一种基于无监督集成学习的虚假评论检测方法
2021-12-30李慧,王琢
李 慧,王 琢
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
网络购物的虚假评论,不仅会误导消费者的购买决策,而且也会扰乱市场竞争秩序,损害其他经营者或消费者的合法权益。据调查[1],美国网站Yelp上虚假评论的比例已从2006年的5%涨至2013年的20%。
虚假评论问题由Jindal N等[2]在2008年美国纽约网络搜索与数据挖掘国际会议上首次提出。Ott M等[3]在2011年美国计算机语言协会第49届会议上强调标准数据集的重要性和困难性。
对虚假评论检测集成学习方法,王琢等[4]提出基于有监督学习的店铺类虚假评论检测,抽取店铺类评论的作弊特征,然后利用机器学习的算法,对店铺类虚假评论进行检测。张大鹏等[5]提出基于异质集成学习的虚假评论检测,通过特征提取,然后结合多个分类器分类,在此基础上选取效果较好的模型进行集成。由于虚假评论的多样性,还没有单一的检测模型可以检测出所有的垃圾评论[6],而集成模型的检测效果往往更好,且在相关领域的研究非常少。关于虚假评论检测,研究人员在手动标记参考评论数据集时经常采用投票的方式,如三名评估人员根据几个共同认可的证据为检测到的可疑评论人贴上标签[7]。另外,大多数虚假评论检测算法是通过人工调节找出一组最佳参数,从而得到最佳虚假评论排序列表;这种传统的调参方式既费时又费力,而且当数据集为无标签数据集时,无法判断出哪组参数得到的排序列表是最佳排序列表。因此本文提出一种基于排序的无监督集成方法,利用多个不同的虚假评论排序列表,以投票方式进行集成。通过本文提出的集成方法,可以对不同参数产生的排序列表进行集成,得出一个与被集成列表相比最优或较优的一个排序列表,省去了算法调参的麻烦。本文的集成方法可以在同一算法不同参数的排序列表间进行集成,也可以在不同算法的排序列表间进行集成。
1 模型的建立
1.1 问题形式化
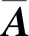
1.2 算法模型
该模型方法是一种基于无监督的集成方法,与其它虚假评论检测集成模型不同的是,本方法通过各个算法的虚假评论排序列表进行集成,在集成过程中不需要改变被集成排序列表中项目的排序顺序。
1.2.1 集成前准备
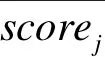
(1)
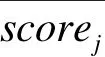
1.2.2 项目在不同算法中的权重rij
为准确估算出项目的排序位置,给每个排序列表中的所有项目都设置了权重。当一次迭代结束后,将会得到一个排序列表A*,这里可以用loc*j和locij的位置差做比较,如果|loc*j-locij|越小,说明项目vj在排序列表Ai中的排序位置和在排序列表A*中的排序位置越接近,那么项目vj在Ai中的权重较大,否则较小。最终,将得到一个N×P的项目权重矩阵。关于rij的计算,使用Sigmoid函数[8];Sigmoid函数是单调增函数,且可以将一个实数映射到(0,1)区间;因此通过变换Sigmoid函数,使0≤rij≤1,Sigmoid函数图像如图1所示。Sigmoid函数公式、rij公式分别为
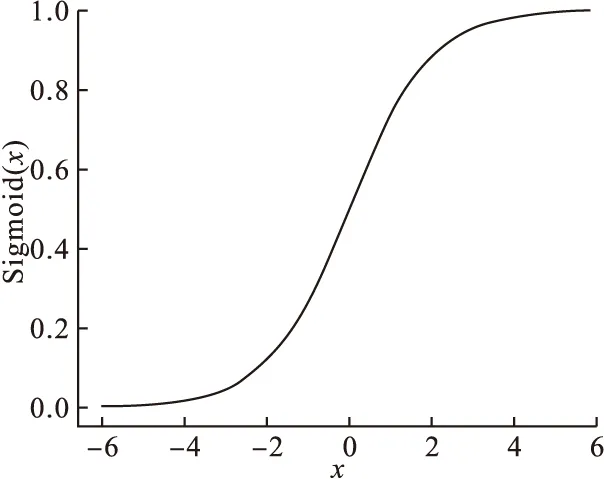
图1 Sigmoid函数图像
(2)
rij=(-2)(1/(1+e-|loc*j-locij|/σ)-1)
(3)
式中σ的取值可以通过|loc*j-locij|(1≤i≤P)的标准差计算。
1.2.3 项目作弊分数的计算方式
第二次迭代后作弊分数scorej计算公式为
(4)
式中:当rij=0.5时,项目在A*列表和Ai列表中的权重一样;当rij>0.5时,项目在A*列表中的权重小于项目在Ai列表中的权重;当rij<0.5时,项目在A*列表中的权重大于项目在Ai列表中的权重。该作弊分数分值越小说明项目的作弊概率越大。
根据项目的作弊分数scorej,重新对项目进行排序,得出新的排序列表A*,然后不断调整项目权重rij,更新A*和scorej,进行迭代直至收敛,停止迭代。
1.2.4 收敛条件(满足任一条件,迭代终止)
(1)当t+1次迭代和t次迭代的rij间的最大差小于阈值时,终止迭代。本实验中阈值eps设置为10-6,计算公式为
(5)
(2)当A*趋于稳定,迭代终止。计算公式为
(6)
(3)迭代次数大于预定的次数,终止迭代。
2 算法详细过程
算法过程如表1所示。

表1 算法过程

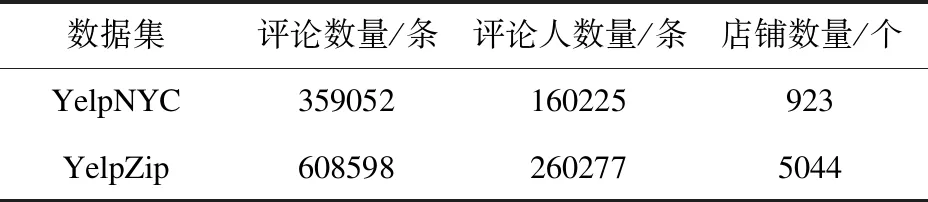
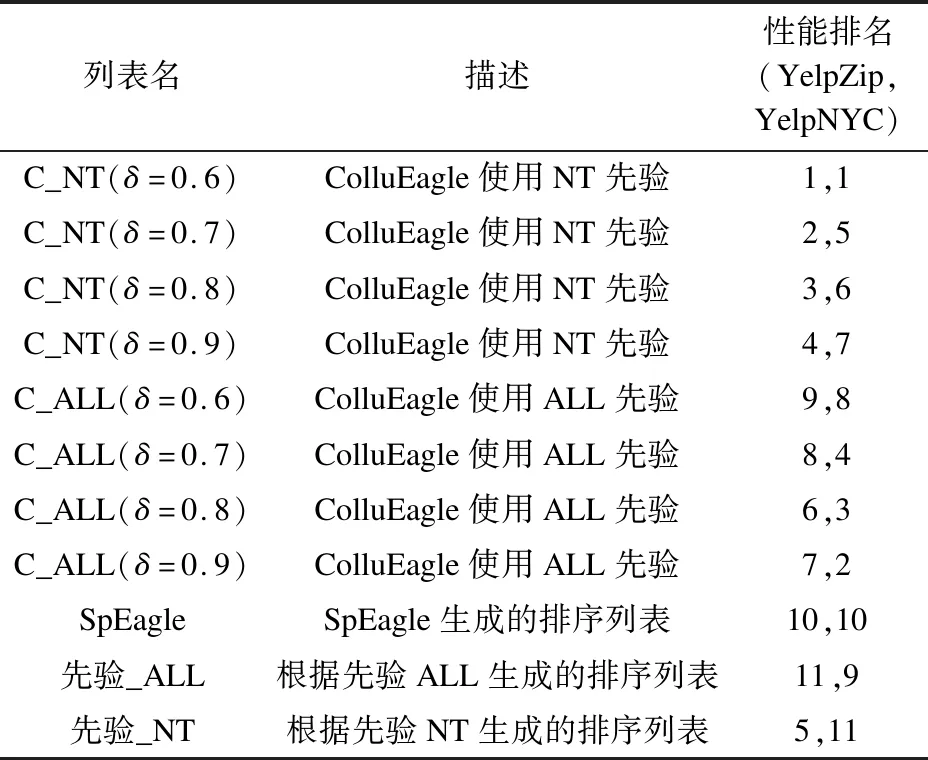
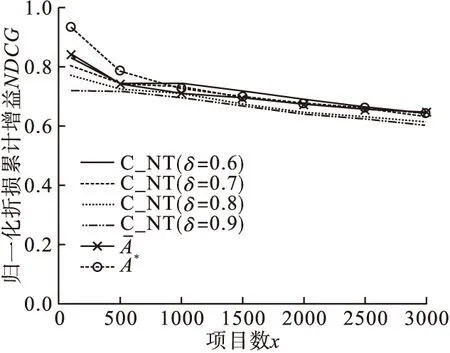
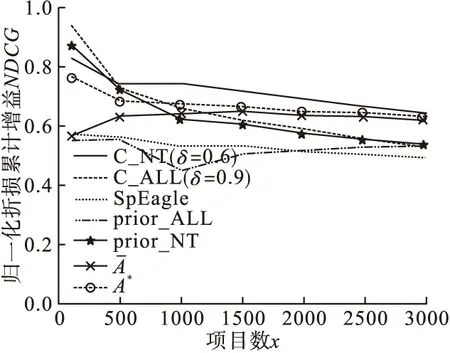
8:A∗= A;9:iter=1;10:while(iter 本文在两个有标注的数据集(YelpNYC和YelpZip)上分别做了2个实验,数据集信息如表2所示。 表2 数据集信息 实验1,用一个算法生成的虚假评论排序列表进行集成。该实验选择使用ColluEagle模型[9]。ColluEagle分为ALL先验和NT先验,分别对不同先验使用不同的最小相似度参数δ,得出对应的排序列表。实验1用到了由ColluEagle模型生成的排序列表,共8个。 实验2,用不同算法生成的虚假评论排序列表进行集成。该实验选择使用ColluEagle、SpEagle[10]模型生成的排序列表及根据ColluEagle中的ALL先验生成的排序列表和NT先验生成的排序列表。实验2用到了由所有模型生成的排序列表,共5个。 根据排序列表中前3000项目数的归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)衡量和评价搜索结果算法。对实验1和实验2用到的所有排序列表进行人工评估,并做性能排名。排序列表如表3所示。 表3 排序列表说明 图2 YelpZip数据集(实验1) 图3 YelpNYC数据集(实验1) 图4 YelpZip数据集(实验2) 图5 YelpNYC数据集(实验2) 通过实验可知,在没有标注数据的情况下,本集成算法会以较大概率得到较为理想的排序结果。 针对虚假评论检测缺乏有标注数据集问题,本文提出了一种基于无监督的多个排序列表的集成方法。实验证明,通过排序列表进行无监督集成的方法有效,但由于一些因素(每个被集成排序列表中的项目(评论/评论人)不一致数过多、每个被集成排序列表的排序质量差异问题、选取参与集成的项目数等)可能会对最终结果产生影响。期待将来能够进一步解决这些问题。3 实验结果评估
3.1 数据准备
3.2 实验及性能评估



4 结束语
