基于区域结构特征的城区LiDAR数据快速分类
2021-12-18曹志民段朝辉
韩 建,李 林,曹志民,段朝辉,万 川
(1.东北石油大学物理与电子工程学院,黑龙江 大庆 163318;2.东北石油大学黑龙江省高校共建测试计量技术及仪器仪表研发中心,黑龙江 大庆 163318)
0 引 言
随着遥感技术的快速发展,人们对三维城市模型构建的需求和兴趣不断扩大。由于具有较高的空间信息获取精度以及不受阴影影响等优点,机载激光雷达系统已经成为智能城市及基础设施建设等相关应用的重要数据源[1-10]。机载LiDAR空间信息获取的本质是测距,如图1所示,结合GPS、INS和激光测距系统,可以快速获取大量具有精确三维坐标的点云数据。然而,所获取数据点信息间是相互独立的,语义信息缺失。为此,为了更好地利用LiDAR点云数据,对应的分类或分割操作即成为语义信息补偿的必要手段。

图1 机载LiDAR系统数据采集示意图
LiDAR点云分类的目的是能有效地将原始数据分为具有不同语义意义的类别。为了解决这一问题,无论是先分割后分类,还是采用深度学习方法,所利用特征大多集中于数据点局部强度、强度差、梯度等直接数值信息或局部纹理、植被指数等统计信息。如在文献[11]中,作者对建筑物、植被和地形采用了基于分割的分类方法,采用的特征有:分段边界梯度、高度纹理、回波强度差、强度等。文献[12]的作者采用的特征有:高度、高度变化、回波强度差、亮度和强度。文献[13]利用了高程、表面变化率、强度和归一化植被指数等特征。文献[14]利用点云位置信息和强度信息建立条件随机场,并利用XGBoost对点云数据进行了分类。通过相关研究的对比发现,从曲面结构特征的角度充分挖掘树木及建筑物点云表征的本质区别方面进行特征提取的研究很少,关键结构信息挖掘不充分。
为了解决以上问题,本文提出在点云局部二次曲面结构表征的基础上,构建局部表征特征向量,该特征向量充分考虑了目标点及邻域点的语义特征,能够实现点云局部结构信息的充分挖掘,在此基础上,利用模糊逻辑技术即可实现目标区域建筑物、植被及地面的分类任务。
1 二次曲面表征结构特征构建
当前利用LiDAR点云数据进行分类或分割的操作中,所利用特征大多仅反映了平面特征[15-18],因为人们总是关注由许多平面部分组成的建筑屋顶或其他人造结构。这里,本文同时考虑建筑物及主要干扰和高大树木等植被,特别是关于二者的局部结构差异的观察,即用高阶特征代替平面特征的拟合。在计算机视觉领域,散乱点云的曲面拟合通常采用多项式模型和径向基函数(RBF)模型。本文采用二次多项式模型有2个方面的考虑:
1)高阶多项式模型能更准确地拟合曲面。由于高阶模型必须使用更多的点来拟合,而LiDAR点云数据中存在稍小植被遮挡、高大树木遮挡建筑物和部分枝叶遮挡而导致潜在点数不充足的问题,而二次多项式模型已能反映拟合曲面的曲率等结构特性。
2)RBF模型由一个低阶多项式(通常是二次多项式)和所选基函数的线性组合组成。要使用它,就必须确定许多参数。因此,所使用的拟合模型在公式(1)中描述为:
Z=P00+P10X+P01Y+P11XY+P20X2+P02Y2
(1)
其中,X、Y、Z为LiDAR点云数据的三维空间坐标值。
为了获取局部结构表征的特征值,针对建筑物目标和树木目标,首先从WG III/4数据集中人工选择不同大尺度区域树木和建筑物目标,然后随机采样建筑物和树木局部结构样本各1000个,类别标签分别为建筑物为“1”和树木为“0”,为实现局部结构精细分析,对各局部结构进行6类聚类,得到了6类典型建筑物和树木局部数据,即T1~T6和B1~B6,图2给出了局部目标的代表样本。
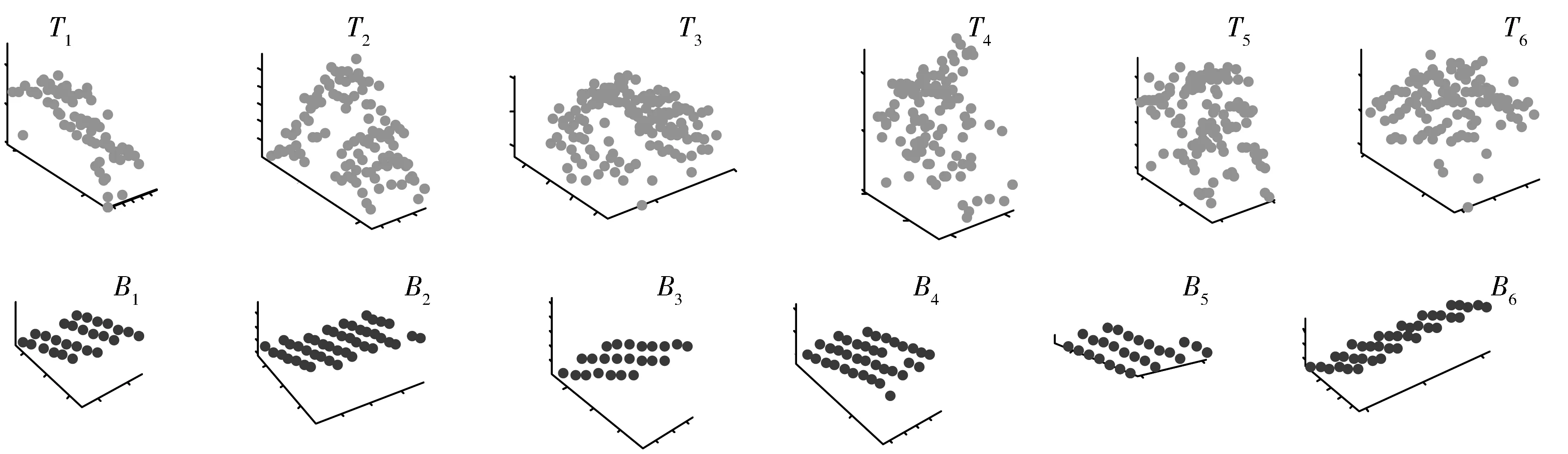
图2 局部目标样本示意图
对每类局部结构进行二次多项式拟合,可以得到表1所示的拟合参数均值结果。

表1 典型目标局部结构二次多项式拟合结果
从表1可以看出,树木和建筑物样本集得到的二次系数(P20,P11,P02)有明显的差异。显然,可以直接利用这3个系数组成一个三元组特征向量。然而,就像使用PCA方法进行特征值分析一样,直接利用所获取特征值进行信息挖掘不是最优的,需要根据实际情况对特征值进行组合。为此,以二次多项式拟合的二次系数为基础,本文设计了一个二元组特征向量,即:
Features=[Feature_1 Feature_2]
(2)
其中:
Feature_1=∑|quadratic coeff|=|P20|+|P11|+|P02|
(3)
Feature_2=max(|quadratic coeffs|)/∑|quadratic coeff|
=max(|P20|,|P11|,|P02|)/(|P20|+|P11|+|P02|)
(4)
图3给出了表1对应的各类目标二次拟合均值的二元特征图,可以看到,所提特征能够显著实现树木和建筑物目标的线性区分。

图3 表1数据对应二元特征显示示意图
2 机载LiDAR点云分类方法
2.1 地面和非地面点分类(即点云滤波)
为了将LiDAR点云数据分为地面和非地面2个部分,有几种滤波方法,包括基于形态学的方法、基于主动TIN的方法、基于分割的方法等[19-21],这些方法的主要假设是地面点总是低于其他物体。如果能更准确地估计出局部的地面高度,最简单的方法就是用一个精确的高度阈值对输入的激光雷达数据进行滤波。基于这种考虑,按照面积阈值大小大于建筑物宽度乘长度的原则,将输入的LiDAR点云数据划分为多个正方形子网格。具体地,在考虑局部未遮挡区块及低矮屋体的情况下,本文将输入LiDAR点云数据的水平面划分为4 m×4 m的网格网络。
为了得到点云滤波的阈值,在相应的子网格中按高度值给定的顺序对点进行排序。然后,每个子网格的阈值可以设置为:
T=HTid, Tid=ρ×N
(5)
其中,N表示子网格中点的个数,ρ表示与地面占有率相关的参数,Tid为高度阈值索引。
2.2 基于局部区域特征的LiDAR点云分类
在确定了用于分类或分割的特征向量之后,主要有2种模式识别方法:
1)无监督方法(clustering)。即仅依赖于特征向量和选定的距离度量将输入数据分类为不同的类别。然后利用先验知识判断提取的类别。
2)有监督分类法。即通过训练一些具有已知类别标签的样本集,将输入数据分类为一些预定义的类别。无论选择哪种方法,邻域形状和大小的选择将严重影响计算结果。

Di=(dij=‖Fi,FCj‖E)j=1,2,…,12
(6)
其中,‖X,Y‖E表示向量X和Y的欧氏距离;FCj,j=1,2,…,12表示表1中给出的12个目标局部类别的特征中心。利用式(6)得到每个点的欧氏距离向量后,通过反距离加权的方式对每个点属于不同目标局部的情况进行投票,可得到每个点被分为树木或建筑物的次数,定义为Nv_tree和Nv_building。最终,可以根据如下目标隶属度进行点类别判定:
(7)
(8)

(9)
3 实验结果及分析
3.1 数据集
本文实验所用原始激光雷达数据和相应的航空彩色图像分别如图4(a)和图4(b)所示。这是从ISPRS委员会第三委员会第III/4工作组获得的数据的一个子集。该激光雷达数据由徕卡地球系统公司于2008年8月21日使用徕卡ALS50系统获得,该系统具有45°视场,平均离地飞行高度为500 m。中间点密度为6.7点/m2。从图4可以看出,在这个数据集中,建筑物周围有许多不同高度的树木。

(a) 航拍真彩图像
3.2 实验结果
为了验证所提出的基于二次多项式拟合区域结构特征的城市分类方法的有效性,使用Matlab 2018A开发了所有相应的算法,使用的计算机配置为Pentium i5双核CPU i5-7500@3.4 GHz,8 GB内存。
首先,需要将原始数据分为地面点和非地面点。那么,必须确认式(5)中的关键参数,对于实验所用的LiDAR点云数据,此参数设置为0.35。相应的地面点与非地面点实验结果如图5(a)所示。在图5(b)中,给出了非地面点。此步骤所用平均时间为0.00763 s。

(a) 分类结果
接下来,对得到的非地面点利用本文所提方法进行树木植被点和建筑物点的分类。具体地,二元结构特征利用式(7)和式(8)进行局部点类别模糊隶属度计算,并根据式(9)完成最终分类。图6给出了最终的分类结果。实验平均用时90.6 s。

(a) 建筑物和树木植被分类结果
3.3 实验结果分析
在具体分析前,图7对建筑物和植被分类结果进行了一些标识。图7中,圆圈标记处为很难分类的建筑物屋顶的一部分,得到了正确分类;圆角矩形框内为人工修剪平整的高大灌木,被误分为建筑物;直角矩形框中为较难分类的小型低矮屋体,得到了正确分类。显然,本文方法通过二次多项式拟合构建局部结构特征较好地从结构角度区分了树木和建筑物。对于结构模糊度较高的人工修剪平整的灌木,利用结构特征一般难于分辨,需要借助强度、光谱等其他特征。

图7 建筑物及树木植被分类讨论
4 结束语
针对当前机载LiDAR点云数据城区建筑物及高大树木植被分类难的问题,提出了表征能力优异的局部结构描述特征,并基于此实现了一种基于模糊逻辑的城区机载LiDAR点云快速分类方法。该方法实现原理简单,易于实现,通过现有后期数据编辑技术的引入,可向智能交通及自动驾驶等领域进行推广。
