基于卷积神经网络的字轮式仪表双半字符识别
2021-12-17徐望明伍世虔闫富海
王 望,徐望明,3,伍世虔,闫富海
(1.武汉科技大学信息科学与工程学院,湖北 武汉,430081;2.武汉科技大学机器人与智能系统研究院,湖北 武汉,430081;3.武汉科技大学冶金自动化与检测技术教育部工程研究中心,湖北 武汉,430081)
随着物联网的兴起,远程自动抄表技术已被广泛应用于各类指针式仪表[1]和字轮式仪表[2-3]中,如水表、电表、气表等,大大提高了工作效率和准确率。在字轮式仪表的远程自动抄表过程中,最为重要的一步就是对采集到的表盘图像中的数字字符进行准确识别。目前,国内外研究者已在字符识别方面做了大量工作,尤其是基于卷积神经网络(convolutional neural network, CNN)的端到端识别方法,在读取各种表盘上的完整数字字符时都取得了良好的表现。熊诚[4]采用基于Inception V1架构的CNN模型识别燃气表字符,在一定程度上解决了传统机器视觉方法对图像质量要求过高的问题;薛亮[5]采用LeNet-5网络进行迁移学习,实现了对水表字符的准确快速识别;熊勋等[6]结合CNN和长短期记忆(long short-term memory,LSTM)网络模型的特点构建了一种卷积记忆神经网络,在无需分割字符的情况下即可对电表字符序列进行准确识别。但对于字轮式表盘,其机械结构可能导致出现双半字符的情形,即在字轮上的某个位置,两个数字字符均出现了一部分。相较于完整字符,对双半字符的识别更加困难,更具挑战性。
目前,人们对仪表盘识别精度的要求越来越高,双半字符识别问题也亟待解决,但相关研究工作较少,主要采用的还是传统的特征提取[7]和模板匹配[8]方法。张艰等[7]利用扫描线穿过半字符的次数来提取字符结构特征进行识别,这种方法依赖于有效的特征设计,对图像质量要求也较高。徐平等[8]通过事先做好字符模板,采用模板匹配的方法来识别双半字符,这种方法鲁棒性较差,两个半字符相邻间隔大小、字符样式以及噪声干扰都会影响识别结果,而且对不同类型的表盘都需要重新制作字符模板。另外,基于CNN的字符识别方法不能直接用于双半字符识别的主要原因是,在实际应用中能采集到的双半字符样本较少,不足以训练CNN模型,而且对实际的双半字符图像直接采用旋转、镜像、平移等深度学习领域中常用的数据增强方法[9]也不合适。
针对以上问题,本文提出一种新的基于卷积神经网络的字轮式仪表双半字符识别方法。为了获取足够多的双半字符样本并实现对双半字符的鲁棒识别,运用从实际采集的完整字符样本随机生成双半字符样本的数据增强方法,并通过生成的双半字符样本集来训练一个专门设计的CNN模型用于识别双半字符,最后通过实验来验证该方法的有效性。
1 双半字符识别方法的基本流程
本文方法的主要思路是:①为了从采集的表盘图像中区分出完整字符和双半字符,采用图像预处理和投影分割算法分离出二值化后的完整字符和双半字符;②CNN模型的训练依赖于充足的样本,为了解决双半字符训练样本不足的问题,提出一种从现有完整字符样本生成双半字符样本的方法;③为了使训练的CNN模型取得较好的识别性能,专门设计了一个用于双半字符识别的CNN网络结构。
本文方法的基本流程如图1所示,可分为离线和在线两个过程。离线过程训练用于识别双半字符的CNN模型:先收集完整字符样本,上下对齐拼接相邻完整字符,并随机截取子图像生成双半字符样本,利用这些样本训练所设计的CNN网络,就可得到所需的CNN模型。在线过程实现对所输入字轮式表盘图像中的字符识别:首先进行图像预处理,包括灰度化、去噪、去倾斜、字符区域定位、字符区域二值化等;然后对字符区域二值化图像利用垂直投影和水平投影算法分割出单个字符,判定是完整字符还是双半字符;最后利用离线训练好的CNN模型分别对完整字符和双半字符进行识别。其中,完整字符识别也采用离线单独训练好的CNN模型,由于此类方法众多且相对成熟,本文不对其展开,而是以燃气表自动读数为例,重点介绍所提出的双半字符识别方法。
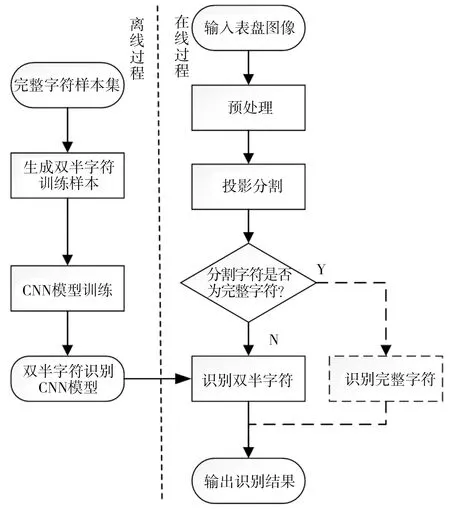
图1 双半字符识别方法的流程
2 双半字符识别方法的实现细节
2.1 图像预处理
在远程自动抄表系统中,由于仪表安装位置、拍照环境、图像网络传输等因素影响,采集的表盘图像可能存在倾斜和噪声,因此图像首先需要经过预处理操作。本文方法的图像预处理过程包括灰度化、去噪、去倾斜、字符区域定位、字符区域二值化等,目的是得到表盘字符区域的一幅较干净的二值化图像,具体的实现方法很多,这里不展开描述。假设图2是初步定位好的燃气表字符区域子图像,下面只给出几个重要的中间结果图像进行说明。

图2 燃气表图像字符区域的双半字符示例
对于图2中最上面一幅图像,去倾斜后的字符区域灰度图如图3(a)所示,使用SWT算法[10]进行二值化处理后的结果如图3(b)所示,最后根据字符高、宽、面积以及高宽比等约束条件去除二值化图噪声后的结果如图3(c)所示。

(a)去倾斜后的字符区域
2.2 字符分割
对于预处理后的二值化图像,通过垂直投影和水平投影,结合投影直方图的特点确定单个字符的位置[11],估计字符标准高度、标准宽度以及位置相邻字符的间隔,进一步确定每个字符是完整字符还是半字符,并将其从二值图像中分割出来。
以图4为例来说明。图4(a)的垂直投影直方图如图4(b)所示,其中白色部分反映了水平轴每点对应的垂直方向白色像素的累计值。根据字符的特点,每个字符在垂直投影图上的高度和宽度满足一定大小,可以很容易区分出残留的噪声,并且定出每个字符的位置。图4(c)为从图4(a)中初步分割出来的完整字符和双半字符,这些字符的水平投影直方图如图4(d)所示,可以看到双半字符投影图像呈现两段白色区域,而完整字符投影图像是一段连续白色区域。为了消除残留噪声的影响,对检测到的白色区域高度与预估字符平均高度进一步比较,即可区分完整字符与双半字符。

(a)去噪图像(仍可能含有残留噪声)
由于表盘规格和拍摄角度的不同,上述直接分割出来的双半字符图像中两个半字符之间的间隔大小很可能不相等,为了使得字符识别算法能够统一识别,需要对图像进行后处理。如图5所示,分割出来的字符通过水平投影后,消除水平投影直方图中两段白色区域间的间隙,保留白色区域对应的字符并合并,最后将尺寸归一化为W×H,这样处理可以保证不同规格的表盘都可以有效识别。完整字符也按相同方式处理,不同之处在于完整字符的水平投影图只有一段白色区域,不存在间隙,可直接保留白色区域对应的字符并将尺寸归一化为W×H。这样就从预处理后的二值图中将完整字符和双半字符都准确分割出来,再输入CNN模型进行数字识别。
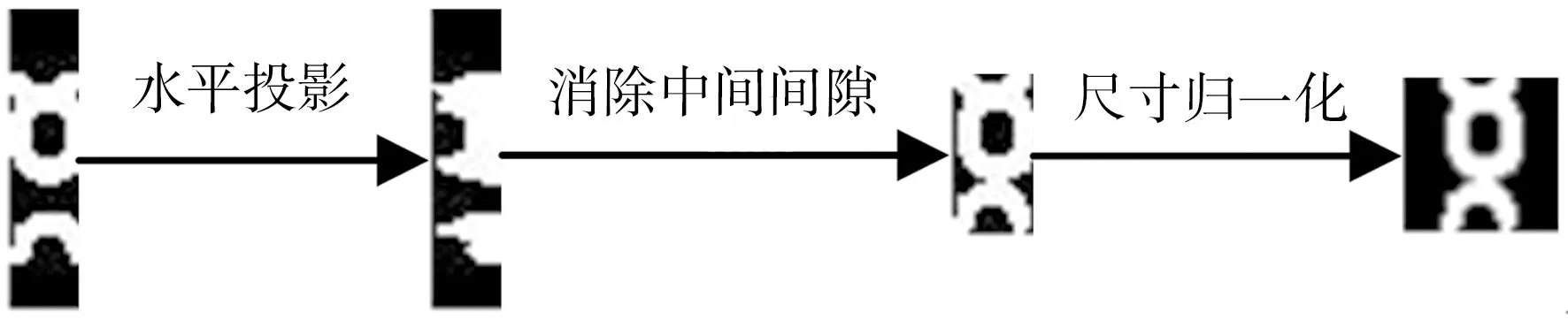
图5 双半字符后处理流程
2.3 双半字符识别CNN模型
鉴于传统识别方法的鲁棒性较差,本文采用卷积神经网络来识别双半字符。由于从实际表盘中采集足够的双半字符样本来训练CNN模型比较困难,本文采用从实际采集的完整字符样本生成双半字符样本的简便方法,如图6所示,其具体步骤为:
(1)从实际采集的完整数字字符图像中随机获取一组相邻数字字符,并将像素尺寸归一化为W×H(本文取W=H=28);
(2)将相邻数字字符按其数值大小进行上下对齐拼接,小的在上,大的在下,拼接图像大小为W×2H;
(3)在区间[0.2,0.8]上取一个随机数α,从上述拼接图像上截取纵坐标从αH到(1+α)H的部分,即从拼接位置向上取αH高度的上半字符,向下取(1-α)H高度的下半字符,从而得到一个尺寸为W×H的双半字符样本;
(4)该双半字符样本的标签取相邻数字字符高度占比大的字符标签(当上、下字符均占1/2时,则取上字符标签),即当0.5≤α≤0.8时取上半字符标签,当0.2≤α<0.5时取下半字符标签。

图6 双半字符样本的生成
由于实际表盘中能采集到的完整字符数据量较为充足,并且在生成双半字符时可随机组合相邻完整字符,并按随机高度比例截取子图像进行拼接,故可保证最终生成的双半字符样本数量充足、形式多样,且更加接近真实的双半字符样本。部分生成的双半字符样本如图7所示。
与传统方法相比,深度神经网络在样本充足且多样的情况下,可大幅改善双半字符识别的鲁棒性。在各种深度神经网络中,CNN是应用最广泛的一种,其基本结构包含卷积层、池化层和全连接层,其中,卷积层用于提取特征,池化层可压缩卷积层得到的特征图,全连接层起到分类的作用。

图7 生成的双半字符样本图例
由于字符图像较小,不适合使用太深的网络结构,本文采用的CNN模型共有4个卷积层(带有标准化层和池化层)、1个全局平均池化层和2个全连接层。网络结构如图8所示,第一卷积层采用16个5×5的卷积核(stride=1,pad=2),对输入大小为28×28的单通道图像进行特征提取,并依次经过标准化层、激活层和池化层(stride=1,pad=0);第二卷积层采用32个3×3的卷积核(stride=1,pad=1),对第一层池化后的特征图进行特征提取;第三和第四卷积层的卷积核个数分别为64和128,大小均为3×3(stride=1,pad=1)。采用全局平均池化层(Global Average Pooling)代替全连接层与最后一个卷积层的池化层相连,可防止过拟合,在本文方法中主要起到了将卷积形式的数据转换为神经元形式的作用,最后连接两个全连接层得到10个数字分类概率。另外,在模型中加入的标准化层可抑制过拟合,防止梯度消失和梯度爆炸。本文CNN模型的总参数量为107 786。
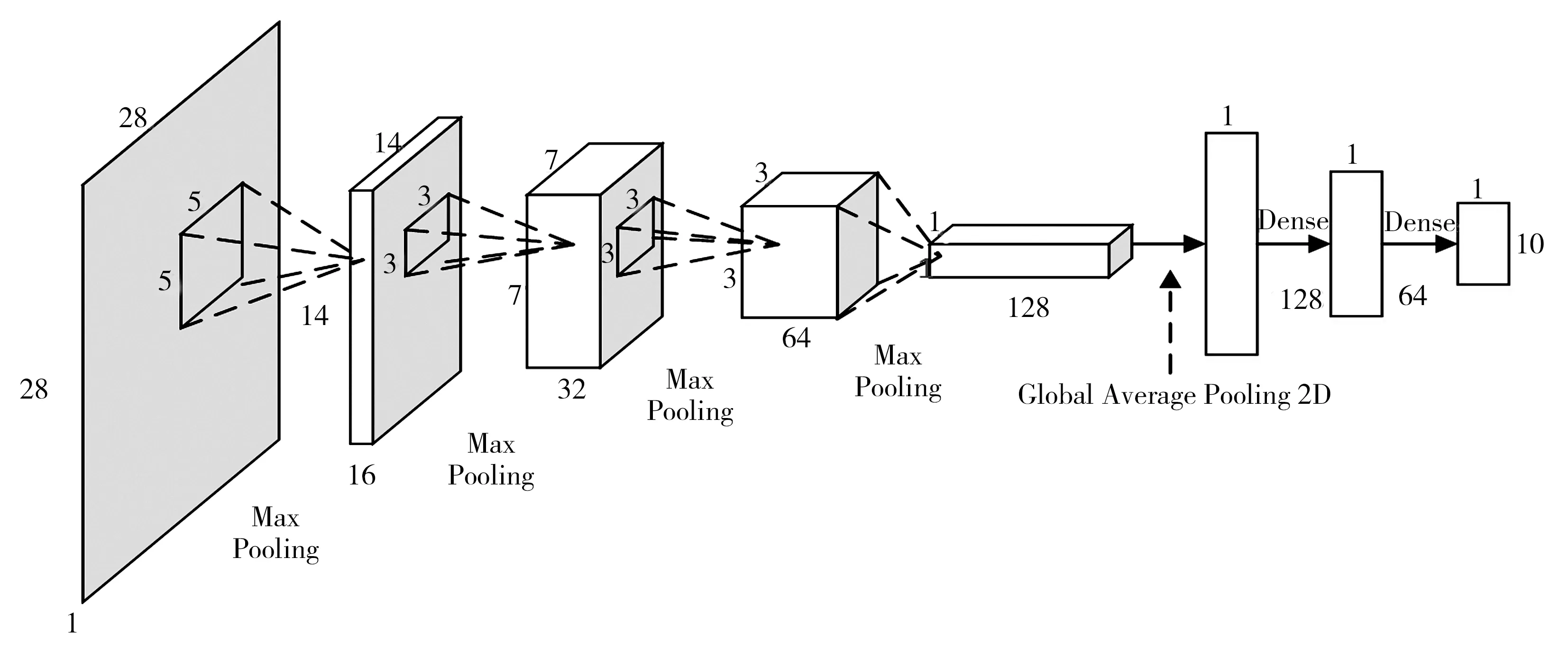
图8 本文方法使用的卷积神经网络结构
3 实验与结果分析
为了验证本文方法的有效性,以实际的燃气表表盘数字图像为例,通过本文方法从20 971幅完整字符样本中生成10 000幅双半字符样本作为训练集,从另外600幅完整字符样本中采用相同方法生成1000幅双半字符样本作为测试集1,并在实际表盘图像中提取114幅真实的双半字符样本作为测试集2,进行双半字符识别实验。对比了传统的模板匹配法、支持向量机(SVM)分类法[12]、HOG+SVM 方法[13-14]、LeNet-5卷积神经网络方法[15]以及本文方法。其中,模板匹配法采用标准化差值平方和的方式判断模板图像与待匹配图像之间的相似程度,标准化差值平方和越小表明相似程度越高;在SVM方法中,选用高斯核函数,直接使用像素值排列作为特征向量;HOG+SVM 方法是在HOG特征提取后再进行SVM分类;LeNet-5是经典的卷积神经网络之一,主要有2个卷积层、2个池化层和3个全连接层。在测试集1和测试集2上的实验结果分别如表1和表2所示。

表1 生成的双半字符(测试集1)识别结果
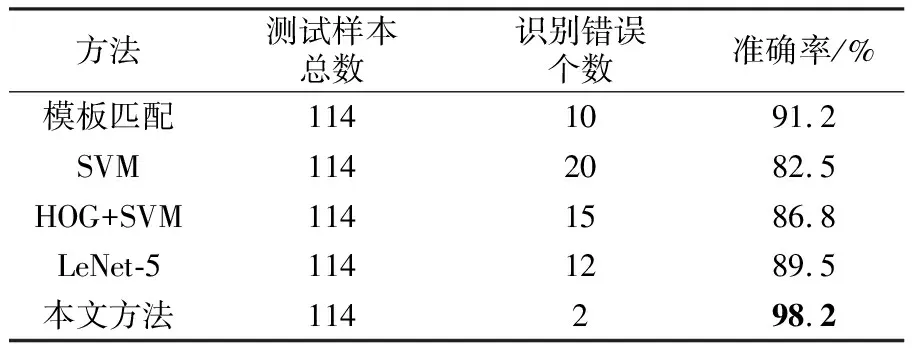
表2 实际采集的双半字符(测试集2)识别结果
实验结果表明:传统的模板匹配方法在两个测试集上的表现比较稳定,但识别准确率都远不如本文方法;两种基于SVM的机器学习方法,在测试集1上表现很好,但在测试集2上表现较差,说明其对实际样本的适应性较差,而本文方法鲁棒性要更好,准确率也更高;LeNet-5网络在测试集1和测试集2上都可以有效地识别双半字符样本,然而识别准确率却受网络所限,低于本文方法;本文方法通过设计一个专门的CNN网络结构,在两个数据集上均取得了最高的识别准确率。
4 结语
双半字符图形时常会出现在字轮式表盘中,为了解决远程自动抄表系统中双半字符识别难题,本文提出了一种基于卷积神经网络的双半字符识别方法,其特点在于专门设计了一个CNN模型,并根据实际采集的完整字符样本来随机生成充足而多样的双半字符样本来训练该CNN模型,解决了实际双半字符样本较少以及识别准确率不高的问题。以燃气表自动读数为例,在生成的双半字符测试集和真实的双半字符测试集上开展实验,并与传统的模板匹配方法、SVM方法以及LeNet-5方法进行对比,验证了本文方法的有效性。本文方法同样适用于水表、电表等其他字轮式仪表的自动抄表系统。
