基于遥感影像的山岳冰川信息计算机解译方法探讨
——以梅里雪山为例
2021-10-14钟鼎杰杨存建
钟鼎杰,杨存建**
(1. 四川师范大学 西南土地资源评价与监测教育部重点实验室,四川 成都 610068;2. 四川师范大学 地理与资源科学学院,四川 成都 610068)
冰川不仅存贮了大量的水资源,同时也是全球气候变化的指示器[1]. 在全球气候变暖的背景下对于冰川变化的研究迫在眉睫,在信息化时代如何运用高效、便捷、精准的方法对冰川变化做出监测与预测是目前的研究热点. 相比大陆型冰川,海洋型冰川作用能大、运动速度快,对于气候变化的响应也更为迅速;海洋型冰川在大量降水与剧烈消融的作用下会产生破坏性的泥石流与雪崩,所以对于海洋型冰川变化的研究具有重要的意义[2]. 在冰川信息提取的方法上,近年来遥感技术、地理信息系统技术的不断发展和集成应用,可利用遥感影像和DEM 等数据快速高效地提取冰川信息并监测冰川面积、高程和冰川末端变化. 1999 年国际全球陆地冰 空 间 监 测 计 划(Global Land Ice Measurements from Space Project,GLIMS)运 用 了 卫 星 传 感 器ASTER 数据和Landsat 数据对世界范围内的冰川进行动态监测[3]. Sidjak 等[4]利用了监督分类法、TM 影像的4、5 波段比值以及归一化积雪指数(Normalized Difference Snow Index,NDSI)等方法对加拿大冰川国家公园进行了冰川信息提取.Kumar 等[5]采用干涉合成孔径雷达(Interfermetric Synthetic Aperture Radar,InSAR)技术对喜马拉雅地区冰川表面速度进行了估算. Robson 等[6]利用基于面向对象的图像分析(Object-based Image Analysis,OBIA)技术,结合Landsat 8 影像、DEM数据和ALOS-PALSAR 影像对喜马拉雅山脉马纳斯鲁峰进行了冰川信息的自动提取. 张世强等[7]利用TM 图像并采用阈值法、谱间关系法、监督分类和非监督分类提取青藏高原喀喇昆仑山地区冰川信息,证明利用比值图像取阈值是提取冰川信息最有效的手段. 怀保娟等[8]利用Landsat TM/ETM+遥感影像和DEM 数据,并运用了面向对象的图像信息自动提取方法,对黑河流域近50 年来的冰川变化进行了分析. 聂勇等[9]利用多光谱遥感数据,采用面向对象的解译方法,结合专家知识分类规则自动提取1976、1988 年和2006 年3 个时期珠穆朗玛峰地区的冰川信息. 李宗省等[10]对1900—2007 年横断山区部分海洋型冰川变化进行了研究,并提出各冰川的变化幅度因冰川规模、纬度位置等因素而存在明显差异. 李霞等[11]对贡嘎山地区近40 年来的冰川变化进行了遥感监测研究,并从不同的角度研究分析了冰川变化的特征.
虽然冰川信息提取方法有多种,但因冰川类型的不同和地域性差异,并没有通适性较高的方法,冰川监测仍以目视解译为主. 因此,研究分类精度较高、通适性强且高效的冰川信息的计算机解译方法意义重大. 本文在已有的计算机自动解译冰川信息方法研究上,纳入了神经网络分类方法,通过对比分析监督分类、分监督分类、比值阈值法、雪盖指数法(NDSI)、基于多尺度分割的面向对象法(OBIA)和基于神经网络的冰川识别方法的信息提取结果,探讨每种方法的优缺点及适用情况,并将梅里雪山地区冰川信息的目视解译作为地面真实数据,对6 种方法的提取结果进行精度验证,发现了神经网络分类法提取的冰川信息精度最高. 在此研究基础上,基于ENVI 深度学习模块,利用神经网分类法解译了1989、1998、2009 年和2019 年的梅里雪山地区冰川信息. 最终,结合Google Earth数据及DEM 数据对梅里雪山地区冰川信息进行目视修正,并通过DEM 数据分析获取梅里雪山地区山脊线,将提取的结果分割为55 条独立的冰川,得到了1989—2019 年梅里雪山地区较为精确的4期冰川信息的提取成果,并在此基础上分析统计其冰川面积的变化量与变化速率. 结果表明,基于神经网络的冰川识别方法分类精度、解译效果明显优于传统冰川信息计算机解译方法,且相较于目视解译该方法效率更高. 在全球气候变暖背景下,本文基于神经网络的冰川识别方法可为全球冰川时空演化的长时序监测提供有效的技术支撑.
1 研究区概况
横断山地处青藏高原东缘,是中国地势一、二阶梯的过渡地带,区域大致包括了藏东南、云南西北部和四川的阿坝、凉山及甘孜地区,总面积约为5×105km2. 横断山区南北走向的高山和深谷相间排列,是本区域最为显著的地貌特征. 梅里雪山位于横断山东南缘,也是横断山地区集中低纬度海洋性/暖性冰川最多的山段[12](图1). 梅里雪山高度大于6 000 m 的山峰有13 座,最高峰卡瓦格博海拔6 740 m,是云南省第一高峰,山脚澜沧江海拔2 020 m,相对高差4 720 m.
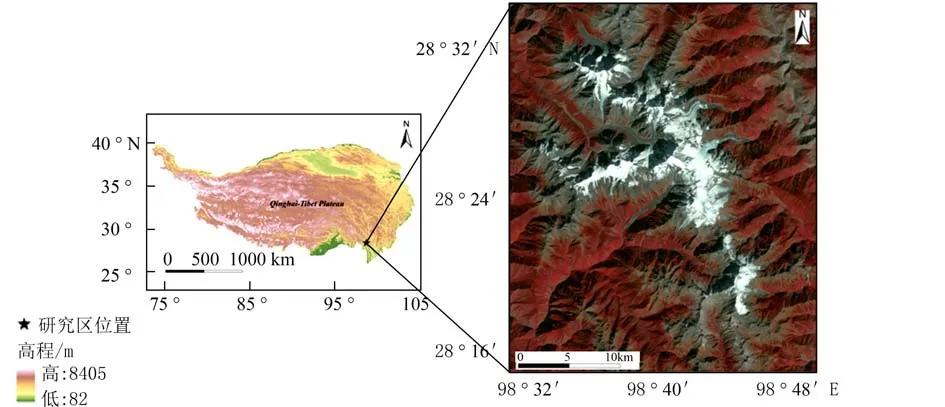
图1 研究区位置与冰川积雪分布图Fig. 1 Location of study area and distribution map of glacier and snow cover
据中国第二次冰川编目数据集(V1.0)[13-16],梅里雪山地区共有冰川55 条. 梅里雪山地区的冰川受来自印度洋西南季风带来的暖湿气流影响,随着暖湿气流的不断深入,给梅里雪山提供了充沛的降水,为冰川提供了丰富的物质来源.
2 数据获取与处理
2.1 数据来源本文选用的遥感数据均为通过美国地质勘探局(https://earthexplorer.usgs.gov)获取的Landsat Level 2 产 品. 数 据 为Landsat 5 搭 载 的TM 传感器、Landsat 8 搭载的陆地成像仪(Operational Land Imager,OLI)传感器所获取的影像(表1).在实际的数据选择过程中,需要特别注意研究区的积雪覆盖是否会影响冰川解译精度以及云层是否覆盖了研究区.
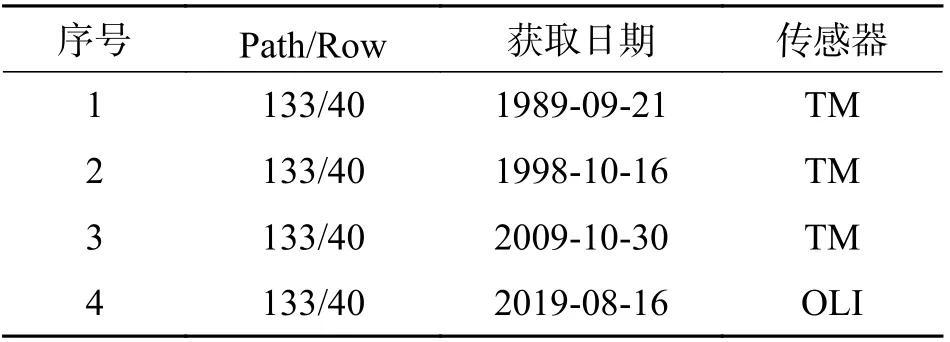
表1 梅里雪山遥感影像数据信息Tab. 1 Remote sensing image data information in Meili Snow Mountain
DEM 数据来源于美国地质勘探局的ASTER GDEM V2 版数据,其空间分辨率为30 m. 高分辨率可见光影像主要来自于Google Earth,用于辅助目视解译. 地图的底图来源于国家科技资源共享服务平台的国家青藏高原科学数据中心(http://data.tpdc.ac.cn/zh-hans/).
2.2 传统分类方法提取冰川信息
2.2.1 非监督分类 是指在没有先验类别样本的情况下,根据像元间地物光谱相似度统计分布规律将其自动分类. 常用的非监督分类方法有ISODATA 和K-Means 两种,K-means 算法 初始随机选取数据集中K个点作为聚类中心,以所有样本到聚类中心距离平方和最小的为分类结果. 在Kmeans 中,K值需要预先人为确定,并且在整个算法过程中无法更改;ISODATA 算法针对这个问题进行了改进,并增加了“合并”和“分裂”操作. 本文选用ISODATA 算法,对梅里雪山地区冰川信息进行提取. ISODATA 算法思想为输入N个样本,预选Nc个初始聚类中心和各参数指标K、θN、θS、θc、L和I(表2). 若 θc小于阀值则归为一类,否则为不同类;若 θN小于阀值,则将其取消[17].

表2 初始聚类中心和参数指标Tab. 2 Initial cluster center and parameter index
2.2.2 监督分类 是在已知类别的训练场地上提取不同种类的训练样本,通过选择特征变量、确定判别函数或判别规则,从而把图像中的各个像元点划归到各个给定类的分类方法[18]. 本文选用最大似然法对梅里雪山地区进行监督分类,在训练样本时将训练区内的地物分为裸地、植被和冰川. 最大似然法算法思想是通过遥感影像的统计特征,假设各类的分布函数为正态分布,在多变量空间中形成椭圆(球)分布,按正态分布规律用最大似然判别规则进行判决,得到较准确的分类结果.
2.2.3 比值阈值法 是将两个具有一定差异的光谱波段反射率相除,比值增强波谱特征的微小差异,该算法对不同波段反射率差异大的地物效果明显. 对于冰川提取,通常使用的是对于冰川反射率较高的可见光波段以及对于冰川反射率较低的波段,一般是近红外波段[19]. 其公式表示为

2.2.4 雪盖指数法 受到植被指数法的启发,Dozier[20]提出了雪盖指数法(NDSI)作为冰川信息提取的方式,主要原理基于冰川表面在可见光波段具有强反射的特性,以及在近红外波段具有的强吸收特性. 将两个波段反射率进行归一化处理,以突出冰、雪的信息特性. 其公式表示为

常用的Landsat TM 影像波段有TM2 和TM5,Landsat OLI 影像波段选用Band 3 和Band 6. NDSI的阈值一般根据具体的情况结合经验值确定,本文根据前人经验及多次试验结果,选取的二值化分类阈值为0.6[21].
2.3 基于多尺度分割的面向对象法(OBIA)提取冰川信息基于多尺度分割的面向对象法(OBIA)提取冰川信息是选用多尺度分割算法并结合遥感影像的光谱特征进行. 当全部待分割对象的综合加权值大于某一特定阈值时分割完成;若小于阈值,则重复进行迭代运算,直至条件成立. 本文使用Edge 分割算法和Fast Lambda 合并算法对遥感影像进行处理. 图像分割完成后,对各波段的光谱、纹理特征等参照直方图探寻相关信息的阈值,综合梅里雪山冰川与其它地物差异性较明显的冰川信息指数分别进行阈值设置并建立提取知识规则[22],即①比值阈值TM3/TM5,以阈值2.4 提取冰川信息;②冰雪指数NDSI,设置阈值为0.6.
2.4 基于神经网络的冰川识别方法近些年来,深度学习发展迅速,在图像分类方面的应用表现优异[23-27]. 它通过学习大量样本,提取样本中的特征值,形成分类模型,进而对遥感影像进行分类. 在冰川信息提取方面,可以提高冰川识别的精度,并对有冰碛覆盖物的冰舌部分提取效果较好. 本文通过ENVI 深度学习模块对梅里雪山地区冰川信息进行提取研究,该模块基于TensorFlow 框架,利用ENVI Net5 网络构建深度学习模型. ENVI Net5 是一种U-Net 架构,它是基于掩码(mask-based)、编码器-解码器(encoder-decoder)的体系结构,用于对图像中每个像素进行分类. 具体的分类步骤如图2所示.
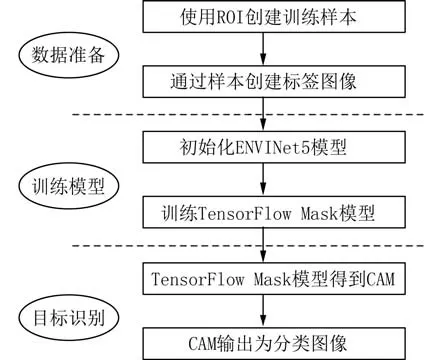
图2 基于ENVI 深度学习模块的图像信息提取步骤Fig. 2 Image information extraction steps based on ENVI deep learning module
影像分类完成后会得到一个CAM 类激活灰度图,灰度图中每个像元大致表示属于目标类别的概率,值阈范围为0~1. 通过密度分割,将类激活灰度图(图3)按不同颜色显示,红色部分表示深度学习识别为冰川的概率较高.
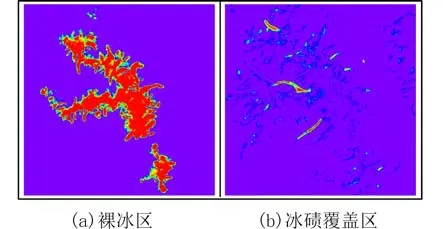
图3 密度分割后梅里雪山地区冰川神经网络分类结果Fig. 3 Neural network classification results of glaciers in Meili Snow Mountain after density segmentation
3 比较与讨论
3.1 分类结果对比为验证本文所用方法的有效性,基于目视解释法梅里雪山地区冰川信息,以目视解译结果作为地面真实数据,对计算机解译结果进行精度验证(表3). 精度评价指标为冰川总面积、面积误差、重叠部分面积、冰川精度[28-29].
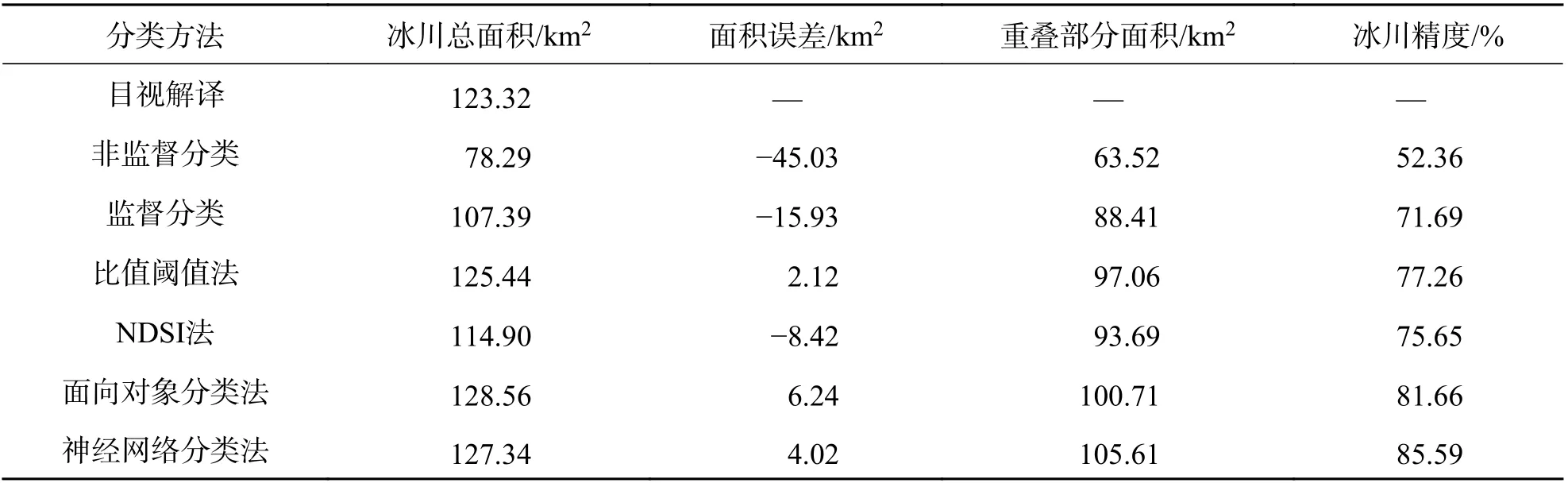
表3 梅里雪山地区冰川分类精度Tab. 3 Accuracy of glacier classification in Meili Snow Mountain
图4 至图9 分别为不同分类方法提取的冰川信息结果. 其中,黄色为基于目视判读方法手动提取梅里雪山地区冰川信息,红色为对应的每种分类方法所提取的冰川信息. 如图4 所示,非监督分类提取冰川信息结果中,裸地被错分为冰川的情况较多(如图4(d)、4(f)),有冰碛覆盖物的冰川被漏分(如图4(a)、4(c)),山体阴影区中的冰川未被识别出(如图4(b)、4(e)). 如图5 所示,监督分类提取冰川信息结果中,水体被错分为冰川(如图5(d)),山体阴影区中的冰川未被全部识别出(如图5(b)、5(e)),有冰碛物覆盖物的冰川被漏分(如图5(a)、5(c)). 由图6 可见,比值阈值法消除了山体阴影的影响,但提取结果中“椒盐”现象也较严重(如图6(b)、6(e)),同时也造成了大量阴影被错分为冰川(如图6(a)、6(c)),水体被错分(如图6(d))、冰碛覆盖区的冰川被漏分(如图6(a)、6(c))的情况仍未得到有效解决. 如图7 所示,利用NDSI 法提取的冰川信息结果与比值阈值法差异不大,阴影和水体被错分为冰川(如图7(a)、7(c)、7(d)),冰碛覆盖区的冰川被漏分(如图7(a)、7(c)). 由图8 可见,在尺度选取合适时,面向对象分类方法(OBIA)提取冰川信息的效果较好,可以区分水体与冰川(如图8(d)). 面向对象分类方法在建立信息规则时,有效地结合了比值阈值法及NDSI,部分有冰碛覆盖物的冰川被识别,但未完全正确划分(如图8(d)).如图9 所示,神经网络分类的整体提取冰川信息的效果好,有效地消除了山体阴影的影响,可以区分阴影、水体与冰川,且有冰碛覆盖物的冰川被正确划分,但整体分类精度仍待提高.
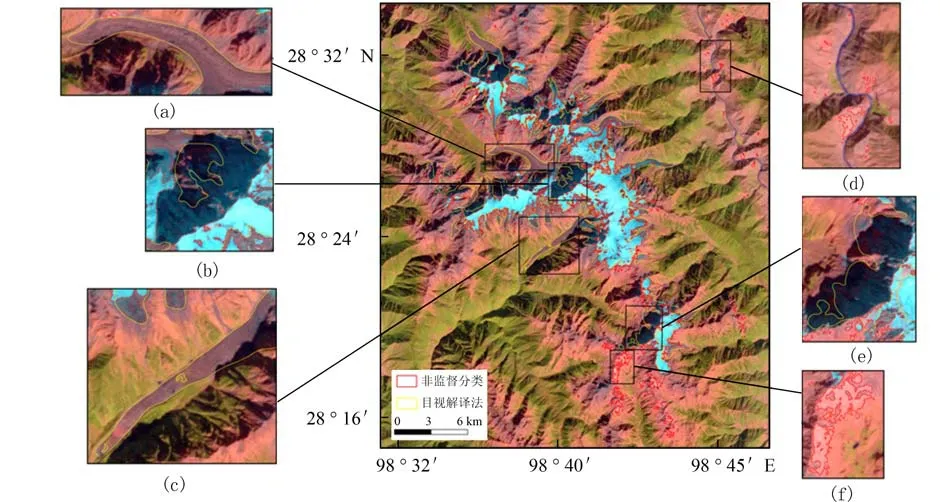
图4 非监督分类提取梅里雪山地区冰川信息结果Fig. 4 Glacier information extraction of Meili Snow Mountain based on unsupervised classification

图5 监督分类提取梅里雪山地区冰川信息结果Fig. 5 Glacier information extraction of Meili Snow Mountain based on supervised classification
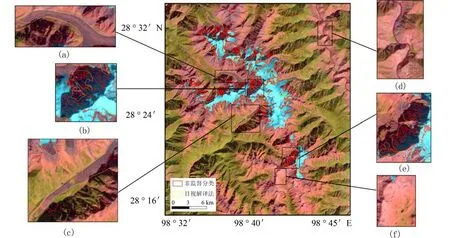
图6 比值阈值法提取梅里雪山地区冰川信息结果Fig. 6 Glacier information extraction of Meili Snow Mountain based on ratio threshold method

图7 NDSI 法提取梅里雪山地区冰川信息结果Fig. 7 Glacier information extraction of Meili Snow Mountain based on NDSI
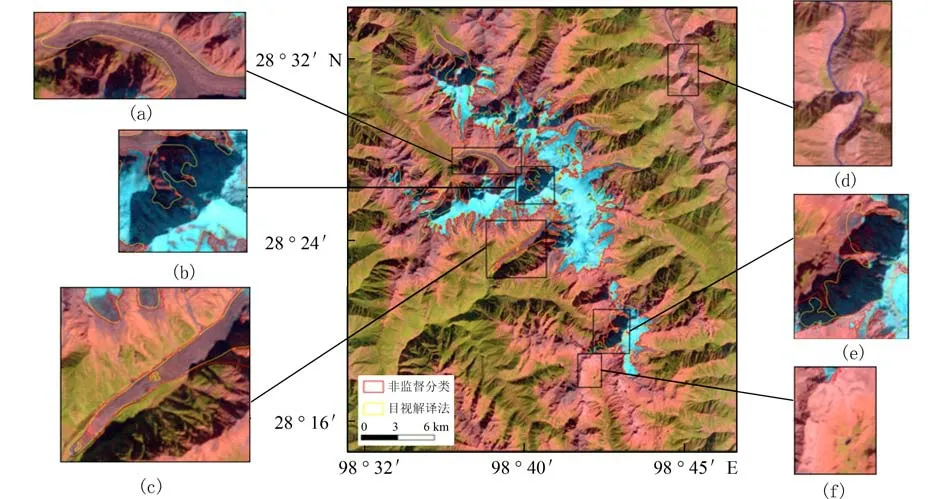
图8 面向对象分类提取梅里雪山地区冰川信息结果Fig. 8 Glacier information extraction of Meili Snow Mountain based on object oriented classification
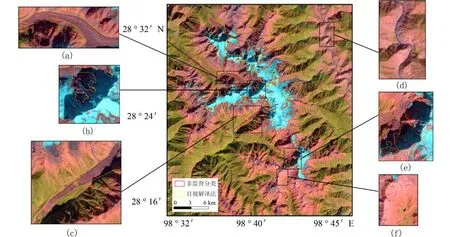
图9 神经网络分类提取梅里雪山地区冰川信息结果Fig. 9 Glacier information extraction of Meili Snow Mountain based on neural network classification
基于遥感影像的山岳冰川信息计算机解译方法从不同的原理角度出发提取冰川信息,不同方法提取的结果各异,但每种方法都有各自的优缺点.表4 结合已有研究成果与本文试验结果,综合比较了6 种分类方法优缺点. 非监督分类法不需要人为干涉,提取冰川信息的效率最高,但是整体提取效果较差、精度较低,裸地错分严重,山体阴影区及冰碛覆盖区中的冰川未被有效识别. 监督分类法非冰川错分的概率较低,并解决了裸地错分的问题,但冰川信息提取效果受样本质量影响,主要问题是水体被错分为冰川、山体阴影区中的冰川未被全部识别出、有冰碛覆盖物的冰川被漏分. 比值阈值法、雪盖指数法(NDSI)均有效地消除了山体阴影的影响,但无法区分水体与冰川,且有冰碛覆盖物的冰川被漏分的问题仍未得到有效地解决. 面向对象分类法(OBIA)可以有效地区分水体与冰川,精度相对较高,但操作相对复杂,精度依赖于知识规则的建立. 本文选取的6 种提取方法中,神经网络分类法是精度最高的一种方法,但是由于样本数量较少、训练深度学习模型的迭代次数较少,整体的冰川精度未达到理想水平. 如何有效地结合传统的计算机自动解译方法,提高深度学习冰川信息提取精度,利用有效的标签对大量数据进行深度挖掘分析且减轻神经网络对于数据的依赖程度,需要进一步的研究.
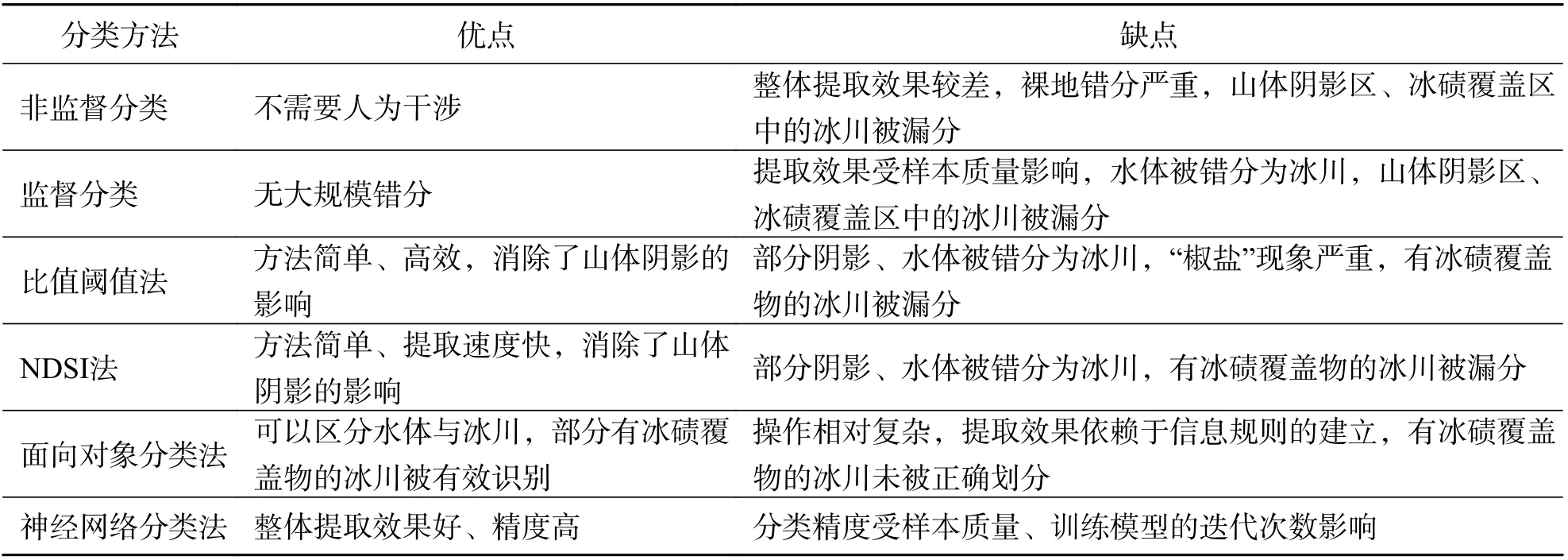
表4 梅里雪山地区冰川分类方法比较Tab. 4 Comparison of glacier classification methods in Meili Snow Mountain
3.2 目视修正为了得到更精准的梅里雪山地区冰川信息,本文结合Google Earth 数据和DEM 数据,在神经网络分类法提取冰川信息的基础上,对其进行了二次目视解译,最终得到梅里雪山地区1989—2019 年较为精确的4 期冰川信息提取成果.利用DEM 数据,通过水文分析得到梅里雪山地区的山脊线对冰川进行分割,得到了55 条独立的冰川,并通过冰川制图得到梅里雪山1989 年—2019年冰川边界变化图(图10). 通过分析得出,1989 年梅里雪山地区冰川面积达139.58 km2,2019 年冰川面积退缩至115.81 km2. 近30 年来,梅里雪山地区冰川面积共退缩23.77 km2,年均退缩0.79 km2,面积相对退缩率为17.03%,年均相对退缩率为0.57%(表5). 计算公式如下:
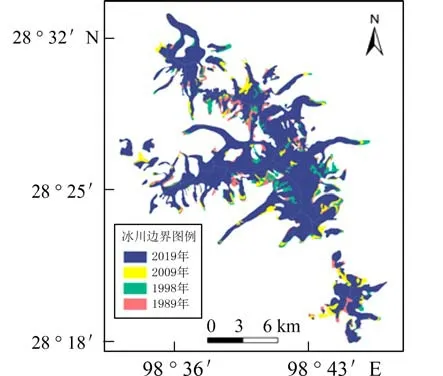
图10 1989—2019 年梅里雪山地区冰川边界变化Fig. 10 Glacier boundary changes in Meili Snow Mountain from 1989 to 2019


表5 梅里雪山冰川面积变化统计Tab. 5 Statistics of glacier area change in Meili Snow Mountain
其中,RS代表面积绝对变化速率,S代表面积变化量,t代表时段年长;RS′代表面积相对变化率,A代表时段起始年份冰川面积.
4 结论
本文利用TM、OLI 影像,通过非监督分类法、监督分类法、比值阈值法、雪盖指数法(NDSI)及基于多尺度分割的面向对象法(OBIA)及基于神经网络的冰川识别方法对梅里雪山地区冰川信息进行提取,综合比较6 种方法的分类效果. 在此基础上,对梅里雪山地区1989、1998、2009 年和2019年的冰川信息进行了提取,得出了以下结论:
(1)计算机自动解译方法中,基于神经网络的冰川识别方法不仅消除了山体阴影的影响,而且可以正确区分阴影、水体及冰川,有冰碛覆盖物的冰川信息也能被有效地提取,冰川信息提取精度最高. 但由于样本数量较少、训练深度学习模型的迭代次数较少,整体的冰川信息提取精度仍待提高.
(2)非监督分类法提取冰川信息效果最差、精度较低,裸地错分严重,山体阴影区、冰碛覆盖区中的冰川未被有效识别. 监督分类法解决了裸地错分的问题,但未提取出山体阴影区、冰碛覆盖区中的冰川,冰川信息提取效果受样本质量影响较大.比值阈值法和雪盖指数法(NDSI)均有效消除了山体阴影的影响,但无法区分水体与冰川,且有冰碛覆盖物的冰川被漏分的问题仍未得到有效地解决.面向对象分类法可以区分水体与冰川,精度相对较高,但操作相对复杂,精度依赖于知识规则的建立.
(3)目前基于遥感的冰川信息提取的过程中,目视解译仍然是精度最高的方法,并且是冰碛覆盖部分冰川信息解译效果最好的方法,在计算机自动解译后进行二次目视修正,仍是冰川信息解译中最重要的部分.
(4)1989—2019 年梅里雪山地区冰川面积退缩了23.77 km2,年均退缩0.79 km2,面积相对退缩率为17.03%,年均相对退缩率为0.57%.
本文在解译冰川信息的过程中发现,目前传统的计算机自动解译方法提取的冰川信息效果较差.而目视解译的效率较低,并且受解译人员的经验和主观因素的影响,不同人员的解译会有一定的偏差. 在深度学习迅速发展的背景下,如何有效结合传统的计算机自动解译方法,提高深度学习冰川信息提取精度,利用有效的标签对大量数据进行深度挖掘分析且减轻神经网络对于数据的依赖程度是未来研究的方向.
