基于排序式SVM的搜索自适应排序系统实现
2021-10-28薛晓慧芮光辉李炜东袁培森
薛晓慧,芮光辉,李炜东,袁培森
(1.国网青海省电力公司,青海 西宁 810008; 2.国网青海省电力公司海北供电公司,青海 海晏 812200; 3.南京农业大学 人工智能学院,江苏 南京 210095)
0 引 言
搜索引擎作为一种基于关键字查询的信息检索工具,已经有30多年的发展历史。尤其在最近十年,搜索引擎随着因特网的普及而得到迅速发展,同时搜索引擎向着个性化和智能化的方向发展[1]。搜索引擎的个性化是指搜索相同的内容时会根据用户不同的需求特点,得到不同搜索结果;而智能化则是指搜索引擎能够进行自我学习,自动地适应用户的搜索需求并将用户进行智能分类,从而为搜索引擎的个性化提供依据[2]。
搜索引擎根据检索方式的不同分为独立型搜索引擎和元搜索引擎[3]。目前用户普遍使用的Google和百度是独立型搜索引擎的代表,其原理是利用Robot从网络中搜集信息并且建立属于自己的索引数据库[4]。当需要搜索的时候则检索其索引数据库,再通过数据库的内容搜索到相应的信息或连接站点并提供给用户。元搜索引擎与独立型搜索引擎不同,其原理是将获得的用户搜索需求,交给多个独立型搜索引擎以获得多个搜索结果,之后进行集中处理将处理过的搜索结果返回给用户[5]。目前比较出色的元搜索引擎包括Mamma,MateCrawler,SavvySearch,万纬,360综合搜索等。
元搜索引擎致力于解决人们在搜索时无法得到所需信息的困扰,不至于使用户陷入“信息过载”和“资源迷向”的困境[6]。元搜索引擎集合了多个搜索引擎检索结果并且能对此做出整合处理,有效地解决了独立搜索引擎信息覆盖率不足和查准率不高的问题,为搜索引擎的发展开辟了一个新的方向。目前对于元搜索引擎的研究主要集中在搜索结果的排序和搜索结果的合成等方面[7]。
对搜索结果的排序很大程度影响了用户对搜索结果浏览时的选择,目前研究的方向不仅是单单基于相关度对结果进行排序,而是期望根据用户的个性和特点排序搜索结果[8]。因此,排序学习(learning to rank)这一个概念应运而生,它运用了机器学习的概念,能够基于特征集合产生训练模型,并在之后能够自动学习得到结果,为实现搜索引擎的个性化奠定了基础[9-10]。已有的排序学习算法可以根据训练样例的不同分为3类:单文档方法(pointwise)、文档对方法(pairwise)和文档列表方法(listwise)[5]。一般情况下性能较优的是文档对方法,其原理是采用查询对应的文档对(document pairs)作为训练样例,这类方法中应用较为广泛的是Ranking SVM,一种基于支持向量机(support vector machine)的排序学习方法[11]。
对于搜索结果的合成,由于元搜索引擎从多个独立型搜索引擎得到结果后,不同的搜索引擎采用了各不相同的排序技术,因此没有一个统一的标准去重新排列得到搜索结果,如何将与用户查询相似度高的放在前面的位置是搜索结果合成的关键。目前大部分元搜索引擎会根据局部相似度或全局相似度的计算,将每个成员搜索引擎返回的文档降序排列[12]。例如J. P. Callana等[13]针对搜索引擎返回结果的排序、相关性分值的不同,给出了间隔排列合成法、分值合成法、加权分值法;再如Krisch等[14]提出的通过修改下层搜索引擎以获得更多信息并进行合成处理的方法[8];再如元搜索引擎系统MetaCrawler引入概念可信度来决定文档与用户请求相关程度[15]。
元搜索引擎需要根据相似度来对搜索结果进行合成和排序,而这种相似度通常是通过词频来度量的[16]。但是在中文语境下对于词频的计算并不容易,这是因为英文的单词与单词之间使用空格断开,每个单词分别有各自的语义,电脑也因此能够更容易地识别从而解释这句话;而中文的每个句子由许多字和词组成,而大多数情况下每个字并不是单独表示意思的,必须与其他字组成词才能表达准确的意思,但是词语之间并没有明显的分隔或其他标志[17]。因此对于中文语境下的元搜索引擎,在计算相似度之前需要将搜索的关键字和获取的网页内容进行分词处理[18]。分词方法根据原理可以分为基于统计的,基于词典的。中国科学院计算技术研究所的汉语词法分析系统ICTCLAS(institute of computing technology,Chinese lexical analysis system)[19]是一种性能优越的中文分词器,综合了基于统计和词典的分词方法,有着很好的性能并得到了广泛的应用。
文中基于元搜索引擎的原理以及相关技术方法,设计并实现了一个网页个性化搜索自适应排序系统。该系统使用ICTCLAS中文分词方法对多个独立型搜索引擎的搜索结果进行分词处理,利用TF-IDF算法计算关键词与搜索结果的相似度,以排序并合成搜索结果,再利用Ranking SVM排序学习方法对搜索结果进行重排序以形成对用户个性化的和自适应的搜索结果。实验结果表明,该系统在中文语境下能对多个独立型搜索引擎的结果进行整合,能对整合结果进行个性化的重排序,具有良好的性能和运行效率。
1 技术原理
1.1 排序学习
为了使搜索引擎的结果能够更好地呈现,使其更好地完成信息检索的功能,近年来关于如何利用排序函数的特征去构建有效的排序函数成为热门问题。它运用了机器学习的概念,能够基于特征集合产生训练模型,并在之后自动学习得到结果,为实现搜索引擎的个性化奠定了基础。
排序学习算法需要的数据是由三部分构成的:查询、与该查询相对应的文档的特征序列,以及由人工进行标注的查询与文档之间的相关度[9]。已有的排序学习算法可以根据训练样例的不同分为3类:单文档方法,文档对方法和文档列表方法。单文档方法,如Pranking with Ranking算法,采用一个查询对应的单一文档作为训练样例,而不考虑此文档与该查询对应的其他文档之间的关系;文档对方法,如Ranking SVM算法,采用查询对应的文档对作为训练样例;而文档列表方法,如ListNet算法,采用查询对应的文档序列(document lists)作为训练样例。已有的研究表明,一般来说文档对和文档列表方法优于单文档方法,但是由于文档列表对于训练样例的要求较高,因此系统采用了文档对方法中的Ranking SVM方法对搜索引擎结果重排序的算法。
Ranking SVM是基于支持向量机的排序学习算法。它通过对机器学习中的支持向量机进行训练,并用训练所得的模型对网页进行排序。Ranking SVM的原理如图1所示。
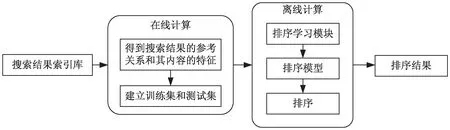
图1 Ranking SVM流程
假设有输入空间X∈n,其中n表示特征数量。有由标签表示的rank值空间Y={r1,r2,…,rq},其中q代表rank值的个数[10]。另外,假设rank值之间存在一个顺序关系rq≻rq-1≻…≻r1,其中≻表示参考关系。存在一系列函数的集合f∈F,集合中每个函数都能确定两个样本之间的参考关系:
(1)
首先,假设f是线性函数:
(2)

将公式(1)和公式(2)相加,得到:
(3)

(4)
根据所给的训练数据集合S,创建了一个新的数据集合S',新的数据集合包含l个标签向量。
(5)

根据SVM原理,得出建立SVM模型就相当于对下面的二次最优问题求解:
(6)

引入拉格朗日对偶公式,把公式(6)经过变化得到以下公式:
(7)
通过求解上述二次规划问题,可以计算出最优解α,依据公式(8)计算出最优特征权向量w。
(8)
如果w是最优权向量,对于一个新样本z,Ranking SVM算法的排序函数f(z)根据公式(9)计算z的排序得分。
(9)
1.2 中文分词方法
在计算词频之前,需要将搜索的关键字和获取的网页内容进行分词处理。中文中每个句子由许多字和词组成,而大多数情况下每个字并不是单独表示意思的,必须与其他字组成词才能表达准确的意思,但是词语之间并没有明显的分隔或其他标志,增加了中文分词的难度[20]。汉语词法分析系统ICTCLAS是常用的汉语词法分析器[19],它使用了基于统计和词典的分词方法,主要功能包括:中文分词、词性标注、命名实体识别、新词识别等。
从结构上来讲,词是由几个字组合而成。因此在检索上下文时,发现有两个或多个字多次相邻出现,则它们就很有可能构成一个词,出现的次数越多,构成词的概率越高。因此字与字相邻共现的频率或概率能够较好地反映成词的可信度[12]。所以只要通过对语料中相邻共现的各个字的组合的频度进行统计,从而计算得到它们的互现信息,即可以此为依据判断这几个字是否为一个词。定义两个字的互现信息如公式(10)所示:
(10)
其中,P(X,Y)是汉字X,Y的相邻共现概率,P(X),P(Y)分别是X,Y在语料中出现的概率。互现信息体现的就是通常意义上汉字之间结合关系的紧密程度,而当紧密程度高于某一个阈值时,便可判定这些字的组合可能构成了一个词。通过上述方法可以根据中文文本识别单词,进而完成中文分词处理。
1.3 网页内容与搜索关键词相似度的计算
对于搜索结果的合成,通常采用的方法是分别计算关键词和搜索结果文本的相似度指标,按照指标进行合成排序。TF-IDF(term frequency-inverse document frequency)算法是一种用于信息检索的常用加权算法,该算法可以有效地评估一个单词在文档集合中的重要程度,以进行关键字提取和分析,广泛地应用于数据挖掘等专业领域[21]。TF-IDF的思想是:如果某关键词在一段文本中出现的频率高,而在其他文本中很少出现,则认为此词具有很好的类别区分能力,也就是这个关键词与这一段文本相似度高,应该出现在合成结果的前面。
关键词在一段文本中出现的频率可以用词频(term frequency,TF)来衡量,其计算公式如式(11)所示:
(11)
其中,T是搜索的关键字在文档中出现的次数,F是整篇文章词语的总数。
关键词在其他文本出现的频率是否较低,或者说这个词语的普遍重要性,可以用逆向文档频率(inverse document frequency,IDF)来衡量,其计算公式如式(12)所示:
(12)
其中,N表示文档的总数量,M表示包含该关键字的文档数量。
TF-IDF算法是计算一个关键词在文档集合中的TF-IDF指标,这项指标是TF指标和IDF指标的乘积,即TF-IDF=TF×IDF。对搜集到的每个搜索结果文本,计算对应的TF-IDF指标,若该指标越高,则说明该关键字在一条搜索结果文本中出现的次数越多,其重要性越高,同时也说明这个关键字与这项搜索结果的相似度越高,能更好地体现和概括文档内容,进而说明该搜索结果是用户期望得到的,应该放在前面;反之若TF-IDF指标越低,则说明该条搜索结果重要性越低,应该放在后面。使用TF-IDF算法计算相似度指标,相较于传统的TF算法,降低了考虑IDF的所带来结果的不可靠性[22]。
2 系统结构和流程
2.1 系统结构
系统功能模块主要由网页数据获取、数据处理排序以及用户界面三个部分组成,系统的内核包括:(1)根据网页的URL得到百度、有道和360搜索引擎的搜索结果;(2)利用HtmlParser解析工具解析网页的HTML;(3)利用ICTCLAS分词工具对解析的结果进行分词处理;(4)利用TF-IDF算法计算关键字和搜索结果文本的相似性,据此排序;(5)在得到训练集和测试集之后,利用Ranking SVM实现对搜索结果的重排序,处理过程如图2所示。
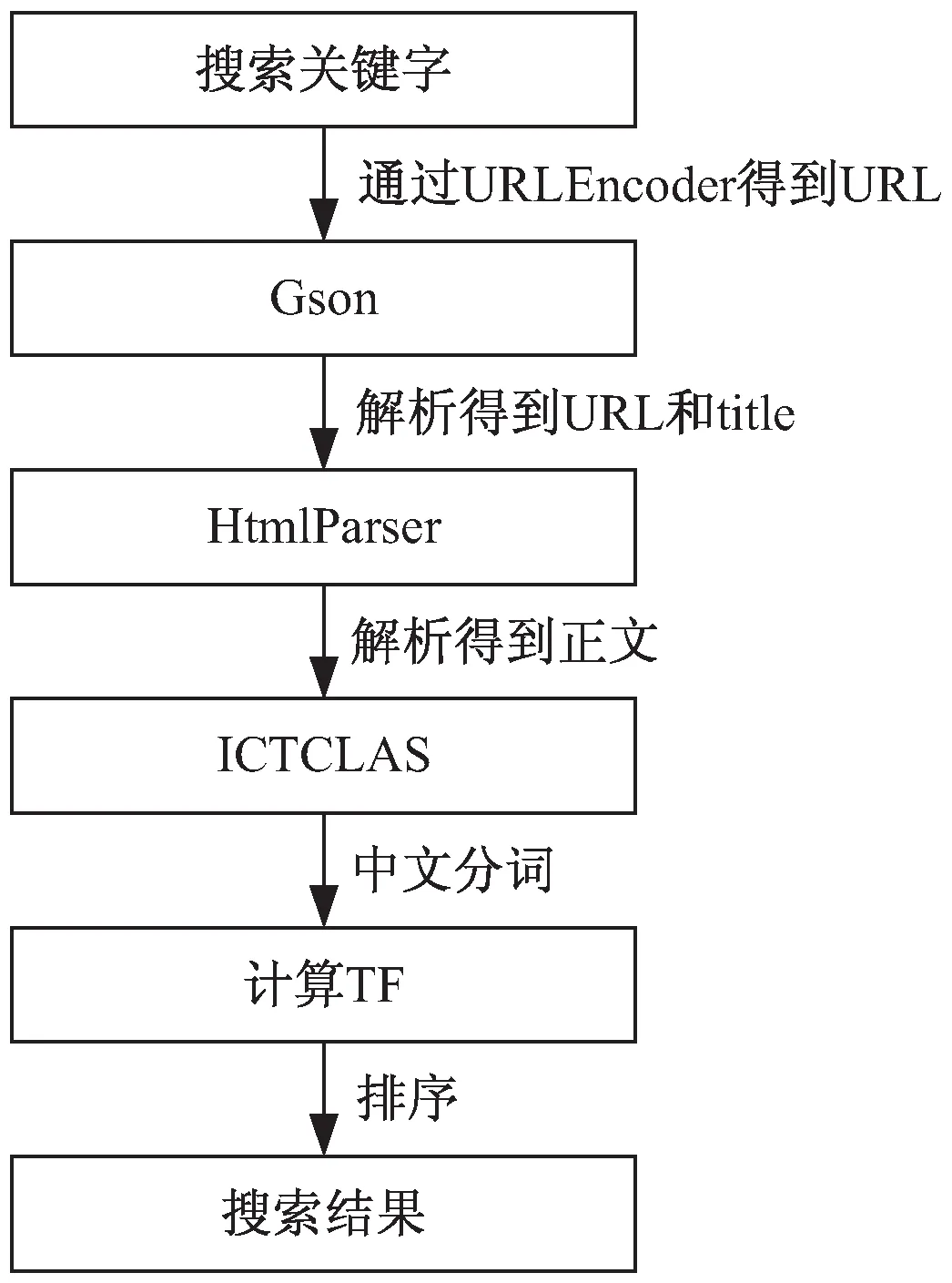
图2 搜索引擎程序实现原理
第(1)步需要使用URLEncoder工具,由于客户端在进行网页请求的过程中,不允许出现非ASCII码的内容。然而本系统是针对中文的个性化搜索引擎,请求中必然包含中文,需要使用URLEncoder将中文请求进行转换以生成请求交由独立型搜索引擎处理。URLEncoder的转换方法是:(a)将请求中的非ASCII字符用其16进制的Unicode编码表示,并在前面加上“%”;(b)请求内容中的空格全部用“+”代替;(c)其余ASCII字符不处理。
第(2)步是对独立型搜索引擎返回的搜索结果进行解析,返回的结果是HTML形式的,因此可以考虑使用HtmlParser工具对HTML进行解析,得到搜索结果正文。HtmlParser可以对HTML文档的DOM进行解析,进而提取出搜索结果的标题文本和正文文本。
第(3)步使用ICTCLAS分词工具对解析得到的独立型搜索引擎的结果进行分词,将连续的文本根据中文语法分割成一个个单词并标注词性。另外标注词性之后,需要对搜索结果文本中的无意义的虚词(例如助词,语气词,叹词等)进行删除,这样处理可以在下一步计算相似度的TF-IDF方法有更好的区分度。
第(4)步使用TF-IDF算法计算搜索关键词和搜索结果文本的相似度并进行排序,按照1.3节所述的方法进行计算,得到每一条搜索结果的TF-IDF指标,按照该指标降序排列并合成搜索结果。
第(5)步则使用Ranking SVM对结果进行重排序,该步骤的目的是根据用户的偏好,提供更加个性化的搜索结果。该方法会记录用户的个人偏好以形成训练集,使用Ranking SVM进行训练以生成排序学习模型,根据训练得到的模型,对上一步结果使用TF-IDF算法合成得到的搜索结果进行重排序,最终得到个性化的自适应排序搜索结果。
2.2 系统运行流程
关于搜索引擎的系统流程设计,主要分为多个搜索引擎搜索结果的获取,对搜索结果内容与标题的解析,对内容与标题的中文分词,计算内容、标语与搜索关键字直接的相关度,确定搜索结果的排序,系统运行时,直接进入搜索界面,输入关键词即可查询,得到搜索结果,系统运行流程如图3所示。

图3 系统运行流程
为了形成个性化的搜索结果,需要保存用户的搜索记录供Ranking SVM训练使用,因此设计了登录系统和数据库,用于收集和存储用户的搜索记录,同时后台也可以获取这些用户信息进行排序学习,从而完成对搜索结果个性化重排序的功能。如果用户不进行登录,则得到的搜索结果仅为根据关键词和搜索结果相似度排序得到的合成搜索结果,不具有个性化的特征。系统支持用户多次查询,用户查询次数越多,系统的个性化排序效果越显著。
3 实验和结果分析
3.1 实验环境
CPU:Intel(R) Core(TM) i3 CPU;内存:8 GB;开发用JDK版本 1.8;依赖项:Gson,HtmlParser,ICTCLAS,Ranking SVM。
3.2 系统性能测试
在线搜索结果的时间由搜索的关键字、网页内容、网速等多种因素决定,实验中选取部分具有代表性的关键词进行搜索并记录搜索时间,实验结果如表1所示。

表1 性能测试结果
目前,由于没采用缓存,系统的搜索时间还有较大的优化空间。根据性能测试结果可以发现,对于一些较为宽泛的关键词(例如计算机、语文等),搜索用时较长,这是因为这一类关键词独立型搜索引擎得到的结果数量就比较庞大,因而计算相似度和重排序的规模也比较大,最终导致用时增加;而对于一些比较明确的关键词(例如南京大学等),搜索用时较短,同理是因为这类关键词独立型搜索引擎结果数量较少导致的。
3.3 系统流程测试
输入“计算机”关键词,系统排序结果对比如图4所示。其中图4(a)是使用TF-IDF算法对搜索结果的合成,图4(b)是使用Ranking SVM对搜索结果的重排序,可以看出顺序已经调整,更加符合用户的使用偏好。
对于关键词“计算机”,经过TF-IDF计算相似度排序合成的搜索结果,可以看到“计算机互动百科”这一项出现在了第3个到第5个,而“计算机基础知识教程”这一项出现在第1个和第2个,这是因为“计算机基础知识教程”这一项的搜索结果文本包含了大量“计算机”这一关键词,导致其TF-IDF指标比较大,所以合成排序结果的时候会前置,而“计算机互动百科”这一搜索结果对应的TF-IDF指标就比较小,所以排在稍后的位置。而经过Ranking SVM对结果进行了重排序,由于系统已经记录了用户的搜索记录并训练了排序学习模型,该用户在之前的搜索中偏向于选择与这个关键词相关的百科,因此在重排序的过程中将“计算机互动百科”放在了前面,变成了第1个到第3个,而“计算机基础知识教程”则被重排到了第8个和第9个。

图4 排序结果示例
通过上述分析可以发现,该系统可以按照前文所述的TF-IDF算法依据相似性对独立型搜索引擎的结果进行合成,同时Ranking SVM可以记录用户的搜索记录生成排序学习模型,对合成的搜索结果进行个性化的重排序,提供给用户自适应的个性化搜索结果。
4 结束语
基于元搜索引擎的原理以及相关技术方法,文中设计并实现了一个网页个性化搜索自适应排序系统。该系统使用ICTCLAS中文分词方法对多个独立型搜索引擎的搜索结果进行处理,使用TF-IDF算法计算相似度指标以合成搜索结果,再利用Ranking SVM排序学习方法对搜索结果进行重排序以形成对用户个性化的和自适应的搜索结果。使用Java和JSP实现该系统,实验结果表明,该系统在中文语境下能对多个独立型搜索引擎的结果进行整合,能对合成后的搜索结果进行个性化的重排序。
