基于正则化贪心森林算法的情感分析方法研究
2021-11-13张贯虹陈婷婷
吴 彤,张贯虹,陈婷婷
(合肥学院人工智能与大数据学院,合肥 230601)
近年来,随着移动终端设备的普及,以及互联网的快速发展,人们享受着智能化带来的便利。与此同时,各大社交APP的使用也逐渐成为大家必不可少的获取信息的方式,人们可以随时随地的在社交媒体上浏览最新最热点的新闻事件、娱乐信息,并且会对自己感兴趣的信息进行评价,而这些评价在情感色彩上持有正面、负面、中立等不同极性。大众对于热点事件的舆论倾向对社会、企业和个人都具有非常重要的作用,相关管控部门需要对社会关注的焦点做出第一时间回应,并对舆论方向做出正确的引导,因此对评论进行情感分析显得十分重要。微博作为当下最热门的社交平台之一,用户的数量愈加庞大,随之产生的信息也与日俱增。于是,对微博文本信息的挖掘研究也成为近年来的研究热点。
情感分析[1],又称为倾向性分析或意见挖掘,是自然语言处理中的一项基本任务。关于文本情感分析的方法主要有基于情感词典的分析方法和基于机器学习的分析方法两大类。[2]基于情感词典的文本情感分析方法主要是利用情感词典对关键词进行极性和强度标注,从而进行情感分类,但是基于情感词典的分类方法由于构建的词典往往只针对特定的领域,所以对跨领域的文本情感分析的效果不是很好,而且考虑到词典中的情感词不够丰富,基于情感词典的方法通常对短文本和特定领域的文本信息处理结果更好。基于机器学习的文本情感分析方法一种是以统计学为基础的建模方法,不需要建立情感词典,利用统计学相关知识选取特征词,将文本矩阵化,再采用有效的模型方法进行分类,从而减少了人工获取语言规则的错误性和不完备性。因此,对于微博评论的跨领域和多样化来说,基于机器学习的方法更适合进行情感分析。
1 相关研究
在处理文本分类问题中,传统方法是通过有监督学习方式,用词袋(Bag-of-words,BOW)模型对分类器进行训练。Pang等[3]对电影评论进行情感分析,对比了朴素贝叶斯、支持向量机和最大熵三种方法,表明了支持向量机的文本分类效果最好。张月梅等[4]提出一种基于随机森林和K近邻的混合算法实现文本分类。在解决中文微博短文本问题上,郝苗苗等[5]采用了基于情感词典的权重规则算法,构建了微博情绪词典,对微博评论进行分析和预测,取得良好的效果。此外,还有研究者针对文本数据不平衡问题基于集成学习方法对文本进行分类。Almeida等[6]在解决情感分类问题时采用了多分类集成方法,实验取得良好的效果。Zhang等[7]对固定规则、加权组合和元分类三种集成技术进行比较,得出基于加权组合的效果最好。朱军等[8]基于情感词典和集成学习的情感分析方法将积极类的准确率和消极类的召回率提升了6.9%和8.8%,取得了较好的分类效果,但是实验数据量较小。
微博评论的文本多为短文本信息,对于该短文本,由于其样本的不平衡性和数据的稀疏性,使用传统的机器学习算法会使情感分析效果下降。因此,通过集成学习的方法来提高文本分类的准确率是可行的办法。集成学习的思想就是将多个弱分类器进行线性组合之后产生一个新的强分类器,目前集成学习方法主要有两种:基于Bagging的集成学习方法和基于Boosting的集成学习方法。随机森林就是比较典型的一个基于Bagging的集成学习算法,Boosting算法常见的有Adaboost、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)等。另外,Rie Johnson等[9]提出了一种在GBDT算法上对正则化改进的正则化贪心森林算法(Regularized Greedy Forest,RGF),增加显式的正则函数来防止过拟合,也是本文所采用的作为情感分析的方法。
本文提出使用基于RGF的微博评论情感分析模型,通过集成学习的方法对决策树进行提升。对比传统机器学习方法贝叶斯分类、决策树、随机森林、基于Adaboost的集成方法以及本文用到的RGF集成学习方法,通过外卖评论数据、微博爬取的评论数据以及电商数据三种数据集对比实验,以准确率、召回率和F1值作为评定标准,通过大量的实验证明RGF模型在情感分析上能取得良好的效果。结果证明,使用正则化贪心森林的算法模型进行微博短文本情感分析,对比其他模型有较好的分类效果。
2 RGF原理及方法
RGF算法是在GBDT算法上进行改进的一种算法。GBDT是一种广泛应用的Boosting算法[10],GBDT通过加法模型,即基函数的线性组合,经过多次迭代,不断减小训练过程产生的损失值来拟合非线性函数,最终达到将数据分类或者回归的效果。但是GBDT的不足之处是,每次迭代都会学习出一棵决策树,而每次迭代只优化新产生的树以及过拟合问题,这样单棵树与整个森林分隔开来,没有利用好决策树的本身的性质,并且GBDT缺少显示的正则化,针对以上问题Rie Johnson等提出了RGF算法。
RGF是一种决策森林,它的核心思想是:每次迭代不再只对新建树优化,而是对整个贪心森林进行学习,并且新增决策树后对全局参数进行优化,增加显式的正则函数来防止过拟合。[11]
在一棵决策树中,从树的根节点x到树的子节点v形成的一条路径即为一条分类规则,对于该分类规则用公式可以表示为
≤
(1)
其中,I(x)取值为0和1,当括号中结果为真时取1,否则取0。因此,当bv(x)=1时,说明x经过决策树的判断能够到达v节点,否则不能到达。每个样本在决策树分类的过程中,都在树的非叶子节点处进行某个特征维度值的二元测试,将样本数据与阈值进行对比,对比后的结果进入下一层再进行判断,最后到达叶子节点,如下图1所示。
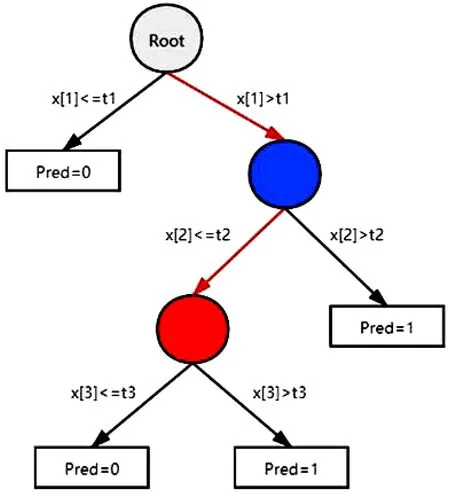
图1 决策树流程图
上图中从Root根节点到红色节点的过程中,每一层都要经过阈值判断 ,所以红色节点可以表示为bv(x)=I(x[2]≤t2)I(x[1]≤t1)。在单棵决策树中,每个节点v都可以表示成其子节点的组合,如bv(x)=bv1(x)+bv2(x),而决策森林模型就可以表示成叶节点的组合模型
(2)
其中,av表示v节点的权重,当v不是叶子结点的时候值取0,F则表示决策森林。有了该模型表示,正则化贪心森林算法就可以直接学习整个贪心森林,而不是只学习新增的决策树。
RGF在构建决策森林时,定义了一个损失函数Q=L(hF(x),Y)+R(hF),其中R(hF)是正则化项,L(hF(x),Y)根据处理的问题进行定义,本文定义的损失函数为:
(3)
3 基于RGF算法的情感分析研究
本文针对微博热点事件的评论数据,提出基于正则化贪心森林算法的情感分类模型,情感分析步骤流程图如下图2所示。

图2 情感分析流程图
首先,对数据集使用NLTK工具包进行文本预处理,包括分词、去除停用词、去除重复数据、去除空值数据、去除特殊字符等,然后再将清洗好的数据进行特征提取,根据数据产生词频,选取特征时选取文本中出现的高频词,具有代表性,也是影响其分类结果的重要因素。然后再把每句话进行分词,本文分词采用的是分词工具jieba分词[12]中的精确模式,分词后的数据根据词频向量化。在特征提取部分主要是采取常用的词袋模型(Bag-of-words,BOW)[13]对文本进行特征提取,然后使用TF-IDF算法[14,15]计算权重,并赋予特征值,tf是词频,其公式表示为
(4)
idf是逆文档频率,其公式表示为
(5)
TF-IDF为tf和idf的乘积,用来表示一个字词在一个文件中的重要程度或者一个文件在整个语料库中的重要程度,公式如下:
(6)
其中nij表示单词i在文本j中出现的频率;nj表示文本的单词总数;|D|表示语料库中的文本数;|Di|表示在语料库中出现单词i的文本总数。接着将提取的特征进行向量化表示,然后通过不同的分类器进行训练。与以往传统机器学习方法不同的是,在建立模型时选择的是利用RGF算法进行建模,实验将数据集按4∶1随机分为训练集和测试集,进行训练及预测。
4 实验与分析
4.1 实验设置
本文进行实验的语料库不仅包括爬取的微博数据,另外加了两组已经处理好的标准语料库的数据:电商评论数据和外卖数据,进行有监督的情感分析。情感标签统一为两分类,正面和负面,数据集统计信息如下表1所示。实验使用RGF模型和其他四种基准模型分别对三种语料库进行训练,通过评价指标对其结果进行分析评估。

表1 数据集统计信息
4.2 评价标准
实验采用的评价标准为准确率(Acc)、召回率(Recall)和F1值(F1)。准确率表示了测量值与标准值的接近程度,召回率表示数据集中的正面数据多少被正确预测了,F1值综合前两个指标,用来对整体进行评估。其计算公式表示为
(7)
(8)
(9)
其中Tp、Tn、Fp、Fn表示的意义如下表2。

表2 混淆矩阵
另外,使用准确率、召回率和F1值折线图直观的显示,方便观察五种分类器的优劣。
4.3 实验结果与分析
本次实验,训练及预测采取多组实验对比的形式来说明所提出方法的有效性。分别选用决策树[16],贝叶斯[17],增强多项式贝叶斯,随机森林[18]和本文所提出的RGF模型对数据进行训练,并且使用这五个分类模型对三种语料库分别训练和预测。各方法介绍如下:
决策树:将数据切分成80%训练集和20%测试集,使用jieba分词器对三类数据进行分词并去除停用词,将分词结果转换成TF-IDF模型,并使用决策树对源文本进行分类,最后利用三种不同的语料库训练决策树分类器。
贝叶斯:将数据切分成80%训练集和20%测试集,使用jieba分词器对三类数据进行分词并去除停用词,将分词结果转换成TF-IDF模型,并使用贝叶斯算法对源文本进行分类,最后利用三种不同的语料库训练贝叶斯分类器。
增强多项式贝叶斯:将数据切分成80%训练集和20%测试集,使用jieba分词器对三类数据进行分词并去除停用词,将分词结果转换成TF-IDF模型,并使用多项式贝叶斯作为弱分类器,通过Adaboost集成算法对其加强,对源文本进行分类,最后利用三种不同的语料库训练增强多项式贝叶斯分类器。
随机森林:将数据切分成80%训练集和20%测试集,使用jieba分词器对三类数据进行分词并去除停用词,将分词结果转换成TF-IDF模型,并使用随机森林算法对源文本进行分类,最后利用三种不同的语料库训练随机森林分类器。
RGF:将数据切分成80%训练集和20%测试集,使用jieba分词器对三类数据进行分词并去除停用词,将分词结果转换成TF-IDF模型,并使用RGF算法对源文本进行分类,最后利用三种不同的语料库训练RGF分类器。
实验将本文提出的方法与几种基准模型进行对比,在数据的爬取、预处理、特征提取、向量化一致的前提下,分类时分别选用了决策树、多项式贝叶斯、增强多项式贝叶斯、随机森林以及本文基于RGF算法的增强分类器对文本进行情感分析,实验结果对比如下表3、表4和表5。

表3 各种分类方法在三个数据集上的结果(准确率)

表4 各种分类方法在三个数据集上的结果(召回率)
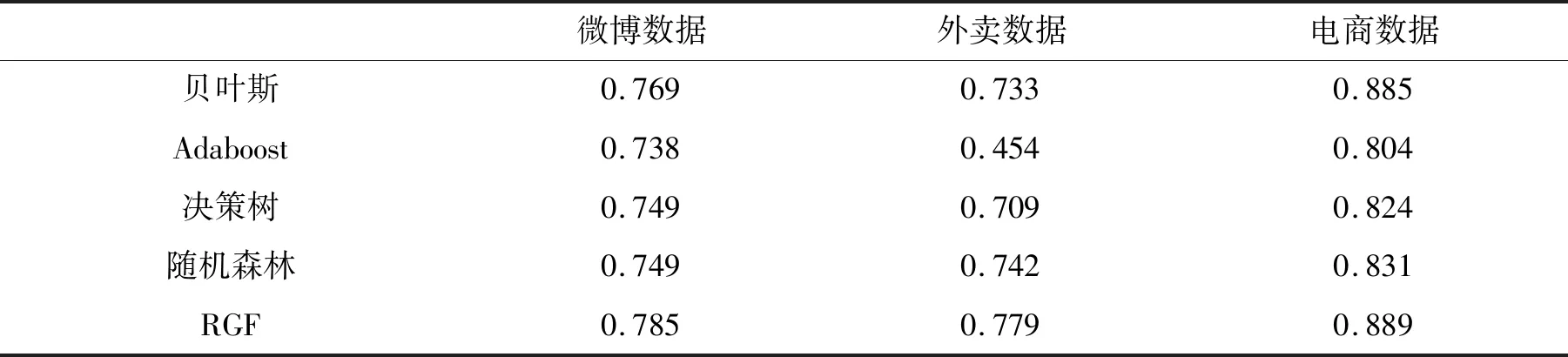
表5 各种分类方法在三个数据集上的结果(F1值)
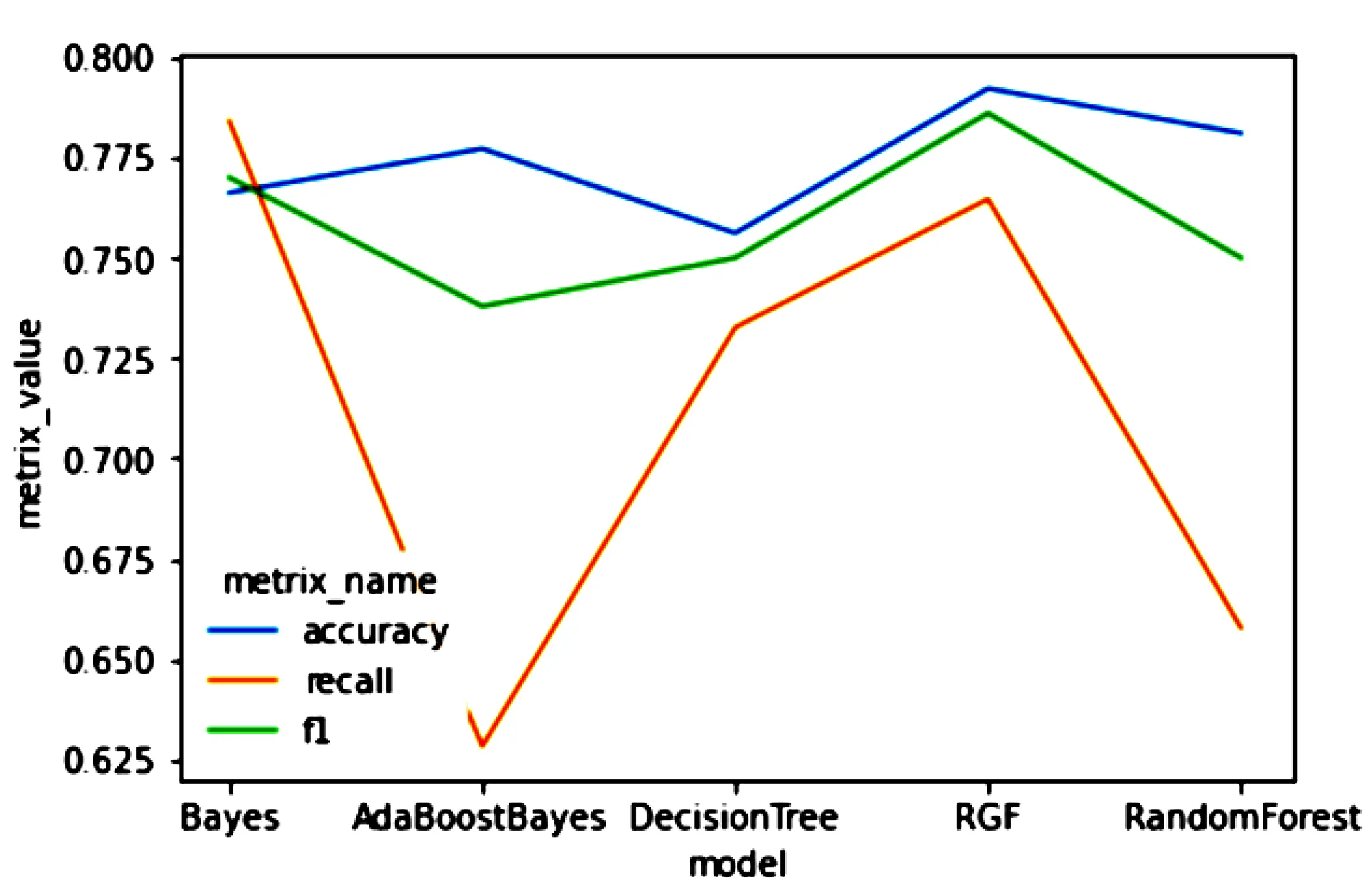
图4 不同分类器对分类效果的影响
从上表可看出,本文提出的基于RGF算法模型的方法进行情感分析结果优于其他方法的效果。另外,在不同的数据集上进行训练和预测的结果也有所不同。从准确率来看,微博数据在五种分类器预测的准确率整体低于外卖数据和电商数据,分析原因可能是微博数据集相较于其他两个更为不平衡,数据整体极性偏向于正面。但是在正负面语料接近1∶1的电商数据中就取得不错的效果,准确率达到了88.7%。对比直接使用决策树进行情感分类,使用RGF算法在准确率上整体提高了4%左右,效果比较理想。从F1值来看,微博数据使用RGF算法对比使用贝叶斯方法提升了1.6%,对比决策树算法提升近4%,而对于电商数据效果不是特别明显,结果表明,RGF算法在针对不平衡数据集时和其他分类器相比分类效果更为明显。
除此之外,针对微博数据集,从不同分类器对分类效果的准确率、召回率和F1值折线图上可以更为直观的看出使用RGF算法进行情感分类效果明显优于其他分类器。对微博不平衡短文本数据集,本文采用的方法在准确率上提高了3.6%,在F1值上提升了3.6%,证明通过正则化贪心森林算法对微博评论文本进行情感分析能够提高分类的效果,验证了该方法的有效性和可行性。
