基于深层次特征增强网络的SAR图像舰船检测
2021-10-15韩子硕王春平付强陆军工程大学石家庄校区电子与光学工程系河北石家庄050003
韩子硕,王春平,付强 (陆军工程大学 石家庄校区 电子与光学工程系,河北 石家庄 050003)
针对SAR图像舰船检测,传统算法在特征提取和图像分析等多个环节均需要人工参与,致使整个过程耗时耗力且检测效果并不理想. 究其原因,一是各类舰船尺度差异大,且存在大量小目标甚至点目标;二是大量的散斑噪声、舰船与海面相互耦合以及近岸区域的复杂环境,导致目标视觉显著性差;三是海尖峰、冰山、小岛、钻井平台、浮标等众多假目标给检测带来难度. 针对目标尺度差异大的问题,DAI等[2]和杨龙等[3]利用特征融合技术,构建位置信息和语义信息同等丰富的金字塔结构特征图,并在多尺度特征层上进行目标检测,增强了网络对多尺度舰船的适应性. 但对于小目标占比大甚至包含一定数量点目标的宽幅大场景SAR图像的目标检测效果并不是很理想. 针对目标视觉显著性差的问题,HU等[4]通过学习特征图各通道之间的依赖关系得到重要性参数,并以此为依据为每个通道赋予不同的权值,达到增强有用特征、抑制无用特征的目的. 基于CNN的注意力模型(CNN-Based AM)[5]通过学习特征图像素点重要性参数,实现像素级空间特征增强. WOO等[6]从通道和空间两个层面分别构建注意力模块,两者经并行连接后共同将网络注意力聚焦于目标区域. SE-Net和CBAM中的通道注意力结构虽对特征丰富的光学图像效果明显,但对特征并不丰富的SAR图像却并不友好. 而CNN-Based AM需要进行大量的实验进行微调,工作量大. 针对干扰假目标多的问题,KANG等[7]依照人类视觉习惯,利用目标及其周边特征构建上下文信息,为分类器和回归器提供额外判别依据,有效降低了目标虚警. LUO等[8]通过分析计算各类别之间的距离构建上下文类别关系矩阵,重新定义分类概率和回归置信度,显著提升了网络检测性能.
基于以上分析,针对SAR图像舰船检测所面临的困难,本文在YOLOv3[9]单阶段检测算法基础上,提出了一种深层次特征增强的多尺度目标检测框架(YOLO-DAC). 通过在四尺度特征图上进行目标预测,提升网络对小尺度目标的敏感度;以基于注意力机制的特征融合方式衔接相邻特征层,自下而上构建目标信息丰富、特征显著的增强型特征金字塔,提升网络对不同尺度舰船的适应能力;同时为了扩大检测网络视野和消除假目标误导,利用目标周边上下文信息为检测器提供有力判别依据,最终实现SAR图像多尺度舰船检测.
1 算法设计
YOLO-DAC共包含4层YOLOv3特征提取网络(YOLOv3-4Layer)、深层次特征增强网络(DFEN)和融合上下文信息的检测网络(Contextual-DNet)三个部分,整体网络结构如图1所示.
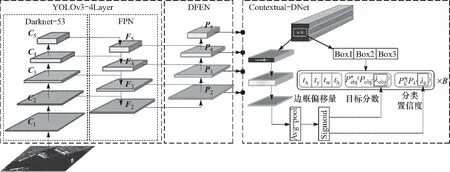
图1 基于YOLO-DAC的SAR图像舰船检测网络框架Fig.1 The architecture of ship detection network based on YOLO-DAC in SAR images
1.1 YOLOv3-4Layer
原始YOLOv3模型以Darknet-53为主干网络,并采用全局到局部的思想构建多尺度金字塔完成目标检测,在多尺度(尤其是小尺度)目标检测方面具有天然优势[10],且Darknet-53具备一定的泛化能力进一步提升了检测性能. 虽然YOLOv3的性能优越,但仍不足以处理目标尺度差异大、小目标占比多的SAR图像舰船检测. YOLOv3要求输入图像分辨率为416×416,并将F5、F4、F3作为预测目标的特征层,三者的下采样步长分别为32、16、8,那么该模型理论上能检测到的最小目标分辨率在8×8左右. 然而,以SAR图像舰船公开数据集SSDD[11]为例,当将输入图像的尺寸统一至416大小时,有136个舰船目标的长或者宽小于8,如图2所示. 以此推断,将有5.4%的目标存在漏检风险. 因此,需进一步增大预测目标特征层的分辨率. 基于以上分析,重新设计特征提取网络,将下采样步长为4且具有更高分辨率的F2层加入特征金字塔(FPN)中,进一步提高小尺度目标检测的细粒度,形成四尺度目标预测网络,如图1中的YOLOv3-4Layer模块所示.
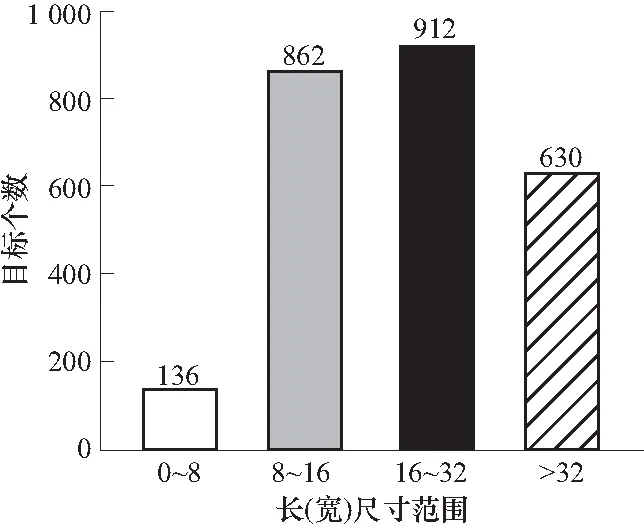
图2 SSDD数据集舰船目标长宽分布Fig.2 Distribution of ship targets in SSDD dataset
1.2 深层次特征增强网络
为了有效利用高层特征图的语义信息和浅层特征图的细粒度特征,本文从丰富特征图信息和提升显著性特征两方面入手,设计了DFEN结构,如图3所示. 在YOLOv3-4Layer输出的初始FPN基础上,DFEN通过自下而上重构特征金字塔的方式,达到缩小浅层特征图与高层特征图之间的卷积跨度,丰富高层特征图所含细粒度特征的目的. 如经过重构特征金字塔,Darknet-53的浅层特征图C2与最高预测层之间的卷积跨度由原来的47减小为6. 此外,为了提升预测层的显著性特征,DFEN以基于空间注意力机制的特征融合(AFF)方式衔接相邻特征层,在生成显著性特征的同时,完成特征金字塔的自下而上连接. 注意力模块中沿通道方向的池化操作(AvgPool和MaxPool)可以有效突出信息区域[12],再经一层卷积和Sigmoid函数整合后,输出空间注意力图. 针对四尺度的目标检测网络,仅需要三个AFF模块即可,每个模块有两路输入Pi∈C×2H×2W和Fi+1∈C×2H×2W,经过特征融合输出Pi+1∈C×2H×2W,C、H、W分别表示通道数、高和宽,特征融合过程可表示为:
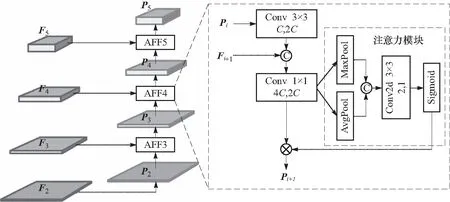
图3 深层次特征增强网络示意图Fig.3 Illustration of the DFEN
(1)
式中:Att(·)为注意力机制;σ(·)为Sigmoid函数;f3×3为3×3卷积;f1×1为1×1卷积;AvgPool、MaxPool、g2x-up分别为平均池化、最大池化和2倍下采样;⊕为concatenate特征叠加方式.
1.3 融合上下文信息的检测网络
DFEN构建的多尺度融合特征金字塔在一定程度上结合了一些上下文信息,但从特征提取的角度来看,并没有对上下文特征进行特殊处理或利用. 基于以上分析,将目标周边特征作为上下文信息引入检测网络,为分类和定位提供有力判定依据. YOLO-DAC从4个尺度的增强型特征图(即图3中的P5:P2)上生成锚框,每个尺度的特征图独立进行目标分类和边框回归,进而预测出坐标、目标分数和类别置信度. 图4展示了在分辨率为13×13的特征图P5上实现舰船检测的基本原理,其它尺度特征图上的检测原理与此相同.
为了有效提高结构的刚度,将传感器支路的连接方式由铰约束改为了固支约束,在主体结构不变的前提下最大限度的提高了刚度[2]。然而这样就导致了传感器无法保证输入输出之间的线性关系。
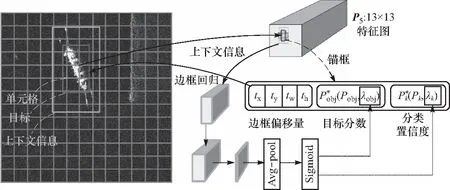
图4 Contextual-DNet原理Fig.4 The principle of Contextual-DNet
将输入图像分成13×13个单元格,每个图像块对应特征图P5上一个像素点,以P5上每个像素点为中心产生不同尺度的锚框(anchor). 根据锚框内的图像特征计算出目标预测边框(bounding box)的偏移量(tx,ty,tw,th)、目标分数Pobj和类别置信度Pk. 每个锚框预测回归一个目标边框,边框回归过程如图5所示,pw和ph为锚框的宽和高,(cx,cy)为单元格左上角坐标. 边框回归其实就是对锚框的平移和缩放,平移参数为(σ(tx),σ(ty)),σ(·)为Sigmoid函数,其作用是将预测边框的中心点和锚框的中心点限制在同一单元格内,缩放参数为(etw,eth),边框坐标(bx,by,bw,bh)通过式(2)进行计算:
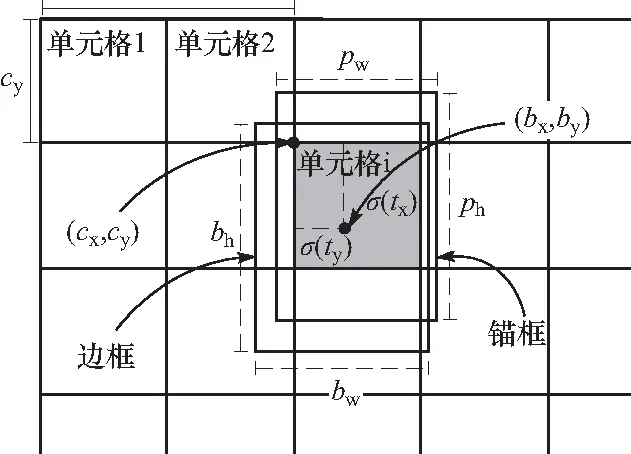
图5 边框回归示意图Fig.5 Diagram of bounding box regression
(2)
目标分数Pobj表示边框内包含目标的概率,类别置信度Pk表示边框内的目标属于第k类的概率. 由于本文主要针对的是舰船目标检测,因此只设置了一个目标分类标签,即“ship”. 分类器只需要计算出目标属于背景的概率P0和属于舰船的概率P1即可.
Pobj和Pk是网络根据锚框内的特征确定的,而锚框不一定囊括整个目标区域,且没有参考信息来辅助检测器进行判定. 为了提升判定的准确性,将预测边框周边特征作为上下文信息,为检测网络提供补充信息. 根据边框坐标(bx,by,bw,bh),在相应预测特征图上提取目标周边上下文特征(context),上下文区域坐标取(bx,by,βbw,βbh),β为扩大倍数,如图4所示. 上下文特征首先经过两个3×3卷积层进行特征整合,然后通过平均池化层进行降维,最后经Sigmoid函数输出目标分数调整参数λobj和类别置信度调整参数λk.Pobj和Pk通过式(3)进行调整:
(3)
式中:σ(·)为Sigmoid函数;Pr(object)和Pr(classk)为由卷积层直接输出且未经Sigmoid函数规范化的目标分数和类别置信度值.
2 数据集及实验设置
2.1 数据集
为了验证本文算法的有效性,实验中共使用了两个数据集:SSDD数据集及自建SAR舰船数据集(SAR-Ship).
SSDD数据集是由LI等[11]构建的SAR图像公开舰船检测数据集,共包含1 160张SAR图像,含有2 456个舰船目标,场景类型包含港口、岛礁、海上区域等. 该数据集中的SAR图像收集于RadarSat-2、TerraSAR-X和Sentinel-1三个星载SAR. 图像的分辨率和尺寸均不固定,样例见图6. 数据集分布信息见表1.
图6 SSDD数据集样例Fig.6 Samples of SSDD data set

表1 SSDD数据集分布信息Tab.1 Distribution of SSDD data set
SAR-Ship自建数据集选取7景欧洲航天局(ESA)提供的Sentinel-1星载SAR图像作为原始实验数据. 本文以10%的重叠率将原始SAR图像切割成一系列500×500的子图像,并按照SSDD样本标签格式进行标注,而后进行训练和测试. Sentinel-1全景图分割示例如图7所示. 取5景图像作为训练数据,将包含舰船目标的1 936幅子图像作为训练数据集,其余2景图像切割而成的3 536幅子图像作为测试数据集. 训练数据集和测试数据集分布信息如表2所示.

图7 SAR-Ship数据集分割示例Fig.7 Segmentation example of SAR-Ship data set

表2 SARShip数据集分布信息Tab.2 Distribution of SAR-Ship data set
2.2 实验设置
网络训练过程共分为两个阶段:第一个阶段只开放主干网络的卷积核参数,冻结其余卷积层,训练50个epoch;第二阶段开放所有卷积层参数,训练80个epoch.
检测网络在4个不同尺度的特征图上进行预测,以特征图上的每个像素点为中心生成3个不同大小的锚框,共需设置3×4=12个锚框. 为了利用舰船目标多为狭长形这一先验知识,通过k-means聚类算法在训练集上预估锚框的宽和高.k-means设置12个聚类中心,每个聚类中心对应一种锚框类型,预估锚框设置见表3.
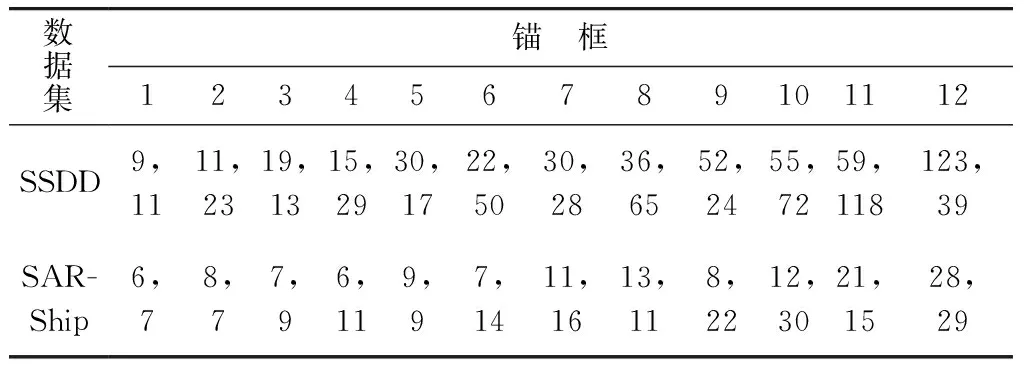
表3 SSDD数据集和SAR-Ship数据集中锚框的宽高设置
3 实验结果及分析
3.1 β取值对检测结果的影响
检测网络中上下文区域的大小取决于β值. 合适的β取值可以使上下文信息辅助检测网络做出更加准确的判定,取值过小作用不明显,取值过大则给检测网络带来干扰信息,从而导致错误判定. 为了确定β的最优值,以所提方法为检测模型,分别取β=1~6,在SSDD数据集和SAR-Ship数据集上分别进行6组实验,结果如表4所示,其中Ntp为正确预测的目标数量,Nfp为错误预测的目标数量,Nfn为漏检数量,P为精确率,R为召回率,AP为平均准确率.
由表4可知,当β取1~5时,随着β值的增大,检测器在两个数据集上的性能表现均呈现向好趋势. 当β=5时,网络性能达到最优,SSDD数据集上的AP值达到0.944 3,SAR-Ship数据集上的AP值达到0.919 2,相较于β=1时,Nfp和Nfn均有所下降,AP分别增长了0.012 6、0.032 0,说明上下文信息可以为检测器提供更加有力的判别依据,增加目标判定的置信度. 当β取6时,目标特征被过多的上下文信息掩盖,网络性能骤降. 基于以上分析,本文将β值设置为5.
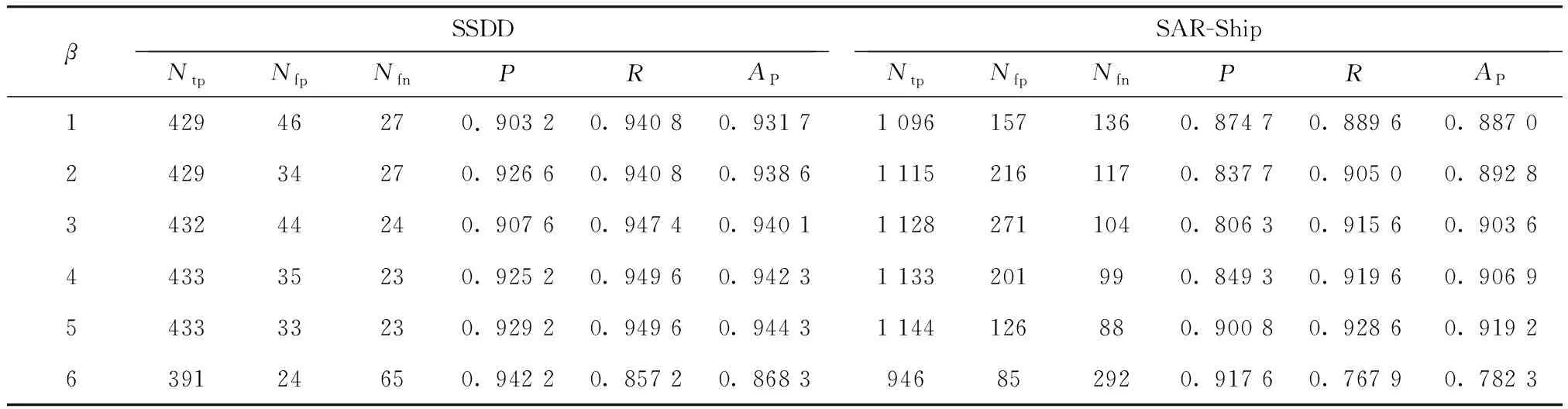
表4 不同β取值时的实验结果比对Tab.4 Comparison of experimental results with different β
3.2 网络各增强模块对检测结果的影响
为了评估YOLOv3-4Lyer、DFEN、Contextual-DNet对提升网络检测能力的贡献度,分别在SSDD数据集和SAR-Ship数据集上做5组实验:第1组实验为原始YOLOv3模型,第2组实验为4尺度的YOLOv3(YOLOv3+4Layer),第3组实验为嵌入深层次特征增强网络的YOLOv3(YOLOv3+DFEN),第4组实验为融合上下文信息的YOLOv3(YOLOv3+CD),第5组实验为所提模型(YOLO-DAC). 各组实验结果的定量比较如表5所示.

表5 不同算法实验结果的定量比较Tab.5 Comparison of experimental results based on different methods
YOLOv3-4Lyer在YOLOv3基础上加入了具有更高分辨率的预测特征层,舰船目标的漏检数量得以减少,但虚警数量有所上升,在SSDD数据集和SAR-Ship数据集上的AP值分别达到0. 862 4和0.850 0,比YOLOv3高0.026 8和0.076 5.YOLOv3+DFEN从丰富特征图信息和提升显著性特征两方面对YOLOv3进行了增强,两个数据集上的AP值分别达到了0.903 7和0.871 2,比YOLOv3提升了0.067 2、0.097 7. YOLOv3+CD在YOLOv3基础上融入了上下文信息,两个数据集上的AP值分别提升了0.058 7和0.056 6,且Nfp和Nfn各有不同程度的下降. YOLO-DAC是嵌入三个增强模块的综合检测模型,在两个数据集上取得最优AP值,分别达到了0.944 3和0.919 2,比YOLOv3高0.108 7和0.145 7.
从各检测模型所取得的性能增益可以看出,由于SAR-Ship数据集中的小尺度目标占比比SSDD数据集更大,因此YOLOv3-4Lyer的作用对其更加突显;Contextual-DNet在两个数据集上所带来的性能增益基本持平,虚警和漏检有明显下降,说明上下文信息可以为检测器提供强有力的判定依据;相较于其它两个模块,DFEN对网络性能的提升效果更加明显,说明丰富预测特征图所含信息和增强显著性特征是提升检测性能的关键.
3.3 与其它算法比较
本节通过与SSD、YOLOv3、DFPN[13]、Faster R-CNN+[14]、YOLOv4[15]、SCRNet[16]进行比较来验证所提YOLO-DAC模型的优越性,各网络模型在SSDD数据集和SAR-Ship数据集上的检测结果定量评估如表6所示,其中t表示测试一幅图像的平均推断时间.
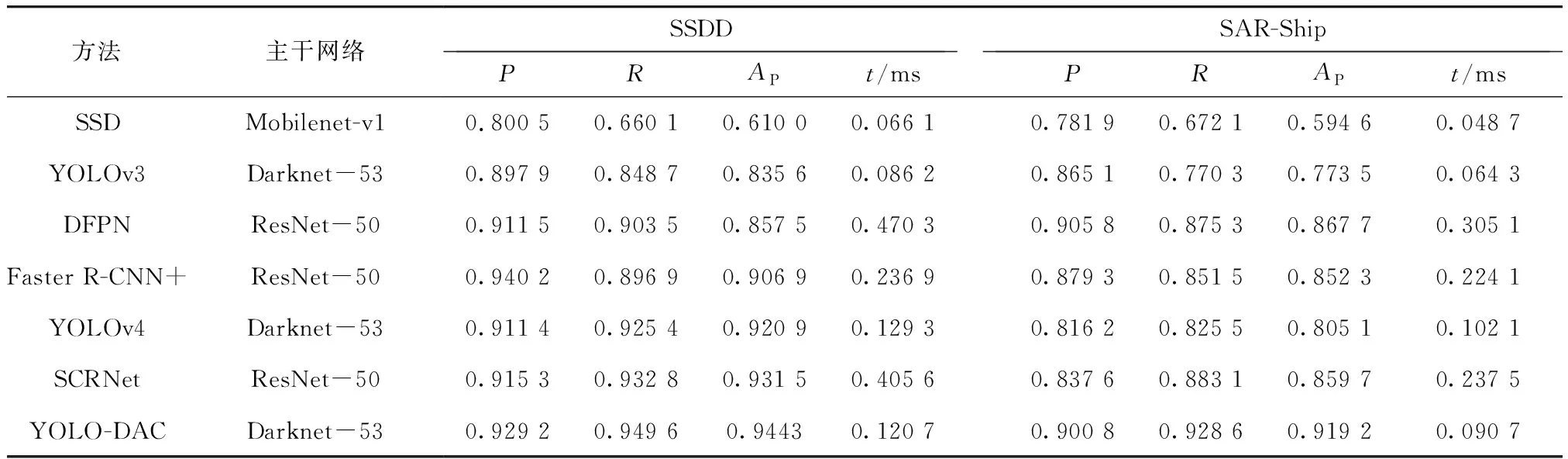
表6 不同网络模型的舰船检测结果定量比较Tab.6 Quantitative comparison of ship detection results based on different network models
由不同方法的性能评价结果和PR曲线图(如图8所示)可以看出,本文算法的检测性能最为优异且PR曲线平稳,平均推断时间也远小于性能相近的其它模型.

图8 不同网络模型的PR曲线Fig.8 The PR curves of different method
图9给出了YOLO-DAC在两个数据集上的可视化检测结果,由图亦知,所提模型能够有效完成SAR图像舰船检测任务. SSD采取的主干网络的泛化性能较差,提取的舰船目标特征不够完善,导致检测性能较差;YOLOv3虽然应用了特征金字塔结构,但基于三尺度特征图的目标预测仍不足以满足小尺度目标检测的需求;YOLOv4综合多种目标检测算法之长,对YOLOv3进行了改进,在SSDD数据集上的AP值达到了0.920 9,但在小尺度目标占比更大的SAR-Ship数据集上的表现却差强人意,PR曲线下降态势过早;Faster R-CNN+利用特征融合技术丰富特征信息,但单预测层设置和复杂的SAR图像环境致使性能表现比较中庸;SCRDet通过将高层特征融合至低层特征来提高预测层的分辨率和特征表达,并嵌入多维注意力网络提升显著性特征,在两个数据集上的AP值分别达到0.931 5和0.859 7;DFPN采取跨尺度连接的方式融合各层特征,构建特征表达更加全面丰富的密集特征金字塔,并在四尺度特征图上进行目标预测,在SAR-Ship数据集上的表现优于前5种算法,但SSDD数据集中各类图像的特征丰富性远不足于支撑训练如此密集的网络结构,导致该方法的检测性能受到影响,PR曲线跌宕起伏.

图9 舰船检测可视化结果Fig.9 Visualization results of ship detection
3.4 拓展实验
为了进一步验证模型对于SAR图像舰船检测的鲁棒性和泛化能力,利用SSDD数据集的训练模型分别对AIR-SARShip[17]和HRDIS[18]数据集中的舰船目标进行检测.AIR-SARShip数据集中的图像尺寸均为3 000×3 000,分辨率包括1 m和3 m;HRDIS数据集中的图像尺寸均为800×800,分辨率包括0.5、1.0和3.0. 图10给出了SSDD训练模型在两个数据集上的检测结果. 由图可知,尽管各个数据集中的样本分布和舰船目标呈现出的灰度纹理特性均有不同,但所提算法仍能有效检测出图像中存在的舰船目标,说明所提模型具有良好的鲁棒性和泛化能力. 究其原因,一方面是因为四尺度特征图的预测模式能够适应多尺度目标;另一方面得益于Darknet53和DFEN结构强大的特征表达能力,探测器能够借助更加有利的目标特征做出准确判定.

图10 AIR-SARShip和HRSID数据集上的检测结果Fig.10 Detection results of AIR-SARShip and HRSID datasets
4 结 论
针对SAR图像舰船检测中目标尺度差异大、小型目标占比多、视觉显著性特征不明显和干扰假目标多等问题,本文提出了一种基于深层次特征增强的单阶段目标检测网络. 该方法通过增加更底层的高分辨率特征图来增强网络对小尺度目标的敏感度,设计特征增强网络重构目标信息丰富、显著性特征强劲的增强型特征金字塔,提升网络对不同尺度舰船的适应能力,同时利用目标周边上下文信息为检测器提供有力的判别依据,有效消除假目标误导. 相较于SSD、YOLOv3、DFPN、Faster R-CNN+、YOLOv4和SCRNet算法,所提模型更能合理有效地利用特征信息,并可以将网络注意力集中至目标区域. 经过在数个SAR图像舰船数据集上进行多组实验验证,所提方法能够高效完成SAR图像舰船检测任务,且具有良好的鲁棒性和泛化能力.
