基于知识图谱的推荐算法研究
2021-12-30黄海新闫啸云
文 峰,曹 雄,黄海新,闫啸云
(1.沈阳理工大学 信息科学与工程学院,沈阳110159;2.中国石油大学 信息科学与工程学院,北京 102249)
推荐系统[1]像很多其他基于海量数据的任务一样受益于深度神经网络的发展[2-3],而知识图谱作为典型的图结构数据[4]包含着实体到实体之间的关系,这对用户的兴趣分析和建模具有一定的辅助作用。基于矩阵分解的协同过滤(Collaborative Filtering,CF)[5]是商业领域最成功的方法之一,然而,基于CF的方法依赖于用户和项目之间过去的交互,这将导致冷启动问题[6](不推荐没有交互的项目)。为缓解这一问题,研究人员通常会采取一些措施去整合辅助信息,比如社交网络、图片和评论等。
在众多种类的辅助信息中,知识图谱被广泛使用,其以机器可读的头-关系-尾(head-relation-tail)三元组形式组成并包含丰富的结构信息。研究人员先后利用知识图谱在节点分类、句子补全和摘要生成等应用中取得了成功。此后出现了基于知识图谱感知的推荐模型,其中许多都受益于图神经网络(Graph neural network,GNN)[7]捕捉图中的高阶结构并细化嵌入用户和项目的特征。如RippleNet传播用户在知识图谱中潜在的偏好并探索其更深层次的兴趣[8];图卷积网络(Knowledge Graph Convolutional Networks,KGCN)利用卷积操作来产生高阶的连通性的物品特征[9];图注意力网络(Knowledge graph attention network,KGAT)使用注意力机制隐式地为图中不同的邻域节点指定权重系数[10]。
由于推荐系统的高维和异质性,在推荐系统中使用知识图谱仍是一个挑战。一种可行的方法是通过知识图嵌入(Knowledge Graph Embedding,KGE)方法先行预处理知识图谱,该方法可将图谱中的实体和关系映射到低维向量表示。常用的KGE方法侧重于建模严格的语义相关性(如TransE模型假定头+关系=尾[11]),因此这类方法非常适合于图文应用领域,如知识图谱补全和链接预测。
本文在此基础上提出一种基于GNN和知识图谱嵌入模型TransE的推荐算法,先把相应的知识图谱信息通过KGE算法映射到高维的向量空间,再将图谱输入到相应的GNN之中;实验表明,更高维的语义信息可以提升神经网络的学习能力,使最后的推荐性能有所提升。
1 相关专业术语介绍
对于一个典型的推荐系统,用户u和物品v的集合通常表示为U={u1,u2,u3…}和V={v1,v2,v3…}。根据用户和物品的历史行为数据,可得到二者间的交互矩阵为Y={yuv|u∈U,v∈V}。如果一对用户和物品间存在关联(如点击、打分等),那么yuv=1;反之yuv=0。
对于用来提升推荐性能的知识图谱,用三元组集合G={(h,r,t)|h,t∈ε,r∈R}来表示,其中每个三元组(h,r,t)包含了知识图谱中的头节点h、尾节点t和二者相互之间的关系r。ε={e1,e2,e3…}表示所有的实体(包括头节点和尾节点)集合,R={r1,r2,r3…}为知识图谱中的关系集合。
一般来说,知识图谱中的实体有一些代表着物品v,而这些存在于知识图谱中的物品通常与多个实体有关联,所以把与物品v有关的实体集合表示为N(v),推荐系统可以在这个集合的基础上寻找到用户的潜在兴趣实体。最终的预测函数表示为
(1)
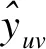
2 知识图谱嵌入模型TransE
为使推荐模型和知识图谱更好地融合,使用知识图谱嵌入模型先行处理知识图谱数据,得到语义信息更为丰富的向量;然后再将得到的相关嵌入向量输入到后续的GNN模型中。
传统的知识图谱一般使用本体语言表示,深度学习给予了一个更为明确的思路:用向量的方式来表示知识图谱。这种形式在需要进行的任务中,如预测、推理等,具有更强的可扩展性与可表达性。嵌入模型目标是把一对对三元组编码为低维的向量形式。知识图谱嵌入模型的目的是向低维向量空间中嵌入多关系数据的实体和关系,同时还能保留数据中的结构信息。
表示学习的目的是将需要表达的对象(知识图谱等)表达为机器可以理解的实值向量的形式。对于知识图谱,表示学习目标是图谱中的实体和关系,然后构建模型将实体和关系映射到低维向量空间中进行后续的推理或预测任务。TransE模型是表示学习的一个经典方法。
TransE模型属于翻译模型:其将实体和关系表示为同一空间中的向量,对于给定的三元组(h,r,t),模型将其中的关系r看成头节点h到尾节点t的平移向量,即h+r≈t;这种思想来自于词向量空间的平移不变性,TransE模型如图1所示。
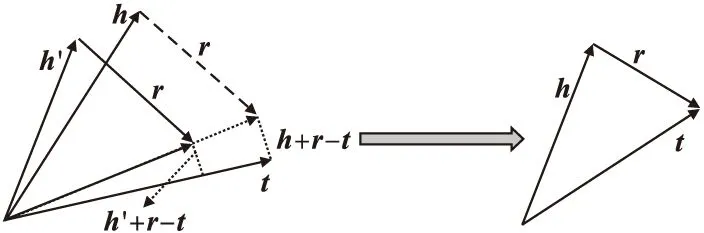
图1 TransE模型原理
在训练模型过程中,模型会不断调整其参数,使得知识图谱中的h+r-t的距离尽可能小。模型的优化目标为
(2)
式中:[x]+表示函数取值大于零时取值不变,小于零时则取零,这种函数一般称之为合页损失函数;γ为一个正确三元组与错误三元组之前的间隔修正,γ越大,两个三元组之前被修正的间隔就越大,则对向量的修正就越严格(一般都设置为1);d为h+r和t两个向量之间的距离,一般使用的是L1或L2范数;S为用来训练的三元组集合。模型的目标是让正确三元组之间的距离变小、错误三元组的距离变大;所以如果函数取值大于零,则表示需要对模型的参数进行调整,训练流程如表1所示。

表1 TransE算法整体流程
3 推荐模型
传统的推荐算法往往只学习潜在的用户和实体的表征,本文在更细粒度的层面利用知识图谱和GNN提取用户和实体的交互特征,通过该方法挖掘出用户更深层次的潜在兴趣。
模型在知识图谱上的采样步骤如图2所示。假设用户点击的物品为v1,以v1为中心向外扩散一个步长,将相关的实体放入一个集合N(v)中,然后根据集合中每个实体的嵌入特征将集合的所有特征聚合成一个向量,再以此特征为中心继续重复之前的步骤向外扩散。
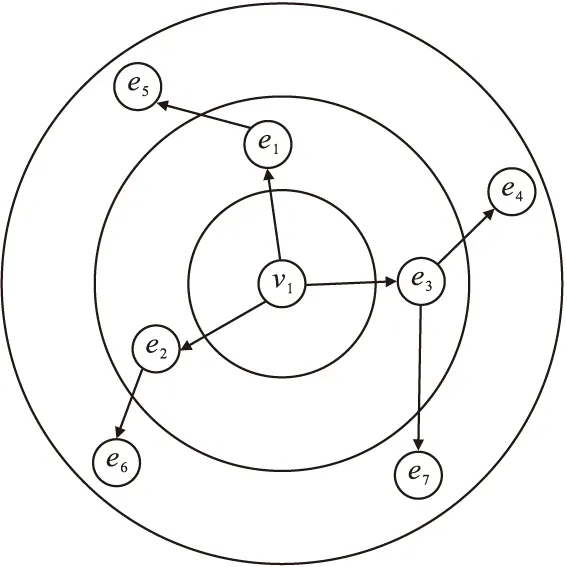
图2 采样步骤
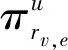
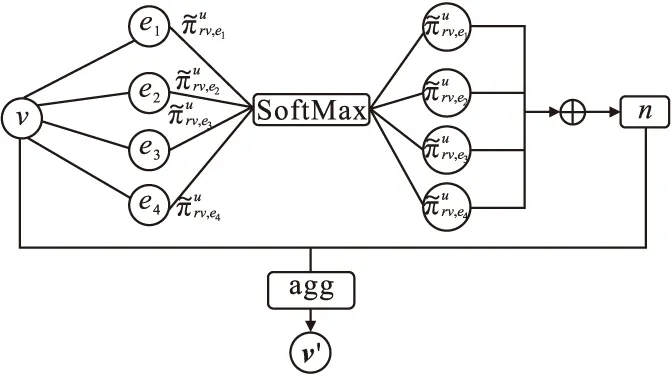
图3 GCN层结构图
(3)
式中wr和br皆为可训练参数。
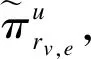
(4)
(5)
通过这种独特的关系注意力机制,能够将知识图谱和给出的用户、物品和关系信息进行融合并挖掘出用户更深层次的潜在兴趣。

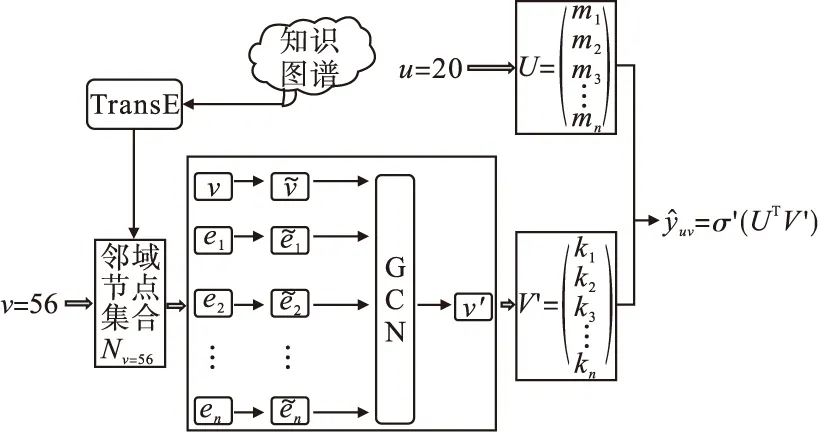
图4 算法整体流程图
4 学习算法
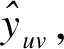
(6)
式中σ′为sigmoid函数。
对模型进行优化时使用的是交叉熵损失函数,同时还使用了负采样策略解决训练数据的正负样本失衡的情况。整体目标函数计算公式为
(7)
式中:£为交叉熵损失函数;p为对样本负采样的联合分布;Nu为对用户u采样的最终结果集,Nu=|{v:yuv=1}|。公式的第二项为L2正则化。
5 实验结果
本实验采用的是电影推荐领域最常用的数据集MovieLen,该数据集包含一百万个用户对电影的评分数据(评分在1~5之间)、2445部电影以及6036个用户。知识图谱来自于微软提供的开源的Satori数据库,通过相应的数据预处理,得到了适用于算法模型的120万条三元组数据、18万个实体及12种关系。
作为一个经典的点击率预测问题,实验中使用准确率(Accuracy,ACC)和曲线下面积(Area Under Curve,AUC)两个评价指标。ACC代表模型推荐的准确率,值越高说明模型性能越好。为克服样本不均衡问题,二分类问题常常把AUC也作为分类器的评价指标,其值越接近1代表分类器越优秀。
实验过程中先将数据集的评分进行二进制编码,阈值设置为4,即评分低于4的编码为0,其余的编码为1。同时根据模型在验证集上的表现不断调整模型的超参数,在向量的嵌入维度方面进行相关的对比实验,其它参数不变的情况下把维度d设置在2~64维之间(以2的幂指数增长)。在数据集上的AUC变化如图5所示。
由图5可以看出,随着d在2~8维之间的尺度逐渐增大,AUC也逐渐变大,因为嵌入的尺寸更大,编码的信息就更为丰富,但在8维之后性能开始下降,这可能是因为过拟合所致,因此实验中最终把嵌入维度设置为8。
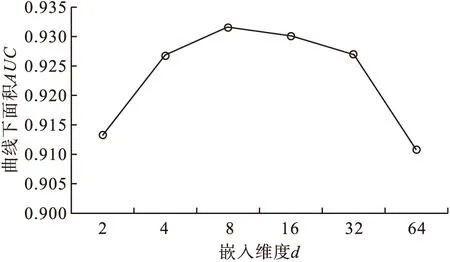
图5 嵌入维度d与AUC的关系曲线
本文在数据集上进行了对比实验,结果表明本文改进后的算法对比业界中表现良好的模型FM[12]、CKE[13]、RippleNet、KGCN取得了较好的结果。基于协同过滤的FM算法由于没有使用异构的知识图谱信息表现最差;基于正则化的CKE忽视了图谱的高阶连接性;虽然RippleNet和KGCN表现同样优异,但本文额外多出的KGE模块使得本文的算法相较于上述各算法在ACC的表现方面分别取得了2.3%、2.4%、1.2%、1.2%的提升,在AUC层面也分别获得了2.9%、2.3%、1.0%、1.6%的增益,具体实验结果对比如表2所示。
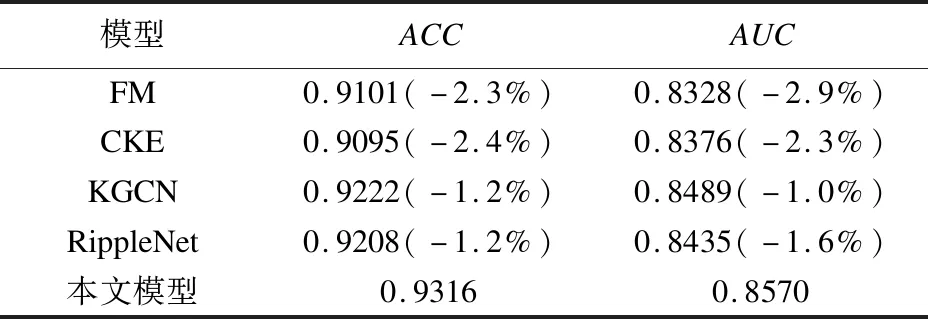
表2 实验结果对比
表中的百分数是其它模型对比本文模型结果获得的百分比增益。
6 结论
提出一种基于知识图谱嵌入模型TransE和图神经网络的推荐算法,通过知识图谱模型可以挖掘出用户更深层次的潜在兴趣,实验证明了该模型的优越性。该方法也可用于需要知识图谱结构性信息的领域,如社交网络或文本处理等。
