基于M-distance算法思想的优化加权KNN算法
2021-11-29程勖,高雍政,郭芳
程 勖, 高 雍 政, 郭 芳
( 大连工业大学 管理学院, 辽宁 大连 116032 )
0 引 言
数据特征选择已成为推荐系统重点研究领域,目的是快速实现最优分类,且要精准识别特征信息.数据特征选择主要通过两种途径实现:其一,通过用户商品数据库进行过滤,采用矩阵分解[1]、Slope One[2];其二,学习用户偏好的描述性模型,采用评分机制,如贝叶斯网络[3]、神经网络分类[4]等.常见的分类方法有决策树、KNN算法、SVM算法、贝叶斯网络、神经网络等.传统KNN算法因其简单高效最为常用.它是一种惰性分类算法,特点在于样本数据不需要训练,使用便捷,但是时间复杂度较高,且将单一变量(距离)作为相似度衡量标准,导致推荐精度低且体验度不够完善,如Jaccard相似性[5]、Manhattan距离[6]等.针对KNN算法的不足,主要解决方案集中在裁剪[7-9]与降维[10-12]两个方面.裁剪方法虽然可快速去除噪声数据,但以损失分类精度为代价;降维方法虽然提高了运算速度,但以牺牲特征数据为代价.如何在保证分类精度的前提下,降低时间复杂度,提升运算速度备受关注.
本文通过M-distance算法思想进行簇聚类,对样本数据进行预处理.相对于k-means方法,它的时间复杂度比较小,聚类效果比较显著[13].然后对数据进行加权处理,以便缩小数据间的距离,并兼顾数据之间的相关性,更加准确地对数据进行分类.最后,通过简谐振动原理,计算数据相似度距离,优化遍历数据过程,提高搜索速度.
1 加权K近邻算法的特征选择方法
1.1 K近邻算法简介
在模式识别中,K近邻算法的优势在于简单且对异常值不敏感,泛化能力强.其核心思想内容[14-15]:任意样本在数据集中的K个最相似样本中,如果大部分样本归并为某一类别,那么此样本也属于这个类别.其意义在于通过待测样本周边的已知数据类别来预测此样本的归属问题,极大弱化了数据集的高维度、高耦合给数据特征分析带来的困难.优点:对数据噪声有较强的忍耐能力,非常适合零售业复杂多变的特征选择情景;分析数据特征时,只关注最相邻的K个样本即可,极大地降低了数据集的维度.缺点:K近邻算法属于惰性算法,不能主动学习;K值的选择对数据分析的结果有影响.
Ayyad等[16]提出一种加权策略(MKNN)算法,在基因序列分类中,已知类别中心样本到其他样本加权距离,使其待测样本的辨别程度不同,但此方法对权值的选取并没有考虑特征的重要程度.Li等[17]通过随机选择特征子集,使用KNN算法评价其分类准确率,并计算其平均值作为置信度的衡量标准.该方法的泛化能力提高了,但是对权值贡献度的衡量有待评估,且没有说明权值是如何影响分类效果的.文献[18]提出的计算近邻算法,通过设置安全边际点来完善KNN模型,并未考虑样本之间距离关系对模型的影响.文献[19]提出的移动K近邻查询算法,采用双目标函数通过调节两者之间的作用权重,来求解最优目标函数值.但是对于例如零售业样本集维度高、参数调节困难等情况,必将直接导致计算能力失衡.文献[20]提出的自然邻居算法,主要将自然邻居特征值作为所有样本的近邻,从而避免了K值的人为设定,但是其对所有样本都采用同样的K值,会导致在稀疏矩阵的样本中,由于分布密度过高而导致计算速度大幅下降.为将样本集按照某种条件进行排序,在测试集参与计算之前,将离群点或弱相关样本直接删除,再将经过处理的数据集按照升序或降序进行有规律的计算,可能会更加快速地得到合理的K值.
综上分析,在特征分析过程中,不仅要考虑每个待测样本之间的距离对类别的贡献,更要把每个特征对样本分类的重要程度融入权值计算当中.
1.2 基于M-distance思想的加权K近邻数据特征选择
本文将样本特征的重要性作为参数融入求解权值当中,简称为IFKNN(importance feature integrate intoK-nearest neighbors)算法.首先获取待测样本数据,将数据中的个体作为初始数据特征,使用IFKNN算法预测样本类别,并设计谐振子摆动的目标函数,最后通过经典谐振动的接受准则搜索最优数据特征.
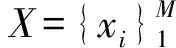
定义样本数据贡献度,作为样本最主要的数据簇.贡献度簇集表达样本在整个观测数据集中作用大小.贡献度越大,样本特征越显著,即商品成交概率越大.也就是说贡献度对商品成交影响是正向的,那么影响贡献度的主要因素,就可以作为重要的营销特征.
每个样本在成交时,它的评价数量与月成交量的商作为此样本对成交的贡献度,记为A.A={α1,α2,…,αn}(0.005≤αi≤1),αi=bi/ci.
通过贡献度阈值的设定,可以更加精确地筛选观测样本数据,也就是说,围绕在中心点周围的样本基本都是线性相关的,几乎没有异常值.如果αi<0.005(参照相关系数设定)就认为此样本属于弱相关或无关样本,直接删除[21].
在初步过滤样本数据时,将样本观测数据集按照样本贡献度的大小降序排列.这样在遍历样本的过程中,不仅减少了求样本中心点的迭代次数,同时,也减小了近邻样本点之间的信息增益,提高了运算速度.
计算相关参数:
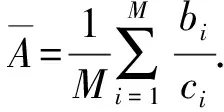
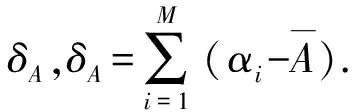
(4)定义特征权重向量wf=(wf1wf2…
wfN},将每个样本的贡献度融入特征权重中,即wfa=wfa·α′i,设样本数据xi与xj之间的距离为dij,融入贡献度的特征权重的欧几里得距离公式为
(1)
(5)通过距离公式可以分析出,距离越小,属于同一类别的概率越大.运用距离倒数加权方法对权值进行加权作用.距离加权函数为
W(d)=e-d
(2)
样本特征进行加权后的样本预测数据集为
(3)
定义损失函数L(yi,Pi),使用预测数据集P与目标数据集Y的差(曼哈顿距离表示),即:
L(yi,Pi)=|yi-Pi(wf)|
(4)
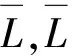
(5)
1.2.2 模拟谐振子运动 简谐振动系统中谐振子的振动轨迹总是从势能最大(离平衡点距离最远)的一端运动到平衡点,再运动到另一端势能最大处,这样持续作往返运动.
(1)初始状态[22]
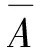
(6)
(2)设定振幅Sl
Sl=max(f(dil))-min(f(djl))
(7)
(3)求解振动能量级
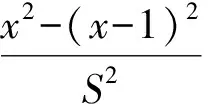
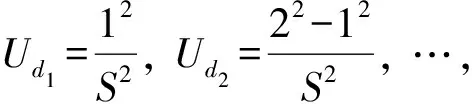
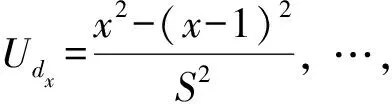
(8)
(4)描述问题转换思想
假定将在求的目标函数所有过程解(计算每个过程的最优解)均映射到简谐振动的能量级中.其中,所有区间的过程解都杂乱无规律地分布其中.设最大解fmax与最小解fmin之差等于最大势能UdS.随机计算两个过程解fi、fj,则Δf=|fi-fj| 表示两个样本点的过程解之间的相对距离.为了可视化方便,将其作归一化处理,即:
(9)
假定fi就是最优解,那么在不断计算的过程中,也就是逐渐靠近最优解的过程.所以Δf/f就是新解与最优解的相对距离.确定了新解的能量区间,就可以确定新解的选择策略(特征值选择方法).经典简谐振动能级选择策略为将fend-fi近似看作简谐振动的最大势能.
(10)
其中L0为初始步长.综上分析,搜索最优数据特征采用经典谐振子算法来遍历样本特征空间,就是求解min(Δf)最优的过程,最终确定最优特征权值,从而得到最优样本数据特征.
1.2.3 数据特征选择 将样本数据集X按照贡献度数据集A的索引顺序,排列既有前驱也有后继.即每当遍历一个样本数据时,它能接受前驱的样本特征信息,并将该信息处理完毕直接传递给后继样本,这样求最优解(最优特征)可表达成一个序列:φ1→φ2→…→φn.即整个解空间D的规模变为(n-1)!/2.同时,这样构建数据结构的好处是,在求解最优特征权值的过程中,保存的最优解向量的索引会一起传递,最终形成最优特征序列,也就是所要挖掘的消费者所关注的消费理念与行为数据.
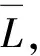
IFKNN算法特征选择方法具体流程为
Input:具有M个样本和N个特征的数据集X
Output:最优特征
(1)按照前文描述,初始化数据集,求解贡献度数据集A.样本数据集X按照样本的贡献度数据集A中的索引顺序从大到小依次排列,并且首尾相连,构建成链状数据结构,样本都拥有前驱与后继.
(2)计算贡献度数据集A的均值与方差.
(3)进行迭代操作:设迭代次数为T
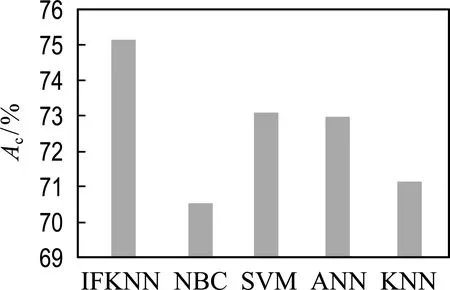
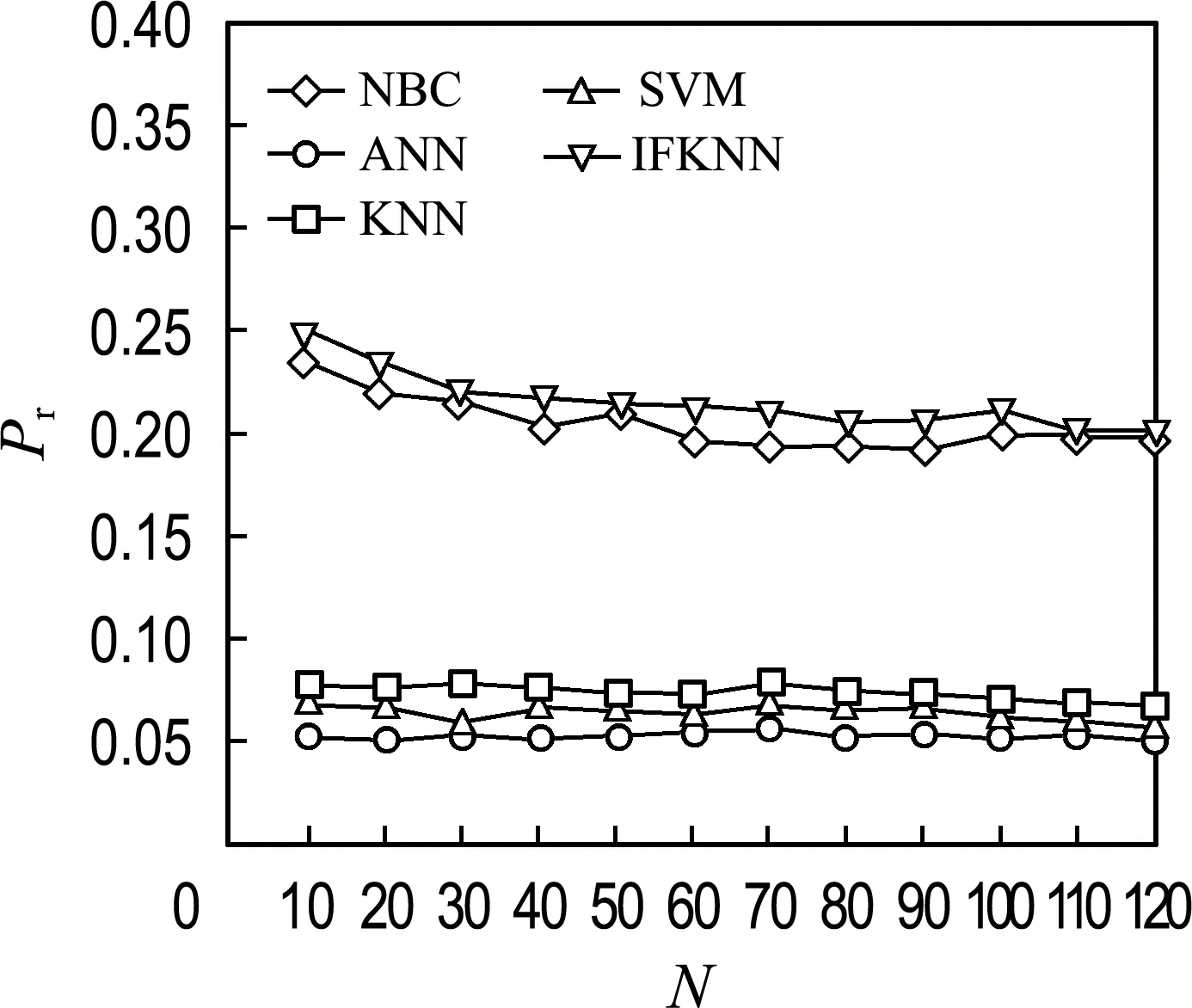
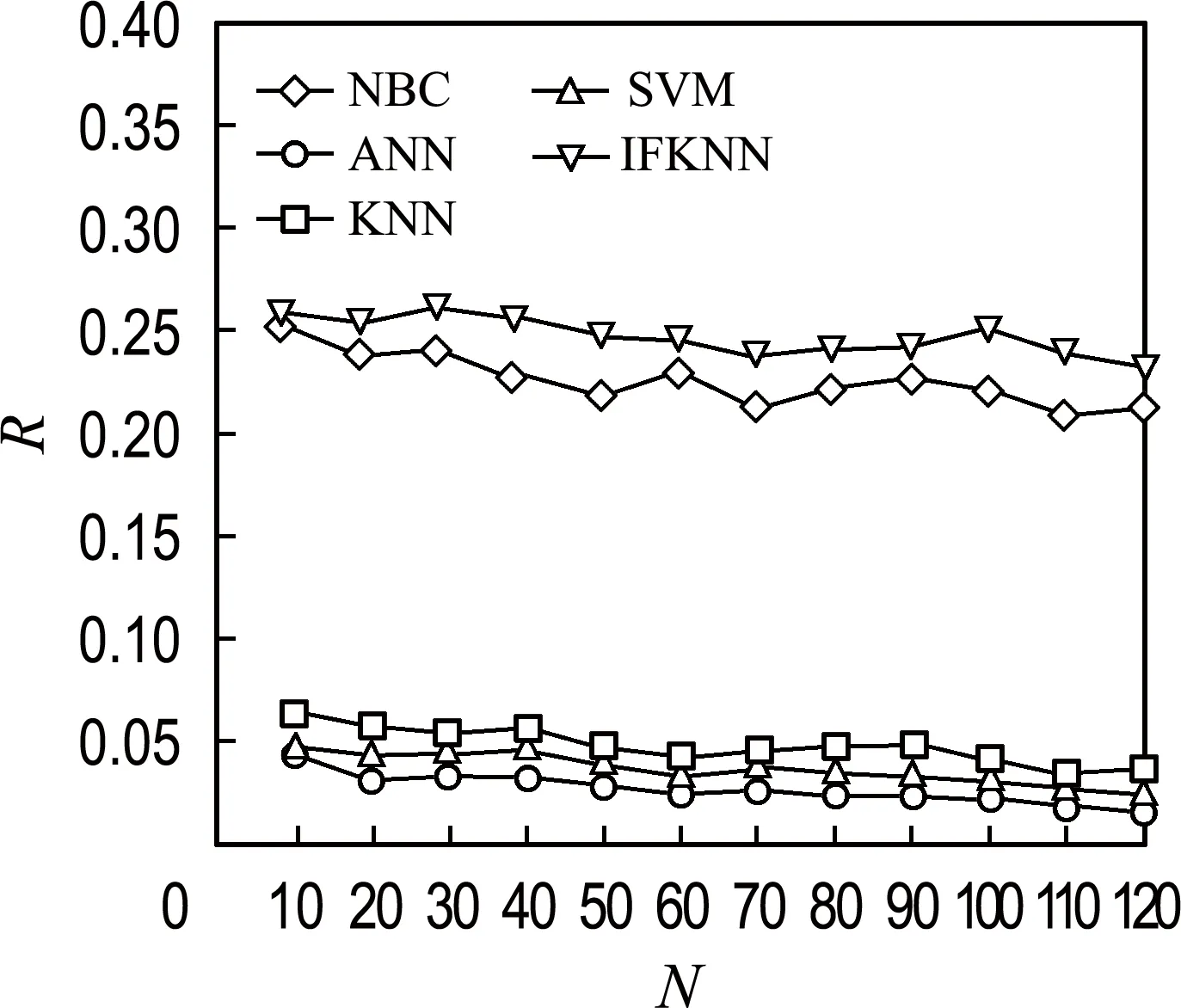
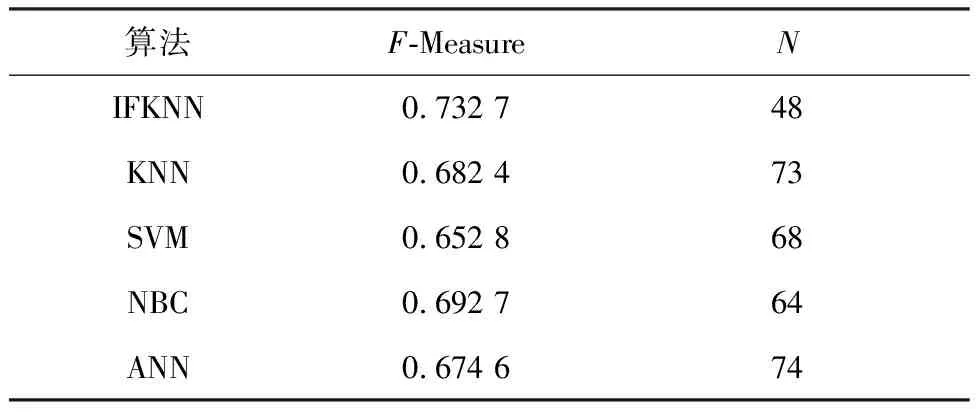
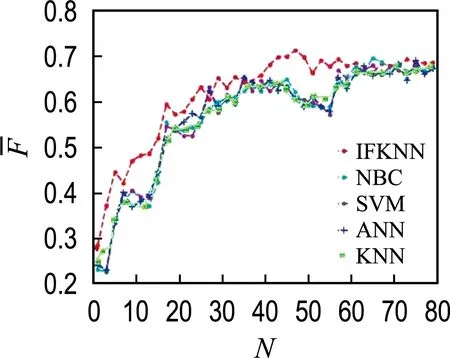
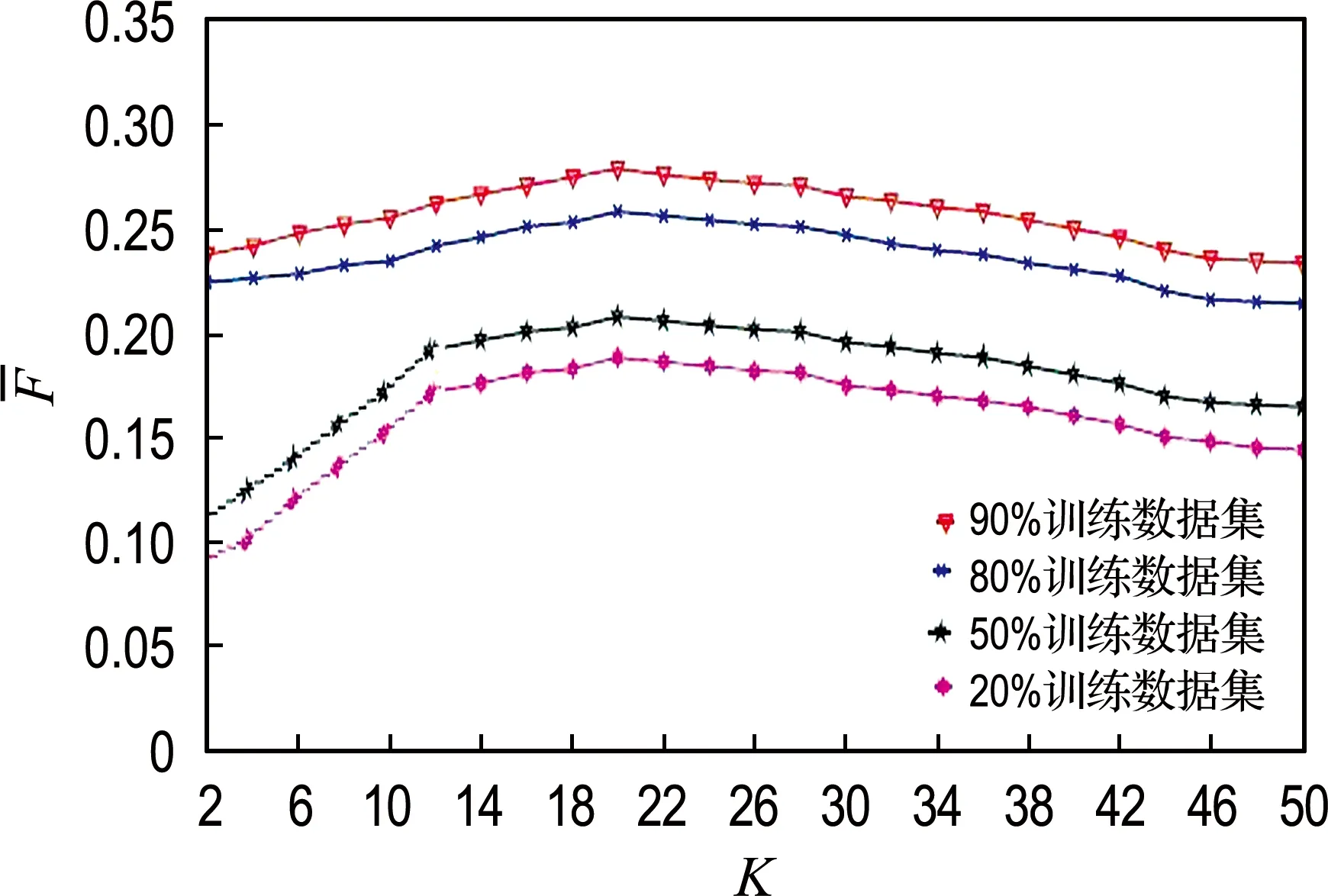
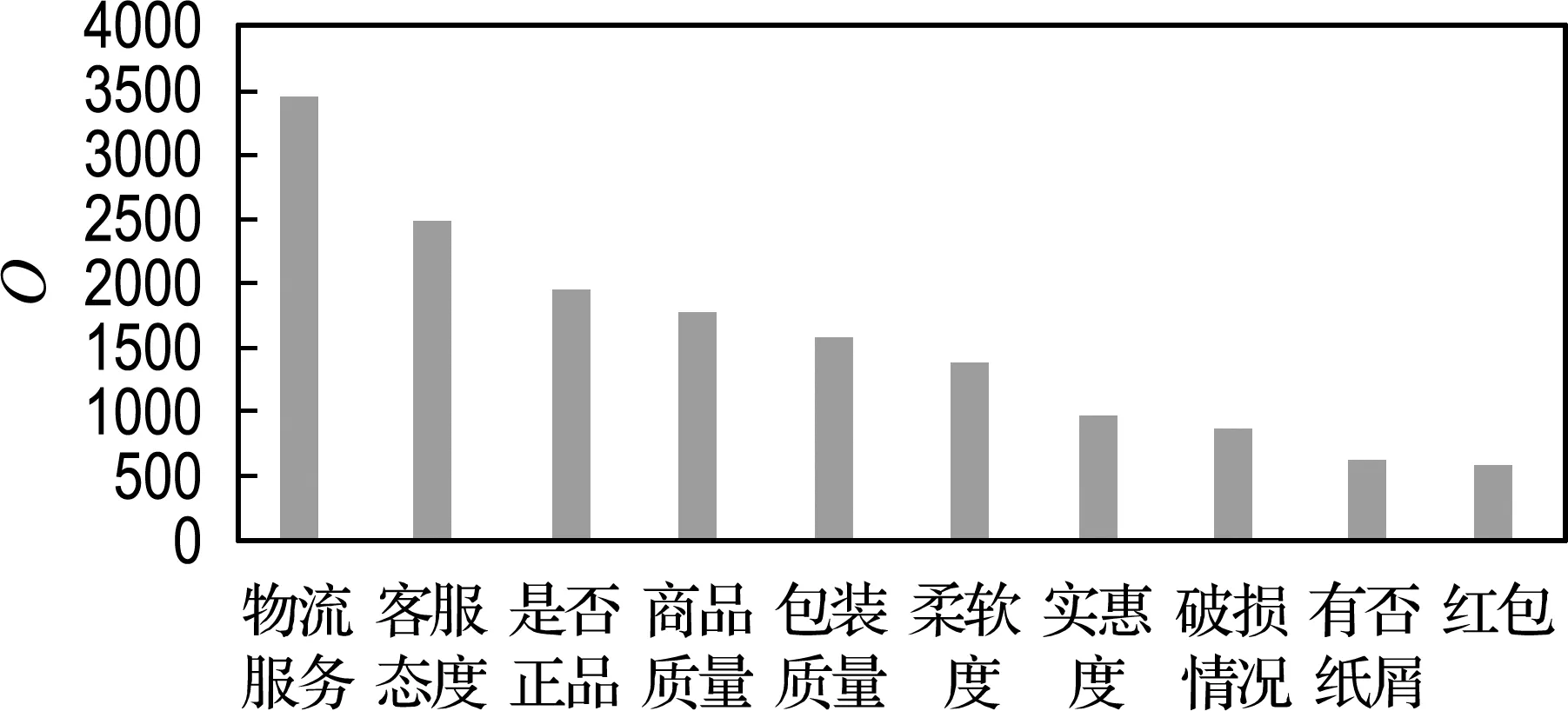
For(i=0;i For:对每个样本进行数据处理 计算数据集X中的预测值P 计算损失函数,将损失函数作为选择最优特征权重的目标函数f,进行迭代操作,使得目标函数的值最小,也就是最接近最优解,即在遍历数据集时,求解目标函数最小值. 计算Δf,按照经典简谐振动的选择策略进行筛选.获得最优解. 以2020年“双11购物节”部分重要日常生活用品(卫生纸)数据为主要研究对象,以2020-11-30为终点抓取消费者购买卫生纸的相关数据.卫生纸品牌选择具有代表性的两个品牌,作为集合Y={维达,心相印},对集合Y作Map处理:Y={维达:0,心相印:1}.每种售出商品向前抓取2 500 个用户留言,即共收集5 000个样本进行分析.在分析用户留言时,利用分词方法,随机抓取频繁出现的关键词120个记录到特征数据集F中.每个关键词出现的次数记为n,按照降序排列,如果次数相同,按照先后顺序,依次存入特征数据集F中.将每个顾客留言出现特征数据的次数除以5 000的商,按照特征数据集F中样本特征出现的顺序依次记录到数据集X中,数据集X共存储5 000条样本信息. 从图1可以直观地看出IFKNN算法准确率比较高.图2表明每个邻居样本数据都被特征的选择数量所影响,当特征数量小于30的时候,预测出的数据不太符合真实的情景,当样本数据大于100的时候,又会发生过拟合,同样也不太适合.所以,选择样本特征数量对于能否成功得到分类结果是非常关键的.图3为5种算法的召回率分布情况.样本特征数量从30到70,召回率下降比较快而且数值比较高,然后召回率缓慢下降最后趋于一致. 图1 5种算法分类的准确率Fig.1 Classification accuracy of five algorithms 图2 不同样本特征数量的5种算法的精准率Fig.2 Precision of five algorithms with different samplefeature numbers 图3 不同样本特征数量的5种算法的召回率Fig.3 Recall rates of five algorithms with differentsample feature numbers 表1分别列出5种算法获得的最高分类性能(F-Measure)和特征数量(N),可以看出,IFKNN算法的分类性能比其他几种算法好,不仅达到的指标最高,而且使用的特征数量也最少.由图4可以直观地分析出,IFKNN算法分类性能最高,而且在很多求解过程中都能最快获取最高分类性能.当选取前20个特征时IFKNN算法相对其他4种算法能明显快速达到最好分类性能.在样本特征数量为30~50时,步调基本趋于一致,这可能是由于在模拟简谐振动的某部分能量级中陷入了局部最优.当样本特征数量在40~60时,IFKNN 算法的效果又显著增强.这也许是由于跳出了局部最优(其他4个算法有明显先下降之后显著上升的过程),最后5种算法结果趋于一致.由图5可以分析出:在其他参数都是最优值,选择的邻居数量K小于20的情况下,分类效果是逐步增强的,尤其是当训练数据集比较少的情况下,变动幅度比较大.当邻居数量K大于20时,分类效果开始逐步降低,最后趋于稳定.实验表明,样本邻居数量K选择在20左右作分类预测时,分类结果比较好.由图6可以看出,消费者最关注的特征是物流服务,而且关注度非常显著.售后服务质量与商品质量关注度相差不多,而对大家极为看好的红包特征并没有明显关注.因此,拟订营销策略时,首先要完善物流服务,其次是重视售后服务与商品质量,也就是企业在网商平台上要介绍商品信息,做好售后服务,而并非把注意力放在红包上. 表1 5种算法指标对比Tab.1 Index comparison of five algorithms 图4 不同样本特征数量的F-Measure指标分布Fig.4 F-Measure index distribution of differentsample feature numbers 图5 样本邻居数量选择对指标F-Measure的影响Fig.5 Influence of sample neighbors number selectionon index F-Measure 图6 消费者关注前10特征序列分布Fig.6 Distribution of top 10 feature sequences ofconsumer concern 本文提出基于M-distance思想的加权K近邻特征选择算法,在模拟简谐振动算法基础上搜索最优特征权重向量进行精确分类.实验表明:IFKNN算法分类性能最好、速度最快、使用特征向量最少,并且邻居数量K值在20左右效果比较理想.构建的样品特征向量集有助于分析消费者日常关注的消费理念与行为,辅助构建消费策略.在未来的工作中,可以使用其他的计算距离公式提高普适性,利用其他的遍历矩阵方法来搜索最优特征向量,提高分类精度及速度.2 实验与性能分析
2.1 数据集
2.2 实验结果及性能分析
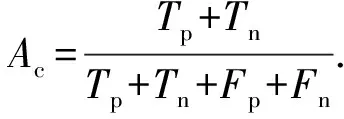
3 结 语
