基于卷积神经网络的苹果栽培品种识别
2021-12-18韩俊英封成智陈永卫
仇 誉,韩俊英,封成智,陈永卫
(甘肃农业大学信息科学技术学院,甘肃 兰州 733070)
0 引 言
苹果是世界上仅次于柑橘的第二大水果,其种植生产遍布于全世界。目前,种植苹果已成为许多国家主要的农事活动,约有80多个国家和地区都种植生产苹果[1]。苹果产业作为中国最具代表性的劳动密集型优势产业,多年来在促进农民收入增长和区域经济发展等方面起到了重要作用。苹果产业也在我国的水果产业中一直占据着非常重要的地位,其很强的市场竞争力,对于果农增加收益以及农业产业结构的改善都具有重要意义[2-3]。随着苹果种质资源的不断创新丰富,如何有效、简单、准确识别苹果品种成为了一个不断引起各界关注的热点问题。文献[4]指出基于深度学习的图像识别技术可以与人类专家的识别能力相媲美,甚至超过专家的识别能力。因此本文拟提出一种基于计算机视觉技术的苹果果树栽培品种识别方法,包括前期数据采集、模型设计训练验证等过程,要求有较高的识别率,可以为苹果产业的生产研究提供力所能及的帮助。
近年来,以深度学习为基础的图像分类成为了计算机视觉技术方面的一个重要课题,特别是在大规模图像分类任务中有良好表现的卷积神经网络[5],已经发展成为计算机模式识别任务中最好的分类方法之一,它的适用范围广泛,还能够自动提取图像低级特征并进一步学习高级特征,现已被广泛应用于图像分类、图像分割、目标识别和物体定位等领域[6-8]。薄琪苇[9]以卷积神经网络算法为基础构建了一个植物叶片识别模型,并选取15种叶片图像进行实验。他根据叶片图像的特点,对模型参数及结构有针对性地进行调整,从实验结果来看,平均识别率能达到93.7%。林君宇等人[10]针对10种常见观赏花卉,提供了一个图像数据集,其中包含4种花卉的共16种叶部病症,设计实现了以卷积神经网络为基础的分类模型,实验结果表明,病症识别准确率达到88.2%。袁培森等人[11]运用卷积神经网络技术获取菊花的特征信息,实验表明,平均识别率可以达到95%左右,部分达到98%,系统识别精度明显提升。Backes等人[12]采用复杂网络算法对不同分辨率以及存在噪声的叶片图像进行识别,取得了不错的识别效果。Krizhevsky等人[13]使用卷积神经网络在ImageNet数据集上的识别取得了突破性进展。Mohanty等人[14]训练了一个深度卷积神经网络,并对其进行了迁移学习,将植物叶片病害进行分类识别,最终的识别精度为99.35%。Carpentier等人[15]建立了一个包含23000张树干图片的数据库,在ResNet18和ResNet34上进行训练,识别精度达到了93.88%。
本文以甘肃省平凉市静宁县果树果品研究所苹果良种苗木繁育基地作为研究基地,将14个苹果果树品种做为研究对象,基于卷积神经网络训练识别分类模型,对苹果栽培品种识别分类问题进行研究。以在大规模图像分类任务中有良好表现的卷积神经网络为基础,调试其各项参数结构寻求最优的苹果栽培品种识别分类模型,以期为现代苹果种植及科研提供帮助。
1 材料与方法
1.1 软、硬件环境介绍
所有实验数据集用到的原始叶片图像均采用数码相机拍摄,实验所用电脑为Thinkpad E440,使用PyCharm软件集成开发,训练模型基于Tensorflow框架实现,所有代码均使用Python语言编写。详细的参数配置如表1所示。
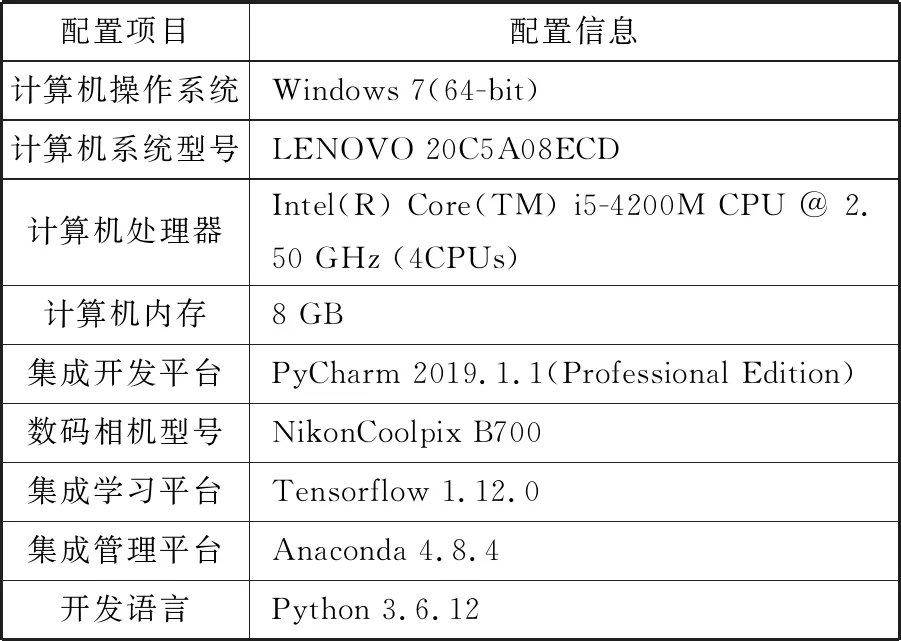
表1 软硬件环境介绍
1.2 卷积神经网络概述
卷积神经网络[16-17]是受人体神经系统启发而创造的一种多层感知模型,具有良好的容错能力、并行处理能力和自学习能力。经典的CNN由输入层、卷积层、池化层(也称下采样层)、全连接层及输出层组成,如图1所示。

图1 卷积神经网络典型结构
以LeNet-5为例,这是典型的卷积神经网络结构,通常会交替设置若干个卷积层和池化层,依此类推。因为在卷积层中输出特征面的每个神经元都和它的输入进行局部连接,并且根据匹配的连接权值与局部输入进行加权求和,最终再加上偏置值计算出该神经元的输入值,这个过程就近似于卷积过程,CNN也由此而得名[18-20]。
1.3 实验
1.3.1 图像采集
自2008年开始,中国苹果产业发展速度开始增快。从区域变化来看,环渤海湾优势区面积和产量逐渐下降,黄土高原优势区持续快速增长,其中,甘肃和陕西发展较快,且向高海拔地区扩张。甘肃已成为最具发展潜力和优势的新兴苹果产区(如甘肃静宁、庄浪、庆阳等地)[2-3]。
静宁地区目前是我国西北黄土高原第二大苹果产区,平均海拔1600 m。本文实验所使用的数据集叶片图像是于2018年7月15日至8月20日期间,在甘肃省平凉市静宁县果树果品研究所苹果良种苗木繁育基地内(35°28′N,104°44′E)采集。该研究所内苹果品种齐全,管理专业化,符合本文实验的实验要求。
笔者共在该研究所基地内选取苹果果树品种14种进行实验。在采集苹果果树叶片图像的过程中,首先选取每个品种的苹果果树10棵左右,选取果树的树龄、树势、长势都存在差异。在这37天的采集期中,有晴天12天,阴天16天,小雨1天,中雨1天,大雨1天,多云5天,雾天1天,涵盖了大部分天气状况。每天在所选取果树的树冠东、西、南、北4个方向的外围(距树干大于1 m)和内膛(距树干小于0.5 m)处随机采摘无损伤、无病虫害的成熟叶片,每个品种约采摘100片,保证数据的全面性。然后在室外自然光下以白色A4纸作为背景,用尼康B700数码相机拍摄叶片图像,分辨率为300 dpi,类型为24位真彩色。共拍摄14个品种的果树叶片图像14394张。
采集叶片图像详细信息见表2,用阿拉伯数字1~14依次给14个苹果品种编号,用字母a~n依次作为其代码。

表2 叶片图像采集详细信息
14个品种的苹果果树叶片彼此相似,形状都近似椭圆。叶片前端都比较尖锐,边缘都是锯齿状,长约4.5 cm~10 cm,宽约3 cm ~5.5 cm。颜色用肉眼看都为绿色。非常高的相似性也导致了利用叶片图像对苹果果树品种进行分类具有很高的难度。叶片图像示例见图2,为了方便展示,本文将叶片图像缩放到统一大小,品种名称以表2中的代码表示。

图2 叶片图像示例
1.3.2 数据集划分
本文将每个品种的叶片图像随机取出5%作为测试集。剩下的95%,随机取出其中80%作为训练集,20%作为验证集。统计数据如表3所示。
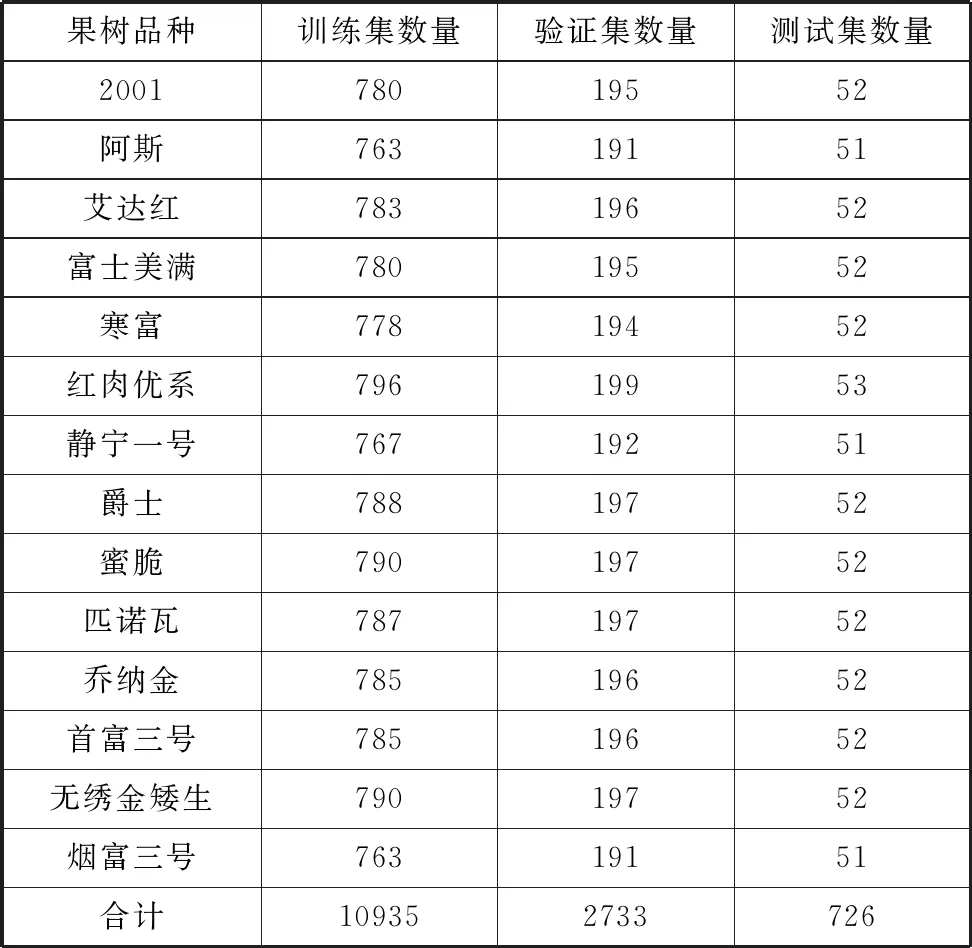
表3 各数据集数据统计
1.3.3 苹果栽培品种识别分类模型构建
模型构建方面,为了得到识别分类效果最好的模型,本文在数据集上进行了大量测试,包括对学习率、卷积层层数、卷积核数量、卷积核大小、全连接层隐含节点等的调整。具体步骤如下:
1)保持学习率为0.0001,卷积核大小为3×3,全连接层隐含节点为512、256,Batch为32。只对卷积层层数和卷积核的数量进行调整,得到该条件下的最优模型,详细参数见表4。使用测试集中的“2001”果树品种叶片作为测试对象,可以明显看到在该条件下model6在所有模型中有着最好的识别精度。

表4 识别分类模型类别及测试精度1
2)用上述测试精度最高的model6继续进行实验。保持卷积层层数、卷积核数量、卷积核大小、全连接层隐含节点等参数不变,调整学习率,得到该条件下的最优模型。如表5所示,当Learning rate=0.0004时,模型具有最好的识别精度。
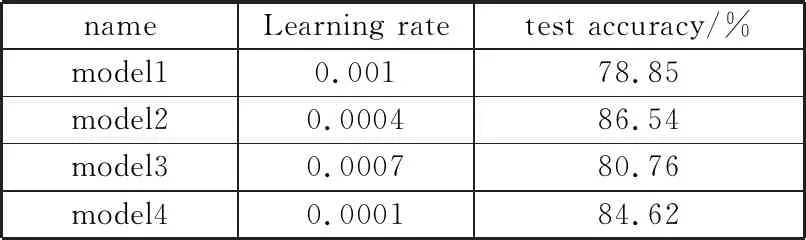
表5 识别分类模型类别及测试精度2
3)使用上一步骤中得到的识别精度最高的model2模型,调整全连接层隐含节点继续进行实验,如表6所示,当fc1、fc2分别为1024、512时,模型具有最好的识别精度。

表6 识别分类模型类别及测试精度3
4)使用步骤3中测试精度最好的model4模型,调整batch大小获得最优解,如表7所示,当batch=64时,模型具有最好的识别精度。

表7 识别分类模型类别及测试精度4
经过反复测试,最终采用的苹果栽培品种识别分类模型为步骤4中的model4,整体学习率learning_rate=0.0004,每次迭代输入的图片数据batch=64。
2 结果与分析
本文实验中最终采用的模型训练程序架构如图3所示。由1个输入层、5个卷积层、5个池化层、3个全连接层、2个Dropout层、1个输出层组成。

图3 程序架构
本文将所有卷积层的卷积核大小都设置为3×3,strides=[1,1,1,1],padding="SAME",用以逐步提取叶片图像的特征,保证叶片图像的主要特征不会因为卷积核大小过大或者strides过大而丢失。每个卷积层都调用Tensorflow的ReLU[21]激活函数进行激励计算。并且在每个卷积层后的池化层都调用Tensorflow的max_pool函数进行池化计算,设置ksize=[1,2,2,1],strides=[1,2,2,1],padding="VALID"。3个全连接层分别有隐藏节点1024个和512个。也使用ReLU函数作为激活函数,并且每层都采用Dropout[22]层,随机舍弃50%的神经元来减少过拟合和欠拟合的程度,保存模型最好的预测效率。
最终确定的苹果栽培品种识别分类模型精度及损失演化曲线如图4所示,该模型大约经过10次迭代以后开始收敛,经过30次迭代后收敛效果良好,最终达到最佳的识别分类性能。
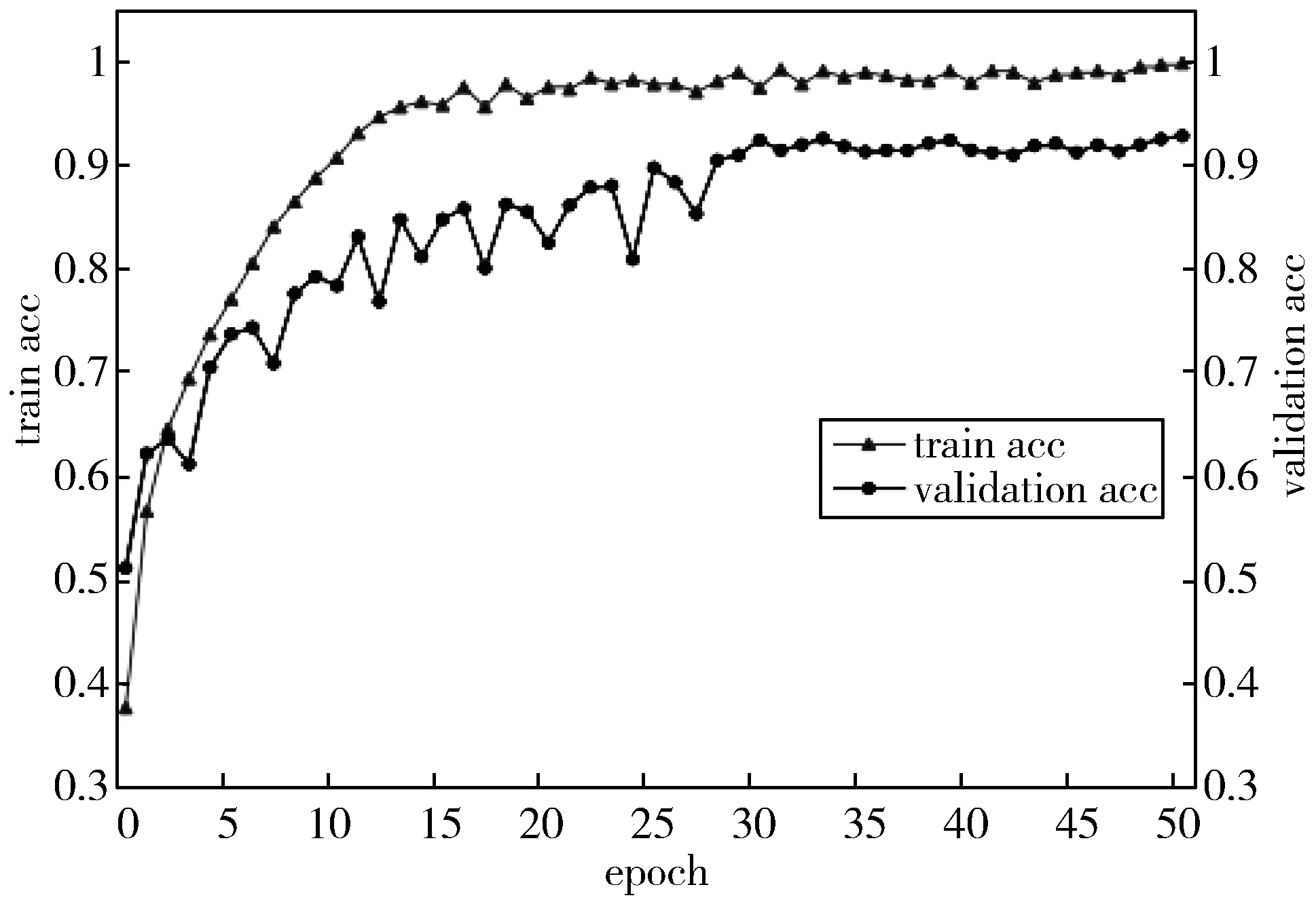
图4 模型训练精度及损失演化曲线
从演化曲线上可以看出,该模型具有很好的学习能力,因为在前10次迭代过程中,其准确率上升较快,损失下降也较快,在10次迭代以后,训练准确率总体上呈现出相对稳定的上升趋势。而且,在整个收敛过程中,精度波动上升,而损失持续波动下降,说明模型具有持续学习的能力,不会陷入局部最优。此外,在整个训练过程中,训练精度略高于验证精度,训练损失略低于验证损失,说明该模型能够成功避免过拟合问题。
3 讨 论
本文实验由于样本数据集有限,为了保证识别分类模型的可靠性和稳定性,所以本文首先通过10折倍交叉验证法来评估该模型的性能,然后使用独立测试集测试该模型的泛化性能。
在10折交叉验证法中,除去独立测试集的样本数据集被随机分为10个互斥的子集。依次用其中1个作为验证集,其他作为训练集,整体交叉验证过程就会重复10次,用10次验证结果的平均值作为最终结果,评价模型性能,防止出现过拟合现象。本文实验10折交叉验证的整体实验数据及结果统计如表8所示,表中的行表示苹果果树品种,列表示验证次数,表中的数据为x/y形式,y代表验证集的数量,x代表验证正确的图片数量。以实验次数来看,在10次交叉验证中,最高验证精度可以达到97.35%,最低为95.98%,平均验证精度为96.69%,平均误差为0.0331,验证精度方差为1.37281E-5,标准差为0.00371。以每个果树品种来看,“富士美满”品种相较于其他品种识别特征不明显,所以它的识别精度最低,只有90.77%,表中以粗体黑色标识。“艾达红”和“红肉优系”相较于其他果树品种有着突出的独特识别特征,其识别精度可以达到99.59%。“2001”品种有着99.28%的识别准确率,其他品种的识别准确率处在94%~99%之间。
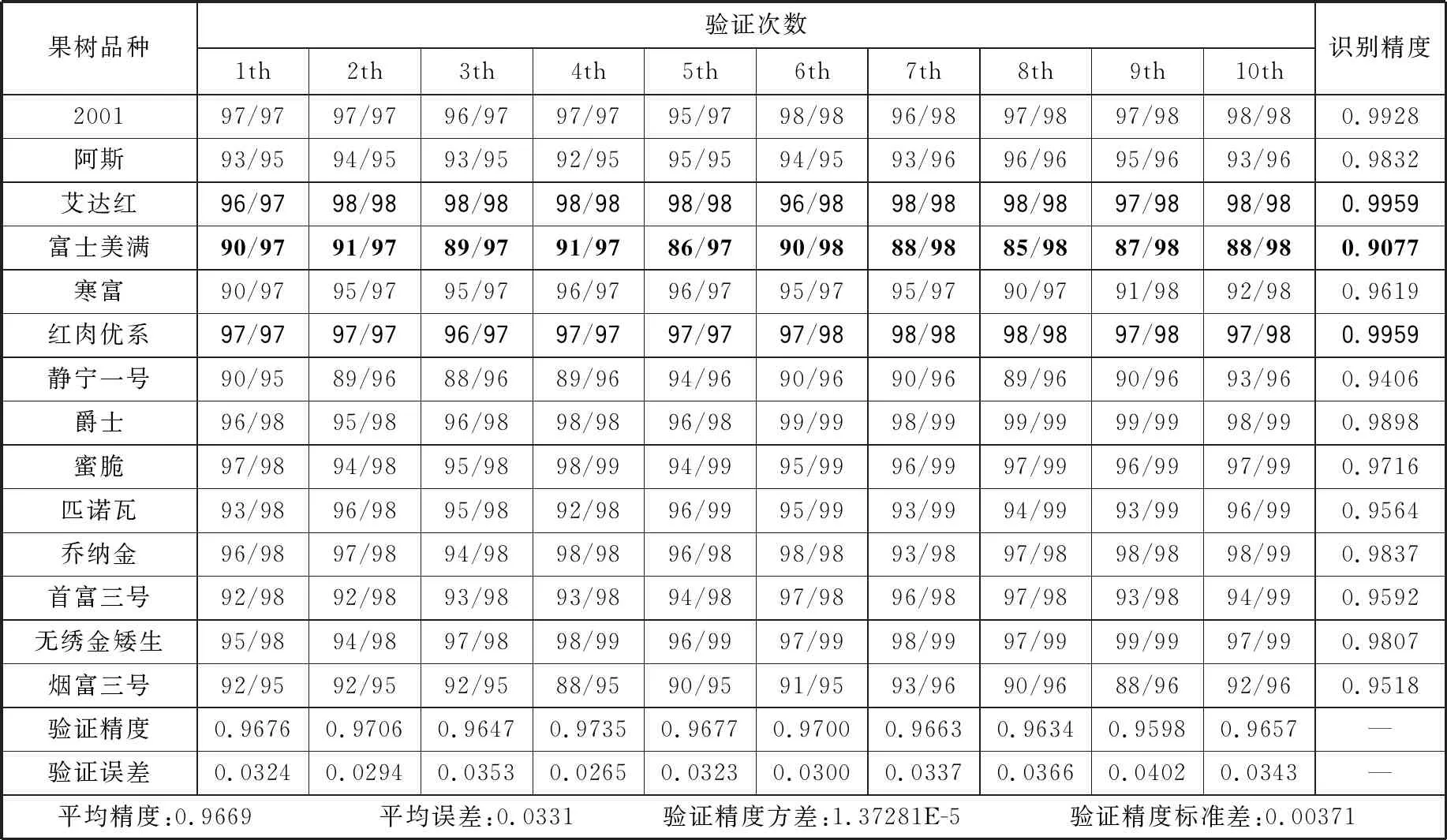
表8 10折交叉验证实验结果统计
一般而言,通过未知数据集测试学习模型的准确性进而评估模型的泛化性能是更加稳定可靠且有说服力的。本文实验使用独立未知测试集测试学习模型的识别结果混淆矩阵如表9所示,行代表苹果果树品种,列代表对应品种通过识别分类模型分析得到的归属品种。各品种名称都以表2中的代码表示。各品种测试识别正确的图片数量以粗体标识。根据实验结果来看,与10折交叉验证实验类似,“艾达红”品种的测试识别准确率最高,达到100%全部识别准确(品种c)。“富士美满”品种的测试识别准确率最低,只有82.69%(品种d)。总体平均测试精度为90.49%,平均测试误差为0.0951,测试精度方差为0.00273,测试精度标准差为0.05227。
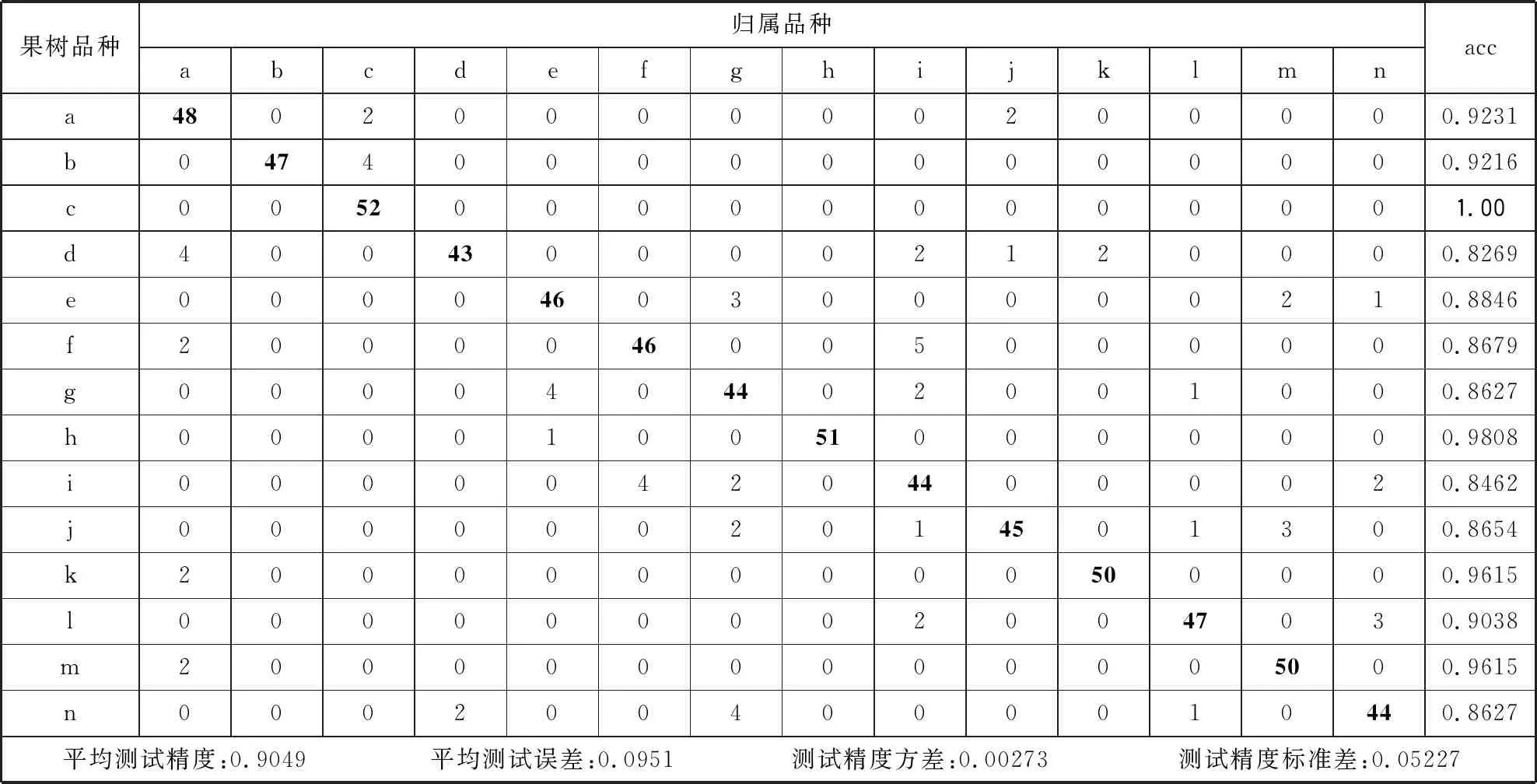
表9 独立测试集测试结果统计
在本文实验中,利用CNN卷积神经网络对苹果果树品种进行了识别分类,相对于传统的需要人工设定提取图片特征的分类识别方法,有着比较满意的识别分类效果,独立未知测试集的测试精度为90.49%。
然而深度学习神经网络训练的模型性能非常依赖训练数据集的大小与丰富度,而本文实验的训练数据集数据量还是不足,所以本文实验现阶段仍然存在一定问题。要想更好符合实际情况,而且还要保证准确性高,则需要更多样化的数据集做训练。不但要增加现有每一个品种的图像数量,还需增加更多的苹果果树品种,并涵盖更加丰富的拍摄条件,例如拍摄设备、光照强度的多样化[23]。并且笔者会继续改进卷积神经网络结构,优化识别分类效果,包括尝试引入多输入[24]、迁移学习[25]、半监督学习[26]等方式。值得借鉴的是,Long等人[27]改进了深度网络结构,通过在网络中加入概率分布适配层,进一步提高深度迁移学习网络对于大数据的泛化能力。
4 结束语
本文提供了一个包含14个苹果果树品种的叶片图像数据集,该数据集包含使用1481片各品种果树叶片拍摄而成的图片共14394张;进而设计并实现了基于卷积神经网络的苹果栽培品种识别分类模型,该模型训练集训练精度可以达到99.88%,验证集验证精度为92.86%,独立未知测试集的测试精度为90.49%。实验表明,本文提出的基于卷积神经网络的苹果栽培品种识别分类模型具有比较不错的识别效果,这对于解决田间果园、科研实验等实际场景的问题有着深远的意义。随着深度学习技术研究的推进,未来与植物表型各种具体问题相结合的解决方案会不断增多,将会出现更多具有影响力的基于深度学习的植物表型工作和成果。
