基于深度学习与子域适配的齿轮故障诊断
2021-12-02揭震国王细洋龚廷恺
揭震国 王细洋 龚廷恺
1.南昌航空大学飞行器工程学院,南昌,330063 2.南昌航空大学通航学院,南昌,330063
0 引言
齿轮及齿轮箱是金属切削机床、直升机动力传动系统等设备中常用的传动部件,据统计,这些设备80%的机械故障由齿轮引起[1],因此,齿轮故障诊断对降低设备维修费用和防止突发性事故具有重要意义。
近年来,深度学习成为机械智能故障诊断的一种主流趋势[2],其中,卷积神经网络(convolutional neural network, CNN)是一种代表性方法。CNN是图片和视频识别领域应用最为广泛的方法,已被广泛应用到故障诊断领域。ZHANG等[3]将一种基于自适应批归一化的第一层宽卷积核深度卷积神经网络模型用于故障诊断。吴春志等[4]针对传统故障诊断方法难以解决端对端故障识别的问题,提出了一维卷积神经网络的故障诊断方法。胡茑庆等[5]针对行星齿轮箱需要专家知识才能实现故障识别的问题,提出了一种经验模态分解和CNN相结合的智能故障诊断方法。但CNN的诊断效果受限于两个条件:一是CNN需要大量的已标注训练集才能达到令人满意的识别率;二是CNN要求训练集和测试集具有相同的分布。然而,在生产实际中难以满足以上两个条件,这会影响CNN的泛化能力,甚至使模型不再适用[6]。
近年来,深度迁移学习成为解决以上问题的一种主流方法,其模型的研究取得了很大进展[7-10],并被应用到故障诊断领域。LI等[11]为了解决轴承数据域差异的问题,提出了一种多层域适配模型。YANG等[12]提出了一种将实验室轴承数据迁移到机车轴承数据的故障诊断方法,该方法采用多层域适配和伪标记学习。HAN等[13]提出了一种基于联合分布适配的深度迁移学习框架,通过将边缘分布适配扩展到联合分布适配来提高分布适配的准确度。
以上深度迁移学习方法虽然在故障识别方面取得了一定的效果,但存在以下两个问题:一是用于特征提取的CNN模型性能较差,影响了迁移效果;二是仅考虑全域的分布差异,而没有考虑相关子域的分布差异。针对以上问题,本文提出了基于深度学习与子域适配的齿轮故障诊断方法:首先构建一维卷积神经网络,从源域数据和目标域数据中提取可迁移特征;然后采用多核-局部最大均值差异来测量可迁移特征相关子域的分布差异,并将测得来的分布差异作为反向传播的优化目标;最后使用训练完成的模型识别无标签目标域的健康状况。
1 卷积神经网络、最大均值差异及域适配
1.1 卷积神经网络
CNN最大的优势是可以直接从数据中自动学习特征,无需人工提取即可实现高效的识别。CNN的单元结构主要包括卷积层、池化层和全连接层。
卷积层是CNN的核心,它的主要作用是提取输入的不同特征,低层卷积层提取低级的特征,高层卷积层提取更深层的特征。卷积层的计算公式如下:
X(l)=X(l-1)*K(l)+B(l)l=1,2,…,L
(1)
式中,X(l-1)、X(l)、K(l)、B(l)分别为第l个卷积层的输入矩阵、输出矩阵、权重矩阵、偏置矩阵;符号“*”表示卷积运算符;L为CNN的卷积层数。
池化层又称下采样,主要作用是通过减少网络的参数来减小计算量,并在一定程度上控制过拟合。最大池化是最常用的池化方法,其计算公式如下:
V(l)=max(A(l)(St+1),A(l)(St+2),…,
A(l)(St+W))
(2)
t=0,1,…,M(l)-1
式中,V(l)为第l个池化层的输出矩阵;A(l)为X(l)的激活向量;S、W分别为池化核的步长、大小,一般S=W;M(l)为第l个池化层的平均段数。
全连接层是一个常规的网络结构,它的作用是全连接经过多次卷积和池化所得的高级特征,输出对结果的预测值。全连接层的计算公式如下:
XF=Z*KF+BF
(3)
式中,XF、KF、BF分别为全连接层F1的输出矩阵、权重矩阵、偏置矩阵;Z为第L个池化层的展开向量。
一般采用Softmax回归进行结果预测,Softmax回归的计算公式如下:
(4)
式中,θ为模型的待训练参数;C为数据的故障类别数;p为样本xi属于类别c的概率值;Pi为样本xi的概率分布向量。
1.2 最大均值差异
作为一种衡量分布差异的非参数距离指标,最大均值差异(maximum mean discrepancy, MMD)被广泛应用于测量源域和目标域的分布差异。MMD的计算流程[14]如下:在同一个映射函数下将源域和目标域映射到一个再生核希尔伯特空间(reproducing kernel Hilbert space, RKHS),然后计算两域的分布差异。MMD的线性无偏估计表示为
(5)
式中,H表示RKHS;Ds、Dt分别为源域、目标域;p、q分别为源域、目标域的分布;ns、nt分别为源域、目标域的样本数;xs、xt分别为源域、目标域中的样例;k(·)为核函数。
1.3 域适配
近年来迁移学习被广泛应用到各个领域,迁移学习的定义如下[6]:给定一个源域Ds和学习任务Ts,一个目标域Dt和学习任务Tt,使用Ds和Ts中的知识提升Dt中目标预测函数f(·)的学习,其中,Ds≠Dt或Ts≠Tt。
在训练数据和测试数据之间的分布存在差异的情况下,学习一个有判别力的模型称为域适配。LONG等[8]提出了深度适配网络(deep adaptation network, DAN),将深度卷积神经网络应用到域适配场景。DAN实现了网络AlexNet[15]的多层适配和基于多核-最大均值差异的适配层。DAN的优化目标由以下两部分组成:源域和目标域的损失函数,源域和目标域的分布距离。优化目标可表示为
(6)
式中,a为源域和目标域有标签的样本;J(·)为损失函数;λ为平衡系数,λ>0。
2 基于深度学习与子域适配的齿轮故障诊断
针对标注故障数据不足的问题,本文提出了深度学习与子域适配的齿轮故障诊断方法。本方法由特征提取、子域适配和模式识别三部分组成:①特征提取由一维卷积神经网络从源域数据和目标域数据中提取可迁移特征;②子域适配首先使用多核-局部最大均值差异测量可迁移特征相关子域的分布差异,然后将测得的分布差异作为目标函数的一部分训练优化;③模式识别利用训练完成的模型识别目标域的健康状况。所提方法流程图见图1。
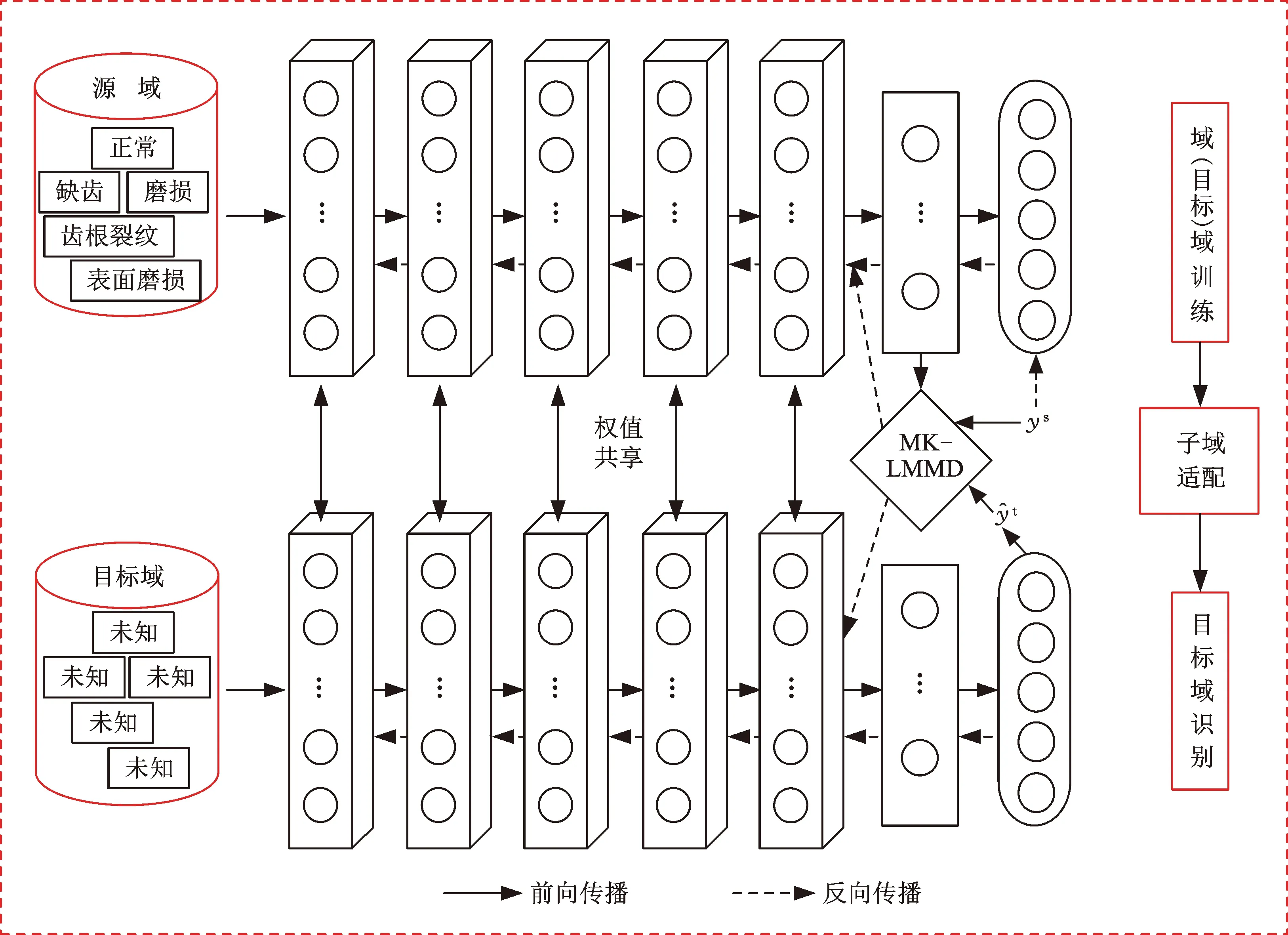
图1 基于深度学习与子域适配的齿轮故障诊断方法流程图Fig.1 Flow chart of gear fault diagnosis based on deep learning and subdomain adaptation
2.1 一维卷积神经网络
针对一些深度迁移学习方法用于特征提取的CNN模型性能较差的问题,本文提出了一维卷积神经网络(one dimensional convolutional neural network, 1D-CNN),1D-CNN在AlexNet的基础上进行了改进,具体改进如下:
(1)采用一维卷积核和第一层宽卷积核。一维卷积核可以直接从一维的振动信号中提取特征,第一层宽卷积核可以提取输入信号的短时特征。
(2)去除局部响应归一化层和第二个全连接层。局部响应归一化层提升网络性能并不明显,可采用Dropout层代替,它可以有效提升网络的识别性能和抑制过拟合。第二个全连接层在齿轮故障诊断中对识别率影响不大,但会增加大量的训练参数。
一维卷积神经网络的结构共有7层,包含5个卷积层、2个全连接层,结构见表1,其中,Dropout层的弃置率为50%。

表1 1D-CNN结构Tab.1 Structure of 1D-CNN
2.2 多核-局部最大均值差异
源域与目标域的数据来源于不同的工况导致1D-CNN提取出的可迁移特征有较大的分布差异。为此,采用多核-局部最大均值差异(multi-kernel local maximum mean discrepancy, MK-LMMD)来测量可迁移特征相关子域的分布差异,MK-LMMD可定义为
(7)
式中,p(c)、q(c)分别为源域、目标域中类别c的分布;E(·)为数学期望;f(·)为映射函数(即高斯核函数)。
假设每个样本属于类别c的权重为w(c),那么样本xi的权重可定义为
(8)
式中,yic为独热向量yi的第c项。
基于高斯核函数将源域与目标域的可迁移故障特征从原空间嵌入RKHS,MK-LMMD的线性无偏估计可表示为
(9)
式中,Asf、Atf分别为源域、目标域第f层的激活向量。
MK-LMMD的效果取决于核函数的选择,核函数选择不当将影响其在域适配中的应用,为此引入最优多核选择方法[16]。多核高斯核函数凸组合为
(10)

2.3 子域适配
子域适配将MK-LMMD测得的分布差异作为目标函数的一部分进行训练,以最小化子域的分布差异。不同于域适配,子域适配不仅能对齐源域与目标域的全局分布,还能对齐相关子域的分布。域适配与子域适配的效果示例图见图2。本文根据类标签将一个领域下同一类别的样本划分到一个子域中。

图2 域适配与子域适配的效果示例图Fig.2 Effect sample diagram of domain adaptation and subdomain adaptation
由图2可知,域适配后,源域与目标域的全局分布几乎一致,但两子域分布的间距很小,这将导致分类错误。子域适配后,源域与目标域的全局分布和子域分布几乎都达到了一致。综上,子域适配可以有效地提高分类精度。
最小化式(9)可实现两个领域间的全局分布和子域分布的同时适配,即子域适配的优化目标为

(11)
(12)
式中,τ-2为估计方差。
综上,子域适配的优化目标可表示为
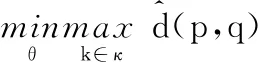
(13)
2.4 模型的训练
(14)
结合式(6)、式(13)、式(14)构建以下目标函数:
(15)
式中,α为伪标签的惩罚系数。
由式(15)可知,模型的优化目标由三部分组成:源域的损失函数、目标域的损失函数及源域与目标域相关子域的分布距离。目标函数的具体训练过程如下:
(3)反向传播。①优化算法选用ADAM,反向更新待训练参数集θ;②执行步骤(2)。
3 实验验证
3.1 数据集描述
齿轮正常和故障状态下的振动信号采集于美国SQI公司的DPS故障预测综合实验台,其结构由电机、行星齿轮箱、平行齿轮箱和负载齿轮箱等组成,如图3所示。实验在平行齿轮箱上进行,平行齿轮箱齿轮为渐开线直齿圆柱齿轮,齿轮箱结构简图见图4,图中N1~N4分别表示输入轴齿轮、中间轴大齿轮、中间轴小齿轮、输出轴齿轮的齿数。在中间轴小齿轮上人工植入磨损、表面磨损、缺齿、齿根裂纹故障,如图5所示。

图3 实验台Fig.3 Test rig
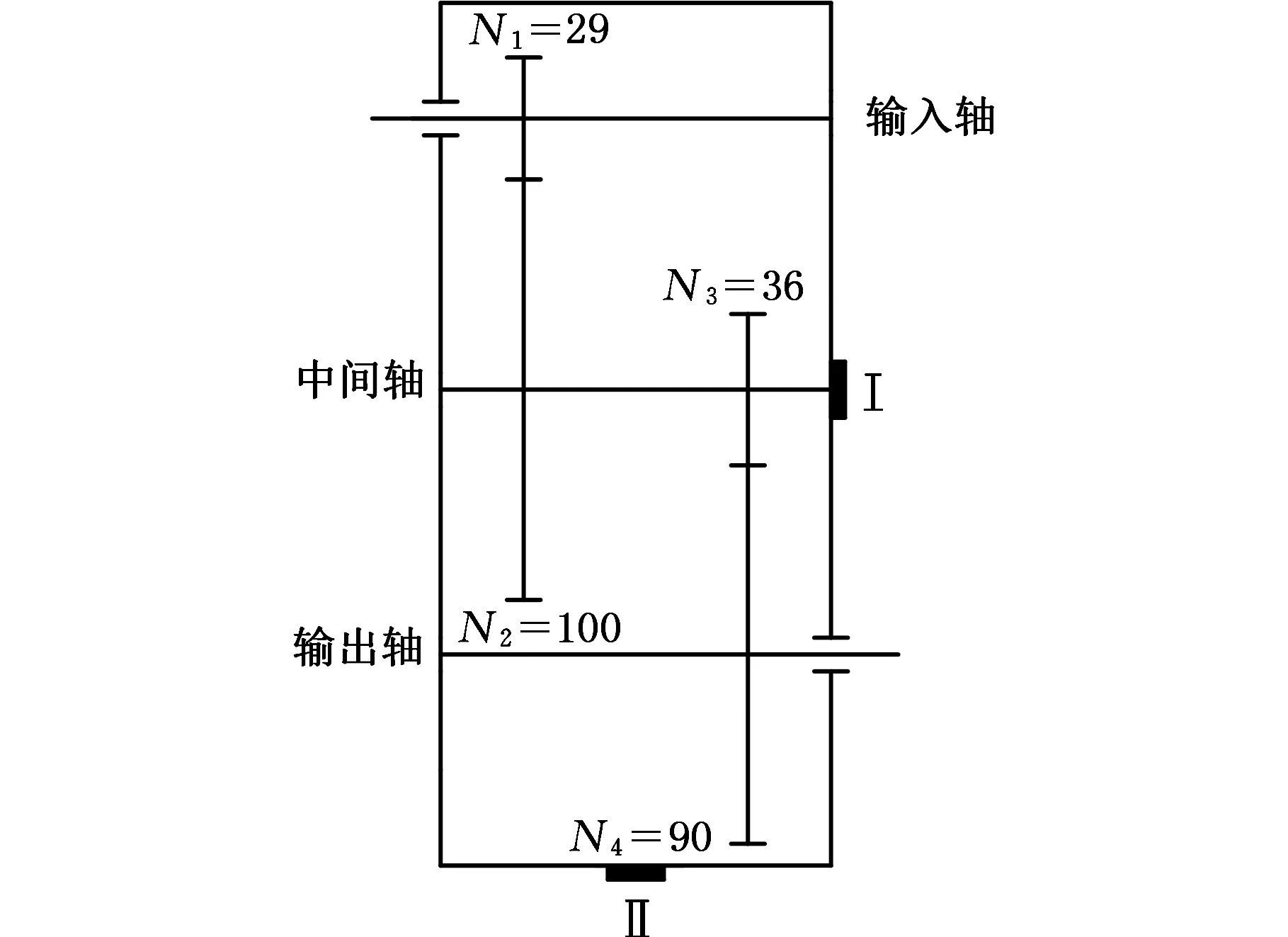
图4 平行齿轮箱结构简图Fig.4 Structure diagram of parallel gearbox

(a)正常 (b)缺齿 (c)表面磨损
采用三轴加速度传感器采集齿轮振动信号,采样频率为20.480 kHz,在电机转速1800 r/min和4种不同负载(0、0.45 N·m、1.35 N·m与0~1.8 N·m变负载)工况下采集齿轮振动信号。以1024个采样点截取样本,得到数据集A、B、C和变工况下的数据集D,按照4∶1的比例将数据集分成训练集与测试集,各数据集的详细信息见表2。为模拟生产实际中带标签故障数据不足的状况,在模型的训练过程中,数据集B、C、D的样本无标签。
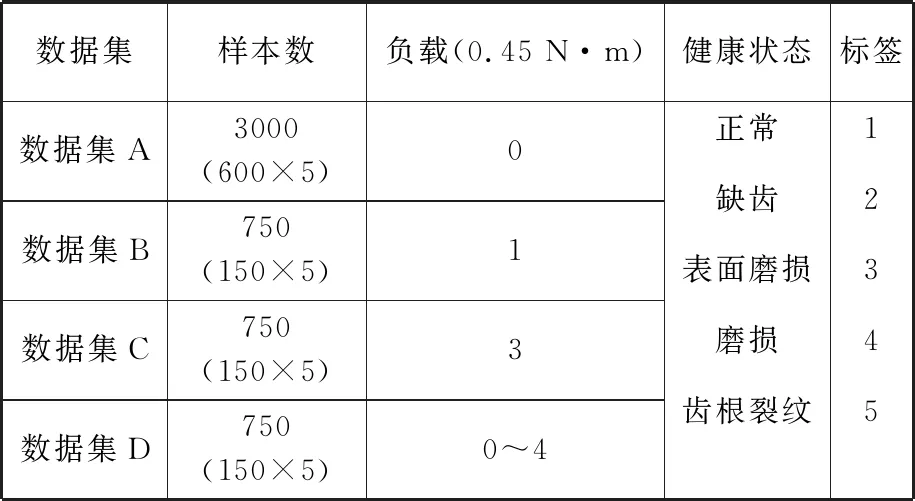
表2 数据集的详细信息Tab.2 Details of the datasets
3.2 对比实验
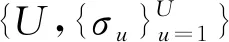
(16)


(17)
(18)
式中,e为训练次数;αf=1[18];γ=10[19];αe为随训练次数变化的惩罚系数α;λe为随训练次数变化的平衡系数λ。
对比实验以类标签为子域划分依据,同一类别的样本划分到一个子域中。为了保证实验结果的稳定性,每种算法重复10次实验。
在1D-CNN的结构参数优化过程中发现,第一个卷积层的卷积核大小和全连接层单元数对故障的诊断结果影响较大,结果见表3与表4。

表3 卷积核大小对诊断结果的影响Tab.3 Effect of kernel size to diagnosis result

表4 全连接层单元数对诊断结果的影响Tab.4 Effect of fully connected layer neural number to diagnosis result
由表3可知,第一个卷积层选用较大的卷积核可以有效提高诊断精度,但当卷积核大于64×1时,诊断精度逐步降低。由表4可知,全连接层单元数增大可以有效提高诊断精度,但当单元数大于128时,诊断精度逐步降低。
为研究多核核函数集系数、惩罚系数和平衡系数对诊断结果的影响,分别以这些参数为变量进行对比实验。其中,核函数数量-步长(u-ζ)从{[5-2], [7-2], [3-2], [5-22], [5-20.5]}中取值,惩罚系数α从{αe, 0.01, 0.1, 0.5, 1}中取值,平衡系数λ从{λe, 0.01, 0.05, 0.1, 0.2}中取值。以下实验为所提方法在迁移任务A→B上的诊断结果,各参数不同时为变量,如以核函数数量-步长为变量(常量下为5-2)时,惩罚系数和平衡系数为“常量”αe和λe,结果见表5~表7。

表5 核函数数量和步长对诊断结果的影响Tab.5 Effect of kernel number and step-size to diagnosis result

表6 惩罚系数对诊断结果的影响Tab.6 Effect of penalty parameter to diagnosis result

表7 平衡系数对诊断结果的影响Tab.7 Effect of tradeoff parameter to diagnosis result
由表5可知,核函数数量U和步长过大或过小都会降低诊断精度,U=5及ζ=2时诊断结果最佳。由表6可知,当α<0.5时,增大α可以提高诊断精度;当α>0.5时,增大α则会降低诊断精度,而随着训练次数变化的αe诊断结果最佳。这是因为α过大会干扰标签数据的训练,过小会导致伪标签数据无效果,而αe不仅可以解决以上问题,还可以避免局部最优。由表7可知,当λ<0.1时,增大λ可以提高诊断精度;当λ>0.1时,增大λ则会降低诊断精度,而随着训练次数变化的λe诊断结果最佳。这是因为λ的主要作用是平衡训练过程中的训练损失与子域分布差异,而λe可以抑制训练早期的适配层噪声。
为了证明1D-CNN模型在齿轮故障特征提取上的有效性,将其与ML-MK-I(multi-layer multi-kernel integrated objective)[11]、FTNN (feature-based transfer neural network)[12]和DTN-JDA(deep transfer network with joint distribution adaptation)[13]用于特征提取的CNN模型在数据集A上进行比较,结果如图6所示。

图6 准确率对比图Fig.6 Comparison diagram of accuracy
由图6可知,ML-MK-I与FTNN的CNN准确率较低。其中,ML-MK-I的准确率为84.50%,FTNN的准确率为85.50%。这是因为它们的CNN结构较为简单,且第一个卷积层的卷积核较小。而DTN-JDA的CNN与1D-CNN都采用宽卷积核和Dropout结构,其准确率较ML-MK-I与FTNN有了较大的提高,分别达到97.72%、99.02%,但通过查看DTN-JDA的训练过程发现其完成模型训练所需的计算资源远大于1D-CNN的计算资源。这可能是因为DTN-JDA的第二个全连接层占用了较大的计算资源。综上,1D-CNN模型较其他深度迁移学习方法的CNN网络在齿轮故障特征提取上具有一定的优势。
为了证明所提方法的优越性,将其与1D-CNN、基于1D-CNN的域适配网络(1D-CNN-based domain adaptation network, 1D-DAN)、FTNN和DTN-JDA在迁移任务A→B、A→C与A→D上进行比较。其中,1D-CNN不进行特征的分布适配,1D-DAN只进行基于最大均值差异的域适配,结果如图7和表8所示。

图7 迁移结果对比图Fig.7 Comparison diagram of transfer results

表8 迁移结果对比Tab.8 Comparison of transfer results
由图7和表8可知,1D-CNN的准确率不高,仅为64.04%,这是因为1D-CNN虽可以提取出深层的可迁移特征,但缺少可迁移特征分布适配的过程,不能减小可迁移特征的分布差异。FTNN和DTN-JDA都进行了可迁移特征的分布适配,准确率较1D-CNN有了较大的提高。1D-DAN的准确率较1D-CNN有一定的提高,但低于本文方法,这是因为1D-DAN虽进行了可迁移特征的域适配,但其分类效果不及子域适配。对比迁移结果可知:
(1)相比其他方法,本文方法具有更高的迁移准确率。一方面是因为1D-CNN能够提取出更为深层的可迁移特征;另一方面是子域适配可以同时减小可迁移特征的全局分布差异和子域分布差异。
(2)FTNN的特征提取网络性能较差,难以提取深层的可迁移特征,而DTN-JDA将边缘分布适配扩展到联合分布适配,提高了分布适配的准确度,故迁移准确率从大到小排序为:本文方法,DTN-JDA,1D-DAN,FTNN,1D-CNN。
为了进一步对比分析不同诊断方法的差异性,使用t-分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法可视化1D-CNN、1D-DAN与提出方法在迁移任务A→D上的分类结果,以散点图形式呈现,如图8所示。
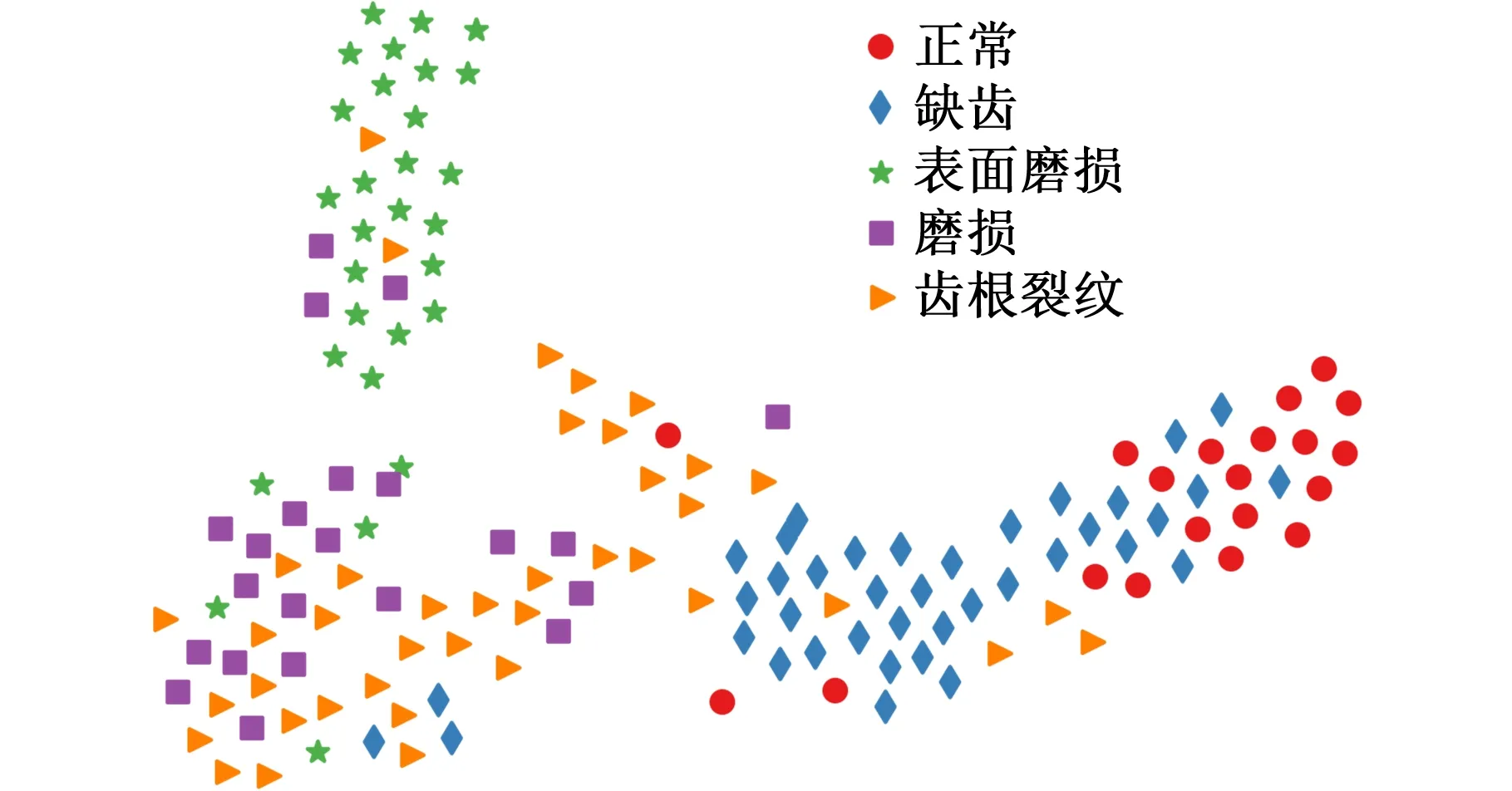
(a)1D-CNN
由图8可知,1D-CNN没有起到缩小故障特征的类内距离和增大类间距离的效果,故无法正确识别数据集D的健康状况。而1D-DAN虽一定程度上缩小了故障特征的类内距离,但没有增大类间距离,故存在错误分类的情况。本文方法在缩小数据集D故障特征类内距离的同时增大了类间距离,故分类效果较好。综上,本文方法通过子域适配缩小了源域与目标域可迁移特征的类内距离,增大了类间距离,使模型能够识别目标域的健康状况,直观地解释了本文方法的有效性。
4 结论
(1)相比同类深度迁移学习方法的特征提取网络,1D-CNN模型在齿轮故障特征提取上具有一定的优势。
(2)子域适配能够同时减小可迁移特征的全局分布差异和子域分布差异,显著提高了识别精度。
(3)本文方法能在目标域无标签的情况下识别目标域的健康状态,使齿轮故障诊断能有效克服生产实际中变工况带来的影响,提高了诊断的泛化性能。
