面向新浪微博的故事脉络生成系统
2021-12-20王崇伟赵旭剑
王崇伟 赵旭剑
(西南科技大学计算机科学与技术学院 四川绵阳 621010)
近年来,社交网络作为一种新型媒体迅速发展,其中代表性平台新浪微博成为了人们发现事件、传播事件的主要平台。与之对应的是爆炸式的微博量增长[1],这些数据带来了丰富的社会事件信息,也让用户难以从中发现感兴趣的事件。因此,从海量的微博数据中检测事件、构建故事脉络,可让用户清晰准确地了解事件的发展全貌。
为了推动故事脉络挖掘工作的研究,一些知名国际会议也逐渐出现了类似任务,如:TAC(Text Analysis Conference)从2014年开始有了事件追踪任务[2],ACL(Annual Meeting of the Association for Computational Linguistics)在2017年举办了第一届“新闻中的事件与故事”研讨会[3]。对于一些影响强烈的事件,百度百科、维基百科等网络百科全书也会构建一条故事记录,以展示事件的起因、经过和结果。可以看到,故事脉络构建在文本挖掘和信息挖掘领域越来越受关注。
目前,故事脉络生成的相关研究可分为以下三类:
(1)基于聚类算法利用相似度将事件聚类到不同的演化分支以构建故事脉络。例如Liu等[4]基于聚类提出合并、扩展、插入3种事件操作实现故事脉络生成;Hawwash等[5]把微博训练成事件向量,输入事件向量对事件进行聚类生成故事脉络。
(2)基于贝叶斯模型把故事脉络建模为事件特征的联合分布,然后推断链接事件。例如佘玉轩等[6]利用贝叶斯模型把故事脉络建模为日期、时间、机构、人物、地点、主题及关键词的联合分布。Zhou等一步步对贝叶斯模型改善,提出无监督贝叶斯模型[7]、动态故事脉络抽取模型[8]和第二代动态故事脉络抽取模型[9],得到更加完善的故事脉络。
(3)基于图算法首先将事件建模为图结构,然后利用图中的树生成算法直接构建故事脉络。例如文献[10-12]都将事件建模为图,基于有向斯坦纳树生成故事脉络;李莹莹等[13]在事件图中识别弱连通分量,为弱连通分量构造最大生成树得到故事脉络。
故事脉络生成系统主要存在两方面挑战,一是微博数据量庞大,并且微博转发特性带来大量冗余帖子,也导致时间发布存在延迟;二是微博数据内容短小稀疏,如何关联事件并呈现故事脉络。针对这两个问题,已有方法存在明显不足:聚类算法依赖丰富的事件内容,贝叶斯模型和图算法均耗费较高的时间复杂度,说明这些方法在微博数据中不具有普适性。
基于以上挑战,笔者把故事脉络不同的演化分支视为不同的事件簇,将事件建模为图结构,并利用图卷积网络对事件节点进行分类,构建故事脉络不同的演化分支,最后利用事件的时间信息生成故事脉络,设计了面向新浪微博的故事脉络生成系统,并在真实微博数据集上进行了实验验证。
1 系统结构及工作原理
故事脉络构建系统的核心在于微博检索、事件提取和事件链接。其中,微博检索模块独立于故事脉络生成系统,基于Scrapy爬虫框架,利用微博的“话题”标签,在新浪微博自带搜索引擎上,基于事件关键词有效捕获相关事件微博,并将数据以JSON格式存储到本地数据库中,在此不做过多赘述。
图1展示了故事脉络挖掘系统的总体架构。首先,用户通过查询接口在数据库检索相关事件;然后,系统经过事件提取模块提取相关事件,并将得到的事件集合输入事件链接模块;最后,经过模型学习将输出的事件簇链接起来得到故事脉络。

图1 系统总体架构Fig.1 Framework of system
1.1 事件提取
事件提取旨在对微博进行过滤分析,从中提取代表性事件。首先对微博进行预处理,包括微博切分、模糊时间补全和事件去重3个步骤,得到大致的事件集合;然后基于微博的传播特性对微博事件进行排序筛选,基于事件的传播度排名提取代表性事件。
1.1.1 预处理
微博切分:微博中每条完整的句子都能表示一种完整的事件信息,因此基于能够表达句子结尾意思的标点符号对微博帖子进行切分,考虑将每一个包含时间表达式的微博帖子视为一个事件,这些事件构成了最初的故事脉络事件集合。
模糊时间补全:事件最显著的特征是时间特征,但通过微博切分得到的事件中,往往存在诸如“5月28日”“29日”等不够准确的模糊时间表达式。对于模糊时间,提出一种顺序匹配的方法补全,包括以下步骤:(1)提取事件中的所有模糊时间表达式;(2)将原始微博发布时间作为基准时间;(3)用基准时间补全集合的下一个时间戳;(4)将新补全的时间戳作为新的基准时间;(5)重复以上步骤直到集合遍历完毕。
事件去重:由于微博的“社交”特性,转发将导致大量的冗余微博,使得事件集合将存在大量冗余事件并且导致信息泛滥。本文提出使用公共子串对事件集合进行冗余过滤,可以有效去除由转发带来的重复微博,由下式计算:
Sim(ei,ej)=Simsubstr(di,dj)
(1)
其中di和dj分别是事件ei和ej的原始文本。
1.1.2 代表性事件提取
经微博预处理得到了粗粒度的事件集合,但是故事脉络旨在直观清晰地展示故事脉络中事件的演化。因此,故事脉络中的事件需要能够反映事件发展的全过程。在社交网络中,社会事件在其中发酵传播,不同用户对事件传播具有不同的传播影响。
由此,考虑微博事件的传播影响力衡量事件是否为故事脉络中的代表性事件,并利用微博的发布者粉丝量以及转发、评论和点赞的数量来量化事件的传播影响力。具体来说,把微博的传播影响力定义为四元组S=
Score(ei)=∑wiSi
(2)
其中wi为S中不同元素的权重值,本文中w1取值为发布者粉丝数归一化值。此外,转发最能代表用户对微博帖子的认可,评论次之,点赞再次之,因此本文中三者权重取值为[w2,w3,w4]=[1.2,1.0,0.8]。由式(2)计算出每个事件的重要性得分后,依据得分对事件进行排序,删除排名靠后的事件,选取排名靠前的事件作为代表性事件。其中事件总数为M,代表性事件选取数量为N,且满足式(3)的条件:
(3)
即选取的前N个代表性事件满足其传播影响力总和恰好小于M个事件影响力总和的一半,这N个事件将作为事件链接阶段的输入。
1.2 事件链接
事件链接模块主要对事件进行细粒度分类,将包含强关联关系的事件分类到不同的事件簇,然后基于时间信息将事件链接。本文考虑基于事件相似性将事件建模为图结构,然后利用图卷积网络[14]进行事件关系学习,输出事件簇。
1.2.1 创建图结构
由于图能够表示事件间的复杂关系,因此首先将事件建模为图结构。具体来说,基于事件相似性建立了一个无向图G=(V,E),其中V表示事件节点集合,每个节点v∈V都包含事件信息,E表示边集合,每条边e=(v1,v2)∈E都表示两个事件节点间的相似性关系,其相似性权重由式(4)计算:
Edgeei,ej=αSim(ei,ej)+βSimsubstr(ei,ej)
(4)
α和β为权重比系数,且α+β=1。式中包括余弦相似度和基于最长公共子串的事件相似度。最长公共子串表示事件句子层面的一种相似性关系,而余弦相似性表示事件集合宏观层面的一种相似性关系,将两者结合能更有效地计算事件间关联关系,并建立事件图结构,加强图卷积网络模型在图上的学习能力。
建立图结构时,当两个事件间的相似性权重大于某个阈值λ1时,在两个事件构造一条无向边,边权重即为式(3)计算得到的相似性权重。相似性权重越大,表明事件关联关系越紧密。通过计算事件集合中两两事件间的相似性权重,得到事件图的邻接矩阵。
1.2.2 初始化事件簇
为避免故事脉络自动构建过程中的人为因素干扰,设计预聚类对事件进行初始簇学习,算法1展示了通过预聚类形成初始簇的过程,对于事件集合E={e1,e2,…,ei,…,en},首先将第一个事件e1作为第一个事件簇;然后计算事件e2和事件簇的相似度,当相似度小于阈值λ2时,将e2作为新的事件簇;接着,继续输入事件ei,计算事件ei和每一个事件簇的相似度,当相似度小于阈值λ2时,将ei作为新的事件簇;重复以上过程,直到输入的事件与每个事件簇的相似度都大于λ2。此时,得到由预聚类算法生成的初始事件簇。

算法 1: 初始事件簇生成输入: 事件集合 E={e1, e2,…ei,…en}输出: 初始事件簇 E={e1’, e2’,…ei’,…em’}step 1:S←{ }step 2:for i in E.size do // 将第一个事件作为第一个初始事件簇step 3:if S = null thenstep 4: S.add(E.get(i))step 5: E.remove(E.get(i))step 6:else // 遍历初始事件簇,计算相似度step 7: for j in S.size dostep 8: similar ← cos(E.get(i),S.get(j)) // 当相似度小于阈值时加入事件簇step 9: if similar < λ2 thenstep 10: S.add(E.get(i))step 11: E.remove(E.get(i)) //返回构建的初始事件簇step 12:return S
1.2.3 事件图卷积网络
图卷积网络[15](Graph Convolutional Network, GCN)是一种对图结构进行学习的半监督神经网络。由于社交网络中数据稀疏的问题,在衡量事件相似性时应考虑同一演化分支中的两个事件可能被第三个事件关联。具体来说,基于图的方法通过相似性将事件建模为图结构,但在图算法生成故事脉络的过程中,两个潜在相关事件的关联性可能会被第三个事件削弱。而基于图卷积网络的模型中,训练过程中节点间通过特征传递能够加强事件间的关联关系,因此可以得到更好的效果。
由此将预聚类得到的初始事件簇作为标签节点输入图卷积模型进行训练,并且事件节点特征被表示为事件文本的TF-IDF向量[16],和事件图的邻接矩阵共同作为图卷积网络模型输入。具体来说,建立了式(5)传播规则的两层图卷积网络模型,允许图中最远两个事件节点进行特征传递。
(5)
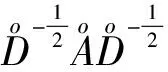
(6)
图2展示了图卷积网络模型架构,基于两层事件相似性关系,事件被建模为事件关系图结构,然后事件关系图的邻接矩阵和特征矩阵将作为模型输入,经过模型的多层网络学习,最终输出每个事件节点的事件簇分类结果。
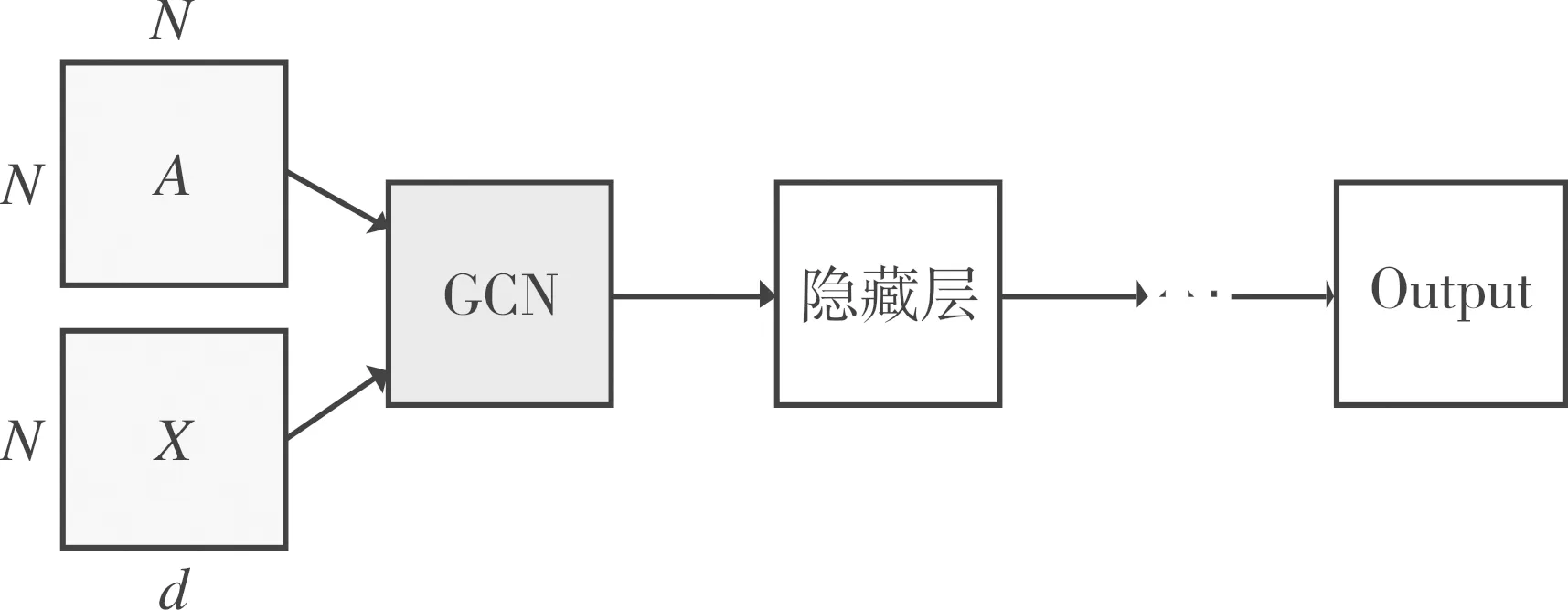
图2 事件图卷积网络模型架构Fig.2 Framework of event graph convolutional network
最后将模型输出的每个事件簇中的事件按照时间顺序进行链接,形成故事脉络中事件的不同演化分支,这些演化分支按照分支中首个事件的时序关系进行链接,得到最终的事件故事脉络。
2 实验及结果分析
2.1 结果分析
通过微博检索模块,基于新浪微博自带搜索工具(https://s.weibo.com/),本文搜集了真实社会事件“长春长生疫苗事件”的所有热门微博,该事件数据集时间跨度为2018年7月11日至2019年9月1日,共计73 614条热门微博帖子。将该微博数据集作为故事脉络挖掘系统的输入,图3展示了故事脉络挖掘系统生成的“长春长生疫苗事件”故事脉络示意图(局部),故事脉络生成系统快照如图4所示,共包含4个功能区域。
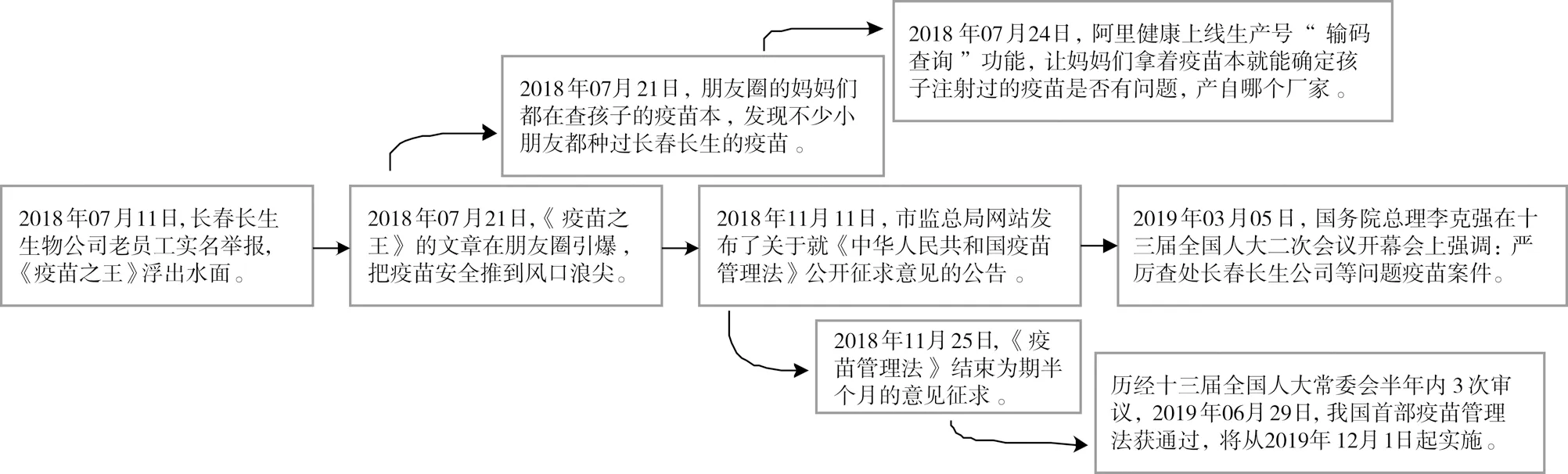
图3 故事脉络示意图Fig.3 Diagram of Storyline
图4区域1为故事脉络系统可视化结果,图中 “长春长生疫苗事件”故事脉络共13条演化分支;图4区域3为选中的演化分支的事件详情,例如图中展示演化分支为“疫苗管理法的诞生过程”;图4区域2为演化分支的核心词集合,图4区域4为核心词的分布细节,让用户准确把握该演化分支的主题方向。此外,用户能够在视图上方选择事件的起止时间。故事脉络生成系统还提供了一个查询接口,用户能够在搜索框对本地数据库中的相关事件进行检索。故事脉络视图中,可以通过点击不同的“Branch”演化分支按钮切换查看故事脉络中事件的演化分支。根据故事脉络的可视化结果,用户能够清晰准确地把握事件演化流程与演化方向,了解事件发展的全部进程。
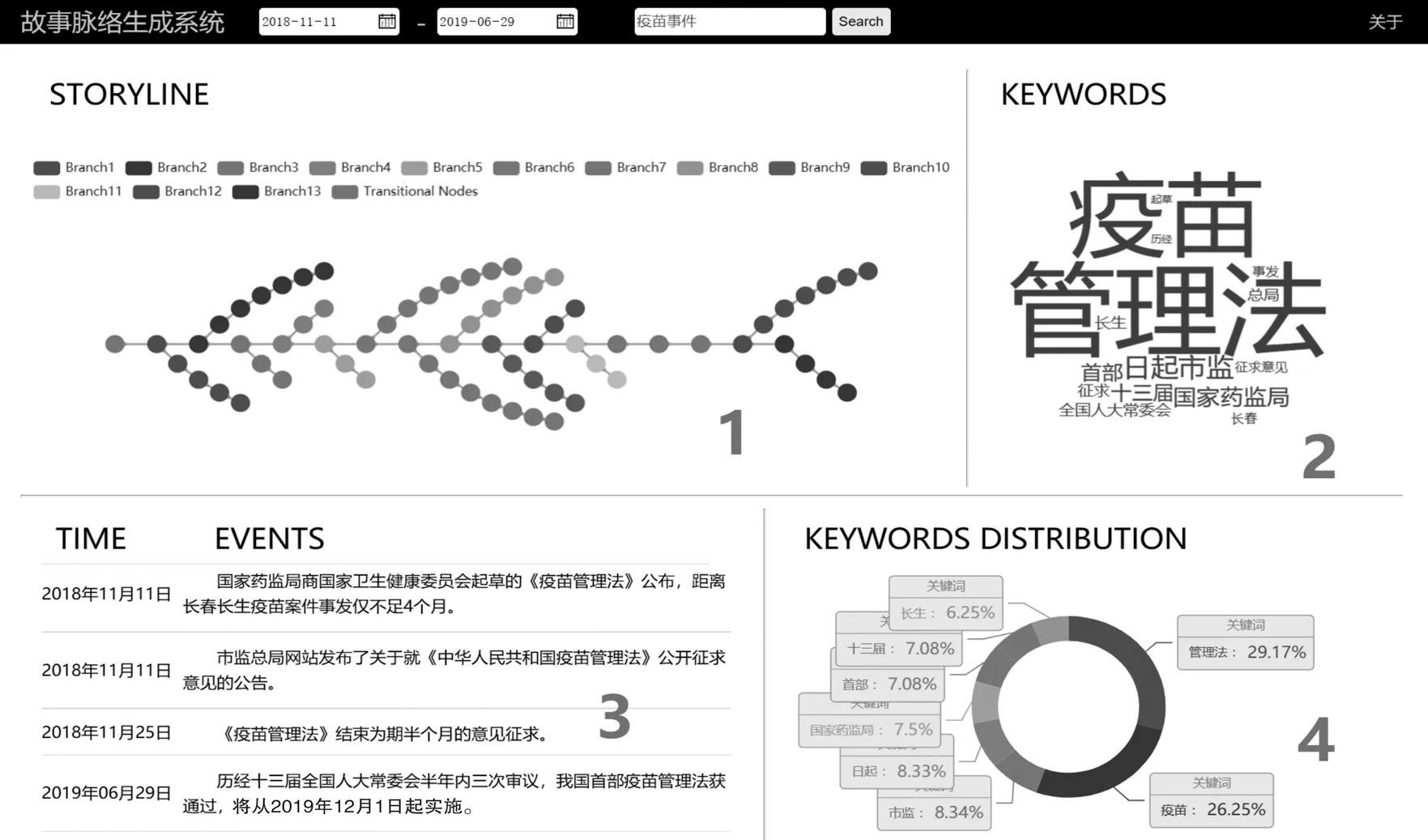
图4 系统快照Fig.4 System snapshot
2.2 用户评价
为了验证故事脉络挖掘系统的实际性能,将聚类算法[4]、贝叶斯模型[6]和基于图的方法[12]作为实验对照组,并基于逻辑性和可理解性两种评分标准评价系统性能。逻辑性指故事脉络中事件演化的逻辑关系,理解性指通过故事脉络用户是否能够清晰了解事件发展的全部过程。最后,随机邀请了10名评价人员,对不同方法构建的故事脉络进行打分(1~10分),用户评价的得分排名如表1所示。
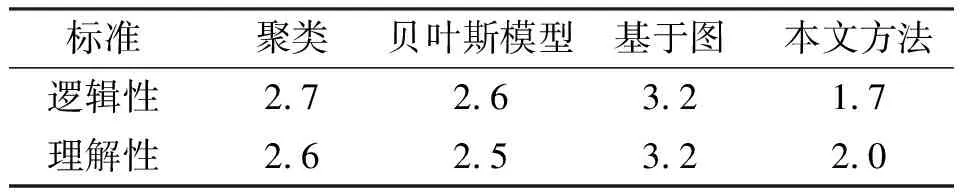
表1 基于用户体验的故事脉络评价(得分平均排名)Table 1 Story context evaluation based on user experience (average score ranking)
结果表明,本文方法生成的故事脉络在逻辑性和理解性上,平均排名均优于传统方法。通过对“长春长生疫苗事件”的真实挖掘分析,构建了疫苗事件故事脉络,能够帮助用户直观、准确地了解该事件的全部发展流程以及事件的演化方向,满足了用户需求,也避免了用户自己从繁杂琐碎的微博中了解事件的发展进程。
3 结束语
针对新浪微博信息爆炸式增长,用户难以准确把握其中社会事件发展的问题,本文提出基于新浪微博的故事脉络生成系统,该系统具有以下特点: (1)基于微博传播影响力能够准确提取微博中的代表性事件;(2)利用图卷积网络捕获事件间的复杂关联关系;(3)向用户提供可视化故事脉络及交互接口。实验验证了该系统在逻辑性、理解性方面优于聚类算法、贝叶斯模型和基于图的方法,能够使用户清晰地把握事件演化流程与演化方向,并轻松了解事件发展的全部进程。
此外,本文也存在以下不足:(1)微博检索模块独立于故事脉络构建模块之外,承担数据检索、匹配和储存的功能,这意味着用户目前只能从本地数据库中查看社会事件的故事脉络。未来工作中,将考虑将在线微博检索功能融入故事脉络构建中,支持用户能够在线检索社会事件,实时提取事件并构建故事脉络。(2)事件提取模块虽然能够有效提取事件,但未对事件时间分布进行分析,导致提取事件内容过于详细,影响故事脉络呈现效果。后续工作中,将考虑事件的时间特征,建立事件随时间演化的分布模型,提取更高质量的代表性事件。(3)事件链接模块利用图卷积网络虽然能够学习事件间复杂关系,但仍属于一种半监督学习模型,需要带标签数据。虽然本文提出用预聚类构造并形成初始事件簇作为模型中的带标签节点,但在实际应用中仍旧存在一些局限性。后续将探索一种更加精确的无监督方法来构建初始簇作为模型标签节点,避免自动故事脉络构建中的人为干扰。
