基于通道切分的人体姿态估计算法
2021-12-18周昆阳赵梦婷张海潮邵叶秦
周昆阳,赵梦婷,张海潮,邵叶秦
(1.南通大学张謇学院,江苏 南通 226019; 2.南通大学交通与土木工程学院,江苏 南通 226019)
0 引 言
人体姿态估计是人体运动识别、运动学分析、人机交互、动画制作等方面的基础性工作。人体姿态估计的目的是借助摄像头等传感器,在复杂场景、不同人群中对人体的关节点进行准确定位。
多年来,人体姿态估计大多基于手工特征,主要包括基于可穿戴设备[1]和基于模版匹配[2]的方法。这2种方法都存在泛化能力较低、检测流程繁琐等缺点。随着神经网络的发展,人体姿态估计取得了很大的进展。Wei等[3]提出了卷积姿态网络(Convolutional Pose Machine, CPM),首次对人体关节点信息进行建模,基于模型输出的热力图,在每个通道上找到最大响应点实现人体姿态估计。同时,由于行人检测算法性能逐步提升,出现很多优秀的检测模型,例如YOLO、Faster-RCNN等。这使得姿态估计算法逐渐从单人姿态估计转向多人姿态估计。按照姿态估计实现方式的差异,多人姿态估计分为2类:自底向上(Bottom-Up)和自顶向下(Top-Down)。
自底向上的多人姿态估计是先检测所有关节点,然后根据所属人体组装这些关节点,其典型模型是OpenPose[4]。OpenPose通过CPM定位所有关节点的位置,并采用部件亲和场(Part Affinity Fields)组装定位好的各个关节点。OpenPose已经被许多学者广泛应用到各个领域中。Hung等[5]将OpenPose应用到传统武术表演评价中,唐心宇等[6]将OpenPose应用到患者康复医疗中。也有学者根据OpenPose的优缺点和应用场景对OpenPose进行改进。冯文宇等[7]提出了CT-OpenPose,通过将OpenPose的底层特征提取网络替换为带有软阈值的残差网络,并且改进了OpenPose底层特征提取的流程和模型压缩方式,在特征提取网络中加入权值修剪和跨层连接机制,有效提高了模型的检测速度和准确度,但CT-OpenPose仅在特定场景下对OpenPose模型进行了改进,通用性不高。
自顶向下的多人姿态估计是先通过人体检测器检测出人所在区域,然后在该区域上进行单人姿态估计。具有代表性的是旷世科技提出的级联金字塔网络(Cascaded Pyramid Network, CPN)[8]和Fang等[9]提出的RMPE。级联金字塔网络是一种由粗到细的网络模型,利用单人的上下文信息完成人体姿态估计。RMPE由对称空间变换网络(Symmetric Spatial Transformation Networks)、参数姿态非极大抑制(Non-maximum Suppression)和姿态引导提议生成器(Pose Guide Proposal Generator)这3个部分组成,通过处理不精确的人体定位框和检测冗余,有效地提高了人体姿态估计的准确率。这些主流人体姿态估计算法虽然提高了模型识别的准确率,但存在模型过大、预测速度较慢的问题,不利于实际使用。
本文提出一种基于通道切分的自顶向下的人体姿态估计算法Channel-Split Residual Steps Network (Channel-Split RSN):
1)在传统残差阶梯网络(Residual Steps Network, RSN)基础上,提出一种通道切分模块,将输入特征的通道分成k个部分,对k-1个部分分别使用卷积提取特征,再将k个特征沿通道进行拼接,并和通道切分模块的输入特征相融合,得到丰富的特征表示。
2)在通道切分模块的基础上引入特征增强模块,使用分组卷积和逐点卷积,对特征通道不同部分采取不同的处理策略,以减少通道内的相似特征,提高特征提取的效果。
3)为了提高人体姿态估计的准确性,提出一种基于改进的空间注意力机制的姿态修正机Context-PRM,通过考虑特征在空间上的相关性,提升姿态估计的准确率。
实验结果表明,本文方法能够有效地提高人体姿态估计的准确率,且模型具有较快的预测速度和较高的实用性。
1 残差阶梯网络算法介绍
残差阶梯网络[10]是旷世科技提出的人体姿态估计算法,算法采用自顶向下方法进行人体姿态估计,人体检测器使用MegDetv2[11]。整体网络结构由多个残差阶梯网络级联而成,每个残差阶梯网络包含8个残差阶梯块(Residual Steps Block, RSB),如图1所示。每个残差阶梯块通过密集的逐个元素相加方式加强特征的融合,有效地丰富了人体姿态估计的特征表示。
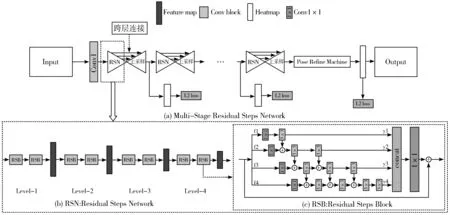
图1 传统残差阶梯网络结构图
另外,残差阶梯网络还包含了一个基于注意力机制的姿态修正机(Pose Refine Machine, PRM),如图2所示。输入特征经过3×3卷积后进入3条路径:第1条路径(First path)用于得到通道注意力,第3条路径(Third path)用于生成空间注意力,第2条路径(Second path)是将这2条路径生成的注意力作用在输入特征上。姿态修正机使用通道注意力和空间注意力进一步提高人体关节点的定位精度。
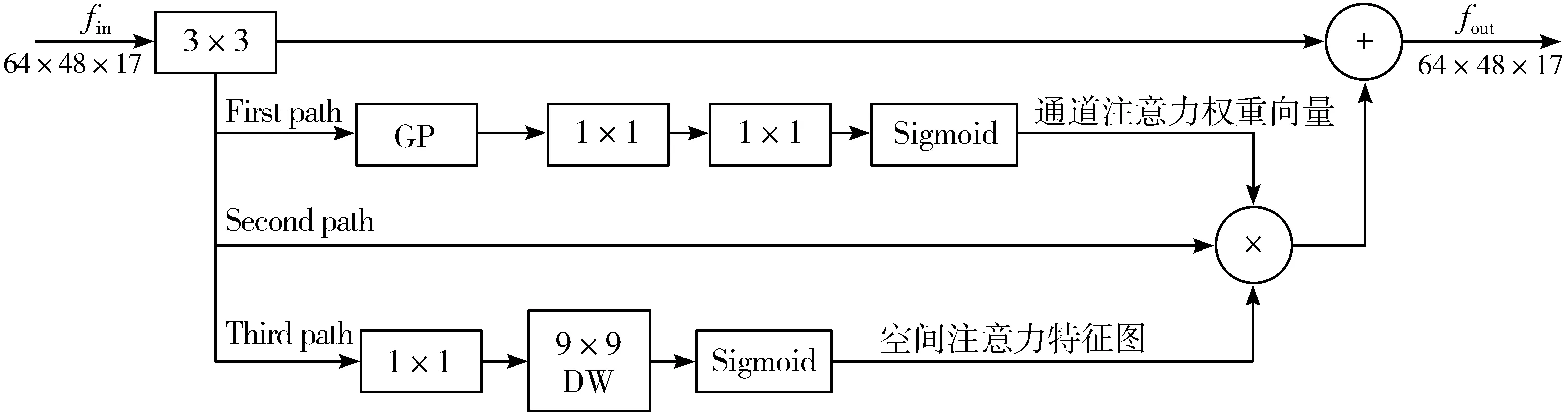
图2 姿态修正机示意
2 基于通道切分的人体姿态估计算法
2.1 算法思路
本文采用自顶向下的方式实现人体姿态估计,使用RSN18作为特征提取网络,YOLOv4[12]作为人体检测器,算法结构如图3所示。输入图像首先经过卷积和最大池化提取特征,接着特征经过一个包含8个残差阶梯块的残差阶梯网络,跨层连接和上采样得到人体姿态估计的初步结果。需要注意的是,本文在最后一个残差阶梯块中引入通道切分模块,替换原有的3×3卷积,如图3中黑色方块所示。最后,基于改进的姿态修正机(Context-PRM),得到更加准确的人体姿态估计。整体算法命名为Channel-Split Residual Steps Network (Channel-Split RSN)。

图3 Channel-Split RSN网络结构
2.2 通道切分模块
2.2.1 通道切分模块算法流程
为了得到丰富的特征表示,本文提出通道切分模块,将特征通道分成若干等份,分别提取每个部分的特征后,再融合起来,如图4所示。

图4 通道切分模块(k=4)
具体来说,输入特征首先沿通道平均分成k个部分,每个部分记为Fi(1≤i≤k,k>2)。每一部分的特征进行如下操作:
FS1=F1,i=1
(1)
FS2,1,FS2,2=H2(F2),i=2
(2)
FSi,1,FSi,2=Hi(Fi+Fi-1,2), 3≤i≤k-1
(3)
FSk=Conv3×3(Fk+Fk-1,2),i=k
(4)
其中,Hi(2≤i≤k-1)表示特征增强模块,Conv3×3包括3×3卷积批量归一化层(Batch Normalization, BN)ReLU激活函数,+号表示拼接(Concat)。
然后,将FS1、FSi,1(2≤i≤k-1)、FSk沿通道拼接,经过一个1×1卷积后再和通道切分模块输入特征相加,得到整个通道切分模块的输出。这里,通道切分模块的输入和输出特征具有相等的尺寸和通道数。
通道切分模块通过切分特征通道并融合不同大小通道数的特征促进特征之间的信息交流,进而丰富通道切分模块中的特征表示。同时,通道切分模块使用特征增强模块减少特征通道内的相似特征,提高特征提取的效果。
2.2.2 特征增强模块
标准卷积对输入特征的所有通道进行相同的卷积操作。经过标准卷积后的特征中,部分通道的特征十分相似,如图5所示,因此这些通道信息存在冗余,对相似特征进行特征提取会造成特征冗余且增加计算量。即使将特征通道(通道数为32)简单地平均分成2个部分,如图6所示,得到的yi,1和yi,2这2个部分中仍有相似的特征,若对yi,1和yi,2使用相同处理方式,还会导致得到的特征通道中存在较多相似特征。

图5 标准卷积的部分通道特征展示

(a) yi,1通道特征图
为了减少通道内的相似特征,GhostNet[13]中提出对特征的每个通道进行对应的线性变换以此来减少通道内的相似特征。受到该思想的启发,本文设计一个特征增强模块,对不同的特征部分采用不同的处理策略,如图7所示。具体来说,将特征沿通道平均分成2个不同部分yi,1和yi,2,对yi,1使用1×1卷积提取特征以补充局部细节信息,而对yi,2使用3×3分组卷积和逐点卷积(pointwise convolution)[14]提取内在特征,如图7所示。分组卷积将特征的通道分为g组(g>1),每个组分别进行卷积操作。与标准卷积不同,分组卷积不同组的卷积核参数不同,相当于每个组进行不同的操作,因此每个组的输出特征是各不相同的,有效减少特征通道内的相似特征。但因为yi,2的通道信息中包含若干模块,每个模块都表示一个主要的特征(例如:条纹、颜色等),分组卷积使得模块间的信息交流被隔断[15]。为此,本文增加逐点卷积,实现输入特征在通道方向上的加权组合,然后将分组卷积和逐点卷积提取的特征相加,丰富yi,2通道的特征表示。
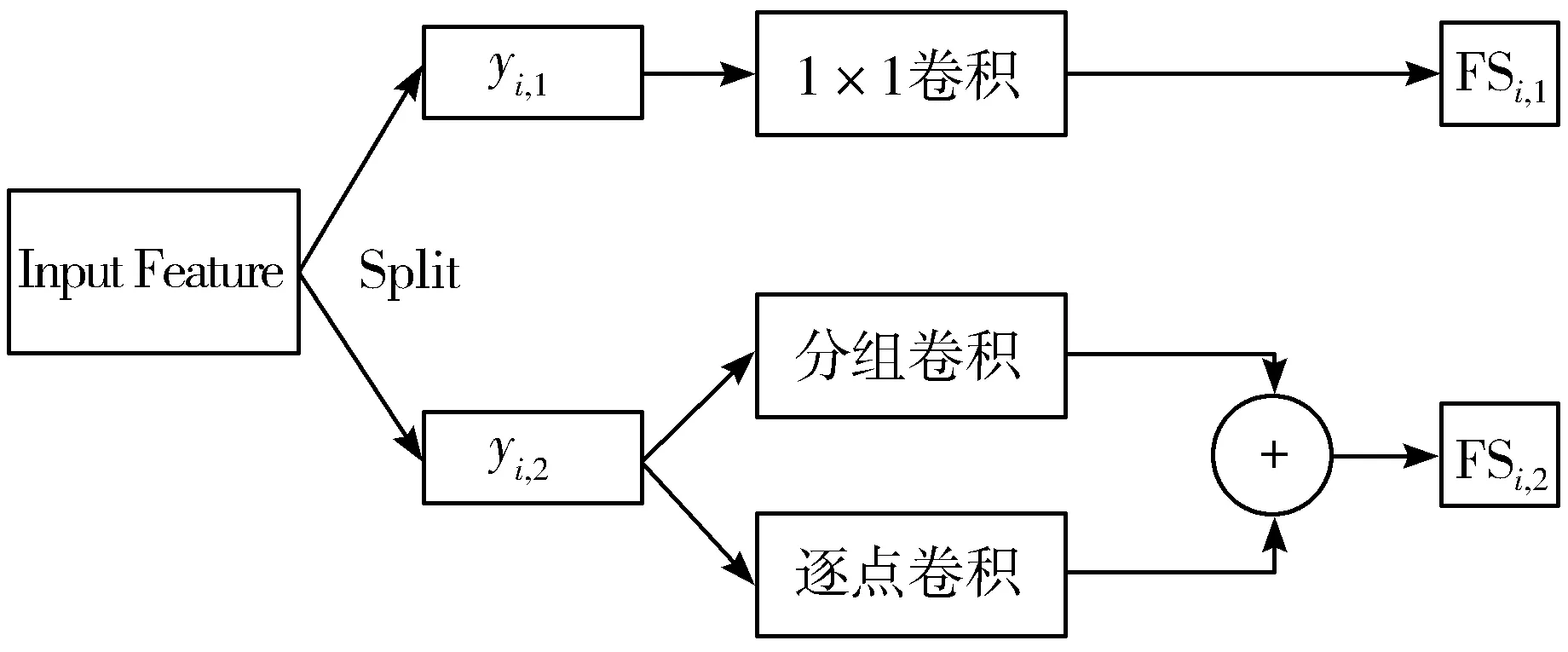
图7 特征增强模块
2.2.3 通道切分模块计算复杂度分析
本文使用通道切分模块替代卷积核大小大于2的卷积操作。为了衡量通道切分模块的计算复杂度,本文对比s×s(s>2)标准卷积的计算复杂度(公式(5))和通道切分模块的计算复杂度(公式(9)),这里,标准卷积计算复杂度用Pnormal表示,通道切分模块计算复杂度用P表示。
Pnormal=s×s×k×w×k×w
(5)
其中,k为特征被通道切分模块分成的份数,k>2,w为每个部分的通道数。
每个特征增强模块对应的计算复杂度Pi如下:
(6)
其中,2≤i≤k-1,g为分组卷积的分组数,g>1。当i=1时,通道切分模块计算复杂度为0,当i=k时,对应的3×3卷积,其计算复杂度Pk如公式(7):
(7)
通道切分模块中1×1卷积的计算复杂度如公式(8)所示:
P1×1=w2×k2
(8)
因此,整个通道切分模块的计算复杂度P如下:
(9)


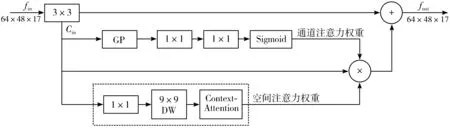
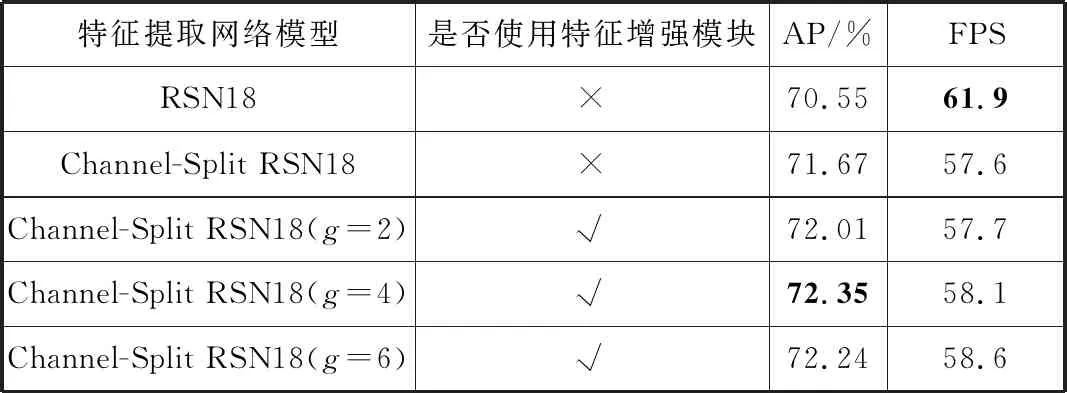
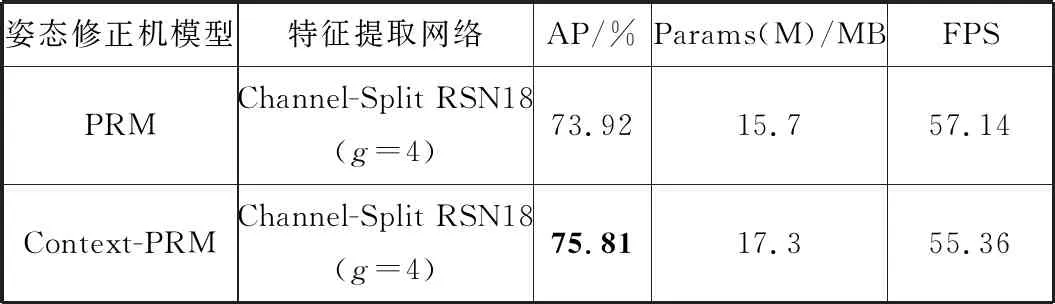
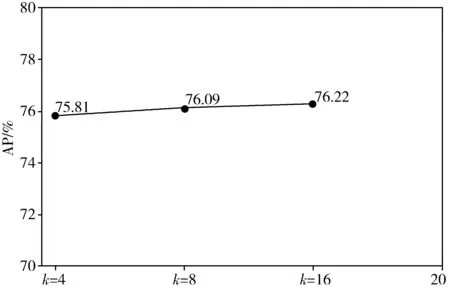
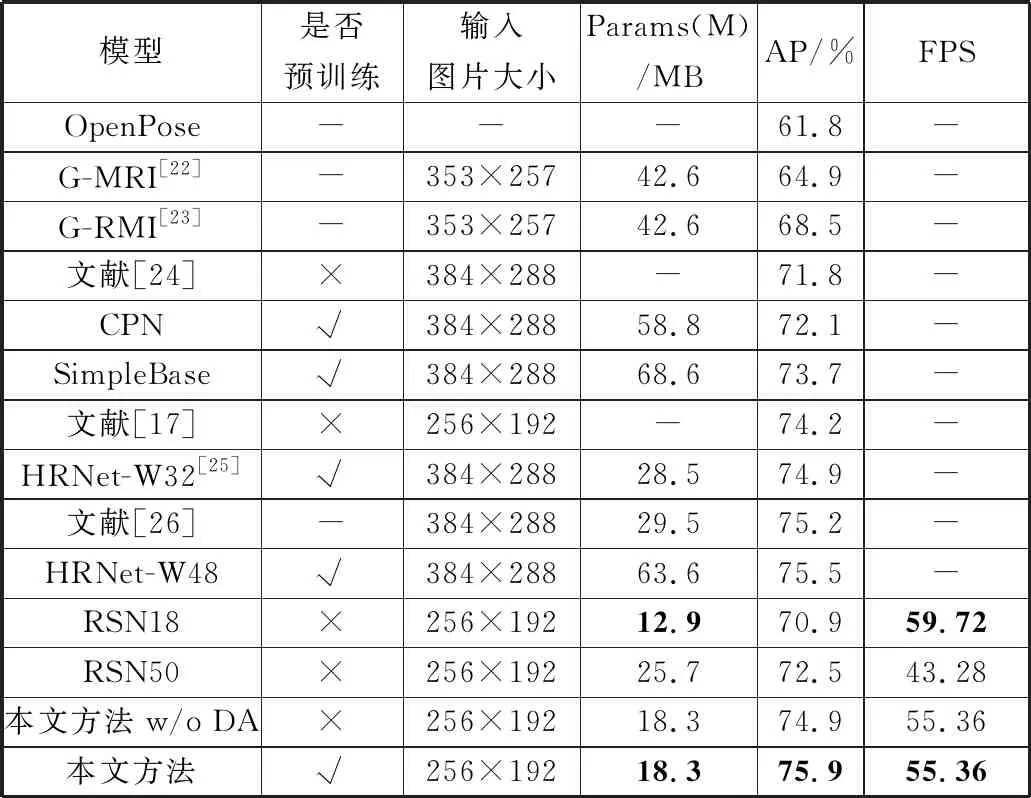
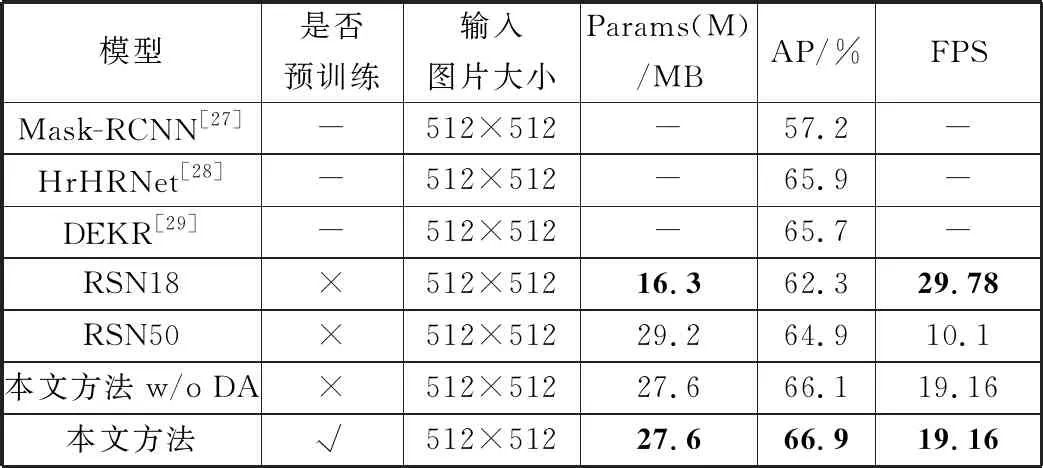
= = ∵当k>2,s>2时(k-2)×s-k≥0 又∵k2×s2-s2×(4k-4)-k2可以分解因式为[(k-2)×s+k]×[(k-2)×s-k] ∴k2×s2-s2×(4k-4)-k2≥0成立 ∴w2×[s2×(4k-4)+k2]≤w2×k2×s2 ∵P ∴P 因此,本文提出的通道切分模块相较于标准卷积计算复杂度更小,只需要更少的计算资源。 残差阶梯网络使用一种基于注意力的姿态修正机,如图2所示。本文在姿态修正机的基础上,对姿态修正机的空间注意力机制进行改进,提出了Context-PRM,如图8所示。 图8 Context-PRM结构 Context-PRM的空间注意力机制如公式(10): attentionspace=ContextAttention(DW(Conv1×1(Cin))) (10) 其中,Cin表示空间注意力机制的输入特征,Conv1×1表示1×1的卷积操作,DW表示深度可分离卷积,ContextAttention为本文提出的Context-Attention模块。Context-Attention模块的具体结构如图9所示。 图9 Context-Attention结构 输入特征首先分别经过2个1×1卷积,之后将输出特征的尺寸重塑(reshape)成二维,得到2个输出R、Q,其中N=H×W。Q进行转置,尺寸变成(N,C)。为了得到2个特征R和Q间的关联性,这里构造一个关联特征A=Q×R。接着,将A重塑到N×H×W的三维矩阵。为了将关联特征A归一化,本文采用平均池化+Sigmoid激活函数,将A的维度从三维变成二维,得到大小为H×W的注意力矩阵(Attention Matrix)。最后通过逐个元素相乘将注意力矩阵作用于第2条路径的特征。 3.1.1 实验数据 本文数据集使用COCO数据集[16]和CrowdPose数据集[17]。COCO数据集的训练集COCO train2017包含50000张行人图片和150000个人体标注实例。验证集COCO minival dataset包含5000张图片,测试集COCO test-dev包含20000图片,模型输入图像大小为256×192。 CrowdPose数据集包含较多拥挤的场景,相较于COCO数据集更具挑战性。其中训练集包括10000张图片,验证集包括2000张图片,测试集包括20000张图片,模型输入图像大小为512×512。 数据预处理:本文对数据集进行了数据增广,具体操作包括随机旋转、随机缩放、随机亮度调整、随机对比度调整、随机饱和度调整等图像增强方式。随机缩放的比例因子为0.7~1.35;随机旋转角度为-45°~+45°;随机亮度调整首先设定阈值为0.5,然后随机在区间(0,1)内抽取一个数a,如果a≥0.5,则亮度调整比例为a,如果a<0.5,则在区间(-a,a)内随机抽一个数b,调整比例即为b+1。随机对比度和随机饱和度的调整与随机亮度调整方法相同,阈值均取0.5。 本文方法的超参数如下:通道切分模块k=4,特征增强模块中分组卷积分组数g=2,COCO数据集共训练200轮,CrowdPose数据集共训练250轮,单批次训练样本数量(batch_size)为20。参数k值和分组卷积分组数g的确定将在实验部分进行详细阐述。本文使用基于Object Keypoint Similarity (Oks)[18]的平均准确率(Average Precision, AP)作为模型准确度的评价标准,每秒预测图片数量(Frames Per Second, FPS)作为模型预测速度的评价标准,Params(M)作为模型大小的评价指标。Oks定义为: (11) 其中,p表示某个人的id,pi表示某个人的第i个关节点,dpi表示预测的第i个关节点和真实关节点间的欧氏距离,vpi表示这个关节点在图片上是否可见,Sp表示这个人所占面积的平方根(根据人的标注框计算得到),σi表示第i个关节点的归一化因子,它是第i个关节点在数据集中坐标的标准差,σi越大,说明这个关节点在数据集上的坐标变化越大,否则说明它的坐标变化小。对于δ(vpi=1),如果vpi=1成立,那么δ(vpi=1)=1,否则δ(vpi=1)=0,这里表示仅计算真实值中已标注的关节点。计算基于Oks的平均准确率的步骤为:先设定阈值th,若某幅图片计算的Oks值大于th,表明该图片关节点检测有效,否则无效。本文的th=0.95。基于所有图片的检测结果,计算平均准确率AP的公式为: (12) FPS定义的公式为: (13) Params(M)定义为: (14) 3.1.2 实验平台 模型训练与测试在百度AI Studio平台进行,CPU是Intel(R) Xeon(R) Gold 6271C @ 2.60 GHz,GPU为Tesla V100,显存16 GB,内存32 GB。编程环境为Python3.7,深度学习框架为PaddlePaddle 1.8.4。 本文在4个Tesla V100 GPU上进行训练,优化方法选择Adam。为了加快模型的收敛,本文选择余弦学习率和指数移动平均的训练策略(Exponential Moving Average, EMA)。学习率和总训练轮数(epochs)的关系为: (15) 其中,begin_rate=0.0005为初始学习率,epoch为当前训练轮数,epochs为总的训练轮数。 为了使得模型参数平缓更新,本文在模型训练时采用指数移动平均策略。指数移动平均通过指数衰减方式计算参数更新过程中的移动平均值。对于每一个参数W,都有一个指数移动平均值Wt,如公式(16): Wt=α×Wt-1+(1-α)×W(t≥1) (16) 其中,α=0.998为衰减系数,t表示迭代次数,W0为0。 此外,本文在训练模型时也采用迁移学习策略,先在公开数据集ImageNet[19]上得到预训练权重,接着迁移到本文数据集上。预训练时,模型的超参数与训练时保持一致。 3.3.1 通道切分模块和特征增强模块作用 为了验证通道切分模块和特征增强模块的作用,本文在RSN18基础上依次加上通道切分模块和包含不同分组数的特征增强模块。从表1可以看出,相比于RSN18,增加了通道切分模块的Channel-Split RSN18的FPS降低了4.3,但AP提升了1.12个百分点。在使用特征增强模块后,分组卷积代替原来的3×3卷积,其分组数g分别取2、4、6,模型Channel-Split RSN18(g=2)、Channel-Split RSN18(g=4)和Channel-Split RSN18(g=6)的AP和FPS均高于未使用特征增强模块的Channel-Split RSN18。相较于RSN18,虽然Channel-Split RSN18(g=2)、Channel-Split RSN18(g=4)和Channel-Split RSN18(g=6)的FPS有所降低,但AP分别提升1.46、1.8、1.69个百分点。因此,本文提出的通道切分模块和特征增强模块对于模型检测准确率的改进是有效的。 表1 通道切分模块和特征增强模块的作用(未使用注意力机制) 此外,通过对比分组卷积的不同分组数(g=2、4、6)可以看出,使用4个分组的Channel-Split RSN18(g=4)相较于使用2个分组的Channel-Split RSN18(g=2),其AP和FPS分别增加0.34个百分点和0.4,而相较于使用6个分组的Channel-Split RSN18(g=6),虽然其FPS降低了0.5,但是AP提高0.11个百分点。在FPS差不多的情况下,考虑算法在AP上的性能,本文选择g=4的特征增强模块。 3.3.2 Context-PRM作用 为了衡量改进的空间注意力机制对姿态修正机的影响,本文实验对比了改进的姿态修正机(Context-PRM)和传统的姿态修正机(PRM)。 从表2可以看出,将Channel-Split RSN的姿态修正机替换为Context-PRM后,虽然模型检测速度有所下降,但模型AP提高了1.89个百分点。 表2 Context-PRM的作用 3.3.3 与主流注意力机制的对比 本文使用现阶段其他的主流注意力机制代替Context-PRM实现姿态修正机,并对比了它们的性能,如表3所示。 表3 不同注意力机制对比 Convolutional Block Attention Module(CBAM)[20]和SE-block[21]是具有代表性的注意力机制。从表3结果可以看出,在使用CBAM和SE-block后,RSN18的AP分别下降0.72和0.1个百分点。而改进的姿态修正机(Context-PRM)和传统的姿态修正机(PRM)在模型的AP上明显优于CBAM和SE-Block。 另外,本文也对比了不同的特征提取网络RSN18和RSN50。结果表明,在PRM上,RSN18和RSN50的AP分别提高1.59和0.38个百分点;在Context-PRM上,RSN18和RSN50的AP分别提高1.74和0.56个百分点。实验结果表明,Context-PRM比PRM对于模型AP提升更有效,同时相较于容量较大的RSN50模型,Context-PRM对于容量较小模型RSN18的AP提升更明显。 3.3.4 通道切分模块的k值选择 不同的k值对模型的准确率和预测速度有不同的影响,本文通过控制变量法确定k值,如图10所示。本文输入通道切分模块的通道数为512。通道切分模块将特征分成k个通道数相等的部分,即k=2n(n>1,k≥4)。从图10中的实验结果可知,当k=8和k=16时,虽然AP比k=4提升了0.28和0.41个百分点,但FPS比k=4分别低了6.15和16.03。在AP差不多的情况下,考虑算法在FPS上的性能,本文选择k=4。 (a) k与准确率曲线 3.3.5 COCO test-dev数据集上与主流姿态估计算法对比 前面的对比实验均在COCO minival dataset上进行。为了实验对比的公平性,本文将Channel-Split RSN和主流姿态估计算法在COCO test-dev上进行对比,实验结果见表4。 表4 COCO test-dev测试结果 从表4的实验结果可以看出,与主流人体姿态估计算法相比,本文方法在平均准确率上超过现阶段主要姿态估计算法,并且模型的Params(M)低于现阶段多数主流人体姿态估计算法。另外,即使未使用预训练和数据增广策略,本文方法的AP达到了74.9%,仅比HRNet-W48低0.6个百分点,比CPN提高2.8个百分点,比RSN18提高了4个百分点,比RSN50提高了2.4个百分点,而模型的Params(M)为18.3 MB,比HRNet-W48低45.3 MB,比CPN低40.5 MB,比RSN50低7.4个百分点,FPS提升了12.08。使用数据增广和预训练后,本文方法的AP达到了75.9%,比HRNet-W48高0.4个百分点,比RSN18高5个百分点,比RSN50高3.4个百分点。以上实验结果表明本文提出的方法是有效的。 3.3.6 CrowdPose数据集上与主流姿态估计算法对比 为了验证本文算法具有较高的鲁棒性和泛化能力,本文将Channel-Split RSN与主流人体姿态估计算法在更具挑战性的CrowdPose数据集上进行对比,实验结果如表5所示。其中,CrowdPose数据集上本文方法的超参数设置与COCO数据集一致。 表5 CrowdPose test-dev实验结果 从表5实验结果可以看出,在CrowdPose数据集上本文方法在平均准确率上超过主流人体姿态估计算法。未使用预训练和实验数据增广策略,本文方法达到66.1%的平均准确率,比Mask-RCNN高8.9个百分点,比HrHRNet提高0.2个百分点,比RSN18提高3.8个百分点。使用数据增广的策略后,本文方法的平均准确率达到66.9%,比DEKR提高1.2个百分点,比RSN50提高2个百分点;FPS达到19.16,比RSN50高9.06。以上实验结果均表明,本文方法在复杂的CrowdPose数据集上性能优于主流人体姿态估计算法。 本文分别将COCO数据集和CrowdPose数据集上的检测结果进行可视化。在COCO test-dev数据集上,本文可视化了本文方法、CPN、SimpleBase、HRNet-W32这4类人体姿态估计算法的实验结果。本文用直线将检测到的人体各个相邻关节点连接起来,如图11所示。实验结果显示,在单人场景下,本文方法的关节点定位比CPN和SimpleBase更加准确。多人场景下,相较于CPN、SimpleBase、HRNet-W32,本文方法能够对更多的人进行姿态估计。此外,在光线较暗的情况下,本文方法对多人人体姿态估计结果优于CPN、SimpleBase和HRNet-W32。可视化结果表明,本文方法在人体姿态估计方面准确率高、鲁棒性强。 单人场景 多人场景 光线较暗场景 在CrowdPose数据集上,本文可视化了本文方法、Mask-RCNN、HrHRNet共3类人体姿态估计方法的实验结果,结果如图12所示。CrowdPose数据集中主要以拥挤场景为主,本文从CrowdPose数据集中选择人在图像边缘(边缘场景)、人在图像中较远距离(目标较远场景)、人与人相互遮挡(遮挡场景)这3类典型场景进行可视化。从边缘场景的可视化结果可以看出,相较于Mask-RCNN和HrHRNet,本文方法能够有效地对图像边缘的人进行姿态估计。从目标较远的场景中可以看出,本文方法能够有效对图像中较远的人进行姿态估计。在遮挡场景中,本文方法相较于Mask-RCNN和HrHRNet,能够有效地对被遮挡的人进行姿态估计。以上实验结果表明本法方法在多人的复杂场景下仍然具有较好的鲁棒性和较高的检测准确率。 边缘场景 目标较远场景 遮挡场景 本文基于通道切分模块提出一种改进的人体姿态估计模型Channel-Split RSN。首先通过通道切分模块增强卷积特征提取能力,同时减少卷积的计算复杂度;接着通过特征增强模块减少特征通道的相似特征以获得更加丰富的特征表示;最后提出一种改进的姿态修正机Context-PRM,用于获得更准确的人体姿态关节点检测结果。在COCO test-dev上的实验表明,本文方法的AP达到75.9%,FPS达到55.36,相较于RSN18,AP提高了5个百分点。与现阶段主流姿态估计算法相比,本文方法在AP上优于主流姿态估计算法,且模型的Params(M)低于多数主流姿态估计算法。在更具挑战性的CrowdPose数据集上,本文方法达到66.9%的AP,模型性能优于主流人体姿态估计算法。 人体姿态估计是一个具有挑战性的问题,本文提出的Channel-Split RSN在COCO数据集和CrowdPose数据集上达到不错的效果。今后将从网络结构、注意力机制上进一步改进本文方法,使其具有更好的性能,并可应用到更多实际场景。2.3 Context-PRM算法

3 实验结果与分析
3.1 实验数据与平台
3.2 训练策略
3.3 实验结果分析

3.4 实验结果可视化


4 结束语
4.1 总结
4.2 展望
