基于深度强化学习信道智能接入方法与NS3仿真
2021-11-17程一强刘泽华谭惠文
赵 楠,程一强,刘泽华,谭惠文
(1. 湖北工业大学太阳能高效利用湖北省协同创新中心,湖北 武汉 430068;2. 湖北工业大学太阳能高效利用及储备运行控制湖北省重点实验室,湖北 武汉 430068;3. 湖北省能源互联网工程技术研究中心,湖北 武汉 430068)
1 引言
随着无线通信技术的迅速发展,频谱资源的需求越来越高。频谱资源日益匮乏且利用率低,已成为制约无线通信发展的严峻问题[1]。多信道接入方法因其能够有效地提高频谱资源的利用率,受到研究者的广泛关注。文献[2]提出了一种基于异步睡眠唤醒的动态信道接入方法,以提高认知无线电网络的能量利用效率。文献[3]讨论了基于双频谱感知的随机信道接入问题,以最大化利用信道和选择最优信道。文献[4]研究了一种基于启发式算法的主信道选择策略,以提高多信道用户的网络吞吐量。文献[5]提出了一种基于博弈论的优化方法,以提高信道接入概率。文献[6]提出了基于时隙分类的多信道多址接入协议,以解决链路冲突和链路不足的问题。文献[7]通过采用随机延迟的信道接入方法,以降低系统延迟。文献[8]提出了一种基于深度神经网络(Deep Neural Network,DNN)的信道估计器,以跟踪信道环境变化。文献[9]研究了一种基于DNN的多信道认知无线电网络资源分配策略,可以在提高授权用户频谱利用率的同时,适当地减少对主用户的干扰。然而,上述多信道接入方法往往需要大量的网络信息;同时,当信道状态发生变化时,很难有效地实现信道的智能接入。因此,如何实现多信道的智能接入是一个值得关注和研究的问题。
近年来,深度强化学习方法(Deep Reinforcement Learning,DRL) 因其强大的学习能力,在智能决策、无人驾驶、边缘卸载等领域取得了一些研究进展。在文献[10]中,作者设计了一种动态自适应DNN算法,真实还原了自动驾驶汽车的视频数据集。 文献[11]提出了一种基于DNN的综合能源系统负荷预测方法,对负荷的时间序列分量进行了预测,提高了综合能源系统负荷预测的准确性。Han G等人提出了基于DRL的二维抗干扰通信系统,借助于卷积神经网络(Convolutional Neural Networks,CNN),能够大幅提高学习速度,有效地减少外部干扰[12]。文献[13]研究了一种基于DRL的异构无线网络媒体访问控制协议,即使没有最佳地设置强化学习框架的参数,也能够获得近似最优的信道访问策略。在文献[14]中,作者通过设计DNN,提出了双选择性衰落信道估计算法,不仅可以从先前的信道估计中提取信道变化的特征,而且能够从导频和接收信号中提取额外的特征。
鉴于此,受到DRL的启发,本文旨在将强化学习策略引入到多信道接入,以期实现多信道的智能接入。在建立多信道接入模型的基础上,将多信道智能接入问题建模为离散状态与动作空间的马尔可夫决策过程。针对Q-learning状态空间过大和收敛速度较慢等问题,通过设计DNN,并利用梯度下降法来训练 DNN 的权值,采用经验回放策略降低经验数据的相关性,修正损失函数解决状态-动作值函数过高估计的问题,以获得近似最优的多信道智能接入策略。最后,搭建NS3仿真平台,验证本文所提出方法的性能。
2 基于DRL的多信道智能接入方法
2.1 基本模型
假设用户在从N个信道的选择接入某一信道的过程中,会受到从第1个到第N个信道的周期性外部干扰。同时,考虑到用户在当前时刻接入信道所获得的效用仅与当前信道状态有关,与信道之前状态无关,上述多信道接入过程可描述为一个马尔可夫决策过程(S;A;p(s′|s,a);r;π(a|s)),具体描述如下:
状态空间S:当前时刻各信道状态s的集合。0表示某一信道正处于空闲状态,1表示某一信道已被占用。于是,N个信道的状态空间S为2N。
动作空间A:选择某一信道动作a的集合。
转移概率p(s′|s,a):在信道状态s情况下,采用某一动作a时,信道状态s转变为下一信道状态s′的概率。
奖励r:用户采取某一动作a时,信道状态从s转移到下一信道状态s′所获得的奖励。如果用户与干扰没有发生碰撞,奖励r=r+1,产生碰撞r=r-1。
策略π(a|s):在信道状态s时,选择某一信道动作a的概率。
这里,本文定义累积奖励R为所有奖励r的累积,即
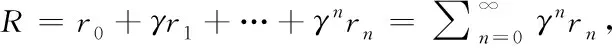
(1)
其中,rn表示在第n个时刻信道所获得的奖励。γ为衰减因子且γ∈[0,1),衰减因子决定了未来时刻奖励和当前时刻奖励的重要性。当衰减因子接近0时,意味着当前时刻获得的奖励权重较多;反之,当衰减因子接近1时,则意味着用户应该更注重未来时刻获得的奖励。
2.2 深度强化学习
作为解决上述马尔可夫决策过程的常用方法,强化学习不断以试错的方式与环境进行交互,通过最大化累积奖励以获得最优策略。强化学习根据环境的评价性反馈实现决策的优化,当用户执行的某一动作得到正向的奖励或回报时,反馈信号就会增强,用户以后执行该动作的概率便会加强;反之,用户以后执行该动作的概率便会降低。本文将强化学习方法应用于多信道接入,用户通过观察当前时刻各信道占位情况,从历史经验中学习,选择接入下一时刻的最佳信道,避免与干扰产生碰撞,从而实现多信道智能接入。
这里,本文定义信道状态s处选择信道a得到的期望奖励为状态-动作值函数Q(s,a)
Q(s,a)=E[R|s,a].
(2)
于是,通过贝尔曼方程[15]得到最优的状态-动作值函数Q*(s,a)
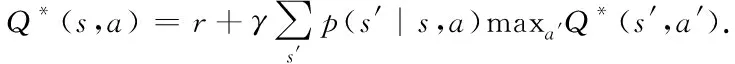
(3)
同时,状态-动作值函数Q(s,a)更新过程可以表示如下
Q(s,a)=(1-δ)Q(s,a)+δQ-,
(4)
其中,Q-=r+γmaxa′Q(s′,a′),δ为学习率,它影响了状态-动作值函数Q(s,a)的更新速度。
值得注意的是,N个信道的状态空间S为2N,当N较大时,整个状态空间S非常巨大。在这种情况下,如果采用经典的强化学习方法Q-learning,通过查找状态-动作值函数Q(s,a)表获得最优的信道接入策略,将变得非常困难。因此,本文提出基于DRL的多信道智能接入方法,以解决状态空间过大的问题。
本文将DNN引入到Q-learning的框架中,以获得近似最优的策略和状态-动作值函数Q(s,a)。DNN以层次分明的方式组织起来,是一个具有多个处理层的神经网络,并且每一层都由许多神经元组成,每个神经元都将前一层的输出通过加权线性组合作为下一层的输入。在这里,DNN由Online网络和Target网络组成,Online网络使用带有权重θ的状态-动作值Q函数,以近似最优的状态-动作值函数Q*(s,a);Target网络使用带有权重θ-的状态-动作值Q函数,以提高整个网络的性能。在特定的回合数后,复制Online网络的权重θ以更新Target网络的权重θ-。利用梯度下降法更新Online网络的权重θ,以获得最小损失函数
L=(r+γmaxa′Q(s′,a′,θ-)-Q(s,a,θ))2.
(5)
同时,为了降低经验数据的相关性,本文采用经验回放策略。在信道状态s情况下,用户通过执行动作a,获得奖励r,然后将信道状态s转变为下一信道状态s′,DNN将这转移信息〈s,a,r,s′〉保存在经验回放存储器D中。在学习过程中,从经验回放存储器D中随机抽取mini-batch样本〈s,a,r,s′〉,以训练神经网络。通过不断减少训练样本之间的相关性,帮助用户更好地学习,以避免最优策略陷入局部最小值。另外,神经网络经常会过拟合部分经验数据,通过随机抽取mini-batch样本〈s,a,r,s′〉,可以降低过拟合。
此外,考虑到上述DNN经常会过高地估计状态-动作值函数Q(s,a,θ)。本文在(5)基础上,设置两个独立的状态-动作值Q函数,且每个函数独立学习,将权重为θ的状态-动作值Q函数用来选择动作,权重为θ-的状态-动作值Q函数用来评估动作。于是,修正后的损失8函数如下:
L=(y-Q(s,a,θ))2,
(6)
其中,y=r+γQ(s′,arg maxa′Q(s′,a′,θ),θ-)。
于是,本文提出的基于DRL多信道智能接入算法流程详细描述如下:
步骤1:初始化当前时刻中各信道状态s;
步骤2:利用ε-贪婪策略来选择信道:以概率ε随机选择下一时刻接入的信道,以概率(1-ε)选择接入满足最优状态-动作值函数Q(s,a,θ)的信道;
步骤3:在信道状态s下,选择信道接入动作a,并得到奖励r。如果信道没有与干扰产生碰撞r=r+1,产生碰撞r=r-1;
步骤4:信道状态s转移到下一信道状态s′;
步骤5:将上述状态转移信息〈s,a,r,s′〉保存在经验回放存储器D中;
步骤6:从经验回放存储器D中随机抽取mini-batch样本〈s,a,r,s′〉;
步骤7:利用(6)计算损失函数,并借助梯度下降法获得最小损失函数;
步骤8:间隔一定回合数后,将Online网络的权重θ复制给Target网络权重θ-;
步骤9:重复第2到第8步骤。
3 实验结果分析
为了验证基于DRL的多信道智能接入算法性能,本文在Ubuntu环境下,利用常见的离散事件网络模拟器NS3,搭建多信道智能接入NS3仿真平台。在整个仿真环境中,处理器为Inter Core i7,内存为4GB,虚拟机的版本号为VMware Workstation 10.0.4,Ubuntu的版本号为16.04 LTS,部分实验代码基于NS3.27库编写,其余仿真参数具体如表1所示。
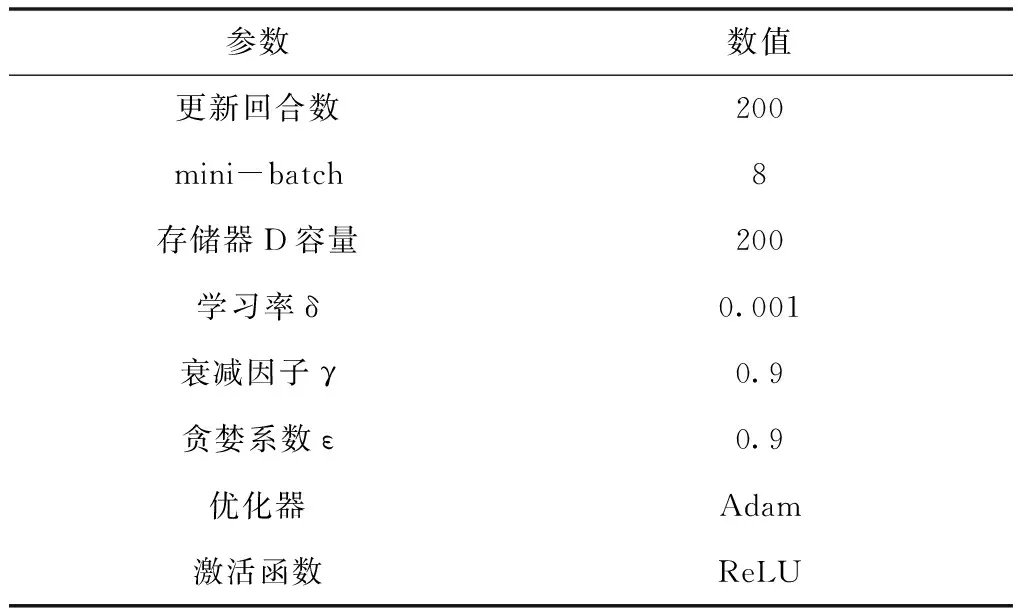
表1 仿真参数设置
图1描述了不同的衰减因子γ对平滑奖励的影响。从图1可以看出,随着回合数的不断增加,平滑奖励增加,且曲线波动变小,逐渐趋于平缓。当γ=0.9时,与其它衰减因子相比较,平滑奖励的曲线波动幅度较小,更加稳定,收敛速度更快。实验结果表明,在本实验中,用户在未来时刻获得的奖励权重较多。
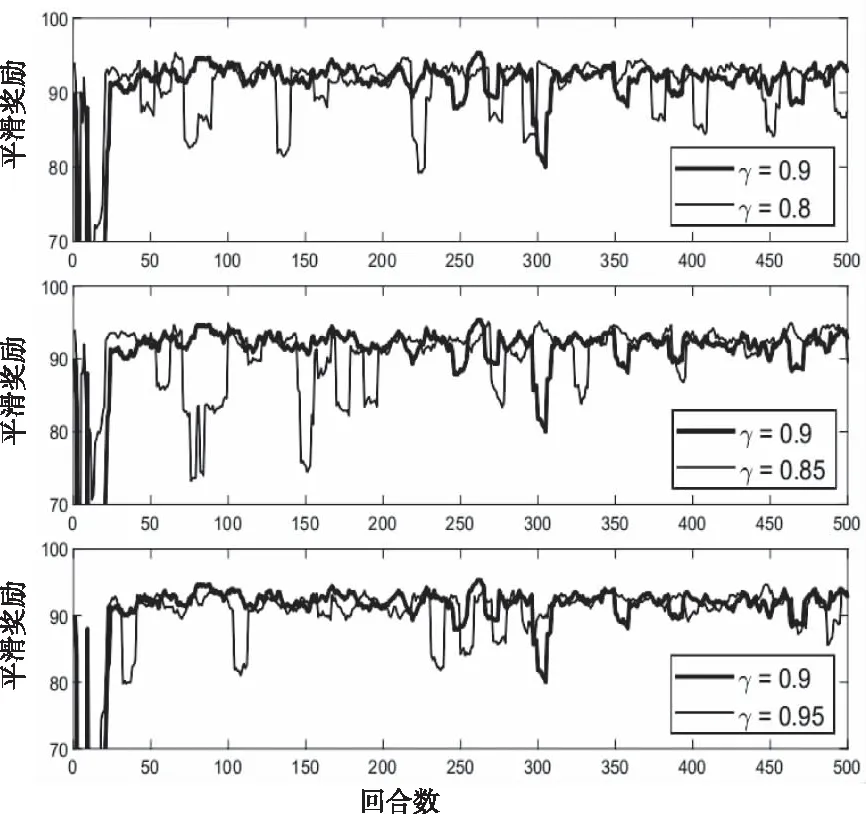
图1 不同衰减因子性能影响 (N=5)
图2显示不同的学习率δ下平滑奖励的变化情况。当学习率较大时,梯度在局部最小值附近来回震荡,损失函数难以取得局部最小值,甚至可能无法收敛。反之,当学习率较小时,状态-动作值函数Q(s,a,θ)和损失函数的变化更新速度较慢,这样就能够更好地捕捉到状态-动作值函数Q(s,a,θ)和损失函数的变化,更容易获得近似最优的的信道选择策略,因而,学习率δ为0.001的平滑奖励明显高于δ为0.1和0.01的平滑奖励。然而,当学习率δ过小时,收敛过程将变得十分缓慢,导致长时间无法收敛,并且容易出现过拟合的情况。因此,本文在综合考虑收敛效率和平滑奖励性能基础上,选用学习率δ=0.001。
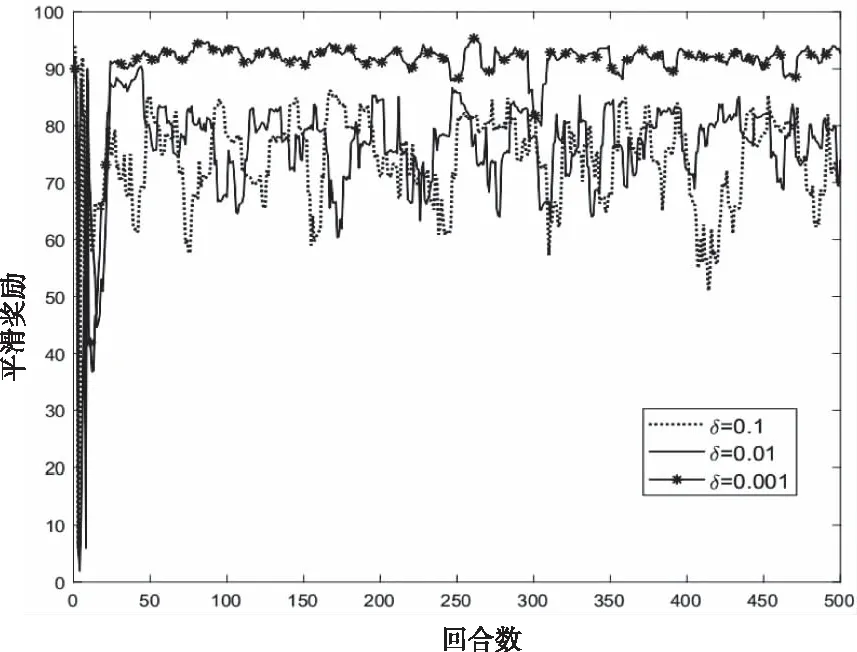
图2 不同学习率性能影响 (N=5)
不同的强化学习方法对平滑奖励的影响如图3所示。从图3可以看出,本文提出的方法性能明显优于Q-learning和随机策略,且曲线波动幅度较小,较为稳定。在平滑奖励方面,与随机策略相比,本论文采用DRL和Q-learning等强化学习方法,具有较强的自主学习能力,通过不断与环境进行交互,从以往经验中学习,获得了更优信道接入策略和更大的平滑奖励。在收敛速度方面,相比于Q-learning方法,本论文通过引入DNN结构,不仅有效地解决了过高估计状态-动作值函数Q(s,a,θ)的问题,也获得了更快的收敛速度和更大的平滑奖励。
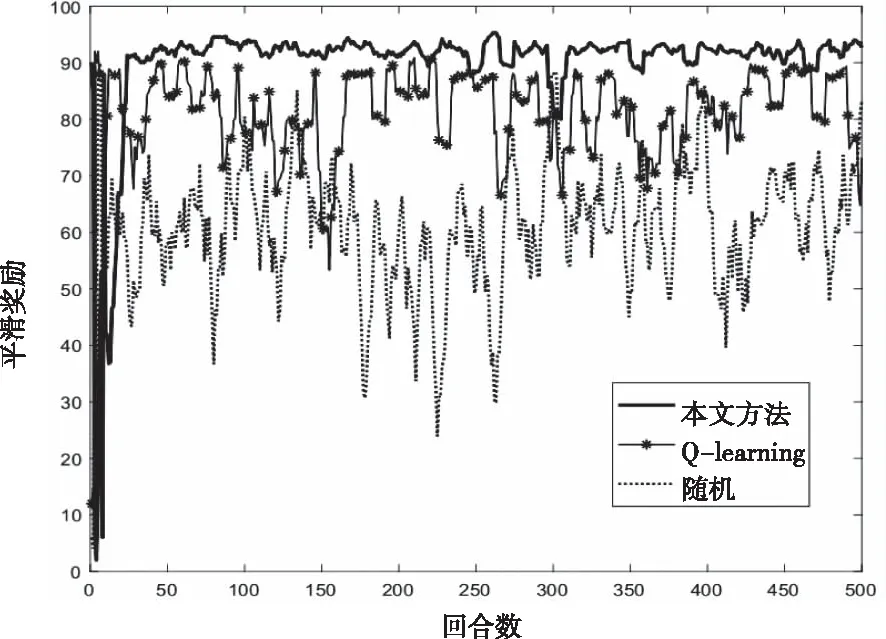
图3 不同强化学习方法性能影响 (N=5)
不同的信道数对平滑奖励的影响如图4所示。从图中曲线可以看出,当衰减因子γ=0.9,学习率δ=0.001时,随着信道数的增加,外部干扰对信道造成的影响减少,信道接入机会随之增多,平滑奖励不断上升。当信道数过多时,信道有充分的接入机会,并且本文方法通过观察当前时刻各信道占位情况,选择接入下一时刻的最佳信道, 外部碰撞的机会大幅降低至不再产生,曲线逐渐趋于平滑。
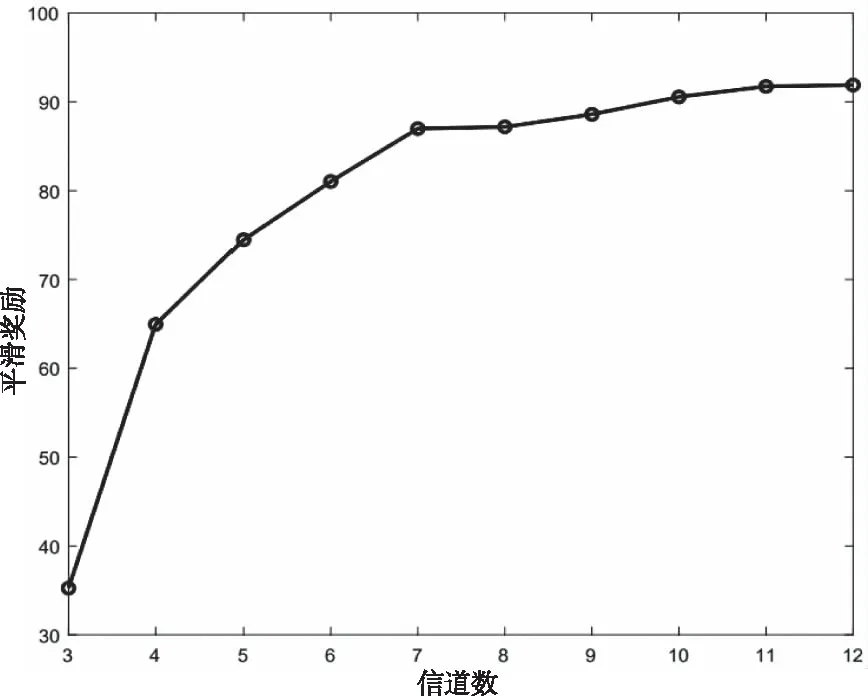
图4 不同信道数性能影响
4 结论
本文提出了一种基于DRL的多信道智能接入方法。针对多信道状态的动态性,将多信道接入过程描述为马尔可夫决策过程。在此基础上,为了有效地解决强化学习状态空间较大的问题,通过引入DNN,以获得近似最优的信道选择策略。在仿真方面,通过搭建NS3仿真平台,验证本文所提出方法的性能。仿真结果表明,本文提出的基于DRL多信道智能接入算法,能够在较快收敛速度的前提下,获得近似最优的多信道智能接入策略。
