基于词性标注和规则相结合的信息抽取方法
2021-10-28潘兴明张海波薄佳男秦小龙
张 伟,潘兴明,张海波,何 霄,薄佳男,秦小龙
(1.中国石油工程技术研究院有限公司 北京石油机械有限公司,北京 102206; 2.中国人民大学 信息学院,北京 100872)
0 引 言
在大数据时代,数据作为重要生产要素[1],对企业发展的重要性日益显著。加速推动企业数字化建设势在必行,如何有效地从多种类型的无结构或半结构化文本中获取有效的信息并形成结构化数据,成为该企业数字化建设过程中面临的一大挑战[2]。传统企业日常经营活动过程中会产生大量文本数据,早期对这些文本中信息的收集只能依靠人工整理的方式,再汇总给企业信息管理部门进行处理,形成结构化数据并保存,完成这些工作常常需要专人专职花费大量时间精力、效率低下[3]。近年来,随着自然语言处理技术的快速发展,文本信息抽取已经在情报收集、科技文献监控、医疗保健服务、商业信息抽取等许多领域得到了有效应用[4-6]。李雪驹等提出一种基于规则和SVM相结合的论文抽取方法,该方法先以SVM模型得到论文抽取特征及分类结果,再根据论文中元数据对规则和机器学习方法的不同适用性,结合规则抽取方法去修正,最终得到了想要的抽取结果[7]。余晨根据抽取任务本身及其常见触发词构建自定义海事词库,提出一种基于规则的海事信息抽取方法,将海事自由文本转化为结构化的数据[8]。吴欢提出针对医疗领域具有一定的规范性的乳腺癌病理文本进行结构化处理,实现对非结构化文本的结构化信息提取方法,以辅助临床科研人员进行下一步医学研究[9]。
但在企业实际应用中,文本中每一个目标信息都事关企业业务经营,每一个错误值都会引起不良后果,所以希望模型在满足绝对精确率的基础上召回率越高越好。以上研究方法在具体实际应用中还有欠缺,因此设计一个更加高效的、精准的、能满足企业实际应用需求的信息抽取方法具有重要实际意义。文中提出一种基于词性标注和规则相结合的信息抽取方法,对文本分别采用基于词性标注和基于规则的信息抽取方法进行信息抽取并得到抽取结果,再对结果信息进行合规判断和冲突避免,最后引入人工识别。经实验测试验证,该方法相比于单一信息抽取方法具有更好的效果,能有效满足企业实际应用需求。
1 相关理论基础
1.1 信息抽取
信息抽取(information extraction,IE)[10],指从自然语言文本中抽取指定类型的实体(entity)、关系(relation)、事件(event)等事实信息,并形成结构化数据输出的文本处理技术[4]。信息抽取更侧重文档中颗粒度更小的关系或事件,满足用户更深层和更细粒度的信息需求,是其他信息获取手段的一种有益补充,可以为进一步的自然语言信息处理技术如文档检索、文本分类、文本摘要、情感分析、问答系统等提供支持。国际ACE(automatic content extraction)会议定义了信息抽取的五个子任务,分别为实体的检测与识别、关系的检测与识别、事件的检测与识别、值的检测与识别和时间的检测与识别[11]。
1.2 常用信息抽取方法
1.2.1 基于规则的信息抽取方法
基于规则的信息抽取方法常用正则表达式法,是一种字符串匹配的模式,可以对字符串进行操作的逻辑公式。该方法需要人工事先定义好一些特定字符及这些特定字符的组合,组成一个“规则字符串”,通过这个“规则字符串”实现从字符串中提取特定子字符串的功能。该方法具有较好的灵活性,抽取过程简单易操作,但抽取效果高度依赖制定的“规则字符串”,可移植性较差,适用于对抽取精度较高,表达规范的半结构化文本[12]。
1.2.2 基于统计机器学习的信息抽取方法
基于统计机器学习的信息抽取方法是从大量原始自然语言语料出发,通过已有的统计学、数学原理计算文本不同的特征组合,进行机器学习模型训练,达到预测语言标签、辨识语义状态和规律的目的。与基于规则的方法相比较,基于统计机器学习的方法不需要人工编写规则,具备较好的可移植性。在复杂的任务下,基于统计机器学习的方法比基于规则的方法能取得更好的效果,但存在训练过程依赖大量标注训练语料、训练时间长等问题[13]。
1.3 词性标注
词性标注(POS tagging),又称词类标注或者简称标注,与命名实体识别(NER)、依存句法分析(dependency parsing)一起都是自然语言处理中最常用的基础任务[14]。词性标注是指为分词结果中的每个单词标注一个正确的词性的程序,即确定每个词是名词、动词、形容词还是其他词性的过程[15],常见的词性标注算法包括隐马尔可夫模型(HMM)[16-17]、条件随机场(CRF)[18]等。
2 石油设备日常监控文本的信息抽取
2.1 数据来源及评价指标
文中使用石油设备日常监控文本信息2 029条,对每条文本中10个不同数据值进行信息抽取实验。文本是半结构化形式[19],文本结构基本相同、关键词比较统一、目标信息类型容易事先判断。石油设备日常监控文本每日由现场服务工程师上传至企业业务与档案管理系统,以供相关人员查阅。
文本信息抽取结果包含4种情况,TP表示文本中有数据,成功抽取到了数据数;FN表示文本中有数据,但没有成功抽取到数据数;FP表示文本中缺失数据,但错误抽取到了数据数;TN表示文本中缺失数据,也没有抽取到数据数;一般以精确率P、召回率R和F值作为其性能的评价指标,计算公式分别如下[20]:
(1)
(2)
(3)
式中,P(precision)为精确率,表示在所有数据的样本中成功抽取到正确数据的概率;R(recall)为召回率,表示在所有抽取到的数据中是正确值的概率;F值即为精确率和召回率的调和平均值。
2.2 信息抽取过程
本实验编程语言使用Python 3.6;主要运行环境包括Jupyter Noetbook软件、Win10系统、8 GB内存;哈工大语言技术平台(LTP)提供的自然语言处理技术,包括中文分词、词性标注、命名实体识别、依存句法分析等;使用正则表达式作为规则模式匹配,具体实验流程如下文所述。
2.2.1 构建专用词库
自定义词库包含石油行业和触发抽取任务的关键词[21],石油行业有较多不常用的专业术语、特殊词汇,文本中触发抽取任务的关键词也各有不同。单独使用LTP提供的通用词库对文本进行分词,分词效果不够理想。事先自定义专用词库,再通过LTP提供加载外部词典库方法segmentor.load_with_lexicon(model_path,user_dict),将自定义专用词库与LTP通用词库合并形成专用词库,确保文本分词效果和关键词定位的准确率。其过程如图1所示。
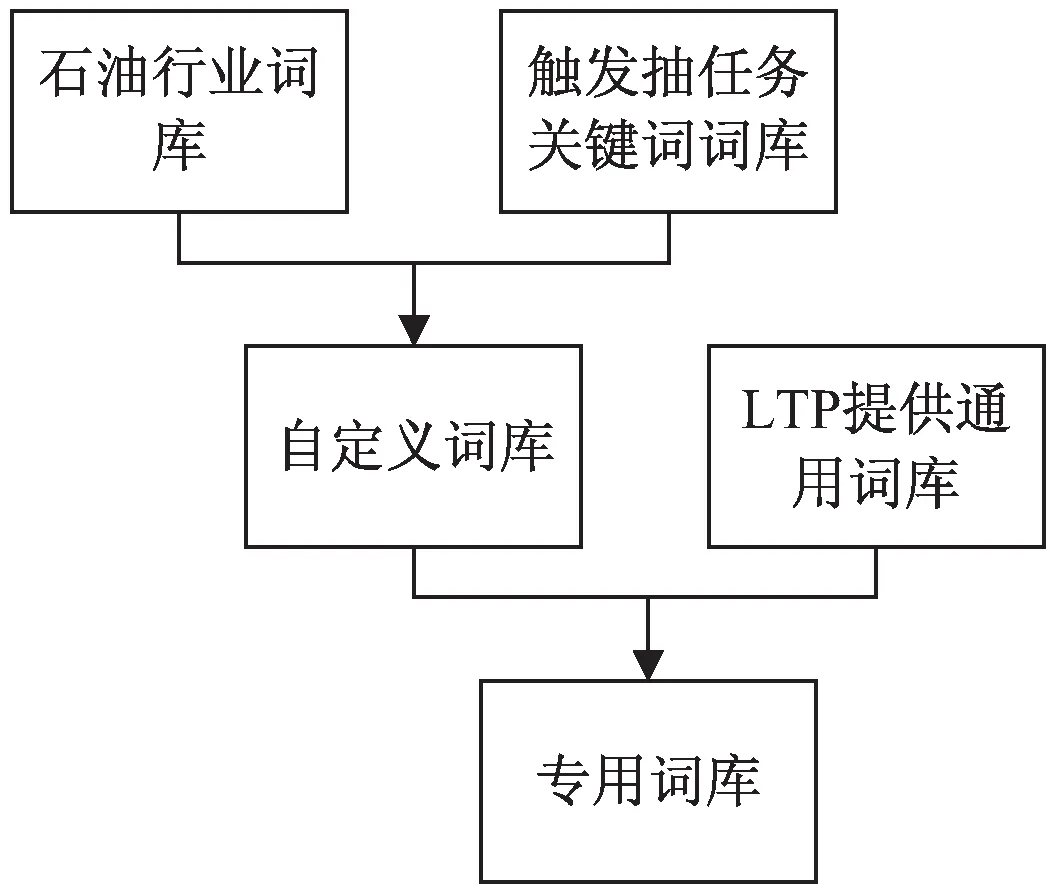
图1 构建专用词库流程
2.2.2 分词效果
笔者分别使用加入了自定义词库和只使用通用词库的模型对样本中某一段文本进行分词和词性标注测试,结果如图2所示。

单使用通用词库分词:井 深 3 458 m , 旋转 导向 仪器 在 下 钻 过程 中 遇阻 , 井 队 词性: n d v wp v n n p nd v n nd v wp n n 分词:循环 泥浆 , 准备 起 钻 。词性: v n wp v v v wp加入自定义词库分词:井深 3 458 m , 旋转导向 仪器 在 下钻 过程 中 遇阻 , 井队 词性: n ws wp n n p v n nd v wp n 分词:循环泥浆 , 准备 起钻 。词性: n wp v v wp
通过测试结果对比,发现加入自定义词库的分词测试中可以更准确地识别石油行业一些特殊词,例如:起钻、下钻、井深、旋转导向等,取得了更好的分词和词性标注效果。
2.2.3 通过关键词定位要抽取的信息位置
对文本进行分句、分词和词性标注,再根据对文本中目标信息的提取要求确定关键词,循环遍历每句、每词查找关键词所在句,定位要抽取的信息所在位置。关键词主要是选取一些不常用但一定会在目标句子中出现的特定词,多与自定义词库相关。例如:当前井深、服务人员等,因此使用合理的自定义词库,可以更加精准地定位到目标信息所在句。
2.2.4 完成信息抽取
(1)基于词性标注的信息抽取方法设计。
定位了目标信息所在句,再通过判断要被抽取的目标信息的词性,在关键词附近查找是否有满足要求的词。例如:原文本中有包含服务人员信息的句子:“服务人员:李艳敏 李双成”,通过在关键词“服务人员”后面查找属于“nh”词性的词,判断是否为需要被抽取的信息。LTP提供的词性对应表如表1所示。

表1 LTP提供的词性对应表

续表1
(2)基于规则的信息抽取方法设计。
定位了目标信息所在句,使用正则表达式进行规则匹配,直接抽取句子中符合要求的信息。基于规则匹配的信息抽取效果非常依赖“规则字符串”质量,每一种类别目标信息都需要特定的“规则字符串”,要求使用者对正则表达式语法使用非常熟练,部分正则表达式语法如表2所示。

表2 部分正则表达式语法
(3)基于词性标注和规则匹配相结合的信息抽取方法设计。
定位了目标信息所在句,对目标句分别采用基于词性标注的信息抽取方法和基于规则的信息抽取方法进行信息抽取,得到抽取结果R1和R2。对结果信息进行合规判断,①如果R1=R2,判断结果都为真,输出结果R1或R2;②如果R1=空且R2≠空,判断结果R2为真,输出结果R2;③如果R1≠空且R2=空,判断结果R1为真,输出结果R1;④如果R1≠空且R2≠空且R1≠R2,说明两种抽取方法结果出现冲突,输出结果标记为-1,标记需要加入后期人工识别。流程如图3所示,图中平行四边形表示目标数据,矩形表示必须处理的过程,椭圆形表示注释。
3 实验结果与分析
选取10项文本中需要抽取的目标信息:时间、井名、服务人员、服务总进尺、当前井深、当前井斜、剩余井深、日进尺、总起钻数、仪器原因起钻数。目标信息包含时间、数值、字符串3种不同类型,结构化信息抽取结果如表3所示。
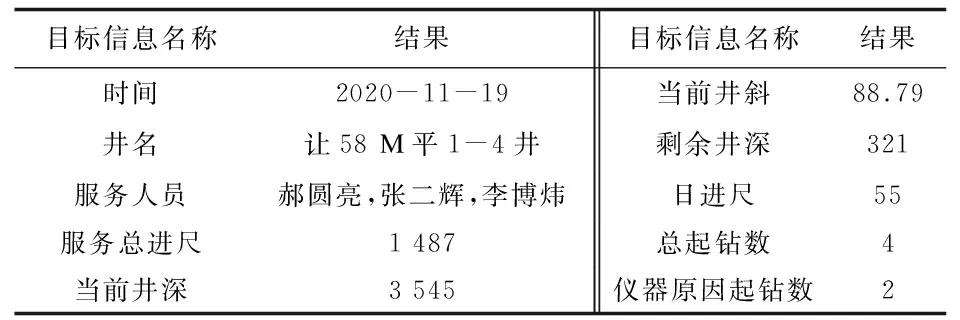
表3 结构化信息抽取结果
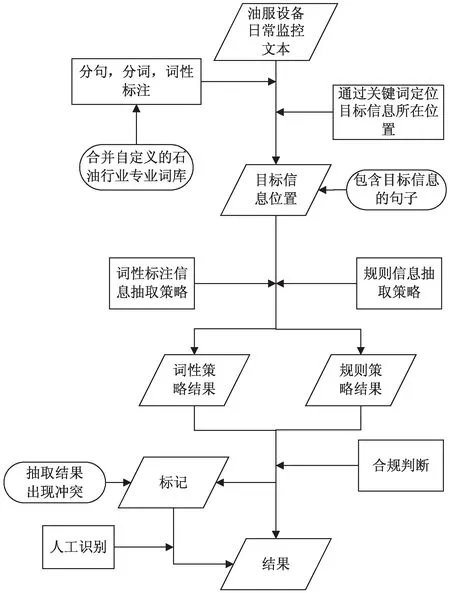
图3 基于词性标注和规则匹配相结合的 信息抽取方法流程
3.1 实验结果
分别采用词性标注信息抽取方法、规则匹配信息抽取方法、词性标注和规则匹配相结合的信息抽取方法进行文本信息抽取实验,结果中不同项对应的信息缺失数如图4所示。

图4 不同项对应的信息缺失数
经过统计,实验共抽取2 029*10个目标数据,其中原文本中就缺失的数据有139个。使用词性标注信息抽取方法得到结果中缺失的数据有695个,使用规则信息抽取方法得到结果中缺失的数据有371个,使用词性标注和规则相结合的信息抽取方法得到结果中数据缺失有160个。
3.2 评 价
通过评价指标公式分别计算出不同方法下的精确率P、召回率R和F值,如表4所示。

表4 效果评价
3.3 结果分析
(1)单使用词性标注方法精确率P达到99.95%,召回率R达到97.28%;单使用规则方法精确率P达到99.90%,召回率R达到98.9%;使用相结合的方法精确率P达到100%,召回率R达到99.87%。实验结果显示相结合的信息抽取方法相比于其他单一信息抽取方法在精确率P、召回率R、F值上都有明显提升;
(2)使用词性标注信息抽取方法在目标信息为“时间”、“井名”、“服务人员”等字符型的抽取任务中,相比于规则信息抽取方法效果更好。使用规则信息抽取方法在目标信息为“当前井斜”、“日进尺”、“总起钻数”等数值型的抽取任务中,相比于词性标注信息抽取方法效果更好;
(3)混合信息抽取方法中文本中有数据,但没有成功抽取到数据的有26个,其中20个是因为文本中出现的关键词是选取的关键词的同义词,例如:当前井深和目前井深;1个是文本中关键词书写错误,所以未能识别出关键词和定位到包含信息的句子;5个数据出现结果冲突,需要引入人工识别。
4 结束语
基于词性标注和规则匹配相结合的信息抽取方法通过对文本分别采用基于词性标注和基于规则的信息抽取方法进行信息抽取并得到抽取结果,再对结果信息进行合规判断和冲突避免,实现对抽取结果的重复确认,保证了抽取结果的精确率。最后再对发生冲突和结果缺失的信息抽取结果进行人工识别并补全,可大幅提高传统信息收集的工作效率。有效满足企业实际应用需求,但仍还有提升空间:
(1)针对实验中因未能识别出关键词同义词和书写错误导致的信息抽取缺失问题,在模型中加入对关键词的同义词识别和文本纠错,可进一步提升模型召回率。
(2)本次实验使用的企业日常经营活动文本属于半结构化类型,信息抽取任务比较简单,所以效果较好。在面对自由文本等复杂信息抽取任务时可以再融合基于统计学习的信息抽取方法得出更为准确的结果。
