基于大数据的混合属性图像冗余特征聚类算法
2021-11-13蔡小爱张海民
蔡小爱,张海民
(1.宣城职业技术学院 信息与财经学院,安徽 宣城 242000;2.安徽信息工程学院 计算机与软件工程学院,安徽 芜湖 241000)
0 引 言
图像中蕴含的不同特征为图像管理、存储、分类以及聚类等工作带来了前所未有的挑战[1-3],如何有效对图像中的不同特征进行准确聚类,降低图像冗余特征对图像特征聚类结果的影响已经成为图像处理领域需要共同面对的问题。[4,5]
针对图像处理问题,相关学者与研究人员经过了长时间的研究与实践,得出了不同的聚类方法。文献[6]提出了基于多模态特征的医学图像聚类方法,对不同帧的图像进行特征提取,采用惯性测量单元对相机云顶进行解算,根据解算结果获取前后两帧图像中的特征点,进行特征点匹配,得到匹配结果,根据匹配结果对特征进行融合。实验结果表明,该方法可以适应不同的动态场景,但是该方法存在聚类结果精准度不高的问题,影响聚类结果的可靠性。文献[7]提出了自适应空间信息MRF的FCM遥感图像聚类方法,根据遥感图像中的空间结构特征,建立空间引力模型,同时,建立一个描述空间信息的马尔科夫随机场,将其引入带空间引力模型中,对图像中的边缘细节信息进行保存,从而实现对遥感图像的聚类。实验结果表明,该方法的聚类效果优于一般聚类方法,但是在聚类效率方面还有待提升。文献[8]提出了基于因子图模型的动态图半监督聚类算法,该方法通过捕捉动态图的节点属性与边邻接属性,获取节点的快照信息,并对这些信息进行分类聚类。实验结果表明,该方法能够满足聚类结果的先验知识,能够捕捉动态的演化规律,但是该方法与上述传统方法类似,在聚类结果准确性与聚类时间方面存在不足。
为了解决传统方法在图像聚类结果与聚类时间等方面的不足,提出基于大数据的混合属性图像冗余特征聚类算法,充分考虑多种混合属性图像的特性,通过大数据技术实现对其冗余特征的有效聚类。本文研究的主要创新点如下:
(1)通过建立图像聚类目标函数,实现对图像混合属性特征的分类,降低了特征误分率。
(2)采用大数据挖掘技术对混合属性图像的冗余特征进行进一步聚类,提升了特征聚类的全面性。
(3)最后,通过实验验证了所设计方法的聚类效果,从多方面验证了该方法的应用价值。
1 混合属性图像冗余特征聚类算法
相对于具备相同属性的图像类别而言,混合属性图像特征提取算法需要花费更多的时间进行类别划分,并且在划分中还要保证划分结果的准确性,以保障聚类精度。为此,考虑到图像的语义属性、非语义属性[9],在进行特征聚类之前首先对混合属性进行具体分析,然后建立图像特征聚类的目标函数,借助大数据挖掘技术获取最终的聚类结果。
1.1 混合属性图像分析
在混合属性图像分析中将零样本图像分类数据集Shoes[10]作为理论基础,根据该理论得到混合属性图像构造示意图,如图1所示。

图1 混合属性图像构造示意图
根据图1可知,可以将图像的属性划分为语义属性和非语义属性,其中,语义属性是指图像中包含某种语义信息,具体包括视觉层、对象层和概念层,视觉层具体指颜色、纹理和形状等内容;对象层具体指某一对象在某一时刻的状态;概念层是指图像中最接近人类理解的东西。而非语义属性是指图像不具备语义信息,即除语义信息之外的内容。在实际分类中,可以采用稀疏编码方法实现对图像属性进行分类,通过稀疏编码方法重构图像低层特征,重构后的图像不具备语义信息,即可将其归为非语义属性一类,而剩余部分即为语义属性。同时,采取重复操作的方式保证属性分类的准确性。
根据稀疏编码方法实现混合属性图像分类,针对混合属性图像的语义属性建立一个语义属性集合A,A={a1,a2,a3,a4,...,an},非语义属性集合B,B={b1,b2,...,bn}。由于传统方法在进行属性分析时,得到的图像属性相似性过高,导致图像属性模糊不清,为了避免该问题的出现,将上述属性作为图像特征分类的依据,避免不同属性特征之间的混淆,同时,由于图像特征属性具有有限性[11],因此,针对不同的图像特征进行稀疏编码,并对编码后的图像属性进行重新定义:将语义属性与非语义属性进行混合形成混合属性,有助于实现对相似类别的有效区分,二者之间相互辅助并不会对特征分类造成影响。
1.2 建立图像聚类目标函数
根据混合属性图像分析结果,建立一个图像样本集,S={s1,s2,...,si},其中,i表示样本图像个数,si表示第i个样本的特征值。用l表示特征类别数量,其为一个正整数,在对图像特征进行聚类之前,首先对特征类别进行划分,在图像样本集中获取图像类别Sl。
由于混合属性图像的样本集中包含了大量的样本类型,因此,进行类别划分的任务量非常大,为了获取较为精准的划分结果,可以通过建立一个分类矩阵来实现。[12]在建立分类矩阵之前,先设定一个目标函数,以其作为分类准则:
(1)
其中:Gs表示图像维度;Cs表示概率约束;ai表示语义属性特征的隶属度;bi表示非语义属性特征的隶属度。
通过欧几里得距离实现对样本图像特征之间的差异性测度,具体可以通过公式(2)实现:
(2)
其中:φ表示混合类型目标;αi表示样本的底层特征;λ表示权重衰减系数。
假设样本图像之间不仅具有数值混合特征,而且具有类属混合特征,则不同样本可以通过公式(3)进行表示:
(3)
根据公式(3)可以获得混合类型目标v1和v2之间的差异性测度:
g(v1,v2)=g(v0,v0)+μ(v1,v2)
(4)
其中:v0表示特征之间的差异系数;g表示一个权值,用于调节不同特征在目标函数中所占的比例;μ表示图像特征类型的模糊划分结果。
联立公式(1)-(3)获取更新之后的目标函数:
G'
(5)
根据更新后的目标函数对图像混合属性特征进行分类时,为了使误分率控制在最低值,可以通过模糊划分的形式,分别获取混合类型目标v1和v2的最小值,以此实现对混合属性图像样本的有效划分。
1.3 大数据挖掘下混合属性图像冗余特征聚类的实现
上文通过建立图像聚类目标函数获取了混合属性图像目标划分结果,以划分结果为基础,采用大数据挖掘技术对混合属性图像的冗余特征进行聚类。[13-15]由于传统方法没有针对特征集中的图像冗余特征进行具体分析,导致聚类结果的全面性较差,为此,本文采用数据挖掘技术对混合属性图像的冗余特征进行挖掘,以挖掘结果为基础,再通过聚类集成算法实现对冗余特征的聚类。[16]
首先,根据混合属性特征的隶属度,设置冗余特征挖掘时需满足的条件:
(6)
其中:Ci表示特征集中的子项;Vi表示特征离散程度;Vim表示特征丢失量;an-1表示语义属性特征中的冗余特征;bn-1表示非语义属性特征中的冗余特征。
在满足上述条件的情况下,可以挖掘出图像冗余特征,根据挖掘结果采用聚类集成算法实现冗余特征聚类,具体实现步骤如下:
(1)将bigging思想[17]作为样本挖掘的基础,首先通过样本抽样实现对冗余特征的进一步采集与挖掘,由于运用bigging思想会得到多个样本子集,因此,运用K-means方法再进行深层次的挖掘,该方法可以保证聚类结果近似于实际样本特征结果,在最大程度上实现对冗余特征的聚类。[18]
(2)以运用K-means方法获取的聚类结果为基础,采用聚类集成思想将聚类结果形成一个聚类集,并对聚类结果进行总结。
(3)建立一个互联矩阵,对聚类结果进行分层,再进行特征合并,合并结果作为最终聚类的依据,以此来降低异常值对聚类结果的影响,保障聚类结果的精度。图2为混合属性图像冗余特征聚类流程图。
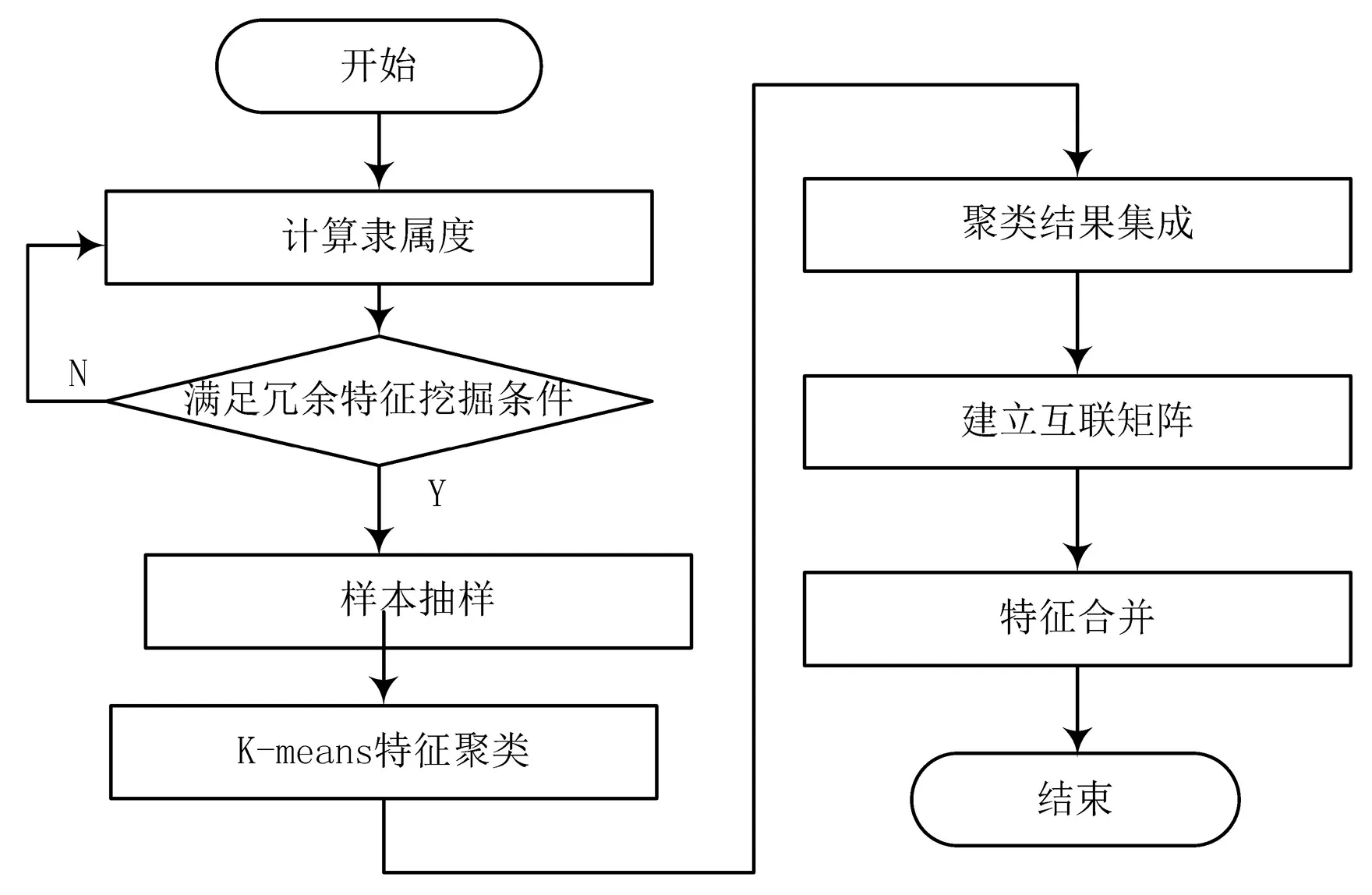
图2 混合属性图像冗余特征聚类流程图
根据上述分析,实现了对混合属性图像冗余特征的聚类,下面对该方法的聚类优势进行分析:
(1)该方法可以在冗余特征聚类样本一致的条件下,对特殊的样本进行有效聚类,解决了传统方法仅面向单一图像属性的问题。
(2)聚类结果中不仅包含语义特征集合,又包含非语义特征集合,聚类结果的覆盖面较广,说明该方法具有全面性的优势。
2 仿真实验验证
为了验证所设计基于大数据的混合属性图像冗余特征聚类算法的有效性,以聚类精度与聚类时间为实验指标,分别采用所设计方法、文献[6]方法、文献[7]和文献[8]方法进行聚类性能测试。
2.1 实验环境设置与数据集构造
在进行测试之前,首先对实验环境与实验中涉及的参数进行具体设置,由于采取的是仿真实验的模式,因此,将不同方法均搭载在同一个仿真平台上,该平台的参数如表1所示。
以表1所示的硬件设计条件为基础,对实验数据集进行构建。为了提升聚类结果的全面性,选取的数据样本中具有10个特征,具体分为类属型与数值型两个类别,每组类别具有3个正态分布的特征点。数据集中总共包含500个样本,样本集中的图像大小均为1 500~8 500pxl,对500个样本通过叠加的方式将特征点由二维扩展到三维模式。同时,对不同类型的特征进行赋值,具体赋值方法为:对大部分特征类型赋予相同的类属值,余下的部分赋予不同的类属值,需要注意的是,该操作应该在随机的条件下进行,并且每个特征的类属值并不代表其类别信息。

表1 仿真平台参数设置
在完成实验环境设置与数据集构造之后,进行实验操作,为了保障实验结果的一致性与可靠性,不同方法统一在表1设置的实验环境下进行训练,并且实验时间保持一致。
2.2 实验结果及其分析
以不同类型图像为测试目标,为测试所设计方法的通用性,在样本图像数量不同的条件下,采用不同方法对混合属性图像冗余特征进行聚类,以聚类精度为对比指标,得出不同方法的聚类结果,如图3所示。
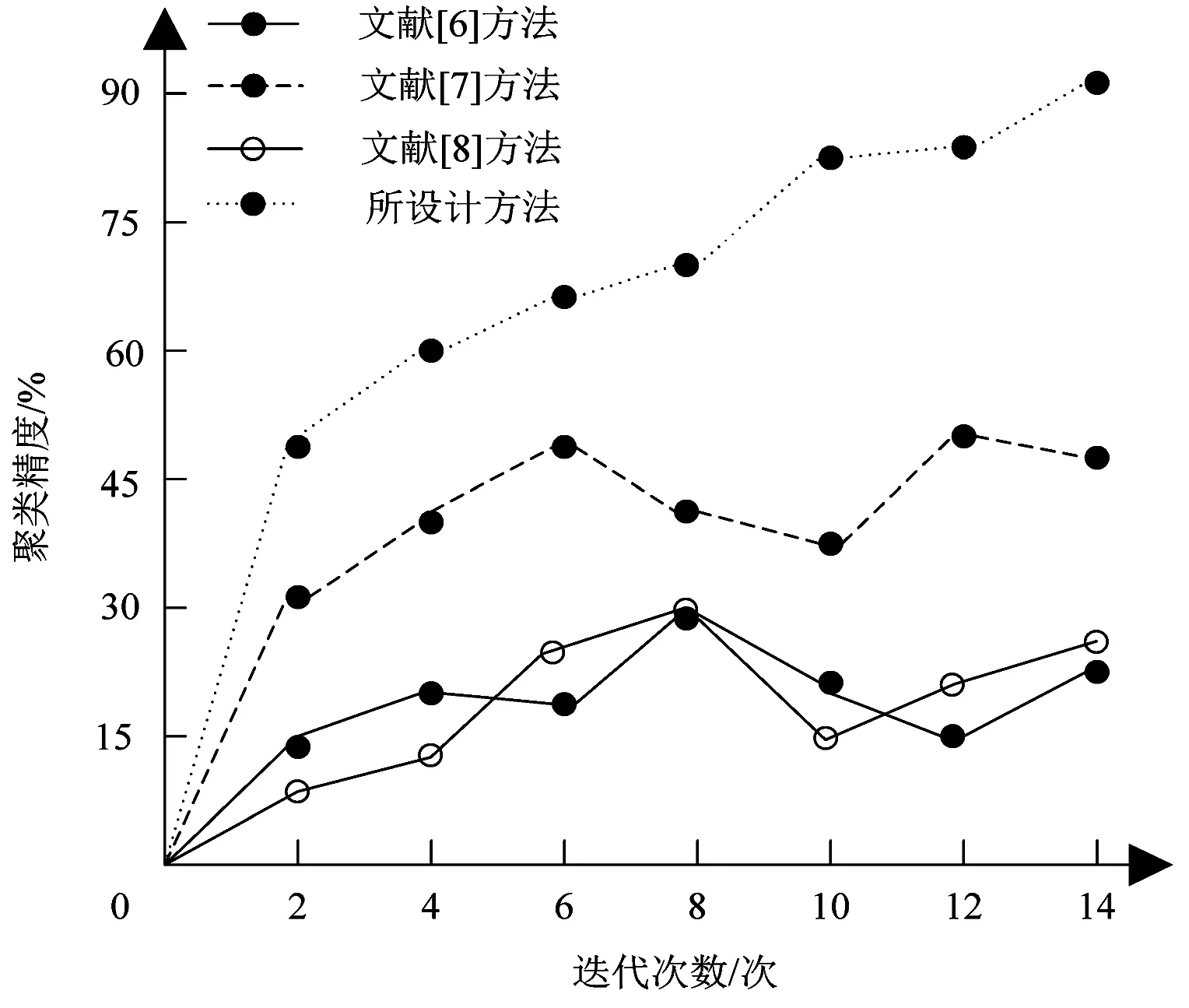
图3 不同方法聚类精度对比
分析图3可知,采用不同方法对混合属性图像冗余特征进行聚类时,当迭代次数为8次时,文献[6]方法的聚类精度为28%,文献[7]方法的聚类精度为42%,文献[8]方法的聚类精度为29%,所设计方法的聚类精度为69%。并且所设计方法的聚类精度最高值达到了90%以上,明显高于传统方法,并且优势从开始聚类到聚类结束能够一直保持,说明所设计方法在聚类精度方面具有显著性优势。这是由于所设计方法在进行冗余特征聚类之前,首先建立一个图像聚类目标函数,在满足该目标函数的前提下,再通过数据挖掘技术挖掘出冗余特征,从而提升了特征挖掘精度。
为了进一步验证所设计方法的全面性,以聚类时间为实验指标,对比不同方法的聚类性能,结果如图4所示。

图4 不同方法聚类时间对比
分析图4可知,所设计方法下混合属性图像冗余特征聚类时间明显低于传统方法,其聚类时间始终低于0.75s,最低聚类时间仅为0.53s,虽然最低聚类时间与文献[8]方法相同,但是传统方法的聚类时间最高值均达到了0.9s以上,不同方法之间的差距仍然十分明显。通过对比可知,所设计方法具有较高的聚类精度,可以在最短的时间内对海量冗余特征进行有效聚类。这是由于该方法通过对混合属性图像的分析,针对不同图像特征进行稀疏编码,有助于实现对相似类别特征的有效区分,降低了后续特征聚类的难度,为特征聚类提供了便利。
综合上述实验结果可知,所设计方法在特征聚类时间和聚类精度方面具有明显的优势,降低了图像处理难度,可以有效排除图像中的冗余特征,为图像分割、图像融合、图像分类等图像处理手段提供良好的基础,可广泛应用于图像处理领域中。
3 结束语
面向不同属性图像进行冗余特征聚类时,由于图像属性在类属与数值方面的差异性,传统方法并不能有效对不同类型特征进行处理,仅能够对单一属性进行有效聚类,在面向混合属性图像特征处理时,存在聚类时间较长和聚类精度较低的问题,为此,提出基于大数据的混合属性图像冗余特征聚类算法。通过分析混合属性图像特征,建立目标函数,在满足目标函数的基础上,采用数据挖掘技术对冗余特征进行分类,最终根据分类结果实现特征聚类。实验结果表明,所设计方法在聚类时间与聚类精度方面均优于传统方法,充分展示了该方法的聚类性能,可以为图像处理领域提供可靠的技术支撑。虽然所设计方法取得了明显的效果,但是为了从深层次提升该方法的应用价值,接下来会将聚类全面性作为研究目标,进一步提升方法性能。
