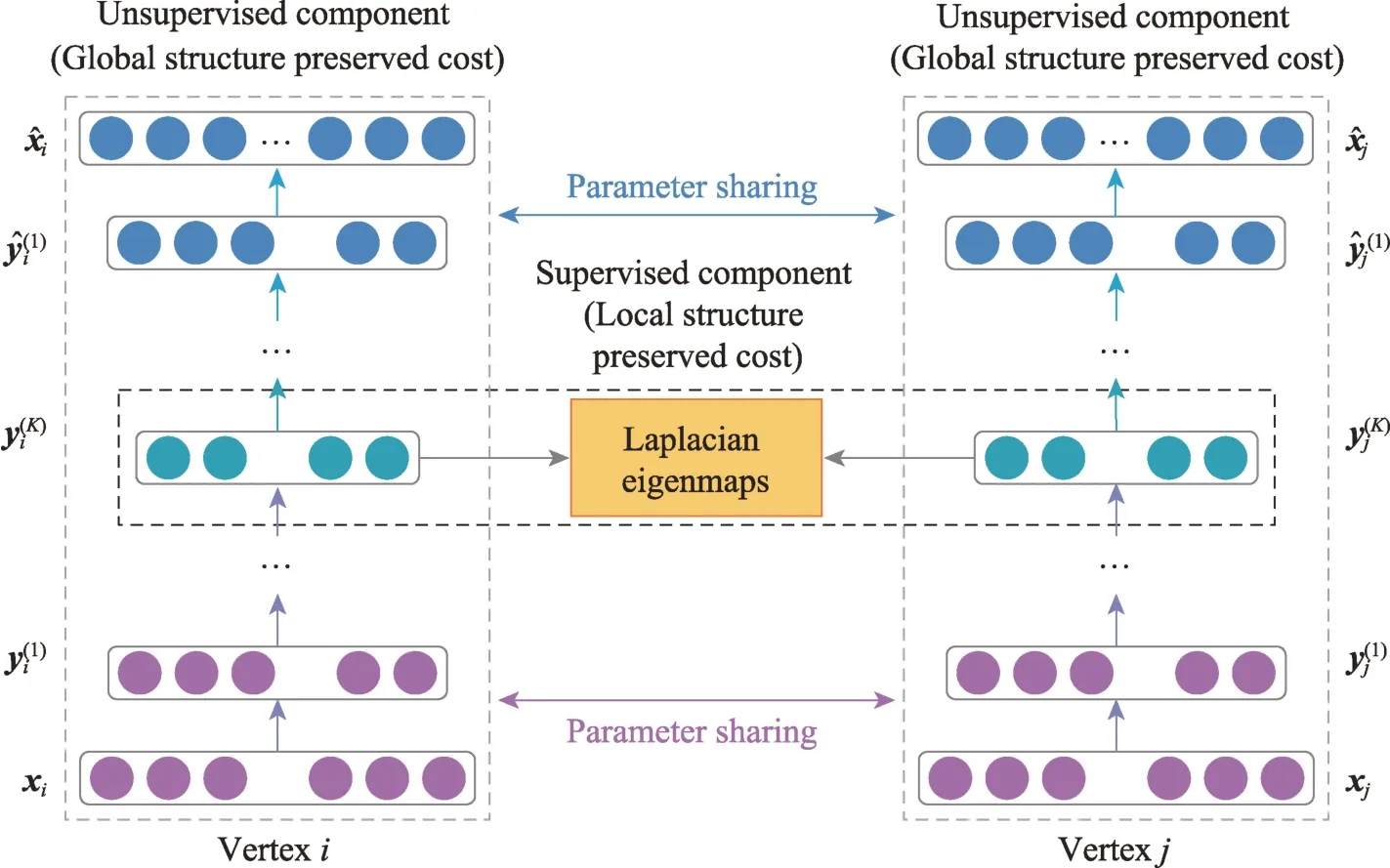
图13 SDNE 模型结构Fig.13 Framework of SDNE
DNGR生成低维嵌入的过程主要分为三步:(1)利用随机冲浪模型捕捉图的结构信息,并生成共现概率矩阵;(2)利用共现概率矩阵计算正逐点互信息(positive pointwise mutual information,PPMI)矩阵;(3)将PPMI 矩阵输入堆叠去噪自编码器(stacked denoising autoencoder,SDAE)生成低维嵌入表示。相较于随机游走,随机冲浪直接获取图的结构信息,克服了原有采样过程的限制;PPMI 矩阵能够保留图的高阶相似度信息;堆叠结构使隐层维度平滑递减,提升深层架构学习复杂特征的能力,同时去噪策略增强了模型的鲁棒性。
DNE-APP利用半监督堆叠式自编码器(stacked autoencoder,SAE)生成保留阶信息的低维嵌入主要分为两步:(1)使用PPMI 度量和步转移概率矩阵,生成包含阶信息的相似度聚合矩阵。(2)使用SAE重构相似度聚合矩阵,学习低维非线性嵌入表示。与仅保持一阶和二阶相似度的SDNE 相比,DNEAPP 模型可以保持不同的阶相似度;与仅重建高阶相似度的DNGR 相比,DNE-APP 在重建过程中引入了成对约束,使相似节点在嵌入空间更加接近。
变分自编码器(variational autoencoder,VAE)是用于降维的生成式模型,其优势为容忍噪声和学习平滑的表示。VGAE首先引入VAE 学习可解释的无向图嵌入表示。模型的编码器部分使用图卷积网络(graph convolutional network,GCN):
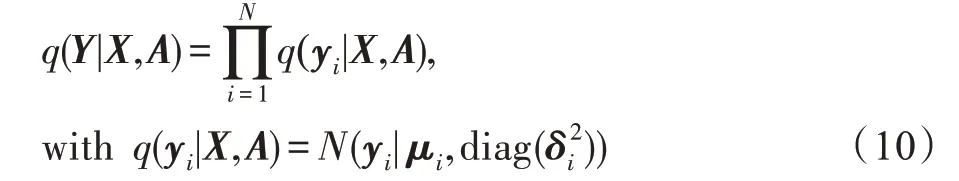
式中,=GCN(,) 是均值向量μ的矩阵,同样ln=GCN(,)为方差向量。模型的解码器部分使用嵌入的内积:
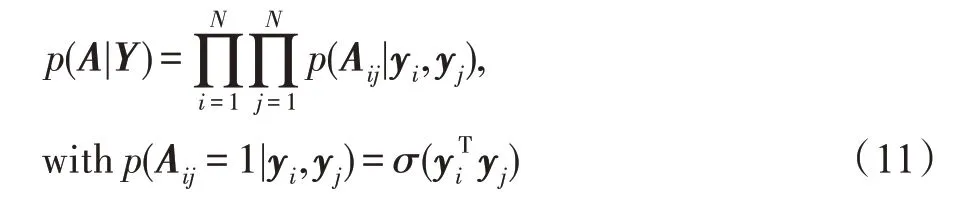
式中,(·)是sigmoid 函数。最后,VGAE 通过最小化重构损失和变分下界对模型进行优化:
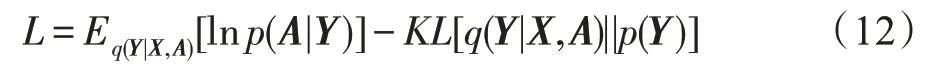
式中,[(·)||(·)]为(·)和(·)的KL散度,()为高斯先验。
Salha 等人提出的Linear-VGAE 模型使用基于归一化邻接矩阵的简单线性模型替换VGAE 中的GCN 编码器:
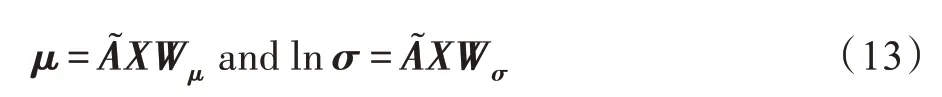
与一般的非对称模型不同,GALA采用完全对称的图卷积自编码器模型生成图的低维嵌入表示。在对输入矩阵重构的过程中,编码器执行的拉普拉斯平滑与解码器的拉普拉斯锐化相对称。与现有的VGAE 方法不同,为了使解码器可以直接重构节点的特征矩阵,GALA 使用谱半径为1 的拉普拉斯锐化表示。相较于仅使用GCN 编码器的模型,GALA 的对称结构,能够在编码和解码过程中同时使用结构信息和节点特征。
ANE使用对抗性自编码器生成捕获高度非线性结构信息的低维嵌入。具体而言,ANE 利用一阶和二阶相似度捕捉图的局部和全局结构,使生成的嵌入可以保持高度的非线性,同时训练过程对抗性自编码器的两个准则:一是基于重建误差的自编码器训练准则;二是将嵌入表示的聚合后验分布与任意先验分布匹配的对抗性训练准则。通过施加对抗性正则化,ANE 改善了嵌入生成过程中的流形断裂问题,提升了低维嵌入的表示能力。
基于自编码器的动态图方法将每个时刻训练的参数作为下一时刻自编码器的初始值,从而在一定程度上保持生成嵌入的稳定性,节省模型的训练时间,提高模型的计算效率。
受SDNE 的启发,Goyal 等人提出了快照型动态图嵌入模型DynGEM(见图14)。该模型使用深度自编码器将输入数据映射到高度非线性的低维嵌入空间,以捕捉任一时刻快照中节点的连接趋势,同时下一个时刻的嵌入模型直接继承前一个时刻的训练参数,使时刻的快照嵌入可以利用-1 时刻快照嵌入进行增量的学习。由于动态图中节点的数量不断变化,DynGEM 设计了一种可动态调节神经网络中神经元个数、隐层层数的方法PropSize。在训练过程中,DynGEM 结合一阶相似度和二阶相似度保留局部结构信息和全局结构信息,同时引入L1 和L2 正则化进一步提升模型性能。需要注意的是DynGEM 不强加保持相邻时刻嵌入接近的显式正则化,即相邻时刻的快照如果明显不同,则相应的编码函数f和f也有所不同。

图14 DynGEM 模型结构Fig.14 Framework of DynGEM
DynGEM 生成当前时刻嵌入时只捕获了前一时刻的信息,致使大量历史信息被忽略,为此Goyal 等人提出了另一个基于自编码器的动态图嵌入模型dyngraph2vec。该模型将之前个时刻的图结构信息作为输入,将当前时刻生成图嵌入作为输出,从而捕获当前时刻与之前多个时刻节点之间的非线性交互信息。该模型有三种变体(见图15):dyngraph-2vecAE 以一种简单的方式对自编码器进行扩展;dyngraph2vecRNN 和dyngraph2vecAERNN 使 用 长 短期记忆网络(long short-term memory,LSTM)对历史信息编码。在动态图的演化过程中,dyngraph2vec仅使用相邻节点,未考虑图的高阶相似度信息。

图15 dyngraph2vec变体结构Fig.15 Variations of dyngraph2vec
随着动态图的演化,NetWalk可以增量地学习网络表示(见图16)。具体而言,NetWalk 利用初始的动态图上提取的多个游走序列以及深度自编码器的隐藏层生成节点嵌入表示。在训练过程中,NetWalk联合最小化游走序列中成对节点的表示距离和自编码器的重构误差,使学习到的嵌入表示既可以实现局部拟合,又可以实现全局正则化。NetWalk 对生成到的嵌入表示使用动态聚类模型,能够标记图中异常的节点或边。
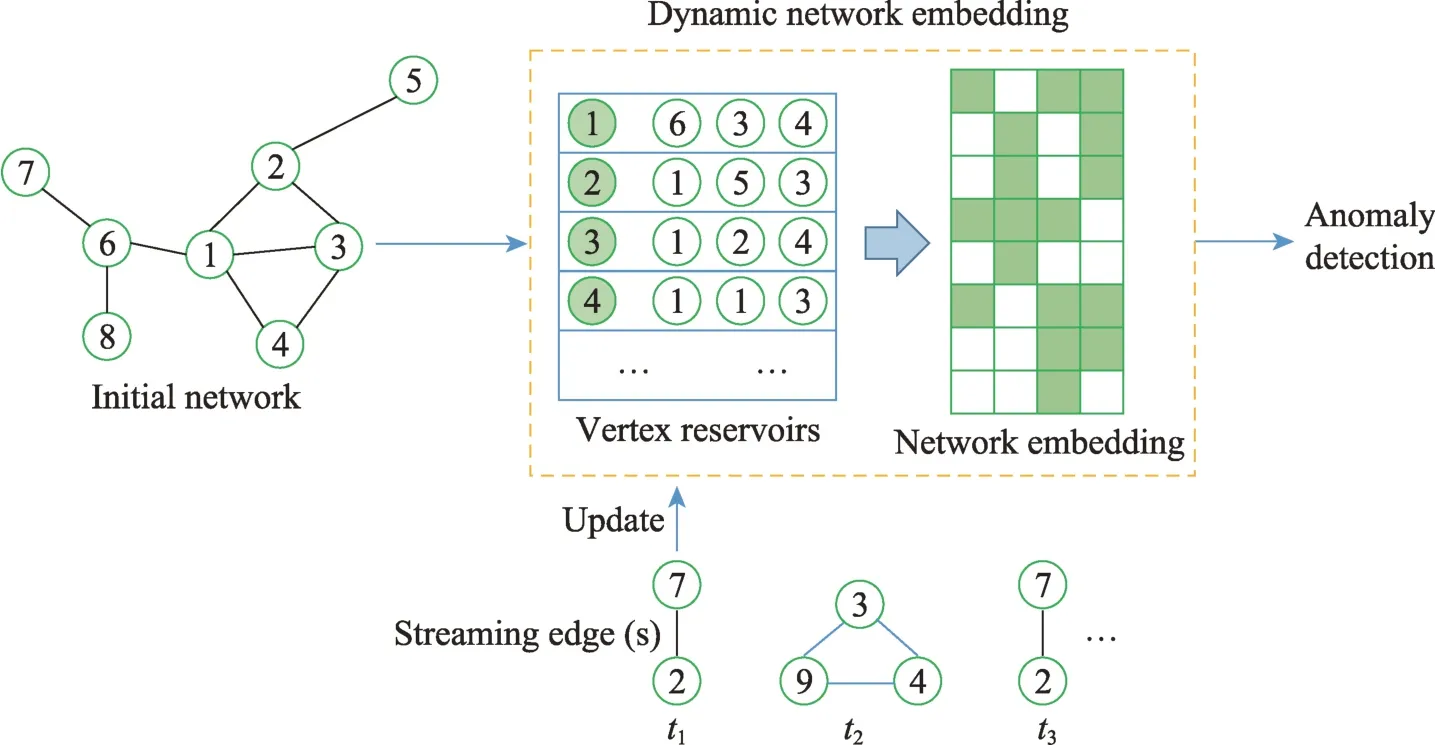
图16 NetWalk 异常检测的流程Fig.16 Workflow of NetWalk for anomaly detection
BurstGraph将动态图的演化分为一般演化和突发演化,并使用两个基于RNN 的VAE 分别对每个时刻的演化信息进行建模。在编码器部分,两个自编码器共同使用GraphSAGE学习到的节点特征和拓扑结构信息。对于突发演化,BurstGraph 在VAE 中引入了spike &slab 分布作为近似后验分布;对于一般演化,BurstGraph 使用原始的VAE 模型。为了充分利用图的动态信息,BurstGraph 使用RNN 捕捉每个时刻的图结构,将一般演化和突发演化信息保留在RNN状态单元中,并随时间的推移不断更新状态单元。由于生成的嵌入中保留了突发信息,BurstGraph常用于关于图的异常检测中的突发检测任务。
动态图嵌入通常存在三方面的局限性:(1)嵌入表示空间,欧式空间表示可能导致图的潜在层次结构失真;(2)动态信息,忽视图的动态演化通常会导致模型错误地利用未来信息来预测过去的交互;(3)不确定性,图的固有特性,生成的确定性表示不能对不确定性建模。为了解决上述问题,HVGNN采用双曲变分GNN 对双曲空间中的动态图进行建模,使生成的嵌入同时包含图的动态信息和不确定性。具体而言,HVGNN 使用双曲空间代替欧式空间,同时引入新的时间GNN(temporal GNN,TGNN)来建模动态特性。为了建模图的不确定性,HVGNN设计了一个基于TGNN 的双曲VGAE,使模型可以对不确定性和动态进行联合建模。最后,引入的重参数化采样算法,实现模型的梯度学习。相较于欧式空间计算量的指数增长,双曲空间降低了模型的计算复杂度;对于不确定性的建模,增强了传递较少信息且具有较多动态特性节点的表示性能。
2.4 基于图神经网络的图嵌入
图神经网络(GNN)是专门处理图数据的深度模型,其利用节点间的消息传递来捕捉某种依赖关系,使生成的嵌入可以保留任意深度的邻域信息。由于GNN 模型强大的表示能力,嵌入模型的性能得到了显著提升。
基于GNN 的静态图模型聚合节点邻域的嵌入并不断迭代更新,利用当前的嵌入及上一次迭代的嵌入生成新的嵌入表示。通过多次迭代,GNN 模型学习到的嵌入可用于表征全局结构。
GCN 使用节点特征矩阵与邻接矩阵生成包含节点的特征信息的嵌入表示(见图17)。对于多层GCN,层间传播公式为:
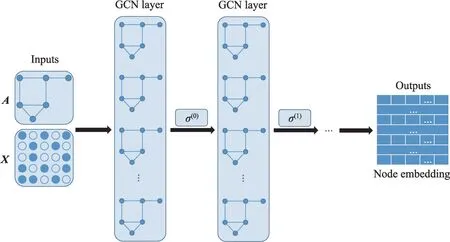
图17 多层GCN 结构Fig.17 Framework of multi-layer GCN
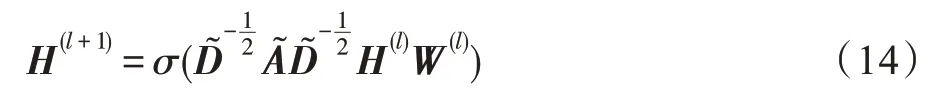
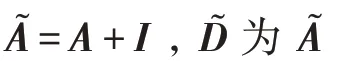
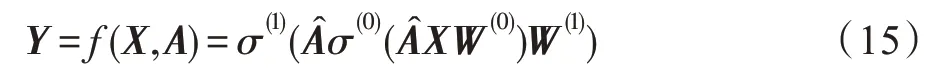

GCN 通常应用于固定图的直推式表示学习,GraphSAGE 将其扩展到归纳式无监督学习的任务中,利用节点特征(例如文本属性、节点度)学习不可见节点的嵌入表示。GraphSAGE 不是为每个节点训练单独的嵌入,而是通过采样和聚合节点的局部邻域特征训练聚合器函数,同时学习每个节点邻域的拓扑结构及特征分布,生成嵌入表示(见图18)。相比GCN,GraphSAGE 使用无监督损失函数强制邻近节点具有相似表示,远距离节点具有不同的表示。在给定下游任务的情况下,GraphSAGE 能够替换或增加相应的目标函数,进行有监督或半监督学习,提升模型的灵活性;训练过程执行分批次训练,提升模型的收敛速度。
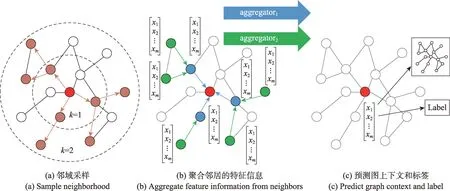
图18 图解GraphSAGE 采样和聚合方式Fig.18 Visual illustration of GraphSAGE sampling and aggregation approach
图注意力网络(graph attention network,GAT)在GCN 的基础上引入注意力机制,对邻近节点特征加权求和,分配不同的权值。针对单个节点,GAT使用self-attention获得注意力系数:

式中,e表示的是节点对节点的重要性。GAT 使用masked-attention将注意力分配到节点的邻域:
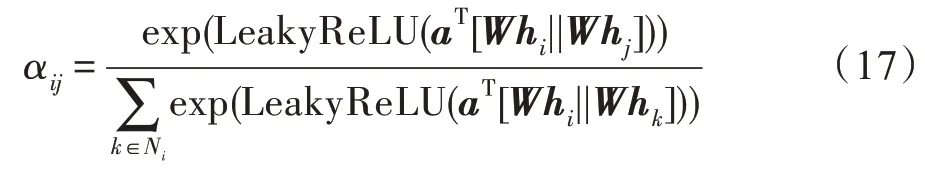
式中,是层间的权重矩阵,||表示拼接运算。最后,使用multi-head attention生成节点嵌入:

式中,表示激活函数,表示multi-head attention的头数,α为第个self-attention。注意力参数全图共享,大幅减少了参数占用的存储空间,同时GAT 对所有邻居节点进行采样,较GraphSAGE 得到的嵌入更具表征性。GAT 的缺点在于使用二阶以上邻居时,容易导致过度平滑。
用于图嵌入的GNN 模型大多遵循邻域聚合架构,通过递归地聚合和变换邻域节点的特征向量生成节点嵌入,因此不能有效区分某些简单的图结构。为了提高GNN 模型对图结构的辨识能力,图同构网络(graph isomorphism network,GIN)利用GNN 和WL(Weisfeiler-Lehman)图同构测试之间的密切联系,使生成的嵌入保留图结构辨识信息。WL 测试通过聚合给定节点邻居的特征向量对该节点进行迭代更新,同时使用内射聚合更新将不同的节点邻域映射为不同的特征向量。GIN 采用与WL 内射聚合相似的方式进行建模:首先,将节点邻居的特征向量抽象为一个多集;然后,将邻居聚合运算抽象为多集上的函数(多集函数的区分性越强,底层的表征能力就越强);最后,将生成的嵌入用于图分类任务,其性能可以匹配WL 测试的结果。
MF-GCN是一种多滤波GCN 模型(见图19),在每个传播层使用多个局部GCN 滤波器进行特征提取,使模型捕捉到节点特征的不同方面。对于第一层,MF-GCN 对节点属性进行如下操作:
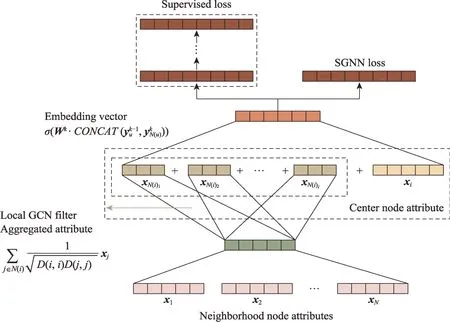
图19 MF-GCN 模型结构Fig.19 Framework of MF-GCN
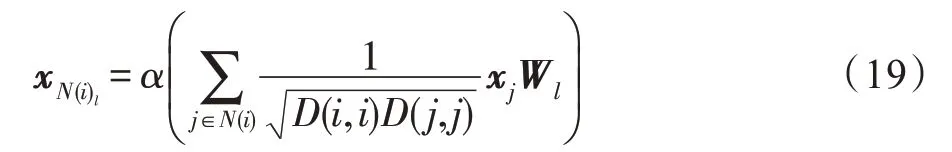

多数GCN 模型中邻域相互作用项的系数相对较小,导致性能与采用线性策略的简化图卷积网络(simplified graph convolutional networks,SGC)相当。为了有效捕捉图的复杂非线性,GraphAIR同时对邻域聚合和邻域交互进行建模。GraphAIR 由两部分组成:邻域聚合模块通过组合邻域特征来构建节点表示;邻域交互模块通过乘法运算显式建模邻域交互。现有的大多数GCN 模型与GraphAIR 兼容,可以提供即插即用的邻域聚合模块和邻域交互模块。此外,GraphAIR 利用残差学习策略,将邻域交互与邻域聚合分离,使模型更容易优化。
SDGNN是用于处理符号有向图的嵌入模型,其在传统GNN 的基础上考虑了平衡理论和地位理论,重新设计聚合器和损失函数。SDGNN聚合来自不同邻域的信息,并使用MLP(multilayer perceptron)将这些消息编码为节点嵌入。SDGNN 的聚合器可分为两类:一是平均聚合器,二是注意力聚合器。为了优化生成的嵌入,SDGNN 使用组合损失函数来重构网络中的符号、方向和三角形三个关键特征。平衡理论和地位理论的引入,使SDGNN 在考虑边缘符号的同时兼顾方向信息,提升了模型在符号图分析任务中的表现。
基于GNN 的动态图模型通常在静态图模型的基础上,引入一种循环机制更新网络参数,实现动态过程的建模,使生成低维嵌入可以有效保留图的动态演化信息。
DyRep将动态图嵌入假设为图的动态(拓扑演化)和图上的动态交织演化(节点间的活动)的中介过程。DyRep 采用关联和通信事件的形式接收动态信息,并基于以下原则捕获观察到的事件的影响,更新有关节点的表示:(1)自我传播。自我传播是支配单个节点演化的动力中最小的组成部分。节点相对于其先前位置在嵌入空间中演化,而不是以随机方式进化。(2)外源驱动。一些外力可以在某时间间隔平滑地更新该节点的当前特征。(3)局部嵌入传播。事件中涉及的两个节点形成临时(通信)或永久(关联)路径,用于信息从一个节点的邻域传播到另一个节点。DyRep 采用双时间尺度来捕捉图级和节点级的动态过程,计算节点表示并参数化。最后,使用时间注意机制耦合模型的结构和时间信息,使生成的节点嵌入可以捕获非线性的动态信息。DyRep 作为一种归纳式学习模型,强调学习节点的表示方法而不是节点的固定表示,因此更利于新的节点表示的生成。
DySAT通过邻域结构和时间两个维度的联合自注意力来计算节点嵌入,主体为三个模块(见图20):(1)结构注意力块通过自注意聚集和堆叠从每个节点局部邻域中提取特征,以计算每个快照的中间表示并输入到时间模块;(2)时间自注意力块通过嵌入每个快照的绝对时间位置来捕获排序信息,并将位置嵌入与结构注意力块的输出组合,输入到前馈层;(3)图上下文预测模块通过跨多个时间步长的目标函数保留节点的邻域信息,使生成的嵌入能够捕捉结构演化。DySAT 的优点在于使用多头注意力能够捕获动态性的多个方面,缺点在于该模型仅适用于节点数恒定的动态图,并且节点共现率作为损失函数导致模型捕捉节点的动态变化的能力有限。
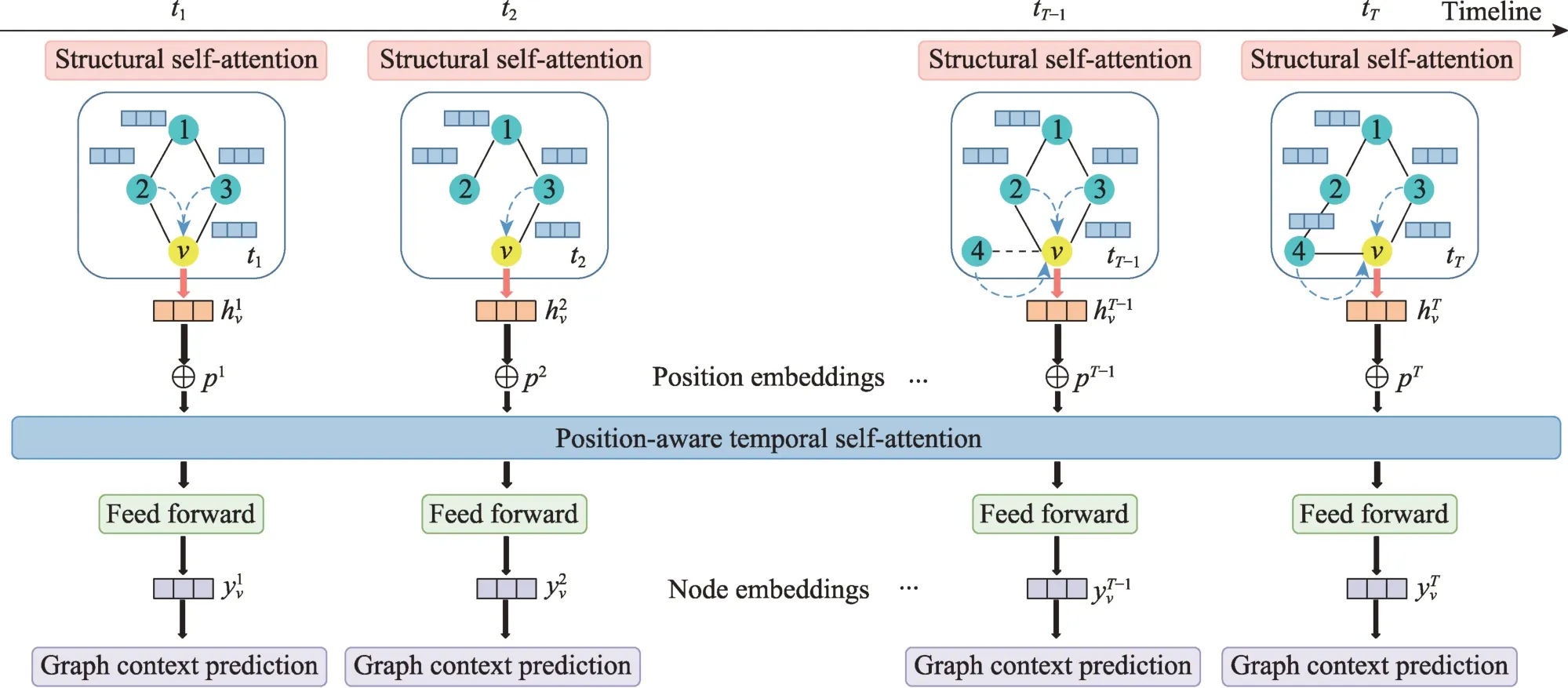
图20 DySAT 模型结构Fig.20 Framework of DySAT
动态图中节点可能频繁出现和消失,使得RNN在学习这种不规则的行为时非常具有挑战性。为了解决这个问题,EvolveGCN在每个时间步使用RNN 来调整GCN(即网络参数),即关注GCN 参数在每个时刻的演化而不关注该时刻的节点表示,这不仅提高了模型的自适应性和灵活性,还可以保持图的动态信息。此外,EvolveGCN 只对RNN 参数进行训练,不再训练GCN 参数,这种方式使得参数的数量不会随着时刻的增加而增长,使该模型像常用的RNN 一样易于管理。
在新的边出现时,DGNN不仅更新节点表示,同时将交互信息传播到其他受影响的节点,使嵌入信息在更新和传播过程中可以合并交互之间的时间间隔。当新的边出现时,两端节点及其一阶邻域都有明显的概率变化。此外,邻域受到的影响与时刻有关,最近时刻与端点交互的邻居节点对出现的新变化很敏感,而较远的过去时刻的邻居受影响较小。端点和一阶邻域均使用时态信息增强LSTM 作为更新模块的基本框架,使模型能够处理不同时间间隔的信息。
TemporalGAT通过集成GAT 和时间卷积网络(temporal convolutional network,TCN)来学习动态图上的嵌入表示(见图21)。该模型将self-attention应用于节点邻域,并通过TCN 保留图的动态信息。最后,采用二元交叉熵损失函数学习节点表示,并预测节点之间是否存在边。TemporalGAT 不仅能够建模节点数目不固定的动态图,还能同时捕获动态图的结构信息与时间信息。

图21 TemporalGAT 模型结构Fig.21 Framework of TemporalGAT
2.5 基于其他方法的图嵌入
LINE同样定义了一阶相似度和二阶相似度函数,并对其进行优化。一阶相似度用于保持邻接矩阵和嵌入表示的点积接近,二阶相似度用于保持上下文节点的相似性。为了结合一阶和二阶相似度,LINE 分别优化一阶和二阶相似度的目标函数,然后将生成的嵌入向量进行拼接。LINE 的边采样策略克服了随机梯度下降的局限性,使其能够应用到大规模图嵌入中;但是一阶和二阶表示单独优化以及简单的拼接操作,限制了模型表示能力。
DRNE没有重建邻接矩阵,而是直接使用LSTM 聚合邻域信息重建节点嵌入(见图22)。DRNE的目标函数如下:由于LSTM 要求其输入是一个序列,DRNE 根据节点的度数进行排序,同时对度数较大的节点采用邻域抽样技术,以防止过长的记忆。这种方法可以保持节点的正则等价性和多种中心性度量(如PageRank)。
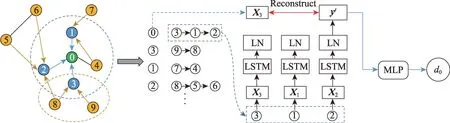
图22 DRNE 模型结构Fig.22 Framework of DRNE
Transformer架构已经成为许多领域的主流选择,但在图级预测任务中,通常表现不佳。为此,Ying等人在标准Transformer 的基础上利用图的结构信息构建Graphormer(见图23)。对于结构信息的编码主要分为三部分:(1)中心性编码(centrality encoding)用于捕捉图中节点的重要性,根据每个节点的度为每个节点分配一个可学习向量,并将其添加到输入层的节点特征中。(2)空间编码(spatial encoding)用于捕捉节点之间的结构关系,根据每个节点对的空间关系为其分配了一个可学习的嵌入。(3)边编码(edge encoding)用于捕捉边缘特征中额外的空间信息,然后将其输入到Transformer 层。Graphormer 同时使用上述结构信息编码,提升模型性能,进而生成更优的嵌入表示。

图23 Graphormer模型结构Fig.23 Framework of Graphormer
HTNE使用Hawkes 过程捕捉历史邻域对当前邻域的影响,建模动态图中节点的邻域序列。然后,将节点分别映射为基向量和历史向量,并输入到Hawkes 过程以生成嵌入表示。由于历史邻域对当前邻域形成的影响因节点而不同,引入注意力机制调节影响的大小。HTNE 的核心在于使用邻域的形成过程描述节点的动态演化,Hawkes 过程及注意力的引入使生成的嵌入有效集成到上述信息。
DynamicTriad通过施加三元组(一组三个顶点的集合)模拟图的动态变化。一般来说,三元组分为两种类型:闭合三元组和开放三元组。由开放三元组演化为封闭三元组的三元组闭合过程是动态图形成和演化的基本机制。DynamicTriad 采用统一的框架来量化上述闭合过程,使模型能够有效捕捉图的动态信息。
动态图通常是在微观和宏观两方面随时间演化,微观动态可以描述拓扑结构的形成过程,宏观动态描述了图规模的演化模式。MDNE是首个将微观动态和宏观动态同时融入到动态图嵌入过程的模型。对于微观动态,MDNE 把边的建立当作时间事件,并提出时间注意点流程来捕获用于嵌入生成的时间属性。对于宏观动态,MDNE 通过定义使用嵌入参数化的动态方程来捕获内在演化模式,再利用内在演化模式在更高层次上约束图的拓扑结构。最后,MDNE 利用微观动态和宏观动态的演化和交互,生成节点嵌入。微观动态描述的是网络结构的形成过程,宏观动态描述的是网络规模的演化模式。大多数动态图方法只考虑了微观动态,忽略了宏观动态在保持网络结构和演化模式方面的重要价值,MDNE 同时使用宏观动态和微观动态,进而增强了模型的泛化能力。
因果匿名游走(causal anonymous walks,CAW)与匿名游走(anonymous walks,AW)相比有两个不同性质:(1)因果关系提取。CAW 从感兴趣的链接开始,随着时间的推移回溯多个相邻链接,以编码动态图的基本因果关系。(2)基于集合的匿名化。CAW 删除遍历集合中的节点标识以保证归纳学习,同时根据特定位置出现的计数对相应节点标识进行编码。CAW-N 是专门用于链接预测的变体,该模型对两个感兴趣的节点进行CAW 采样,然后通过RNN 和集合池化对采样结果进行编码和聚合,生成最终嵌入。CAW-N 不仅保留了游走过程中所有细粒度的时间信息,还可以通过motif计数将其移除。
2.6 图嵌入模型关系分析
图嵌入可以解释为生成图数据的向量表示,用于洞察图的某种特性。表2 和表3 归纳了主要静态图嵌入和动态图嵌入的模型策略。基于矩阵分解的方法只有包含特定的目标函数,才能学习相应的图结构和信息。基于随机游走的方法可以通过改变参数来控制游走方式,还可以与其他模型叠加提升性能。基于AE 和GNN 的方法利用近似定理广泛建模,使模型能够同时学习节点属性、拓扑结构和节点标签等信息。
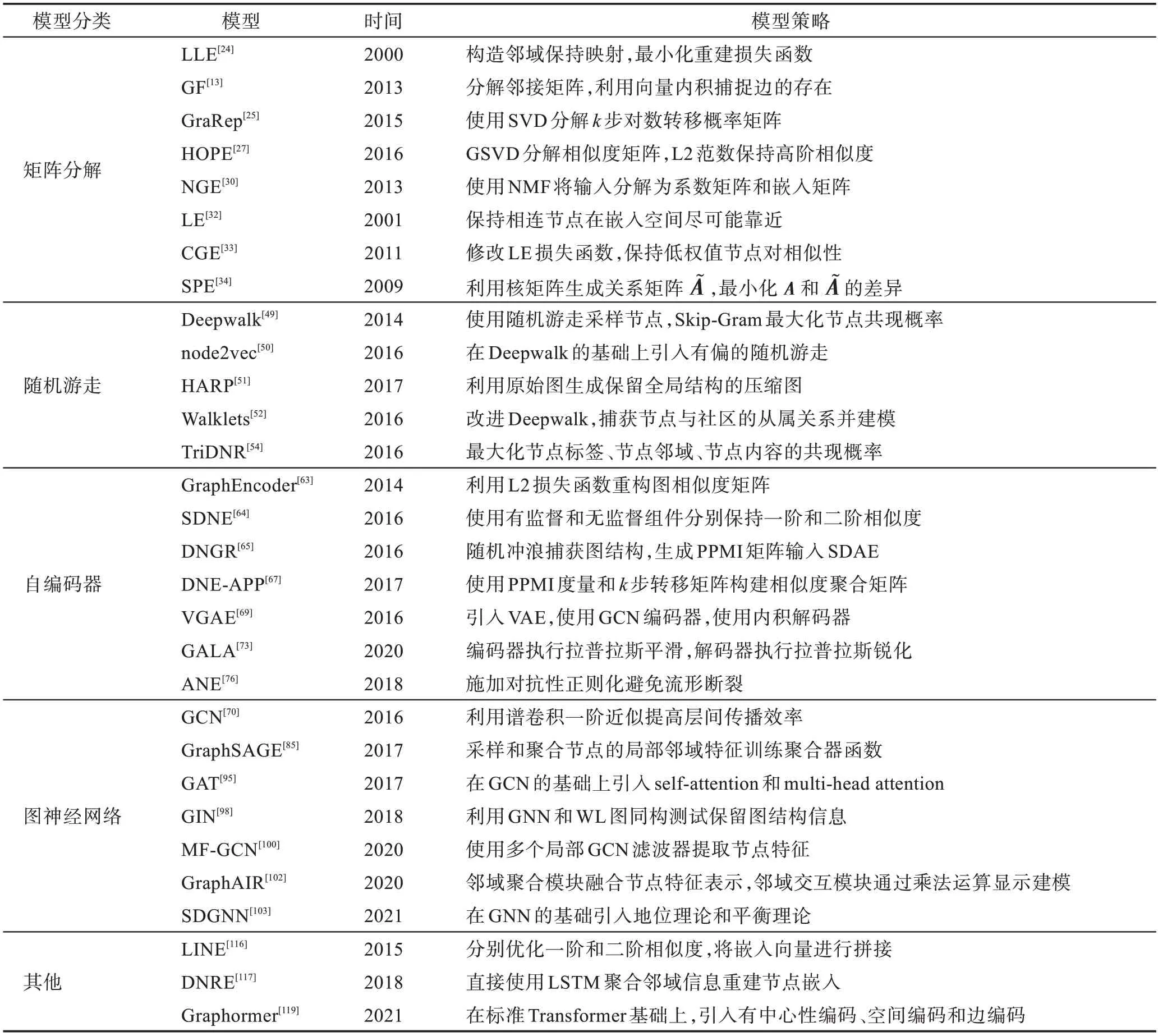
表2 静态图嵌入模型策略归纳Table 2 Strategies of static graph embedding
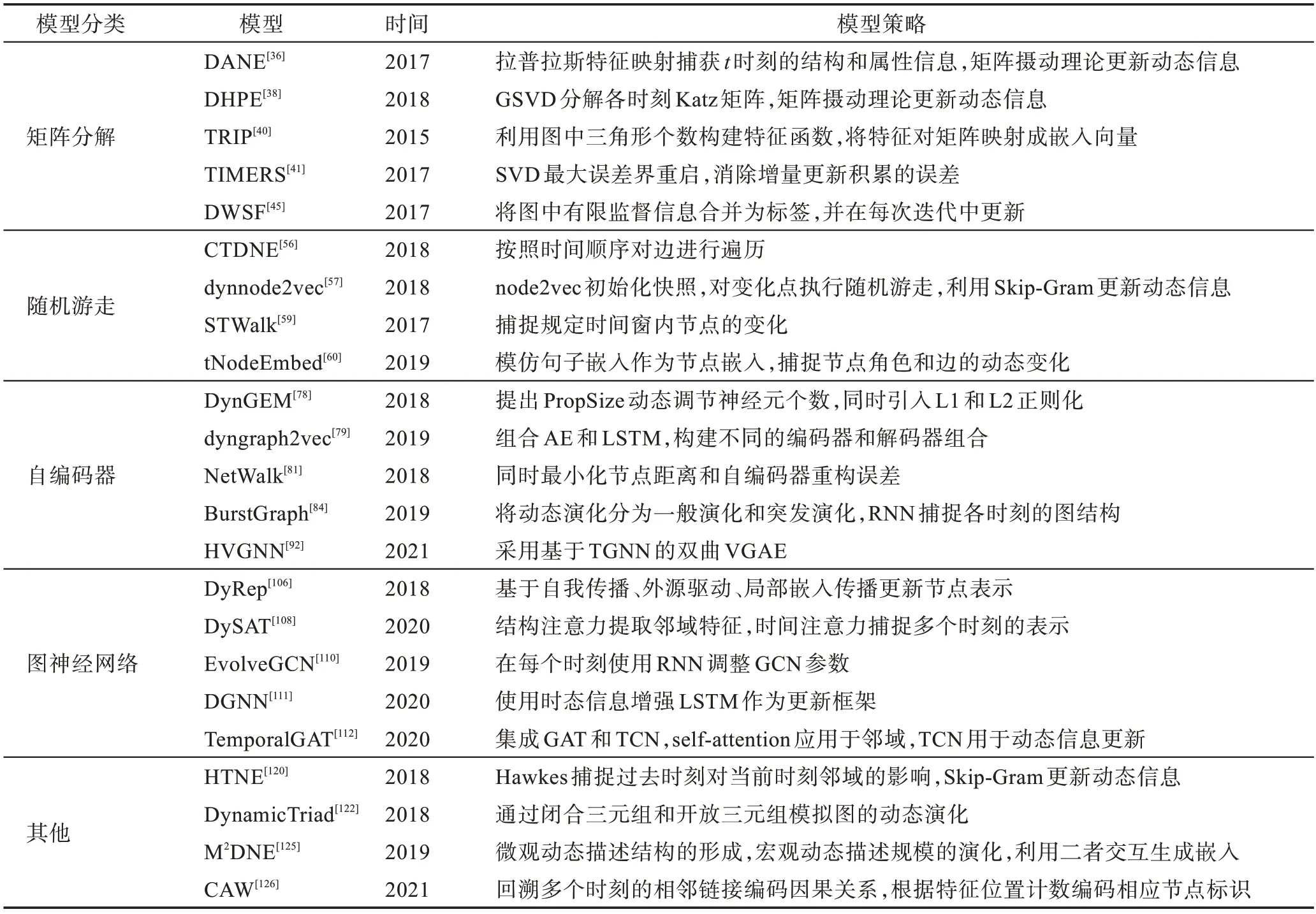
表3 动态图嵌入模型策略归纳Table 3 Strategies of dynamic graph embedding
图嵌入模型之间不是相互割裂的,而是存在理论依托关系:CGE 修改LE 的目标函数,进一步增强邻近节点相似性;DANE 离线模型采用类似LE 的方式保持各时刻快照的一阶相似度;DHPE 以HOPE 为基础,引入矩阵摄动理论更新动态信息;NGE、MF 和DWSF 以NMF 为基础;node2vec 在Deepwalk 的 基础上引入有偏的随机游走;HARP 通常与Deepwalk 或node2vec 结合使用;dynnode2vec 在node2vec 的基础上,使用Skip-Gram 更新动态信息;DNE-APP 在DNGR 基础上引入成对约束;VGAE 使用GCN 作为编码器;BurstGraph 使用GraphSAGE 进行采样;GAT在GCN 的基础上引入注意力机制;MF-GCN 以GraphSAGE为基础构建;GraphAIR 将GCN 和GAT作为组件;EvolveGCN使用RNN调整GCN参数;TemporalGAT 对GAT 和TCN 进行集成。
3 数据集与应用
本章将详细介绍常见图嵌入数据集和机器学习任务。表4 和表5 分别为常用静态图和动态图嵌入数据集的统计信息。

表4 静态图数据集统计信息Table 4 Statistics of static graph datasets

表5 动态图数据集统计信息Table 5 Statistics of dynamic graph datasets
3.1 数据集
20-Newsgroup:由大约20 000 个新闻组文档构成的数据集。这些文档根据主题划分成20 个组,每个文档表示为每个词的TF-IDF 分数向量,构建余弦相似图。为了证明聚类算法的稳健性,分别从3、6 和9 个不同的新闻组构建了3 个图,使用的缩写NG 是Newsgroup 的缩写。
Flickr:由照片分享网站Flickr 上的用户组成的网络。网络中的边指示用户之间的联系关系。标签指示用户的兴趣组(例如黑白色摄影)。
DBLP:引文网络数据集,每个顶点表示一个作者,从一个作者到另一个作者的参考文献数量由这两个作者之间的边权重来记录。标签上标明了研究人员发表研究成果的4 个领域。
YouTube:YouTube 视频分享网站用户之间的社交网络。标签代表了喜欢视频类型(例如动漫视频)的观众群体。
Wikipedia:网页共现网络,节点表示网页,边表示网页之间的超链接。Wikipedia数据集的TF-IDF矩阵是描述节点特征的文本信息,节点标签是网页的类别。
Cora、CiteSeer、Pubmed:标准的引文网络基准数据集,节点表示论文,边表示一篇论文对另一篇论文的引用。节点特征是论文的词袋表示,节点标签是论文的学术主题。
Yelp:本地商业评论和社交网站,用户可以提交对商家的评论,并与其他人交流。由于缺乏标签信息,该数据集常用于链接预测。
Epinions:产品评论网站数据集,基于评论的词袋模型生成节点属性,以用户评论的主要类别作为类别标签。该数据集有16 个时间戳。
Hep-th:高能物理理论会议研究人员的合作网络,原始数据集包含1993 年1 月至2003 年4 月期间高能物理理论会议的论文摘要。
AS(autonomous systems):由边界网关协议日志构建的用户通信网络。该数据集包含从1997 年11月8 日到2000 年1 月2 日的733 条通信记录,通常按照年份将这些记录划分为不同快照。
Enron:Enron 公司员工之间的电子邮件通信网络。该数据集包含1999 年1 月至2002 年7 月期间公司员工之间的电子邮件。
UCI:加州大学在线学生社区用户之间的通信网络。节点表示用户,用户之间的消息通信表示边缘。每条边携带的时间指示用户何时通信。
3.2 网络重构
网络重构任务是利用学习到节点低维向量表示重新构建原始图的拓扑结构,评估生成的嵌入保持图结构信息的能力。通过计算基于节点嵌入的内积或者相似性来预测节点间是否存在链接,使用前对顶点真实链接所占原始图中链接的比例来评估模型的重构表现。
网络重构任务通常分为3 个步骤:(1)使用图嵌入模型生成嵌入表示。(2)计算节点对应的重构邻近度并进行排序。(3)计算前对节点的真实链接的比例。
网络重构任务通常采用MAP(mean average precision)作为评价指标:

式中,@()是节点v的精度,Δ()=1 表示节点和之间存在连接。
好的网络嵌入方法能够捕捉到具有网络结构信息的嵌入表示,从而能够很好地重构网络。在Yelp数据集上,ANE 和LINE 的结果要好于仅利用一阶相似度的LE 和使用随机游走的Deepwalk。可见,表示局部结构的一阶相似性和表示全局结构的二阶相似性在保持网络结构方面都起着重要的作用。由于ANE 采用了对抗性训练,其表现略优于LINE。各模型网络重构性能见图24。

图24 网络重构性能对比Fig.24 Performance comparison of graph reconstruction
3.3 节点分类
节点分类任务是利用图的拓扑结构和节点特征确定每个节点所属类别。现实世界的图数据,可能不是完全标签化的,由于各种因素大部分节点的标签可能是未知的,节点分类任务可以利用已有标签节点和连接关系来推断丢失的标签。此外,节点分类任务可分为两类:多标签分类和多类分类。前者使用的数据集中每个节点仅由一个类别标签标记,后者则由多个类别标签标记。
节点分类任务通常分为3 个步骤:(1)使用图嵌入模型生成嵌入表示。(2)将包含标签信息的数据集划分为训练集和测试集。(3)在训练集上训练分类器,在测试集验证模型性能。常用的分类器包括逻辑回归分类器、最近邻分类器、支持向量机和朴素贝叶斯分类器等。
节点分类任务通常采用-1 和-1作为评价指标:
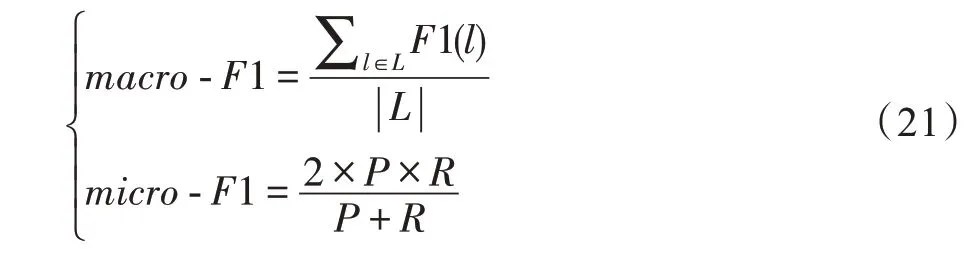
式中,1()是标签的1 分数,表示准确率,表示召回率。对于多分类任务准确度(Accuracy)与-1 的值相同。
利用网络结构和节点特征预测节点标签在网络分析中有着广泛的应用。通过将生成的嵌入作为节点特征对节点进行分类,可以比较各种嵌入方法在该任务中的有效性。
在CiteSeer 数据集上的静态图节点分类实验中,同时使用节点特征和网络拓扑结构的GNN 模型均取得了较好的结果,仅使用网络结构进行无监督学习的Deepwalk、node2vec 和LINE 模型性能较差。相较原始的GraphSAGE 模型,MF-GCN 使用多个局部GCN 滤波器进行特征提取,使模型捕捉到节点特征的不同方面,从而进一步提升了模型性能。同样突出的GraphAIR 模型分别对邻域聚合和邻域交互进行建模,与原始的GCN 和GAT 模型结合使用,提升基础模型的性能。各模型静态图节点分类性能见图25。

图25 静态图节点分类性能对比Fig.25 Performance comparison of static graph node classification
在引入时间信息的DBLP 数据集上的动态图节点分类实验中,与静态图嵌入模型(DeepWalk、node2vec、LINE 和SDNE)相比,DANE 保留的动态信息使生成的嵌入具有更强的表示能力;与动态图嵌入模型(tNodeEmbed、CTDNE、HTNE、DynamicTriad和MDNE)相比,DANE 捕捉了拓扑结构和节点属性特征的相关性,并保留图的动态信息,生成抗噪声的嵌入,从而提高结构嵌入的准确性。此外,由于DANE抗噪声的特性,使其有较好的鲁棒性。各模型动态图节点分类性能见表6。

表6 动态图节点分类性能对比Table 6 Performance comparison of dynamic graph node classification %
3.4 链接预测
链接预测任务用于预测两个节点之间是否存在边或者预测图中未观察到的链接,评估生成嵌入在保持拓扑结构方面的性能。
链接预测任务通常分为3 个步骤:(1)使用图嵌入模型生成嵌入表示。(2)对数据集中任意两个节点间的边信息进行标记,然后将数据集分为训练集和测试集。(3)在训练集上训练分类器,在测试集上进行链接预测实验。
链接预测任务通常采用AUC(area under the curve)和AP(average precision)作为评价指标:
AUC:把阈值设置在紧靠每个正例之下,计算负类的查全率,再取平均值。
AP:把阈值设置在紧靠每个正例之下,计算正类的查准率,再取平均值。
图嵌入可以显式或隐式地捕获网络的固有结构,以预测可能存在但未被观察到的连接关系。在CiteSeer 数据集上,GraphAIR(AIR-GAE)的性能优于其他基于GNN 和AE 的方法,Deepwalk 的表现最差。主要原因可能是链路预测任务通常使用成对解码器来计算两个节点之间链路的概率。例如,GAE和VGAE 假设两个节点之间存在边的概率与这两个节点的嵌入的点积成正比。AIR-GAE 通过两个节点嵌入相乘来显式地对邻域交互进行建模,这与链接预测任务有着内在的联系,进而提升了模型性能。各模型链接预测性能见表7。

表7 链接预测性能对比Table 7 Performance comparison of link prediction %
3.5 聚类
聚类任务采用无监督的方式将图划分为若干个社区,使属于同一社区的节点具有更多相似特性。在利用模型生成嵌入后,一般采用频谱聚类(非归一化谱聚类和归一化谱聚类)和-means等经典方法将节点嵌入聚类。
聚类任务通常采用归一化互信息(normalized mutual information,NMI)评估聚类性能:
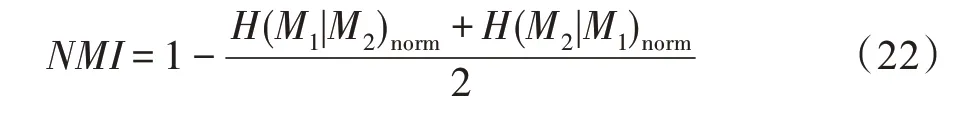
式中,用于度量和聚类结果之间的相似性,(·)表示信息熵。
将生成的嵌入表示进行聚类,使具有相似特性的节点尽可能在同一社区。在20-NewsGroup 数据集上,GraRep、LINE 和DNGR 模型在3NG、6NG 和9NG实验中性能明显优于其他基线算法。对于GraRep 和LINE,两种方法可以有效捕捉丰富的局部关系信息,从而提高了聚类结果。对于DNGR,使用的深度神经网络能够有效捕捉图的非线性,同时使用随机冲浪代替广泛使用的抽样方法加强了原始图中信息的提取。各模型聚类性能见图26。

图26 节点聚类性能对比Fig.26 Performance comparison of node clustering
3.6 异常检测
异常检测任务用于识别图中的“非正常”结构,通常包括异常节点检测、异常边缘检测和异常变化检测。常见的异常检测方法有两种:一是将原始图进行压缩,通过聚类和离群点检测识别压缩图中的异常;二是利用模型生成节点嵌入并分组为个社群,检测不属于已有社群的新节点或边。
异常检测任务通常采用AUC 作为评价指标。
图数据的异常检测主要是找出与正常数据集差异较大的离群点(异常点)。好的嵌入表示能够利用决策边界,有效界定正常点与异常点。在DBLP 和Hep-th 数据集上,Deepwalk、node2vec 和SDNE 的实验结果相近,而NetWalk明显优于上述方法。NetWalk模型的高性能得益于以下优点:(1)网络嵌入可以动态更新;(2)流式节点和边可以在存储空间恒定的情况下进行高效编码;(3)可以灵活地扩展到不同类型的网络;(4)可实时检测网络异常。各模型异常检测性能见图27。
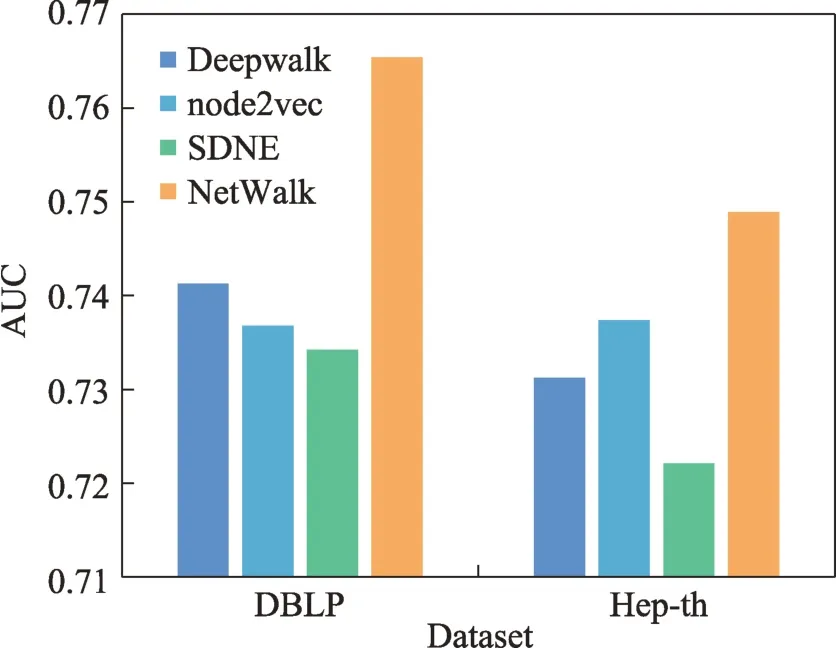
图27 异常检测性能对比Fig.27 Performance comparison of anomaly detection
3.7 可视化
可视化任务是对嵌入进行降维和可视化,从而直观地观察原始图中某些特征。可视化任务通常是在有标签数据集上进行的,不同标签的节点在二维空间中使用不同的颜色进行标记。由于嵌入中保留了原始图的某种信息,可视化结果直接反映了二维空间中同一社群节点具有更加相似的特征。
对于可视化任务,好的嵌入表示在二维图像中相同或相近的节点彼此接近,不同的节点彼此分离。在Cora 数据集上,将模型生成的低维嵌入输入到-SNE,使嵌入维数降至2,同一类别的节点使用相同的颜色表示。Yuan 等人比较了不同模型的可视化性能,部分可视化结果见图28。GCN 和GAT学习的节点向量能够有效捕捉到社区的结构,使同类型节点更为接近。Deepwalk 和SDNE 只使用邻接矩阵作为输入,没有充分利用节点特征和标签信息,导致模型性能较差,尤其是SDNE 模型,不同类型的点在二维空间中几乎是无序的。
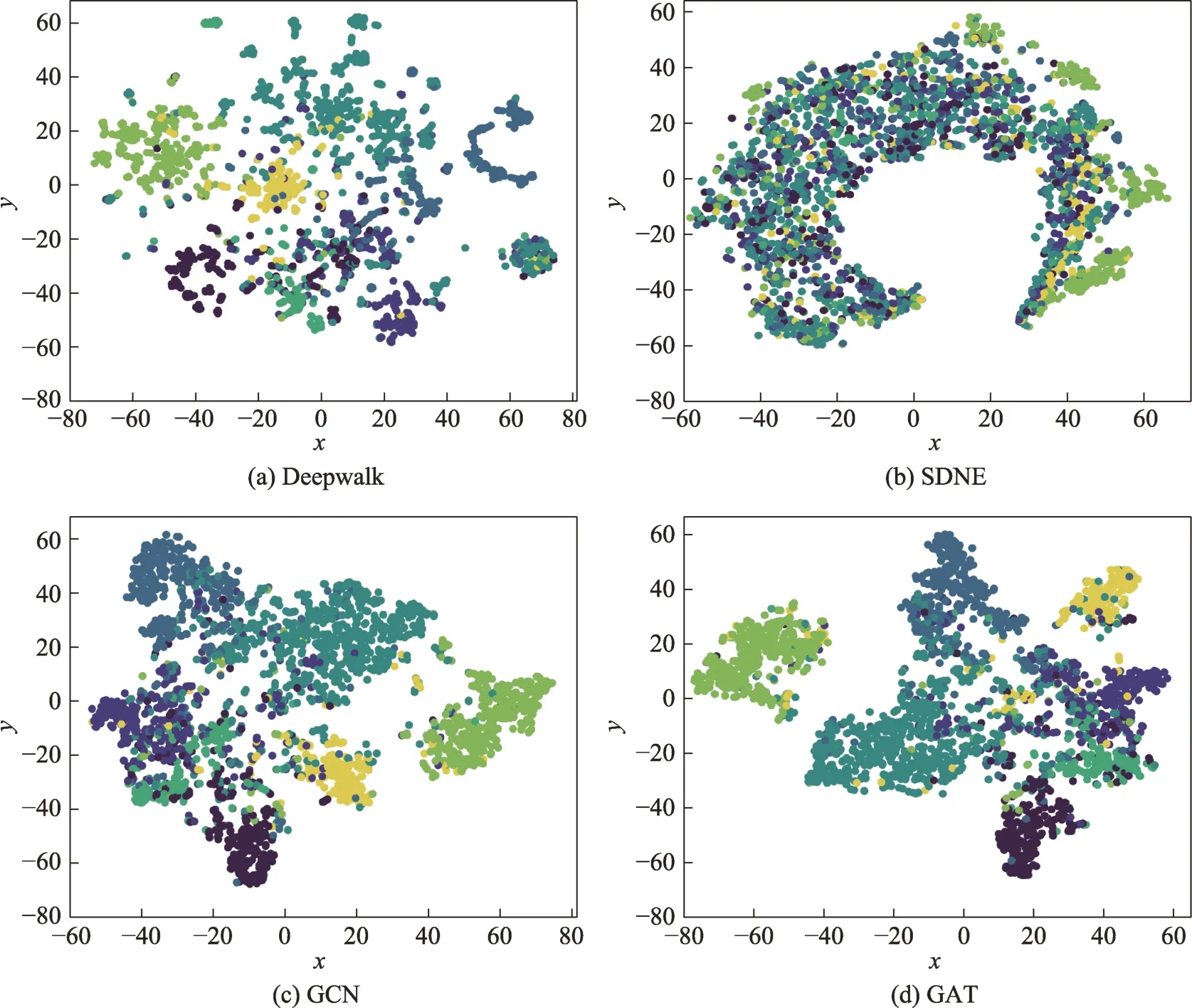
图28 不同模型的可视化结果Fig.28 Visualization of different models
4 未来研究方向
通过对传统和新型图嵌入方法的研究和分析,现阶段的主要任务依然是提升模型对大规模和复杂图数据的扩展性、创新模型方法和提高下游任务性能。据此,本章提出了未来工作的四个研究方向。
(1)面向大规模图数据的嵌入模型
对于大规模静态图嵌入,通常采用分布式计算或无监督学习的方式提高计算效率。开放图基准(open graph benchmark,OGB)是新兴图学习领域可扩展、可重复的基准,通过验证node2vec、LINE 和GraphSAGE 等实验表现,证明了模型的有效性。对于大规模动态图嵌入,现有模型无法采用类似静态图的方式实现图表示学习任务,因为动态图的规模不仅涉及图的大小,还涉及快照或时间戳的数量。因此,降低网络演化复杂度和提升模型性能是解决大规模动态图嵌入问题的两个重要方面。
(2)面向复杂图数据的嵌入模型
现阶段,大部分研究仍集中在简单的同质图上,如经典的GCN 模型只需邻接矩阵、节点特征矩阵和系数矩阵即可实现。然而,现实世界的网络往往更加复杂,如异质图、有向图和超图等。现有模型中,HGSL实现了异质图表示学习,SDGNN 实现了符号有向图表示学习,DANE 实现了属性图的表示学习。随着图表示学习研究的深入,探索更为复杂图数据的表示将仍旧是有前景的研究方向。
(3)改进模型训练策略
复杂的模型可以提升效果,但往往超参数较多且难以训练。相较于设计新的模型架构,一些研究者开始探索如何利用训练策略(如数据扩增)来提升现有模型的性能。GraphMix利用数据扩增技术,将简单的GCN 架构提升到先进基线模型的水平,并且无需额外的内存和计算消耗。现阶段,除了开发新的图嵌入模型外,充分挖掘已有模型潜力仍然是一项充满挑战的工作。
(4)面向特定任务的嵌入模型
大部分图嵌入模型生成的结果将用于节点分类、链接预测、可视化等多个任务。与上述建模思路不同,面向任务的嵌入模型只关注一个任务,并充分利用与该任务相关信息来训练模型。多数情况下,面向任务的嵌入模型在目标任务上比通用嵌入模型更有效,如Semi-AttentionAE采用集成学习的方法,联合训练GAT 与LE,提升节点分类任务性能。针对特定任务设计高性能模型同样是今后研究的热点方向。
5 结束语
本文对图嵌入文献进行了全面回顾,给出了图嵌入有关定义,提出了静态图和动态图模型通用的分类方法,对现有模型的核心策略以及静态图和动态图模型理论相关性进行了系统性分析。在应用部分,介绍了图嵌入常用数据集以及节点分类、链接预测等常见的机器学习任务,比较了不同模型的表现。最后,从图数据、模型策略和应用场景三方面提出了图嵌入领域四个未来有希望的研究方向。
