面向滚动轴承故障诊断的改进对抗迁移学习算法研究
2021-10-23李立新廖晨茜蔡晋辉曾九孙
杨 健,李立新,廖晨茜,蔡晋辉,曾九孙
(1.中国计量大学,浙江 杭州 310018;2.中电海康集团有限公司,浙江 杭州 310000)
0 引 言
传动装置在工业生产中是常用的机械设备,它的平稳运行离不开轴承的正常工作。轴承一旦发生异常,有可能引发设备的故障,严重时还可能造成生命和财产的重大损失。为保障传动装置的安全平稳运行,研究人员对轴承的故障诊断问题进行了大量研究。这些研究通常以轴承工作时采集到的振动信号为基础,并通过机器学习等方法进行特征提取和故障诊断研究。
考虑到机械设备采集的时间信号易受外部干扰,因此需要寻找合适的方法从振动信号中提取有用的信息,常见的方法如小波变换,傅里叶变换等。在提取了有效的特征之后,再利用支持向量机[1]、神经网络[2]等机器学习方法对故障数据进行分类,从而实现故障的诊断。此外,各种深度学习技术在故障诊断领域中得到了应用并取得了良好的效果,如深度置信网络[3]、卷积神经网络[4]等。这些方法在训练数据和测试数据具有相同分布时取得了较好的应用效果。但在很多实际应用中,训练数据集和测试数据集是在不同的工作条件中采集到的,此时现有方法难以获得较好的识别效果。为解决该问题,研究人员提出了基于迁移学习(transfer learning)的方法,这类方法通过学习相关领域的特征来提高本领域中学习的表现,放宽了训练数据和测试数据同分布的要求,解决了测试数据不足产生的过拟合问题[5]。
近年来,研究人员发现将对抗学习(adversarial learning)[6]与迁移学习结合,即利用对抗迁移学习,能够更有效地减少源域和目标域数据之间的分布偏差,从而有利于提高分类准确率。该方法由特征提取器,域判别器和分类器组成,特征提取器用来提取原始数据样本特征,域判别器用来判断数据属于源域还是目标域,通过对抗训练不断改善模型性能[7]。考虑到现有对抗迁移学习方法的主要应用领域在图像处理,存在难以处理时间序列数据、易受梯度消失现象影响等问题[8],本文提出了一种改进的基于对抗迁移学习的轴承故障诊断方法。在对抗迁移学习的基础上,将特征提取器替换成一维卷积结构,直接作用于时间信号,非常适用于振动数据的处理;同时将域判别器中全连接网络结构替换成卷积结构,减少了因层数限制导致的梯度消失等现象,增强了信息整合能力,实现了分类精度的提高。
最后为了提高故障诊断效果,在不同数据集上进行了试验,验证了该模型的有效性。
1 背景理论
1.1 迁移学习
迁移学习是一种新型的机器学习方法,通过将已训练好的模型参数迁移到新的模型,以加快并优化新模型的训练,非常适用于解决故障诊断中的训练数据不足的问题。
迁移学习由域和任务两个概念组成,域包括特征空间 χ及总体概率分布p(x),记为D={χ,p(x)},其中(x1,x2···xn)∈χ为总体样本。给定带标签的源域数据DS={χs,p(xs)}及 不带标签的目标域数据Dt={χt,p(xt)},由于工作环境的不同,两个数据集之间的分布也不相同,即p(xs)≠p(xt)。迁移学习的任务是将源域数据xs和目标域数据xt映射到相同的特征空间,通过寻找具有代表性的特征使源域和目标域数据具有相同的分布。在建立起源域数据的分类模型后,就可以对目标域数据进行准确分类。常用的映射函数包括核函数、卷积函数等,分类模型通常采用全连接神经网络。其具体思路如图1 所示。
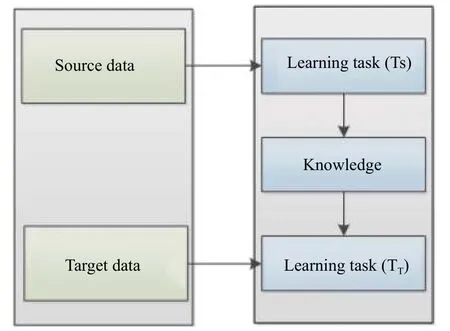
图1 迁移学习过程
1.2 对抗学习
对抗学习受生成对抗网络[7]的思想启发,通常用于生成接近于真实样本的虚假数据,其结构如图2 所示。从图2 可以看出,对抗学习的模型由生成器和判别器组成,通常均采用多层感知机。记生成器为G(·),判别器为D(·),对抗学习首先随机生成一组噪声变量n∼pn(n),通过生成器进行训练得到一组虚假样本G(n),使其尽可能接近真实数据x∼px(x);同时还需要使得得到的虚假样本G(n)和真实样本x能够有效地被判别器所鉴别。
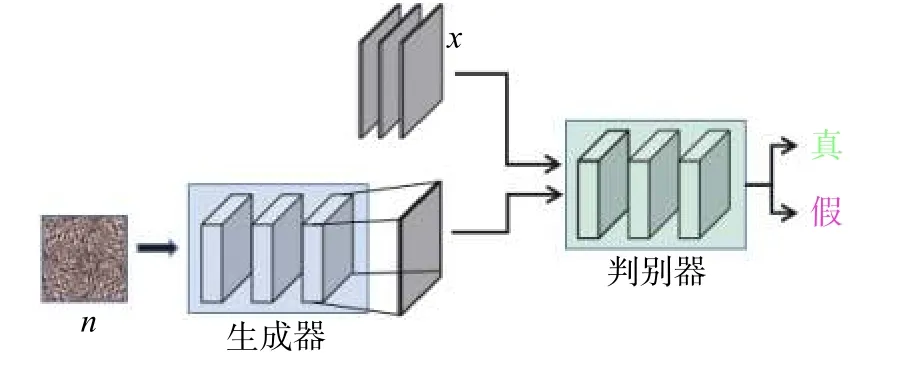
图2 生成对抗网络结构图
在模型的训练过程中,噪声数据经过生成器和判别器输出概率值D(G(n)),D(G(n))等于1 表示虚假样本G(n)与 真实样本x来自同一分布,等于0 表示完全独立。在生成器G(·)的优化过程中,需要在判别器D(·) 确 定的情况下,让D(G(n))尽可能接近1,从而使得噪声生成的虚假样本分布不断接近真实样本分布,其目标函数为:
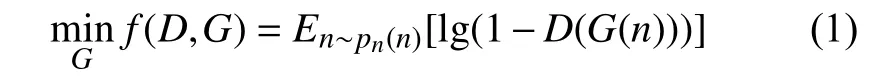
另一方面,在判别器D(·)的优化过程中,希望真实样本的输出概率值D(x)尽量接近1,而噪声数据生产的虚假样本概率值D(G(n))尽量接近0,从而使得判别器能够精确判断数据的真假,其目标函数如下:
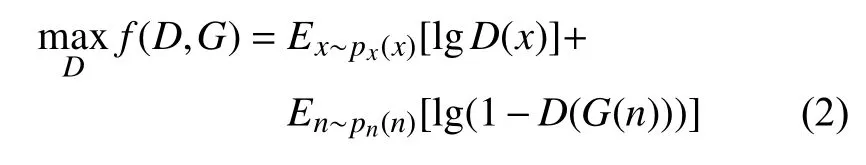
需要指出的是,式(1)和式(2)两个目标函数是相互矛盾的,对抗学习通过生成器和判别器两个目标之间的相互博弈使虚假数据分布尽可能接近真实的数据分布,这样噪声生产的虚假数据就可以被当作真实数据使用。综合式(1)和式(2),模型总体目标函数如下:
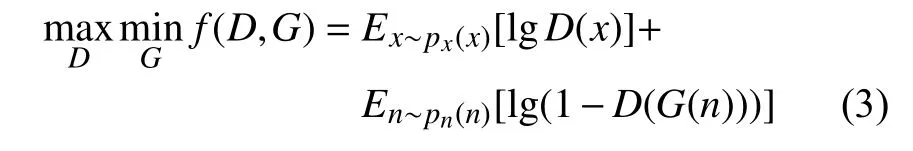
2 基于对抗迁移学习模型
近年来,人们通过将对抗学习的思路引入迁移学习,将目标域的数据通过对抗学习使其分布尽可能接近源域数据,从而不受目标域数据标签是否可用的限制,同时适合有监督学习和无监督学习应用。其中具有代表性的方法是DANN (domain adversarial training of neural networks)网络[9]。
和生成对抗网络不同的是,基于对抗的迁移学习将随机噪声替换成了目标域数据,免去了生成样本的过程,此时生成器也不再用于生成新样本,而是用于提取特征[10]。本文在文献[9]的基础上,提出了一种改进的对抗迁移学习方法,通过将特征提取器和域判别器替换为一维卷积结构,同时设置特征提取器为大小连续卷积核,使其适用于时间信号的处理。另一方面,考虑到不同维度的特征尺寸差别较大,模型的优化过程容易受到梯度消失现象的影响,本文在卷积操作中加入LeakyRelu (LRelu)激活函数和批量归一化操作,使划分的特征更容易识别,能够更好的解决训练过程中的梯度损耗问题。
2.1 网络结构
本文提出的改进对抗迁移学习模型由特征提取器,域判别器和分类器组成。其基本思路如图3 所示,对带标签的源域数据,经过特征提取器后传入分类器分类。再将带标签的源域数据和未带标签的目标域数据传入特征提取器,提取后的特征由域判别器判断数据所属域。训练过程中,特征提取器的作用是提取源域和目标域数据的共同特征,域判别器的作用是正确判断数据所属域,通过特征提取器和域判别器之间的对抗训练,使目标域数据分布不断接近源域数据分布,从而提高模型的分类精度。
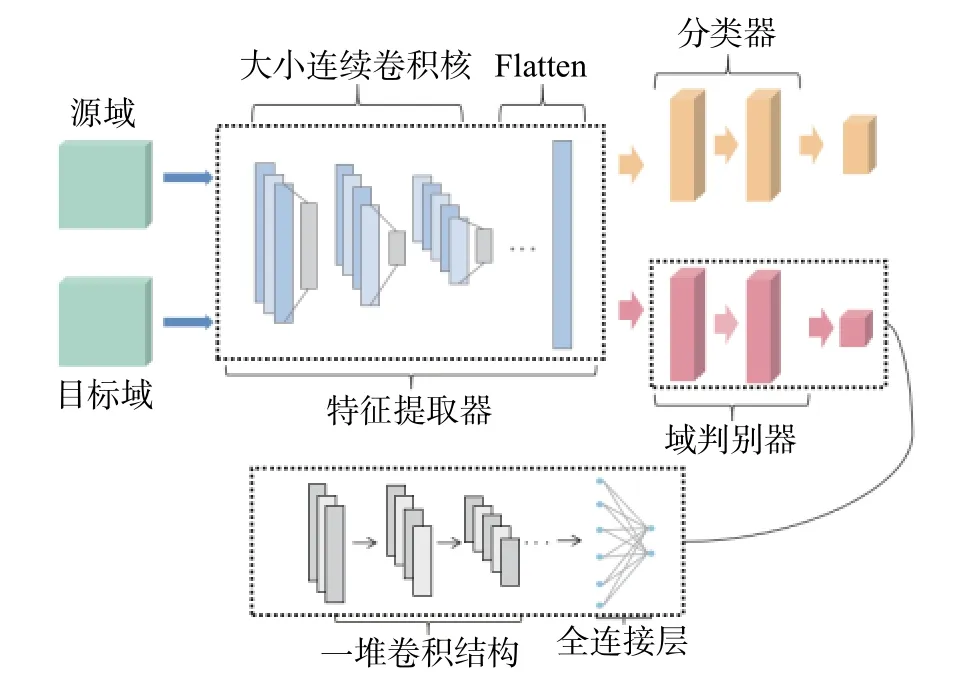
图3 基于对抗迁移学习模型网络结构
与传统对抗迁移方法方法不同的是,本文将特征提取器替换成一维卷积结构,该结构第一层卷积可直接从时间信号提取特征,无需对数据进行预处理,同时设置较大的卷积核用于抑制高频噪声,利用卷积层提取振动信号的浅层特征,再利用连续小卷积核扩展网络深度,提高网络性能。
另外,本文对传统方法中的域判别器结构进行改进,以消除梯度消失现象。传统的域判别器通常采用全连接神经网络,本文使用的域判别器由卷积层,LRelu 激活函数和批归一化组成,在卷积操作中通过权重共享保留重要参数,使其能够更好的判断数据所属域。通过将传统方法中的Relu 激活函数替换成LRelu,避免了输入信息为负时产生的梯度消失等现象,其公式如(4)所示,最后通过二分类激活函数判断数据属于源域还是目标域。

模型的分类器采用全连接神经网络结构,用于对源域数据进行分类。
2.2 优化目标
本文提出的基于对抗迁移学习模型包括对分类损失Lcls和域判别器损失Ladv两种损失函数,如下式所示:
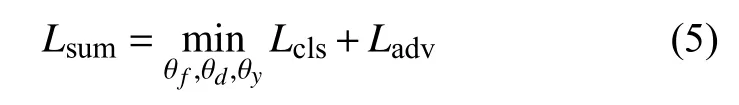
其中 θf,θy,θd为特征提取器,分类器和域判别器的参数。
式(5)中第一个优化目标为最小化源域数据的分类损失,采用交叉熵作为损失函数,定义如下:
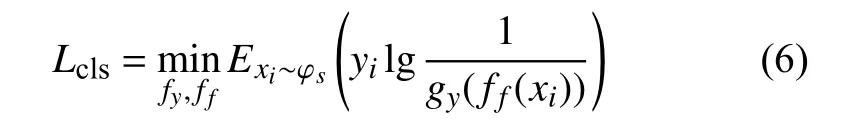
式中:xi∼φi——源域数据分布;
ff(xi)——源域数据经过特征提取器后得到的特征;
gy(ff(xi))——分类器得到的类别概率;
yi−样本xi的 类别指示变量,当类别的估计值和观测样本xi的 真实值相同时为1,不相同则为0。
第二个目标函数对应于域判别器,其作用是判断数据所属域,并通过对抗训练减少源域数据和目标域数据之间的分布差异,其损失如下式所示:
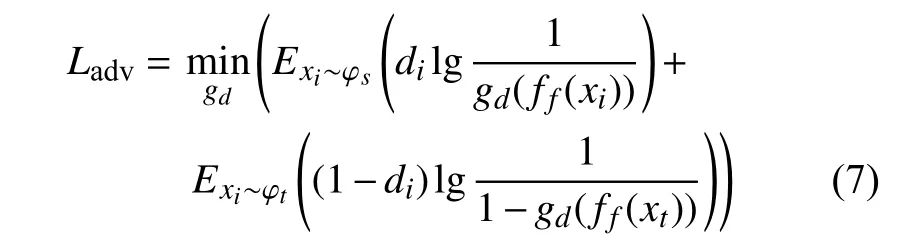
式中:xt∼φt——目标域数据分布;
gd(ff(xt))——域判别器的输出;
di— —第i个样本的二元标签值。
实验过程中,通过随机梯度下降法(SGD)沿着梯度向量的相反方向对特征提取器和域判别器的参数进行更新,以提高故障的分类精度。
3 应用结果
为验证本文提出的方法(AD+CNN),将其应用于江南大学滚动轴承数据库和凯斯西储大学数据库。采用两种方法进行对比,第一种方法将特征提取器和分类器相连,不添加域判别器,记为BASELINE[11];第二种方法在对抗学习的基础上添加了全连接网络的域判别器[12],记为AD+FC。
3.1 案例1(江南大学数据)
首先采用江南大学提供的滚动轴承故障数据对本文提出的方法进行验证[13]。除正常数据之外,还包括在内圈、外圈、滚动体故障下采集的振动数据,采样频率50 kHz。在转速600,800,1000 r/min时采集了4 组数据,其中每1024 个时间点为一个样本数据,具体数据集如表1 所示。

表1 江南大学迁移任务数据集
考虑‘A-B’,‘A-C’,‘B-C’,‘C-A’,‘C-B’,‘B-A’ 6种迁移任务案例。利用本文提出的方法对这六种迁移任务进行建模,训练过程中,单次训练样本数为64,迭代次数为300,随机梯度下降过程中,学习率为1×10–3,动量为0.9 用于加速收敛,权重衰减系数为1×10–5用于防止过拟合,为消除随机性,分别对每个迁移任务进行五次测量取平均值得到最后的目标域分类准确率,结果如表2 所示。从表2 可以看出,改进后方法的平均准确率达到96.7%,单次迁移任务的平均准确率可达到98.5%。

表2 目标域分类准确率
为进一步显示结果,图4 给出以“A-C”迁移任务为例给出了不同算法准确率变化随迭代次数变化情况。其中绿色实线为AD+CNN 方法,橙色实线为AD+FC 方法,蓝色实线为BASELINE 方法。从图中可以看出,随着迭代次数增加,不同方法的模型准确率和损失值逐渐稳定,其中本文提出的AD+CNN 方法的分类准确率明显超过另外两种。
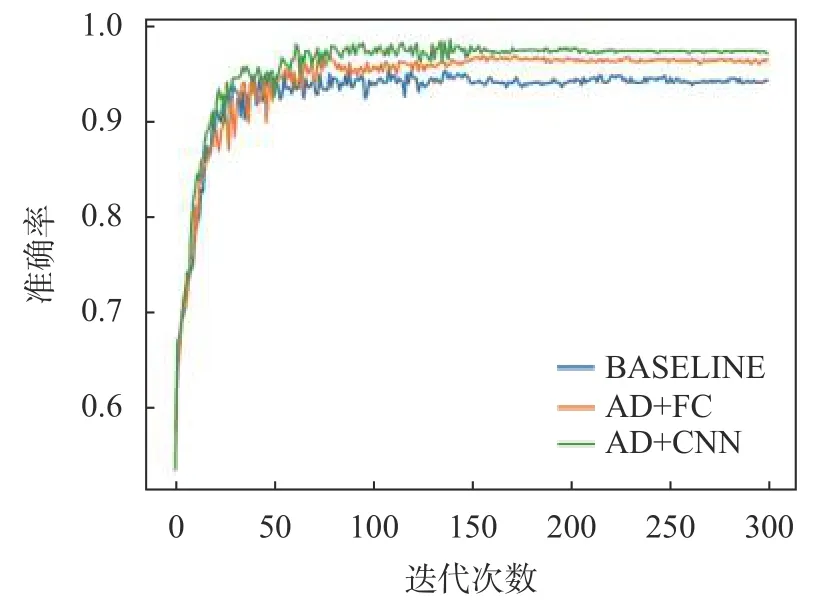
图4 不同方法分类准确率随迭代次数变化图
3.2 案例2(凯斯西储大学数据)
采用凯斯西储大学[14]添加噪声信号之后的滚动轴承数据进行验证。该试验装置由电动机、扭矩传感器、功率测试计和电子控制器组成。故障直径为0.007,0.014,0.021,0.028 in (1 in=0.0254 m),采样频率为12 kHz 和48 kHz,采样转速为1730,1750,1772 r/min,具体数据集如表3 所示。

表3 凯斯西储大学迁移任务数据集
为了验证算法的鲁棒性,选用了添加不同信噪比(SNR)的训练数据集,信噪比为信号功率和噪声功率的比,值越大抗干扰能力越强。采用本文方法进行迁移学习分类,模型参数不变,表4 给出了不同卷积核尺寸和信噪比情况下本文提出方法的准确性。可以看出,随着卷积核逐渐变大,平均准确率不断提高,当卷积核尺寸到达55 时,准确率可达到最大值99.6%,之后呈下降趋势,因此最后选用的卷积核尺寸为55。另一方面,比较不同信噪比下的分类准确率可以看出,本文提出的AD+CNN 方法在不同噪声环境下均保持较高的准确率。通过对比在不同卷积核以及不同噪声环境下的分类准确率可以看出,大尺寸卷积核减少了噪声的干扰,改善了模型的分类精度。
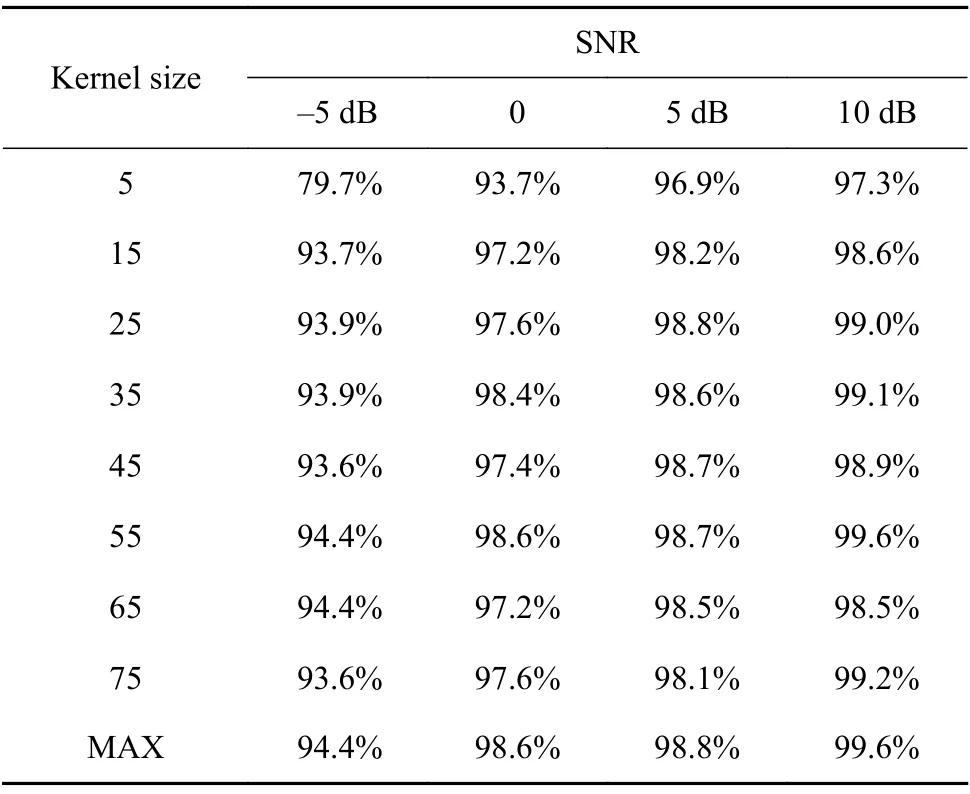
表4 不同卷积核和信噪比环境下分类准确率
作为对比,表5 给出了本文提出的方法与BASELINE 方法和AD+FC 方法在目标域的分类准确率对比。从表5 可以看出,本文的方法较其他方法相比均具有更高的准确率,平均准确率为99.1%,而BASELINE 和AD+FC 方法的平均准确率分别为97.7%和95.7%。上述实验可以看出,基于全连接神经网络的的域判别器受梯度消失现象的影响,分类准确率受到限制,将域判别器替换为卷积结构后[15],能够更精准的判断数据所属域,从而进一步提高分类精度。
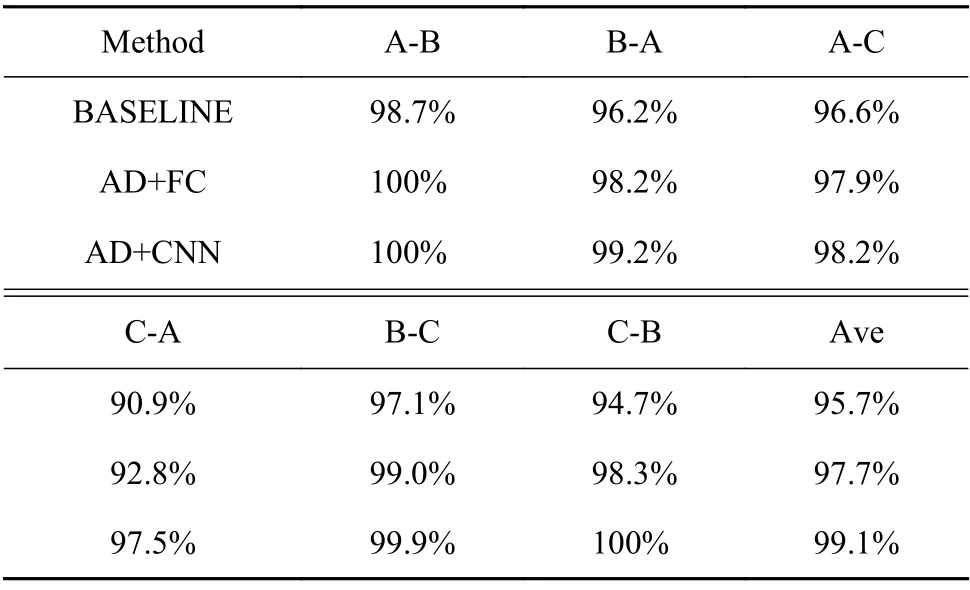
表5 目标域数据分类准确率
4 结束语
针对轴承故障诊断任务,本文提出了基于对抗的迁移学习模型,该模型将特征提取器和域判别器替换成一维卷积结构,使其直接作用于时间信号,提高了故障诊断效率,减少了噪声的干扰。同时添加了LRelu 激活函数和批量归一化操作,解决了梯度损耗的问题,并提高了分类精度。
将本文改进的方法应用于江南大学故障数据和含有不同信噪比的凯斯西储大学故障数据。结果表明,即使受到不同噪声干扰,本文所改进的模型依然可以保持较高的分类准确率,验证了该模型可以在故障诊断任务中保持良好的性能。
