基于正则化逻辑回归的阿尔茨海默病早期诊断模型*
2021-10-25张贻泉徐培然韩莉莉张宝昌肖如意刘汉磊崔新春
张贻泉, 徐培然, 韩莉莉, 张宝昌,肖如意, 刘汉磊, 崔新春
(①曲阜师范大学计算机学院,276826,日照市;②济宁学院计算机科学系,272071,济宁市;③曲阜师范大学管理学院,276826,日照市;④济宁医学院网络信息中心,273100,山东省济宁市)
0 引 言
阿尔茨海默病(AD)是一种退行性神经疾病,一旦患病不可逆,最常见于老年人[1].2017年全世界有3000多万人患有AD,到2050年这个数字将增加2倍[1].由于世界人口老龄化的发展,患有阿尔茨海默病和其他形式痴呆的人数迅速增加,这是对世界范围内保健和社会保健系统的一个重大挑战.轻度认知障碍(MCI)是介于正常和AD之间的一种中间状态.据估计,年龄在58岁以上的MCI患者中有40%~60%有潜在的AD病理[2].每年大约有15%的MCI患者转换成AD.因此,准确诊断AD和MCI对延缓疾病进展具有重要意义.但MCI患者临床症状不明显,这一阶段的诊断非常困难.因此,设计和实施正确识别MCI不同阶段(早期轻度认知障碍(EMCI)和晚期轻度认知障碍(LMCI))的方法具有重要意义.
近年来,计算机辅助诊断AD和MCI引起了人们的广泛关注[3].许多机器学习方法已经成功地应用于AD分类领域[4].其中逻辑回归(LR)被认为是一种较强的判别方法.LR有一个直接的概率解释,它可以获得除类标签信息之外的分类概率[5,6].然而,高维问题的求解仍然具有挑战性[7,8].与从MRI数据中提取的特征向量维数相比,用于训练的样本数量通常非常小.这可能会导致逻辑回归模型的过拟合问题,带来较大的计算压力[9,10].为了解决这个问题,在最近的文献中提出了许多优化方法.Koh等人[11]引入L1正则化逻辑回归作为解决大规模问题的特例.L1正则化可以缩小回归系数,同时选择较小的特征子集[12].L1正则化具有一定的优点,但也存在一些不足.首先,L1正则化在某些情况下会产生不一致的特征选择,并且在参数估计时经常引入额外的偏差[13].其次,L1正则化只在一组相关特征中选择一个基因.最后,L1正则逻辑回归是不可微的.它有许多计算上的挑战,特别是当任何一个权值为零时.Jorge等[14]和Zhang等[15]采用L2正则化逻辑回归对AD进行分类.L2正则化直接对每个特征的权值进行优化,获得优异的性能[16].此外,L2正则逻辑回归平滑且凸,计算比较容易.L2正则化虽然可以将特征的权重限制在尽可能小的范围内,但不能减少特征的数量.本文采用独立成分分析方法对数据进行降维,利用ICA作为一种应用广泛的降维算法,提高了计算效率,减少了特征个数.因此,我们在逻辑回归模型中加入ICA和L2正则化,提高AD的分类效果,避免过拟合问题.值得注意的是,逻辑回归的目标函数没有解析解,不能直接得到最优参数,只能采用迭代法求解[17].牛顿算法是优化的最常用算法之一,该算法相对简单过程容易控制.我们利用牛顿算法对模型进行优化,得到一个最小的损失函数.
1 材 料
1.1 ADNI数据库
本研究使用的所有数据均来自阿尔茨海默病神经成像倡议(ADNI)数据库(http://www.loni.ucla.edu/ADNI).ADNI是一个非营利性组织,由美国国家生物医学成像和生物工程研究所于2003年成立[18].ADNI用于检测序列磁共振成像(MRI)、正电子发射断层扫描(PET)、其他生物标志物、临床和神经心理评估是否可以结合来测量MCI和AD的进展[19].ADNI提供不受限制的数据访问,并鼓励研究人员开发分析.

图1 AD早期诊断框架
1.2 受试者
结构磁共振成像(MRI)是一种广泛应用于AD诊断和预测的成像方式[20].MRI图像易于获取,具有良好的诊断准确性[21].可以获得大脑的形态学数据,如灰度密度、灰体积、皮层厚度.因此,使用结构MRI图像进行分析.我们选择了197例ADNI数据库中的MRI图像,其中AD 51例、CN 50例、MCI 96例.96名MCI受试者中,LMCI 51名、EMCI 45名.
1.3 系统框架
本文提出的AD早期诊断框架如图1所示.该框架包括图像预处理和特征提取,独立成分分析和RLR模型.详细信息将在下一节中描述.

图2 图像预处理和特征提取过程
2 方 法
2.1 数据预处理和特征提取
从ADNI数据库下载的MRI图像需要进行一系列图像预处理,提取90个感兴趣区域的灰质体积作为有效特征.将有效特征输入到分类器中进行分类.图2展示的是图像预处理和特征提取过程.
本文使用SPM8软件(http://www.fil.ion.ucl.ac.uk/spm/)和VBM8工具箱对MRI图像进行预处理.预处理过程包括5个步骤,即(1)颅骨剥离(移除非脑组织),(2)空间标准化和分割灰质(GM),白质(WM)和脑脊液(CSF),(3)平滑(去除图像的噪声),(4)配准(将每个受试者的灰质图配准到一个AAL的模板),(5)选择90个感兴趣区域的灰质体积作为特征. 我们提出的诊断算法见下页表1.
2.2 独立成分分析
ICA是一种将多元分量分离为若干统计独立分量线性组合的计算方法,它帮助降低数据噪声,提高分类精度.每个样本包含90个特征,整个数据集包含197幅图像,总共有17730个功能,计算量很大.为了减少计算量,使用独立成分分析方法对数据进行降维.独立成分分析有以下步骤.
协方差矩阵的特征分解:
(1)
(2)
其中,D是特征值构成的对角矩阵.白化过程
如下
(3)
通过白化将混合矩阵转换为Y
(4)
因而通过ICA的白化过程对所需的矩阵进行了降维.
2.3 逻辑回归模型
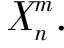
(5)

(6)


表1 基于L2正则化LR的AD诊断算法
2.4 稀疏逻辑回归模型
为了简化逻辑回归模型,避免过拟合,引入正则化逻辑回归模型用于AD的早期诊断,提高分类精度.L2正则化可以防止模型过拟合,经常用于约束损失函数.基于公式(6)的RLR损失函数定义为
(7)

2.5 优化算法
本研究使用牛顿算法来最小化公式(7)中的目标函数,选择最优的权值.表2总结了牛顿算法的步骤.

表2 基于牛顿法的迭代算法

2.6 L2正则化逻辑回归的AD诊断算法
本文提出的基于L2正则化逻辑回归的AD早期诊断.算法的整个过程主要包括如下几个部分.首先,对sMRI图像进行预处理,提取90个感兴趣区域的灰质体积作为特征.其次,采用ICA对数据进行降维,选择重要的特征用于分类.最后,将L2正则化逻辑回归用来对AD进行分类.算法的具体过程如表1所示.
3 实验与结果
3.1 实验设置
本文考虑了3个分类任务,即AD受试者与CN受试者(AD vs.CN)、MCI受试者与CN受试者(MCI vs.CN)和LMCI与EMCI (LMCI vs.EMCI).在所有分类方法中,训练集和测试集的比例都是7∶3.为了避免随机影响,实验重复100次.对该模型进行了测试,并与LR、LR-PCA和RLR进行了比较.所有比较方法的性能通过计算准确性(ACC)、敏感性(SEN)、特异性(SPE)、受试者工作特征曲线(ROC)和受试者工作特征下面积(AUC)来量化.具体公式定义为:
(8)
(9)
(10)
ROC曲线是研究分类器性能的有力工具.在ROC曲线上,横轴为假阳性率(FPR),纵轴为真阳性率(TPR).公式为:
(11)
(12)
真阳性(TP)是正确分类的疾病类别的患者数量.真阴性(TN)是指健康人被正确划分为健康类的数量.假阳性(FP)是指把健康人划分为病人的数量.假阴性(FN)是指将病人划分为健康人的数量.图3和图4分别表示了3种双比的ROC曲线.

图3 AD/MCI不同分类方法的ROC曲线 图4 LMCI和EMCI不同分 类方法的ROC曲线
3.2 结果分析
ICA的累计贡献率设定为95%.在数据集AD vs.CN,MCI vs.CN和LMCI vs.EMCI中,特征的数量分别减少到35,40和24.表3列出了AD/MCI不同分类方法的比较.
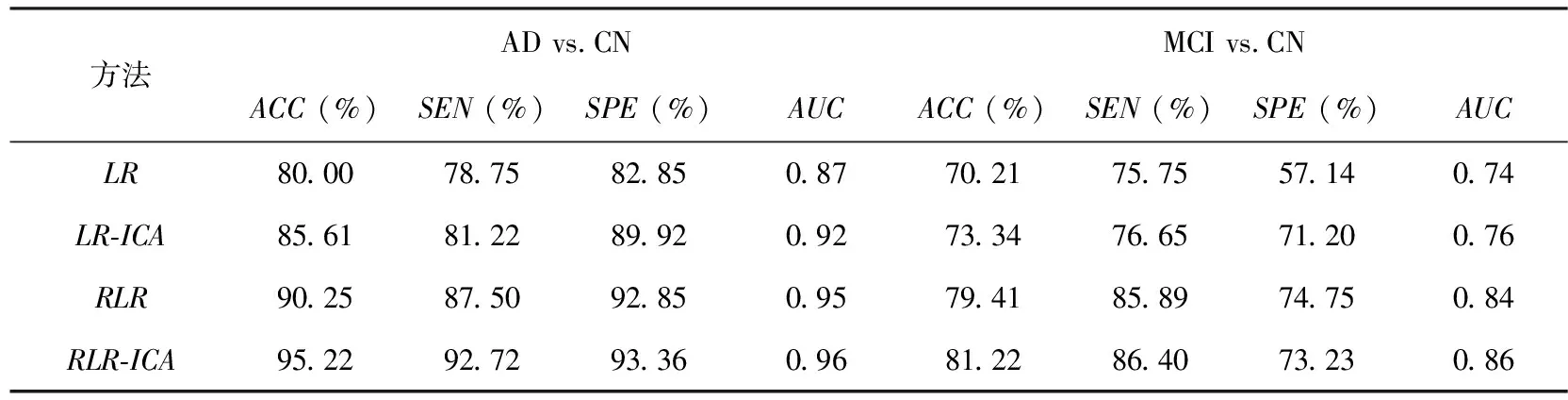
表3 AD/MCI不同分类方法的比较

表4 LMCI和EMCI患者的分型表现

表5 不同的方法在AD上分类性能的比较
从表3可以看出,本文方法在分类准确率、敏感性和特异性方面都优于其他竞争方法.具体来说,对于AD和CN的分类,本文方法的分类准确率为95.22%,灵敏度为92.72%,特异性为93.36%,曲线下面积(AUC)为0.96.对于MCI和CN的分类,该方法的分类准确率为81.22%,灵敏度为86.40%,特异性为73.23%,曲线下面积(AUC)为0.86.特别是RLR-ICA在AD与CN分类中具有最好的敏感性,表明我们提出的方法能够有效识别AD患者.高灵敏度值表明对疾病诊断有很高的信心.因此,从临床的角度来看,与上述方法相比,RLR-ICA较不容易误诊.
图3为相应的ROC曲线.从ROC曲线可以看出,RLR-ICA在3个分类任务上明显优于其他所有方法,采用L2正则化和ICA的RLR取得了更好的结果,说明L2正则化和ICA能够提高LR的分类性能.我们也进行了MCI不同阶段的分类实验,结果如表4和图4所示.
从表4和图4可以看出,与其他方法相比,本文方法在LMCI和EMCI中取得了更好的分类性能,提出的RLR-ICA方法各项指标均优于其他几种逻辑回归模型.具体来说,本方法在LMCI和EMCI上的分类准确率达到74.35%,这对于AD的早期诊断至关重要.
为了进一步评价RLR-ICA方法对AD早期诊断的疗效,我们列举了近年来一些有代表性的方法[8,22-26].使用AD的分类精度作为性能衡量.在表5中,对于使用多模态生物标志物的多项研究,仅使用MRI数据报告我们的结果;使用多模态数据报告他人的结果.RLR-ICA方法尤其在分类精度方面均优于表中其他人提出的方法.本文提出的AD诊断框架与其他研究相比仅采用了MRI数据作为AD,LMCI,EMCI,CN的分类依据.在文献[23]中,提出一种将多图像归一到同一公共空间的方法,这意味着更多的信息被考虑在内.在文献[26]中,提出一种基于监督学习的计算机辅助诊断方法,利用ROI作为评价指标进行了实验.这种方法的特征提取方法与我们提出的方法不尽相同.这种比较可以在一定程度上显示RLR-ICA方法的有效性.在大多数情况下,RLR-ICA方法的准确性均优于其他比较方法,说明RLR-ICA在AD的早期诊断中具有更好的诊断效果.
4 结 论
本文提出了RLR-ICA方法来识别AD受试者、MCI受试者和CN受试者.为了防止模型对数据过拟合,使用ICA对数据进行降维,并使用L2正则化来限制系数的权重.我们在基线ADNI数据库和MRI数据上评估此方法.该方法对AD与CN和MCI与CN的分类准确率分别为95.22%和81.22%.实验结果表明,该方法的性能可以与现有技术相媲美.特别是在LMCI和EMCI中的分类准确率为74.35%,可以区分MCI的不同阶段.这对MCI的及时诊断和治疗具有重要价值.在今后的工作中,我们将进一步优化逻辑回归模型,提高模型的分类性能,更好地预测AD的早期阶段.
