基于WOA优化神经网络的BOTDA传感信息提取
2021-12-18刘亚南余贶琭
刘亚南,郭 南,赵 阳,余贶琭
(1.北京交通大学信息科学研究所,北京 100044; 2.现代信息科学与网络技术北京市重点实验室,北京 100044;3.重庆大学光纤光子器件及系统研究室,重庆 400044; 4.中国长征火箭有限公司,北京 100070)
0 引 言
在过去的几十年里,基于布里渊散射的分布式光纤传感器得到了广泛的研究[1-3]。其中,布里渊光时域分析仪(Brillouin Optical Time Domain Analyzer, BOTDA)传感器系统已被广泛应用于分布式温度和应变传感,在结构健康监测、岩土工程等领域有着广泛的应用[4-6]。
传统方法通常采用洛伦兹曲线拟合(Lorentz Curve Fitting, LCF)和相关卷积等方法求取布里渊频移(Brillouin Frequency Shift, BFS)[7-8]。由于曲线拟合技术需要设置初始参数,同时噪声对准确性影响较大,另外采用LCF拟合处理BOTDA传感信号所需的时间相对较长,尤其是在较长的传感距离、高空间分辨率、测量振动信号等情况下,制约尤为明显[9-10]。
近年来,人工神经网络(Artificial Neural Network, ANN)被广泛应用在自然科学的不同领域中,ANN是受生物神经系统启发而产生的智能化数学模型[11],具有优秀的非线性映射能力。因此科研人员利用ANN可以提取BFS[12-13],即使采用较大的频率扫描步长来减少测量时间,ANN也能提供比LCF更好的测量精度。训练ANN经常使用的方法是反向传播法[14]或者反向传播与其他启发式算法相结合的衍生算法[15]。然而,原始基于梯度方法进行训练的ANN有2个主要缺点:容易陷入局部最优、收敛速度慢[16]。
为此,有科研人员提出进化算法和基于群体的算法等元启发式算法对ANN进行优化,以避免局部最优[17]。在基于群体的算法中,生成、进化和更新一些可能的随机解,直到找到满意的解或达到最大迭代次数。这些算法将随机性作为从局部搜索到全局搜索的主要机制,因此更适合于全局优化[18]。文献[19]提出了一种遗传算法(Genetic Algorithm, GA)与BP神经网络相结合的多峰布里渊散射谱特征提取方法,文献[20]使用了GA-QPSO算法。GA以BP神经网络中的权重与偏置为对象,利用选择、交叉和变异等遗传操作,得到合适的用于初始化BP网络的权重与偏置。GA使优化后的BP神经网络能够准确确定多峰布里渊散射谱中峰的数量和位置,并正确绘制连续多峰拟合曲线。文献[21]提出了基于广义回归神经网络(Generalized Regression Neural Network, GRNN)的曲线拟合方法,利用GA来确定GRNN的最优扩展常数。但是这类算法需要设置的控制参数较多,参数设置影响算法的收敛性,也关系着能否得到高质量的解。同时GA的搜索速度比较慢,要得到较精确的解需要的时间较长。目前在BOTDA系统中,除了使用GA来训练神经网络,有的还使用PSO(Particle Swarm Optimization),PSO是模拟鸟类捕食的群智能算法,通过将BP神经网络中随机产生的权重与偏置当作粒子,经过寻优以后,得到最优的用于初始化的权重与偏置组合,提高BP神经网络提取BFS的精度。但是PSO中由于粒子位置的更新方式比较单一,因此容易陷入局部最优,而使用GA进行求解时,存在需要设置的初始参数较多和搜索速度较慢的问题。因此本文使用了鲸鱼优化算法(Whale Optimization Algorithm, WOA)来训练神经网络,以此提高BOTDA系统传感信息提取的性能。
鲸鱼优化算法是一种新的元启发式算法,灵感来源于鲸鱼在捕食过程中的运动,在2016年由Mirjalili和Lewis提出[22]。使用WOA优化神经网络在不同的研究领域[23-25]中已得到应用。本文提出使用WOA来优化神经网络提取BOTDA中的BFS,并与常用的ANN,以及优化算法PSO和GA进行了比较。最后因标准WOA中收敛因子线性减小不符合实际需要,设计了新的非线性收敛因子,并提出了NWOA-NN网络。实验表明,使用WOA-NN提取的BFS精度优于ANN、PSO-NN和GA-NN,而改进后NWOA-NN进一步提升了RMSE等性能,并缩短了训练时间。
1 相关理论
1.1 鲸鱼优化算法

1.1.1 随机搜索猎物(全局探索)
研究人员发现,鲸鱼在捕食初始时会随机选择种群中的一条鲸鱼,跟随着其位置变换而更新自身的位置,进行随机的大范围搜索猎物(种群中其他鲸鱼的位置)。该阶段数学表达式如下:
D=|C·Xrand-Xi(t)|
(1)
Xi(t+1)=Xrand-A·D
(2)
式(1)表示种群中第i条鲸鱼与随机选取的鲸鱼之间的距离,其中t表示当前的迭代,Xrand表示第t次迭代中随机选取的鲸鱼的位置,Xi(t)表示第t次迭代中第i条鲸鱼的位置。A为控制因子,C为摆动因子,分别由以下的式(3)和式(4)计算得出:
A=2a·r1-a
(3)
C=2·r2
(4)
其中,r1与r2为[0,1]之间的随机数,a随着迭代次数的增加从2线性递减到0,由下式表示:
(5)
其中,tmax表示最大迭代次数。通过式(5)中a的线性减小来控制A的变化,在WOA算法中,当|A|>1的时候,鲸鱼进行随机搜索。
1.1.2 气泡捕食(局部开发)
在气泡捕食阶段,鲸鱼在收缩包围和螺旋捕食之间选择鲸鱼位置更新的方式,这2种捕食方式如下:
1)收缩包围。
在捕食过程中,鲸鱼首先需要观察猎物所在的位置才能对其进行包围,然而猎物在搜索空间中的位置通常是不可知的,因此在WOA中,通常假设当前种群中适应度最优的鲸鱼的位置为当前的最优解。种群中的其他鲸鱼将会根据当前最优解更新自身的位置。可描述为:
D=|C·X*(t)-Xi(t)|
(6)
Xi(t+1)=X*(t)-A·D
(7)
式(6)表示种群中的第i条鲸鱼与当前最优解之间的距离,X*(t)表示第t次迭代中的当前最优解。
2)螺旋捕食。
在本阶段,鲸鱼首先计算出自身到当前最优解之间的距离。使用螺旋方程,用来模拟鲸鱼以螺旋形姿势向上游动进行捕食的行为,即:
D′=|X*(t)-Xi(t)|
(8)
Xi(t+1)=D′·ebl·cos(2πl)+X*(t)
(9)
其中,b代表螺旋常数,一般取为1,l为[-1,1]之间的随机值。
鲸鱼在捕食过程中,是在一个缩短的圆圈内,沿着一条螺旋形的路径,同时围着猎物游来游去,因此包含了包围捕食和螺旋捕食2种机制。为了更好地模拟这种捕食行为,假设鲸鱼执行上述2种捕食行为的概率各为50%,即在优化过程中,鲸鱼有50%的概率可以选择包围捕食或螺旋捕食来更新位置,可表达为:
(10)
其中,p为[0,1]之间的随机数。
在WOA中,“探索”指的是鲸鱼在全局目标范围内搜索到食物的能力,即全局搜索能力。“开发”指的是当鲸鱼发现目标食物时不断逼近最终捕食的能力,即局部搜索能力。在全局探索猎物时,鲸鱼步长应该设置较大,这样发现猎物的可能性高;在局部开发时,其步长应该设置较小,有利于鲸鱼在猎物附近游走并最终到达猎物位置。设置太大或太小实际上都不利于算法整体搜索效率。因此,设计一个合理的收敛因子模型平衡算法的全局探索能力和局部开发能力,成为提高WOA搜索效率的关键因素,后文将进行探讨。
2 WOA-NN提取BOTDA传感信息
本章首先使用标准WOA对神经网络进行优化,随后针对在标准WOA中线性收敛因子a将算法中全局探索和局部开发过程分成相等的2个部分,使算法得到最优解的效果并非最优的问题,设计了新的非线性收敛因子a。
2.1 基于标准WOA的ANN(WOA-NN)
在本节中,本文以具有单个隐含层的BP神经网络为例说明如何使用WOA训练人工神经网络。
首先是WOA中搜索代理(个体)的设计,将一组连接输入层和隐含层的权重,一组连接隐含层和输出层的权重,以及一组偏置编码为一维向量,该一维向量代表一个候选的神经网络。其中每个向量的长度等于网络中权值和偏差的总数,可以用式(11)计算,其中n1是神经网络输入的数量,n2是隐含层中的神经元数量。
V=(n1n2)+(2n2)+1
(11)
为了评估生成的搜索代理的适应度,本文使用均方误差(MSE)作为适应度函数,该函数基于神经网络对所有训练样本的实际值和预测值的差。MSE可表示为:
(12)
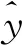
本文基于WOA训练BP神经网络用于BOTDA系统中的BFS提取的工作流程如下:
1)初始化。随机生成预定义数量的搜索代理。每个搜索代理代表一个可能的BP神经网络。
2)计算适应度。首先将搜索代理向量的权重和偏置分配给BP神经网络,输入布里渊增益谱(Brillouin Gain Spectrum, BGS)与相对应的BFS信息作为训练数据,得到网络的MSE作为该搜索代理的适应度。
3)使用WOA更新搜索代理。
重复步骤2到步骤3,直到达到最大迭代次数。最后得到最优搜索代理,即最优的权重与偏置组合。
2.2 基于非线性WOA的ANN(NWOA-NN)
根据上一节的内容,控制步长的收敛因子a是仅与迭代次数相关的线性递减函数,由于其步长在迭代次数范围内不可能为0,因此WOA在一定程度上相较于其他优化算法,例如PSO,可以克服陷入局部最小值的问题。
虽然该收敛因子模型能够有效避免算法陷入局部最优,但这种简单的线性递减策略有时并不能完全符合需要。由于收敛因子的规律性变化,将会导致鲸鱼初始阶段在全局搜索时,步长变化较小,导致全局探索能力不高。同时,在局部开发时需要精细搜索,但相对而言步长过大,不利于鲸鱼搜索到全局最优。
因此本文设计了新的非线性收敛因子a。根据标准WOA可知,收敛因子a必须满足:1)迭代开始时,a=2;2)迭代结束时,a=0;3)a在迭代过程中减小。在实际应用中,为了避免算法陷入局部最优,影响最终的收敛精度,因此在设计收敛因子a时应考虑:在迭代早期,a应该缓慢减小,这样即使迭代次数增加,在初始阶段依然能保持较大的步长,来保持较强的全局探索能力,避免陷入局部最优;在迭代后期基本确定最优解的搜索范围时,选择让a快速减小,这样较小的步长让算法具有较强的局部开发能力,有利于搜索到全局最优解。
由于任何函数都能被5个基本函数:幂函数、指数函数、对数函数、三角函数和反三角函数表示出来[26],因此假设所设计的非线性收敛因子a的函数表达式为:
g(x)=af(bx+c)+d
(13)
因此根据上述要求,非线性收敛因子a的函数表达式应满足如下要求:

(14)
经过多次实验比较,最终采用的非线性收敛因子a的数学表达式为:
(15)
2.3 基于WOA-NN和NWOA-NN提取BOTDA传感信息
本文基于WOA-NN和NWOA-NN提取BOTDA传感信息的算法分为3个部分:
1)确定参数。确定WOA-NN和NWOA-NN参数。
在设计实现WOA-NN和NWOA-NN时需要确定4个参数,分别为隐含层的数量、整个WOA-NN和NWOA-NN的训练函数、隐含层和输出层之间对应的传递函数、隐含层所包含神经元的数量。
2)网络训练。输入大量BOTDA频谱信息训练WOA-NN和NWOA-NN。
3)测试。利用训练好的权重和偏置的WOA-NN和NWOA-NN来对BOTDA测试数据进行测试,并获得传感信息。
综上,使用WOA和NWOA训练ANN用于BOTDA系统中的BFS信息提取的流程如图1所示。
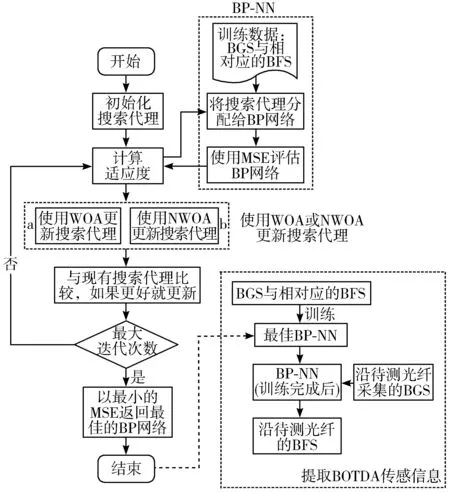
图1 基于(a)WOA和(b)NWOA的BP神经网络提取BOTDA传感信息的工作流程图
3 实 验
3.1 实验装置及数据
本文采用的实验装置与文献[12]相同。在实验中,使用了长41 km的单模光纤,光纤末端50 m放置到烤箱中,烤箱温度从室温(21 ℃),以步长为1 ℃,逐渐增加到50 ℃,扫频范围为10.75 GHz ~10.95 GHz,将实际采集到的BGS与相对应的BFS作为BP神经网络的训练集。在神经网络的构造过程中,本文采用trainlm作为网络的训练函数,隐含层的神经元采用logsig作为传递函数,而输出层的神经元采用purelin作为传递函数。对于每个频率扫描步长下的神经网络,输入层的神经元数目等于该频率扫描步长下获得的被测BGS中的扫描的频率数量,而输出层只有1个神经元代表相应的BFS信息。当频率扫描步长较小时(1 MHz、2 MHz、5 MHz),具有2个隐含层的神经网络的训练效果要比一个隐含层的神经网络的训练效果要好。因此,本文在1 MHz、2 MHz和5 MHz的扫频间隔中使用了具有2个隐含层的神经网络,在10 MHz和15 MHz的扫频间隔中使用了一个隐含层的神经网络。经过多次试验,最终确定了在1 MHz、2 MHz、5 MHz、10 MHz和15 MHz扫频间隔下的神经网络的输入层、隐含层、输出层的神经元的个数分别为:201-49-7-1、101-40-6-1、41-10-5-1、21-14-1和14-12-1。
在测试阶段,利用上述实验装置,将烤箱温度设置为60 ℃进行实验并采集BGS,扫频间隔分别为1 MHz、2 MHz、5 MHz、10 MHz和15 MHz,最后将采集到的BGS输入到对应扫频间隔的神经网络中,并直接提取BFS。此外,BP神经网络使用的训练集和测试集都未经过滤波处理
本文分别使用WOA和NWOA对神经网络进行优化,并将实验结果与BP-NN、PSO-NN和GA-NN进行比较。其中PSO-NN和GA-NN分别指使用PSO和GA得到最优的初始权重和偏置的BP-NN。表1是WOA、PSO以及GA的一些初始参数设置。

表1 算法的初始参数
3.2 实验结果及分析
根据文献[12],可以清楚地知道使用ANN可以在不同的扫频间隔下直接提取410 m待测光纤的BFS信息分布,其中末端50 m被加热到60 ℃,如图2(a)所示。但是ANN容易陷入局部最优,训练时间较长;通过采用元启发式算法对ANN进行优化,能在一定程度上避免陷入局部最优,图2(b)~图2(e)分别代表采用PSO、GA、WOA和NWOA优化后的ANN所提取的BFS曲线,图2(a)~图2(e)中的插图为最后100 m的BFS细节。图2的作用在于展示不同方法提取BFS的效果,由于图中曲线过于密集,因此无法在曲线上加入不同的描点标记进行区分。该图为黑白印刷时可能无法有效分辨图中的曲线,并不影响得出最终结论。图中放大部分的曲线从上到下分别为15 MHz、10 MHz、5 MHz、2 MHz、1 MHz。
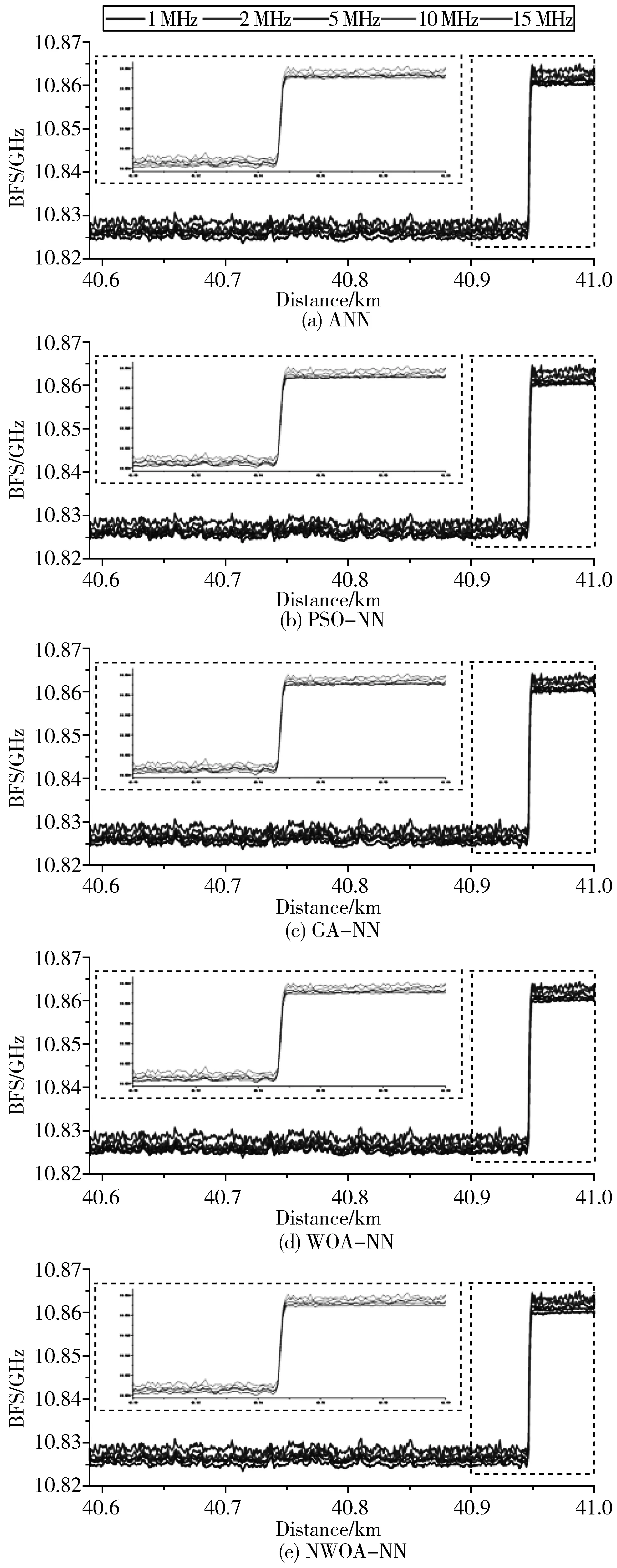
图2 提取沿41 km光纤最后410 m的BFS曲线,其中末端50 m被加热到60 ℃
下面分别从均方根误差(Root Mean Square Error, RMSE)、标准偏差(Standard Deviation, SD)、网络训练时间和优化时间4个方面来更直观地评估上述方法提取BFS信息的性能。
3.2.1 均方根误差
通过使用BFS与温度之间的关系公式,将提取的BFS转换为温度,并与实际温度进行比较,分别得到上述5种方法测量温度的RMSE(℃),结果如图3所示。在不同扫频间隔下,NWOA-NN所获得的RMSE均最小,其中在1 MHz下使用NWOA-NN的RMSE与ANN在10 MHz下的RMSE几乎相等,这意味着使用NWOA-NN提取的温度信息更接近实际温度,提取精度更高。

图3 在不同扫频间隔下,分别使用WOA-NN、ANN、PSO-NN、GA-NN以及NWOA-NN测量温度的RMSE(℃)
3.2.2 标准差
图4是在不同扫频间隔下,在加热段提取的温度信息的SD。可以看出,在小频率扫描间隔下,上述5种方法之间的性能相差不大,而对于比较大的扫频间隔(>5 MHz),WOA-NN的SD要小于单纯使用ANN获取的温度信息的SD,并且小于PSO-NN和GA-NN。NWOA因为使用了非线性收敛因子,相对于WOA更容易避免陷入局部最优。实验证明NWOA-NN提取温度的SD的确更优于WOA-NN。
图4 在不同扫频间隔下,分别使用WOA-NN、ANN、PSO-NN、GA-NN以及NWOA-NN所获得温度的SD(℃)
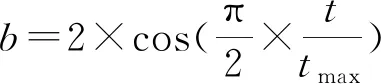
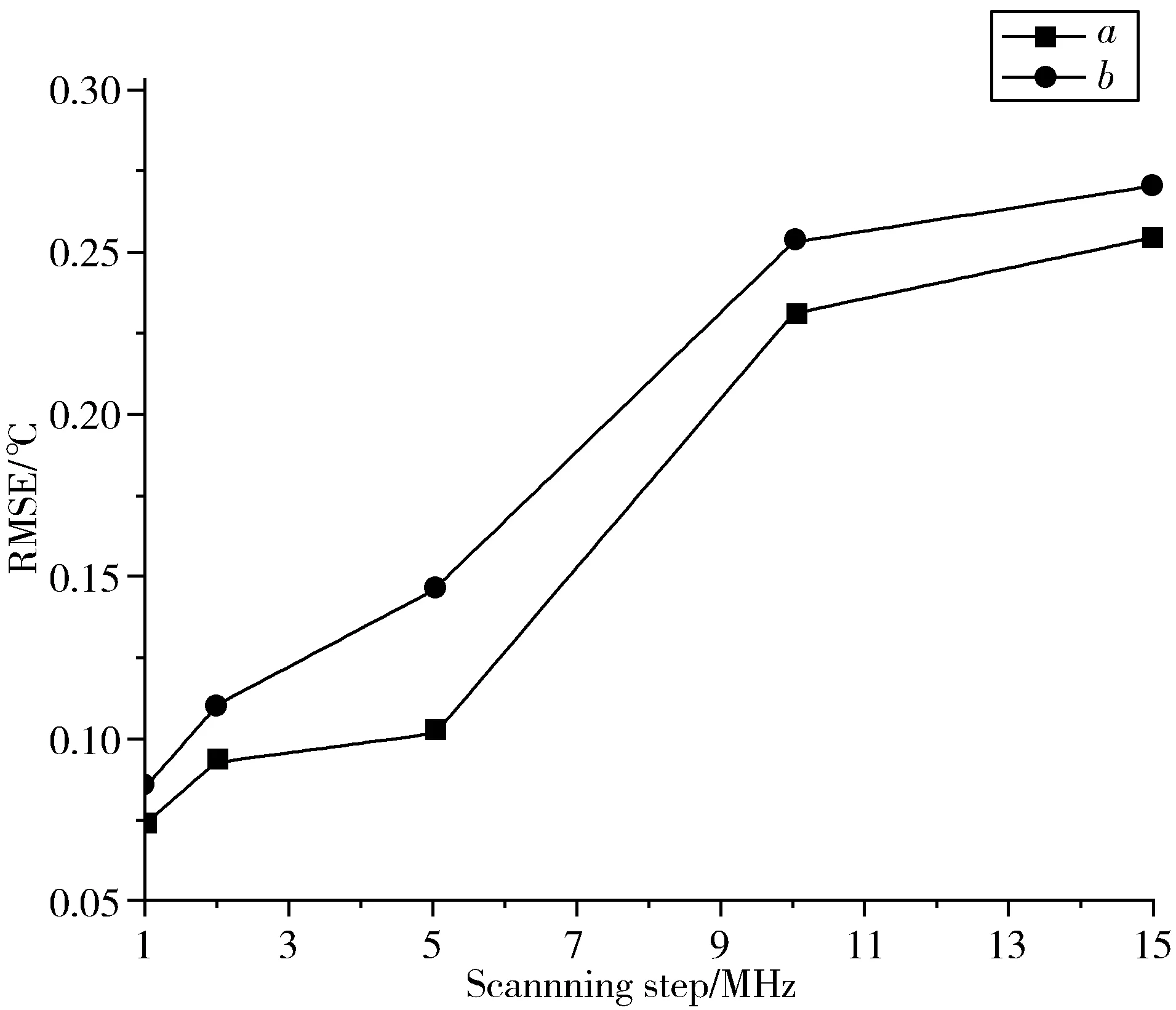
图5 在不同扫频间隔下,使用不同a的NWOA-NN测量温度的RMSE(℃)
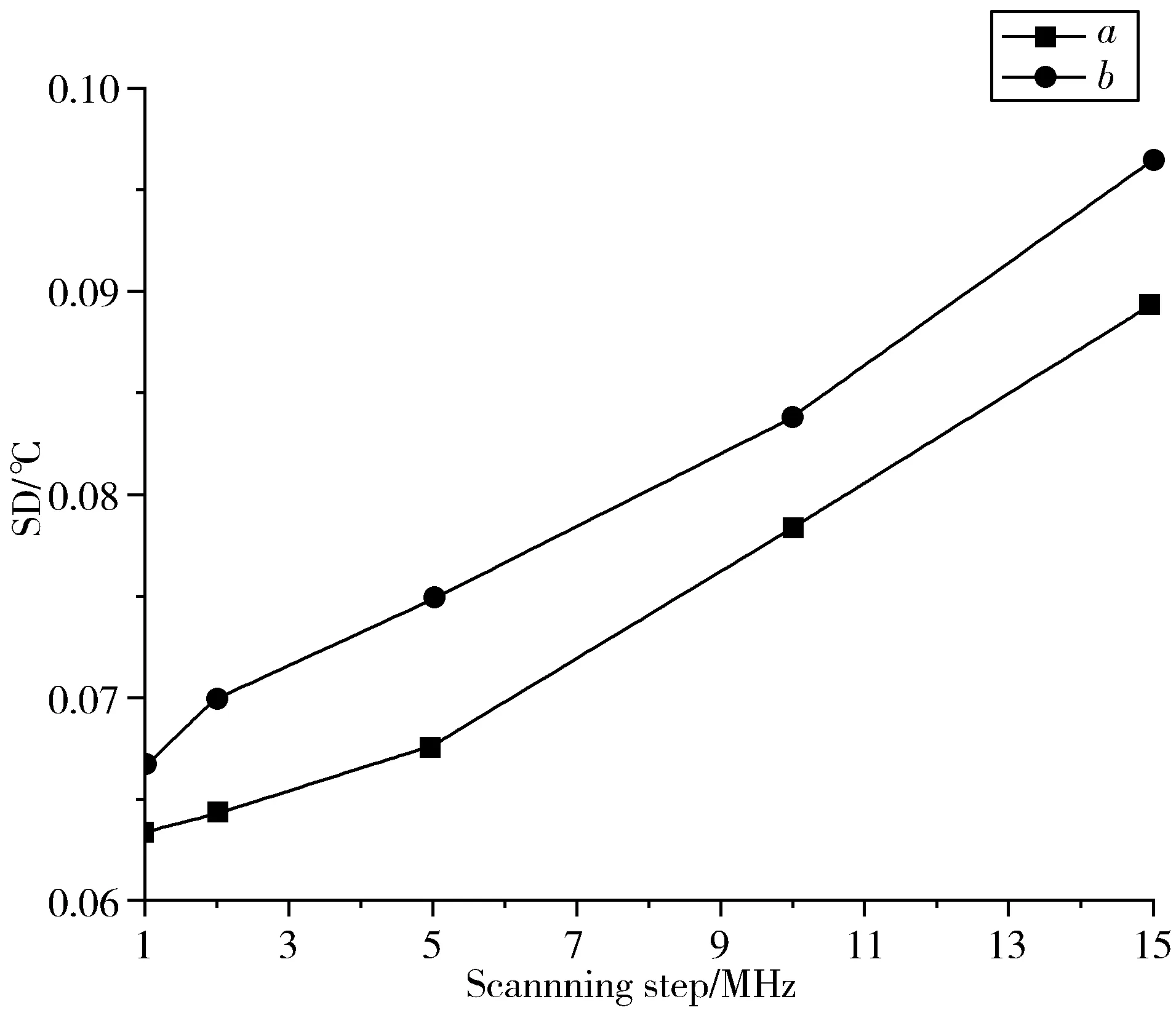
图6 在不同扫频间隔下,使用不同a的NWOA-NN测量温度的SD(℃)
3.2.3 训练时间和优化时间
最后,本文比较了上述5种方法训练网络所需时间(不包含优化算法优化网络所花费的时间),如表2所示。
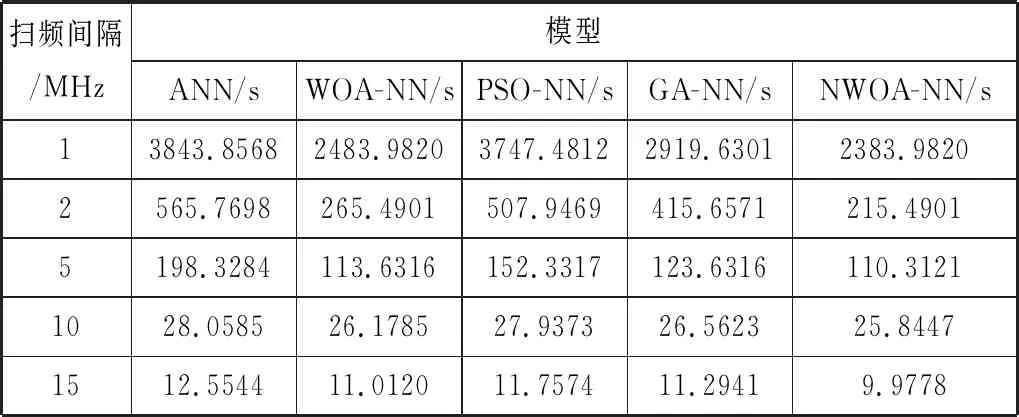
表2 WOA-NN、ANN、PSO-NN、GA-NN以及NWOA-NN的训练时间
由于优化算法可以让ANN在训练开始时获得较好的权重和偏置,而非随机产生,因此可以有效避免ANN在训练时陷入局部最优,减少了ANN的训练时间。相对于PSO和GA,因为WOA本身的随机参数更少,种群中的个体有着更多的位置更新方式,所以能够得到更优的解,因此WOA-NN和NWOA-NN的训练时间要小于PSO-NN和GA-NN。而NWOA-NN的网络训练时间在不同的扫频间隔下均为最小,因为相对于标准WOA,NWOA将原先的线性收敛因子替换成了非线性收敛因子,在更新候选解的时候能够更好地避免陷入局部最优,因此NWOA能得到更好的权重与偏置的组合。
表3为优化算法优化网络所消耗的时间(即优化算法得到最优解所需要的时间)。从表中可以看出,相对于WOA、PSO和GA,NWOA得到最优解的时间明显较短,这是因为NWOA中的非线性收敛因子在后期快速减小,加快了NWOA的收敛速度,因此NWOA能更快地得到最优解。

表3 WOA、PSO、GA以及NWOA优化ANN的时间
4 结束语
目前使用神经网络从BOTDA测量的BGS中直接提取BFS正逐渐变得普遍。为了克服神经网络在训练过程中容易陷入局部最优的缺点,本文提出使用WOA优化的方案,将ANN中的权重与偏置看作种群中的个体,获得最优的权重与偏置的组合,优化ANN的训练过程。实验结果表明,本文提出的NWOA-NN和WOA-NN的RMSE、SD和训练时间均低于ANN、PSO-NN和GA-NN网络。特别在大扫频间隔下,NWOA和WOA的RMSE甚至优于ANN在小扫频间隔下的表现,且NWOA-NN所获取BFS的平均RMSE低于WOA-NN约19%。在训练时间方面,因为设计使用了非线性收敛因子,NWOA比WOA节省了大约18.7%的时间;同时由于NWOA-NN能够得到比WOA-NN更适合的权重与偏置的组合,并进一步节省了约5%的训练时间。本文所提优化算法亦可推广于光纤分布式传感信息提取的其他神经网络优化。
